
基于粗糙集理论的恶意代码特征分析
2018-06-13 07:05张长胜任小波
电子科技 2018年6期
张长胜,周 洌,任小波,李 川
(昆明理工大学 信息工程与自动化学院,云南 昆明650500)
在促进业务信息化以及网络化快速发展的同时, 信息化技术给用户的业务信息系统带来了越来越多的安全问题,恶意代码是其中一个倍受瞩目的安全问题[1-2]。
针对Android[3]系统的恶意代码检测技术主要有动态检测和静态检测技术。其中,最经典的是基于恶意代码特征指令序列的静态检测方法, 其通过分析软件的源代码等信息,与已知的恶意代码进行匹配,检测是否包含恶意代码特征来确定,被广泛应用于各种杀毒软件。N.Peiravian[4]使用纯静态分析,通过提取 APK 的权限与 API 调用,并构建高维特征向量,使用机器学习的方法对数据集进行判断,来确认软件是否含有恶意代码。董胜亚[5]提出基于 KNN 的 Android 平台软件异常监测模型。传统的静态检测方法因为需维护样本库使得其应用受到制约。但是随着云计算技术的发展,有效解决了传统静态检测技术中样本库内容不断增加的难题,使静态检测技术突破了样本库维护的瓶颈[6]。因此,本文采用基于粗糙集算法的方法,建立特征模型,提取权限特征、API特征,在机器学习算法的基础之上,对安卓恶意代码特征进行分析检测。
1 粗糙集理论
在粗糙集(RS)中,特征属性叫做故障案例,由决策属性、条件属性组成。相似性由特征属性决定。在计算特征相似度时,不同特征属性的权重也不相同[7]。到目前为止,确定属性权重的方法分为3类:(1)基于Z.Pawlak属性重要度的概念[8],通过代数的形式来算出属性权重;(2)根据矩阵的方式来确定权重,在模糊矩阵中,属性频数就是该属性权重重要程度;(3)使用信息熵来对属性权重进行计算。为了得出比较客观的权重值以及特征之间的相似度,结合粗糙集理论来进行权重、相似度的计算。
粗糙集算法基于其它算法有如下两方面的优点:首先, RS是一个用数据来分析的工具,数据分析能力强。可表达和解决一些不确定、不完备、不精确的信息;可针对数据做出化简操作;可判别数据之间的相互依赖关系;可根据经验数据,获取得到容易验证的规则知识信息[9];其次,RS运用了数据自身所提供的数据信息,不要求有先验的知识[10]。
2 特征匹配计算
2.1 知识粒度RS计算方法
Decui Liang 等人提出了计算粒度的一般方法[11]。苗夺谦研究了如何对RS中粒度进行划分,并且提出了“粒度计算”模型来计算属性权重[12]。
在RS中,把研究对象抽象成S=(U,C∪D,V,f),U代表的是论域(U不为空),属性的子集为X⊆C,x⊆C代表属性。则x对于X的属性重要度用Sig(x)表示为[13]
(1)
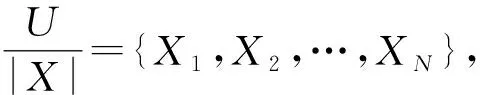
2.2 属性权重的计算
在RS中,属性权重计算是欧式相似度计算的前提,根据信息系统中信息表求出各个属性的权重值。
基于RS的属性权重计算过程如下:
输入案例特征信息表S=(U,A,V,F),新案例集Ci=(ai1,ai2,…,ain)。
输出客观权重。
步骤1根据新案例特征属性ai1~ain确定信息表;
步骤2将j初始化为1,n=|Ci|;
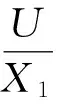
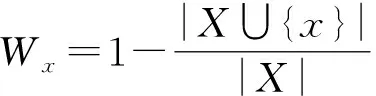
2.3 RS与欧氏距离匹配模型
知识粒度RS和欧氏距离的特征匹配模型如图1所示。
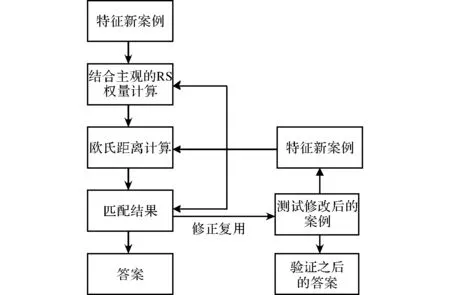
图1 基于RS和欧氏距离模型
移动终端手机故障按照一定的形式表现出来,如手机运行状态、手机型号、CPU处理器型号等等。云平台收集移动终端这些参数并且创建新的特征案例。
在RSCu={a01,a02,…,a0n}中,定义一般特征案例集为Ci=(ai1,ai2,…,ain),Ci代表案例库中的案例集,ai1,ai2,…,ain代表特征属性。用多维数组来表示新产生的案例,a01,a02,…,a0n表示Cu特征案例中的参数属性值。云平台利用知识粒度RS原理计算属性的权重值。一般把计算出来的属性权重值定义为I=(Ia1,Ia2,…,Ian),0≤Iai≤1。计算一般案例与新增案例的欧氏距离[12]
(2)
基于粗糙集和欧氏距离的相似度匹配算法过程如下:在收集新特征案例之后,云平台首先从案例库中检索出有没有与新案例一样的特征案例,若存在,云平台就直接返回特征案例的结果,若云平台中不存在与案例库匹配的特征案例,利用欧氏距离算法进行特征匹配计算[15-16]。(1)提取终端特征,同时创建新故障案例; (2)根据提取的特征属性案例,生成特征故障信息表; (3)基于RS计算属性权重; (4)按照式(2)计算当前特征案例与案例库中条件属性的欧氏距离。
3 实验结果与分析
3.1 实验设计
针对本文中研究的安卓恶意代码检测模型,进行多组实验,包括:权限特征的特征选择对比实验、系统 API 特征的特征选择对比实验。
(1)权限特征实验。 权限特征实验进行 10组分类实验,观察准确率、漏报率、误报率评估指标的变化;
(2)API 特征实验。 在 API 特征实验过程中,为 2 000 个 API 分别设计了 10 组实验,梯度是 200 ,观察准确率、漏报率、误报率评估指标的变化。
在机器学习算法的基础之上,对安卓恶意代码特征进行分析检测,需要对实验数据集进行划分操作,划分出测试样本集合以及训练模型的训练样本集合。在实验数据集划分的过程中,对样本采取均匀抽样的方法来对样本进行提取,从而构成训练数据集以及测试数据集。训练数据集样本数量是3 140,测试数据集样本数据是2 123。
本实验实施过程中,将安卓恶意应用程序说明为正样本,良性应用程序说明为负样本。为检测本文方案的性能以及效果,需要计算Accuracy(准确率),FPR(误报率),FNR(漏报率) 指标。TP 表示恶意样本被正确分类为恶意样本的数量; FN 表示恶意样本被错误分为良性样本的数量;TN 表示良性样本的数量;FP 表示良性样本误报为恶意样本的数量。
准确率的计算如式(3)所示
(3)
误报率的计算如式(4)所示
(4)
漏报率的计算如式(5)所示
(5)
3.2 实验结果分析
在进行权限特征实验之前,需要对权限特征进行分组,根据权限特征在相应数据集上的排序,对权限特征进行分组,梯度为10 个权限特征,一共分了13组,在数据集现有的情况下,使用粗糙集(RS)实验所采用的数据集合当中良性安卓样本和恶意安卓样本数量都为500。针对权限特征在实验数据集上的准确率、误报率、漏报率进行实验结果详细统计。实验结果如表1所示,准确率如图 2所示,误报率如图 3 所示,漏报率如图4 所示。
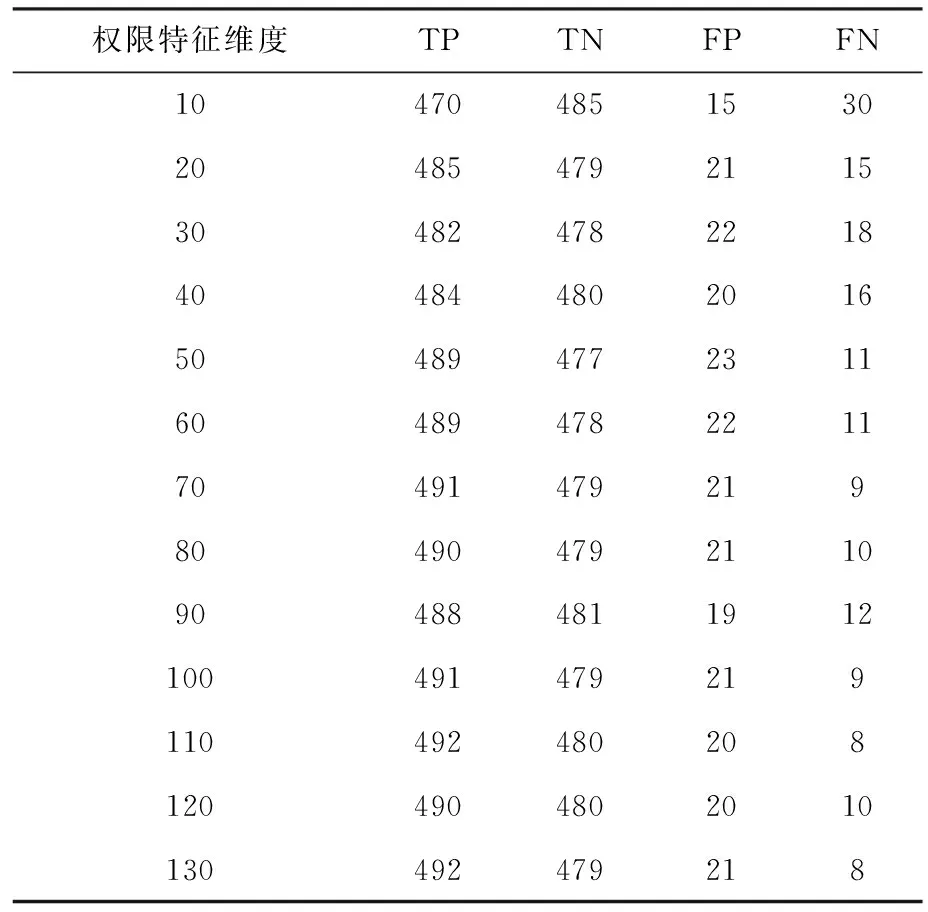
表1 基于RS权限特征
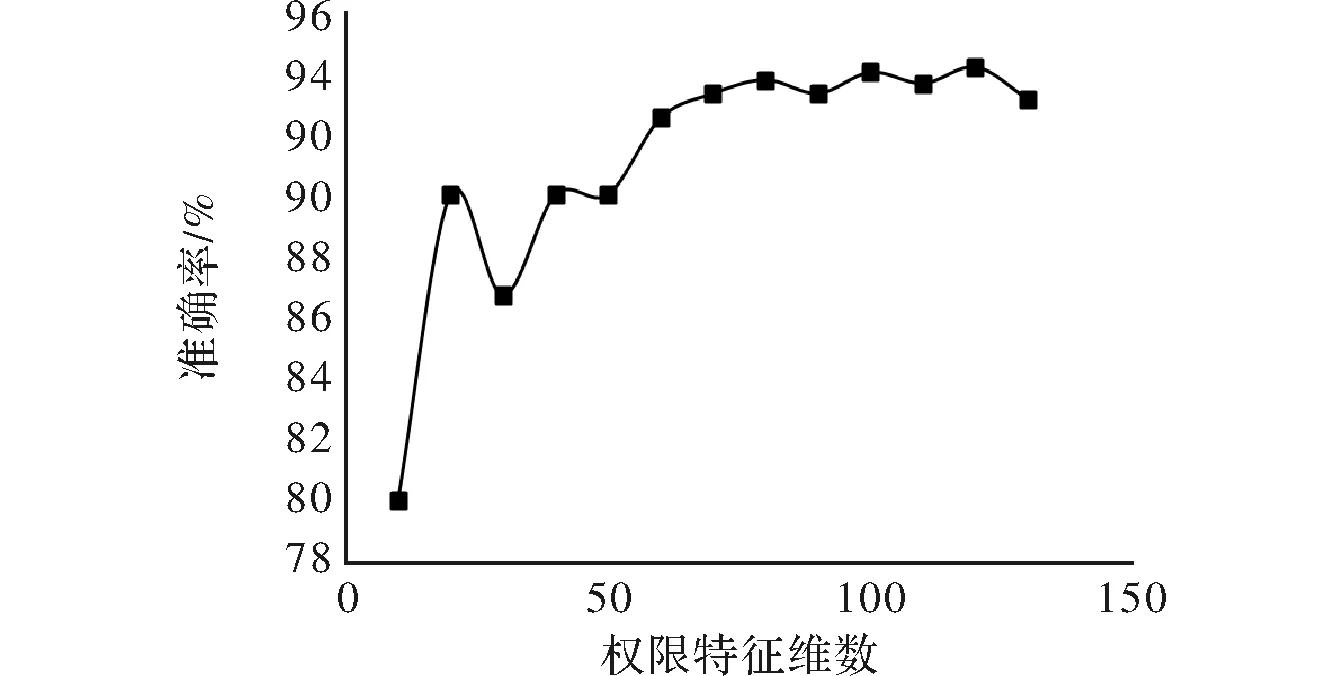
图2 准确率
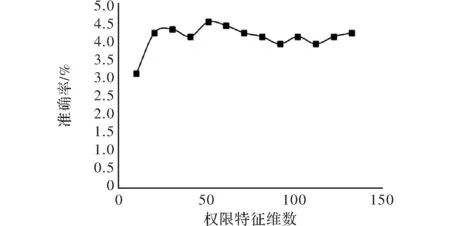
图3 误报率
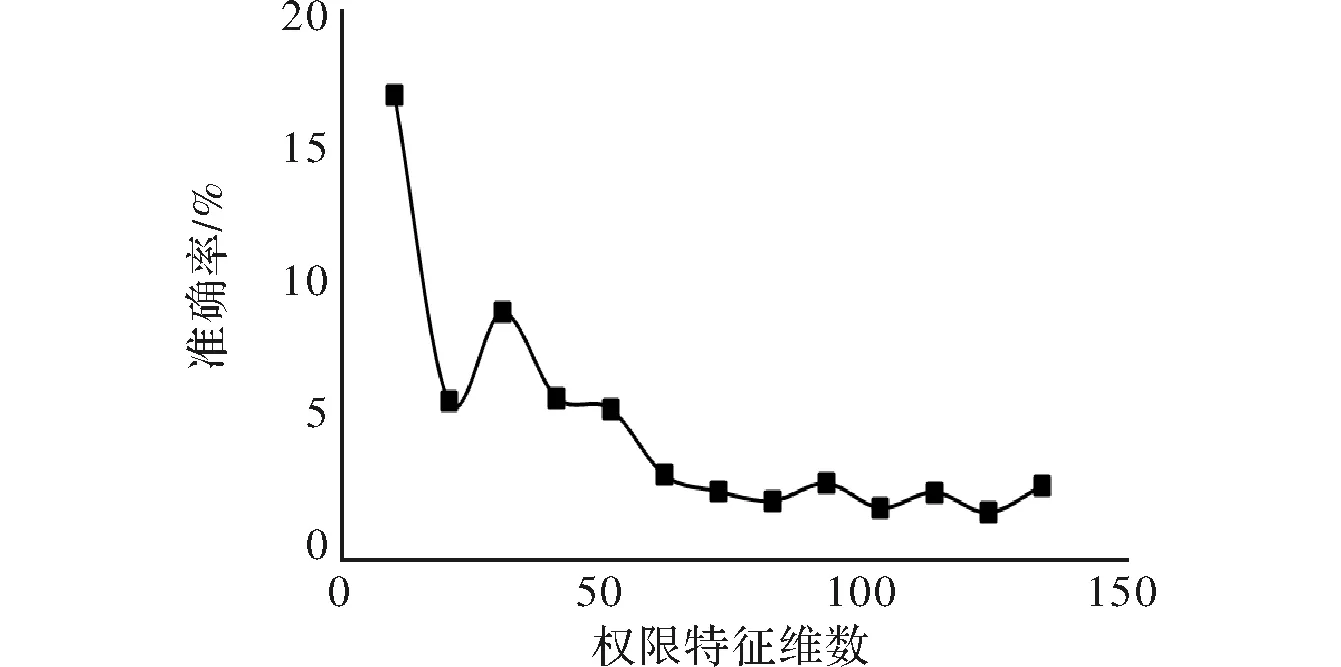
图4 漏报率
从以上3幅图中分析得到:对于维度不一样的权限特征的选择,以及不同的算法的选择,当特征维数达到 约60维时,其准确率、误报率、漏报率所对应的数值都接近收敛。所以,在建立基于权限特征的安卓恶意代码检测模块的时候,选择前60维的权限特征。
为了挖掘出较强分类能力的系统 API 特征集,本实验获取了系统 API 排序中的前2000个 API 来进行实验,并且分成 10 组,基于RS算法进行实验。本实验采用的实验数据集正样本数量和负样本数量都是500。实验结果如表2所示,准确率如图5所示,误报率如图6所示,漏报率如图7所示。
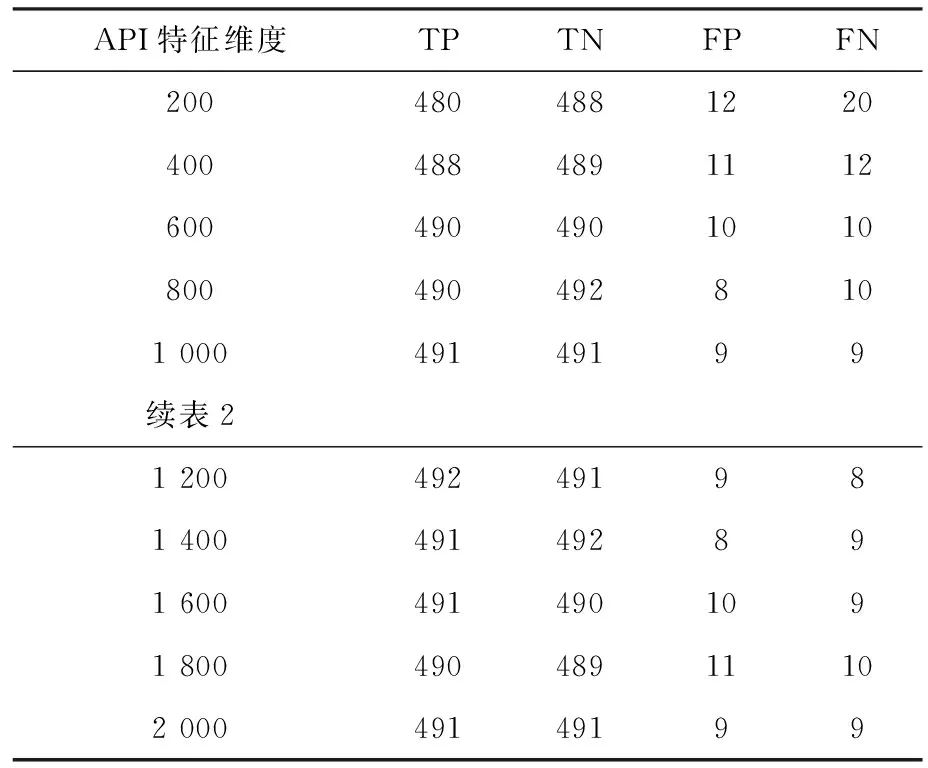
表2 基于RS 系统API特征
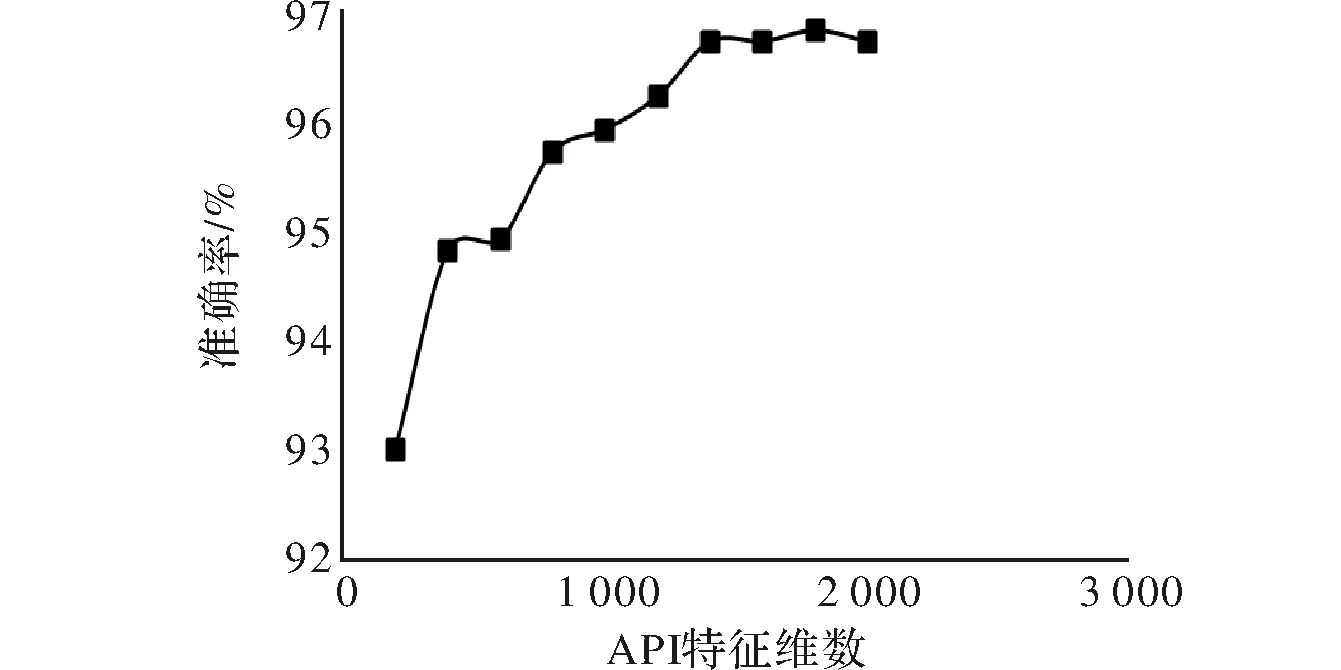
图5 准确率
从图5中API特征准确率分析得到,随着 API特征维数的增加,准确率在提高,但当API 特征的维数超过 1 300时,算法的准确率开始趋向收敛,不会发生明显变化。
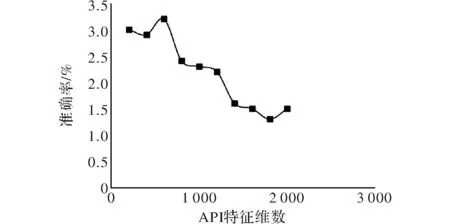
图6 误报率
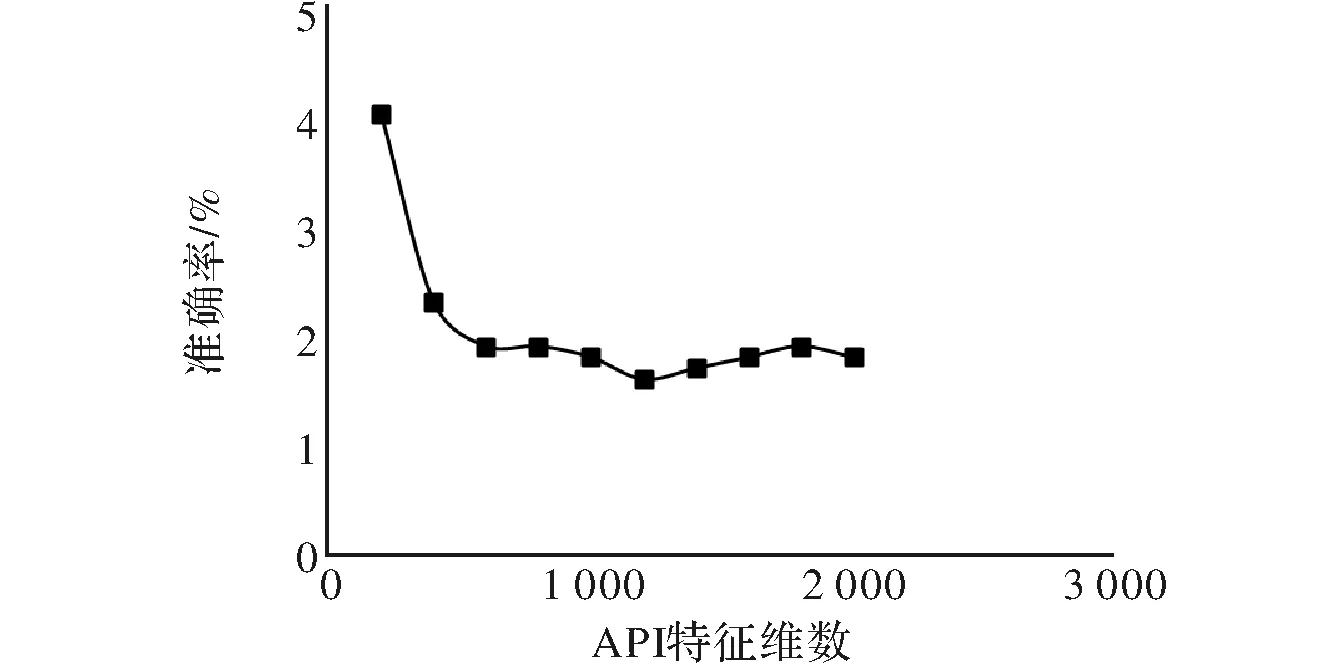
图7 漏报率
由图6和图7可知,随着特征维数的增加算法误报率以及漏报率都会降低,当系统 API 特征维数增加到约1 300维,漏报率以及误报率均趋收敛、平缓,有最低趋势。所以训练时,使用前1 300维的 API 特征。
4 结束语
从实验结果可知,实验的全部检测准确率都达到90%,说明了提取权限特征、API特征,并进行恶意检测的思路是可行的。但是,良性与恶意样本的准确率都没有达到100%。良性样本没有达到100%主要原因是部分应用特征的行为跟恶意程序的很相似,从而导致了检测过程的误报。而恶意样本没达到100%,主要原因是本实验对恶意软件调用的API特征没有进行覆盖完全,部分少量的恶意应用行为没有被全部检测到。
[1] 徐小琳,云晓春,周勇林,等. 基于特征聚类的海量恶意代码在线自动分析模型[J]. 通信学报, 2013(8):146-153.
[2] 韩晓光.恶意代码检测关键技术研究[D].北京:北京科技大学,2015.
[3] 万一,朱志祥,吴晨,等. 一种基于数据加密技术的安卓软件保护方案[J]. 电子科技, 2016, 29(2):173-176.
[4] 董胜亚.基于Android 平台的软件异常行为检测技术研究[D].北京:北京邮电大学,2013.
[5] Peiravian N, Zhu X. Machine learning for android malware detection using permission and API calls[C].Houston: International Conference on TOOLS with Artificial Intelligence. IEEE, 2013.
[6] 卿斯汉. Android安全研究进展[J]. 软件学报,2016,27(1):45-71.
[7] 贾冀婷.基于PSOABC-SVM的软件可靠性预测模型[J]. 计算机系统应用,2014,23(7):161-164.
[8] 张锐,杨吉云.基于权限相关性的Android恶意软件检测[J].计算机应用,2014, 34(5):1322-1325.
[9] 张文,严寒冰,文伟平.一种Android恶意程序检测工具的实现[J].信息网络安全, 2013(1):27-32.
[10] 徐尤华, 熊传玉. Android应用的反编译[J]. 电脑与信息技术, 2012, 20(1):50-51.
[11] Jia J T, Computer D O. Software Reliability Prediction Based on PSOABC-SVM Model[J]. Computer Systems & Applications, 2014(9):511-519.
[12] 于洪,王国胤,姚一豫,等. 决策粗糙集理论研究现状与展望[J].计算机学报, 2015(8):1628-1639.
[13] 王蕊,冯登国,杨轶,等. 基于语义的恶意代码行为特征提取及检测方法[J].软件学报,2012, 23(2):378-393.
[14] 杨帆. 软件安全性测试与分析的若干关键技术研究[D]. 武汉:武汉大学, 2013.
[15] 张清华,王进,王国胤.粗糙模糊集的近似表示[J].计算机学报,2015(7):1484-1496.
[16] Miao D Q,Xu F F,Yao Y Y,et al. Set-theoretic formulation of granular computing[J]. Chinese Journal of Computers, 2012, 35(2):351-363.
猜你喜欢
湖南文理学院学报(自然科学版)(2022年2期)2022-05-06
煤气与热力(2021年6期)2021-07-28
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
设备管理与维修(2020年14期)2020-08-12
中国交通信息化(2018年5期)2018-08-21
中国质量监管(2016年10期)2016-07-10
现代电子技术(2015年21期)2015-11-09
卫生职业教育(2014年20期)2014-05-16
