
基于语义的聚焦爬虫算法研究
2018-06-27 07:53孙红光藏润强姬传德杨凤芹冯国忠
东北师大学报(自然科学版) 2018年2期
孙红光,藏润强,姬传德,杨凤芹,冯国忠
(1.东北师范大学信息科学与技术学院,吉林 长春 130117; 2.智能信息处理吉林省重点实验室,吉林 长春 130117; 3.吉林大学计算机科学与技术学院,吉林 长春 130012)
0 概述
传统搜索引擎是通过关键字匹配对网页进行比对[1],结果将使搜索引擎返回大量无关的页面而影响用户使用,忽略了网页的相关性和网页的访问优先次序.主题爬虫(聚焦爬虫)的出现正是由于互联网中所有的信息资源并不都是用户所感兴趣的,因此需要一种机制可以面向用户的需求而对获取的资源进行判断.主题爬虫可以使用未访问URLs的主题相关性判定机制确定其主题相关性,因此可以从互联网中获取更多用户感兴趣的信息资源.
从主题爬虫被提出到现在一直有很多学者对其进行了研究,P.D.De Bra等[2]提出“fish-search”将主题爬虫对于网络资源的采集过程比作鱼群觅食的过程;A.Patel等[3]通过对HTML文档的标签和属性等结构信息进行分析与应用,提出基于应用文档的主题爬虫;J.W.Lin等[4]提出在语义上比较标记语料库中输入字段的相似性,自动识别爬行过程中遇到的输入字段;H.Dong等[5]在提出的半监督主题爬虫SOF中包含网络信息格式化,是一种基于本体的半监督学习框架和由支持向量机聚合的混合网页分类方法;杜亚军等[6]通过改进文档词项与主题词项的相似度计算公式,来改善爬虫性能的SSVSM;林超等[7]提出主题爬虫算法主要用于深度网络资源信息的发现;Ran Yu等[8]提出了一种自适应的聚焦爬行方法,它考虑到种子列表的特征,从而改进了爬虫和相关排序方法.
但是,基于语义的主题爬虫仍然存在许多缺点,如主题确定的随意性,相似度计算模型存在不足,对于主题词项细化过于苛刻,或者某些词项会隐藏在一些不相关的词项之后,会造成抓取的相关页面数量不足以满足用户的需求,如何让计算机能够自动解决成为主题爬虫面临的一个重要问题之一.为弥补语义主题爬虫存在的不足,本文提出主题爬虫算法,首先使用LDA构建主题模型,并将依据本体获取的语义相似度加入到向量空间模型VSM中,从而对语义相似度计算模型进行改进,另外加入上位词替换模块,以保证不出现主题过于细化导致检索结果过少的情况,最后计算未访问URLs的全文本和锚文本与主题的相关程度,从而对未访问URLs的优先级进行排序.
1 相关技术与研究
1.1 基于LDA主题模型的主题构建
页面文档和主题文档的相关性除了词项间的重复关系外,还与文字的语义信息有关,如挖掘相关联的语义信息,爬虫的抓取结果的准确性将进一步增加.主题模型是发现所包含的隐藏主题并对其进行建模[9],它与传统信息检索的文档相似度计算方法不同,性能更优,并且可以自动发现互联网资源中大量的文字间语义主题.
首先,用生成模型分别对文档和主题进行描述.生成模型的主要思想是指文档中每个词语都以一定的概率指向一个主题,同时每个主题又都以一定的概率指向某一篇文档,从文档出发,找出文档所对应的主题和主题所对应的词项构成模型,LDA通过调整参数实现对模型参数的控制[10],计算公式为
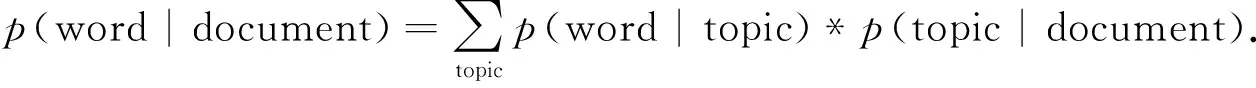
(1)

图1 文档中词语概率图示
公式(1)概率图示见图1.图1中:左边方框表示词语在文章中出现的概率c是已知的;主题中每个词语出现的概率用Φ矩阵表示,看做是文档中主题所占的比例;主题模型的构建就是通过训练大量已知的“词语-文档”矩阵,得出未知的“词语-主题”矩阵Φ和“主题文档”矩阵Θ.
本文在给定主题爬虫概念时,首先使用维基百科或百度百科对该概念进行解析,这里假设主题中对于某一个概念的描述是具体的、全面的.模型构建过程是无监督并跨语言、完全自动化的,不需要人工进行标注,自动计算多种概率.
1.2 改进的语义相似度向量空间模型
向量空间模型没有考虑任何语义信息,只要网页中词项不与主题词项有重复就认为网页是与主题无关的,不考虑同义词或近义词而直接判定为主题无关,这显然不合理,例如更精确地指导爬虫获取与主题相关的网页集合,此方法不够完善.对于语义相似度检索模型,即网页词项与主题词项集集合之间都是同义词或者重复词项,该模型虽考虑了语义信息却忽略了能够代表网页与主题信息的词项出现频率比较高的事实,按照语义相似度检索模型将判定此时网页与主题的相关性度为1,这显然也是不合理的.最后可能导致网页与主题间的相似度计算不准确,从而导致主题爬虫逐步发生主题漂移,继续检索返回的结果都是与主题无关的.
为解决上述问题,本文对语义相似度计算方法中使用模型进行改进,提出改进的语义相似度计算模型(SVSM).SVSM主要结合了向量空间模型(VSM)[11]和语义相似度检索模型(SSRM)[12]的优点,同时弥补了两者的缺陷.此模型首先构建网页与主题向量空间模型,并将主题的语义向量的语义值置1,通过计算网页文本词项与主题词项的平均语义相似度后加入到构建的向量空间模型中,形成具有语义与统计信息的语义向量空间模型,采用乘积的方法加入语义信息,对于向量空间模型中的每一个数值,都可以看做该词项与主题词项的平均语义相似度.最后,通过计算主题语义向量与页面主题向量的夹角余弦值确定页面与主题的相似度.
1.2.1 语义向量构建
同时构建页面内容和主题的向量空间模型并加入语义信息,从而得到文档与主题的语义向量.语义向量构建方法主要包括如下步骤(给定文档d和主题t):
STEP1:进行预处理,包括分词和去停用词等获取文档词项和主题词项;
STEP2:使用相同词项构建页面文档与主题文档的向量空间模型,使用TF-IDF计算词项权重构建文档与主题向量空间模型;
STEP3:获取文档词项与主题词项间的语义相似度;
STEP4:计算主题语义向量,这里认为一个主题与它自身的语义相似度为1,即形式上与向量空间模型相同;
STEP5:计算文档d的语义向量,计算出文档d中的每一个词项与主题中每个词项的语义相似度并求出平均值,最后与对应的词项权重相乘,构建文档d的语义向量.
现使用一个具体的例子对上述算法进行描述.经过STEP1后,STEP2构建文档与主题的向量空间模型的公式为:
DT={term1,term2,…,termn},d= (Wk1,Wk2,Wkn,0,0,…,0);
TT={term1,term2,…,termm},t= (Wt1,Wt2,Wtm,0,0,…,0).
(2)
文档d的词项集合用DT表示,主题t的词项集合用TT表示,文档d和主题t的向量分别用d和t表示,Wki(1≤i≤n)为在文档dk中词项i的TF-IDF值,Wtj(1≤j≤m)为主题t中词项j的权重,n,m为文档dk、主题t的词项总数,主题t中出现而文档d中未出现的词项和文档d中出现而主题t中未出现的词项集合用0表示.文档向量与主题向量长度相等,例如一个主题和一篇文档,公式为:
主题t:TT={平台,课程,文本}=(0.24,0.1,0.09,0,0,…,0);
文档d:DT={章节,部分,步骤}=(1.4,1.1,0.4,0,0,0,…,0).
(3)
获取文档词项与主题词项间的语义相似度.词项之间的语义相似度可以通过词项在HowNet本体的位置信息获得[13-14],上例的中文文档词项与主题词项的语义相似度如表1所示.

表1 文档d和主题t的语义相似度
STEP4中认为一个主题与它自身的语义相似度为1,对于其他文档而言,主题向量在被赋予语义信息(1,1,1,1,…,1)后没有发生形式上的改变,所以得到主题语义向量,公式为
STV=(0.24,0.1,0.09,…,0).
(4)
STEP5计算文档d1的语义向量.首先计算出在文档d中的词项“章节”、“部分”,“步骤”与主题中各个词项的平均语义相似度,其公式为
ST=(0.645,0.089,0.679).
(5)
STEP5计算文档d的语义向量,其公式为
ST*DT=(0.645,0.089,0.679)*(1.4,1.1,0.4,0,0,…,0)=(0.916,0.039,0.184,0,0,…,0).
(6)
1.2.2 余弦相似度计算
向量空间模型中将文档和主题向量化,当文档与主题间的词项发生重复时,才可以对文档与主题的相关度通过余弦相似度进行计算.在SVSM 中,即使文档和主题没有共同词项,文档和主题都是通过向量表示后再附加语义信息,因为加入了语义信息,两语义向量的余弦相似度是可以计算的.因此可以通过计算文档dk的语义向量、主题t的语义向量TSV的余弦值,获取文档dk与主题t的相似度,其公式为
(7)
(7)式中Sim(d,t) 为文档dk的主题相似度,文档词项与主题词项权重分别用Wdi和Wtj表示.通过(7)式获得上一节例子中文档d和主题t的相似度,其公式为:
STV=TT=(0.24,0.1,0.09,0,…,0);
SD=(0.916,0.039,0.184,0,0,0);
Sim(d,t)=STV·SD=0.670.
(8)
SVSM首先使用TF-IDF值对词项进行加权,加入词项间的语义信息从而构建文档与词项的语义向量,计算两者语义向量的余弦值并作为网页的主题相似度.此模型在一定程度上考虑到向量空间模型统计上的优势,同时加入语义上的特征,使网页与主题之间相似度的获取更加合理,并减少计算时间,提高抓取网页信息的速度,使主题爬虫能满足抓取大量主题相关页面信息的需求.由于加入语义信息,可以获取与主题语义相关的页面,最终提升主题爬虫的抓取速度、抓取网页数量和抓取结果的质量.
1.3 上位词替换
1.3.1 知网(HowNet)的结构特点

图2 上位词和下位词图示
HowNet是用于反映概念之间的相同点与不同点的网状结构,比如“老师”和“学生”,“人”是它们的共性.一个比较简单的关系就是上下位关系,就是知网中概念与属性的描述.其中相对于下位词的延伸之一就是上位词(hypernym),例如:“笔记本电脑”的上位词可以是“电脑”,“鱼”的上位词可以是“水产”,“交响乐”的上位词可以是“音乐”.上位词是针对某一个主题衍生出的概念,也存在其他的关系.等同词、上位词、下位词、同类词是主题词的4种变化.上位词和下位词之间的关系如图2 所示.
1.3.2 搜索中上位词的使用
搜索首先要提炼关键词,要先知道找什么,并对信息之间的共性进行分析,找出与其他信息不同的特性,对具有代表性的关键词进行提炼,这就是选择搜索关键词的原则,它将影响对定位的速度和查找的准确性.
细化搜索条件:指的是如果你将搜索的条件描述得越详细,所得到的搜索结果也越精确.对于检索的细化过于苛刻时,或者某些词项会隐藏在一些不相关的词项之后,就像是一个通道,需要穿过这个通道才能找到想要的搜索结果.这种情况的出现,对于用户而言增加了难度,需要增加相关的专业知识才能够改变搜索条件,从而获取更多的搜索结果.
为了让计算机能够自动地解决这个问题,本文结合知网的结构特性,提出上位词替换的主题替换方法.利用本体中的上位/下位关系帮助主题爬虫进行主题概念词替换,实现主题重定义.当主题概念词过于细化而导致搜索结果达不到目标下限时,主题爬虫将使用该概念词的上位词重新进行爬行,重复这一过程直到得到满意的结果为止.通过上位词的替换会避免爬虫出现概念过度细化而导致搜索结果过少的情况,使得爬虫具备一定的穿越隧道的能力.
1.4 基于主题模型构建的语义主题爬虫
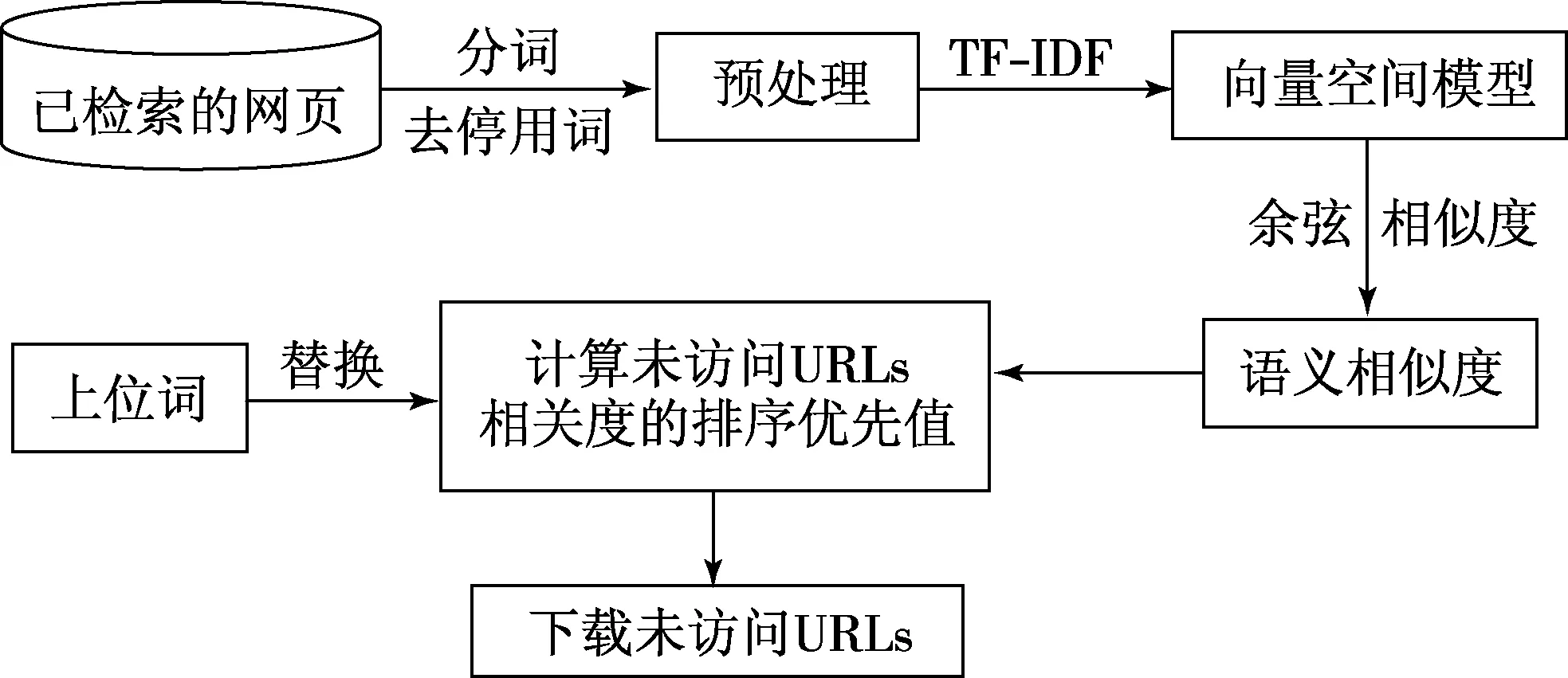
图3 基于主题模型构建的语义主题爬虫框图
基于主题扩展的语义主题爬虫,主要利用LDA模型对检索关键词进行主题模型构建,然后利用SVSM计算网页各种文本与主题的相似度,从而确定待爬行页面的全文本与标题和主题的相关性,称之为基于主题模型构建的语义主题爬虫,最后改进为语义相似度计算模型并结合上位词替换策略的聚焦爬虫ESVSM,将主题与全文本的相关性和主题与锚文本的相关性进行组合,据此对链接是否是主题相关进行判断,完整的流程如图3所示.
本文提出的基于主题模型构建的语义主题爬虫可以有效解决以下问题:
因为人为指定时带有很大的随意性,并且要求用户具备一定的专业知识.虽然也有人使用统计的方法对主题词汇进行扩展,但扩展的准确度仅仅依赖于词项出现的频率.本文提出的方法采用LDA模型对主题概念词的描述文档进行降维,使得主题概念得到较准确的扩充,为页面文档与主题相似度的计算准确性和页面优先级的计算提供依据,充分体现基于语义的主题爬行算法准确度高的优势.再利用SVSM 的语义检索优点,使得该主题爬虫具备语义理解能力,并且结合知网的结构特性,具有上位词替换的特性,在保证检索质量的前提下,具备一定的通道穿越能力,有效地引导主题爬虫从互联网中检索回大量与主题相关的网页.
当搜索达到某一条件下限时,比如搜索页面数量少于1 000并且平均搜索时间内页面数量不继续增加时,将爬虫关键词替换成它的直接上位词,从而使搜索结果得到扩充.当搜索条件是“智能手机”时,如果搜索结果满足条件下限,“智能手机”将被直接上位词“手机”替换.关于通道的穿越,一个典型的例子是,当搜索某一所高校的某一个老师发表的论文或著作,使用这个老师的姓名进行检索时,隐藏在通道后面的该名老师的主页可能没有被检索到,将影响搜索结果,此时,可以退回到该老师姓名的上位概念,例如学校名称与学院名称等,从而进入这名老师的主页,关键词得到匹配从而得到搜索结果,实现通道的穿越.
1.5 计算排序优先值模块
通过SVSM模型对文档与主题相似度进行计算,据此来判断未访问URLs与主题的相关度.文档内容包括页面的全文本和锚文本,本文对于未访问URLs优先级的计算综合考虑全文本和锚文本与主题的相似度,将全文本和锚文本与主题相似度进行线性组合作为未访问URLs的排序优先值,将加权因子设为0.5,计算公式为
(9)
未访问超链接l的优先值用priority(l)表示,也就是链接l与主题的相关度,父网页l全文本fp与主题t的相似度用Sim(fp,t)表示,包含链接l的父网页的总数为N,链接l的锚文本a1与主题t的相似度用Sim(at,t)表示,这里将线性组合因子设定为λ1=λ2=1/2.
给定2个加权因子,并使用相似度计算模型获取网页与主题的相关度值,然后使用加权因子将2个文档的相关度进行组合作为未访问URLs 的排序优先值.此主题爬行方法结合相似度计算和优先级判断的优势,使主题爬虫可以实现语义理解,并且具备一定的通道穿越的能力,在主题爬虫获取页面更准确的情况下缩短了页面抓取时间,提高主题爬虫系统整体性能.
2 实验结果及分析
将本文提出的ESVSM爬虫与其他4组爬虫进行对比分析:
(1) 广度优先爬虫[15](BF Crawler).在本文实验中作为基线爬虫和其他爬虫的参照,广度优先爬虫算法的主要思想是利用图的广度优先的策略对网页进行遍历.
(2) VSM主题爬虫(VSM Crawler).VSM主题爬虫算法的主要思想是通过构建页面与主题的向量空间模型VSM,并通过页面与主题的余弦相似度确定与主题的相关性.
(3) SSRM主题爬虫(SSRM Crawler).SSRM主题爬虫的主要思想是通过语义相似度检索模型SSRM计算页面与主题的相似性,页面内容包括全文本和锚文本.
(4) SVSM主题爬虫(SVSM Crawler).SVSM主题爬虫通过本文提出的语义相似度计算方法计算页面与主题的相关性,与ESVSM算法不同的是该算法并未使用LDA构建主题模型,主要用于验证本文提出的主题爬虫方法中主题模型构建的有效性.
(5) ESVSM主题爬虫(ESVSM Crawler).ESVSM主题爬虫算法由本文提出,算法的主要思想是先通过LDA构建主题模型,然后通过本文提出的改进语义相似度计算方法判断未访问URLs的爬行优先级,最后加入上位词替换策略防止由于主题描述过于细致所产生的检索结果较少的情况.ESVSM主题爬虫使用页面的全文本和锚文本计算页面与主题的相关性,通过本体计算词项间的语义相似度,设置主题爬虫ESVSM Crawler的实验参数,将获取结果上限设定为5 000,下限设定为1 000.当爬行记录中结果数量达到5 000时停止,在一定的时间内(设定为15 s)不再增加并且未达到下限时,将进行主题词汇替换,然后进行主题扩充再继续检索.
2.1 数据集
主题爬虫从相同的主题出发,设置相同的初始种子集.实验中选定5个不同主题分别为酷睿、计算机、文本挖掘、操作系统、人工智能.用于主题扩展的描述文档为百度百科文档,使用百度搜索引擎检索当前的主题词项,得到前5个返回结果的URLs作为该主题的初始种子集合.实验中设定选择经LDA扩展的主题模型中的前10个子话题,作为主题模型的子话题,每个子话题选择频率最高的前20个词项.
2.2 评价指标

(10)

2.3 实验结果与分析
2.3.1 主题爬虫获取相关页面数量对比分析
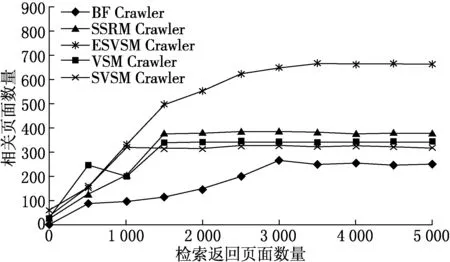
图4 所有爬虫主题“作者姓名”获取相关网页数量对比
为验证主题上位词替换方法的有效性,先进行如下实验,本文将作者的名字作为主题,使用本文研究的主题爬虫进行页面获取,得到结果如图4所示.
从图4中可以看出,由于网络中不存在更多与作者姓名为主题的相关页面,因此爬虫不到500页时,所有爬虫的页面抓取数量都增加缓慢,此时,将主题词人为地替换为作者所在学校与院系并进行主题扩展,相关页面数量呈明显的上升趋势,证明了主题上位词替换的有效性,使得ESVSM爬虫具有一定的穿越通道的能力.但由于网络中相关页面数量较少,所以随着检索返回页面数的增加,相关页面数量没有继续增加,此时由于程序设定上位词只替换一次,直到返回页面数量达到5 000时退出程序.
2.3.2 主题爬虫获取率对比分析
爬虫检索相关页面的速度可以用获取率表示(见图5).图5中由于初始种子集合都是与主题相关的,所以在开始阶段VSM爬虫表现最优,并且在检索返回页面达到500时最高,随后开始下降,并在1 000 以后,缓慢升高.本文提出的ESVSM爬虫随着检索返回页面数量的增加,一直呈上升趋势,尤其是返回前1 000 个页面时,之后上升速度略有降低.本文提出的ESVSM爬虫与其他爬虫相比,获取率高出20%~30%.证明了ESVSM爬虫的高效性.
2.3.3 主题爬虫获取页面平均相关度对比分析
平均相关度能够衡量爬行结果的质量(见图6).在爬行初始阶段,各爬虫爬行结果的平均相关度均较高,当返回页面数量超过2 500以后,ESVSM爬虫爬行结果的平均相关度要高于其他爬虫,并且随页面数量的增加呈上升趋势,平均准确率可达到85%以上.

图5 主题爬虫爬行获取率对比
3 结束语
本文针对聚焦爬虫算法存在的不足,提出ESVSM主题爬虫算法,该算法通过LDA进行主题模型构建,并采用基于语义信息的向量空间模型计算文档与主题的相似性,对于主题描述过于细化的情况,本文提出的主题爬虫算法通过上位词替换进行解决.实验结果表明,本文提出的ESVSM爬虫算法在爬行速度和爬行质量上都有一定的提升.
将来对网页中其他的文档如页面内容标题等主题的相似度进行判断,并分析页面中其他文档对未访问URLs与主题相关性的影响.目前爬虫的上位词替换需要手动检索并替换,未来研究工作将实现上位词的自动替换.
[参 考 文 献]
[1] RYAN G J,RYAN S W,RYAN C M,et al.Search engine:US,US6421675[P].2002-07-16.
[2] DE BRA P M E,POST R D J.Information retrieval in the World-Wide Web:making client-based searching feasible[J].Computer Networks & Isdn Systems,1994,27(2):183-192.
[3] PATEL A,TING P.Apparatus,method,and computer program for dynamic processing,selection,and/or manipulation of content:US,US20120209963[P].2012-08-16.
[4] LIN J W,WANG F.Using semantic similarity for input topic identification in crawling-based web application testing[DB/OL].2016[2018-03-23].https://arxiv.org/abs/1608.06549.
[5] DONG H,HUSSAIN F K.SOF:a semi-supervised ontology-learning-based focused crawler[J].Concurrency & Computation Practice & Experience,2013,25(12):1755-1770.
[6] DU Y,LIU W,LYU X,et al.An improved focused crawler based on semantic similarity vector space model[J].Applied Soft Computing,2015,36:392-407.
[7] 林超,赵朋朋,崔志明.Deep Web数据源聚焦爬虫[J].计算机工程,2008,34(7):56-58.
[8] YU R,GADIRAJU U,FETAHU B,et al.Adaptive focused crawling of linked data[C]// International Conference on Web Information Systems Engineering.Berlin:Springer,2015:554-569.
[9] HOFMANN T.Probabilistic topic maps:navigating through large text collections[C]// Advances in Intelligent Data Analysis.Berlin:Springer,1999:161-172.
[10] BLEI D M,NG A Y,JORDAN M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[11] BRIN S,PAGE L.The anatomy of a large-scale hypertextual Web search engine[J].Computer Networks & Isdn Systems,1998,30(98):107-117.
[12] KLEINBERG J M,KUMAR R,RAGHAVAN P,et al.The Web as a graph:measurements,models,and methods[C]// Proceedings of the 5th Annual International Conference on Computing and Combinatorics.Berlin:Springer,1999:1-17.
[14] 殷耀明,张东站.基于关系向量模型的句子相似度计算[J].计算机工程与应用,2014,50(2):198-203.
[15] CHO J,GARCIA-MOLINA H,PAGE L.Efficient crawling through URL ordering[J].Computer Networks & Isdn Systems,1998,30:161-172.
[16] LIU W J,DU Y J.A novel focused crawler based on cell-like membrane computing optimization algorithm[J].Neurocomputing,2014,123:266-280.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
哲学评论(2018年1期)2018-09-14
车迷(2018年12期)2018-07-26
电子制作(2017年9期)2017-04-17
中国老区建设(2016年3期)2017-01-15
山东工业技术(2016年15期)2016-12-01
学习月刊(2015年3期)2015-07-09
电子设计工程(2015年6期)2015-02-27
上海理工大学学报(社会科学版)(2011年4期)2011-09-26
