
基于犹豫模糊语言术语集的正交模糊聚类算法①
2018-07-18 06:06:18王慧冰林铭炜姚志强
计算机系统应用 2018年7期
王慧冰, 林铭炜, 姚志强
(福建师范大学 数学与信息学院, 福州 350117)
聚类算法已经在经济学, 计算机科学, 天文学等各个领域得到广泛应用[1,2]. 传统的聚类算法是根据准确的数值对确定的对象进行划分的, 但是随着社会的进步, 模糊数据、糊模模型成为了一种新的趋势, 这意味着传统的硬划分聚类方法也要逐渐转向软划分聚类方法[3]. 研究模糊聚类的前提是要引入模糊集理论, 因为模糊聚类是基于模糊集进行划分的. Zadeh[4]首先引入模糊语言学理论, 然后将模糊集应用于多标准决策(MCDM)问题中, 称之为模糊 MCDM. 之后, Torra[5]提出了犹豫模糊集(HFSs), 它允许使用多个属于[0, 1]范围的值来评估一个属性, 增强了模糊性. 然而, 在实际问题中, 我们更多的时候得到的数据是定性信息, 不是定量值[6,7]. 例如, 当人们评估汽车的性能时, 他们可能会更偏向于使用“差”, “好”, “非常好”等语言术语来表达他们的评估结果. 因此, Zadeh提出了采用模糊语言学方法对评估信息进行建模的思想, 最典型的模型有:二类模糊集合模型[8], 二元语言模型[9]和虚拟语言模型[10]. 这些语言模型的缺陷是: 它们要求一个对象的一个属性只能对应一个语言术语[11]. 基于犹豫模糊集思想和模糊语言学方法, Rodríguez 等人[12]提出了HFLTSs的概念, 它允许一个对象的一个属性可以用多个语言术语来描述, 提高了评估属性的灵活性.
目前已经存在许多关于模糊聚类的研究, 比如, 文献[13]和文献[14]提出了基于直觉模糊集(IFSs)的聚类方法; 文献[15]提出了犹豫模糊环境下的最小生成树(MST)聚类方法; 文献[16]通过计算犹豫模糊集的相关系数得到相关系数矩阵, 然后构造相关系数矩阵的等价矩阵, 最后, 基于λ置信值切割矩阵得到聚类结果; 文献[17]提出了一种层次犹豫模糊k-means聚类方法, 以层次聚类的结果作为k-means的初始聚类中心进行迭代以获得最终聚类结果, 该算法减少了k-means的迭代次数, 计算成本和聚类时间; 近期, 文献[18]将文献[16]的方法扩展到犹豫模糊积性集(HMSs)上使用,并取得了一定的成果; 文献[19]则提出了一种基于犹豫模糊环境下的正交聚类算法. 但是目前还没有比较成熟的基于HFLTSs的聚类方法, 而HFLTSs在实际应用中较HFSs、IFSs及HMSs的使用更加广泛且灵活性更大, 因此, 本文针对HFLTSs提出了一种新的正交模糊聚类算法.
1 理论基础
1.1 犹豫模糊语言术语集
定义 1[12]. 设是给定的一个语言术语集, 一个HFLTS,指的是上有限个连续的语言术语的有序子集, 表示为:
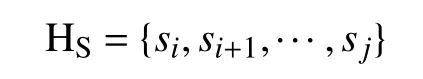
备注1. 在定义1中, HFLTSs是一些离散的数值,为了避免丢失语言信息, 可以将离散形式扩展为连续形式, 即,
1.2 上下文无关语法
文献[20]提出了一种上下文无关文法, 我们可以将一些简单而丰富的语言表达通过转换函数[21]转换成HFLTSs.
定义2. 假设表示将语言表达转换成HFLTSs的转换函数表示上下文无关方法是语言术语集.通过将转换成的表达式如下:
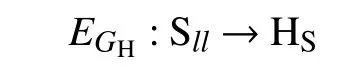
具体转换过程如下:

例 1. S={极差, 很差, 差, 一般, 好, 很好, 极好}作为一本书的语言术语集, 假设一位评估者给出的对三本书的三个属性的评估结果如下:


2 基于 HFLTSs的距离测度
距离测度是聚类分析的重要指标之一[22], 本节将介绍基于HFLTSs的传统距离测度以及改进之后的距离测度.
2.1 传统距离测度
定义3[23].设是一个语言术语集,和是 S上的任意两个HFLTSs,表示中每一个语言术语的下标,指的是中的犹豫模糊语言术语元素(HFLTEs)个数,则之间的距离测度为:
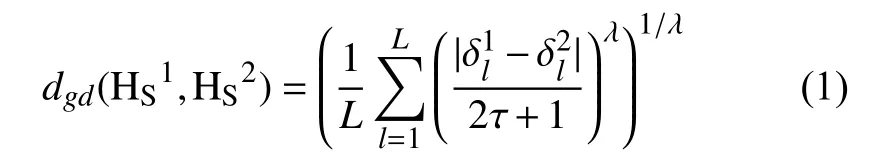

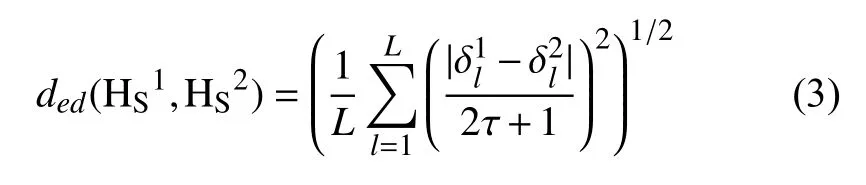
传统距离测度公式要求两个HFLTSs的HFLTEs个数一样, 而实际上如例 1所示, 两个不同的HFLTSs 的 HFLTEs 个数可能不同. 因此, 传统距离测度采用最大值、最小值或者平均值来补齐HFLTEs个数较少的HFLTSs, 使HFLTEs的个数一致[24].

传统距离测度方法, 涉及到有多个HFLTSs时, 是对这些HFLTEs个数进行两两对比, 得到距离测度.
2.2 新型距离测度
针对上面提到的传统距离测度存在的缺陷, 本文对其做出改进, 重新定义如定义4.
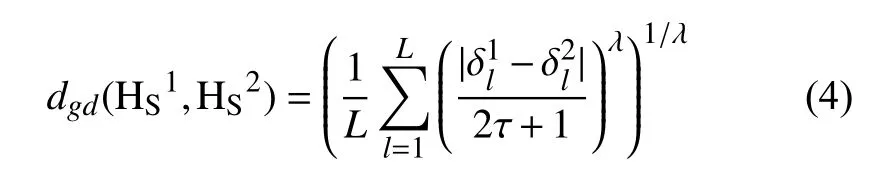
L表示需要进行对比的所有HFLTSs中HFLTEs个数最多的HFLTSs的长度.
2.3 考虑犹豫度的新型距离测度
HFLTSs 的传统距离测量只考虑了HFLTEs的值的差异, 而不考虑 HFLTEs的个数差异. 文献[25]在距离测度中考虑到了犹豫度这个影响因素, 提高了计算HFSs的距离测度的准确性和可靠性. 文献[26]受此启发, 也在HFLTSs的距离测度公式中考虑犹豫度对其的影响, 提出了新的距离测度公式.
定义5[20]. 设是一个语言术语集,上任意的一个HFLTSs, 则的犹豫度定义为:
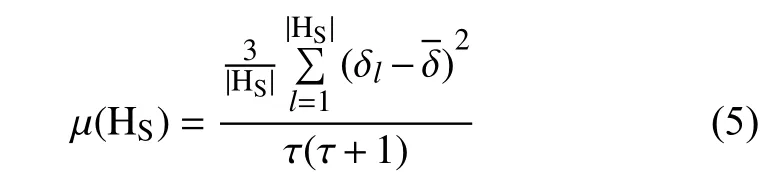
定义6[25]. 设是一个语言术语集是S 上任意两个HFLTSs, 定义的距离测度公式为:
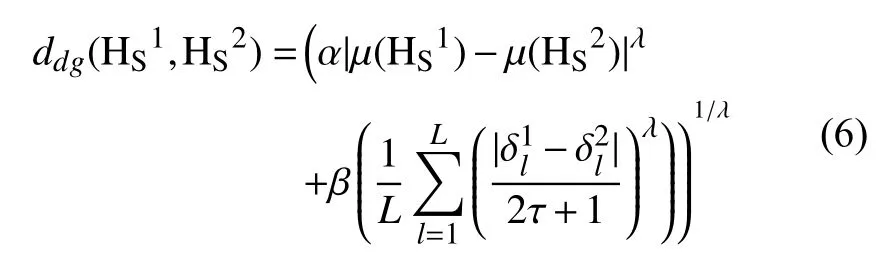
将上述距离测度扩展到多个属性的情况, 则定义为如定义7所示形式.
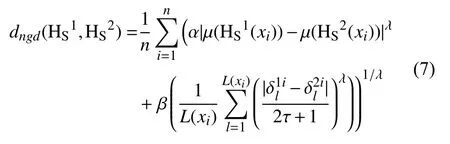
3 基于 HFLTSs的正交模糊聚类算法
3.1 基于犹豫模糊环境的正交聚类算法
近来, 文献[19]提出了基于HFSs的正交聚类算法,简化了聚类过程, 降低了算法复杂度, 提高了算法的效率. 该算法的步骤如下.
算法1. 基于HFSs正交模糊聚类算法.
步骤4. 根据列向量之间的正交关系对样本进行聚类, 具体原理如下:
为了说明计算的复杂性, 文献[19]随机生成一些HFSs用以对比正交模糊聚类算法和模糊网络聚类算法. 表1是两种聚类方法得到聚类结果之前的运行时间, 显然, 正交模糊聚类算法消耗更少的时间.

表1 运行时间对比 (单位: s)
但是该算法存在一个缺陷, 当样本数量大时, 会得到一个非常高维的距离测度矩阵, 如果矩阵中的所有不相同的值都作为置信水平对距离测度矩阵进行切割, 则需要消耗大量的计算成本, 且其中存在很多重复操作, 因此本文对该算法做出了改进.
3.2 基于HFLTSs的正交k-means聚类方法
针对算法1存在的问题, 如果我们可以解决样本数量大带来的高维矩阵难以计算的问题, 那么就可以进一步降低计算复杂度. 本文采取的解决方法是减少距离测度矩阵内部元素的差异性, 以此缩小置信水平的取值空间, 具体原理是采用构造等价矩阵[14](等价矩阵的概念将直接体现在算法步骤中), 替代原始距离测度矩阵, 在等价矩阵的基础上进行正交聚类. 后期,为了证明该算法的可行性和高效性, 还将通过k-means算法对聚类结果进行验证.
基于HFLTSs的正交模糊聚类算法过程如算法2.
算法2. 基于HFLTSs正交模糊聚类算法.

步骤5. 根据列向量之间的正交关系对样本进行聚类, 得到聚类结果.
K-means算法是常用的聚类算法, 该算法需要给定k值用以指定将目标对象划分成k个类别. 算法的第一个步骤是要计算初始数据的质心, 然后计算数据到质心的距离进而得到新的集群质心, 不断迭代这个过程, 直到质心的位置不再变化, 即聚类结束. 该算法精度高, 是最为广泛使用的聚类算法之一, 但是kmeans的效率高低很大程度上依靠于对k值和初始质心的选择, 选择不当往往造成迭代次数多, 计算量大,消耗时间成本大的问题, 因此本文只借助它的优点来对本文提出的算法结果的准确性进行验证.
本文将算法2的聚类结果作为k-means的初始数据, 代入到 k-means 算法中, 进行一次迭代运算, 求得迭代之后的聚类结果, 如果该结果与算法2的聚类结果一致, 则说明聚类结果准确.
4 实例分析
聚类分析在各行各业的应用十分常见, 对顾客进行细分是最为常见的分析需求, 本文以顾客细分为例,验证本文提出的正交模糊聚类算法的可行性和高效性.
设某公司要对自己的客户进行划分, 划分客户的主要参考因素为以下5个: (1)消费水平(2)收入水平(3)文化程度(4)上网时间长度(5)外貌长相等级5 个属性分别所占权重为: w=(0.25, 0.2, 0.25,0.15, 0.15)T, 依据语言评价术语集, S1={s–3: 非常低, s–2:很低, s–1: 低, s0: 一般, s1: 高, s2: 很高, s3: 非常高},S2={s–3: 非常短, s–2: 很短, s–1: 短, s0: 一般, s1: 长, s2: 很长, s3: 非常长}, 给出了 10 位客户的评估信息, 如表2所示.

表2 某公司针对 10 位客户的评估信息
步骤1. 将得到的评估信息进行规范化, 即为元素较少的HFLTSs补齐元素, 使HFLTEs个数一致:

步骤2. 根据距离测量公式(7)计算样本之间的距离测度, 其中得到距离测量矩阵
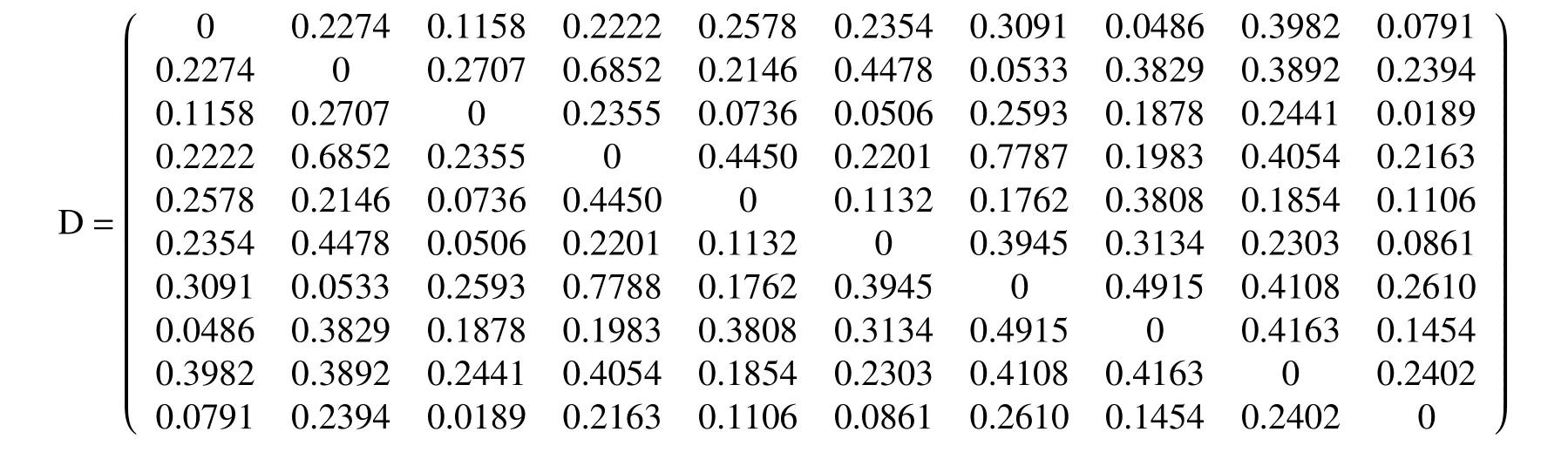
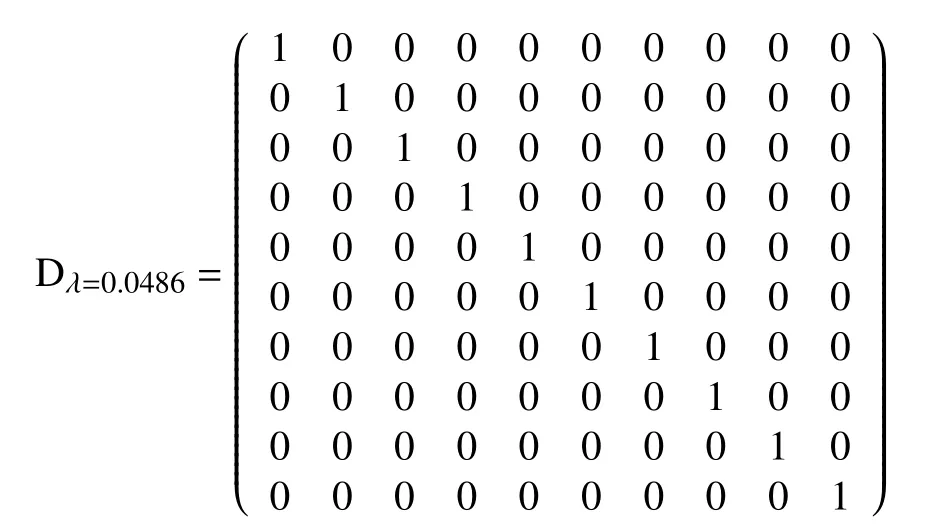
步骤3. 计算距离测量矩阵D的等价矩阵:

例如当λ=0.1983时,

当λ=0.0486时,
步骤6. 将上面得到的聚类结果作为k-means算法的初始集群, 做进一步聚类分析, 验证本文算法聚类结果的准确性. 因为分为10个类和1个类的结果都只有一种, 所以下面只对分为2–9个类的结果进行验证.


表3 正交模糊聚类结果
计算每一个样本到类之间的距离测度:
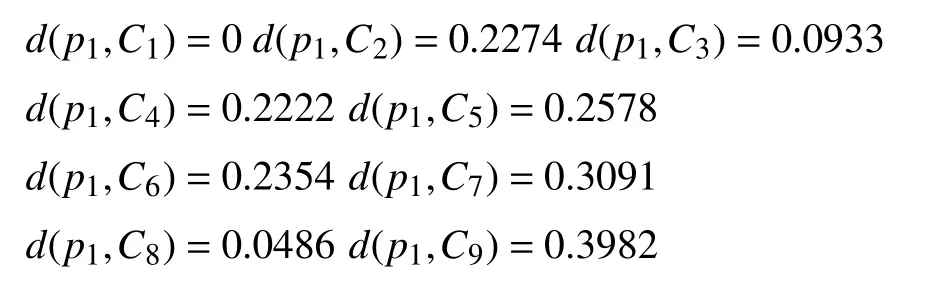

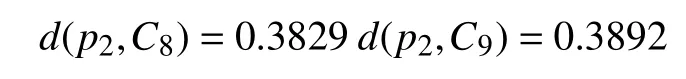
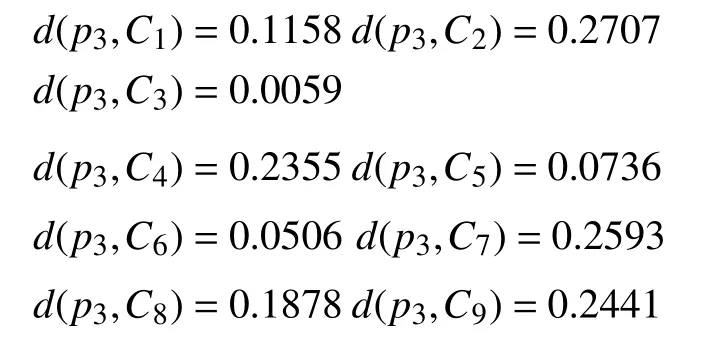
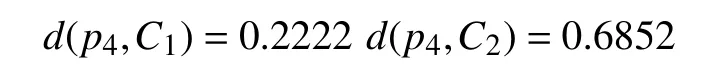


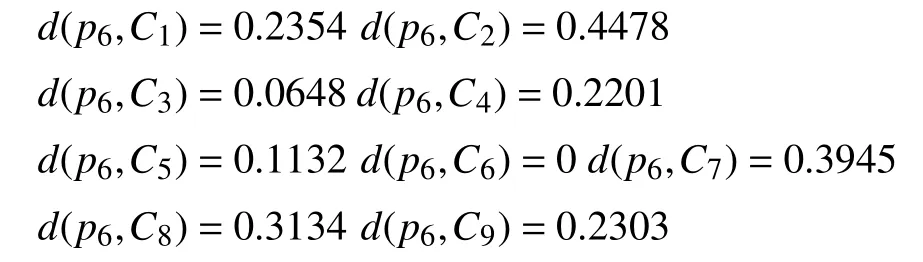
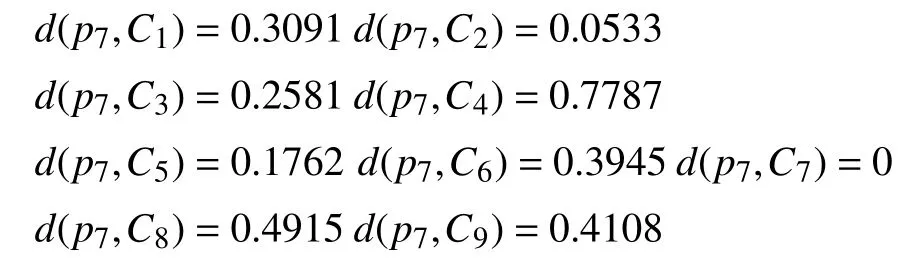
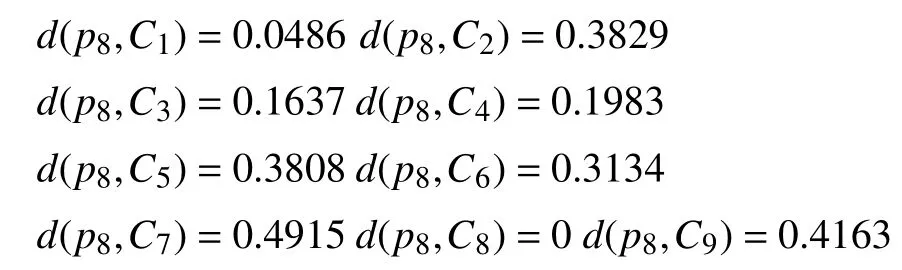
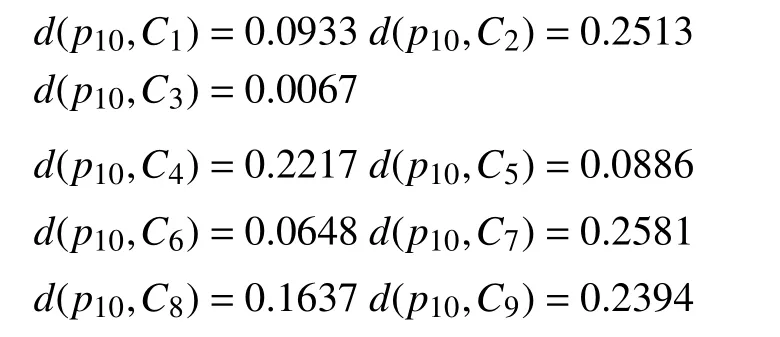
5 总结
模糊聚类逐渐成为新的研究热点, 许多模糊聚类算法已经被提出, 但是基于HFLTSs的模糊聚类算法尚未成熟, 存在计算复杂度高的缺陷, 而HFLTSs是比较流行而且灵活度很高的语言术语, 因此本文提出了计算复杂度相对较低的基于HFLTSs的正交模糊聚类算法. 该算法基于HFLTSs的距离测量矩阵采用正交思想, 确定无法划分为同个类别的样本, 得到聚类结果.为了验证算法的准确性和高效性, 本文还通过一个实例结合 k-means算法对本文算法进行了验证. 未来 , 我们将继续研究将该算法扩展延伸至可以应用于更多类型的语言术语, 例如概率语言术语集(PLTSs), 以及为了使该算法可以更好地应用于大数据做进一步的研究和努力.
猜你喜欢
数学物理学报(2022年3期)2022-05-25 13:33:12
数学物理学报(2022年2期)2022-04-26 14:07:54
数学物理学报(2020年4期)2020-09-07 09:14:00
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
电子测试(2017年15期)2017-12-18 07:19:27
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
中国科技术语(2012年3期)2012-03-20 14:36:13
中国科技术语(2012年3期)2012-03-20 14:36:11
