
MTSAX:一种新的多元轨迹索引方法
2018-05-30 01:26周向东陈海波
计算机工程 2018年5期
王 飞,庞 悦,周向东,陈海波
(1.复旦大学 计算机科学技术学院,上海 200433; 2.国网上海市电力公司,上海 200122)
0 概述
随着传感器、无线通信网络以及GPS定位等技术的飞速发展,各种基于位置的应用产生了海量轨迹数据,如导航地图上的出行记录、跑步软件上的历史线路等。轨迹是一种位置相关的时间序列[1]。由于实际应用中移动对象往往同时包含多种信息,如速度和运动方向等,因此多元轨迹数据在导航规划、位置服务等领域[2-3]具有非常重要的应用价值,得到了越来越多的研究与关注。
为了提高海量多元轨迹数据的分析和挖掘效率,轨迹数据的索引技术是关键。学术界对轨迹索引技术进行了大量研究,以往工作主要在面向点查询和范围查询[4]的轨迹索引研究[5-8]。近年来出现的面向相似轨迹查询的方法中,基于空间划分的索引[9]通常对原始空间采取固定划分的方式;基于特征压缩的索引通常会丢失大量原始空间信息[10];基于度量空间的索引[11]运用三角不等式等下界过滤技术提高查询效率,但该类索引仍难以克服高维数据索引面临的“维灾问题”。
本文提出一种新的多元轨迹索引方法MTSAX。对单个轨迹点设计基于Geohash的GeoWord编码,根据经度、纬度、速度等数据的密集程度和数据的重要性进行动态编码,保留指定精度下的轨迹信息。将每条轨迹分成若干等长子段来压缩原始轨迹,每个子段采用GeoWord编码,所有子段的GeoWord编码组成的符号串代表一条轨迹,即用MTSAX表示。对于MTSAX表示的整条轨迹,设计了基于一元时间序列索引iSAX技术的多元轨迹索引结构,实现一种新的轨迹索引MTSAX。
1 相关工作
文献[4]提出轨迹查询的3种类型:点查询,范围查询和轨迹相似查询。面向点查询和范围查询的轨迹索引又可划分为移动物体的历史位置索引[5]、当前位置索引[6]、未来位置索引[7]和全时空位置索引[8]。轨迹相似查询有多种方式,常见的面向相似轨迹查询的索引方法如下:
1)基于空间划分的轨迹索引。该类方法通常采用划分空间单元格的方式对原始空间进行编码,借助空间编码建立索引。文献[9]提出轨迹索引方法TRSTJ,首先使用PAA[12]方法将原始轨迹分段表示,然后将PAA表示的轨迹空间切分成相同大小的单元格,并为每个单元格分配一个符号,最终一条轨迹被表示成一个字符串。
2)基于特征压缩的轨迹索引。该类方法提取轨迹的特征并编码,借助特征编码建立索引。文献[10]提出一种多元时间序列索引方法,该方法将多元时间序列以多变量求和的方式转化为一元时间序列,使用PAA方法把一元时间序列变成N维向量,最后使用R树来索引该N维向量。
3)基于度量空间的轨迹索引。该类方法先选择若干参考点,定义某种距离,再计算所有轨迹相对于参考点的距离,最后在查询时通过这些参考点过滤掉不符合要求的轨迹。文献[11]提出一种基于参考点距离的方法,建立了多元时间序列索引LBS,在飞行数据集上进行相似性查询。
2 多元轨迹符号化索引MTSAX
2.1 一元时间序列索引方法iSAX
文献[12]在分段聚集近似PAA[12]和符号化聚集近似SAX[13]的基础之上,提出一种可索引的符号化聚集近似方法iSAX[14],可以索引海量一元时间序列,支持时间序列相似性查询。iSAX假设原始时间序列服从高斯分布,并将原始时间序列转换成均值为0标准差为1的标准时间序列。iSAX采用PAA方法将时间序列分成若干等长子段,然后根据正态分布的概率区间将均值表示的序列离散化为符号串,最后将符号化表示的时间序列进行树状索引。iSAX可以根据时间序列的分布情况采用不同的离散化基数来动态编码。
2.2 多维空间编码GeoWord
Geohash是一种二维空间编码,对经纬度交替编码,缺乏灵活性。多元轨迹不仅包含移动物体在运动过程中的经纬度位置,还包含速度、方向等信息;不同变量的重要性一般也不同,例如在轨迹中经纬度位置通常比速度、方向更加重要。因此,本文提出一种基于Geohash的多维空间编码GeoWord,可以对经纬度位置和速度、方向等附加信息同时编码,并考虑了不同变量数据的密集程度及重要性。
GeoWord算法需要给定单个轨迹点的多元信息和对应的离散化基数。离散化基数用于将PAA得到的连续值离散化为指定精度的编码,对于经度、纬度这样的空间位置可以看做是对空间切分的精度。GeoWord可以采用等切分获得分割点,也可以通过对数据进行采样估计获得分割点。图1以等切分为例展示了GeoWord编码,初始切分中的GeoWord编码为021212,其中,02、12、12分别由经度、纬度和速度3个变量的编码组成,上标表示该变量的离散化基数。
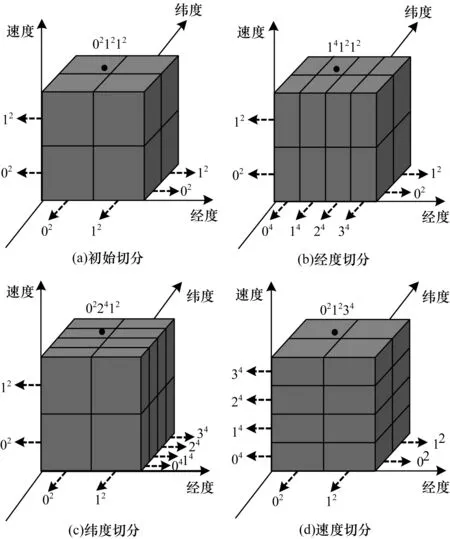
图1 GeoWord编码示意图
GeoWord可以选择不同变量进一步离散化,如图1中在初始切分的基础上可以对经度、纬度和速度进行切分。切分变量的选择依赖于不同变量数据的密集程度和变量本身的重要性,切分的目的是为了更好地索引轨迹,关于切分变量的选择策略见2.3节MTSAX索引构建方法中的节点分裂介绍。
GeoWord编码可以得到单个多元轨迹点在指定精度下的压缩表示,从而得到整条轨迹的压缩表示;对于压缩表示,执行GeoWord的逆过程可以得到单个多元轨迹点在指定精度下的信息,从而得到整条轨迹在指定精度下的信息。
算法1GeoWord算法

输出第i个轨迹点GeoWord编码
1.gi=null//保存GeoWord编码
2.for j from 1 to m//对m个变量依次编码
3. 获取基数aij对应的所有分割点cuts[]
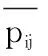
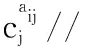
7.end for
8.return gi//第i个轨迹点GeoWord编码
2.3 多元轨迹符号化表示
如图2所示为MTSAX的索引结构,图3中轨迹被分为3段,各变量初始基数均为2。当某一索引节点包含的轨迹数量超过指定阈值,该节点分裂为2个新的索引节点,原先的索引节点作为中间节点,图2中的节点{121202,021212,120202}分裂产下面描述MTSAX表示的生成过程。
生{121202,022412,120202}和{121202,023412,120202}2个新的叶子节点。图3所示为索引节点{121202,022412,120202}的空间划分情况。
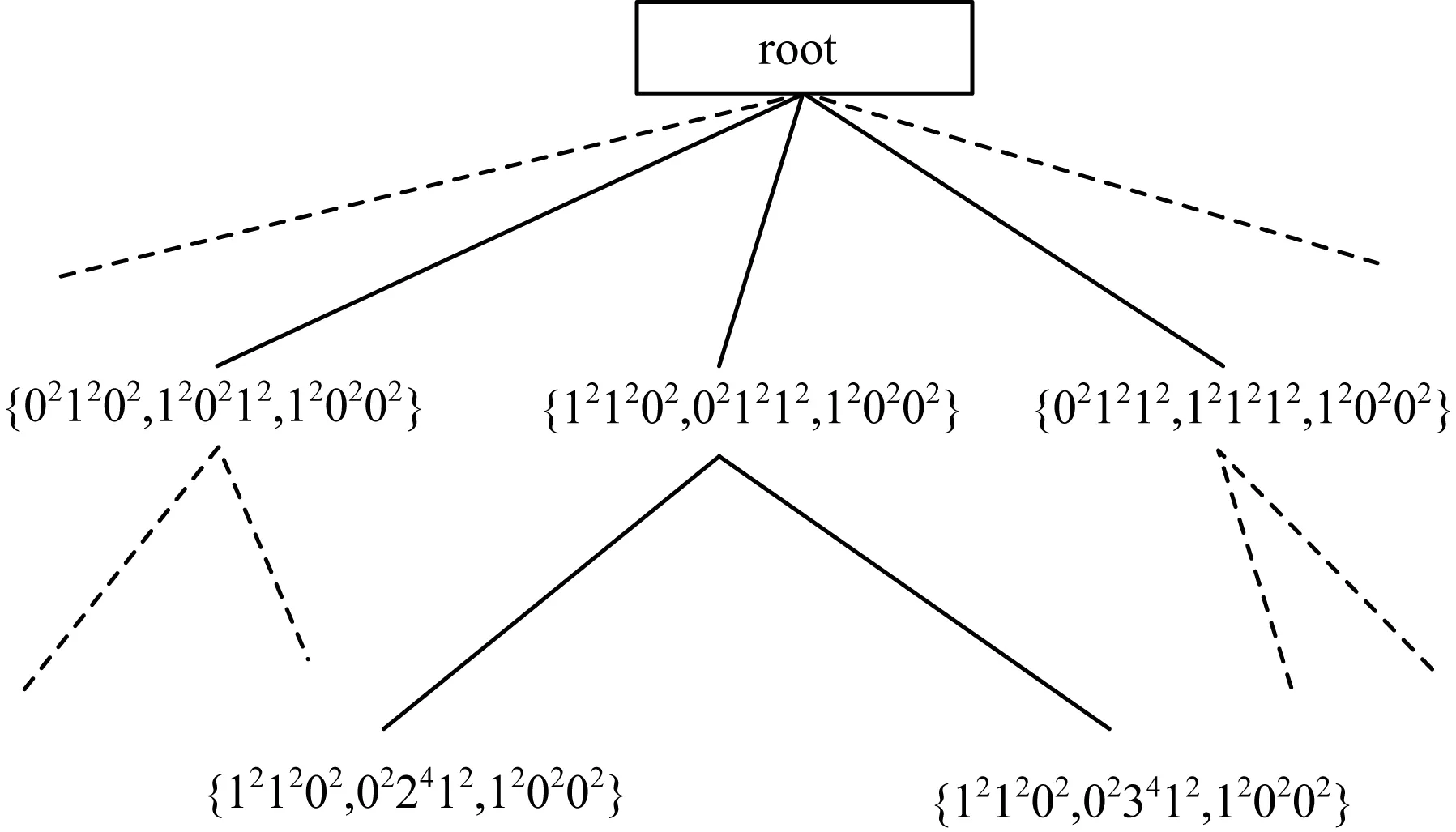
图2 MTSAX索引结构示意图
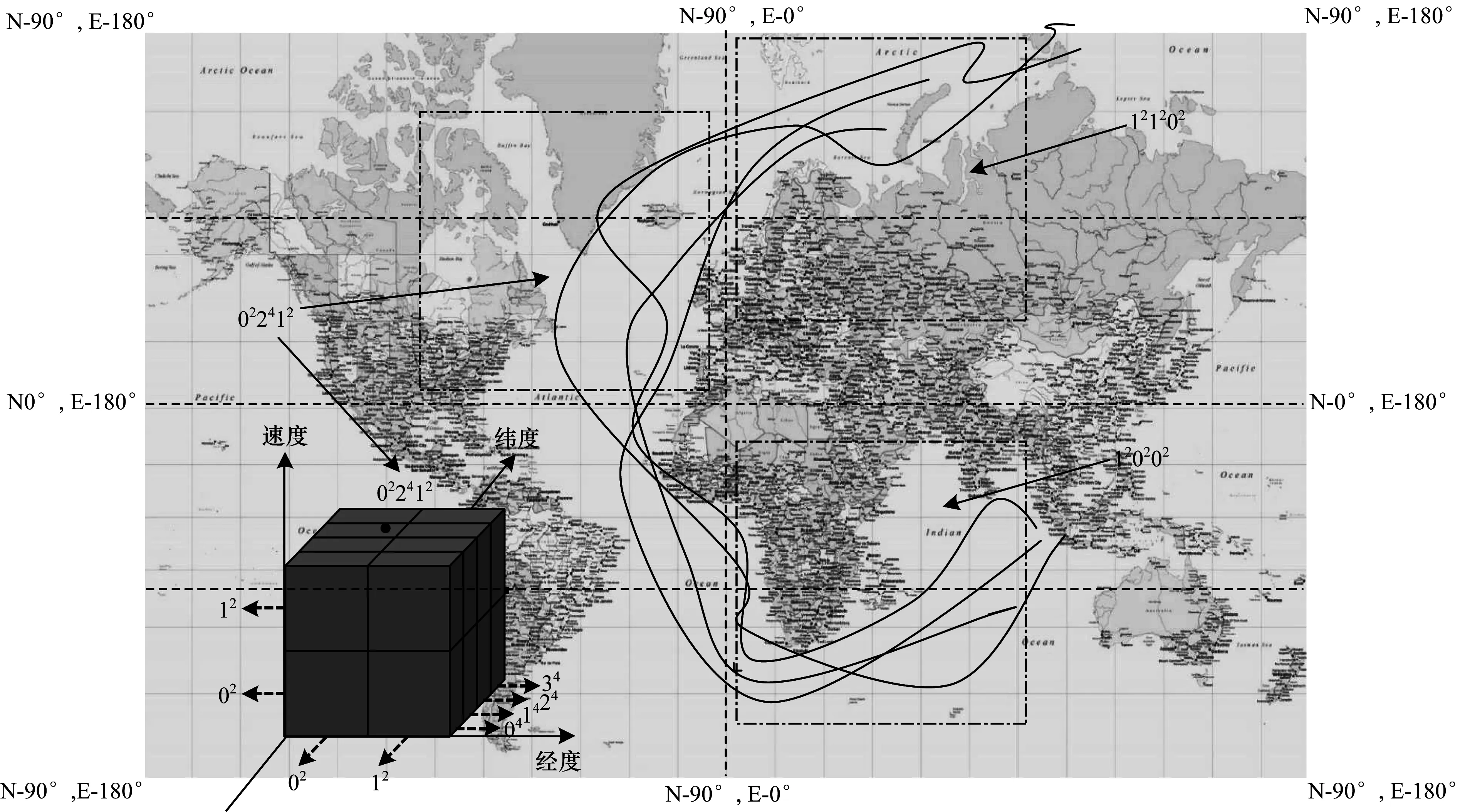
图3 MTSAX索引节点空间划分示意图
步骤1本文采用PAA模型将原始多元轨迹数据从n维降到w维。
给定多元轨迹:
T0= {(p11,p12,…,p1m),…,(pi1,pi2,…,pij,…,
pim),…,(pn1,pn2,…,pnm)}
(1)
其中,n表示轨迹长度,m表示轨迹变量的数目,pij表示第i个轨迹点的第j个变量,1≤i≤n,1≤j≤m。
使用PAA轨迹约减为:
(2)
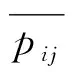
每个子段用其均值代替为:
(3)
步骤2本文将多元轨迹的PAA表示离散化为符号,使用GeoWord算法对单个多元轨迹位置编码,得到:
T2={g1,g2,…,gi,…,gw}
(4)
其中,gi为(pi1,pi2,…,pij,…,pim)经过GeoWord编码得到的表示,1≤i≤w,w个GeoWord编码{g1,g2,…,gi,…,gw}组成一个MTSAX表达。
2.4 MTSAX索引构建方法
MTSAX索引是树结构,第一层可以看作是多叉树,且第一层所有节点基数相同,即对原始空间采用同样的划分精度。从第二层开始,由于叶子节点根据数据的密集程度进行二分裂,则以第一层节点为根节点的子树是二叉树。MTSAX索引构建因此可以看作是对多叉树和二叉树混合在一起的树的构建,MTSAX索引建立详细过程如算法2所示。
算法2MTSAX索引建立
输入需要插入的多元轨迹ts
输出MTSAX索引插入多元轨迹ts
1.获取ts的MTSAX表示G
2.if当前索引节点存在MTSAX表示为G的后继节点
3. 获取MTSAX表示为G的后继节点node
4. if node 为叶子节点
5. if node存储的轨迹数量小于节点分裂阈值th
6 node直接插入ts
7. else//叶子节点索引的轨迹已满,需要分裂
8. 新建中间节点newnode
9. newnode递归插入ts和node索引的所有轨迹
10. 删除node节点
11. 将newnode作为当前节点的后继节点
12. else// node为中间节点
13. node递归插入ts
14.else
15. 新建MTSAX表示为G的叶子节点newLeaf
16. 叶子节点newLeaf直接插入ts
MTSAX索引采用二分裂的方式,因此,分裂过程中可以升高某子段的某个变量的基数,将原先叶子节点索引的轨迹分配到2个新的叶子节点。节点分裂后还可能有新的数据插入,所以从概率上选择最可能均分数据的某子段的某个变量升高基数。依次计算要分裂的叶子节点索引的所有轨迹数据在w个子段的m个变量的均值μ和标准差σ,若某子段的某个变量的均值越靠近升高基数后得到的新分割点a,同时对应的标准差越大,那么从概率上就越可能在新的分割点均匀地分配数据;考虑到各变量的量纲不同,需要除以其最大值max归一化;考虑不同变量本身的重要性weight,这样在相似性查询中可以更加倾向重要性更大的变量。通过求解式(5)可以寻找最可能均分数据的分裂子段和分裂变量。图4所示为每段包含2个变量的三段轨迹数据从基数2升高到基数4的情况,求解得到在第2段的第2个变量分裂能够从概率上最均匀的分配数据。
(5)
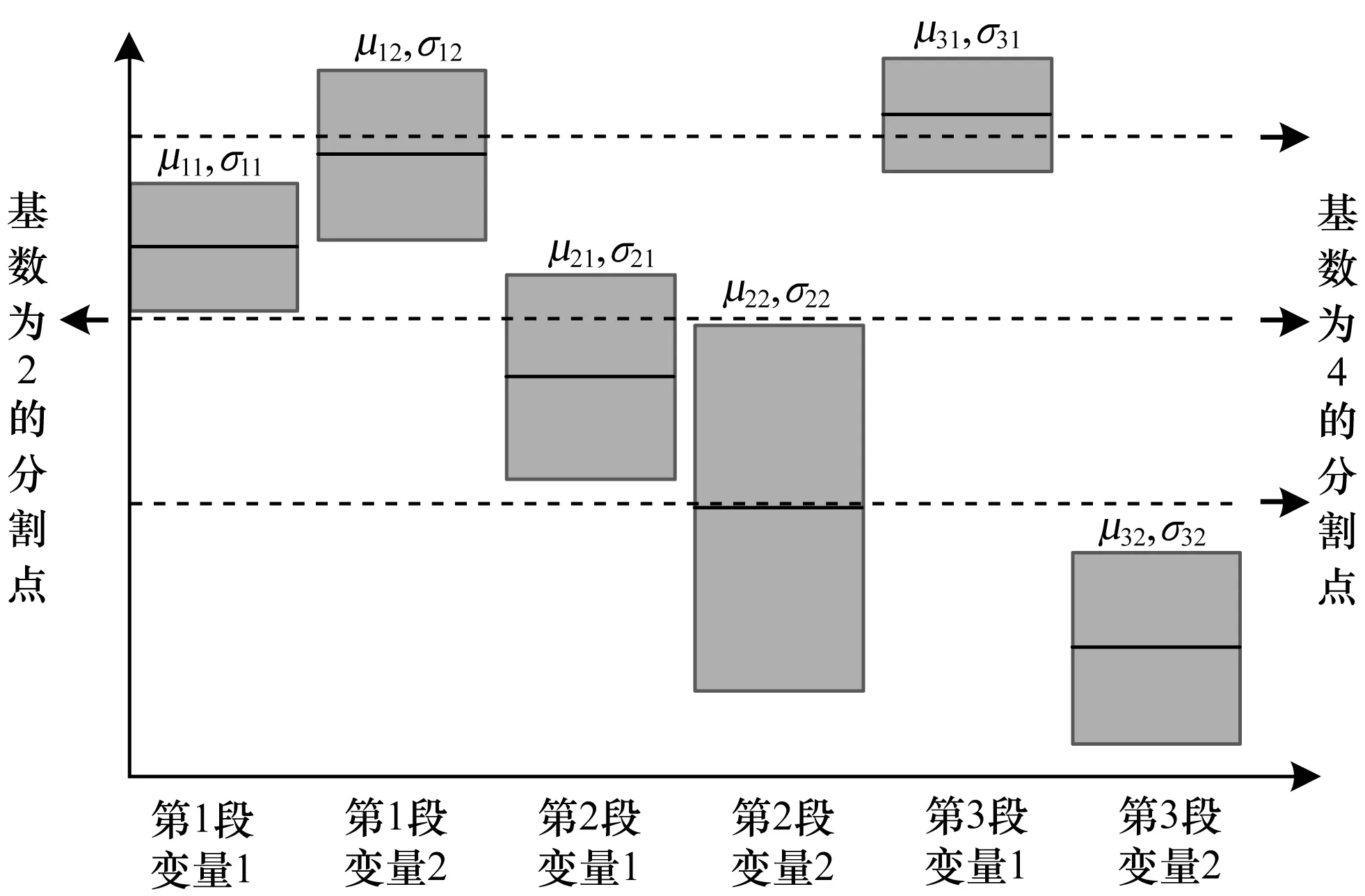
图4 GeoWord对切分变量的选择
2.5 基于MTSAX的多元轨迹相似轨迹查询
MTSAX索引相似查询假设相似的两条多元轨迹具有相同的MTSAX表示,查询的结果是与查询轨迹距离最近的轨迹。MTSAX索引是层次且没有重叠的,可以遍历索引树找到对应的索引节点,获取其索引的所有轨迹,分别计算这些轨迹与查询轨迹之间的距离,返回距离最小的轨迹。使用式(6)计算轨迹s和t之间的距离,计算过程中考虑了不同变量的重要性,距离越小越相似。
(6)
其中,m表示轨迹的变量数目,n表示轨迹中包含的轨迹点数目,sij和tij分别表示轨迹s和t在第i个变量的第j个轨迹点,wi表示第i个变量的权重。
3 实验结果与分析
3.1 数据集
航运数据:从全球免费在线航运船舶跟踪网站www.vesselfinder.com爬取40 000条船的轨迹,每条轨迹有200个轨迹点,每个轨迹点包含经纬度坐标和航速3项信息。
GeoLife数据集:GeoLife数据集[15]是一个关于被广泛使用的轨迹数据集,有18 670条轨迹,24 876 978个轨迹点,轨迹总距离为1 292 951 km。轨迹由用户步行、骑自行车、乘坐公交车、出租车等多种出行方式产生,每个轨迹点包含经度、纬度和海拔3项信息。
3.2 对比方法
对比方法如下:
1)在基于空间划分的轨迹索引中,选择文献[9]提出采用固定空间划分的TRSTJ作为对比方法。
2)在基于空间划分的轨迹索引中,选择文献[10]提出的基于多变量加和的轨迹索引方法,将其简记为ADD。ADD的处理过程与本文方法处理步骤类似,主要区别在于ADD对原始的多元轨迹采用多变量加和的方式,而MTSAX采用GeoWord编码。
3)在基于度量空间的轨迹索引中,选择文献[11]提出的基于参考点距离的LBS作为对比方法。
3.3 结果分析
为验证MTSAX索引方法的有效性,本文在相同初始基数下分别对MTSAX、TRSTJ、ADD、LBS和原始数据顺序扫描5种方法随机查询100次,通过平均查询时间比较这些方法的查询性能。
3.3.1 航运数据上的查询性能对比
查询性能对比过程如下:
1)MTSAX和顺序扫描的对比
从图5和表1中可以看出,顺序扫描与空间划分无关,基数对顺序扫描没有影响,不同基数下顺序扫描的时间相同。MTSAX、TRSTJ、ADD和LBS建立了相应的索引机制,因而均比顺序扫描要快。
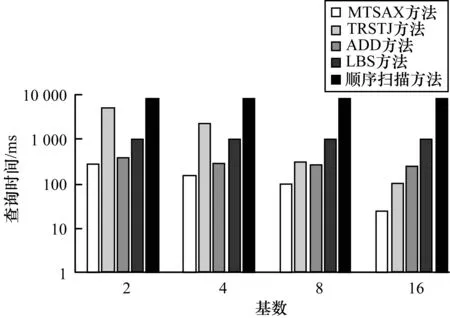
图5 航运数据上的查询性能对比
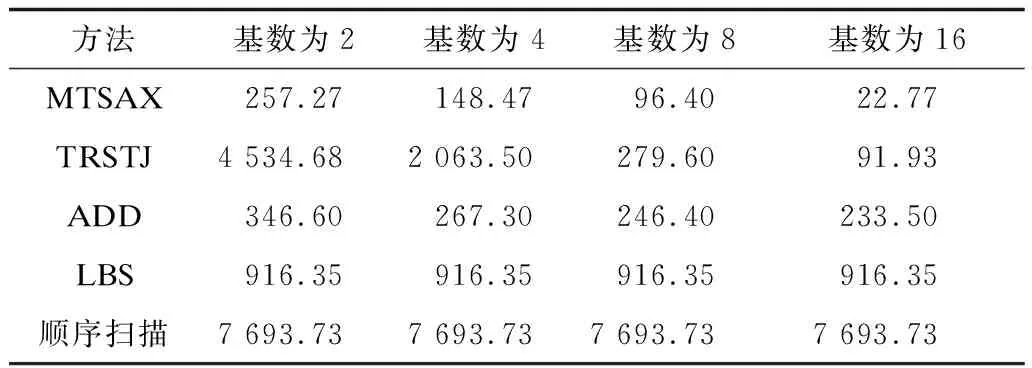
方法基数为2基数为4基数为8基数为16MTSAX257.27148.4796.4022.77TRSTJ4 534.682 063.50279.6091.93ADD346.60267.30246.40233.50LBS916.35916.35916.35916.35顺序扫描7 693.737 693.737 693.737 693.73
2)MTSAX和TRSTJ的对比
从图5和表1中可以看出,相同基数下MTSAX的查询性能均比TRSTJ要好,如基数为2时MTSAX查询速度是TRSTJ的17.6倍,基数为4时MTSAX查询速度是TRSTJ的13.9倍。这是TRSTJ对空间采取固定划分方式,导致TRSTJ索引中数据分布很不均匀,极少数的索引节点索引了大多数的轨迹,大多数的索引节点只索引了少部分的轨迹。因此,TRSTJ大部分的查询发生在极少数的索引节点上,而这些索引节点又索引了大量轨迹,查询需要扫描节点上索引的所有轨迹,该查询已经退化为顺序扫描,性能大大降低。
与TRSTJ相比,MTSAX索引节点索引轨迹的数量分布相对均匀。MTSAX可以随着数据量的大小动态调整索引结构,当单个节点包含的轨迹数量超过指定阈值节点则分裂,虽然增加了查询的深度,但是在每个索引节点上查询时间大大缩短,从而提高了整体查询的性能。
3)MTSAX和ADD的对比
从图5和表1中可以发现,在相同基数下MTSAX效果均比ADD方法要好。这是因为ADD方法将多个变量加和,不同变量数据的变化被抵消,索引节点存放了很多不相似的轨迹,查询时间变长。
4)MTSAX和LBS的对比
LBS采用基于度量空间的方法,与空间划分无关,因此在不同初始空间基数下结果相同。由于时间序列的高维特性,基于度量空间的方法会面临维灾问题,当维度超过15时索引性能会随着维度的膨胀明显下降,而实验中每条轨迹包含200个轨迹点,远远大于15。此外,LBS将整条轨迹分成多个子段,查询整条轨迹需要将多个子段拼接在一起,降低了查询效率。
3.3.2 GeoLife数据集上的查询性能对比
图6与表2是在GeoLife数据集上进行查询得到的性能对比,可以看出,MTSAX、TRSTJ、ADD、LBS和顺序扫描5种方法的查询表现与航运数据是相似的。顺序扫描与空间划分无关,MTSAX、TRSTJ、ADD、LBS均建立了相应的索引机制,均比顺序扫描要快。在相同基数下,MTSAX的查询性能表现最佳。如基数为2时MTSAX查询速度是TRSTJ的13.9倍、ADD方法的1.3倍、LBS方法的11.2倍、顺序扫描的26.2倍;基数为4时MTSAX查询速度是TRSTJ的8.5倍、ADD方法的1.3倍、LBS方法的11.9倍、顺序扫描的27.8倍。
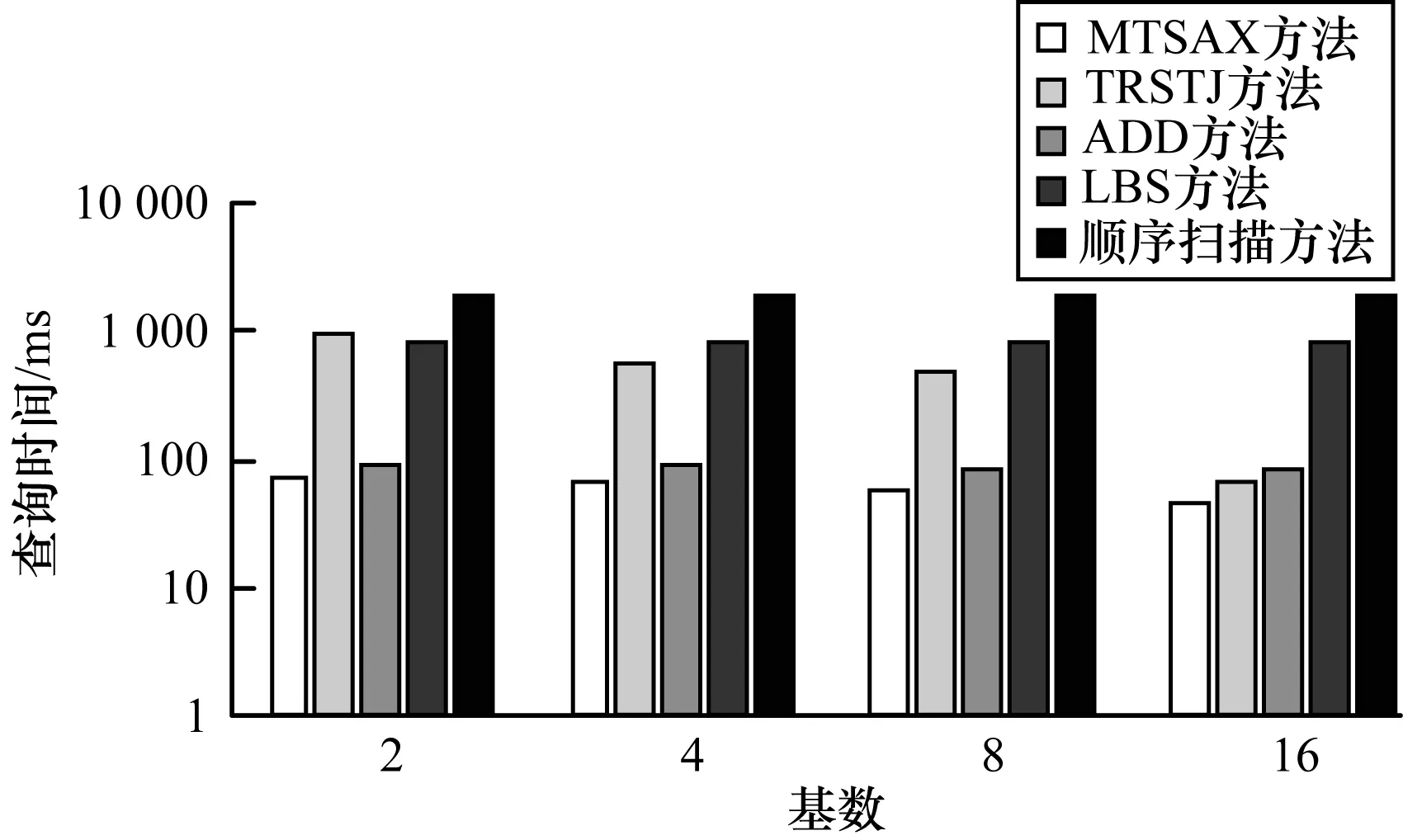
图6 GeoLife数据集上的查询性能对比
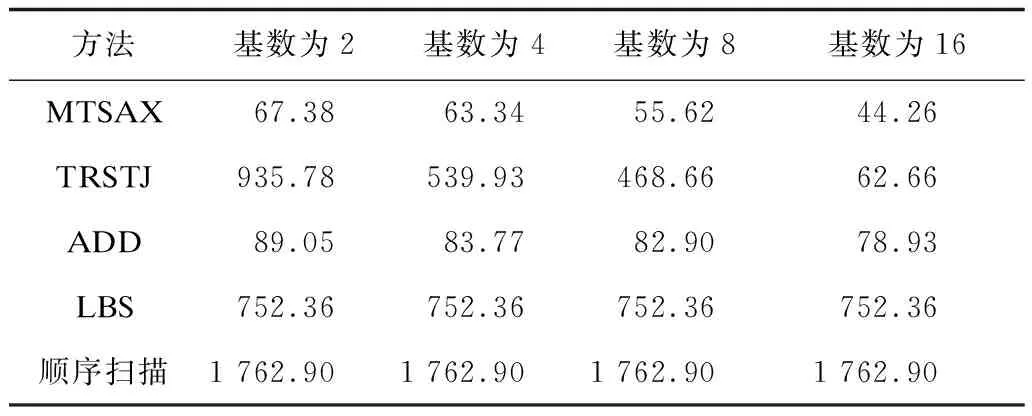
方法基数为2基数为4基数为8基数为16MTSAX67.3863.3455.6244.26TRSTJ935.78539.93468.6662.66ADD89.0583.7782.9078.93LBS752.36752.36752.36752.36顺序扫描1 762.901 762.901 762.901 762.90
4 结束语
针对现有轨迹索引方法存在的问题,本文提出一种多元轨迹符号化索引MTSAX。该方法针对单个多元轨迹点设计了一种基于Geohash的新编码GeoWord,在iSAX索引框架的基础上,给出了移动对象历史轨迹索引方法MTSAX。实验结果表明,在相同基数下MTSAX搜索性能均优于已知的基准索引方法,在海量数据下MTSAX对近似查询可以快速响应。下一步将侧重于建立分布式轨迹索引,提升索引建立的速度。
[1] 龚旭东.轨迹数据相似性查询及其应用研究[D].合肥:中国科学技术大学,2015.
[2] HECTOR G,HAN Jiawei,LI Xiaolei,et al.Adaptive fastest path computation on a road network:a traffic mining approach[C]//Proceedings of the 33rd International Conference on Very Large Data Bases.Washington D.C.,USA:IEEE Press,2007:794-805.
[3] GORJI S M,MOHAMMAD S,ABDOLLAH H.Non-stationary time series clustering with application to climate systems[M].Berlin,Germany:Springer,2014.
[4] ZHENG Yu,ZHOU Xiaofang.Computing with spatial trajectories[M].Berlin,Germany:Springer,2011.
[5] ELIAS F.Indexing objects moving on fixed networks[C]//Proceedings of International Symposium on Spatial and Temporal Databases.Washington D.C.,USA:IEEE Press,2003:289-305.
[6] KIM K S,KIM S W,KIM T W,et al.Fast indexing and updating method for moving objects on road networks[C]//Proceedings of Web Information Systems Engineering Workshops.Washington D.C.,USA:IEEE Press,2003:34-42.
[7] SALTENIS S,JENSEN C S,LEUTENEGGER S T.Indexing the positions of continuously moving objects[C]//Proceedings of 2000 ACM SIGMOD International Conference on Management of Data.New York,USA:ACM Press,2000:331-342.
[8] LIN Dan,JENSEN C S,OOI B C,et al.Efficient indexing of the historical,present,and future positions of moving objects[C]//Proceedings of the 6th International Conference on Mobile Data Management.Washington D.C.,USA:IEEE Press,2005:59-66.
[9] PETKO B,MARIOS H,TSOTRAS V J.Time relaxed spatiotemporal trajectory joins[C]//Proceedings of the 13th Annual ACM International Workshop on Geographic Information Systems.New York,USA:ACM Press,2005:182-191.
[10] 李正欣,张凤鸣,李克武,等.一种支持DTW距离的多元时间序列索引结构[J].软件学报,2014,25(3):560-575.
[11] KANISHKA B,ZHU Qiang,OZA N C,et al.Fast and flexible multivariate time series subsequence search[C]//Proceedings of 2010 IEEE International Conference on Data Mining.Washington D.C.,USA:IEEE Press,2010:48-57.
[12] EAMONN K,KAUSHIK C,MICHAEL P,et al.Dimensionality reduction for fast similarity search in large time series databases[J].Knowledge and Information Systems,2001,3(3):263-286.
[13] JUNEJO I N,AL A Z.Using SAX representation for human action recognition[J].Journal of Visual Communication and Image Representation,2012,23(6):853-861.
[14] JIN S,EAMONN K.iSAX:disk-aware mining and indexing of massive time series datasets[J].Data Mining and Knowledge Discovery,2009,19(1):24-57.
[15] ZHENG Yu,ZHANG Lizhu,XIE Xing,et al.Mining interesting locations and travel sequences from GPS trajectories[C]//Proceedings of the 18th International Conference on World Wide Web.Washington D.C.,USA:IEEE Press,2009:791-800.
猜你喜欢
四川劳动保障(2021年9期)2022-01-18
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
读友·少年文学(清雅版)(2020年4期)2020-08-24
汉字汉语研究(2020年2期)2020-08-13
读友·少年文学(清雅版)(2020年3期)2020-07-24
电子制作(2019年22期)2020-01-14
无锡职业技术学院学报(2019年4期)2019-12-27
疯狂英语·新读写(2018年3期)2018-11-29
小学生必读(中年级版)(2018年6期)2018-09-05
现代装饰(2018年5期)2018-05-26
