
基于自适应性分类器的垃圾邮件检测
2018-05-30 01:26梁意文谭成予
计算机工程 2018年5期
陈 龙,梁意文,谭成予
(武汉大学 计算机学院,武汉 430072)
0 概述
近年来,垃圾邮件泛滥给人们的通信造成很大的困扰和不便,其不仅消耗通信带宽和网络资源,且浪费人们的处理时间,因此,对垃圾邮件进行检测很有实际意义,但是,垃圾邮件越来越容易伪装成正常邮件而绕过检测,其中新型垃圾邮件的检测更是成为一大难题。
目前,垃圾邮件检测技术分为2类:基于知识工程的方法和基于机器学习的方法[1]。基于知识工程的方法主要包括黑名单白名单[2]、灰名单[3]等,其利用已知规则鉴别垃圾邮件。该方法主要依赖于对当前发件人身份的识别[4],优点是鉴别准确率高,缺点是需要人为频繁更新规则,不易于维护。基于机器学习的方法兴起于20世纪90年代末期,主要包括朴素贝叶斯[5]、支持向量机(Support Vector Machine,SVM)[6]、人工神经网络[7],该方法通过样本训练集生成分类器以对垃圾邮件进行识别,优点是其独立于知识库,无需经常更新,缺点是效果优劣完全依赖于训练集,只有测试邮件跟训练集的正常邮件和垃圾邮件训练样本形式匹配时才能正确分类。但是,目前垃圾邮件的伪装技术愈加成熟,因此,分类器对伪装邮件的正确识别成为影响垃圾邮件检测准确率的重要因素。
本文受生物免疫系统多层防御机制、自适应性强的启示,结合反向选择算法(Negative Selection Algorithm,NSA)和SVM,设计一种新的自适应性分类器,将其应用于垃圾邮件检测。该分类器对邮件进行预检验并快速区别出能匹配检测模型的“正常邮件”和垃圾邮件,然后结合反向选择的自适应性对该“正常邮件”进行二次检测,得到最终的正常邮件和新型垃圾邮件,同时计算出最初最优超平面模型得到的垃圾邮件检测率和正常邮件准确率,最后根据正常邮件和垃圾邮件集合去自适应调整初始化的最优超平面方程,直至垃圾邮件的检测率和正常邮件的准确率趋于稳定,此时,分类器对当前的邮件分类达到最优。
1 垃圾邮件检测方法
文献[8]将计算机系统的安全保护比喻成学习鉴别“自我”“非我”的问题,其基于生物免疫系统的T细胞生成机制,提出一种变化检测的NSA,并且阐明该方法在计算机病毒检测方面的可行性。
文献[9]首次将计算机免疫应用于垃圾邮件检测,将“自我”当成正常邮件,“非我”比喻成垃圾邮件,借鉴抗体匹配抗原的思想随机生成垃圾邮件检测器,且在系统运行过程中建立权值和阈值的评价体系,其中匹配次数多的检测器其权值较大,通过将检测器的权值和与阈值进行比较来判断邮件类别。
文献[10]针对垃圾邮件重复性(每个邮件服务器的众多用户都会收到相同的垃圾邮件)和迷惑性(不断改变垃圾邮件的特征关键词来绕过垃圾邮件过滤器,但是该改变不会偏差太大)的共性,无需先验信息,仅借鉴NSA来进行垃圾邮件检测。该算法包含随机检测器生成、检测器成熟、抗原匹配和检测器老化4个并行的工作模块,以及自我库和检测器库2个库。在系统学习垃圾邮件模式的1/3阶段,垃圾邮件检测率就超过80%,该方法大多情况下检测率都超过70%。
文献[11]结合神经网络与NSA对垃圾邮件进行区分。先将已去重的检测集划分为“自我”和“非我”,然后将由“自我”和“非我”浓度向量生成的特征向量作为神经网络分类器的输入,分类找出程序的“自我”“非我”特征向量。神经网络和人工免疫的结合,提高了垃圾邮件检测率,且使得该两种不同的检测器在统一的平台上获得高效的运行性能。
文献[12]受NSA的启发,改进差分优化方法(NSA-DE),将其用于垃圾邮件检测。该算法在随机检测器的生成阶段使用局部差分进化,将局部离群系数作为适应函数,求解检测器和非垃圾邮件在空间上的最大距离。理论分析和实验结果均表明,相比标准的NSA,NSA-DE性能较高。
文献[13]基于增量SVM和人工免疫(克隆选择)的思想,针对邮件流的垃圾邮件检测提出不间断检测的方法。该方法使用滑动窗口标注邮件,追踪邮件内容和用户兴趣的动态变化,其中一封新邮件的最终标签由多数表决判定。滑动窗口被用来清除过时信息,其包含的分类器动态更新采用超边际分析技术。在其不间断的检测过程中,使用8种不同的方法,本文选取3个基准数据集对该8种方法分别就正确率、精确率、召回率、失误率和速度5个指标进行比较,结果表明该8种方法在垃圾邮件检测的实际应用中具有良好的性能。
目前,由于自身的局限性,单一检测方法不能很好应对垃圾邮件内容形式多变的特性,因此越来越多的混合方法被提出以解决垃圾邮件检测问题[14]。混合方法综合了多种单一方法的优势,规避其不足,在性能方面有明显的提升。本文正是将NSA和SVM进行结合,提出一种基于自适应性分类器的垃圾邮件检测方法。
2 自适应性检测模型
2.1 反向选择算法
NSA最初在1994年被提出,该算法模仿人工免疫的反向选择过程,随机产生检测器,将检测到“自我”的检测器清除,保留能正确检测“非我”的检测器。该算法包含数据表示、训练阶段和测试阶段。数据一般用二进制或实值表示,训练阶段(也称探测器生成阶段)利用既定的训练算法随机生成探测器,测试阶段通过评估探测器是否会匹配正常邮件来确认探测器是否成熟,如果能匹配正常邮件,则丢弃该探测器,反之,说明该探测器已成熟,可以投入使用。图1和图2分别展示了NSA应用在垃圾邮件检测中的训练过程和测试评估过程。

图1 NSA训练过程

图2 NSA测试过程
NSA能够根据“自我”来辨别“非我”,如果正常邮件样本足够多,该算法就能根据外来邮件与成熟检测器是否匹配来判断邮件是否为垃圾邮件。
2.2 支持向量机
SVM于1995年首次被提出,其建立在统计学习理论的VC维理论和结构风险最小原理的基础上,根据有限的样本信息,在模型的复杂性(即对特定训练样本的学习精度)和学习能力(即无错误地识别任意样本的能力)之间寻求最佳平衡,以获得最好的推广能力(或称泛化能力)。
如图3所示,SVM利用已知的正常邮件和垃圾邮件样本,用其训练出检测模型并使用该模型去鉴别其他邮件。

图3 SVM垃圾邮件检测模型
SVM垃圾邮件检测方法的缺陷在于垃圾邮件形式多变,而检测模型却固定不变,因此,该方法只能检测出与模型相匹配的垃圾邮件。
2.3 自适应性垃圾邮件检测模型
本文借鉴上述2个算法的思想,建立如图4所示的自适应性垃圾邮件检测模型。对准备好的公有实验数据集进行特征降维,利用现有的数据抽样分别生成基于SVM的最优超平面方程和基于NSA的成熟检测器模型。输入的测试邮件先经过最优超平面以判定其是否为垃圾邮件,若是,则将该邮件放入垃圾邮件集合;若不是,则开始第二轮成熟检测器的判定,如果不能匹配成熟检测器,则将该邮件放入正常邮件集合;反之,将其放入垃圾邮件集合。最后结合2轮得到的垃圾邮件和正常邮件集合,更新初始的邮件样本,动态调整最优超平面方程以适应新型垃圾邮件的检测,直至该检测器的正常邮件准确率和垃圾邮件检测率都趋于稳定,停止更新。

图4 自适应性垃圾邮件检测模型
自适应性检测模型第1层使用检测精度高、高维模式识别效果佳的SVM分类超平面进行过滤,该层的目标是尽最大可能将与样本集特征匹配的正常邮件和垃圾邮件区分到其应属的集合,存在的问题是机器学习算法具有无法有效检测新型垃圾邮件的固有缺陷,因此,在该层中,会有较多的新型垃圾邮件被错误归类在模型所输出的“正常邮件”集合中;第2层使用NSA对第1层的“正常邮件”进行二次过滤,这是一个自适应的过程,开始时可能由于样本数量少,检测的新型垃圾邮件不多,但是随着样本数量的补充,“自我”集合(正常邮件集合)越来越丰富完备,检测出的新型垃圾邮件会越来越多。通过上述2次检测,能够有效减少垃圾邮件漏报率,提升整体分类效果。下文还提出运用NSA检测的新型垃圾邮件增量,更新原有的样本训练集从而更新SVM的分类超平面,通过优化SVM模型以提升该方法的检测效果。
2.3.1 邮件预处理
邮件预处理阶段是对数据集中的邮件进行初步加工,将邮件内容转化为后续模型易处理的标准形式,一般是将每封邮件处理成一个固定维数的邮件向量。该阶段主要包括文本分词、去除停用词和词汇还原3个步骤。
1)文本分词。数据集是英文邮件,文本分词将每封邮件的内容分解成一个包含很多单词的数组(允许数组有多个相同单词),其主要方法是根据单词分隔符(包括空格、符号、段落)将每封邮件的文本内容分割成各个独立的单词。
2)去除停用词。停用词是一些高频出现但是不重要的词,如“a”“an”“and”等。因为停用词会对邮件关键词的特征选取造成影响,所以需根据已收录的停用词表将邮件中出现的停用词进行去除。
3)词汇还原。也称词干提取,是针对英文单词的特有处理。有些单词在单复数、时态间进行转变,但是在计算相关性时,其应该当作同一个单词来处理。如“creat”“created”“creating”都应该还原成同一个单词“creat”来处理。词汇还原的目的是将该不同类型的词还原为同一个单词。
2.3.2 邮件表示
当数据集里的邮件经过预处理后,每封邮件都可以看成是一个单词列表,其主要包含主题、正文内容和收发件人等关键信息。本文将邮件数据集中出现的每个单词都当成邮件的一个特征,因此,每封邮件都可以由一个包含多个单词的特征向量来表示。
常用的特征提取方法包括二进制表示、TF-IDF(Term Frequency-Inverse Document Frequency)[15]、TF(Term Frequency)、DF(Document Frequency)[16]等。本文采用二进制的方法表示邮件的特征向量。如果Wi表示邮件的任意一个单词,则邮件可以表示为Mail=(W1,W2,…,Wm)(m表示特征向量的个数,即单词的总个数)。Wi的取值为0或1,1代表该单词出现在邮件中,0则反之。
2.3.3 特征降维
当数据集中的邮件经过文本处理后,每封邮件都可以看成一个单词列表,不同邮件同一单词的频率、位置、区分性大不相同,该单词根据不同的特征选择机制,分别计算其对文本的影响强度值,并进行排名,强度值大于阈值的词汇被选取为特征词,反之,则丢弃。该过程根据单词的重要程度(垃圾邮件和正常邮件的可区分度)将所有的单词进行排序,选取重要程度高的单词作为邮件特征关键词,并开始特征表示阶段。如果没有词筛选这一阶段,单词数量过多,特征不明显且杂乱的情况下,不仅会因为特征维度高而造成维度灾难,且无法选取有效的特征准确区分正常邮件和垃圾邮件,从而影响后续分类效果。通过词筛选这一阶段,一方面可以减少区分度较差的单词,降低其带来的不良影响,另一方面可以降低特征维度,减小计算复杂度。
在大多数文档中经常出现的特征,无法区分文档,而很少出现的单词,在分类过程中不能给予人们足够多信息[17],因此,本文采用的方法是丢弃在邮件数据集中出现频率达95%以上和5%以下的特征[18]。
2.3.4 自适应性分类器
分类器的设计主要涉及SVM的分类平面和NSA的检测器2个模块。图5所示为SVM求解线性可分问题的最优分类线示意图。

图5 SVM最优分类线示意图

NSA模块中,初始化随机生成的检测器与“自我”集合(本文指正常邮件)进行匹配,如果能匹配,则删除该检测器进行重新生成,如果未能匹配,则将其进化为成熟检测器。本文选取的是简单通用的r连续位匹配规则[20],具体步骤为:首先初始化随机生成二进制形式的未成熟检测器d,然后将该检测器与“自我”集合S的所有个体逐一匹配,如果存在至少一个个体Sk与检测器连续对应的r位相同,则认为该检测器与样本匹配,删除该检测器;否则,将该检测器加入成熟检测器集合D中[21]。
图6所示为自适应性分类器结构框架,从邮件数据集中抽样的样本经过SVM[22]和NSA[23]的并行计算,分别生成最优超平面和成熟检测器,经过最优超平面筛选出正常邮件,将其与成熟检测器进行匹配,如果能匹配,说明该邮件是最优超平面检测漏报的垃圾邮件;反之,则为正常邮件。最后将这些邮件检测结果重新反馈到样本集中,调整生成新的最优超平面。循环上述过程,直至最优超平面的分类效果趋于稳定,此时得到的最优超平面方程则是根据当前的测试输入邮件得到的最佳分类选择。

图6 自适应性分类器结构框架
3 实验结果与分析
3.1 实验设计
本文实验数据集是Ling-Spam,其中包含2 893封电子邮件,分别存储在10个文件夹中,垃圾邮件总计481封[24]。所有邮件都去除了Html标签,只剩下主题和正文,内容全是文本类型,无图片和附件。该数据集有4种不同的类型,每种类型的邮件总数和垃圾邮件数量一样,本文选取的是已经进行词汇还原和停用词去除的集合,其中选取任意9个文件夹的邮件数据作为训练集,另一个作为测试集。
对实验数据进行分析,随机抽取文件夹中的垃圾邮件进行抽样观察,发现文件夹1~文件夹9中垃圾邮件样本的形式大多类似,如图7所示,这些垃圾邮件常常包含call、percent、profit、www、discount等关键词。

图7 文件夹1~文件夹9垃圾邮件样本
文件夹10的垃圾邮件如图8所示,其比较隐蔽,如正文中很少提到的“商品”和“折扣”等信息,但其会通过将free扩展为freedom、将Web替换为W-e-b等方式来逃避关键词过滤。

图8 文件夹10垃圾邮件样本
本文选取的实验指标包括垃圾邮件召回率、精确率和正常邮件的召回率、精确率以及准确率。最终,本文将文件夹1~文件夹9的垃圾邮件视为旧垃圾邮件,文件夹10的垃圾邮件看成新型垃圾邮件。
3.2 结果分析
本文实验分为3组,每次选取Ling-Spam数据集中的一个文件夹数据作为测试集,其他数据作为训练集。第1组用原始的SVM方法测试该数据集;第2组用原始的NSA方法测试该数据集;第3组用本文自适应性分类模型来进行实验。每组实验重复10次,取平均值作为参考依据。
第1组实验结果如表1所示,其中第10次实验以文件夹1~文件夹9的邮件为训练集,文件夹10的邮件为测试集。

表1 SVM垃圾邮件检测结果 %
由表1可以看出,在10次实验中,正常邮件的召回率和精确率普遍较高,基本都在95%以上,这是因为正常邮件的形式比较固定,所以经过样本训练出来的检测模型能较为准确地识别出正常邮件。而第10次实验数据比较异常,其原因是文件夹10中的邮件(如图8所示的样例)没有预先抽取样本参与到检测模型的生成中,因此,检测模型不能很好地模拟新型垃圾邮件的特征,导致在实验中垃圾邮件的召回率和精确率普遍较低,甚至出现无法识别该类邮件的极端情况。实验结果还表明,SVM对现有垃圾邮件的识别率较高,但是对新型垃圾邮件的识别率较低。
第2组实验结果如表2所示。由表2可以看出,NSA检测正常邮件的精确率不如SVM,而检测垃圾邮件的精确率普遍较高,平均值达到90%以上。这是因为NSA依靠“自我”来识别“非我”,检测器能根据正常样本集提取出正常邮件的特征,无需记忆垃圾邮件特征,所以即使出现新型垃圾邮件,其也能根据正常邮件来识别剔除该新型垃圾邮件。

表2 NSA垃圾邮件检测结果 %
第3组实验结果如表3所示。由表3可以看出,自适应性分类模型在保证邮件的准确率和正常邮件的召回率、精确率的基础上,还能有效提高垃圾邮件的召回率和精确率,这也验证了本文自适应性分类器的高效性,其不仅能保证正常邮件的高识别率,也能高效地检测出新型垃圾邮件。
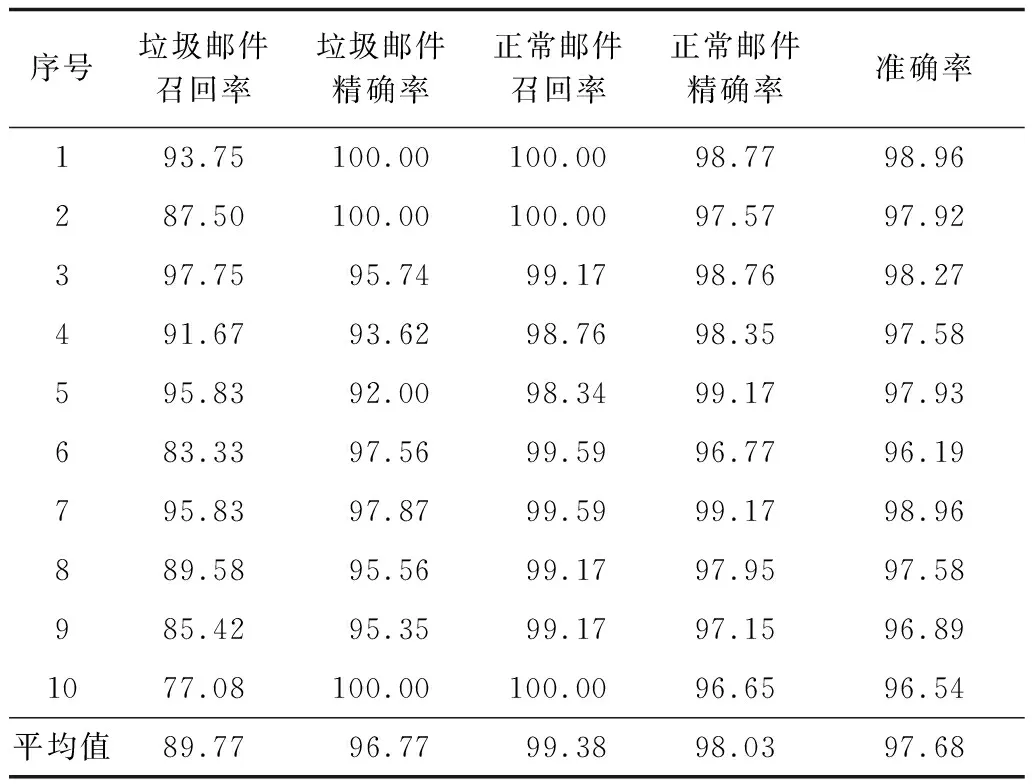
表3 自适应性垃圾邮件检测结果 %
4 结束语
本文设计垃圾邮件自适应性分类器,依据该分类器建立垃圾邮件的自适应性检测模型。实验结果表明,与单一的NSA和SVM算法相比,该方法有效地提高了识别垃圾邮件和正常邮件的精确率、召回率以及准确率。针对日益增多的附件和图片嵌入等形式的垃圾邮件,下一步将抽象出这些邮件的共性,结合本文针对文本型垃圾邮件的研究,进一步提升垃圾邮件的识别率。
[1] IDRIS I,SELAMAT A,NGUYEN N T,et al.A combined negative selection algorithm-particle swarm optimization for an email spam detection system[J].Engineering Applications of Artificial Intelligence,2015,39(39):33- 44.
[2] BLANZIERI E,BRYL A.A survey of learning-based techniques of email spam filtering[J].Artificial Intelligence Review,2008,29(1):63-92.
[3] HARRIS E.The next step in the spam control war:greylisting[EB/OL].[2017-02-25].http://projects.puremagic.com/greylisting/whitepaper.html.
[4] 谭 营,朱元春.反垃圾电子邮件方法研究进展[J].智能系统学报,2010,5(3):189-201.
[5] SAHAMI M,DUMAIS S,HECKERMAN D,et al.A bayesian approach to filtering junk e-mail[EB/OL].[2017-02-25].https://www.researchgate.net/publication/2788064_A_Bayesian_Approach_to_Filtering_Junk_E-Mail.
[6] CORTES C,VAPNIK V.Support-vector networks[J].Machine Learning,1995,20(3):273-297.
[7] CLARK J,KOPRINSKA I,POON J.A neural network based approach to automated e-mail classification[C]//Proceedings of 2003 IEEE/WIC International Conference on Web Intelligence.Washington D.C.,USA:IEEE Computer Society,2003:702-705.
[8] FORREST S,PERELSON A S,ALLEN L,et al.Self-nonself discrimination in a computer[C]//Proceedings of 1994 IEEE Symposium on Security and Privacy.Washington D.C.,USA:IEEE Computer Society,1994:202-212.
[9] ODA T,WHITE T.Spam detection using an artificial immune system[EB/OL].[2017-02-26].http://terri.zone12.com/doc/academic/crossroads/.
[10] MA W,TRAN D,SHARMA D.A novel spam email detection system based on negative selection[C]//Proceedings of the 4th International Conference on Computer Sciences and Convergence Information Technology.Washington D.C.,USA:IEEE Press,2009:987-992.
[11] MOHAMMAD A H,ZITAR R A.Application of genetic optimized artificial immune system and neural networks in spam detection[J].Applied Soft Computing,2011,11(4):3827-3845.
[12] IDRIS I,SELAMAT A.Email spam detection using differential evolution negative selection algorithm[J].International Journal of Digital Content Technology and Its Applications,2013,7(15):15-20.
[13] TAN Y,RUAN G.Uninterrupted approaches for spam detection based on SVM and AIS[J].International Journal of Computational Intelligence and Pattern Recog-nition,2014,1(1):1-26.
[14] SIRISANYALAK B,SOMIT O.An artificial immunity-based spam detection system[C]//Proceedings of 2007 IEEE Congress on Evolutionary Computation.Washington D.C.,USA:IEEE Press,2007:3392-3398.
[15] SALTON G,BUCKLEY C.Term-weighting approaches in automatic text retrieval[J].Information Processing and Management,1988,24(5):513-523.
[16] SPARCK J K.A statistical interpretation of term specificity and its application in retrieval[J].Journal of Documentation,1972,28(1):11-21.
[17] ZUCHINI M H.Aplicações de mapas auto-organizaveis em mineração de dados e recuperação de informação[EB/OL].[2017-02-25].http://viacodigo.com.br/pos/Zuchini,MarcioHenrique.pdf.
[18] BEZERRA G B,BARRA T V,FERREIRA H M.An immunological filter for spam[C]//Proceedings of International Conference on Artificial Immune Systems.Berlin,Germany:Springer,2006:446-458.
[19] DRUCKER H,WU D,VAPNIK V N.Support vector machines for spam categorization[J].IEEE Transactions on Neural Networks,1999,10(5):1048-1054.
[20] JI Z,DASGUPTA D.Revisiting negative selection algori-thms[J].Evolutionary Computation,2007,15(2):223-251.
[21] 金章赞,廖明宏,肖 刚.否定选择算法综述[J].通信学报,2013,34(1):159-170.
[22] 刘菊新,徐从富.基于多分类器组合模型的垃圾邮件过滤[J].计算机工程,2010,36(18):194-196.
[23] 王祖辉,姜 维.基于支持向量机的垃圾邮件过滤方法[J].计算机工程,2009,35(13):188-189.
[24] ANDROUTSOPOULOS I,KOUTSIAS J,CHANDRINOS K V,et al.An experimental comparison of naive bayesian and keyword-based anti-spam filtering with personal e-mail messages[C]//Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York,USA:ACM Press,2000:160-167.
猜你喜欢
英语文摘(2021年10期)2021-11-22
数学年刊A辑(中文版)(2021年3期)2021-11-05
数学年刊A辑(中文版)(2021年2期)2021-07-17
潍坊学院学报(2020年2期)2021-01-18
计算机与网络(2020年4期)2020-04-20
数学物理学报(2019年1期)2019-03-21
火力与指挥控制(2018年10期)2018-11-13
上海理工大学学报(2018年2期)2018-05-22
中国交通信息化(2017年9期)2017-06-06
电子制作(2017年10期)2017-04-18
