
安卓恶意软件的静态检测方法①
2018-07-18 06:06:16陈红闵胡江村
计算机系统应用 2018年7期
陈红闵, 胡江村
(中南民族大学 电子信息工程学院, 武汉 430074)
在如火如荼的高科技时期, Android软件的开发呈现了爆发式增长. 根据日前App Annie发布的《全球移动应用市场2016年回顾报告》显示数据表明,2015年至2016年两年全球应用下载量增长率为15%.可惜不幸的是, 这样的受欢迎程度也会吸引恶意软件开发者, 预置应用程序、捆绑下载、过度获取权限、山寨应用等防不胜防. 恶意应用程序的盛行却让用户的个人隐私逐渐走向透明, 在《2017Q1中国手机安全市场研究报告》[1]中提到, 89.6%的受访用户表示曾遭受过个人隐私信息泄露, 诈骗电话等, 如今信息安全成为很多用户的心腹大患. 360、金山等是深受用户喜爱的安全厂商也投入到移动安全领域, 而这些软件进行杀毒基本原理是通过匹配已知的病毒木马特征来确认入侵行为, 以防火墙、动态监控等方式进行主动防御,但缺点是依赖病毒特征库的更新, 学习新型病毒能力较弱[2,3]. 本文在前人的基础上进行进一步研究, 提取不同的特征组合进行检测. 首先, 通过反编译提取权限和高危API, 经过预处理组成权限——API特征集合, 利用机器学习分类算法进行检测, 并与单独特征集合进行分类的准确率进行比较, 得出相应的优化检测方案.并将服务器端的这一静态检测过程整合至开发的安卓恶意软件检测与防御系统中, 以向用户返回静态检测报告的方式返回检测结果.
1 Android应用程序安全机制
1.1 权限机制
Android是一个“权限分离”的系统, 在开发App过程中, 要想使用Android系统受限资源, 需在Android.xml文件中申请相关资源的权限, 利用唯一字符串来分别表示每一资源的权限. 权限主要由以下组成: 权限的名称; 属于的权限组; 保护级别. 每个权限通过protectionLevel来标识保护级别: normal, dangerous,signature, signatureorsystem[4]. 使用该权限时就要根据不同的保护级别进行认证, 如normal的权限只要申请了就可以使用, 而dangerous权限需要用户确认才能被使用. 在AndroidManifest.xml中会通过一些标签如<permission>标签, <permission-group>标签<permission-tree>等标签来指定package的权限信息.为此将所有应用程序的权限提取出来作为特征值, 具有一定的实际意义. 但是不同的App会申请不同的权限, 故使用频率有一定的差异, 同时恶意软件和良性软件在申请权限上也互不相同, 因此将恶意软件和正常软件中所申请的权限全部提取出来, 根据使用次数分别提取恶意和良性软件中排名前20的使用权限, 同时进行归类, 组成相应的权限特征集.
1.2 签名机制
应用程序通过签名机制唯一区别APK文件, 这样就解决了Android程序重名的问题, 因此开发者必须对开发的应用程序进行数字签名, 通过签名将应用程序作者和应用程序之间建立一种信任关系. 应用程序的签名文件和证书两者缺一不可, 当用户在安装应用程序的过程中, 首先会被系统的安装程序检查, 确定该应用程序是否被签名, 未被签名的应用程序, 系统安装程序将阻止该应用程序的安装, 同样的, 在应用程序需要升级时, 新版的应用程序也会被系统安装程序检查,确定其签名与旧版本的应用程序签名是否一致, 一致则更新, 不一致则被认为是新的应用程序来安装, 同时也防止了被恶意软件替换的风险. Android有jarsigner和signapk签名两种方式: jarsign对APK签名, 因其是Java内置的一个签名工具, 所以通过jarsign签名需要安装JDK. 而signapk是为Android应用程序签名专门开发的工具. jarsigner和signapk签名的签名算法大同小异. 通过上面的签名后会生成一个META-INF文件夹, 这里有三个文件: MANIFEST.MF、CERT.RSA、CERT.SF[5].
1.3 Android恶意软件分析检测方法及理论
恶意软件分析和检测技术可以分为三类: 静态分析, 动态分析和混合方法. 静态检测利用相应的反编译工具提取程序的静态特征如语法语义、签名等特性等进行分析, 评估软件安全. 在动态分析技术中, 应用程序被部署在模拟器上或被控制的设备上进行模拟和监控[6,7]. 而近年来国内外很多学术研究人员及一些商业软件公司已经意识到传统的基于签名的静态分析方法很容易受到攻击, 也无法实现对未知恶意软件的检测.特别是, 常见的隐形技术, 例如加密技术, 代码转换, 以及环境意识的方法等都具有生成恶意软件的能力[8]. 文献[9]提出的基于特征码的恶意代码检测方法利用特征值匹配技术进行检测与国外著名的Androguard Android恶意代码检测工具一样都是基于签名的检测方法, 但不能对未知恶意应用检测. 在文献[10]中作者对网络行为、短信等进行监控, 考虑到Android平台实际资源需求, 一般单独使用Monkey程序进行动态测试, 实用性不强. 在大数据时代, 数据挖掘技术越来越成熟, 云端处理能力越来越强, 很多研究者也将机器学习算法和巨大的恶意样本量结合起来进行相应的研究[11–13]. Justin Sahs[14]利用 Androguard 提取 APK 包恃征, 利用分类器训练这些特征来分类Android软件. 王超[15]设计了基于机器学习算法的Android恶意软件检测系统, 他将静态、动态、客户端和云端结合成一体,实行全方位的控制与监听检测. 解决了Android系统在权限控制的缺点, 实现了细粒度的权限控制. 并通过实验数据比较不同机器学习分类算法, 从而提高检测效率. 徐欣等人[16]设计并实现了一个恶意软件动态分析云平台, 通过基于虚拟化沙箱机制来判断目标软件是否是恶意软件, 但对网络的实时性和并发性要求较高.
2 方案介绍
本文在邵舒迪等人[17]提出的基于权限和API特征结合的Android恶意软件检测方法基础上进行相应的预处理过程及提取不同的特征集合, 同时运用不同的分类算法提高检测准确率. 然后将相应的静态检测过程整合至开发的安卓恶意软件检测与防御系统中, 以恶意软件检测报告详情方式返回给用户, 供用户知晓.
2.1 Android恶意程序检测流程
本文提出的Android恶意软件检测与防御系统,将静态检测与动态监控相结合, 实现在服务器端利用机器学习算法对已知正常和恶意软件进行训练学习,建立相应的分类模型, 对未知的恶意软件进行静态检测, 并返回相应的静态检测报告. 客户端通过对未知样本进行扫描, 与已存在的病毒库通过MD5值进行比对过滤, 同时通过监听广播发送与接收实时监听软件的行为信息, 并提供给用户防御与处理措施. 用户通过上传本地的APK文件至服务器端进行静态检测, 该系统能有效地用于对已知未知应用的恶意性进行检测. 整个系统检测流程如图1所示.
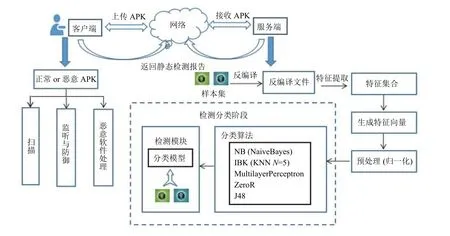
图1 系统检测框架
2.2 特征提取
在权限特征提取阶段, 采用静态分析方法, 分别收集正常和恶意APK软件作为训练样本库, 利用Java编写的解压应用程序对收集的样本进行批量解压, 利用Android自带的aapt(aapt.exe在SDK的platformt o o l s目录下)工具反编译A P K同时获取其AndroidManifest.xml文件中申请的权限信息, 将提取的权限进行格式化处理, 每个样本抽象为1×(n+1)维向量, 其数据格式为其中packagname是应用程序的名称, 是统计的Android应用程序申请的权限, 并将其存入Oracle数据库中, 为了统计恶意样本和正常样本申请权限的使用情况, 分别将得到的权限信息在数据库中存入两张不同的表permissiondesc和permissiondescmal中, 并分别选择将排名前20的权限提取出来, 通过程序抽象为1×20维向量该程序使用的权限标记为1, 未使用的则标记为0. 由于在此实验过程中要引入weka数据挖掘工具, 其处理数据集格式为Arff格式的数据, arff格式是weka专用的文件格式, 全称Attribute-Relation File Format. 它是一个ASCII文本文件, 记录了一些共享属性的实例. arff格式文件主要由两个部分构成, 头部定义和数据区. 头部定义包含了关系名称(relation name)、一些属性(attributes)和对应的类型. 数据区以@data开头, 故数据区一横行就代表一个样本实例, 竖行是作为属性和变量. 遍历样本生成权限特征向量集如下所示:

如图2和图3所示, 是正常样本和恶意软件排名前20的权限, 对比其使用情况发现, 两者重合申请的权限比较多, 故将其进行组合生成1×23维共有特征向量生成权限数据特征集如表1所示,将其输入weka中进行训练. 在预处理模块中选择信息增益InfoGainAttributeEval特征选择算法来衡量各权限在判断恶意软件上的贡献值大小. 在信息增益中, 重要性的衡量标准就是看特征能够为分类系统带来多少信息, 带来的信息越多, 该特征越重要. 即某权限特征的信息增益值越大, 即它为恶意值的贡献越大. 设置一定的阈值, 选择相应的特征重新进行训练, 比较其实验结果.

表1 权限数据特征
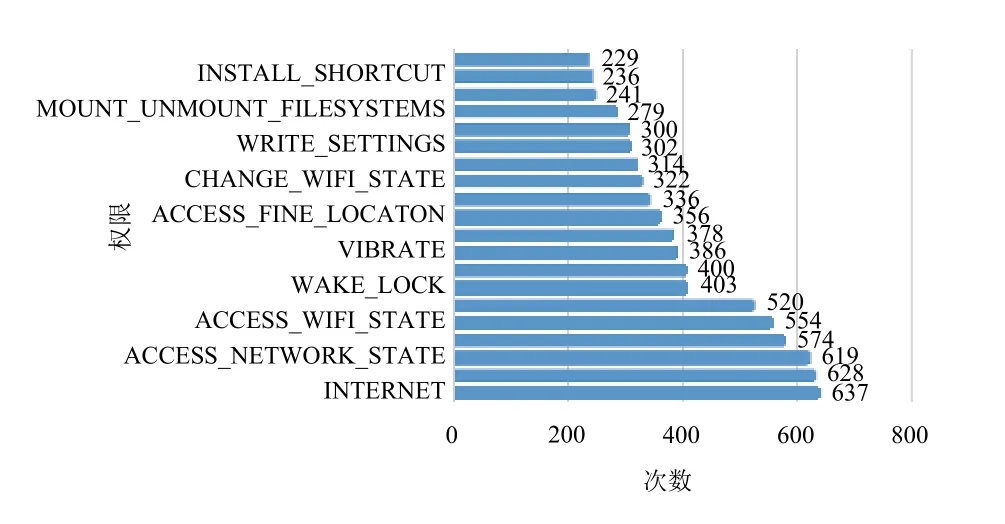
图2 正常样本权限统计直方图
在高危API特征提取阶段, 参照张锐[4]在其论文Android环境下恶意软件静态检测方法研究中提出的通过逆向解析Android软件安装包, 获取代码级的41种高危API作为另一种检测特征. 将得到的高危API特征存入数据库dangerousapi表中, 在提取高危API特征时, 将获取样本的APK文件进行解压得到文件如表2所示.
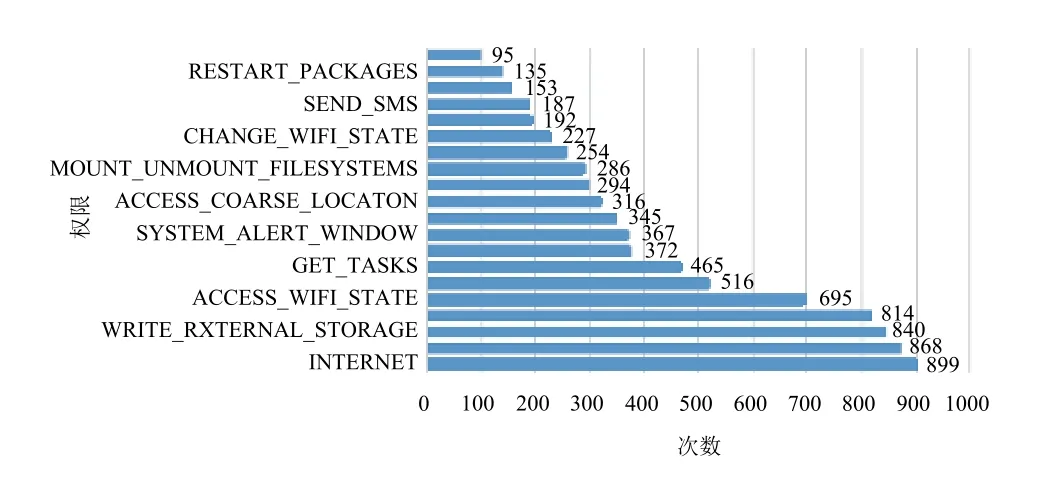
图3 恶意样本权限统计直方图

表2 APK文件
classes.dex是java源码编译后生成的java字节码文件, 在Dalvik虚拟机上执行, 它包含了所有的源码信息, 利用反编译工具Baksmali解析APK的classes.dex文件, 即可获得以smali为后缀的文件, 遍历所有smali文件获取每一APK高危API的使用次数生成特征空间向量. 根据Android官网提供的API信息及张锐[4]在其论文中统计的具备高危行为的41种API, 根据smali语法规则生成相对应的java函数形式,遍历所有smali文件得到41种API使用次数,每使用一次count++最后每一样本便生成1×41维特征向量smali文件中方法的表现形式:Lpackage/name/ObjectName;->MethodName(III)Z Lpackage/name/ObjectName;表示类型, MethodName 是方法名. III为参数(在此是3个整型参数), Z是返回类型(bool型). 方法的参数是一个接一个的, 中间没有隔开.
代码实现如下所示:


将其转为arff格式数据作为高危API数据特征集输入Weka中进行训练. 遍历样本得到API特征向量集如下所示:

由于单一权限和高危API信息能在一定程度上对恶意软件进行检测, 但是正确率不太高, 同时也存在一定的局限性, 所以考虑将其合并在一起作为统一特征集进行检测, 然后对得到的特征集进行相应的预处理过程选出最优特征子集, 提高分类器的正确率.
3 实验过程及结果分析
Weka自带了许多机器学习算法, 它能够用来进行模型的训练和预测. 当使用这些算法来构建模型的时候, 我们需要一些指标来评估这些模型的性能, 为此定义一组相关指标从各方面衡量实验效果. 针对一个二分类问题, 将实例分成正类(Postive)或者负类(Negative). 但是实际中分类时, 会出现4种情况:
(1) 真正类(True Positive, TP): 被模型预测为正类的正样本.
(2) 假正类(False Positive, FP): 被模型预测为正类的负样本.
(3) 假负类(False Negative, FN): 被模型预测为负类的正样本.
(4) 真负类(True Negative, TN): 被模型预测为负类的负样本.
1) 正确率(Accuracy)
正确率是我们最常见的评价指标, Accuracy =(TP+TN)/(P+N), 这个很容易理解, 就是被分对的样本数除以所有的样本数, 通常来说, 正确率越高, 分类器越好.
2) 错误率(Error Rate)
错误率则与正确率相反, 描述被分类器错分的比例, Error Rate = (FP+FN)/(P+N), 对某一个实例来说,分对与分错是互斥事件, 所以 Accuracy =1 –Error_Rate.
3) 精度(Precision)
精度是精确性的度量, 表示被分为正例的示例中实际为正例的比例, Precision=TP/(TP+FP).
4) 召回率(Recall)
召回率是覆盖面的度量, 度量有多个正例被分为正例, Recall=TP/(TP+FN)=TP/P=Sensitivity.
5) 灵敏度(Sensitivity)
灵敏度是将正样本预测为正样本的能力, Sensitivity=TP/(TP+FN), 可以看到召回率与灵敏度是一样的.
6) 特异度(Specificity)
特异度是将负样本预测为负样本的能力, Specificity=TN/(TN+FP).
7) ROC曲线
ROC (Receiver Operating Charateristic): ROC的主要分析工具为画在R O C空间的曲线, 横轴为1–Specificity, 纵轴为 Sensitivity. 在分类问题中, 一个阀值对应于一个特异性及灵敏度, 一个好的分类模型要求ROC曲线尽可能靠近图形的左上角.
8) AUC面积
AUC (Area Under roc Curve)值指处于ROC曲线下方的那部分面积大小, 一个理想的分类模型其AUC值为1, 通常其值在0.5至1.0之间, 较大的AUC代表了分类模型具备较好的性能[18].
3.1 实验过程
本次实验选取了552个正常样本和475个恶意样本作为实验的样本数据集, 为了避免数据的不均衡性,正常样本分别从木蚂蚁安卓市场(http://www.mumayi.com/)和安卓市场(http://apk.hiapk.com/)分类别通过自己编写的爬虫程序抓取, 包括影音、生活、社交、教育、购物等多个应用类别. 而475个恶意样本则来自于https://virusshare.com/国外一个共性病毒库网站上所收集的恶意软件样本集, 通过发邮件联系管理员注册接收邀请获得样本来源. 在分类算法的选择上, 使用基础分类器NB (NaiveBayes)、IBK (KNNN=1)、MP(MultilayerPerceptron)、J48、ZeroR五种分类器进行分类, 特征采用10折交叉检验来评估模型. 其中ZeroR分类器作为基分类器基准衡量其它分类器效果.
3.2 实验结果
步骤1. 只选取权限特征集permission进行训练,此时样本数据为24×1027维向量, 其中23维为前文所述正常和恶意样本的组合权限特征, 另一维为分类属性, 1027为总样本数量(后续实验相同), 不经过特征属性选择, 得到实验结果如表3所示.
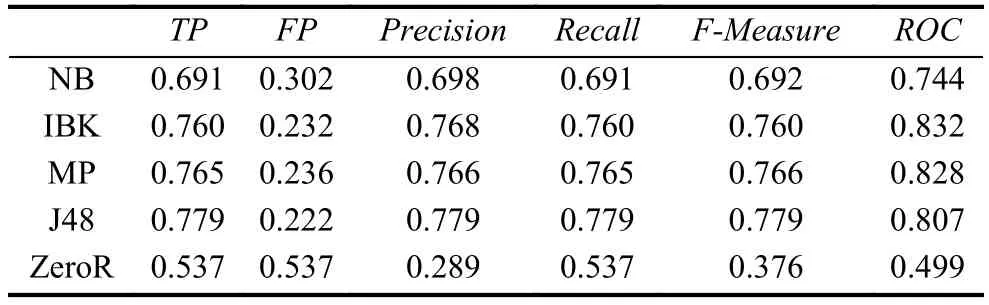
表3 五种分类算法检测结果(permission)
步骤2. 对权限特征集进行特征属性筛选(InfoGainAttributeEval Ranker -T 0.0 -N -1)得到权限优化特征集permissionInfoGain, 此时数据集为17×1027向量, 其中16维为经过信息增益算法得到各特征风险性评分筛选出的权限特征如图4所示, 所得实验结果如表4所示.
表4和表3实验结果对比可知, 将权限特征集用信息增益选择算法进行预处理之后, 虽然整体的正确率没有明显的改善, 但是ROC Area有明显提高, 而分类器中ROC指标对分类器预测准确性具有重要意义,故对权限作预处理对分类效果改善具有促进作用.
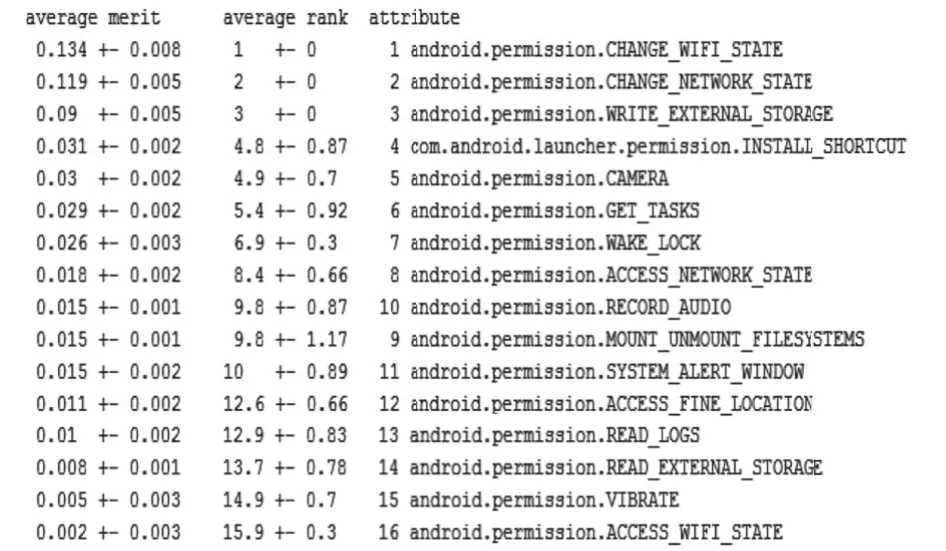
图4 权限特征信息增益结果
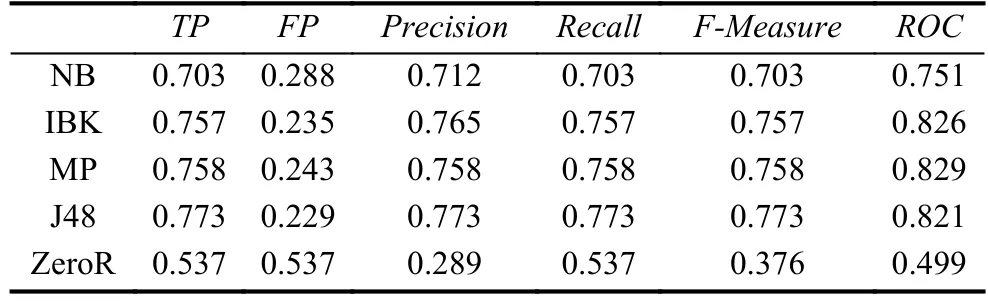
表4 五种分类算法检测结果(permissionInfoGain)
步骤3. 对高危API特征集API41, 此时样本数据为42×1027向量, 其中41维为前文所述的41种高危API, 1027为总样本数量, 利用上述5种算法进行实验,得到实验结果如表5所示.

表5 五种分类算法检测结果(API41)
步骤4. 将权限和API特征集permission-API组合至至一起进行实验, 此时样本数据为58×1027向量, 其中57维为16种权限和41种高危API的组合, 102为总样本数量得到实验结果如表6所示.

表6 五种分类算法检测结果(permission-API)
据上述4张表的结果均可以看出, 选择NB、IBK、MP、J48四种分类器效果均比基分类器ZeoR效果好, 说明上述实验结果是有实际意义的. 同时将表3和表5的实验结果与表6的实验结果对比可以看出, 将权限和高危API进行联合检测比单独使用权限(permission)特征和高危API特征进行检测的模型有较高的检测率和准确率. 故后续实验过程中选择经过预处理的权限特征和API组合成整体特征集进行训练具有实际意义.
3.3 结果比较
为了评估本方案的有效性, 本文将提出的方法与近年来的相关工作进行对比, 魏理豪、艾解清等人[5]2016年提出了将Android权限、敏感API调用、MD5等特征进行分析处理, 共同协作完成对Android应用程序的安全检测. 如表7所示是其实验结果.
由表7结果与本方法中表6中所得到的实验结果对比可知, 在所选取的分类算法大体相同的情况下, 本文选择较少的特征得到较好的检测准确率, 稍显优势.
4 实验分析
由于在weka中得到的ROC曲线图不够清晰而且无法导出, 因此通过result对象得到TP Rate和FP Rate数组, 利用SPSS软件绘制了其ROC曲线图. 图5、图6和图7分别是根据上述实验结果画出的ROC曲线.
从上述ROC曲线图中可以看出, 当选择单独权限和API特征时, IBK和J48分类器分类效果明显好于其他两类分类器, 而将两特征结合起来时,Multilayer Perceptron分类效果优于另外三种分类器.

图6 permissionInfoGain ROC曲线

图7 permission-API ROC曲线
5 结论
当我们生活越来越依赖手机时, Android平台安全问题也越来越受大众关注. 而现有的安全防护软件缺乏对未知恶意软件的检测, 故针对Android移动平台恶意软件进行快速有效的分析检测成为当务之急, 本文提出的将权限和API特征结合起来对APK进行静态检测过程只是作为设计与开发的安卓恶意软件防御与检测系统中的一部分, 后续会将这部分功能嵌入至自己开发的系统中使其能实现完整的检测与防御功能,使恶意行为能防患于未然. 但是本文提出的方案还存在一些待改进的地方: 如在特征集预处理过程中利用多种预处理算法选取子特征集后进然后比较各分类器的准确率, 样本集数量不够多也不够均衡, 如果收集更多的样本进行训练可能会得到更好的分类效果. 后续将会在更大的样本空间及提取不同的静态特征上进行检测研究, 提高分类器的检测率及准确率.
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:24:00
电脑报(2019年12期)2019-09-10 05:08:20
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
机电信息(2015年9期)2015-02-27 15:55:56
电子设计工程(2015年15期)2015-02-27 12:07:33
电测与仪表(2014年15期)2014-04-04 12:05:20
上海金属(2013年6期)2013-12-20 07:57:59
电脑迷(2012年15期)2012-04-29 17:09:47
