
一种新颖的面向数据流量特征的片上网络设计*
2018-05-28 09:25胡森森陈皇吉
电讯技术 2018年5期
胡森森**,陈皇吉
(1.重庆工商大学 电子商务系,重庆400067;2.中国西南电子技术研究所,成都610036)
1 引 言
William J. Dally提出采用片上网络(Network-on-Chip,NoC)连接多个处理器核芯,并采用路由和分组交换技术进行数据通信,使得片上网络开始成为计算机系统结构领域中的一个研究热点[1]。片上网络成功地实现了多核系统的计算功能与通信功能的分离。在片上网络拓扑结构方面,研究人员提出了多种拓扑结构,如二维环网(Ring)、二维Mesh和二维Torus等结构。片上网络的拓扑结构不仅决定了节点和链路的物理布局,而且紧密耦合着构建在其上的路由算法、流量控制等机制和策略[2]。
另一方面,目前主流的瓦片结构(Tile)的多核处理器设计中,大容量的Cache被划分成多个小的Bank(或者Slice),并以二维Mesh的拓扑结构分布在片上网络中。因此,处理器对各个Bank的访问延迟会因物理拓扑距离的差异,造成非一致 Cache 访问现象(Non-uniform Cache Access,NUCA)[3-4]。在对片上网络中的流量研究发现,网络流量由请求消息和应答消息交织在一起,处理器核与处理器核之间(Core-Core)、处理器与缓存之间(Core-Cache)的数据流量存在巨大的差异。在核间通信中,请求消息占绝大多数,数据流量小,而在处理器与缓存通信中占绝大多数的是应答消息,需要承载大量的缓存数据的读/写,数据流量大。因此,处理器核的不同通信模式需要不同的的网络带宽来降低网络延迟,提高网络吞吐量,从而提高通信效率。
本文探讨了将传统的片上网络分离为双片上网络的设计,即核间通信网络和片上存储网络,分别用于核间通信和核-缓存之间的通信。本文提出的方案针对片上网络中处理器核和缓存数据流量的特点进行了网络优化。对比实验表明,该方案具有较低的网络延迟和较高的网络吞吐量,提升了系统整体性能。
2 片上网络流量特征
为了评估系统中各种消息所携带的数据流量,我们选择了真实的服务器工作负载,使用GEM5[5]全系统模拟器进行了仿真。对片上网络流量研究发现,处理器核与处理器核之间通信(Core-Core)和处理器与缓存之间通信(Core-Cache)存在不同的通信模式。片上网络的流量主要由请求消息和响应消息组成,请求消息和应答消息交织在一起。
请求流量主要由取指(Fetch)、内存驱逐(Evict)请求和缓存一致性(Cache Coherence)请求组成,具有短消息的特征,而响应流量主要由读/写数据块构成,具有长消息的特征。图1给出了对常见的四种服务器工作负载的仿真结果,统计结果显示,短消息流量平均占总请求流量的91.8%,长消息流量平均占总响应流量的89.2%。在核间通信中,请求消息占绝大多数,因此具有信息量小的特点(短消息),而在处理器与缓存通信中占绝大多数的是应答消息。由于应答消息一般需要承载缓存数据块,具有信息量大的特点(长消息)。不同消息对网络带宽的需求是不一样的,因此需要根据数据的特征进行网络设计的优化。

图1 常见的四种服务器工作负载片上网络流量分布Fig.1 Four kinds breakdown of server workload on-chip network traffic
3 双片上网络设计
网络拓扑定义了节点如何布局和连接,影响着网络的延迟、吞吐量和系统整体性能。因此在多核处理器设计中,片上网络的结构起着至关重要的作用。本文针对片上网络流量的特征,设计了一种异构非对称双片上网络,即核间互连网络和片上缓存网络,分别用于核间通信和核-缓存通信。
3.1 核间互连网络
2D Mesh在布局布线方面的优势,使得其在多核处理器设计中被广泛采用。最常见的基于Mesh拓扑结构的多核处理器绝大多数采用瓦片设计方案。WK-Recursive[6]递归网络拓扑具有层次性(Hierarchy)、可扩展性(Scalability)、规整性(Regularity)、鲁棒性(Robust)和对称性(Symmetry)等优点[7]。在这些属性中,对于超大规模集成电路(Very Large Scale Integrated Circuits,VLSI)设计来说,递归层次结构和规整性是最有价值的属性。核间互连拓扑结构采用4度网络,既有利于采用传统的2D Mesh布局,又可利用其递归性带来的设计优势。本文设计的核间互连结构中,每4个核全互连构成1个基本簇。每个核都拥有1个私有L1缓存,基本簇内的4个核共享1个L2,以此方式逐步进行扩展,进而形成相互包含的层次化分组结构。
WK-recursive网络记为WK(D,L),其中D表示节点的连接度,L表示网络的层数。2D Mesh结构的核间互连网络属于连接度为4的一种特例,记为WK(4,L)。核间网络拓扑编码如下:
定义1 对于一个给定的节点总数为4L的WK-recursive网络拓扑WK(4,L),其网络上各节点的编码为Ak-1Ak-2…A1A0,其中Ai∈(0,1,2,3),0≤i≤k-1。Ai的取值根据以下规则确定:0代表左上节点,1代表右上节点,2代表右下节点,3代表左下节点。
根据定义1,i代表了节点所在的层次。当L为1、2、3时,核间网络分别对应4核、16核、64核处理器。在度为4的2D Mesh网络中,每4个节点构成一个簇,簇节点以4的指数级增长。如图2所示,图中描述了L值分别为1、2、3时,核间互连网络的拓扑结构和每个节点的编码方案。L代表层次数,L=0时,代表单个节点;L=1时,代表由4个内核构成的基本簇。在该拓扑中网络节点划分为4个区域,每个区域分配1个固定代码,每个区域可以进一步划分直到一个基本的节点。如节点302,代表在第3层编号为3的簇内,在第2层编号为0的簇内,在第1层右下角位置,因此节点编码过程也是一个迭代的过程。
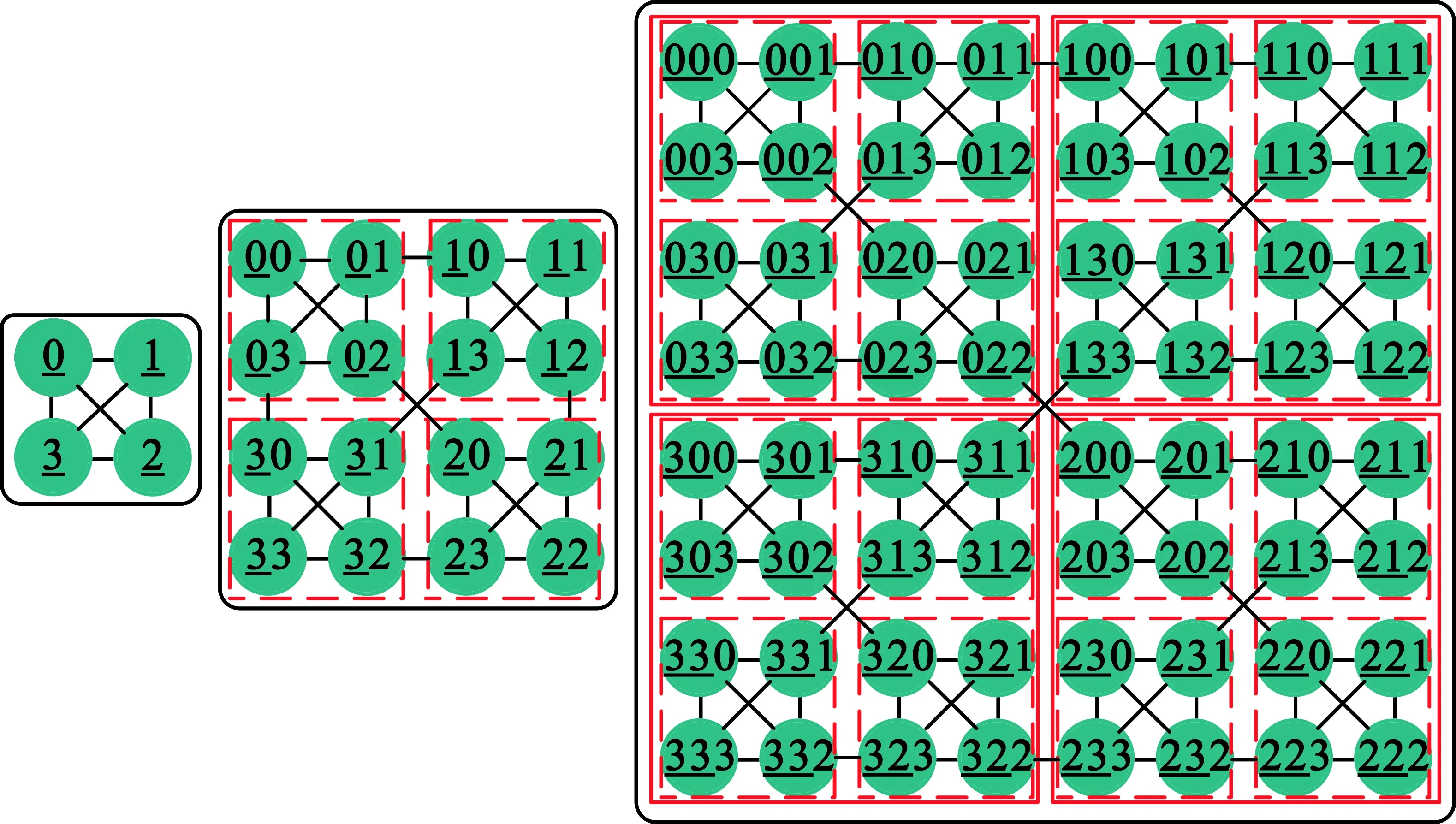
图2 4核、16核、64核处理器的核间互连网络Fig.2 Core-core interconnection network of 4-core, 16-core and 64-core
3.2 片上缓存网络
缓存一致性问题源于Cache的组织结构和使用方式,包括了数据在存储器中的存放策略、片上网络的结构、Cache的组织方式等[8]。在水平方向,本文设计的每层网络都是WK-Recursive拓扑结构,而在垂直方向,该网络的拓扑为四叉树结构,如图3所示。该网络构造出一个层次化分组共享的高性能片上存储系统,而且其分组特色与核间网络的层次特征相契合。片上缓存网络中节点的编码规则如下:
定义2 对于一个给定的片上缓存网络拓扑结构,网络的垂直高度为L+1层,其内核节点的编码为LxL-1…x1x0,xn{0,1,2}(0≤n≤L-1),n表示该节点所在的L级缓存。同样,xn的取值根据以下规则:0代表左上节点,1代表右上节点,2代表右下节点,3代表左下节点。
以16核结构为例,片上网络层次化存储器主要由3个存储层次构成:私有L1 Cache片上存储层次、分簇共享L2 Cache片上存储层次以及簇间共享L3 Cache存储层次。在垂直方向,所有的节点通过树状网络链接。随着水平层次的上升,节点数目逐级减少,最终形成一个尖端节点(0)。L1片上存储器访问速度最快,但容量小、成本高。3个存储层次的访问速度从下至上逐级递减,容量则逐渐增加。根据程序及运算局域性原理,片上网络结构将紧密耦合的对象和进程映射到同组处理核内,而松散耦合的对象和进程映射到邻近组的处理核内。这样处理核访问同组内的存储器用时比跨组访问时间要大大缩短,共享存储器在时间和空间上取得了一个平衡。
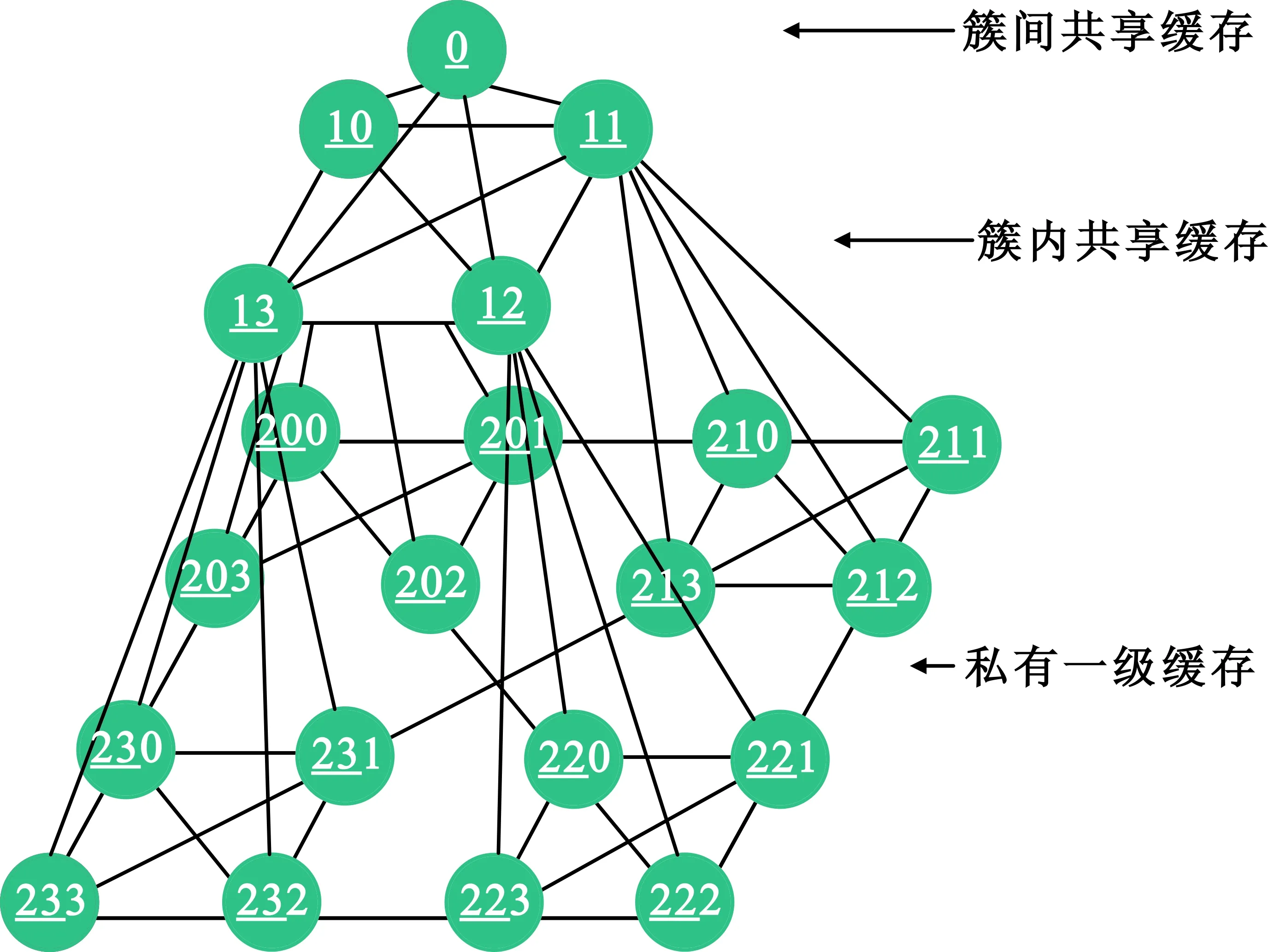
图3 16核处理器的片上缓存网络Fig.3 On-chip network of 16-core processor memory
4 实验评估
针对本文提出的非对称双片上策略,我们评估采用合成流量和真实负载两种方法评估网络性能。
4.1 实验设计及方法
GEM5是美国威斯康星大学(University of Wisconsin)开发的一款开源的全系统模拟器,它集成了多种商用 ISA,具备高度可配置的特性。为了评估非对称双片上网络的性能,我们扩展了GEM5模拟器搭建了一个功能丰富的片上网络性能测试平台。本实验的GEM5模拟器运行环境为Linux操作系统(内核版本2.6.38)、GCC编译器(版本4.5.2),仿真前对模拟器进行了预热以获得稳定可靠的结果。表1列出了实验平台的系统配置参数。

表1 实验平台的系统配置参数Tab.1 System configuration
本实验设计了两种双网络方案,一种是同构对称的双网络,另一种是异构非对称双网络。同构对称的双网络设计采用核间互连网络和缓存网络各96 bit带宽;非对称双网络设计中,核间互连网络带宽为64 bit,而缓存网络带宽为128 bit。同时本实验对比了192 bit带宽的单网络设计方案。
合成流量模式可以模拟消息在片上网络中的空间分布情况,它是研究人员对实际应用程序中通信方式的抽象。我们建立了一个抽象的通信事务来反映缓存一致性问题,具体的策略是:
(1)读请求被发送到系统最远端的Tile中,当收到来自其L1的数据后事务完成;
(2)写请求传输到最远端的Tile中,当收到来自其核的应答后事务完成。
4.2 网络延迟分析
在合成流量模式测试中,网络平均通信延迟随着网络数据包注入速率的增长而增长。在数据包注入速率较低时,网络平均通信延迟增长较缓慢,而当网络达到饱和后,数据包平均延迟急剧上升。图4显示了采用Uniform Random合成流量模式时三种设计方案对网络延迟的影响。从合成流量模式测试结果来看,异构非对称双网络的平均网络延迟最低,本文方案的平均网络延迟比同构对称双网络和单网络平均低27.14%和58.83%。实验数据表明,本文的异构非对称双网络结构由于将片上网络细分了核间通信网络和片上缓存网络,从而有效提高了数据的并行传输能力,减少了平均通信延迟。

图4 网络平均延时比较Fig.4 Average network latency
4.3 网络吞吐量分析
网络的吞吐量定义为每个周期接收的Flit的数目,吞吐量越大网络在单位时间内接收的数据包越多,网络带宽就越大。在理想情况下,片上网络的带宽随着数据包注入速率的增长呈线性增长。然而,受到片上网络路由资源(路由器和片上互连线)等限制,网络在一定的数据包注入速率下达到饱和。图5显示了采用Uniform Random合成流量模式时三种设计方案对网络延迟的影响,图中横轴表示每时钟周期向网络中注入Flit的数量,纵轴表示每时钟周期接收的Flit数量。本文方案的吞吐量比同构对称双网络和单网络平均分别提升了14.86%和28.78%。
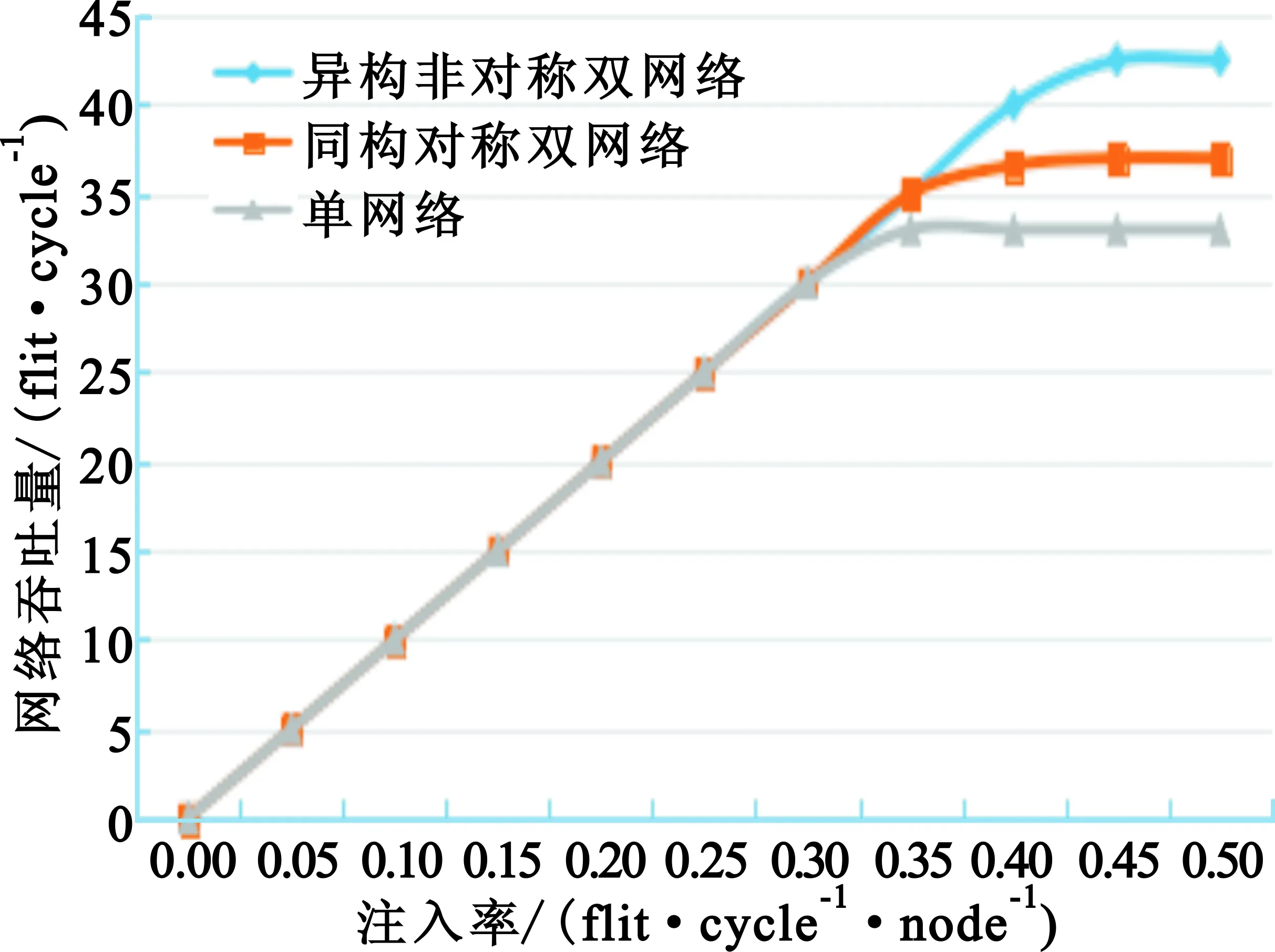
图5 网络吞吐量比较Fig.5 Average network throughput
4.4 系统性能分析
在真实负载测试中,本实验选择了常见的DB2、Oracle、APACHE、ZEUS四种服务器工作负载[9]。图6显示了系统整体性能,可见本文提出的异构非对称双网络设计优于同构对称双网络和单网络设计,分别是4.3%和6.1%,这充分说明针对网络数据流量特征的优化片上网络设计的必要性。

图6 系统整体性能比较Fig.6 Overall system performance
5 结束语
片上网络是多核处理器系统中的重要部件之一,直接关系着系统的整体性能。本文针对片上网络数据流量不平衡的特点,提出了一种异构非对称双片上网络的设计。区别于传统的单片上网络的设计,本文根据数据消息的种类,利用核间互连网来处理核间的短消息通信,利用缓存片上网络来响应数据请求。通过扩展的GEM5模拟器,分别搭建了同构双网络和异构双网络的实验平台,进行了高层次仿真,结果表明,异构双网络方案具有低网络延迟、高网络带宽的优点,对提升系统整体性能具有重要意义。
本文目前只对服务器负载程序进行了测试,后续还将对具有其他访存特征的工作负载进行测试。另外,后续研究还将考虑一种自适应的非对称网络调节方案,以更大程度提升系统性能。
:
[1] 李晨,马胜,王璐,等. 三维片上网络体系结构研究综述[J].计算机学报,2016,39(9):1812-1828.
LI Chen,MA Sheng,WANG Lu,et al.A survey on architecture for three-dimensional network-on-chip[J].Chinese Journal of Computers,2016,39(9):1812-1828.(in Chinese)
[2] 徐昌彪,王华,王珩,等. 信息中心网络中基于节点缓存命中贡献率的缓存替换方案[J].电讯技术,2017(3):311-315.
XU Changbiao,WANG Hua,WANG Heng,et al.A cache replacement scheme based on contribution to hit ratio of node in content-centric networking[J].Telecommunication Engineering,2017(3):311-315.(in Chinese)
[3] 胡森森,计卫星,王一拙,等. 片上多核处理器Cache一致性协议优化研究综述[J].软件学报,2017,28(4):1027-1047.
HU Sensen,JI Weixing,WANG Yizhuo,et al.Survey on cache coherence protocol and performance optimization for chip multiprocessor[J].Journal of Software,2017,28(4):1027-1047.(in Chinese)
[4] XU C,NIU D,MURALIMANOHAR N,et al.Overcoming the challenges of crossbar resistive memory architectures[C]//Proceedings of 2015 International Symposium on High Performance Computer Architecture. Burlingame,CA,USA:IEEE,2015:476-488.
[5] BINKERT N,BECKMANN B,BLACK G,et al.The GEM5 simulator[J].ACM SIGARCH Computer Architecture News,2011,39(2):1-7.
[6] WANG Y,JUAN S. Hamiltonicity of the basic WK-recursive pyramid with and without faulty nodes[J].Theoretical Computer Science,2015,562(C):542-556.
[7] HU S S,SHI F,CHEN X. Hybrid WK-recursive on-chip network for multi-core system[J].Electronics Letters,2017,53(13):839-841.
[8] BECKMANN N,TSAI P A,SANCHEZ D. Scaling distributed cache hierarchies through computation and data co-scheduling[C]//Proceedings of 2015 IEEE 21st International Symposium on High Performance Computer Architecture. Burlingame,CA,USA:IEEE,2015:538-550.
[9] JALEEL A,NUZMAN J,MOGA A,et al.High performing cache hierarchies for server workloads:Relaxing inclusion to capture the latency benefits of exclusive caches[C]//Proceedings of 2015 IEEE 21st International Symposium on High Performance Computer Architecture.Burlingame,CA,USA:IEEE,2015:343-353.
猜你喜欢
小学教学研究(2022年5期)2022-04-28
通信产业报(2020年43期)2020-01-15
数学年刊A辑(中文版)(2018年2期)2019-01-08
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
数学理论与应用(2016年4期)2016-05-17
通信电源技术(2016年6期)2016-04-20
电测与仪表(2015年4期)2015-04-12
中国卫生(2014年12期)2014-11-12
中国卫生(2014年8期)2014-11-12
