
引入兴趣稳定性的时间敏感协同过滤算法
2018-06-01 10:50孙福振
计算机工程与应用 2018年11期
张 旭,孙福振,方 春,郭 蕊
ZHANG Xu,SUN Fuzhen,FANG Chun,GUO Rui
山东理工大学 计算机科学与技术学院,山东 淄博 255049
College of Computer Science and Technology,Shandong University of Technology,Zibo,Shandong 255049,China
1 引言
《中国互联网络发展状况统计报告》显示,截至2015年6月,中国互联网网民规模达6.68亿[1]。伴随着信息技术飞速发展,信息量也发生着爆炸式的增长,信息过载问题也日益突出。在海量信息中用户很难发现自己需要的,感兴趣的部分。而推荐系统是在用户没有明确需求的情况下,通过分析用户历史行为数据给用户进行兴趣建模,然后将用户可能感兴趣的信息推荐给用户。
协同过滤推荐是迄今应用最成功、最成熟的技术之一,其主要分为两类:基于用户的协同过滤和基于物品的协同过滤[2]。基于物品的协同过滤推荐算法的思想是根据用户的历史行为数据分析计算得出用户的行为偏好,据此用户偏好给用户做出推荐。其前提假设是,在未来的一段时间内用户的兴趣偏好是不变化的。而传统的基于用户的协同过滤推荐算法的思想是根据用户A的行为数据计算出和用户A具有相似偏好的邻居用户,然后将邻居用户感兴趣的物品且用户A还没有发现的物品推荐给用户A。虽然协同过滤取得了很大成功,但也存在时间动态性问题,物品流行偏执等问题。
针对协同过滤技术中的动态性问题,文献[3]加权时间权重和资源相似度的数据权重,提出了适应用户兴趣的推荐算法,没有考虑用户短期兴趣和长期兴趣的稳定性。文献[4]提出了一种动态推荐技术,考虑了时间信息,并没有涉及用户兴趣稳定性。随着移动设备蓬勃发展,文献[5]提出了一种SUCM模型来学习细粒度的用户偏好给用户做推荐,没有考虑时间敏感和用户兴趣稳定性。本文从时间和兴趣稳定性角度出发,考虑用户兴趣稳定的情况下引入时间敏感因子,进而给用户产生动态推荐,实验表明,该模型降低了推荐误差。
针对物品流行偏执问题,文献[6-8]提出了运用近邻度、影响力和普及性三方面综合考虑用户评分对用户之间相似度的影响。文献[9]提出了一种启发式相似度计算模型,提高了用户之间的相似度。文献[10-12]通过使用自编码方式来提高topN推荐质量。文献[13]利用社交网络,分析社交群体中的强弱关系,提出一种EM算法来提高推荐质量。文献[14-15]不是从相似度计算模型而是通过改变推荐结果的流行度分布来缓解偏执问题。而本文在相似度建模阶段通过将所有物品流行度进行“装箱化”,然后根据用户实际评分映射“箱子”,映射生成三维的基于物品流行度的用户兴趣特征向量——“向量化”,进而计算用户之间的相似度。
综上所述,针对协同过滤中的流行偏执问题和时间动态性问题,本文考虑时间敏感的用户兴趣稳定性,以及物品流行度因素对用户之间相似度的影响,提出了一种引入兴趣稳定性的时间敏感协同过滤算法。实验表明,该算法能够有效降低推荐误差,挖掘长尾物品,缓解物品流行偏执现象。
2 方法介绍
2.1 基于物品流行度的用户兴趣特征相似度模型
定义1(物品i的流行度定义)所有用户对物品i的评价次数之和与物品总数的比值。公式如下:

其中,counti表示有多少个用户对物品i进行了评价,countI表示物品总数。
算法描述:
(1)取三个物品流行度区间[a1,a2),[b1,b2),[c1,c2)。
(2)用公式 popularityi计算用户u已经评价的所有物品的流行度。
(3)将步骤(2)中用户计算的所有物品的流行度先装箱,然后映射到步骤(1)。
装箱伪代码为:


说明:a1,a2,b1,b2,c1,c2是根据实验取得的阈值数据。
映射伪代码为:

(4)将步骤(3)中生成的 featurevector用户特征向量采用余弦相似度公式来计算用户A和用户B的基于物品流行度的用户兴趣特征相似度。公式描述如下:
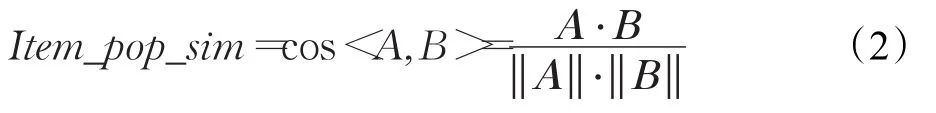
上述模型称为Item_pop_sim模型,简称IPS模型。
2.2 引入兴趣稳定性的时间敏感相似度模型
在实际应用过程中,用户的兴趣通常具有易变性,不仅与用户对物品评分数值有关,还与物品的流行度有关,这两者加权构成了用户的兴趣度。用户兴趣度定义如下:
定义2(用户u的兴趣度)是由用户u对i个物品的兴趣向量组成的向量集合Pu=(Pu1,Pu2,…,Pui)。
定义3(用户u的第i个物品兴趣向量)用户u评价的第i个物品的实际评分值与满分值的比值再加权该物品的流行度。公式描述如下:
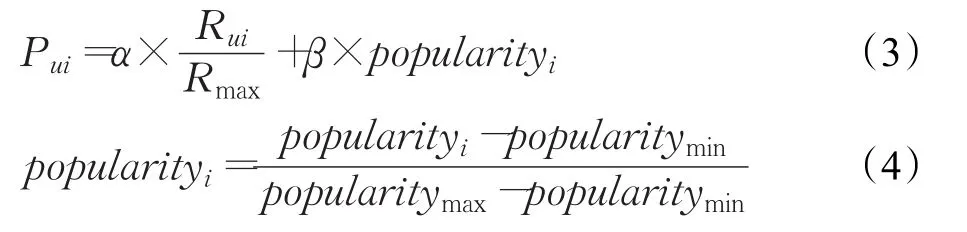
其中,Pui表示用户u对第i个项目的兴趣程度,Rui表示用户u对物品i的打分值,Rmax表示该物品的满分值,popularityi表示公式(1)中定义的物品i的流行度,popularitymax表示所有物品的最大流行度,popularitymin表示所有物品的最小流行度。α,β表示参数,且α+β=1,该参数可以通过实验验证得出。同样,使用余弦相似度来计算用户u和用户v之间的兴趣相似度,公式描述如下:

该模型通过引入带权值的物品流行度可以有效地缓解用户打分偏置的问题。
定义4(用户u的兴趣稳定性)用户u评价的所有物品评分数值的方差。公式描述如下:
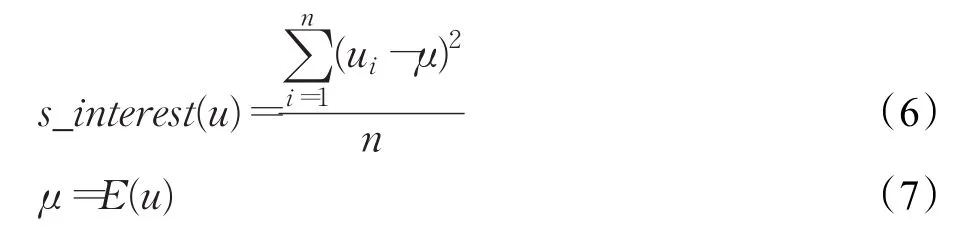
其中,ui表示用户u评价的第i个物品的评分值,n为用户u评价的所有物品的总数,μ为用户u评价的所有物品评分值的平均值。方差的大小来衡量用户兴趣的稳定性,即方差越小用户兴趣越稳定。
现实中,用户的兴趣往往不是一成不变的,可能受自身因素的影响,周围环境,兴趣会随着时间的流逝潜移默化,很早之前的兴趣可能会逐渐淡忘或者消失。本文从影响用户兴趣的因素出发,给出了时间敏感的表征。
定义5(时间敏感)在两个用户兴趣稳定的基础上,两用户对物品的评分时间越相近则用户间的兴趣相似度就越高,即用户的兴趣相似度对时间敏感。
考虑到用户兴趣随着时间的增长可能会发生变化,本文引入 e-φ| |tui-tvi为时间敏感因子,以天为单位且两用户评分时间越相近,表明用户的区域时间段内兴趣相似度就越高。
为建模用户兴趣的时间敏感动态性,本文提出了一种时间敏感的用户兴趣稳定性相似度计算模型。公式如下:

其中,σu=σu-σmed,σv=σv-σmed,σu和 σv分别表示用户u和用户v分别去中心化后的评分方差,σmed是指评分方差的中值,通过统计分析可以得出,方差大部分在0.5到1.5之间,所以σmed=1,δ表示实验取得的参数,其中,δ∈(0,1)。Iu⋂Iv表示用户u和用户v共同评分的物品交集,tui和tvi分别表示用户u和用户v对物品i的评价时间。φ表示实验取得的参数,其中,φ∈(0,1)。∑X2和∑Y2表示用户u和用户v对物品评分值的平方和。上述公式(8)中的模型称为Stability_Time_Sim模型,简称为STS模型。
2.3 两种相似度模型的融合
上面介绍了两种相似度模型各有各的优点,其中基于物品流行度的用户兴趣特征相似度模型可以有效地缓解物品偏置问题,引入时间敏感的用户兴趣稳定性的相似度模型可以实时抓住用户兴趣,挖掘长尾物品,提高推荐系统的新颖度。所以为了使推荐效果更好,不增加算法时间复杂度且易于实现起见,将两种模型进行线性加权,提出了Item_Pop_Stability_Time_Sim函数模型。公式描述如下:
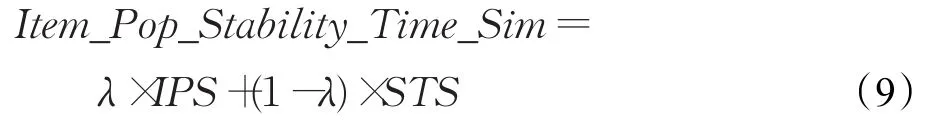
其中,λ为实验取得的参数且λ∈[0,1]。关于λ取值对于模型的影响,见本文3.3.3节详细分析。
上述模型简称IPSTS模型,IPSTS模型综合考虑了用户兴趣的稳定性、时间敏感情况,以及物品流行度等因素。综合这些因素进行建模,实验表明,加权后的相似度模型在推荐质量上有明显提高。
3 实验设计及分析
3.1 实验数据集
本文实验所用的数据集是美国Minnesota大学GroupLens小组开发的MovieLens站点所提供的数据集。MovieLens建立于1997年,是一个基于Web的推荐系统,目前,该站点提供三种不同数量级的数据集,分别为:943个用户对1 682部电影的10万条评分的数据;6 040个用户对3 900部电影评分的100万条数据;71 567个用户对10 681部电影做出的1 000万条评分数据。
本文实验采用了943个用户对1 682部电影的10万条评分数据集,其中每个用户至少对20部电影进行了评价。该数据集的稀疏等级为1-100 000/(943×1 682)=0.937,本文将实验数据集划分为训练集和测试集,其中训练集占80%,测试集占20%。
3.2 评价标准
本文采用的推荐质量的评价标准分别是平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Squared Error,RMSE)[16]。平均绝对误差(MAE)公式如下:

均方根误差(RMSE)公式如下:

3.3 实验结果
实验比较了IPSTS模型与Pearson(皮尔森)模型以及Euclide(欧几里德)模型在推荐质量上的差异,第一步先考查当参数δ和参数λ固定时,随着邻居数量逐渐增多,三种模型在RMSE和MAE两个评价标准上的效果。第二步固定邻居数量,考查当参数δ和参数φ以及参数λ按照相应的步长逐渐增长时,三种模型在RMSE和MAE两个评价标准上的效果。
3.3.1 IPSTS模型实验结果
图1显示出取不同邻居时,各个相似度计算模型对RMSE的影响。其中邻居数量分别为10,20,30,40,50,60,70,80,90。分析得出,IPSTS模型计算的均方根误差(RMSE)比Euclide和Pearson模型计算的均方根误差(RMSE)都要低(例如:当邻居数量为20时,本文提出的IPSTS模型比Pearson模型要低6%左右,比Euclide模型要低30%左右)。所以,降低了误差,提高了推荐质量。

图1 IPSTS、Pearson、Euclide三种模型RMSE对比图
图2 显示出取不同邻居时各个相似度计算模型对MAE的影响折线图。其中邻居数量分别为55,60,65,70,75,80,85,90。分析得出,IPSTS模型计算的平均绝对误差(MAE)比Euclide和Pearson模型计算的平均绝对误差(MAE)都要低(例如:当邻居数量为80时,IPSTS模型比Pearson模型要低1%左右,比Euclide模型要低8%左右)。所以,提高了推荐质量。

图2 IPSTS、Pearson、Euclide三种模型MAE对比图
在实验中,参数的选取是至关重要的,为了让实验达到满意的效果,同时充分测试算法的健壮性和适用性,更为了优化算法,本节对δ取值选取进行了实验,为了尽可能地排除其他因素干扰,仅仅检验δ对IPSTS模型的影响,取邻居数量为50,参数λ取0.2时,检验随着δ的递增,IPSTS模型在RMSE评价标准上的效果。如图3所示。
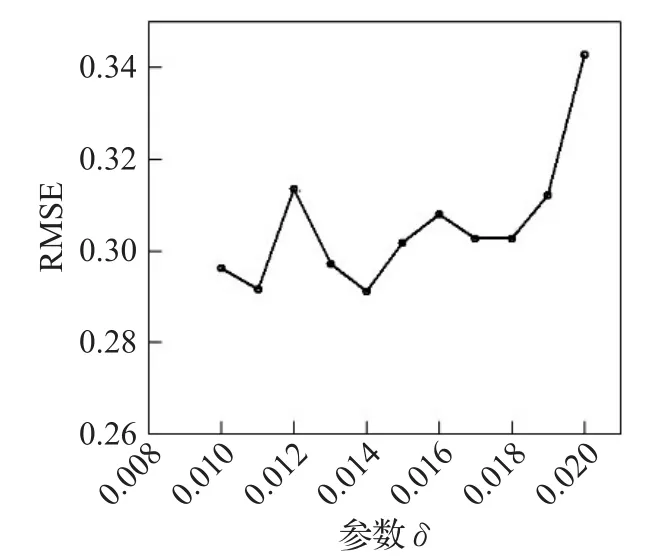
图3 参数δ变化对IPSTS模型的影响
3.3.3 参数λ对IPSTS模型的影响
同时,为了检验权重参数λ对IPSTS模型的影响,结合上一节实验结果取邻居数量为50,参数δ取0.014时,检查随着λ的增长,IPSTS模型在RMSE评价标准上的效果。
图4显示,从0.1开始,随着λ的增长,RMSE是先减少后增长,然后增长到一定的数值后再下降,之后,随着λ的增长,RMSE基本上趋于缓和。由图4可知,当λ取0.2时,RMSE最小。所以,在IPSTS模型中,参数λ取0.2最优。
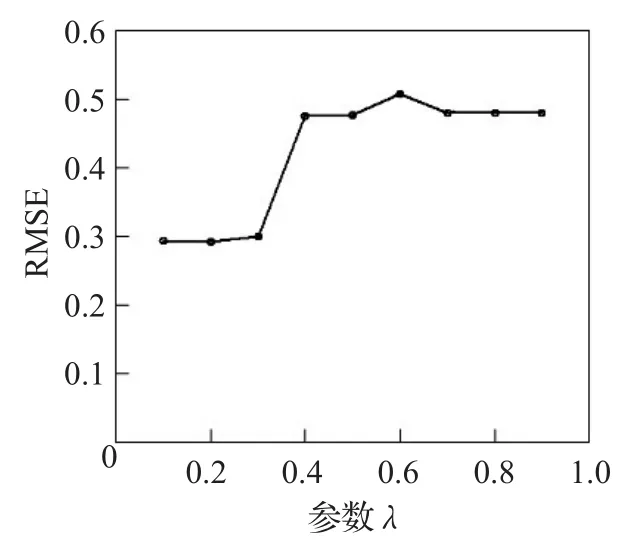
图4 参数λ变化对IPSTS模型的影响
3.3.4 参数φ对IPSTS模型的影响
为了检验参数φ对IPSTS模型的影响,结合上一节实验,邻居数量固定为50,λ取0.2,δ取0.014。
图5显示,当φ取1.0时,RMSE最小。因此,在IPSTS模型中,参数φ取1.0最优。
3.3.5 IPSTS模型对长尾物品的影响

图5 参数φ对IPSTS模型的影响
由图6可知,这些物品存在长尾现象。其中,物品ID越靠前,流行度越高,ItemID在1 000之后的为长尾物品。为检验IPSTS模型对长尾物品的挖掘能力,实验如下:随机选取3个用户,对3个用户分别进行top5(推荐前5个)推荐,用户ID分别为80,800,888。userID为需要进行推荐的用户编号,RecommenderSize=5为推荐列表大小,NeighborSize(邻居数量)=90。Pearson模型中RMSE=0.335 60,IPSTS模型中RMSE=0.329 65。
银行业的发展离不开创新技术的支持,当前银行业要想提升自身的竞争力,同样需要借助新技术的支持与应用。但是,在应用新技术的时候需要能够适应银行的高风险、高收益、运转周期长的特点,并形成一个新型的金融服务方式,以此来促使更多的资金支持技术创新。同时,银行业还需要不断的提升互联网技术的更新,运用人工智能、云技术等现代化的科技来提升银行业的服务效率,降低成本,以此来提升银行业的服务实体经济能力,促使银行业更好的发展。
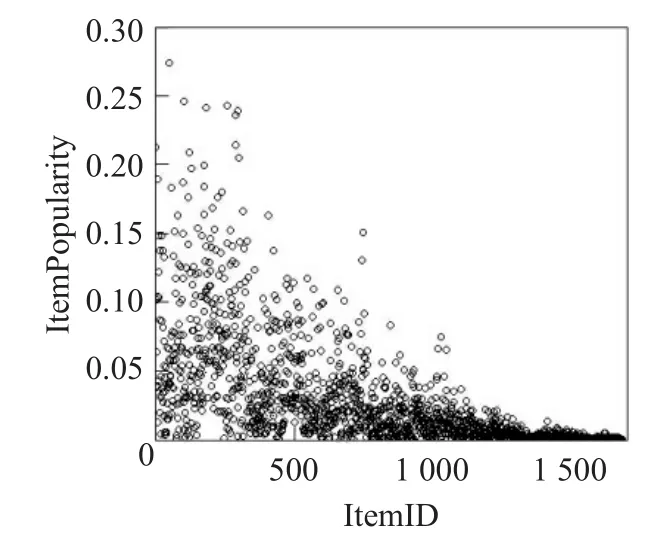
图6 物品ID与物品流行度散点图
表1(ItemID为推荐的物品编号)显示,IPSTS模型在降低了RMSE的基础上,提高了推荐质量的同时,能够挖掘出物品编号为1 467,1 189的长尾物品给用户进行推荐,对长尾现象起到了一定的缓解作用,可以给用户带来惊喜。

表1 userID为80时Pearson模型与IPSTS模型推荐比较
同样,表2(ItemID为推荐的物品编号)显示,采用IPSTS模型相比Pearson模型而言,挖掘出了1 159,1 121,1 103三个长尾物品推荐给用户,能够给用户带来新鲜感。

表2 userID为800时Pearson模型与IPSTS模型推荐比较
表3(ItemID为推荐的物品编号)显示,在给编号为888的用户进行推荐时,IPSTS模型在降低了RMSE的基础上,给用户做出的推荐策略为1 467,1 368,1 512,615,169。其中的前三个物品为长尾物品。但是,Pearson模型不仅均方根误差比IPSTS模型要高,而且给出的推荐策略也没有挖掘出长尾物品。因此,IPSTS模型对长尾现象有所缓解,能够挖掘出长尾物品给用户进行推荐。

表3 userID为888时Pearson模型与IPSTS模型推荐比较
4 结束语
推荐系统是在用户没有明确需求的情况下,从海量的数据中帮助用户寻找感兴趣的信息,进而以合适的方式给用户展现和推荐。本文围绕降低预测评分误差以及挖掘长尾物品问题,引入兴趣稳定性,同时关注时间敏感因子,构建了引入兴趣稳定性的时间敏感相似度融合模型。实验表明该模型能够实现用户兴趣的实时动态推荐,且进一步提高了推荐质量。然而,影响用户兴趣的因素还包括外部环境因素等其他关键因素,随着移动设备的蓬勃发展和定位系统的成熟,可以将这些因素引入到模型中。其次,融合后的模型是线性加权的,下一步还可以考虑构建一个非线性模型进行推荐。
参考文献:
[1]佚名.第36次《中国互联网络发展状况统计报告》[J].网络传播,2015(7):54-59.
[2]Resnick P,Iacovou N,Suchak M,et al.GroupLens:An open architecture for collaborative filtering of netnews[C]//Acm Conf on Computer Supported Cooperative Work,1994:175-186.
[3]邢春晓,高凤荣,战思南.适应用户兴趣变化的协同过滤推荐算法[J].计算机研究与发展,2007,44(2):296-301.
[4]项亮.动态推荐系统关键技术研究[D].北京:中国科学院自动化研究所,2011.
[5]Liu B,Wu Y,Gong N Z,et al.Structural analysis of user choices for mobile app recommendation[J].Acm Transactions on Knowledge Discovery from Data,2016,11(2):17.
[6]Koren Y.Factorization meets the neighborhood:A multifaceted collaborative filtering model[C]//ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Las Vegas,Nevada,USA,August 2008:426-434.
[7]Kim D,Yum B J.Collaborative filtering based on iterative principal component analysis[J].Expert Systems with Applications,2005,28(4):823-830.
[8]Ahn H J.A new similarity measure for collaborative filtering to alleviate the new user cold-starting problem[J].Information Sciences,2008,178(1):37-51.
[9]Liu H,Hu Z,Mian A,et al.A new user similarity model to improve the accuracy of collaborative filtering[J].Knowledge-Based Systems,2014,56(3):156-166.
[10]Li S,Kawale J,Fu Y.Deep collaborative filtering via marginalized denoising auto-encoder[C]//Acm Int Conf on Information&Knowledge Management,2015:811-820.
[11]Wu Y,Dubois C,Zheng A X,et al.Collaborative denoising auto-encoders for top-N recommender systems[C]//ACM International Conference on Web Search and Data Mining,2016:153-162.
[12]Strub F,Mary J,Gaudel R.Hybrid recommender system based on autoencoders[C]//Workshop on Deep Learning for Recommender Systems,2016:11-16.
[13]Wang X,Lu W,Ester M,et al.Social recommendation with strong and weak ties[C]//Acm Int Conf on Information&Knowledge Management,2016:5-14.
[14]Vuurens J B P,Larson M,De Vries A P.Exploring deep space:Learning personalized ranking in a semantic space[C]//Workshop on Deep Learning for Recommender Systems,2016:23-28.
[15]Adomavicius G,Kwon Y O.Improving aggregate recommendation diversity using ranking-based techniques[J].IEEE Transactions on Knowledge&Data Engineering,2012,24(5):896-911.
[16]Herlocker J L.Evaluating collaborative filtering recommender systems[J].Acm Transactions on Information Systems,2004,22(1):5-53.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
疯狂英语·初中天地(2021年11期)2021-02-16
少年漫画(艺术创想)(2019年2期)2019-06-06
知识经济·中国直销(2018年11期)2018-11-26
幽默大师(2018年5期)2018-10-27
小哥白尼(野生动物)(2018年2期)2018-05-25
商用汽车(2016年11期)2016-12-19
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
小天使·一年级语数英综合(2015年8期)2015-07-06
