
基于改进的K近邻和支持向量机客户流失预测
2018-07-13 03:28卢光跃王航龙李创创赵宇翔李四维
西安邮电大学学报 2018年2期
卢光跃,王航龙,李创创,赵宇翔,李四维
(西安邮电大学 陕西省信息通信网络及安全重点实验室, 陕西 西安 710121)
有效预测客户流失情况,可以提升客户挽留率。电信客户流失预测是一个典型的不平衡数据二分类问题[1],客户流失数据集的主要特点有:数据集存在极度的非均衡性;两类样本错分代价之间的差异性大,可以用非均衡代价来刻画;数据量大,维数高等[2]。
K近邻(K-nearest neighbor,KNN)算法是一种简单易行的数据挖掘分类方法、其基于类比思想的学习算法,每个类别都要具有相当数量及代表性的训练样本才能确保分类的精确度[3],所以对平衡数据的分类效果好。由于分类时需要计算测试样本到所有训练集样本之间的距离,所以计算量与存储量都比较大,经典的KNN算法很难在大数据样本集上得以良好应用[4]。当数据集里两类样本数量不均衡时,会导致判决规则倾斜于多数类样本,从而会降低少数类的检测精度[5-6]。
支持向量机(support vector machine,SVM)是数据挖掘领域比较经典的分类器,在1995年由Vapnik提出[7],是一种基于统计学习理论和结构风险最小化理论的机器学习方法[8],它在解决高维非线性数据集的分类问题时表现出了优良的分类性能[9]。SVM算法在样本均衡的数据集上有较好的分类效果,当数据集样本不均衡时,分类效果较差,分类的结果偏向于多数类样本[10],从而使少数类样本的漏检概率增大。通过进一步对传统SVM错分样本的具体分布进行分析,发现其错分的样本点基本聚集在分类平面附近[11]。
电信客户流失预测模型中流失客户的检测精度是人们关注的焦点,然而流失客户数目远远少于非流失客户数目。针对这类样本非均衡的问题,数据方面常见的解决方法为随机过取样算法(Over SVM)和随机欠取样算法(Under SVM)[12]。随机过取样算法采用随机复制训练集中少数类样本,从而使采样后的训练集中两类样本数目保持均衡[13]。然而,随机增加样本不仅使计算量增加,而且使分类间隔减小,难以正确检测,泛化能力变差。随机欠取样算法采用随机去除训练集中的多数类部分样本,从而使两类样本数量基本相当[14]。由于欠取样算法并不能够代表原多数类样本的完备信息,所以有可能使得多数类检测精度极度降低,算法的稳定性欠佳。改进的SVM-KNN组合算法EDKSVM(euclidean distance nearest neighbor and support vector machine)[15],虽然减少了KNN的邻域样本数量,但是支持向量中仍存在噪声点,这些噪声点作为邻域样本同样会降低少数类的分类精度,虽然降低了KNN算法对近邻参数的依赖,但由于邻域样本本身的不均衡性和噪声点的存在,少数类的精度同样会降低。
针对KNN、SVM、Under SVM、Over SVM和EDKSVM算法的不足,本文将给出一种基于加权K近邻和支持向量机(weighted K-nearest neighbor and support vector machine,W-KSVM)的电信客户流失预测算法,先利用SVM删除支持向量集中多数类错分的支持向量,然后将剩余的全部支持向量作为加权KNN的邻域样本,融合二者的优势进行分类。
1 KNN和SVM算法
1.1 KNN算法
KNN算法是非参数学习中一种简单而有效的方法,为最近邻算法的拓展。它以N个训练样本作为邻域样本,计算测试集中每个点到邻域样本的距离,对距离进行排序,找出距离最近的K个训练样本,即K个最近邻,然后对选出的两类样本进行统计,哪个类别近邻数目多,则该样本点就会判定为该类。
1.2 SVM算法
支持向量机的核心是求解最优分类超平面。假设训练样本为(xi,yi)(i=1,2,…,n),其中,xi∈l代表l维样本,yi∈{-1,+1}代表类标签。通常将样本通过映射函数Φ(x)从原始的空间映射到高维特征空间,来提高分类精度。在高维映射空间中寻找分类超平面wΦ(x)+b=0,然后利用结构风险最小化理论通过优化分类平面的权向量w和b,得到最大分类间隔平面。
问题的核心是在以下约束条件下求解目标函数的最小值,其本质是一个凸二次规划问题

(1)
其中,C为惩罚系数,C越大错分数目越少,但泛化能力下降,通过调节C能平衡泛化能力和训练误差[16],能控制对错分的样本的惩罚程度。ξi为松弛因子,表示训练样本不满足约束的容忍程度。Φ(x)为映射函数。
利用拉格朗日乘子法将问题转化为其对偶问题进行求解,即

(2)
其中αi为拉格朗日乘子,满足KKT(Karush-Kuhn- Tucker)条件
αi{yi[wΦ(xi)+b]-1-ξi}=0,(C-αi)ξi=0。
(3)
求解式(2),可得
且分类超平面为
最终所得分类决策函数为
(4)
2 针对非平衡样本的W-KSVM算法
W-KSVM算法基于删除多数类错分支持向量后剩余的支持向量作为加权KNN的邻域样本,在特征空间用SVM和加权KNN组合算法进行分类,充分地利用了二者的优势对非均衡数据进行分类。
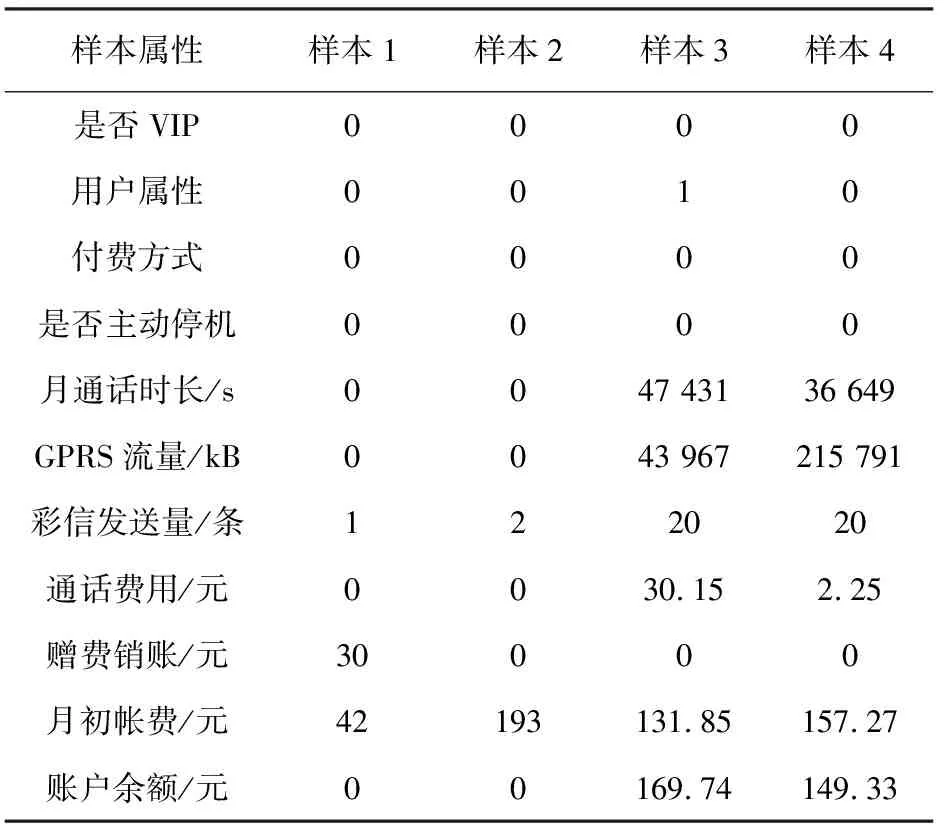
在训练数据集上运用标准的SVM得到支持向量集J。由式(2)求得αi,若0<αi yi[wΦ(xi)+b]-1-ξi=0, 所以 yi[wΦ(xi)+b]=1, 于是,样本xi是标准的支持向量。 得到多数类和少数类的支持向量后,计算支持向量样本点到分类超平面的距离 (5) 对于多数类支持向量而言,当γi≤0时,样本落入到少数类一侧,故该样本被错分。可以删除掉γi≤0的多数类样本点,但分类超平面会发生偏移。为了防止分类平面的过度偏移,影响整体分类性能,对于稀疏数据集删除的多数类个数控制在该类的5%以内。少数类精度提升的同时也达到去掉噪声点的目的。将除去噪声点后的支持向量集记为J′,其元素作为加权KNN的邻域样本,不仅能提升少数类的检测精度,还能提升KNN的运算效率。 计算测试集中各样本到分类平面的距离 (6) 其中n为测试集样本个数。为了降低分类超平面附近样本点的错分率,当其距离大于阈值ε时,用SVM算法对样本点进行分类;当其距离小于阈值ε时,用加权KNN进行分类。当用加权KNN进行分类时,计算测试集里各样本点xi到J′中各样本点的距离 d(x,xi)=‖Φ(x)-Φ(xi)‖2= (7) 其中,高斯核函数 K(x,xi)=e-σ‖x-xi‖2, σ为核宽度,控制函数的径向作用范围,可与SVM算法保持一致。 将距离排序,取出最近的K个样本点对类别进行统计。KNN判决方式为少数服从多数,由于邻域样本的不均衡,现将KNN判决方式进行改进加权,即少数类的个数达到 就可判别为少数类,反之判为多数类。其中,β由支持向量中两类样本的比例决定,K为近邻参数。 W-KSVM算法具体步骤如下。 步骤1将数据集划分为训练集Dtrain和测试集Dtest。 步骤2计算Dtrain中样本距分类平面的距离,得出支持向量机集J。 步骤3根据式(7)计算出的距离,删除错分为多数类支持向量的点(γi≤0),将剩余支持向量记入集合J′,作为加权KNN的邻域样本。 步骤4当Dtest=∅时,此算法结束;否则,记xi∈Dtest。 步骤5根据式(6)计算xi到超平面的距离di。人为给定ε,如果|di|≥ε,则根据式(4)得到xi的类别f(xi);否则,在特征空间根据式(7)计算距离d(x,xi),使用加权KNN对xi进行分类。 步骤6从Dtest中删除xi,返回步骤4。 针对电信客户流失的问题,错误判断一个流失客户的代价远远大于不流失客户的代价,因此更加关注的是客户流失的检测精度(少数类的检测精度)。假定少数类样本为正例样本,多数类样本为负例样本,以TP表示将正例样本判断正确的数目,TN表示将负例样本判断正确的数目,FP表示将负例样本判断错误的数目,FN表示将正例样本判断错误的数目,混淆矩阵如表1所示。 表1 二分类问题的混淆矩阵 少数类样本的检测精度 多数类样本的检测精度 整体性能评估指标 GM综合了两个指标,只有当多数类样本和少数类样本的分类精度都比较高的情况下,GM的值才会达到最大。所以,GM指标可以动态调整多数类和少数类之间的精确率,在可以接受的范围内通过降低多数类的精确度来提升少数类的精确度,有利于解决类似于客户流失、客户欠费和信用卡欺诈等实际问题。 实验数据分别为5个UCI不平衡数据集[17]Churn、Wine、Haberman、Pima-Indians、Waveform和某省的电信数据集[18]。其中数据集Churn定义客户不享有电信企业提供的全部服务即为流失客户。电信客户消费数据的基本属性包括是否VIP、用户属性、付费方式、是否主动停机等,其中数值属性可以直接使用,对非数值属性进行one-hot编码。某省电信原始数据集处理后的部分样本如表2 所示。 表2 某省电信用户部分样本 原始数据集属性之间存在较大差异,这会降低算法的学习速度和精确度,故需对数据进行归一化处理,即取 所用实验数据集具体特征如表3所示。 表3 数据集描述 为了验证所提算法在不均衡数据集上的可行性、有效性,分别与Normol SVM、Under SVM、Over SVM、EDKSVM、KNN算法在所提数据集上进行比较试验。为了保证算法的公平性,在每次实验中对所有算法选用相同的训练集和测试集,每次实验的训练集和测试集分别占总体样本的80%和20%。仿真环境和工具分别为Windows 8.1 、MATLAB R2013a和LIBSVM。 仿真结果如表4所示。对比可知,Over SVM在Churn数据集上少数类的精度为0.010 0,原因是过采样造成少数类的分类间隔变小,导致算法泛化能力变差,精确度下降。但所提算法W-KSVM在实验数据集上的少数类和整体精确度均有不同程度的提升,克服了其他算法在不平衡数据集上的不足,完全融合了SVM和KNN算法的优势。 表4 仿真结果对比 针对SVM、KNN对电信客户流失预测精度低的问题,给出了W-KSVM算法。在5个UCI不平衡数据集和某省电信数据集上的仿真结果显示,所给算法在对少数类的检测精度和整体分类性能明显优于其他算法。不均衡数据中少数类数目太少,分类器很难区分出少数类样本和噪声样本,今后研究的重心将是如何更精确更有效地去除噪声样本,进一步提升算法的精确度。
ξi=0,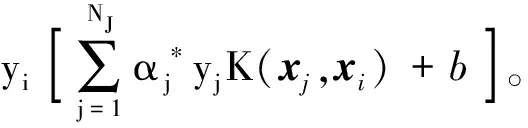
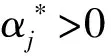
K(x,x)-2K(x,xi)+K(xi,xi)。3 实验分析
3.1 不均衡数据分类效果评判指标

3.2 实验数据描述及准备


3.3 不同算法的性能比较
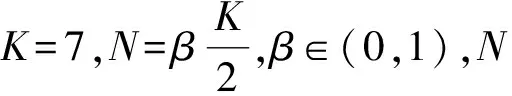

4 结语
猜你喜欢
农业工程学报(2022年7期)2022-07-09
计算机应用与软件(2022年2期)2022-02-19
四川大学学报(自然科学版)(2021年6期)2021-12-27
数学年刊A辑(中文版)(2021年3期)2021-11-05
数学年刊A辑(中文版)(2021年2期)2021-07-17
唐山师范学院学报(2018年6期)2018-12-25
自动化学报(2018年7期)2018-08-20
上海理工大学学报(2018年2期)2018-05-22
自动化学报(2017年4期)2017-06-15
文苑(2015年9期)2015-09-10
