
面向云数据库服务的隐私字符串加密查询方案
2018-06-01 10:50吴宗大陈恩红徐贯东
计算机工程与应用 2018年11期
吴宗大,江 芳,陈恩红,徐贯东
WU Zongda1,JIANG Fang1,CHEN Enhong2,XU Guandong3
1.温州大学 信息安全研究所,浙江 温州 325035
2.中国科学技术大学 计算机科学与技术学院,合肥 230026
3.悉尼科技大学 工程与信息学院,澳大利亚 悉尼 2007
1.Information Security Centre,Wenzhou University,Wenzhou,Zhejiang 325035,China
2.Computer College,University of Science and Technology of China,Hefei 230026,China
3.Engineering&IT Faculty,University of Technology Sydney,Sydney 2007,Australia
1 引言
随着互联网技术的迅猛发展,云数据库服务作为一种新型的数据服务形式,由于其灵活性高、成本低等优势越来越受到人们欢迎,被广泛地应用于各类企业信息管理系统中[1-2]。然而,不同于传统数据库,云数据库部署在不可信云端,这对企业信息管理系统的各类用户隐私信息(如个人电话号码、身份证号等)构成了严重威胁[3-4]。更重要的是,这种安全威胁无法通过传统的数据库安全策略(如身份认证、授权访问等)解决,也无法通过传统的数据加密技术解决(加密后,定义在隐私数据上的查询操作将无法在密文上执行,即密文查询问题)[5-6]。因此,如何在不影响数据库查询有效性的前提下,保证存储在不可信云数据库中各类隐私信息的安全性,极富挑战。
为了确保云数据库中用户隐私数据的安全性,最自然解决方案就是数据加密。然后,为了解决密文查询问题,可以先对密文解密,再在解密后的明文上查询。然而,这种方案势必会严重降低数据查询效率,严重制约了其实际可用性。传统的同态加密算法[7-8]允许部分查询操作在密文上直接执行,而无需解密数据,但这种技术容易受到统计攻击。此外,研究者还提出了其他的一些数据加密方法以支持密文查询[9-14],但存在安全性差[9-11]或有效性差(即无法支持一些常见的字符串查询)[12-14]等缺点,因而,难以直接运用它们解决云数据库中的隐私数据加密查询问题。最近,文献[15]提出为密文数据建立特征索引,然后,在服务器端通过查询索引以过滤掉绝大部分的非目标元组,较好地解决了查询有效性问题。然而,该工作给出的索引生成方案过于简单,严重降低了方法的灵活性和安全性。本文是该工作的深化和改进。本文重新设计了隐私字符串的索引生成方案,给出了新的查询转换方案,能在不影响查询高效性的前提下,极大地提高方法的灵活性和安全性。
2 加密查询方案
本文采用类似于文献[15]的隐私数据加密查询方案,其总体框架如图1所示。其流程如下:(1)用户通过可信客户端提交明文形式的隐私字符串,由“数据加密部件”对字符串进行加密后,生成密文数据和索引数据并上传至云端数据库;(2)用户通过客户端提交针对明文字符串的原始SQL查询语句时,由“查询转换部件”将原始查询语句转换成可以在索引数据上执行的新查询,提交给云数据库执行,以过滤掉绝大部分的非目标元组;(3)在云数据库返回密文形式的元组集后,由“数据解密部件”解密为明文后存放到临时结果中,再由“数据筛选部件”在临时结果上执行原始查询,从而进一步排除不满足查询条件的元组,返回精确结果给用户。在该模型中,数据加密、解密以及查询转换过程涉及到的各类参数均存放在可信的客户端中。从图1可以看出,设计合理有效的字符串索引方案(应用在数据加密部件),以及将定义在明文上的原始查询转换为定义在索引上的新查询(应用在查询转换部件),是影响云数据库查询效率的关键因素。本文的后续内容将主要围绕特征索引方案以及查询转换方案两部分展开。
2.1 数据存储方法
为了在云数据库中存储隐私字符串对应的密文数据和索引数据,需要改造原有关系表。假设在云数据库中存在关系表R(A1,A2,…,Ar,…) ,其中,Ar是存储隐私字符串的隐私字段,则改造后的加密关系表为,其中:(1)RE中新增的密文字段(其类型为二进制型)用于存储由R中整个元组加密后得到的密文数据;(2)RE中新增的索引字段用于存储对应隐私字段A的索引数据(其类型与r隐私字段Ar保持一致,一般为变长字符串型);(3)RE中其余字段与R中的原有字段保持一致(但删除隐私字段 Ar)。
2.2 数据索引方法
根据图1所示,当用户通过客户端向云数据库提交一条元组时,“数据加密部件”首先会对元组进行加密,同时为元组里隐私字符串构建索引。这里,元组加密使用传统加密算法完成(如AES)。传统加密算法已经非常成熟,可以很好地保护密文的安全性。本文不再讨论数据加密算法本身,而主要讨论的是如何为隐私字符串构建特征索引。
对于给定关系表R的隐私字段Ar(其数据类型为可变字符串型),假定字段的最大长度为nr。一般化地,给定定义在隐私字段Ar上的任意字段值ar。以下研究如何将明文形式的字段值ar映射为索引值ax,记作ar⇒ax。该过程共需要4个步骤,其中,前面3个步骤在元组提交之前预先设置完成,最后1个步骤在元组提交之后在线完成。
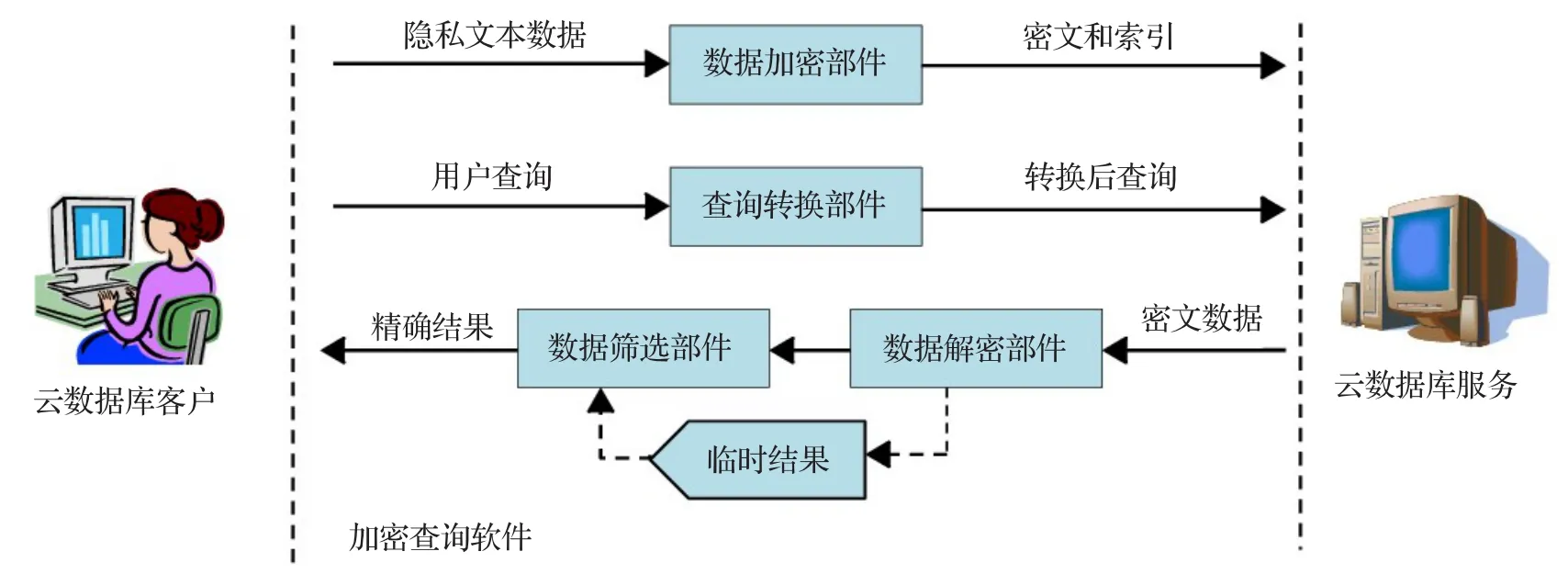
图1 云数据库隐私数据加密查询方法的总体框架
步骤1将最大长度为nr的隐私字段Ar划分为m个子字段,记作:B1,B2,…,Bm(1 ≤m≤nr),并且这些子字段满足以下3个条件。
(1)任一子字段均不为空集,即任一子字段的长度均不为零,即
(2)各个子字段互不相交,即
(3)各个子字段的并集等于隐私字段Ar,即
步骤2对步骤1分段得到的各个子字段Bk(i=1,2,…,m)的值域(即子字段各个字符单位所有可能取值所构成的集合)进行分区。假设任一子字段Bk的值域为domain(Bk),且被分成nk个分区,分别记作:,,…,,这些分区满足以下4个条件。
(1)任一分区均不为空集,即
(2)各个分区互不相交,即
(3)各个分区的并集等于该子字段Bk的值域,即
(4)各个分区中任意元素的值均大于其相邻分区中所有元素的值。该条件可形式化表示为
步骤3为各个子字段Bk的各个分区,,…,分别分配一个互不相同的唯一标识字符,记作id),即
基于步骤2和步骤3的设定,给定子字段Bk的任一具体值b,均可被映射为一个标识符id),其中k,即确定了一个映射函数,记作Xk(bk)。
步骤4给定定义在隐私字段Ar上的任意值ar,基于步骤1的设定,假定它覆盖了隐私字段Ar的n个子字段B1,B2,…,Bn(1 ≤n≤m ),并且假定它对应于各个子字段的取值分别是b1,b2,…,bn,即ar=b1b2…bn。那么基于步骤2和步骤3,可将ar映射为一个新的字符串,记作ax=X(ar)=X1(b1)X2(b2)…Xn(bn),作为其索引值。
例子1假设隐私字段Ar为“手机号码”。手机号码一般有11位字符构成,其中,前2位只能是13、15、17或18,剩余的9位可以为字符0至9的任意取值。首先,步骤1将隐私字段Ar划分成若干个子字段。假定步骤1将隐私字段划分成3个子字段(即m=3),且| B1|=3,|B2|=4,| B3|=4。然后,步骤2将对各个子字段进行分区。假定子字段B1被划分2个分区,B2被划分10个分区,B3被划分20个分区,分别如下:

接着,步骤3为各个子字段的各个分区分配标识字符。假定分区标识符分别如下:
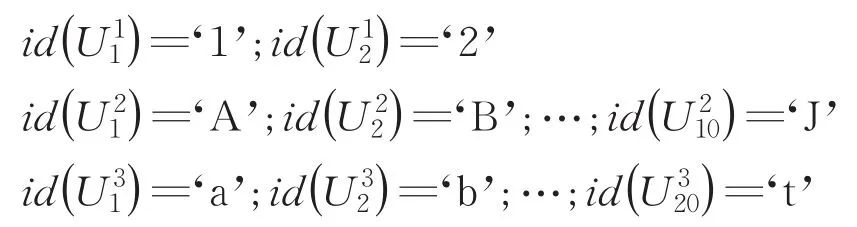
以上3个步骤预先离线设置完成。最后,对于用户通过客户端提交的定义在隐私字段Ar上的任意值ar,步骤4将其映射为一个索引值ax。假定ar=‘155 6123 4890’,则基于步骤1至步骤3的设定,映射得到索引值ax=X(ar)=‘1Gj’。
2.3 查询转换方法
根据图1所示,当用户在客户端提交数据查询语句时,“查询转换部件”负责将定义在隐私字段上的原始查询转换为定义在索引字段上的新查询,并且要求:新查询的执行结果必须是原始查询结果的超集(即新查询返回的元组集合必须包含所有的目标元组)。字符串相关的查询条件主要包括:精确查询、模糊查询和范围查询。为此,本文针对这三种查询条件给出相应的转换方法,将定义在隐私字段上的原始查询条件转换为定义在索引字段上的新查询条件,以使得它们能够在云数据库上正确执行。
(1)精确查询转换。其表示形式一般为:R.Ar=a,其中a表示字符串常量,Ar为隐私字段。基于步骤1的设定,假定字符串常量a覆盖了n个子字段(1 ≤n≤m ),并假定它对应于各个子字段的值分别为b1,b2,…,bn,即a=b1b2…bn,则精确查询条件转换如下:
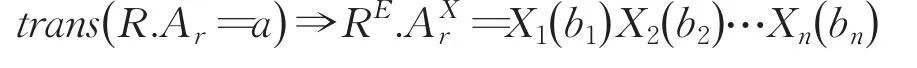
(2)模糊查询转换。模糊查询条件建立在谓词“LIKE”的基础之上,其一般语法格式为:LIKE<匹配字符串>,其中,匹配字符串可以含有通配符“%”、“_”或“[]”。以下分别讨论基于三种通配符的模糊查询条件转换。
①基于通配符“%”的模糊查询转换。“%”代表匹配任意长度字符串。以下先考虑“%”位于右边的情况,此时模糊查询条件的一般形式为:R.ArLIKE a%。基于步骤1的设定,假定字符串常量a靠左完整覆盖了n个子字段B1,B2,…,Bn(1 ≤n≤m ),假定它对应于各子字段的值分别为b1,b2,…,bn,则模糊条件转换如下:
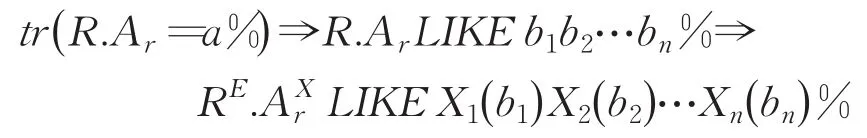
当通配符“%”位于左边时,即R.ArLIKE%a。基于步骤1的设定,假定字符串常量a靠右完整覆盖了(m -i+1)个子字段Bi,Bi+1,…,Bm(1 ≤i≤m ),并假定它对应于各个子字段的值分别为bi,bi+1,…,bm,则模糊查询条件转换如下:
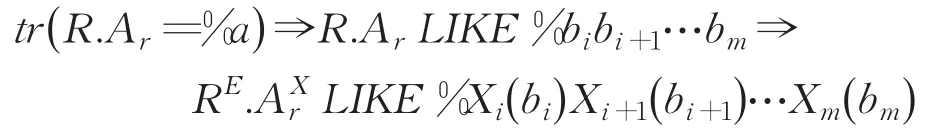
②基于通配符“_”的模糊查询转换。“_”代表匹配一个任意字符,此时模糊查询条件的一般形式为:R.ArLIKE a_b,其中,a和b为字符串常量。假定字符串a_b完整覆盖了n个子字段B1,B2,…,Bn(1≤n≤m),其中,Bi(1≤i≤n)为包含通配符“_”的子字段。并假定a_b对应于子字段B1,B2,…,Bi-1的值分别为b1,b2,…,bi-1,对应于子字段Bi+1,Bi+2,…,Bn的值分别为bi+1,bi+2,…,bn,则模糊查询条件转换如下:
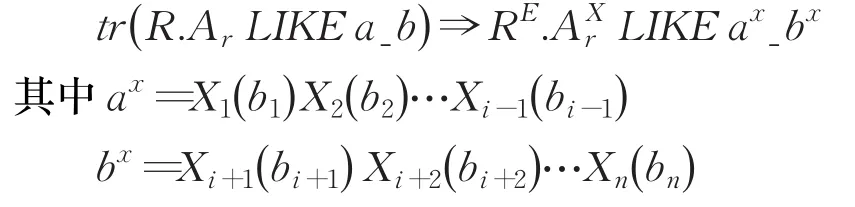
③基于通配符“[]”的模糊查询转换。“[p]”表示匹配列表p里的一个字符,此时模糊查询条件的一般化形式为:R.ArLIKE a[p]b(a、b、p均为字符串)。若p=p1p2…pt,则模糊查询条件可基于精确查询条件来完成,转换如下:
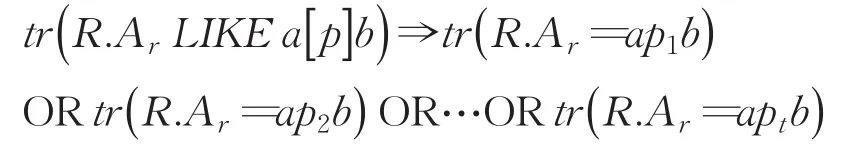
(3)范围查询转换。范围查询条件的一般形式为:R.Ar≥a。基于步骤1的设定,假定字符串常量a完整覆盖了n个子字段B1,B2,…,Bn(1 ≤n≤m ),并假定它对应于各个子字段的值分别为b1,b2,…,bn。记子字段Bi的最大取值为,记next(bi)为 Bi中大于bi的最小取值。那么,对于不小于a的任意字符串a′=b1'b2'…bz'(1 ≤z≤m ),它必定满足条件:(n ext(b1)≤b1');或 (b1=b1'∧next(b2)≤b2');…;或 (b1=∧b2=∧…∧bk-1=∧next(bk)≤),其中,k=max(n,z)。基于以上分析,范围查询条件可基于相似查询条件来完成,转换如下:
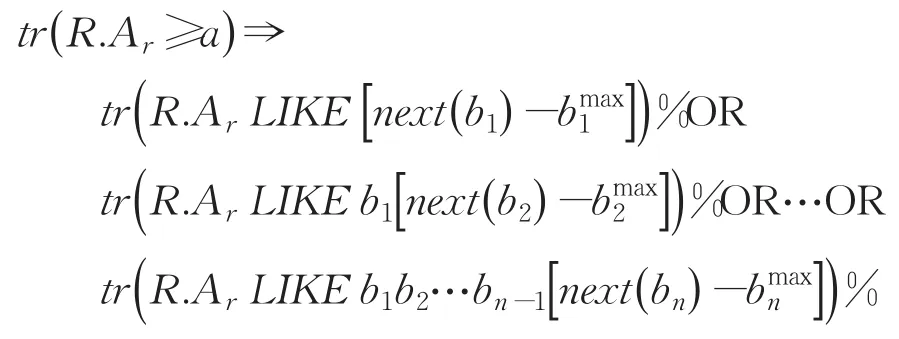
以上,针对三类常见的字符串查询条件分别给出了对应的查询转换方法。可以看出,云数据库中的任意元组,如果它满足转换后的查询,则它解密后必然满足转换前的查询(即新查询条件是原查询条件的必要条件)。当用户通过客户端提交查询语句时,“查询转换部件”分析用户查询中的基本查询条件,将定义在隐私字段上的基本查询条件转换为定义在索引字段上的新查询条件,从而生成可以在加密云数据库上正确执行的新查询。然后,再将转换后的新查询提交给云数据库执行。最后,由“数据解密部件”解密云数据库返回的查询结果,由“数据筛选部件”在查询结果上执行原始查询,从而进一步过滤掉非目标元组,获取精确结果,返回给用户。
3 安全性分析
传统加密算法可以保证密文的安全性,所以只讨论索引的安全性,即基于索引方法生成的索引数据,攻击者能否分析出相应的明文字符串或相关的敏感信息。将对比文献[15]的方法(下文称作:简单分区法)来分析本文方法(下文称作:复合分区法)的安全性。
在简单分区法中,隐私文本字段的各个单位字符的值域将被统一划分(如“手机号码”字段的单位值域被划分为如下5个分区:{0 ,1}、{2 ,3}、{4 ,5}、{6 ,7}和{8 ,9}),然后,为每个分区设定标识符(假设分别为:A、B、C、D和E),最后,将隐私字符串映射为相应索引值(如“155 6123 4890”将被映射为“ACC DABB CFFA”)。
分析1两种索引方法均能很好地抵抗常见攻击,拥有较好的安全性。不论是简单分区法还是复合分区法,从明文字符串到索引字符串之间的映射是一种“多对一”映射(即一个索引值对应多个明文值),因此,即使利用攻击方法(如统计攻击、已知明文攻击等)获知了映射函数,也难以根据索引值获知相应的明文。此外,还可以看出,各个分区包含的字符越大(即分区规模越大),则一个索引值对应的明文值就越多,从而索引的安全性也就越好。为此,为了获取更好的安全性,可以适当提高方法步骤2中的各个分区的规模。
分析2相比简单分区法,复合分区法拥有更好的安全性。对于简单分区法,虽然难以根据索引值获知具体的明文值,但是攻击者还是可以根据索引值获取一些明文的相关敏感信息,例如,可以获知明文的长度(索引值与明文值具有相同的长度)。对于复合分区法,由于步骤1的子字段划分,避免了这个问题。此外,相比于简单分区法,攻击者更加难以获知复合分区法所构建的索引映射函数。例如,对于电话号码的例子,根据已知明文攻击法,攻击者最少只需要知道5个从明文到索引的二元映射组,就可以获知简单分区法的映射函数,而对于复合分区法,由于各个子字段独立分区(即分区各不相同),攻击者需要知道大量的明文及其相应的索引值,才可能获知映射函数。

表1 相似查询条件和范围查询条件
分析3相比简单分区法,复合分区法拥有更好的灵活性。可以看出复合分区法是简单分区法的深入扩展。如果步骤1将各个子字段的长度均设置为1,步骤2对所有子字段均采用统一的分区划分方案,则复合分区法得到的索引映射函数将与简单分区法的一致。相比于简单分区法,复合分区法拥有更好地灵活性,能更好地满足实际的应用需求。例如,对于电话号码字段,虽然每个字符单位均拥有相同的值域(均是从0到9),但实际上它们的取值却并不一致(如第一位字符只能是1)。在复合分区法中,步骤1让用户可以根据实际需要先进行子字段划分,从而使得每个子字段均可拥有相似规模的值域。此外,在复合分区法中,用户还可以根据需要,将敏感的子字段划分粗些,以获得更好地数据安全性,将不敏感的子字段划分细些,以获得更好的查询高效性。
4 高效性评估
前文展示了基于本文的索引方案,定义在字符串型隐私字段上的各类查询条件均可有效地转换为索引字段上的新查询,使得它们可以在加密云数据库上正确执行,即本文索引方案拥有很好的查询有效性。以下,将实验评估本文方案的查询高效性,即评估查询转换得到的新查询能够过滤绝大部分的加密云数据库中的非目标元组,以提高查询效率。
4.1 实验设置
首先,构造实验数据库,随机生成一百万条元组,其中敏感字段由11位数字字符构成的电话号码;然后,在两台电脑上进行实验,其中一台作为云数据库服务器,另一台作为客户端,其配置为:Intel I7 4510U CPU+8 GB内存+1 TB硬盘。此外,操作系统为Win 7(64位),数据库系统为MySQL。从图1所示的数据查询过程可以看出,索引方案的查询高效性,表现在转换得到的新查询对加密云数据库中非目标元组的过滤效果。这里采用文献[9]的过滤效果衡量公式:,其中,表示满足用户查询的元组数量,R′2表示满足转换生成的新查询的记录数量,R表示与用户查询相关的数据表规模大小。Fr的取值范围从0到1,并且其值越大表示对非目标元组的过滤效果越好。索引方案采用例子1的设置。表1给出了实验中涉及的基本相似查询和基本范围查询,其中B1表示三个数字字符,B2和B3表示四个数字字符,它们分别对应一个隐私子字段值。
4.2 评估结果
第一组实验评估基本相似查询条件的高效性。实验中,让每个索引值对应的可能明文值数量持续增长变化(记作K值),从25增长到215(K值可通过设定索引方案的步骤1和步骤2相关参数来完成),实验结果如图2所示(其中,横坐标表示K值,纵坐标为Fr值)。基于图2的实验结果,有以下几个观察。(1)随着K值的持续增长,Fr值将持续变小,即新查询条件对非目标元组的过滤效果将随之变差。因为,随着K值的增长,不同电话号码被映射为相同索引值的概率将变大,从而使得非目标元组在云端被过滤掉的概率也随之变小,即使得Fr值随之变小(最极端情况下,如果所有的电话号码都被映射为相同索引值,此时索引对非目标元组的过滤效果最差,即Fr=0)。(2)基于本文的索引方案,大部分的非目标元组将在服务器端被过滤掉(过滤比率基本大于0.9,即使K值被设置为较大的时候),从而极大地降低了返回客户端的密文元组规模,即降低了网络通讯开销,减小了客户端的数据查询规模,从而极大地提高了相似查询效率。(3)不同信息量的相似查询条件会导致不同的Fr值变化趋势,即相似查询条件相关的匹配字符串常量包含的信息量越多,则Fr值也随之变大(相同K值设定下,F1小于F2,F2小于F3)。这是因为,相似查询条件包含的信息量越大,通常返回客户端的元组规模就越少,从而增加Fr值。

图2 基本相似查询条件的高效性评估结果
第二组实验评估基本范围查询条件的高效性。实验结果如图3所示。基于图3的实验结果,有以下几个观察。(1)通过使用索引方案,大部分的非目标元组将在服务器端被过滤掉,从而降低了返回客户端的密文元组规模,减小了客户端的数据查询规模,极大提高了范围查询效率。(2)随着K值的持续增长,新查询条件对非目标元组的过滤效果将随之变差。综合以上,可以看出:对于绝大多数的相似查询和范围查询,90%以上的非目标元组均能在服务器端被过滤掉。因为加密而导致的用户查询效率的下降比例,近似地反比于服务器端对非目标元组的过滤比例。因而,索引方案具有很好的查询高效性,能有效地降低数据查询开销。最后,需要指出,简单分区法与本文方法拥有一致的查询高效性,为此本节不再重复给出简单分区法的高效性实验评估结果。

图3 基本范围查询条件的高效性评估结果
5 结论
本文面向云数据库的字符串型隐私数据的加密查询问题,提出了一个有效解决方案。该方案核心是加密索引方法和查询转换方法,不仅能够确保隐私字符串在不可信云端的安全性,还能够确保用户查询操作的高效性。理论分析和实验评估验证了方案的实际效用:(1)安全性,即难以根据索引数据获知字符串的敏感信息;(2)有效性,即能够支持常见的字符串查询条件(包括相似查询和范围查询);(3)高效性,即能在云端过滤掉绝大部分的非目标元组,极大地提高数据查询效率;(4)灵活性,即能够根据字符串的分布情况,灵活设置相关参数,协调安全性和高效性。
参考文献:
[1]束柬,梁昌勇,陆文星,等.基于云的企业管理信息系统再造研究综述[J].情报学报,2015(5):549-560.
[2]王柠,刘国华,赵春红,等.一种适用于外包数据库的综合密文索引技术[J].小型微型计算机系统,2010(9).
[3]Bharath K,Samanthual,Wei Jiang.Efficient privacy-preserving range queries over encrypted data in cloud computing[C]//2013 IEEE Sixth International Conference on Cloud Computing,2013.
[4]Zhang Wei,Lin Yaping,Xiao Sheng,et al.Privacy preserving ranked multi-keyword search for multiple data owners in cloud computing[J].IEEE Transactions on Computers,2016,65(5):1566-1577.
[5]崔宾阁,刘大昕,王桐.支持快速查询的数据库加密方法的研究[J].计算机科学,2006,33(6):115-118.
[6]Li J,Wang Q,Wang C,et al.Fuzzy keyword search over encrypted data in cloud computing[C]//Proc of the 31st Conference on Computer Communications.New York:ACM Press,2012:1-5.
[7]Domingo F J.A new privacy homomorphism and applications[J].Information Processing Letters,1996,60(5):277-282.
[8]Chung S S,Ozsoyoglu G.Anti-tamper databases:Processing aggregate queries over encrypted databases[C]//Proc of the 22nd International Conference on Data Engineering Workshops.Atlanta,GA,USA:IEEE Computer Society,2006.
[9]Wu Z,Xu G,Zong Y,et al.Executing SQL queries over encrypted character strings in the database-as-service model[J].Knowledge-Based Systems,2012,35:332-348.
[10]Wang Z,Dai J,Wang W,et al.Fast query over encrypted character data in database[J].Communications in Information and Systems,2004,4(4):289-300.
[11]俞志斌,周彦晖.基于关键字的云加密数据索引保护检索[J].计算机科学,2015,42(6A):365-369.
[12]Fu Zhangjie,Sun Xingming,Xia Zhihua,et al.Multi-keyword ranked search supporting synonym query over encrypted data in cloud computing[C]//Performance Computing and Communications Conference(IPCCC),2013:1-8.
[13]Xu Zhiyong,Kang Wansheng,Li Ruixuan,et al.Efficient multi-keyword ranked query on encrypted data in the cloud[C]//2012 IEEE 18th International Conference on Parallel and Distributed Systems(ICPADS),2012:244-251.
[14]Cao Ning,Wang Cong,Li Ming,et al.Privacy-preserving multi-keyword ranked serach over encrypted cloud data[J].IEEE Transactions on Parallel and Distributed Systems,2014,25(1):222-233.
[15]卢成浪,刘明雍,吴宗大,等.针对网络信息系统的个人隐私保护方案[J].小型微型计算机系统,2015,36(6):1291-1295.
猜你喜欢
电脑报(2021年14期)2021-06-28
无线互联科技(2020年11期)2020-12-01
计算机与生活(2019年5期)2019-07-18
吉林大学学报(理学版)(2018年2期)2018-03-29
民间故事选刊·上(2018年1期)2018-01-02
小小说月刊·下半月(2016年6期)2016-05-14
中国资源综合利用(2016年11期)2016-01-22
燕山大学学报(2014年1期)2014-03-11
电信科学(2013年10期)2013-08-10
测绘科学与工程(2013年6期)2013-03-11
