
基于HBase的车联网海量数据查询
2018-07-11 03:30:10冯心欣胡淑英邹其昊徐艺文
福州大学学报(自然科学版) 2018年4期
冯心欣, 胡淑英, 邹其昊, 徐艺文
(福州大学物理与信息工程学院, 福建 福州 350116)
0 引言
车联网(internet of vehicles, IoV)是物联网(internet of things, IoT)在交通运输领域的典型应用, 它是一种基于人、 车、 环境协同的开放融合网络系统, 通过先进的信息通信与处理技术对网内各环节产生的大规模复杂静态、 动态信息进行感知、 认知和计算, 解决泛在异构移动融合网络环境中智能管理和信息服务的可计算性、 可扩展性和可持续性问题, 最终实现人、 车、 路、 环境的深度融合[1-3].
在人、 车、 路、 环境的交互过程中产生了海量数据, 一些实际项目的统计发现, 这一数据的规模将会突破10 TB级[4], 因此, 如何在庞大的数据中快速查询到用户需要的信息, 以进行车联网交通信息的综合分析, 成为车联网研究的热点.然而, 这些数据的海量特性、 异构性和众多并发访问, 给传统基于单机数据库的系统带来了很大的挑战.虽然有研究者提出了一些关系型数据库集群的解决方案, 例如在MySQL集群[5]和Oracle集群[6]中采用分表分库的方法来进行扩容, 但此扩容操作比较复杂, 需要联合多个分表数据, 查询繁琐, 并增添了分表维护问题.近年来, 基于云计算的分布式存储系统和新兴的非关系型(NoSQL)数据库技术为解决上述问题带来契机.目前, 具备高容错、 高可靠、 经济等优势的开源分布式大数据处理平台的Hadoop和有高扩展性、 快速存储等优势的NoSQL数据库代表HBase, 广受各界青睐.已有实际案例利用Hadoop和HBase构建存储仓库以存储来自地质气象研究[7-8]、 环境检测[9]、 太阳能光伏效应研究[10]、 医疗卫生大数据分析[11]和智慧交通[12-13]等各领域产生的大数据.
基于以上背景, 为解决海量交通数据中快速查询用户所需信息的问题, 本研究提出一种基于HBase的车联网海量数据存储查询方案.考虑车联网数据的时空相关性, 在HBase表设计中通过合理的列族设置和行键设计, 使海量数据分布有序, 提高查询算法的效率, 满足车联网信息实时查询的需求.最后通过实际数据的实验测试, 验证方案的可行性与合理性.
1 数据预处理
研究采用的实测车联网数据是福州市出租车轨迹数据, 原始数据包对每辆车采集包含设备标识(mdtid)、 车辆地理位置经度(longitude)、 纬度(latitude)、 车辆定位时间(msgdatetime)等11项数据.对原始数据进行初步分析发现, 数据包内数据庞杂, 质量参差不齐.为了提高数据的合理利用率以及保证后期数据查询分析的正确性, 在把数据导入HBase之前, 先进行数据预处理工作, 主要包含以下4个方面内容.
1) 剔除重复数据.由于设备重复发送数据, 导致在原始数据中出现连续多条相同记录, 为保证数据的唯一性, 剔除整行重复数据.
2) 剔除异常状态数据.原始数据中的异常数据主要指经纬度数值位数不满足要求、 车速不合理以及方向信息数值错误的数据, 这类数据干扰后期的数据分析.在研究的先期工作中, 已讨论了基于Epanechnikov核的修正边界核建立, 及相应的数据集概率密度函数建立[14].本研究采用其中的核密度估计方法, 对经纬度、 车速和方向信息数据中出现概率较小的数据(即信任度不足的数据)予以剔除.
3) 剔除缺失数据.缺失数据是指在某些字段中存在空缺值的数据, 这样的数据在后期数据分析时会因缺项而不起作用.缺失数据的数量较少, 预处理中也予以整行数据删除.
4) 地理位置的路段匹配.虽然原始数据中已收集有车辆经纬度的定位信息, 但由于数据来源和地图更新等问题, 将这一信息投射在地图上时, 发现并不是所有数据点都能落在城市道路上, 这对后期道路车流量分析、 车辆路径轨迹分析都存在影响.因此预处理工作对原始数据增加一步地图匹配工作, 将车辆的经纬度定位信息与地图上的道路位置进行匹配, 修正原始经纬度数据, 使得校正后的车辆经纬度位置可以较为精确地落在地图道路上, 并得到一列新的数据“road”, 该字段表示该定位信息具体落在哪一段道路位置上, 信息格式为“0000-00”, 前4位为道路路段编号, 后两位为该路段的路径编号.然而实际工作发现, 并非所有的定位信息都能得到准确的道路匹配, 这是由于有些现实中新建设的道路没有及时在地图上更新.但这些数据不属于上述提及的3种需要剔除的数据类型, 因此对这些少量的暂时无法得到精确道路匹配的数据采取在“road”字段保留“xxxx-xx”的形式.这样, 既能保证最后的数据行不含缺项, 也能在地图更新后修改对应的道路信息.
2 HBase表设计与查询模式设计
HBase的物理模型是以列族为单位存储数据, 磁盘上同一个列族下所有的单元格都存储在一个存储文件(StoreFile)中.因此, 相关的数据项应放置在同一个列族, 保证数据物理存储的靠近以提高查询效率[15-16].另一方面, 行键作为 HBase 表索引的主键, 决定了表数据处理的性能.因此, 为了使海量车联网数据在云服务器集群能够合理存储并便于后期用户访问, 需要针对数据特点并结合实际应用对数据存储表做表结构设计, 设计主要包含列族设置与行键设计.
2.1 列族设置
将经过预处理后的数据视作合理、 可用的车联网数据, 对现有的12项信息进行分析发现: 车辆定位的经纬度信息、 道路位置信息、 车辆定位时间、 车速、 方向等信息都是车联网综合分析服务中常用到的查询项目, 对分析交通运行情况、 司机驾驶习惯等实际应用场景都十分必要.考虑查询的高效率, 在设计表时将上述提及的几项常用信息放置在同一列族中; 而数据项中的“islocate-是否定位”、 “sourceflag-信息源”、 “indate-数据入库日期”这3项信息较为不常用, 归为同一列族.最终的列族设计如表1所示.

表1 车联网数据的列族设置
2.2 行键设计
由于数据在HBase中以键值(key value)形式存储, 行键(row key)是主键, 行键的设计对数据的存储查询性能起关键作用, 因此在设计时需充分考虑车联网信息查询的应用场景, 做综合分析.在车联网信息查询应用中, 车牌号、 车辆定位信息、 定位时间是最关键的信息项.如, 对某一路段车流量的查询, 希望根据车辆定位时间(msgdatetime)查询到某路段上的所有车辆设备标识(mdtid)并统计其数量; 对某车运动轨迹的查询, 希望根据车辆设备标识(mdtid)和定位时间(msgdatetime)查询到车辆定位的经纬度(longitude & latitude).
因此将实测数据中采集的对应信息项 “mdtid-设备标识”、 “msgdatetime-车辆定位时间”和“road-道路信息”放入行键的位置并进行组合, 分析对比各复合行键设计方案后, 采用如表2所示的最终方案.

表2 行键最终方案
此行键设计方案的优点是:
1) 用此3个字段信息组合的复合行键保证了行键的唯一性和长度一致.
2) 规避数据以时间顺序存放时, 因时间数据呈现单调递增趋势而引起集群内单一region过载, 而其他机器闲置的风险.
3) 根据HBase存储特性, 以车辆设备标识为顺序排列的存储方案使同一辆车的数据能在物理存储上同样靠近, 在以车辆为检索条件的查询应用上体现出高效性.
2.3 查询模式设计
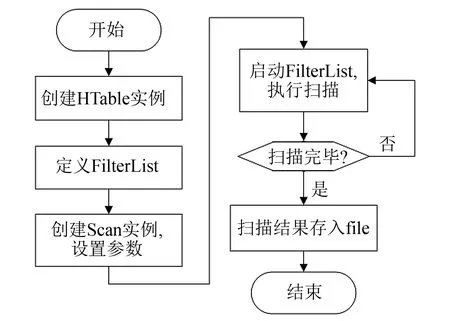
图1 车辆轨迹查询程序流程 Fig.1 Flowchart of vehicle trajectory query program
在上述行键设计的基础上设计两类车联网信息查询的模式.
模式一: 车辆驾驶情况查询.该模式包含车辆在某个时间点的定位情况查询和车辆在某个时间段内行驶轨迹查询.根据用户输入车辆设备标识和查询时间, 可定位车辆坐标位置并显示车速、 方向等相关信息以分析特定车辆的行驶状况.
模式二: 路段车流量查询.该模式根据用户输入的路段信息和时间范围, 显示该时间段内经过该路段的所有车辆的设备标示并统计车辆总数.
下面分析各查询模式的程序实现流程.
1) 模式一: 车辆轨迹查询程序的流程, 如图1所示, 具体步骤说明如下.
① 设置自定义过滤器集合(Filterlist), 集合包含一个前缀过滤器用来确定车辆, 两个行过滤器(RowFilter)确定检索的起始时间和结束时间, 3个过滤器全通可以锁定Scan()的起始行和结束行, 过滤器参数为用户输入的车辆设备标识(mdtid), 查询起始时间(start_time)、 查询结束时间(end_time).
② 创建Scan实例, 用s.addColumn()方法限制返回数据列只有车辆定位经度(longitude)、 纬度(latitude)、 对应的路段-路径编号(road)、 数据发送时间(msgdatetime).
③ 将返回至扫描器(scanner)的信息逐行输出至名为“设备标识-时间时间-结束时间.txt”的文本中, 通过文本将车辆轨迹数据导入地图模块, 最终可在ArcGIS软件中已经事先导入的城市地图上显示该车辆该时段的轨迹图.
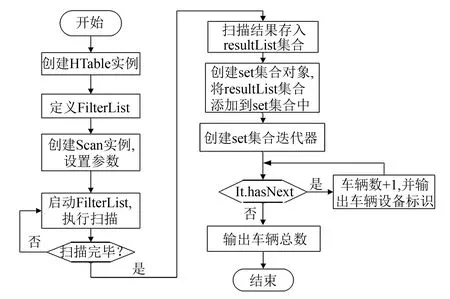
图2 路段车流量查询程序流程Fig.2 Flowchart of roadtraffic flow querying program
2)模式二: 路段车流量查询的程序流程如图2所示, 具体步骤说明如下.
① 设置自定义过滤器集合(Filterlist), 集合包含一个行过滤器用来确定路段, 两个列值过滤器(SingleColumnValueFilter)确定检索的起始时间和结束时间, 一个列限定符过滤器, 限定返回列项仅为“设备标识-mdtid”, 4个过滤器全通使Scan()操作结果满足查询要求.
② 创建Set集合, 通过addAll()循环将Scan()结果添加进集合, 此方法可以去掉重复值, 保证车辆数量统计的正确性.
③ 最后通过iterator()对象获取Iterator()实例, 再通过遍历迭代器来获取集合对象, 即该时段经过该路段的车辆设备标识, 并统计车辆总数.
3 实验与结果分析
为了验证上述HBase表设计与查询模式的性能, 通过实验对其进行评测.实验平台采用3台机器搭建HBase集群, 操作系统均为Ubuntu 14.04 LTS, 每台机器的主机名、 IP地址、 角色分配如表3所示.

表3 集群配置
3.1 查询模式的性能验证
在所搭建的平台上对上述查询模式进行测试, 实验数据使用福州市出租车2015年12月2日的GPS数据, 数据量10 506 479 条.
模式一: 车辆驾驶情况查询.
1) 查询车辆11823在2015年12月2日12:20:00的定位记录, 结果如图3(a)所示.查询结果显示该车在该时间点, 所在的经纬度位置为119.327 298 583°E, 26.068 719 103 4°N, 所在路段编号为0554-08, 车辆行驶方向为6(正西), 车速16 km·h-1.此查询功能可以有效地对特定车辆的行驶情况进行分析, 如检测车辆是否超速、 追踪车辆的位置等.
2) 查询车辆13702在2015年12月2日12:00—12:30的车辆轨迹信息, 得到结果如图3(b)所示, 图中分别用蓝点和红点标出该车辆在此时段行驶轨迹的起点和终点, 车辆的行驶方向则用箭头标识.
模式二: 路段车流量查询.
查询2015年12月2日17:00—17:10经过道路0616-01的车流量, 部分结果如图4所示.图4(a)显示了查询的部分结果, 分别为该时间段经过该路段的各车辆设备标识和车辆总数; 图4(b)显示了该路段的地图; 图4(c)则是从查询结果中任意选取的两辆车在该时间段的轨迹图, 从轨迹图中可以看出这两辆车在2015年12月2日17:00—17:10时段内确实经过路段0616-01, 从而验证了查询结果的正确性.

图3 车辆驾驶情况查询结果Fig.3 Querying the driving conditions of a certain vehicle

图4 路段车流量查询结果Fig.4 Result of traffic flow querying for a road
3.2 行键设计方案的性能验证
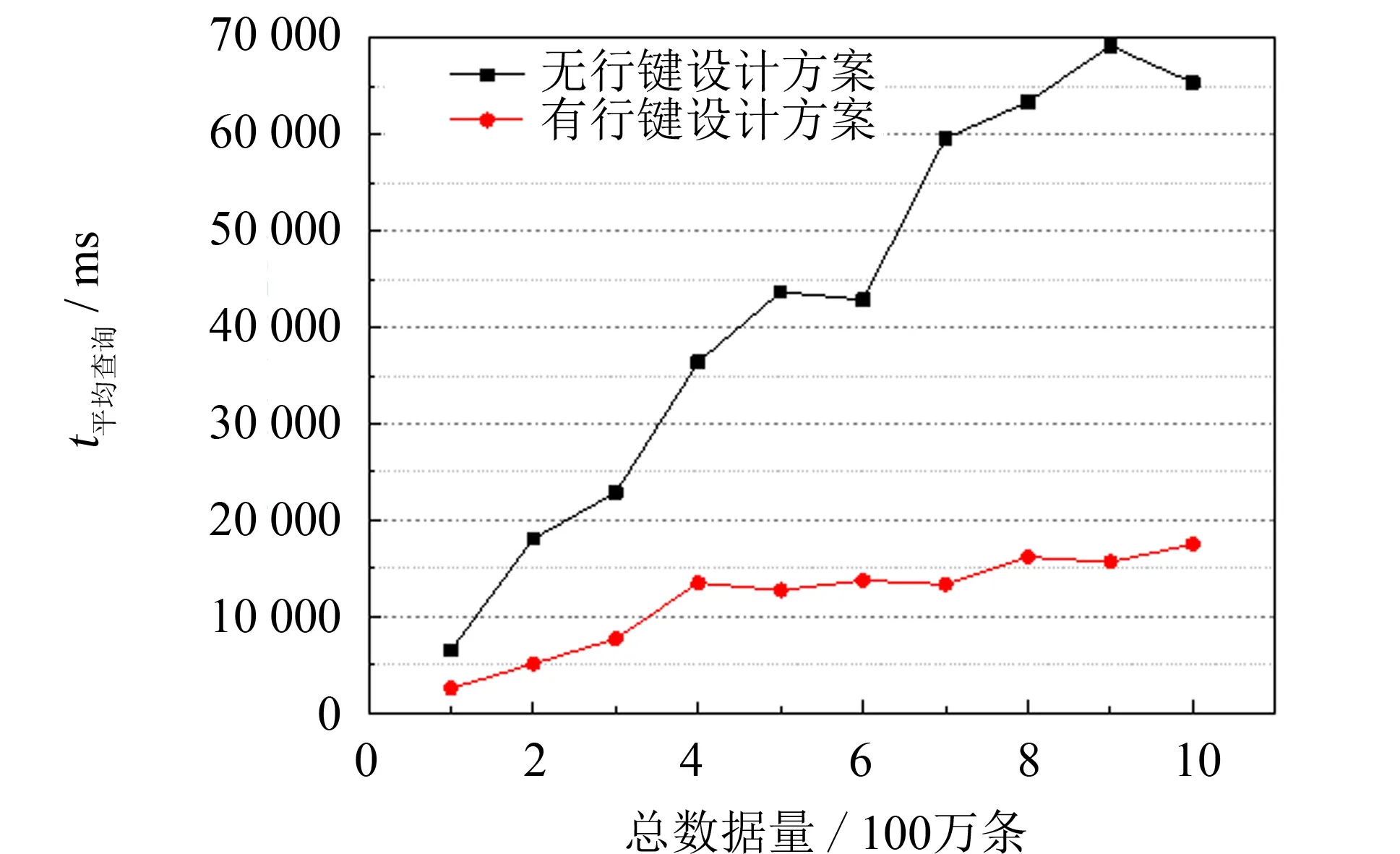
图5 查询耗时对比 Fig.5 Time consumption comparison
为了验证HBase行键设计方案确实能有效提高数据查询性能, 设计实验通过查询相同的数据以对比有无行键设计对实际查询耗时的影响.具体方法为:
1) 设置每组实验的数据总量从100万条逐次递增至1 000万条, 每次增加100万条数据, 总共做10组对比实验;
2) 每组实验随机选取20辆车, 查询指定1 h的轨迹数据;
3) 每组实验重复3次, 取最终的查询时间平均值.
按以上策略分别测试行键设计方案和无行键设计, 仅以列值做检索这两种方法的数据查询用时, 通过对比两者的差异来比较两种方法的查询性能优劣.实验结果如图5所示, 图中横轴为数据总量, 纵轴为平均查询时间.
由图5可知, 随着数据总量的增大, 两种方案的平均查询时间都逐渐增长, 但是当数据总量达到400万条时, 以行键为查询索引的方案平均查询时间的增速开始放缓, 而没有行键设计的查询方案直至数据总量达到900万条时, 平均查询时间的增速才开始下降.虽然曲线的转折点不同, 但两种查询方案都呈现出在数据总量增至一定程度时, 查询时间的增速将下降的趋势, 这显示了HBase对于海量数据查询的适用性.同时, 图5显示出在不同的数据总量中查询时, 有行键设计的方案平均查询时间都明显小于没有行键设计的查询方案.实验说明, HBase表设计中, 是否针对查询应用做合理的行键设计, 对数据查询耗时影响较大.本研究采用的方案在数据特性分析的基础上针对数据查询应用功能做了对应的行键设计, 使查询指定车辆某段时间轨迹数据的耗时降低, 从而显著地提升了查询性能, 对比实验验证了行键设计方案的高效性.
4 结语
车联网对实现智能交通系统(intelligent transportation system, ITS)具有重要意义.研究针对车联网采集到的海量数据, 提出一种基于HBase的存储查询方案.HBase是建立在Hadoop上的列式开源数据库, 相比于传统关系型数据库在存储海量数据时有突出优势.研究提出一种合理的表结构设计, 实现在HBase中存储庞大的车联网数据, 并在数据导入HBase之前, 对数据进行了预处理工作, 特别是通过地图匹配校正了原始数据中错误的车辆经纬度定位信息, 并增加了精确的道路信息以丰富交通情况的查询分析功能.通过实验测试了几种查询模式的合理性, 并通过对比实验显示了行键设计方案在查询耗时上的优越性.
猜你喜欢
工会博览(2022年5期)2022-06-30 05:30:18
党的生活(黑龙江)(2022年4期)2022-04-25 22:14:17
中国交通信息化(2021年2期)2021-07-22 07:34:40
IEEE/CAA Journal of Automatica Sinica(2021年2期)2021-04-22 03:54:26
导航定位与授时(2020年5期)2020-09-23 03:05:00
铁道通信信号(2020年9期)2020-02-06 09:16:06
建材发展导向(2019年11期)2019-08-24 06:34:56
通信世界(2018年27期)2018-10-16 09:02:56
知识经济·中国直销(2018年3期)2018-04-12 06:43:37
学习月刊(2015年1期)2015-07-11 01:51:12
