
基于LSTM和N-gram的ESL文章的语法错误自动纠正方法
2018-07-18 03:02谭咏梅杨一枭刘姝雯
中文信息学报 2018年6期
谭咏梅,杨一枭,杨 林,刘姝雯
(北京邮电大学 计算机学院,北京 100876)
0 引言
英语是当今世界上最主要的国际通用语言,全球有超过10亿人将英语作为第二语言使用。语法(syntactic)错误是ESL(English as Second Language)学习者最常犯的一种错误[1]。语法错误自动纠正(Grammatical Error Correction,GEC)指利用计算机对文章进行自动语法错误纠正。
冠词错误、介词错误、名词单复数错误、动词形式错误和主谓不一致错误是ESL学习者常犯的五类语法错误[2]。它们对文章智能评改系统的性能影响最大,因此本文重点关注并解决这五类错误。
这五类错误中,冠词和介词错误的变化形式有限,可将其看作序列标注问题,且长短时记忆(Long Short-Term Memory,LSTM)对于序列标注问题效果较好,因此,本文提出了一种基于LSTM的序列标注GEC方法。名词单复数错误、动词形式错误和主谓不一致错误变化形式多样,所对应的混淆集为开放集合。本文提出一种基于ESL和新闻语料的N-gram投票策略GEC方法。
1 相关工作
GEC开始于20世纪80年代,Writer’s Workbench主要使用规则进行语法错误纠正,随后出现了基于句法分析的Epistle系统,1993年微软的Word基于拓展短语结构语法(Augmented Phrase Structure Grammar)对文本进行语法错误纠正。
LSTM由Sepp Hochreiter和Jurgen Schmid-huber于1997年提出[3],通过设置输入门、输出门、遗忘门等,解决了循环神经网络(Recurrent Neural Network)的梯度消失和信息的长期依赖问题,在处理序列问题中,效果较为突出。
随着各种规模语料库的出现,基于语料库的统计方法成为有效的GEC方法。HOO在2011年、2012年连续举办了两年相关评测任务[4-5],CoNLL在2013年、2014年继续举办了相关评测任务[2,6]。
GEC方法主要可以分为基于规则和基于统计两类。基于规则的方法主要依赖语言学家编写的语法规则,可分为以下两类:
(1) 基于上下文无关规则驱动的方法。其主要依赖语言学家编写的语法规则进行错误检查[7],少量规则对系统不够实用,大量规则则会出现互相矛盾的问题。该方法局限性太大,错误检查范围有限。
(2) 基于简单统计的规则驱动的方法在提取规则的时候考虑了上下文[8],可以有效避免规则的错误使用,但错误纠正范围仍然有限。
基于统计的GEC方法[9-12],即使用机器学习的方法对英文写作中的错误进行纠正时,纠正的性能依赖于语料库的构建。本文在进行识别和纠正时,将新闻语料、ESL语料和纠正后的中国学生写的英文文章语料(PIGAI语料*www.pigai.org)混合使用。
在本文的N-gram方法中,使用大量的新闻语料进行N-gram的频次统计,以用于对名词、动词、主谓错误等的识别和纠正;在神经网络模型中,对不存在语法错误的语料进行人工错误生成,以平衡语料之间的差异并补充用于模型训练的语料。
对于冠词和介词的纠正,传统的GEC方法使用N-gram或者基于规则的方法对语法错误进行纠正。单纯的使用固定窗口大小的上下文信息进行纠正,信息使用并不充分,且当窗口大小变大时,难以对模型进行训练。LSTM网络模型可以学习到决定介词或者冠词使用的长期依赖信息,并且可以避免传统循环神经网络中可能发生的梯度消失等问题。
因此,本文将冠词和介词错误看作一项特殊的序列标注任务,提出一种基于LSTM的序列标注GEC方法。在训练时,使用ESL语料和补充语料,对特定冠词或介词进行标注。针对名词单复数错误、动词形式错误和主谓不一致错误,其混淆集为开放集合。提出一种基于ESL和新闻语料的N-gram投票策略的GEC方法。
2 基于LSTM和N-gram 的ESL文章的GEC方法
基于LSTM和N-gram的ESL文章的GEC方法系统架构如图1所示。
针对冠词和介词错误,将其看作一项特殊的序列标注任务,该文提出一种基于LSTM的序列标注GEC方法。首先,对于已有词性标注的训练语料进行预处理,将冠词词性用一个特殊标记“ART”代替,将介词词性用一个特殊标记“TO”代替,把上述标记与冠词或介词的位置进行对换。然后,使用LSTM进行模型训练。最后,将训练得到的模型用于测试数据。
针对名词单复数错误、动词形式错误和主谓不一致错误,混淆集为开放集合,提出基于ESL和新闻语料的N-gram投票策略的GEC方法。
2.1 N-gram搜索服务及知识库
2.1.1N-gram搜索服务
语法错误的纠正策略基于N-gram的频次统计,因此需首先建立N-gram搜索服务。使用的N-gram*http://webscope.sandbox.yahoo.com/catalog.php?datatype=l来源为约12 000个新闻网站2006年的所有新闻,统计信息如表1所示。

表1 N-gram详细信息
为了提高其查询效率,使用开源搜索引擎solr*https://lucene.apache.org/solr/对其建立倒排索引,提供搜索服务。
2.1.2知识库
冠词和介词的变化形式有限,都处于封闭集合内。针对冠词和介词建立有限混淆集。

图1 系统架构图
名词及动词不像冠词和介词那样变化形式有限,其变化形式是开放集合。因此针对名词错误、动词形式、主谓不一致错误分别建立变化表。
冠词混淆集冠词混淆集包含三种情况: the,a/an,null。null代表不使用冠词。
介词混淆集介词混淆集包含常见的17个介词: on,about,into,with,as,at,by,or,from,in,of,over,to,among,between,under,within。
名词单复数变化表名词单复数变化表包括: 名词单数、名词复数,如表2所示。

表2 名词单复数变化表
动词形式变化表动词形式变化表主要包括: 动词原形、过去式、过去分词、现在分词,如表3所示。

表3 动词形式变化表
动词单复数变化表动词单复数变化取决于其主语单复数形式。动词单复数变化表主要包括: 动词单数,动词复数,如表4所示。

表4 动词单复数变化表
2.2 移动窗口及N-gram投票策略
对混淆集为开放集的GEC方法,基于移动窗口[10]及N-gram投票策略。
2.2.1移动窗口
移动窗口(Moving Window)定义如式(1)所示。
MWi,k(w)={wi -j,…,wi -j+(k -1),j=0,k-1}
(1)
wi为句中第i个单词,k代表窗口大小,j为窗口内第一个单词与wi的距离。如表5所示。

表5 移动窗口
窗口大小k的选择和j的取值范围直接影响着GEC的效果,针对不同的错误类型,选择不同的k,j值。
2.2.2N-gram投票策略
本策略模拟现实生活中的投票表决机制,含语法错误候选的N-gram片段代表一个可能具有投票权利的候选人。由于语料库有限,N-gram片段的频次可能出现非常稀疏的情况。本策略设置一个最小有效频次,只有当查询到的频次高于最小有效频次时,此N-gram片段才具有投票权利。
在现实生活中,不同的人针对不同领域所投的票的重要性是不一样的,例如: 领域专家的投票重要性高于普通人。本策略使用N-gram片段长度模拟领域专家的专业程度,N-gram越长所投票的重要性越高。
最后,针对投票结果,得到纠正后的结果。具体算法如图2所示。

图2 N-gram投票策略
Fset和Wset为参数。Fset为最小有效频次,只有当查询到的频次大于Fset时才可参加投票。Wset用于调整不同长度N-gram片段投票的权重,N-gram片段长度越长其权重越大。
此算法基于语料库,由于一方面语料库规模有限不可能包含所有的片段,另一方面语料库中存在噪音数据。所以,设置最小有效频次Fset,只有当查询出的N-gram片段频次大于此频次,才能说明语料库中包含相关语料,此N-gram片段具有投票权利。依据实验对比,将Fset设置为100。
具有投票权利的N-gram片段的频次代表改为相应结果的概率。假设修改冠词错误时,“have an apple”的频次为2,“have the apple”的频次为1,“have apple”的频次为1。那么,根据语料库改为“have an apple”的概率将大于“have the apple”及“have apple”。而投票策略是要在“have an apple”、 “have the apple”及“have apple”中选出一个作为投票对象,本策略选择概率大的作为投票对象。
2.3 基于LSTM的标注纠正策略
该文对混淆集为固定集合的语法错误使用基于LSTM的标注纠正策略。
2.3.1LSTM模型原理
在进行序列数据的标注时,当前单词的标注信息一般依赖于上下文信息。传统的序列标注方法依赖统计或者融合的方法[13-14],而循环神经网络通过建立隐藏层的序列关系,可以很好的提取序列信息[3]。其中,LSTM通过设置门限单元和Cell,可以有效避免传统循环神经网络在训练时可能会出现的梯度消失和梯度爆炸等问题[15]。
相比单向的LSTM模型仅仅累积当前时刻之前的信息,双向的LSTM可以累积当前时刻的上下文信息,使得模型可以综合上下文信息进行序列的标注。
2.3.2基于LSTM的标注纠正策略
基于LSTM的标注模型如图3所示。模型首先将单词转换成单词向量作为模型的输入,每个时刻输入序列中相应位置的单词向量。在训练的过程中,词向量作为参数进行更新。模型使用词向量作为LSTM单元的输入,并在每个时刻,输出相应的标注向量。其中,标注集合为所有的词性集合和所有介词或者冠词的混淆集的并集。该标注向量的维度和标注集合总数一致,并通过softmax选择概率最大的标注进行标记。
标注模型依赖BPTT(back propagation through time)算法[3],使用随机梯度下降的方式进行监督训练。
本文针对混淆集固定的语法错误,即冠词和介词进行标注纠正。在标注之前,将序列中的冠词或者介词使用统一的标识进行表示。在标注时,统一的标识被标注成具体的介词或者冠词,实现语法中冠词或介词错误的纠正。
例如,在进行冠词纠错时:
原句:
“Debateonthelegislation,whichfacesavetothreatfrompresidentBush,istocontinuetoday.”
首先,将其处理为:
“DebateonARTlegislation,whichfacesARTvetothreatfrompresidentBush,istocontinuetoday.”
即,使用统一的符号”ART”进行代替句子中所有的冠词作为输入。
标注模型输出为:
“NNINtheNN,WDTVBZaNNNNINNNPNNP.VBZTOVBNN.”即,冠词部分标注为具体的冠词。其余部位输出相应的词性标注。
2.3.3人工错误生成
因新闻语料和ESL语料之间存在差异,故模型在训练时,对新闻语料进行人工错误补充,以减小语料之间的差异。根据语法错误的类型,随机选择句子中的动词或者名词进行形式的变化。例如,随机地将名词的单复数形式进行修改,将动词的时态进行修改等。
2.4 冠词错误识别与纠正
冠词错误主要包括: 冠词误用,冠词冗余,冠词缺失。错误类型举例如下。
1) 冠词误用:
例“It is alsotheadvance of surveillance technology.”
将“theadvance”改为“anadvance”。
2) 冠词冗余:
例“It givesthepolice a better control of the criminal.”
将“thepolice”改为“police”。
3) 冠词缺失:
例“Government had to uninstall all the devices in the end.”
将“Government”改为“Thegovernment”。
本文将冠词错误纠正看作一项特殊的序列标注任务,涉及三个子模块: 冠词错误预处理模块、冠词错误识别与纠正模块和冠词错误后处理模块。
因冠词缺失在冠词错误中的占比较小[2],本文主要处理前面两种错误类型。
2.4.1冠词错误预处理模块
将冠词词性用一个特殊标记“ART”代替,把词性与冠词的位置进行对换。这样,句子中所有出现冠词的地方都被替换为“ART”,而其对应的词性则被修改为此处应该出现的冠词。如“A_DTrecord_NN date_NN has_VBZ n’t_RB been_VBN set_VBN ._.”处理为“ART_Arecord_NN date_NN has_VBZ n’t_RB been_VBN set_VBN ._.”。
2.4.2冠词错误识别与纠正模块
根据给定句子,判断句子中可能存在冠词使用错误的位置,对句子进行词性标注,然后识别出所有词性被标注为冠词(a,an,the)的地方。使用基于LSTM的序列标注方法进行冠词错误识别与纠正。
基于LSTM的序列标注GEC方法,系统架构如图3所示。其中,wn为输入的待纠正句子的第n个单词,tn为输出的纠正后句子的第n个单词。首先,将输入句子中的每个单词转换为词向量表示;然后,经过两层LSTM模型,得到标注结果。

图3 基于LSTM的冠词、介词错误识别与纠正方法
2.4.3冠词错误后处理模块
将上一步骤的结果中为特殊标记“ART”的单词与词性标记进行对换,再将词性标记删除,得到最终输出结果。
2.5 介词错误识别与纠正
介词错误主要包括: 介词误用、介词冗余、介词缺失。错误类型举例如下。
1) 介词误用:
例“Pets are supposed to be chained when they are outonthe streets.”
将“onthe streets”改为“inthe streets”。
2) 介词冗余:
例“In that case,they would have no choice but to seekforthe power of loyal police.”
将“seekfor”改为“seek”。
3) 介词缺失:
例“Although we are not implantedwithchips we are exposed under CCTV.”
将“implanted”改为“implanted (with)”。
将介词错误纠正看作一项特殊的序列标注任务,涉及三个子模块: 介词错误预处理模块、介词错误识别与纠正模块和介词错误后处理模块。
因介词缺失在介词错误中的占比较小[2],本文主要处理前面两种错误类型。
2.5.1介词错误预处理模块
将介词词性用一个特殊标记“TO”代替,把词性与介词的位置进行对换。这样,句子中所有出现介词的地方都被替换为“TO”,而其对应的词性则被修改为此处应该出现的介词。如“Some_DT 0_CD institutions_NNS are_VBP part_NNof_INthe_DT pension_NN fund_NN ._.”处理为“Some_DT 0_CD institutions_NNS are_VBP part_NNTO_ofthe_DT pension_NN fund_NN ._.”。
2.5.2介词错误识别与纠正模块
根据给定句子,判断句子中可能存在介词使用错误的位置,对句子进行词性标注,然后识别出所有词性被标注为介词的地方。
使用基于LSTM的序列标注方法进行介词错误纠正,系统架构如图3所示。
2.5.3介词错误后处理模块
将上一步骤的结果中为特殊标记“TO”的单词与词性标记进行对换,再将词性标记删除,得到最终输出结果。
2.6 名词单复数错误纠正
名词单复数错误纠正模块基于名词单复数变化表及N-gram投票策略,主要针对名词单复数误用情况进行纠正。此模块具体纠正过程举例说明如下:
例“This will,if not already,caused problems as there are very limitedspacesfor us .”
将“spaces”改为“space”。
1) 对例句词性标注得到其词性序列,并提取词性标注为NN和NNS的单词得到错误候选集合E={problems,spaces};
2) 使用名词单复数变化表得到相应的纠正候选集合。如: spaces的纠正候选集合C={space,spaces};
3) 基于纠正候选集合,使用大小为3—5的移动窗口获取N-grams片段集合。使用N-gram投票策略得到得票最高的纠正候选,在原句中进行替换。如果“space”为得票最高纠正候选,则纠正后的句子为“This will,if not already,caused problems as there are very limitedspacefor us .”
2.7 动词及主谓不一致错误纠正
动词错误纠正模块主要针对动词形式误用情况及主谓不一致情况进行纠正。此模块依赖于动词形式变化表、动词单复数变化表及N-gram投票策略,具体纠正过程举例如下:
动词形式错误:
例“The more peopleusingit over us,the more power they will have on us.”
将“using”改为“use”。
主谓不一致:
例“Every move of usareeasily tracked.”
将“are”改为“is”。
1) 对句子词性标注得到其词性序列。针对动词形式错误,提取词性标注为VB、VBD、VBG、VBN的单词作为其错误候选。针对主谓不一致错误,提取词性标注为VBP、VBZ的单词作为其错误候选。
2) 根据错误候选及动词形式变化表/动词单复数变化表得到错误候选的纠正候选集合。
3) 针对纠正候选,使用大小为3—5的移动窗口获取N-grams片段集合。使用N-gram投票策略得到得票最高的纠正候选,并在原句中进行替换。
3 实验
3.1 实验数据
实验数据来源于CoNLL2013的GEC评测任务,统计结果如表6所示。由于CoNLL2013语料没有正确的词性标注,且CoNLL2013训练语料较PIGAI词性标注语料[13]和Brown语料*http://www.nltk.org/nltk_data/规模较小。因此,使用PIGAI词性标注语料、Brown语料和标注后的CoNLL语料等扩充LSTM训练语料标注时,用Stanford 标注工具对其进行词性标注。其中,CoNLL2013语料和PIGAI语料作为ESL语料,Brown语料作为补充的新闻语料参与模型的训练。
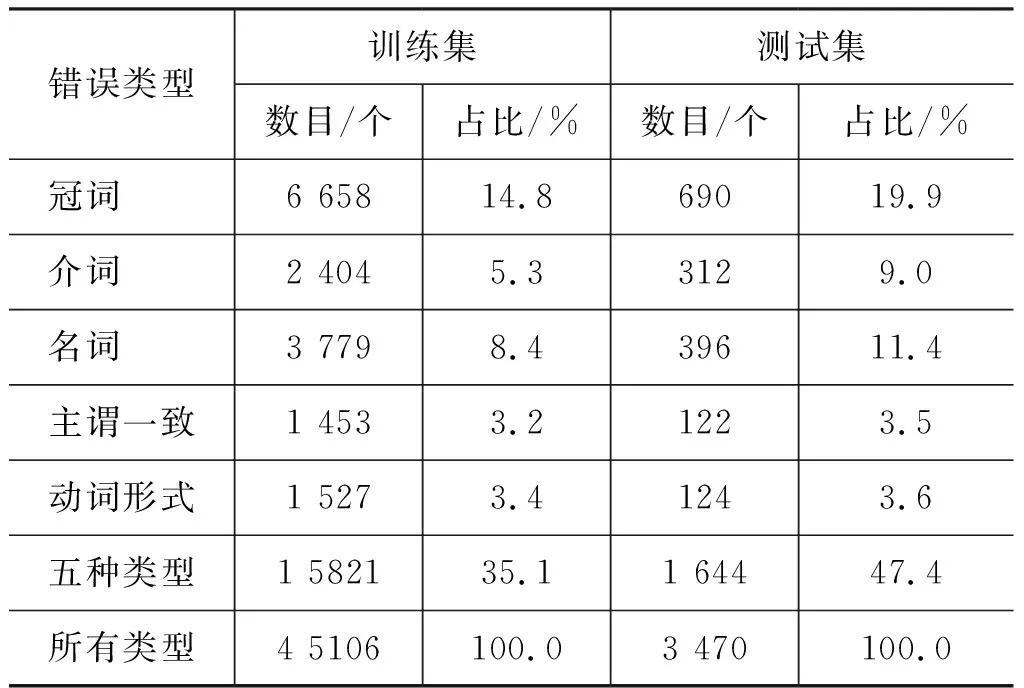
表6 CoNLL2013的GEC评测任务数据统计
CoNLL2013的GEC评测任务数据里标注了多种错误类型,但评测任务主要是针对冠词错误、介词错误、名词错误、主谓一致和动词形式错误这五种占比较高[2]的错误类型。
3.2 评价方法
CoNLL2013评价标准为F1[2],定义如式(2)所示。
(2)
其中P与R分别表示准确率和召回率,定义如式(3)、式(4)所示。
Ncorrect指系统修改正确的错误的数目,Npredicted指系统修改的错误的数目,Ntarget指语料本身存在的错误的数目。
3.3 实验结果及分析
基于LSTM和N-gram的ESL文章的GEC方法在CoNLL2013的GEC评测数据上的实验结果如表7到表9,并与基于语料库的英语文章语法错误检查及纠正方法[16]和2013年评测第一名UIUC[12]进行比较。
如表7所示,针对冠词错误的纠正,本文的方法的F1值比UIUC方法高5%,比Corpus GEC方法高5%。针对介词错误的纠正,本文方法的F1值比UIUC方法高21%,比Corpus GEC方法高13%。表明基于LSTM的序列标注GEC方法对冠词和介词语法错误纠正任务有效。这是由于词向量包含丰富的上下文信息,而使用LSTM更好地学习到了决定冠词或者介词使用的长期的依赖信息,所以结果较好。

表7 冠词及介词错误纠正结果
如表8所示在仅使用N-gram+vote投票策略对名词及动词错误纠正时,F1值与UIUC方法都还存在一定的差距。这是由于N-gram + vote策略基于的新闻语料与所需纠正的ESL文章具有差异性,会将大量正确句子改为错误句子。名词及动词变化表不能涵盖所有的名词及动词的变化形式,导致纠正名词及动词时还具有一定的局限性。

表8 名词及动词错误纠正结果
如表9所示,对于全部五种类型错误的纠正,本文方法均优于UIUC方法,在2013年CoNLL的GEC数据上总的F1值为33.87%,超过第一名UIUC总的F1值31.20%。总的实验结果表明基于LSTM和N-gram 的ESL文章的语法错误自动纠正方法是有效的。
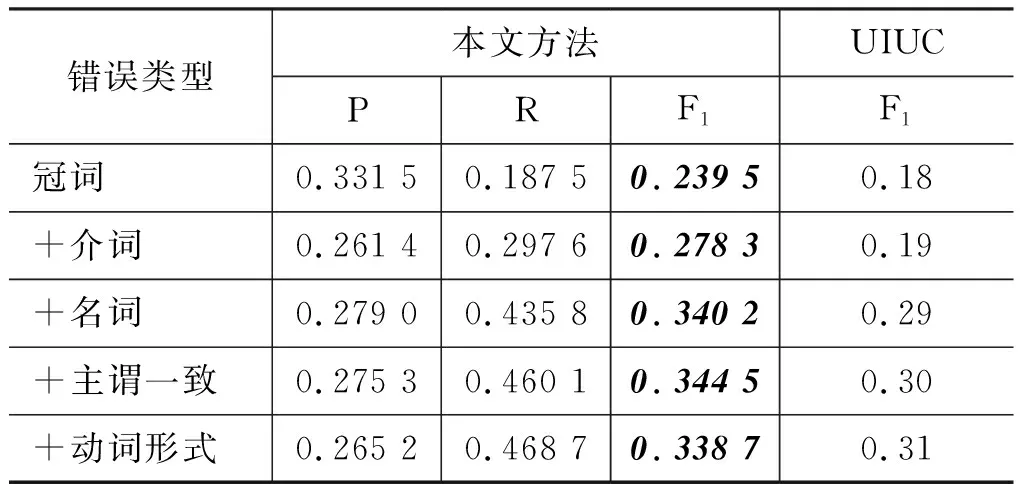
表9 所有类型错误纠正结果
4 结束语
针对冠词和介词错误,本文提出一种基于LSTM的序列标注GEC方法。针对名词单复数错误、动词形式错误和主谓不一致错误,本文提出一种基于N-gram投票策略的GEC方法。在2013年CoNLL的GEC评测数据上,针对冠词错误纠正F1为38.05%,介词错误的纠正F1为28.89%,所有五种类型错误的总F1为33.87%,均高于评测第一名UIUC。实验结果表明,本文方法对冠词及介词错误的纠正是有效的,但仍有一些问题存在。例如,在介词缺失和冠词缺失时如何进行纠正;在纠正名词单复数错误及动词错误时,如何避免将正确句子改为错误句子;及动词形式中如果出现被动语态错误时该怎么纠正等。这些问题仍需进一步研究解决。
猜你喜欢
通信技术(2021年12期)2022-01-25
初中生学习指导·提升版(2021年4期)2021-09-10
疯狂英语·新悦读(2020年5期)2020-06-20
试题与研究·中考英语(2014年3期)2015-05-21
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
外语教学理论与实践(2014年1期)2014-06-15
中文信息学报(2012年2期)2012-06-29
中学英语之友·上(2010年8期)2010-09-20
阅读(中年级)(2009年5期)2009-06-23
