
基于师生访问行为挖掘的校园网负载测试方法
2018-07-06 06:30:24柯秀文
山东商业职业技术学院学报 2018年3期
柯秀文
(商丘职业技术学院,河南 商丘 476001)
0 引言
随着互联网和信息技术的迅速发展,校园网逐渐成为校园信息交流的重要平台,基于B/S模式架构的各种“信息管理系统”在校园网中的应用日趋广泛,校园网在学校日常事务中发挥着越来越重要的积极作用。然而随着师生访问量及数据量的急剧增加,校园网服务器负载过重的现象也逐渐显现,导致校园网性能不佳[1],降低了服务质量。
了解校园网服务器负载能力,需要进行有效的负载测试。通过负载测试进而了解系统性能,实现系统调优,提高校园网服务效率和质量,更好的发挥“互联网+”[2]功能。因此,构造与真实负载情况更加接近的负载测试尤为重要。一般的网页负载测试通过录制访问序列并进行回放的方式进行,但全部访问序列的数量庞大,难以进行操作,以及容易造成测试负载与真实负载之间的差异较大[3]。因此,在校园网的负载测试中,本文提出了一种基于师生访问行为挖掘的校园网负载测试方法,从校园网访问日志中挖掘师生访问行为特征,获得师生频繁访问模式[4],用于负载测试脚本的开发,构造负载测试环境,以达到测试负载与真实负载情况更加接近的目的,使得测试结果更有参考价值。
1频繁访问模式挖掘
师生访问行为特征[5]是师生访问校园网进行系统交互时在操作上差异性的表现。校园网负载测试主要是通过模拟大量师生访问,利用负载测试工具评估校园网系统性能,根据评估结果进行系统调优,提高用户体验。为了提高负载测试的精度和可靠性,需要真实地模拟师生访问校园网时的行为,就要考虑师生角色、操作方式等行为特征。由于校园网用户访问序列具有规律性和重复性,可以从师生访问行为中挖掘其频繁访问模式。
1.1访问序列树
为了说明师生对校园网访问序列如何被表示成树,下面举例进行说明,每次访问以“教务信息管理平台”登录开始,以“/”标记,师生访问平台示例如图1所示。

访问会话1访问会话2///信息维护.html/信息维护.html/信息维护/个人简历.html /查看.html/信息维护/选修课.html/信息维护/个人简历.html /上传照片.html/信息维护/选修课.html /课程搜索.html/信息维护/个人简历.html /修改密码.html/信息维护/选修课.html /申请开课.html/学生成绩.html/学生成绩.html/学生成绩.html /成绩查询.html/学生成绩.html /成绩添加.html/学生成绩.html /成绩删除.html
图1 师生访问平台示例
为了更好的说明访问序列树,方便对树模型的理解,对图1中出现的访问页面分别用数字进行标记,访问页面的数字标记如表1所示。

表1 访问页面的数字标记
根据图1师生访问“教务信息管理平台”页面的顺序,结合在表1中给出的页面数字标记,可以得到如表2 所示的师生访问序列。

表2 师生访问序列
参照约束关系,获得约束集1:C10={1,2},C11={3} ,C12={10,11,12};获得约束集2:C20={1,2} ,C21={4} ,C22={5,6,7},C23={8,9}, 进而得到如图2所示的树型结构。
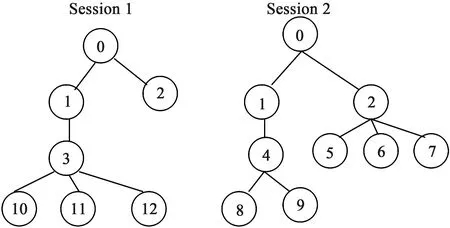
图2 访问序列树结构
师生对校园网的访问序列通过树模型的形式表示更能体现校园网站的层级结构,能够清晰的反映出每个节点与其它相邻节点之间的上下层关系,表达的含义比简单的访问序列更加清晰,更易于理解。如图2所示,在会话1序列树结构中,父节点3“个人简历”下有3个子节点“查看”、“ 上传图片”、“ 修改密码”; 在会话2序列树结构中,有“成绩查询”、“成绩添加”、“成绩删除”3个操作属于父节点2“学生成绩”下。访问会话1中学生对“个人简历“相关操作较多,访问会话2中教师对“信息维护”、“选修课”、“学生成绩”操作较多。从以上师生访问以看出,师生对校园网关注不同其操作也是不同的,但其访问序列却有规律性和重复性,有利于从中挖掘出其频繁访问模式。
在师生访问行为中挖掘其频繁访问模式时,将访问行为信息转化树结构模型,要考虑师生访问不同页面之间的约束关系。从简单的访问序列中并不能看出操作之间的层级关系。如访问会话2的访问序列为<0,1,4,8,9,2,5,6,7>,访问页面5虽然在页面6、7的前面,但却不是页面6、7的交节点,在树型结构中可以看出访问页面5、6、7是并列的兄弟关系。在实际转化时要借助校园网网络拓扑结构图,提取操作之间的并列约束关系,建立准确的约束集,这样才能在师生访问序列中准确地生成树结构模型。
1.2 WUFPSM算法
师生访问树模型的建立:假如给定表3所示的“教务信息管理平台”5条师生访问序列,每条师生访问会话序列对应唯一ID号,合并假定的5条师生访问会话序列,从第一个节点0开始遍历,如果该节点已存在于WUPT(Web Usage Pattern Tree,频繁使用树)中,则将标识tid(频繁节点,即该节点频率不小于用户给定的最小支持度β)记录到节点中,如果该节点没有在WUPT中出现过,则参照约束关系,新创建此节点,并记录当前序列标识,最终可以构造出如图3(a)所示的师生访问树模型。

表3 师生访问序列
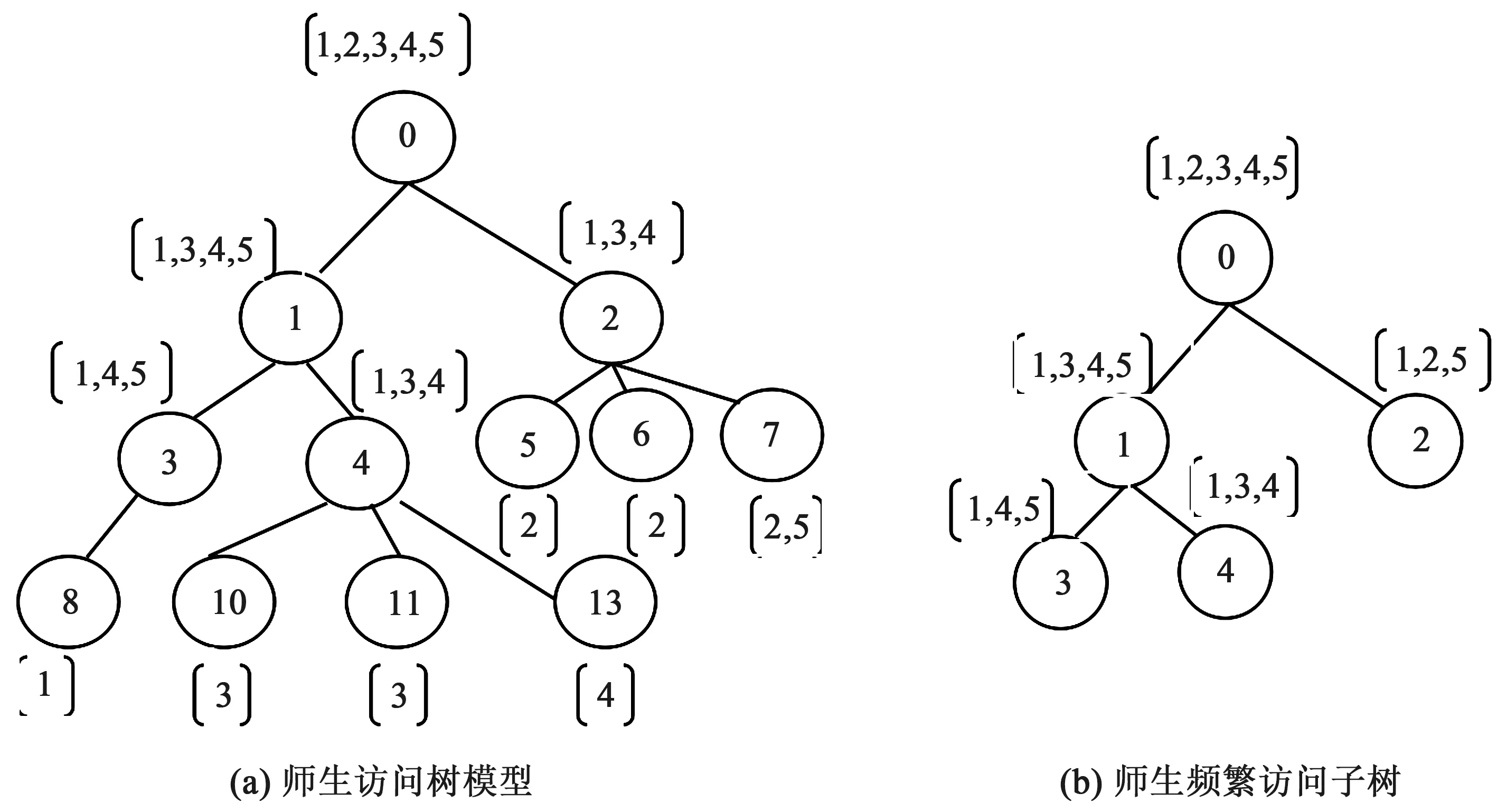
图3 师生访问树挖掘前后对比
频繁访问模式挖掘是从用户的会话序列中挖掘出满足一定支持度阈值的频繁序列[6]。这里我们假定最小支持度为0.6,图3(a)中有4个访问ID对节点1进行了访问,其频率为4/5=0.8>0.6 ,有3个访问ID对节点2进行了访问,其频率为3/5=0.6=0.6,以上2个节点满足大于等于最小支持度0.6,所以节点1和2都是频繁节点。非频繁节点的相关路径也是非频繁的,去除后可以得到如图3(b)所示的师生频繁访问子树。
频繁模式子树挖掘算法,即WUFPSM(Web Usage Frequent Pattern Subtree Ming)算法,如下所示:
输入:会话集S={s1,s2,s3,…,sn},访问序列p(si)=〈p1,p2,p3,…,pn〉,约束关系集C,最小支持度β。
输入:频繁带根子树。
算法步骤:
initializes a tree T= (V0,V,E),V0is the root node, V is the set of nodes, E is the set of edges;
for each session do begin
{
Start from the first session s1;
from P1to Pn;
if(Piis in V)
{
break;
}
else
基于商务部的结论,法院推测了为了解决非市场经济国家进行商品补贴的问题商务部在未来可能采取的行动。其中一点是通过采取“非市场经济方法”来征收反倾销税,在这一基础上征收反补贴税,同时,对反倾销税采取“细微的调整”来抵消对同一企业进行双重征税的问题。法院注意到了商务部将要实施的措施可能会引起更多的问题与纠纷,正如其所说“这种措施是否会造成与法规的直接冲突”或者“这种措施从根本上是否为不公平的,因而造成对法规不公正的解释或者滥用”[2](P1290)。然而,法院并没有对这一话题进行更加深入的探讨或者分析,原因是这一问题与原告所受到的损失无关。
go through the constraint set C;
if (Pi, Pk∈the same constraint Ci)
{
Pkis already in T,
Pi→parent node=Pk→parent node
insert Pito the T;
}
}
tid= session id;
begin next session;
perform the above steps;
until all session are completed;
save T into the database D;
FST=generate freqsubtree(root,β);
return FST;
2实验
本节利用提出的负载测试方法对“S学院图书馆图书信息管理服务平台”进行负载测试,该平台基于B/S体系模式架构,通过通用浏览器即可实现师生基础信息以及图书的查询、预借等功能。“S学院图书馆图书信息管理服务平台”是S学院校园网日常负载具有代表性的校园网页,选取其相关数据做为实验数据,测试结果具有代表性。由于校园网不同于一般的网站,不同月份师生访问频率差异较大,如寒暑假访问频率较低。实验人员选取比较有代表性的时间段进行实验,对2017年11月1日-2017年11月30日系统使用高峰时段9:00~11:00的网页访问日志进行分析和预处理,当要求支持度β≥0.6的情况下,得到师生在“S学院图书馆图书信息管理服务平台”的频繁访问页面为人员登录、图书查询、图书预借、新书信息、综合服务等,结果如表4所示,这里需要指出,不同师生对校园网系统熟悉程度不同,系统思考操作时间也会不同。
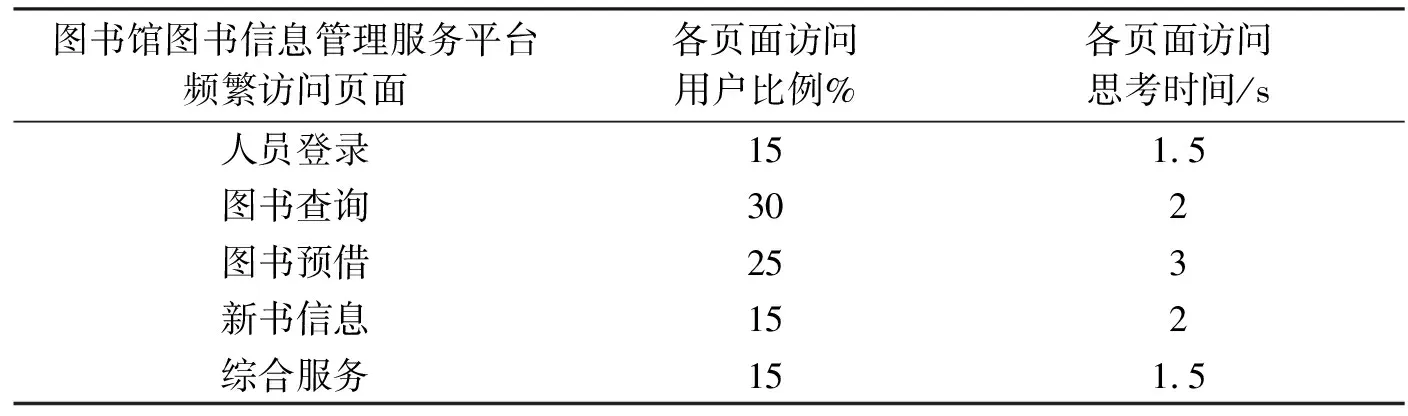
表4 师生访问页面行为的特征表
根据表4所示特征表,利用负载测试工具LoadRunner[7]录制虚拟师生用户脚本,在构造的测试场景中,模拟100用户并发,对“S学院图书馆图书信息管理服务平台”进行负载测试,结果如表5所示。
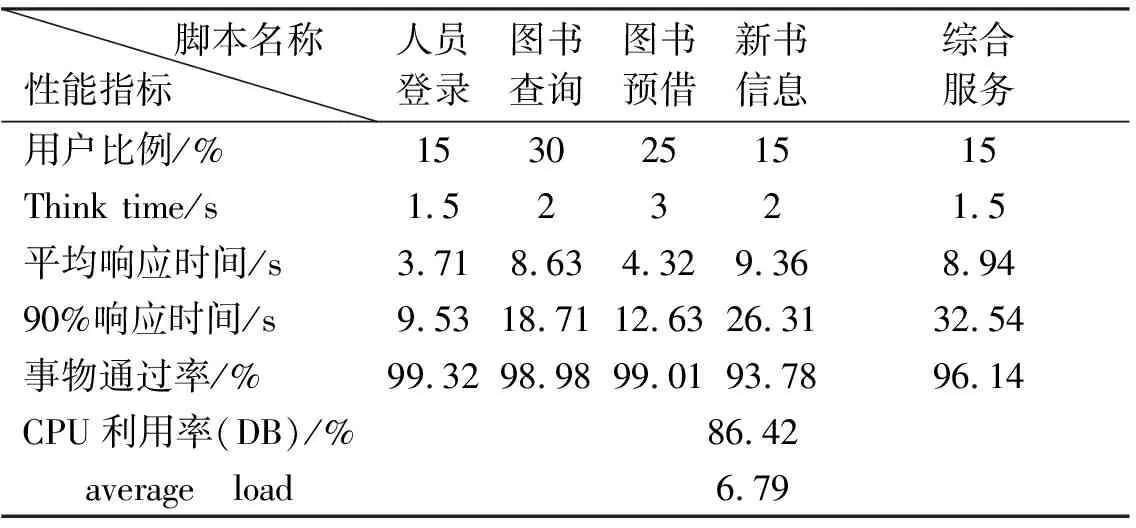
表5 负载测试结果
从图4负载数与响应时间测试数据结果可以看出,当并发负载数小于200时,不考虑师生访问行为的事务平均响应时间与考虑师生访问行为的事务平均响应时间相当, 随着负载数的增加,负载超过300后,不考虑师生访问行为的事务平均响应时间增长加快,并发负载数大于400时,在事务平均响应时间上,考虑师生访问行为优势明显。
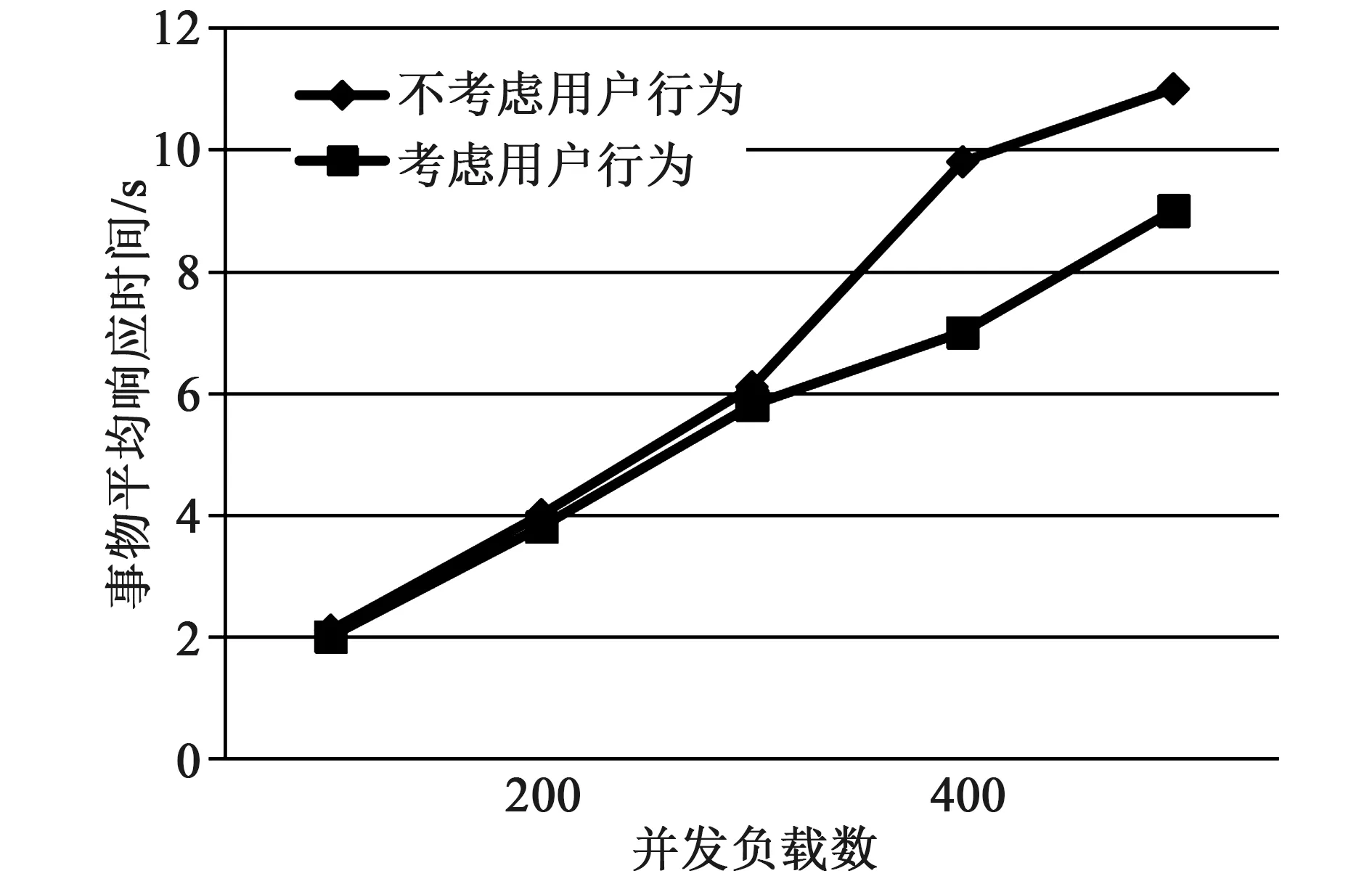
图4 负载数与响应时间关系
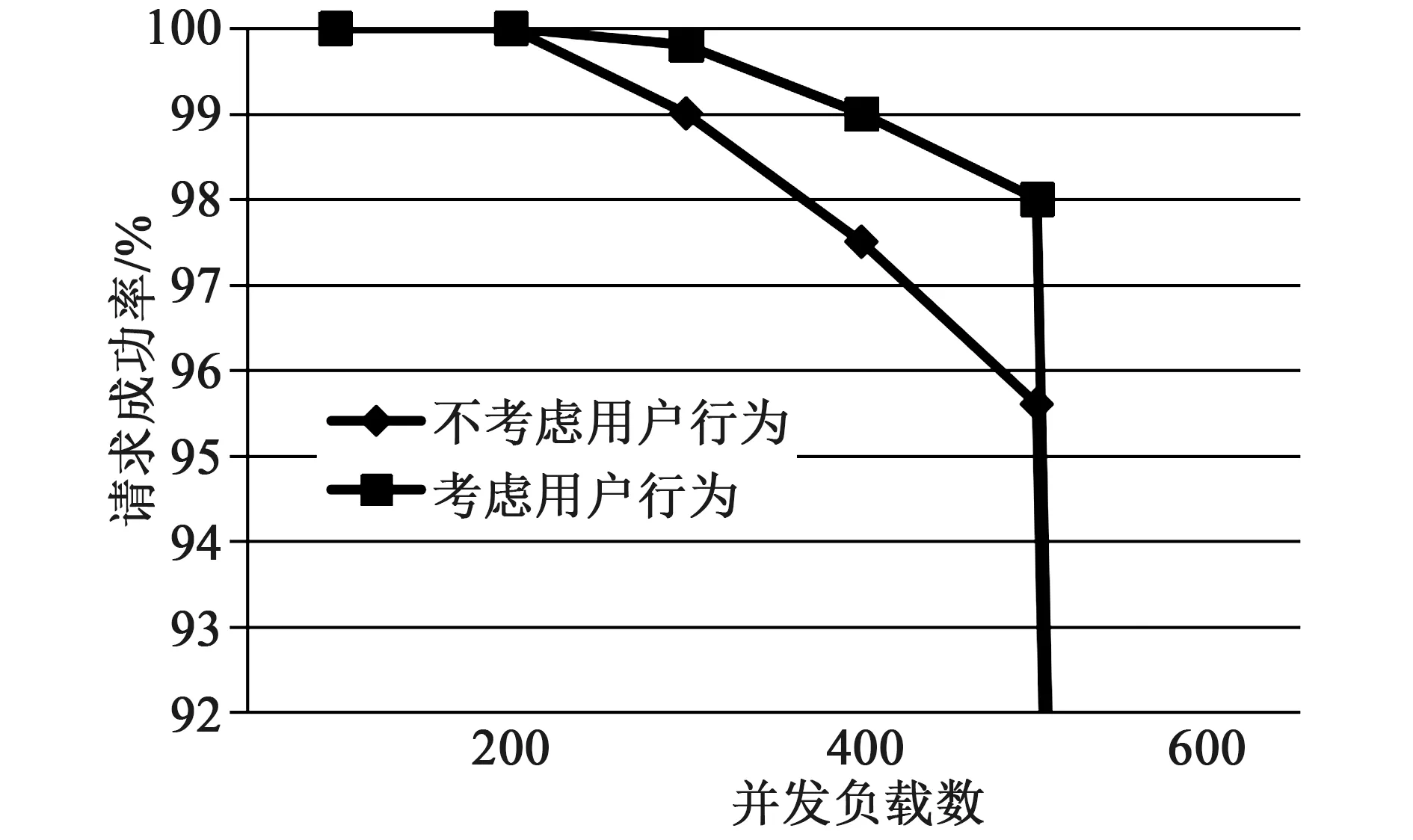
图5 负载数与请求成功率关系
从图5负载数与请求成功率测试数据结果可以看出,当并发负载数小于200时,不考虑师生访问行为与考虑师生访问行为的请求成功率相当,随着负载数的增加,不考虑师生访问行为
请求成功率下降较快,负载超过300后,二者请求成功率差距较大。
采用师生访问页面频繁模式子树挖掘算法,挖掘出师生的频繁访问页面,以便于开发出的测试脚本能够反映师生对校园网的真实使用情况,师生频繁访问的页面才是整个校园网负载压力最大的部分,也是体现系统负载能力的地方。对于一些很少访问的校园网页面,对负载测试的意义不大。事物响应时间、请求成功率是反映校园网性能最为重要的两个指标,从负载数与事物响应时间、请求成功率的实验结果可以看出,对师生访问页面行为特征进行挖掘,利用得到的师生频繁访问模式进行脚本开发,考虑师生访问行为特征设计负载测试场景,测试负载与真实负载情况更加接近,可信度更高,测试结果有利于系统调优,在实际应用中更有参考价值。
3结束语
本文提出了一种基于师生访问行为挖掘的校园网负载测试方法,从校园网访问日志中挖掘师生访问行为特征,获得师生频繁访问模式,用于负载测试脚本的开发。利用负载测试工具LoadRunner录制虚拟师生用户脚本,在构造的测试场景中,对“S学院图书馆图书信息管理服务平台”进行负载测试,并取得较好的实验结果,测试负载与真实负载情况更加接近,测试结果更有利于校园网系统调优,为师生提供更加优质、高效的校园网信息服务。
参考文献:
[1]杨蒋蔚.Web性能测试技术研究及工具开发[D].上海:上海交通大学,2014.
[2]黄楚新,王丹."互联网+"意味着什么——对"互联网+"的深层认识[J].新闻与写作,2015(5).
[3]梁力图,陆璐.基于用户会话的Web应用性能测试方法的研究[J].计算机科学,2014(11).
[4]邢东山,沈钧毅,宋擒豹.基于Web使用挖掘和内容挖掘的用户浏览兴趣迁移挖掘算法[J].小型微型计算机系统,2004(7).
[5]乔志杰,田剑.基于用户访问特征的Web性能测试模型[J].智能计算机与应用,2015(4).
[6]肖扬.序列挖掘算法研究及其在用户行为分析中的应用[D].北京: 北京邮电大学,2014.
[7]仵圣梅.企业库存管理系统的设计与实现[D].辽宁:大连理工大学,2014.
猜你喜欢
保健医苑(2022年1期)2022-08-30 08:39:14
铁道建筑技术(2021年4期)2021-07-21 05:33:42
甘肃教育(2020年18期)2020-10-28 09:05:54
科技进步与对策(2020年15期)2020-08-18 08:08:30
电子制作(2019年10期)2019-06-17 11:45:26
电子制作(2017年8期)2017-06-05 09:36:15
中国交通信息化(2016年2期)2016-06-06 07:27:47
电子设计工程(2015年17期)2015-02-27 12:08:04
土木建筑工程信息技术(2013年3期)2013-10-17 03:15:00
电脑爱好者(2011年11期)2011-06-22 08:20:18
