
基于YOLOv2算法的运动车辆目标检测方法研究
2018-06-13 07:04:10李良荣
电子科技 2018年6期
龚 静,曹 立,亓 琳,李良荣
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
随着社会经济的发展,隧道交通智能化管理的需求越来越受重视,而隧道通行车辆信息的快速并准确获取,是智能化管理能否实现的关键技术问题。近年来,随着机器视觉技术的发展,其在车辆检测方面的研究也在逐步的加深[1-3]。2012年,AlexNet网络结构的提出和GPU计算能力的加强,使得基于深度学习的卷积神经网络算法结合大数据的训练处理图片成为可能,并在目标检测方面得到了较好的应用。
当前大多车辆检测算法分为3个阶段:生成目标候选区域、提取检测目标特征、检测目标候选验证。文献[4]中介绍了一种典型的特征提取车辆检测方法,Hedi Harazllah 等人首先利用滑动窗口依次遍历待检测图像,提取HOG(Histogram of Oriented Gradient)和SIFT(Scale-Invariant Feature Transform)特征,利用SVM(Support Vector Machine)分类器完成候选验证及车辆检测;Bautista C M 等人采用卷积神经网络[5](Convolutional Neural Networks,CNN)的卷积层和池化层提取车辆特征,用全连接层进行候选验证。但滑动窗口生成候选区域会降低时效性,为克服该缺点,研究者又提出基于感兴趣区域的区域生成法:蔡英凤等人基于CNN算法[6],在生成候选区域阶段采用了基于视觉显著性的方法,并将候选区域输入CNN进行特征提取和候选验证完成车辆检测;在文献[7]中,FanQ应用Faster R-CNN一步完成车辆检测,大幅提升了车辆检测速度。但Faster R-CNN算法检测速度仅为5 f/s,还无法满足隧道中高速行车信息检测的实时性要求。
2015年,Redmon J提出了YOLO(You Only Look Once)检测算法[8],YOLO是一种全新的端到端的检测算法,在检测过程中模糊了上述3个阶段的区别,直接快速地完成检测任务。YOLO能够同时保证准确率和检测速率,标准YOLO能够检测的速度为45 f/s,而Fast YOLO检测速度则达到155 f/s。2016年,YOLO从v1版本进化到v2版本,YOLOv2在保持原有速度的优势之下,精度得以提升。因此,本文算法基于YOLOv2算法框架,在训练过程中进行改进,将小批量梯度下降法和冲量[9]结合来对隧道视频中车辆进行检测,以提高隧道高速行车信息检测的准确度。
1 关于YOLOv2算法
1.1 YOLOv2网络结构
由于YOLOv2算法具有较强的实时性和准确率,本文运用YOLOv2算法对视频中的车辆进行检测。针对视频捕获的图像,只检测车辆一类,采用Darknet-19网络结构并进行调整。其中,L3和L4分别与L1和L2相似。L9~L28层与L5和L8相似,皆是交替出现的卷积层和池化层[10]。把1×1的卷积核置于3×3的卷积核之间,用来压缩特征。本实验输入层图片分辨率为1 024×576,输出层为13×13×(5×1+5×5)维张量。YOLOv2网络结构如图1所示。

图1 YOLOv2网络结构图
YOLO由卷积层、池化层和全连接层构成[11]。相对于CNN,Fast R-CNN,YOLO在目标定位方面速度较快,但精确度不够,因此,YOLOv2的改进,集中于在保持分类准确率的基础上增强定位精确度。
YOLOv2去除了全连接层,将输入图片划分为S×S的网格,采用固定框(anchor boxes)来预测边界框,边界框信息包含5个数据值,分别是x,y,w,h和confidence(置信度),以及1个类别概率。其中,类别概率为当前网格预测得到的物体的边界框所包含物体为车辆的概率;(x,y)是指边界框的中心位置的坐标;(w,h)是边界框的宽度和高度;置信度反映当前边界框是否包含物体以及物体位置的准确性,即检测边界框对其检测出物体的置信度[12],计算公式为
(1)
confidence=Pr(Object)×IOU
(2)
式中area(·)表示面积,BBgt为训练的参考标准框(Ground Truth Box),BBdt为检测边界框(Detection Truth Box),Pr(Object)为边界框包含物体的概率。若边界框包含物体,则Pr(Object)=1;否则Pr(Object)=0;IOU(Intersection Over Union)为预测边界框与物体真实区域的面积交并比,最大IOU值对应的物体即为当前检测边界框负责预测的物体。
YOLOv2采用维度聚类取代手动精选的先验框和直接位置预测来解决anchor模型的不稳定,使网络更容易学习到准确的预测位置。为提高模型收敛速度,减少过拟合,在卷积池化之后,激活函数之前添加批量规范化[13]BN(Batch Normalization),对每个数据输出按照均值为0、方差为1进行规范化,通过标准化输出层,均衡输入数据分布,以加快训练速度,同时降低激活函数在特定输入区间达到饱和状态的概率,避免梯度消失,使得其适用于不同分辨率的样本输入,提高了算法的定位精确度。
(3)
(4)
式中,x(k)为第k维输入,E为均值,Var为方差,(k)为归一化比例,(k)为转换尺度。BN也有助于规范化模型,优势在于可以在舍弃dropout优化后依然不会过拟合。
YOLOv2还进行了一系列优化:(1)缩减网络,调整图片输入分辨率为416×416,使卷积特征图产生一个中心格,借助中心格来预测物体的位置;(2)使用卷积层降采样(层数为32),使得输入卷积网络的416×416图片最终得到13×13的卷积特征图(416/32=13);(3)在卷积特征图上进行滑窗采样,每个中心预测5种不同大小和比例的anchor boxes,最终特征图的每个特征点和原图的每个网格是一一对应的。
1.2 损失函数
YOLOv2使用均方和误差作为loss函数来优化模型参数[14],即网络输出的S×S×(B×(5 +C))维向量与真实图像S×S×(B×(5+C))维向量的均方和误差,即
(5)
其中,coordError、iouError和classError分别代表预测数据与标定数据之间的坐标定位误差、IOU误差和分类误差。另外在计算IOU误差时,在一个检测框中,图像中存在很多不包含物体中心的网格,该类网格预测的置信度接近0,通常,该类网格在训练时的梯度远大于包含物体的网格,若给定相同的权重,变相放大了包含物体中心的网格的置信度误差对网络参数梯度的影响,所以这3类误差对网络损失的贡献值是不同的,因此将赋予其不同的权重。综上,YOLOv2在训练过程中损失函数计算

(6)

2 训练过程
2.1 分类网络预训练
在训练过程中,采用小批量梯度下降法MSGD(Mini-batch Gradient Descent Scheme)[15]更新网络模型参数,减小损失函数直至收敛,并结合冲量(momentum)使训练过程具有更好的收敛速度与收敛性。
使用开源的神经网络框架Darknet[16]在ImageNet1000类数据集上训练10轮后,得到预训练参数。为防止过度拟合和提高训练速度,设置权重衰减系数为0.000 5,初始学习率为0.001,采用多分布策略,冲量常数为0.9。
2.2 检测网络训练
使用分类网络获得的预训练参数对网络结构进行微调,即去掉分类网络的最后一个全连接层,采用多尺度输入的方法训练检测网络,每隔10个批次(batch)便改变模型的输入尺寸,以增强模型对不同分辨率图像的鲁棒性。网络结构为32层,要求输入图像的分辨率为32的倍数。
3 检测过程
给定一个视频帧输入图像,首先将图像划分成13×13的网格。anchor=5;每个anchor box包含5个预测量以及1个类别概率,总共输出13×13×(1×5+5×5)=5 070个目标窗口,根据式(2)和式(3)预测出目标和其边框。预测目标物是车辆的条件概率为Pr(car|object),则预测物为车辆的置信度为
Conf(car)=Pr(car|object)×Pr(object)×IOU
(7)
当Conf(car)大于阈值[17]0.24,输出检测出车辆的边界框,再经过非极大抑制NMS(Non-maximum Suppression)处理去除冗余窗口,定位车辆位置。检测示意图如图2所示。
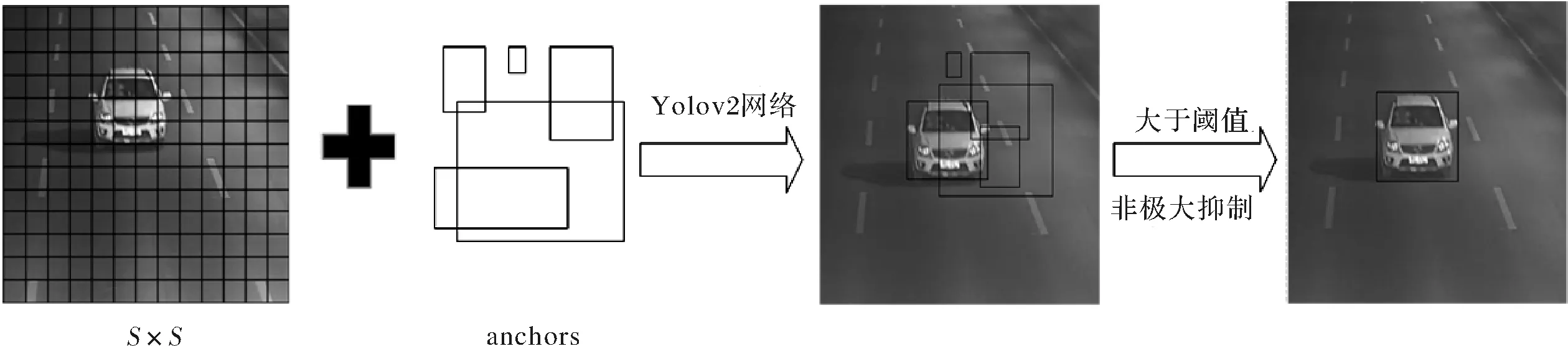
图2 车辆检测过程示意图
4 评价方法
通过计算定位精度评价公式IOU可以判断结果的类型,IOU表示了边界框与标定过的真实数据的重叠度。当IOU≥0.5时,为真正样本;当IOU<0.5,为假正样本;IOU=0,为假负样本。
精确率(Precision),它表示预测为正的样本中有多少是真正的正样本,计算
(8)
召回率(Recall),它表示样本中的正样本有多少被预测正确,计算
(9)
式中tp表示真正样本(正样本预测结果数),fp表示假正样本(系统未识别出正样本但正确判定为正样本),fn表示假负样本(将正样本错判断为负样本),n表示正样本的实际数[18]。精确率和召回率反应了算法的优劣程度,其值越高则算法越具有优越性。
5 检测过程
5.1 实验环境与数据集
实验环境:PC机为i7处理器、8 GB内存、64位操作系统(Windows7);GPU(GTX970)统一计算设备架构CUDA9.0,GPU加速库CUDNN7.5。
本实验数据集来自隧道内交通视频监控系统的视频,总共截取了3 000张分辨率为1 024×576的图片。训练数据集包含1 500张正样本图片,车辆数2 841辆,分为A、B、C3类:A为车身已全部进入拍摄区;B为车头已驶过拍摄区;C为只有车头进入拍摄区。测试数据集包含正样本图片1 000张,车辆数1 350辆,样本示例如图3所示。

图3 训练集示例
5.2 实验方法与结果
(1)YOLOv2方法实验结果。实验采用本文所述YOLOv2算法分别对两段隧道视频中的行驶车辆进行检测,测试结果如图4所示。

图4 检测效果图
(2)实验数据分析。课题组分别采用文献[6]中的CNN算法、文献[11]中的Faster R-CNN算法和文献[12]中的YOLO算法对图4所用视频进行处理,然后计算基于不同算法的精确率、召回率以及每秒识别帧数进行数据对比,如表1所示。
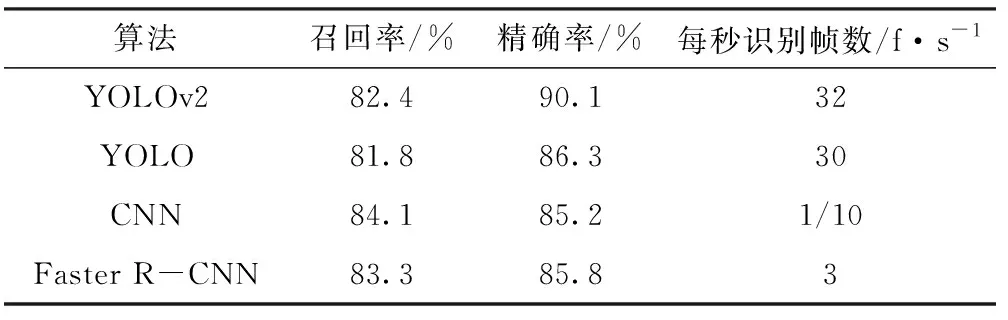
表1 测试实验结果
从表1中可以看出,采用本文所述YOLOv2算法的精确率、召回率和每秒识别帧数较YOLOv1有所提高,且每秒识别帧数远大于CNN、Faster R-CNN,满足基于视频的车辆目标检测。虽然YOLOv2召回率略低于其他两种算法,但对于背景环境简单、目标类别较少的情况,其检测召回率、精确率较高,检测速度足以应对车辆目标检测。且本文采用了多尺度输入的方法训练检测网络,增强了该模型检测鲁棒性。实验中发现车灯亮度的变化对检测效果有一定的影响,这是今后的研究中需要解决的问题。同时,对于远处的车辆检测容易出现漏检,这是导致召回率较低的主要原因。
YOLOv2模型在近处对运动车辆进行检测时,能保证较高的召回率、精确率和识别速度,满足对道路交通检测的准确性和实时性,且YOLOv2适应不同分辨率的输入图像,对车辆目标检测有较好的鲁棒性。
6 结束语
本文应用YOLOv2检测算法对基于隧道视频的车辆进行检测,实验结果获得了较高的准确性和时效性,且该算法具有较好的鲁棒性,基本满足交通视频监控要求。该算法目前能检测9 000多种物体类别,算法较为新颖,对今后多运动目标检测具有较好的实用性。但是基于深度学习的算法对硬件设备的要求比较高,所以将其用于现实场景还需进一步研究。
[1] Saran K B,Sreelekha G.Traffic video surveillance: vehicle detection and classification[C].Pasadina:2015 International Conference on Control Communication & Computing India(ICCC),IEEE,2015.
[2] Cao Q, Liu R, Li F, et al. An automatic vehicle detection method based on traffic videos[C].Tokoyo:2010 17th IEEEE International Conference on Image Processing (ICIP),IEEE,2010.
[3] Zhang X.Research on vehicle object detection in traffic video stream[C].Beijing:2010 5thIEEE Conference on Industrial Electronics and Applications(ICIEA),IEEE, 2010.
[4] Harazllah H,Schmid C,Jurie F,et al.Classification aided two stage localization[C].Denver:Pascal Visual Object Classes Challenge Workshop,in Conjunction with ECCV,2008.
[5] Bautista C M, Dy C A, Maalac M I, et al. Convolutional neural network for vehicle detection in low resolution traffic videos[C].Houston:2016 IEEE Region 10 Symposium (TENSYM P),IEEE,2016.
[6] Huynh C K,Le T S,Hamamoto K.Convolutional neural network for motorbike detection in dense traffic[C]. Phoneix:2016 IEEE Sixth International Conference on Communications and Electronics (ICCE),IEEE,2016.
[7] Fan Q,Brown L,Smith J.A closer look at faster R-CNN for vehicle detection[C].Portland:2016 IEEE Intelligent Vehicles Symposium(IV),IEEE,2016.
[8] Redmon J,Divvala S,Girshick R,et al.You only look once: unified, real-time object detection[C].Las Vegas:Proceeding of the IEEE Conference on Computer Vision and Pattern Recogniton,IEEE,2016.
[9] Juhwan Kim,Hyeonwoo Cho.The convolution neural network based agent vehicle detection using forward-looking sonar image[C].San Diego:2016 IEEE Oceans 2016 MTS,IEEE,2016.
[10] 王丽君,于莲芝.基于卷积神经网络的位置识别[J].电子科技,2017,30(1):104-106.
[11] Gao Yang,Guo Shouyan.Scale optimization for full-image-CNN vehicle detection[C].Guangzhou:2017 IEEE Intelligent Vehicles Symposium (IV),IEEE,2016.
[12] 高宗,李少波,陈济楠,等.基于YOLO网络的行人检测方法[EB/OL].(2017-06-23)[2017-11-29]http://kns.cnki.net/kcms/detail/31.1289.TP.20170623.0916.002.html.
[13] 杨天祺,黄双喜.改进卷积神经网络在分类与推荐中的实例应用[EB/OL]. (2017-04-01)[2017-11-29]http://kns.cnki.net/kcms/detail/51.1196.TP.20170401.1738.054.html.
[14] 张祎.一种启发式线性回归损失函数选取方法[J]. 计算机与现代化,2017(8): 1-4.
[15] 王宇宁,庞智恒,袁德明.基于YOLO算法的车辆实时检测[J].武汉理工大学学报,2016, 38(10):41- 46.
[16] 魏湧明,全吉成,侯宇青阳.基于YOLO v2的无人机航拍图像定位研究[EB/OL].(2017-06-23)[2017-11-29] http://kns.cnki.net/kcms/detail/31.1690.TN.20170623.11 24032.html.
[17] 赵勇,李怀宇. 基于改进Sobel算法的车辆检测技术[J]. 电子科技, 2017,30(11):78-180.
[18] Ahmed E,Mohaisen A.ADAM:Automated detection and attribution of malicious webpages[C].Albuquerque:2013 IEEE conference on Communications and Network Security,IEEE,2013.
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21 06:18:46
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化·高一版(2020年1期)2020-02-20 13:24:32
电子制作(2019年11期)2019-07-04 00:34:38
中学生数理化·八年级物理人教版(2018年10期)2018-12-06 09:33:16
证券法律评论(2018年0期)2018-08-31 02:33:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
科普童话·百科探秘(2015年4期)2015-05-14 07:06:42
外语学刊(2014年6期)2014-04-18 09:11:49
电视技术(2014年19期)2014-03-11 15:38:20
