
基于石油领域本体的概念相似度级联模型①
2018-07-18 06:07赵国梁宫法明
计算机系统应用 2018年7期
赵国梁, 宫法明
(中国石油大学(华东) 计算机与通信工程学院, 青岛 266580)
1 概述
概念的语义相似度计算已经成为数据挖掘和信息检索领域的基本问题, 而且是自然语言处理的核心问题[1]. 例如, 语义相似性度量已应用于词义消歧[2]、信息提取[3]、文本相似度计算[4]以及文本聚类[5].
目前, 语义相似度的计算方法大致可分为两类:(1)依赖于分类中术语间的层次关系的基于路径的度量; (2)根据概念的特异性分类, 基于语料库信息内容(IC)的测度. 许多相似度计算是建立在本体的内在结构上, 在本文中, 我们首先考虑在查询概念对在本体中的路径信息, 然后我们不仅考虑了相关概念的父类集合, 并考虑了子代集合. 这种方法可以获取进行相似性度量的概念对间更多、更具体的信息. 事实上, 不同的度量方法从不同的角度刻画了两个对象的相似性或相异性, 这可能有助于整合各种相似性度量以获得更好的结果.
我们引入了一个新的级联模型进行高效的概念相似度排名. 与以前的方法不同, 级联模型能够逐步修剪本体和细化排名顺序. 通过级联, 可以产生更高质量的结果和更快的查询执行时间. (1)在粗计算阶段, 我们的方法是针对整个本体使用基于路径的训练措施获来计算过两个概念间的相似度得分; (2)精确计算及扩展阶段, 我们使用不同的IC算法从不同的方面来计算每一个概念的相似度得分. 为了充分考虑概念中的可用信息, 将目标概念使用其子代和父代概念集进行扩展,然后用于下一个阶段的训练; (3)利用权重来平衡粗计算和精确计算的相似度得分; (4)最后通过训练BP神经网络得到概念的相似性排名. 我们在石油本体模型和Babel-net上对本文的模型进行了测试, 实验结果表明我们的方法提高了相似度计算的准确度.
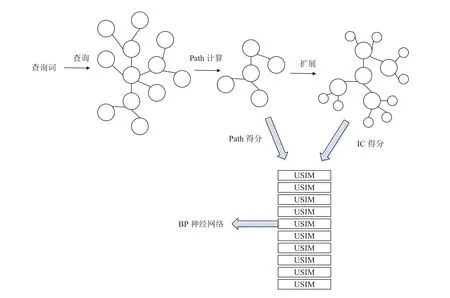
图1 概念相似度计算的模型体系结构
2 相关工作
语义相似度估计是自然语言处理(NLP)的一个重要组成部分, 在许多NLP应用中得到了成功的应用.基于路径的方法主要考虑概念在本体中的路径距离来确定它们的语义相似度[6]. 基于IC的方法主要比较所涉及的概念及其父代或子代的属性[7]. 与基于路径的方法相比, 基于IC的度量对可变语义距离的问题不敏感[8].此外, 基于IC的方法强调了本体的同一层次上的术语并不总是等价的思想, 因为它们在本体中的重要性或特异性是由它们的信息量来衡量的[9]. Alexopoulou[10]提出了“Closest Sense”的方法, 该方法计算了可能的概念语义类型与目标词周围的语义类型之间的平均最短距离. Garla[11]使用 Patwardhan[12]提出的语义关系算法对基于路径和基于分类的相似性度量进行评价.Resnik[8]和Jiang[13]提出的语义相似度算法被广泛的使用. Rada[14]提出了一种基于两个目标词间最短路径的相似度计算方法. Wu[9]定义一个相似性度量由三部分组成: 概念在本体中的公共子集, 概念间的公共属性以及它们的最近公共父代距离.
最近, Dang[15]提出了一种新的两阶段学习模型.Dang使用一组有限的特征集合, 包括加权词语、相邻性和扩展项来训练整个检索的排名函数. Wang[16]提出了一种级联模型, 通过逐步细化和精炼候选文档集来尽可能减少检索中的不利因素, 提高检索的质量. 朱新华等[17]提出了一种综合的词语语义相似度计算方法,算法通过特殊的单调递减曲线的边权重策略, 并且采用以词语距离为主要因素、分支节点数和分支间隔为微调节参数的方法, 改进了现有的词林词语相似度算法. 李阳等[18]提出一种通用的实体相似度计算方法, 通过清洗噪声数据, 对数值、列表以及文本等不同数据类型进行预处理, 使用SVM、随机森林等集成学习模型以及排序学习模型进行建模. Pesquita[19]考虑了影响相似度的内在和外在问题, 以及如何处理这些问题, 强调了不同环境下的最佳措施, 并比较了不同的实施策略及其使用效果.
3 模型
在这部分, 我们介绍计算概念相似度的级联模型的具体细节. 模型的体系结构如图1所示.
3.1 粗计算阶段: 基于路径的相似度算法
粗计算阶段是模型的第一阶段, 我们使用基于路径的相似计算方法来计算概念间的相似度得分, 然后将该得分以及路径集合作为后续阶段输入数据, 以生成最终的查询结果.
Leacock[20]最先提出了一种基于路径的本体相似度计算方法, 并且被广泛的使用. 假设c1和c2是两个概念, 他们考虑了概念的最大深度, 定义了公式(1):

本文考虑到不同本体领域存在许多差异性, 采用Batet[21]提出的特定领域的相似性度量模型, 它充分考虑了本体的特性以及多重继承的关系, 与石油领域本体基本相似, 如公式(2)所示:
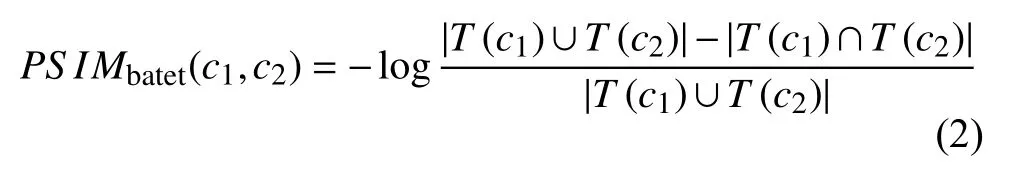
本文使用公式(1)对公式(2)进行了改进, 如公式(3)所示:
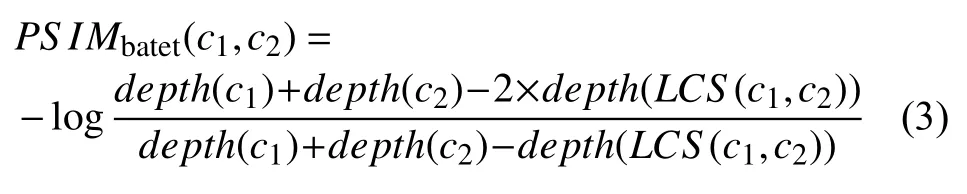
3.2 精确计算阶段: 基于IC相似度计算
在精确计算阶段, 本文使用基于IC的相似度算法去计算从扩建阶段获得的所有结果集中每个概念的得分. 每个概念的得分将被作为构建成特征向量. 本阶段将采用5种目前使用最为广泛的基于IC的相似度算法作为精确计算阶段的方法, 先使用这5种去获取概念在本体上部(概念与其父代集合)的相似度得分, 并且通过扩展阶段重新定义公式, 来获取概念在本体下部(概念与其子代集合)的相似度得分. 以下五种算法都是基于概念在本体上部的相似度计算方法.
Resnik首先把概念信息量(IC)应用到相似度计算中. 在Resnik的模型中, 相似度通过两个概念的最小公共集合的IC进行计算, 公式定义如下:
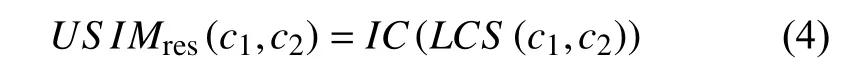
Lin[22]在Resnik相似度算法的基础上, 额外考虑了概念和概念的IC信息量值. 模型(Lin)定义如下:
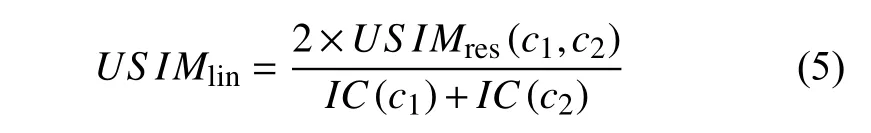
Jiang和Conrath提出的模型根据公式(6)进行量化:
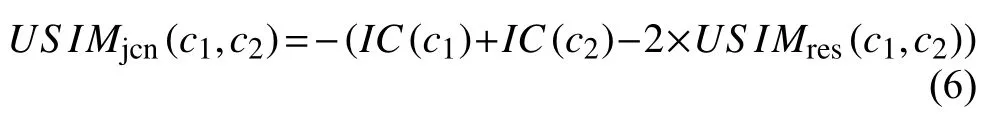
Sánchez和Batet提出了一种新的语义相似度度量方法, 定义如公式(7)所示:
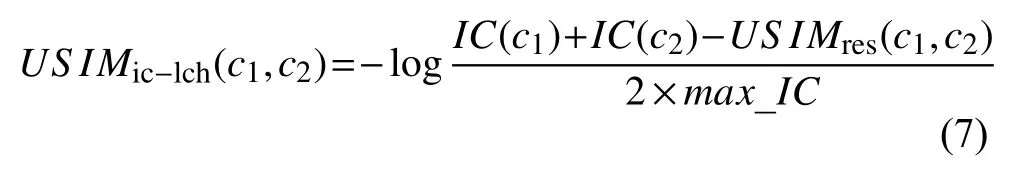
通过考虑到本体中概念对之间的语义距离以及概念在本体中的深度, Wu提出的相似度计算模型定义如公式(8):
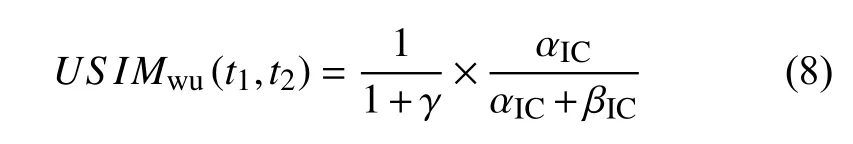
3.3 扩展阶段
为了能够获取概念的更多属性, 以便获得更好的数据进行训练, 使最终计算结果的准确性更高、更具潜力. 因此, 我们扩展本体概念集合以获得更多信息.
Zhang[23]发现两个概念的共同子集同样影响相似性得分. 本文中, 我们认为两个概念的下一代子集影响两个概念间的相似度得分, 如图2所示.
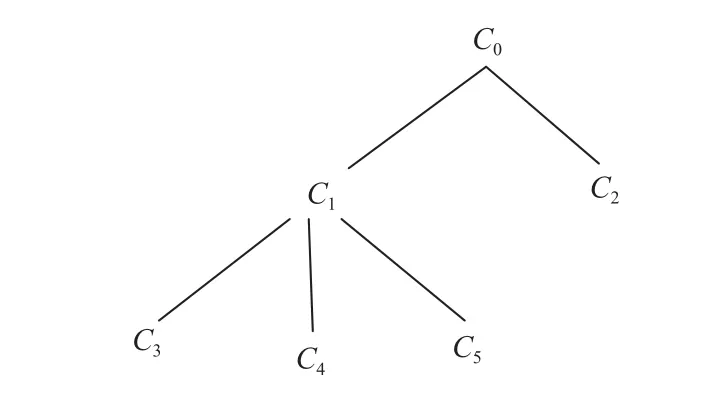
图2 概念子集图
这意味着两个概念的子代集合也可以用来描述它们的相似性度量. 我们在下面的公式中重新定义子代公共部分的IC值:

最终, Resnik提出的相似的计算模型就被重新定义为如下:
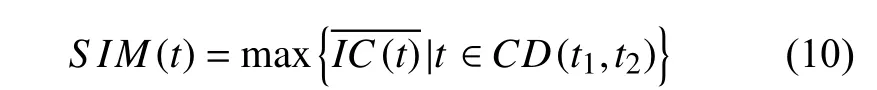
其余四种相似度算法以同样的方式重新定义.
3.4 相似度特征
本文把两个概念之间的相似度得分作为是每一对概念的特征值, 通过构造基于本体的不同相似度模型获取相似性得分值来进一步构造特征向量来表示概念对, 相似度特征表示为公式(11):

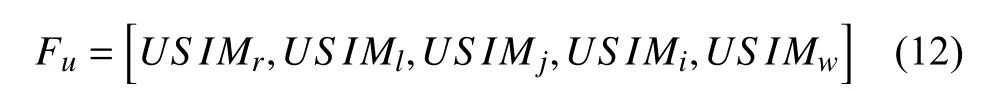
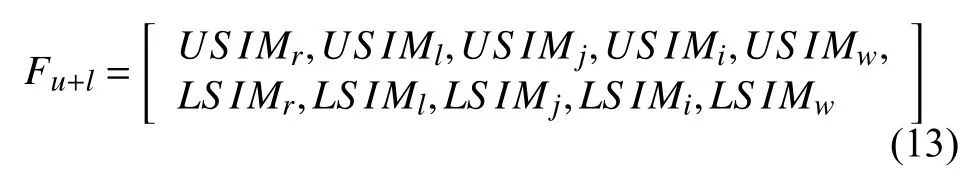
3.5 得分权重
基于路径的相似度算法只考虑到概念对在本体中的路径长度, 忽略了每个概念的信息量. 相反, 基于IC的相似度算法只考虑到每个概念的信息量, 忽略了每个概念对在本体中的路径长度. 为了充分利用这两种信息, 本文通过使用得分门网络来实现的, 该网络为每个概念生成聚合权重, 控制两种相似度算法计算的的相似度得分对最终相似度得分的贡献. 综合特征向量被改写为公式(14).

3.6 BP神经网络
BP神经网络是误差反向传播算法训练的多层前馈神经网络, 是目前应用最广泛的神经网络模型之一.BP网络可以学习和存储大量的输入输出映射关系, 而不需要揭示描述映射关系的数学方程. BP神经网络的结构由输入层、隐层和输出层, 在神经元的连接权值和阈值, 输入层和输出层只有一个, 它的单位数量与实际输入输出参数一致; 隐层可以是一个或多个神经元参与, 数字必须重复计算. 由于三层神经网络具有很好的函数逼近功能, 结构设计简单, 运算能力强. 在本文中, 我们是用三层BP神经网络, 如图3所示.
隐藏层节点的数目由公式(15)确定:


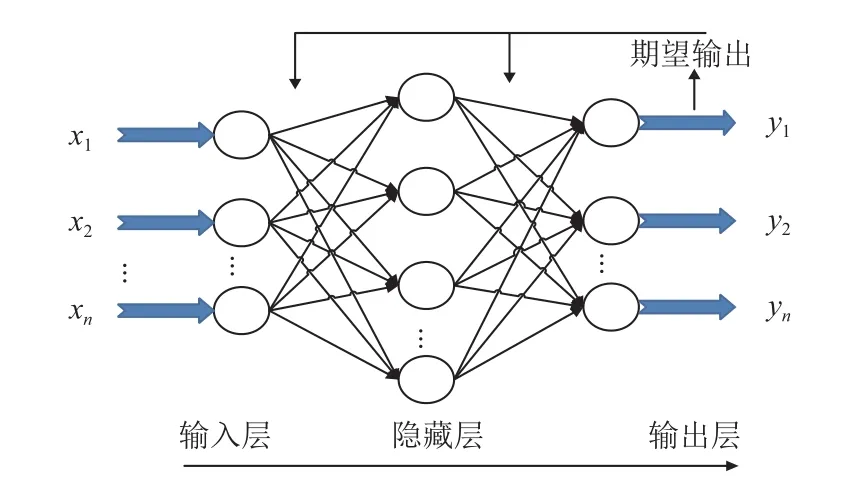
图3 三层 BP 神经网络
训练BP神经网络时, 我们将最终的相似度特征向量作为BP神经网络的输入, 将两个概念对应的相似度分类作为输出.
对于输出结果, 我们期望BP神经网络将两个概念的相似性分数划分为10个类别, 0个代表不相似, 9个代表极其相似 (相同), 值越高, 相似度越高.
4 实验评估
4.1 数据集
在本文中, 石油本体和BabelNet[24]用来作为数据集测试本文的方法. 我们收集了石油领域的数据, 建立了自己的石油领域本体. BabelNet 是一个多语言语义网络, 其概念和关系是利用自动映射算法从英语中最大的有效语义词典WordNet[25]和最大的覆盖面的百科全书Wikipedia中获得的.
4.2 评判基准
为了得到一个比较基准, 我们的实验标准类似于Miller和Charlest提出的基准, 给予五十名受试者(四十名石油工程学生和十名石油领域教授)相同的330个名词对(30个名词对与Miller和Charles相同,300个名词对是关于石油的). 这些操作和Miller和Charles的用法完全一样. 一半的受试者以随机顺序收到单词对的列表, 另一半接受固定顺序的列表. 对于同一概念对, Miller和Charles基准的平均评分和本文中评价基准的平均评分之间的相关程度为95%, 说明我们的基准是有效的.
4.3 实验结果
为了验证所提出方法的有效性, 本研究采用十倍交叉验证, 并以精确度作为验证指标. 在十次交叉验证中, 数据集被随机划分为十个相等的子集, 验证过程重复十次. 每次保留其中一个子集作为验证数据, 其余四个子集作为训练数据. 交叉验证的十个结果的平均值产生一个总体估计. 使用公式(17)表示的准确率和召回率来判断实验结果,

表1和表2列出了实验的预测结果特点, 在石油本体和babelnet上采用了不同的相似性度量策略. 从表格中, 我们可以看出, 采用基于路径、基于概念父代、子代扩展集合的信息量相似度计算方法相结合的特征通常比只采用其中一种策略对应的综合特征具有更高的精度.
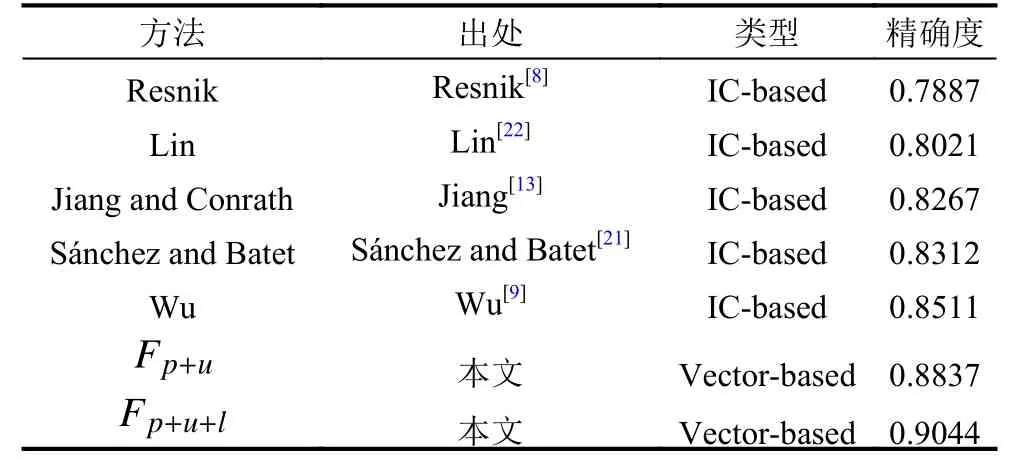
表1 不同相似性算法在石油本体中的精度得分
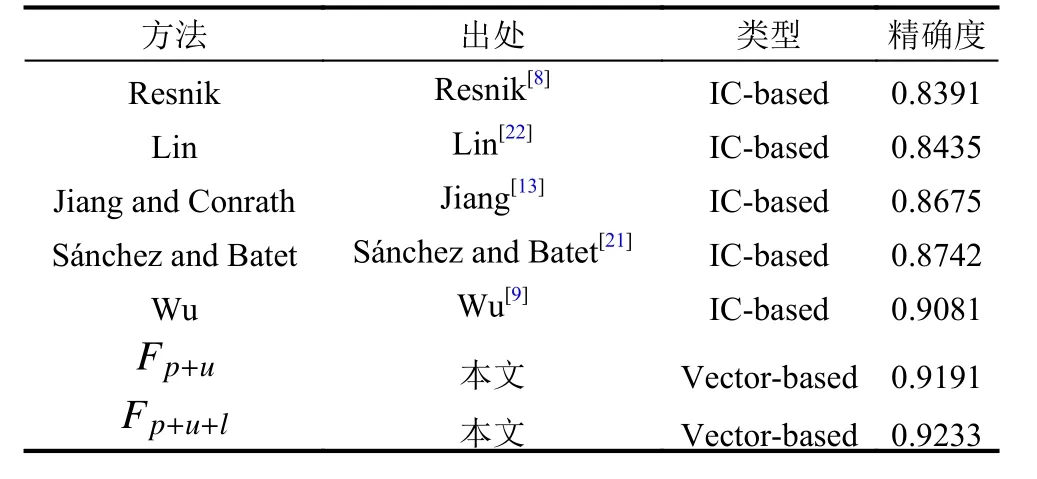
表2 不同相似性算法在 BabelNet中的精度得分
从表2中的结果可以得出几个结论. 本文中的相似度计算方法在石油本体和BabelNet获得最高的精确度得分, 分别为90.44%和92.33%. 这表明我们从本体中获得的信息越多, 分类器的预测能力就越好. 本文中的算法在不同的本体上表现出良好的性能.
5 结论
在本文的研究中, 我们提出了一种基于石油本体的概念对语义相似性的计算方法. 将不同相似性测度得到的信息作为BP神经网络的输入. 我们相信, 基于路径的、基于IC和扩展的基于IC的测度的更多信息可以提高预测性能, 我们的方法的缺点是计算量大, 预测性能会受到BP神经网络的影响. 将来, 我们计划采用一种更全面的方法来预测两个概念的相似性.
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
哈哈画报(2021年10期)2021-02-28
河北画报(2020年8期)2020-10-27
五邑大学学报(自然科学版)(2019年3期)2019-09-06
小型微型计算机系统(2019年6期)2019-06-06
江西教育B(2019年2期)2019-04-12
中国诗歌(2018年6期)2018-11-14
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
图书与情报(2013年1期)2013-11-16
