
异构计算环境下的三维 Kirchhoff叠前深度偏移混合域并行算法
2018-05-23 01:03王一达赵长海张建磊晏海华张威毅北京航空航天大学计算机学院北京100191中国石油东方地球物理公司物探技术研究中心河北涿州072751
石油地球物理勘探 2018年3期
王一达 赵长海 李 超 张建磊 晏海华 张威毅(北京航空航天大学计算机学院,北京 100191; 中国石油东方地球物理公司物探技术研究中心,河北涿州 072751)
1 引言
Kirchhoff叠前深度偏移(Kirchhoff Prestack Depth Migration,KPSDM)技术是地震数据处理中最重要的深度域成像方法之一。该方法高效灵活,且易于输出地下共成像点道集,被广泛应用于成像处理和速度分析。
近年来,随着勘探地质目标越来越复杂,高密度、全方位野外地震采集非常普遍,数百TB级数据总量的工区屡见不鲜,地震勘探正迈入PB级数据时代,地震资料处理周期越来越长[1],并行化势在必行[2]。然而在已知的偏移方法中,KPSDM的高效并行难度较大,其主要挑战来自执行过程中重复读取地震数据和旅行时场数据带来的巨大的输入/输出(I/O)开销[3]。对于当前宽方位三维观测系统,旅行时场一般能达到数TB的规模,每一个地震道对应的旅行时场不同,需要在计算时临时查询旅行时表,访问旅行时的I/O模式非常不规则,给旅行时数据的读写优化带来巨大的挑战。
在集群架构上,为满足不断增长的计算需求,当前地震数据处理中心单个集群已经达到了256~1000个节点的规模。随着可编程图形处理器(GPU)技术的不断发展,集群中的一部分计算节点会配有若干GPU协处理器来提升节点的计算能力。在这种大规模异构计算集群上,节点处理能力的一致性、硬件的可靠性假设都会失效。
GPU是一种高度并行的、多线程的众核处理器。相较于CPU,GPU能够提供更强的浮点计算能力。此外,根据Gao等[4]的研究,相比于只有CPU的服务器,配有GPU的服务器在单位能耗下能够提供更加强大的计算能力。GPU的这种优势使得其在高性能计算领域的应用越来越广。根据TOP500的统计数据,大约有15%的超级计算机都使用了GPU,并且提供了占TOP500中35%的计算能力[5]。在石油物探领域,通用计算GPU也得到了广泛的应用。例如Shi等[6]利用GPU对叠前时间偏移程序进行了加速,性能得到了明显提升。随着诸如CUDA[7]等GPU编程语言的发展,使用GPU进行通用计算也变得越来越容易,使得利用GPU加速KPSDM软件成为可能。然而受限于GPU的一些特性,例如显存空间有限、CPU-GPU之间数据传输速度的限制、多线程的执行模式等,传统的深度偏移的任务拆分方法并不能有效发挥GPU的计算能力。
鉴于以上原因,本文提出了异构计算环境下的KPSDM混合域并行算法,将传统的仅从成像空间进行任务拆分的方法,扩展到成像空间、输入数据两个域,消除了任务间的依赖关系,任务的粒度也更细。同时使用CUDA编程语言对偏移的核心算法进行移植,并根据GPU的特性实施了一系列优化,使得软件能够适用于大规模异构集群系统和复杂的共享运行环境,达到了运行时容错、高度可扩展、动态负载均衡的效果。
2 KPSDM计算复杂度分析
地震资料处理时首先在沿Inline和Crossline方向用一定的间隔对地震工区进行网格化,每一个网格称作一个面元,面元的划分以及孔径的说明见参考文献[8]。现代地震勘探多采用多次覆盖技术,在一次采集过程中每一个面元将被不同的炮检组合进行多次记录,所以三维勘探记录到一个4维数据,4维坐标分别是平面坐标x、y、时间t和炮检距h。
串行算法逻辑结构如图1所示,KPSDM的旅行时场是炮(检)点和地下空间点的函数,三维情况下旅行时场计算量很大。由于偏移过程中要反复使用旅行时,通常预先计算旅行时场,偏移时再根据炮检点位置检索旅行时。在旅行时场计算之后,对于每一个输入地震道,首先进行地震道的预处理,随后分别从线、CMP、输出道、输出样点四个维度循环进行偏移计算。
假设两个方向上的偏移孔径相等,对于r个面元,每个面元中有k个地震道,每个输出地震道的样点数为s,并将椭圆用圆形近似,则每个输入地震道的样点要映射到πr2ks个输出样点上,输入地震道数为n,则算法的时间复杂度是O(nr2ks)。近些年一个勘探工区采集数据已经达到几亿地震道,一个面元中的地震道从几十到数千个不等,每一道数据包含数千个样点,偏移孔径一般在几百米到上万米范围内,每一对样点的映射包括旅行时的查询与插值、振幅加权、反假频滤波、积分求和等计算。一般工区的旅行时场可以达到数TB的规模,在如此庞大的数据集内反复查询旅行时场,数据访问负载极高。
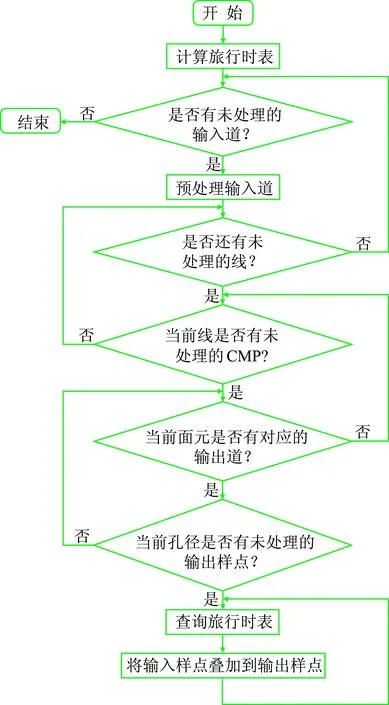
图1 串行算法逻辑结构
KPSDM并行算法设计的难点主要有以下两点。①如何利用内存和显存提升旅行时的检索速度。偏移的计算量与面元数成正比,而旅行时数据量与面元数也成正比,内存和显存的容量分别限制了CPU和GPU能够处理的最大面元数量。如果一个地震道的偏移计算量不够大,那么偏移计算的时间就会小于查询旅行时的时间,导致软件的性能受限于数据访问瓶颈,并且会降低处理器的资源利用率。②如何减少地震数据重复读取。成像空间与地震数据之间是多对多的关系,即成像空间中的每一个成像块,都是多块地震数据共同叠加的结果;而每一个地震数据块,都会参与到多个成像块的计算中。另一方面,成像空间与旅行时是一对一的关系,即成像空间中的每一个成像块都只需要相应的一个旅行时块。如果各个任务做同样的成像空间,对地震数据进行拆分,那么每个任务就需要重复读取同样的旅行时;反之,如果对成像空间进行拆分,每个任务就需要重复读取同样的地震数据。
3 现有KPSDM并行算法分析
已有的并行KPSDM算法并不能很好地适应不断增长的数据规模以及新的集群架构,主要表现在以下三个方面。
3.1 任务的拆分方法
Chang等[9]介绍了一种按Inline方向进行滚动偏移的方法,该方法是建立在“所有节点的内存之和大于一条测线上所有面元对应的旅行时”这个假设上,该方法在问题域上不具备扩展性,当测线对应的旅行时规模较大时,通常要求添加更多节点或者降低追踪点网格密度、减少测线旅行时对内存的需求。
王华忠等[10]和Rastogi等[11]提出按照深度方向切分成像空间,与Inline方向的切分没有本质区别,这种方法唯一的好处是便于过滤孔径外的地震数据,对于小孔径的偏移作业可以减少读取冗余地震数据,但实际应用中,小孔径作业并不常见。
Panetta等[12,13]采用边长可变的矩形块分解成像空间。这种任务拆分方法的优点是,任务间耦合度降低,但是旅行时和地震数据需要反复从单一存储上读取,重复读取的数据量与成像空间的分块数成正比,导致KPSDM并行程序的可扩展性与单个节点的计算能力成反比。可扩展性是指在存储和网络带宽既定的情况下,软件的运行效率随处理器数量的增加而线性地提高。该文献提供的算法受到存储带宽的限制,导致单个节点处理器核数越多,程序就越容易在节点数量比较少的时候达到I/O瓶颈。即使继续增加计算节点,程序性能的提升效果也不明显。
3.2 任务的调度、分配方案
在偏移阶段,部分实现会选择采用经理/雇员(Manager/Worker)架构来组织进程。将一条测线对应的成像面元在所有计算节点分开后,由Master节点从共享盘阵读取该测线输入范围内的地震数据,并广播给所有Worker节点,Worker节点接收到数据后对成像空间进行偏移。广播的副作用非常明显,即每个节点对应的成像空间不同,导致节点间的计算步调不一致,广播的同步副作用导致大量CPU时间被浪费。为了克服这些缺陷,Li等[14]提出采用进程组来缓解全局广播带来的副作用,但是由于在一个组内仍然需要进行广播,而且组间需要同步,在复杂的运行环境下,无法做到负载均衡。
3.3 I/O负载压力
为降低旅行时对内存空间的消耗,Cunhua等[15]提出了位编码压缩算法,利用旅行时在深度方向上连续性较好的特点,让每一个深度方向只存放三个原始的旅行时,其余旅行时采用4位二进制存放2阶段导数的值。试算发现该算法虽然能够达到3.5倍的压缩比,但是解压时间太长,与偏移的时间相当。Alkhalif[16,17]和Teixeira等[18]提出计算旅行时的时候降低网格密度、偏移的时候进行插值的方法,牺牲了旅行时场精度,对偏移质量有影响。并且由于旅行时场占用空间非常大,即使压缩几倍,依然有TB级的规模。盛秀杰等[19]基于谷歌文件系统的设计理念设计并实现了PetroV分布式存储系统,Li等[20]利用Hadoop的MapReduce编程模型对旅行时的排序进行优化,并且将地震数据和旅行时数据存放在HDFS(Hadoop分布式存储系统)上,从而降低了集中存储的数据访问压力。但是这种方法只是将部分数据的I/O转移到了额外的HDFS上,并没有从根本上解决数据重复读取的问题。
4 混合域并行算法设计与实现方案
并行算法及其实现的主要目标是在大规模集群系统上高效运行,计算系统的体系结构深刻影响着并行算法的设计,一个典型的地震数据处理中心计算系统具有如下特征:
(1)一般处理中心单个集群规模已经达到256个节点,大型处理中心的集群系统规模已经达到数千个节点;
(2)使用集中存储存放地震数据;
(3)计算节点是普通的双路x86服务器,至少配置1块本地盘存放临时数据,内存大小为64~256GB,万兆以太网或者Infiniband互联;
(4)GPU集群系统已经是常规配备,主要用于偏移计算,目前常见的配置是计算节点配置两个CPU、两块GPU。
异构集群的硬件体系结构可以参见文献[8]。KPSDM算法设计面向的是数千异构节点组成的大规模集群,任务的耦合度要低,便于运行时容错。KPSDM并行算法设计关键是要处理好三个并行层次:节点间的进程级并行、CPU内的线程级并行以及GPU内的数据级并行。任务拆分要保证并行层次间的数据局部性和层次内的可扩展性。还要处理好两类协同计算:协处理器之间、CPU与协处理器之间。不同处理器间的协同计算需要尽量保证计算任务之间的异步性与负载均衡。
4.1 并行算法设计
三维地震KPSDM输入数据可以用4维坐标表示,同样成像空间可以对应到4维空间I(x,y,t,h)。如果从炮检距维度拆分任务,则任务之间相互独立,方便进行并行化,但是这样的拆分方法对一个计算节点来说任务粒度过大,有三个原因:①作业中的炮检距一般只有几十个,总的任务数太少;②一个炮检距成像空间对应的旅行时场一般有数TB,由于对外存储的随机查询效率很低,因此一个任务的全部旅行时必须能够放入内存;③在单个节点内部,为了保证CPU与协处理器之间计算任务的异步性以及负载均衡,采用CPU与GPU处理相同面元的策略,并将任务对应的地震数据在两类处理器之间动态分配。这种策略要求一个任务的旅行时能够常驻GPU显存中,否则频繁地在内存与显存之间传输旅行时数据会严重影响软件性能。
基于以上原因,进一步把一个炮检距的成像空间分解为多个面元块。面元块对应的旅行时大小与面元数量是正比例关系,考虑到一般情况下显存会小于计算节点的内存,以显存中能够容纳的旅行时数据量作为划分任务的依据,确定单个任务包含的面元数量。
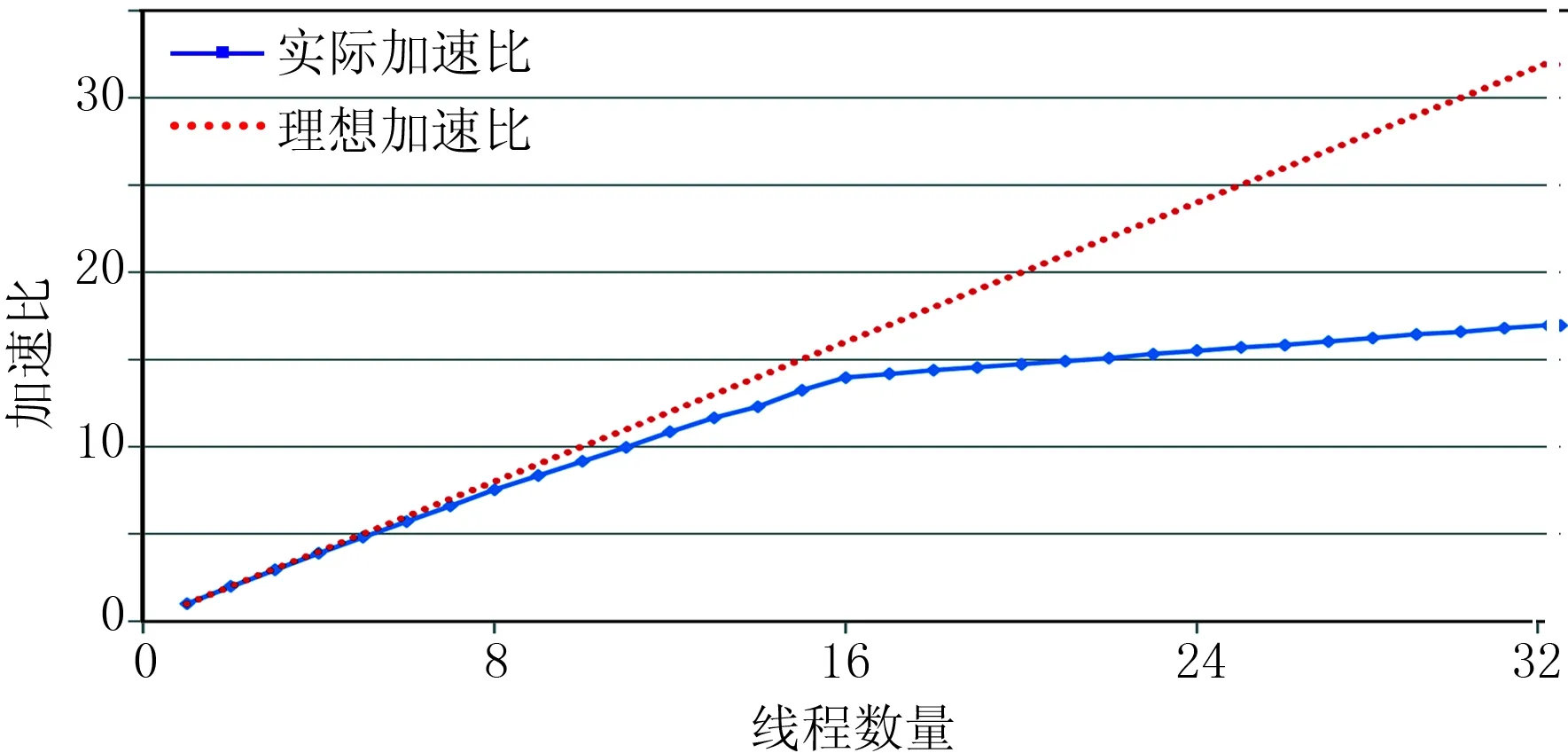
同时,将地震数据进一步拆分,把一个炮检距的地震数据拆分为多个数据块。假设数据块大小为d,单个任务的面元块对应的旅行时量为m,计算节点物理内存为M,需要满足:m+d 从成像空间、输入数据两个域进行拆分之后,一个偏移计算的任务就是炮检距h、面元块C和数据块D组成的三元组:Task(hi,Cj,Dk),每一个任务都是独立的,而且总的任务数足够大,能够满足大规模并行的要求。KPSDM并行算法的流程如图2所示。在旅行时场的计算完成之后,从炮检距、面元块、数据块三个维度进行循环,每一次循环就是一个独立的偏移任务。每个任务又对该面元块中的所有的输出样点循环进行偏移计算。 图2 本文的KPSDM并行算法流程 上述混合域任务拆分策略最核心的优势是便于利用本地内存和磁盘优化数据访问。上文已经介绍过,各个成像面元块与输入数据块之间是多对多的关系,因此所有的面元块都需要同样的输入数据。如果每个任务独立读数据,从集中存储重复读取的数据量与面元块数成正比。目前已知的算法通常采用广播加速重复数据的读取,但广播会带来任务间的同步、难以容错等问题。在本文的并行算法设计中,每一个任务将使用过的旅行时和数据块缓存在本地内存和磁盘,任务获取数据的优先级是:本地内存、本地磁盘、远程节点和集中存储。理想情况下,集中存储的数据只需读一遍,大大降低了集中存储的I/O压力。 为便于分析算法的I/O时间,假设每个炮检距对应的地震数据量相同,则理论I/O时间为 (1) (2) 式中: DS为地震数据量;DT为总的旅行时数据量;F为炮检距数量;α为节点间的网络传输速率和本地磁盘带宽的最大值;β为集中存储的吞吐率;n为作业节点数。 从式(2)可以看出,计算节点数越多,本地存储的聚合带宽越高,传输旅行时与地震数据的传输效率越高,从而解决了I/O对并行扩展性的限制。 对于旅行时计算的并行化实现,在上述任务拆分策略下,旅行时场的各个面元块的旅行时计算之间没有耦合性,按照轮询调度的方式将任务分配给各个计算节点。计算节点只需要在计算开始的时候读取一次速度场数据,速度场数据一般在几百MB到几GB之间,能够全部放入内存中,可以被多个计算任务重复使用。各个计算节点完成任务后将结果存放在集中存储上。由于旅行时计算的并行化策略比较简单,不再详细介绍,主要重点介绍偏移部分的并行算法实现策略。 4.2.1 节点间的并行任务调度 图3显示了节点间的并行任务调度策略,KPSDM实现采用Manager/Worker并行架构,每个计算节点只启动一个Worker进程,Worker进程内启用多线程共同完成一个任务。整个作业只有一个主节点上启动Manager进程,负责向各个Worker分配任务,单个任务单元为4.1介绍的Task(hi,Cj,Dk)。Worker进程收到任务后分别读取任务对应的地震数据并进行计算,然后将成像结果写回集中存储。 算法实现的第一个关键技术是负载均衡。实际用于地震数据处理的集群系统不仅仅是节点内的异构,还可能存在系统级的异构,即一个集群只有部分节点配置GPU,计算节点CPU型号与核数也可能不一致。KPSDM采用“动态异步”任务分发策略保障负载均衡,Worker进程维护一个任务队列,该队列只能存放一个任务,一旦任务被取走执行,Wor-ker就向主进程请求新的任务,并放入队列等待执行。计算节点的计算能力越强,请求任务的频度就越高,从而实现按计算能力分配任务的效果;任务在队列中等待的同时,可以预先将任务的地震数据与旅行时数据读到本地内存,实现等待任务I/O与当前任务计算异步执行的效果。 图3 节点间的并行任务调度 算法实现的第二个关键技术是用本地存储“扩展”集中存储的带宽。每个任务对应的地震数据与旅行时数据缓存在本地内存和磁盘,服务于其他需要同样数据的任务,同一份数据有可能在多个计算节点上存在,主节点记录根据每个节点的负载状况,选择最空闲的节点提供数据服务。每个计算节点既作为数据的提供者,又作为消费者,发挥网络的双向带宽,节点越多I/O聚合带宽越高,保障了KPSDM程序的可扩展性。 算法实现的第三个关键技术是运行时容错。对于大规模集群系统来说,计算节点发生硬件或者软件故障的概率会非常高[21]。基于检查点的容错一方面I/O开销太大,与节点规模成正比[22],此外需要重启整个应用也带来很差的用户体验。为此,开发了新的并行与分布式编程模型(Geophysical Pa-rallel Programming,GPP)[23]替代MPI,能够支持应用程序实现运行时任务迁移。GPP运行时系统周期性检测作业进程的健康状况,一旦某进程发生故障,采用事件机制向所有进程报告发生故障的进程号。KPSDM主节点负责捕获故障事件,将所有分配给故障Worker且没有执行完的任务,重新分配给其他Worker。 算法实现的第四个关键技术是慢节点的处理。慢节点也是大规模集群中常见的问题,借鉴Map-Reduce框架的“任务备份”[24,25]策略处理慢节点可能拖延作业运行时间的问题。在所有任务分配完毕后,测算已经完成任务的平均执行时间,假设平均完成时间为t,如果任务运行时间超过λt,向空闲Worker分配该任务作为备份,其中λ的值一般设置为2,太小会过于灵敏,产生过多的备份任务会造成很高的I/O负载,影响整体性能。 4.2.2 节点内的并行策略 在单个节点内部,由于有GPU参与计算,需要在GPU和CPU之间进行任务的分配,以保证最大化地发挥整个计算节点的计算性能。GPU的计算需要先将需要的数据通过PCIE总线(外围设备互联总线)从内存传输到显存中。相比于GPU的强大的计算能力,CPU-GPU之间的数据传输带宽往往成为软件的性能瓶颈。因此要尽可能降低显存内数据切换的频率,减少数据传输的开销。 本文的CPU与GPU之间的并行策略如图4所示。节点收到一个成像任务后,CPU和GPU处理相同的面元块。计算前需要先将该任务对应的旅行时块加载到内存中,随后利用CUDA的数据传输接口,将这个旅行时块一次性地通过PCIE总线传输到GPU的显存中。任务对应的地震输入数据在CPU和GPU之间动态分发,最后将CPU和GPU的计算结果叠加输出。这种分配策略的好处是,由于在计算节点的内存和本地磁盘上缓存着大量的输入地震数据,因此将旅行时传入显存之后,充足的输入数据能够保证GPU在计算足够长的时间之后再进行旅行时数据的切换。另外,在节点间的任务分配中,使用了一些优化措施,使得相同面元块的偏移任务尽可能地调度到同一个节点上,这样即使更换了新的偏移任务,内存和显存中的旅行时场仍然可能被重复使用,进一步减少了GPU中旅行时数据切换的频率,处理器利用率更高。 在CPU多核之间的并行策略是,每个CPU核启动一个线程,采用轮询调度的方式将面元均分给计算线程,保证每个线程分到等量的计算任务,降低线程之间的同步开销,所有线程共享输入数据,可以提升缓存命中率。微架构方面另外一个重要的优化是向量化,生产用的代码里面存在比较多的条件分支,是向量化的最大阻碍,必须综合应用代码各种优化方法移除条件分支,将KPSDM核心代码进行充分向量化之后,整体性能至少提升一倍。 当节点配备了多个GPU时,各个GPU之间均分面元,与CPU核间的任务划分方式相同。对于GPU上的计算并行,使用CUDA编程语言实现偏移的核心算法,并且根据GPU的特性以及CUDA的规则从以下几个方面进行了优化。 第一个优化策略是任务的CUDA线程之间的任务划分。对于GPU协处理器,需要在面元的基础上将任务粒度进一步细分。CUDA中每32个线程被组织成一个线程组(Warp),每个面元内的输出地震道由一个Warp线程配合完成,每个线程计算一部分输出样点。采用这种GPU任务划分方法,一方面可以产生足够多的任务,提高处理器利用率;另一方面,同一个Warp中的线程访问的地震数据位于连续的128字节对齐的显存块中,访问模式符合GPU中全局内存(Global Memory)的合并访问规则,可以通过一次访存操作满足所有线程的读取请求,如图5所示。 图4 CPU-GPU协同计算 图5 全局内存的合并访问 第二个优化策略是利用纹理内存(Texture Memory)加速地震数据的访问。纹理内存中的缓存机制能够提供比全局内存更快的数据读取速度,但是其存储容量比较小,并不适合对显存内大块的旅行时数据进行加速;另外,纹理缓存的数据是只读的,也不适合存放成像结果数据。地震输入数据在显存中所占的空间较小,而且在计算过程中要被所有的计算线程只读访问,适合利用纹理内存提高访问速度。 第三个优化策略是减少每个线程使用的寄存器数量,提高处理器的利用率。每个GPU设备只提供数量有限的寄存器,因此每个线程要求的存储单元越多,处理器中能够驻留的计算线程就越少,处理器的利用率也就越低。实现中,由于CUDA函数的参数列表中的参数占用了大量的寄存器,因此将参数列表中的一部分参数,尤其是一些在软件运行过程中不会被改变的指针变量,都存放在常量存储器中,大幅减少了寄存器的使用数量。 第四个优化策略是利用CUDA流(Stream)隐藏内存到显存的数据传输延迟。在偏移计算过程中,尽管旅行时数据可以长时间驻留在显存中,GPU处理器仍然需要等待输入地震数据依次从内存传输到显存中之后才能执行偏移计算过程。CUDA的Stream原理如图6所示,单个Stream中的传输和计算必须按顺序执行,但是相邻的不同Stream中的传输和计算过程可以并行执行。如果计算量足够大,GPU的计算时间就能够“覆盖”数据传输的时间,隐藏数据传输的延迟。 图6 CUDA的Stream隐藏数据传输的延迟 在实际生产中发现GPU也会发生两类常见的故障: ①检测不到GPU; ②虽然检测到GPU,但运行程序崩溃,主要是由硬件Bug引起,在较新的GPU内比较常见。因此,GPU的容错非常必要。由于CPU和GPU间的任务耦合性非常低,可以采用一种简单有效的容错策略:调用GPU之前,进行一系列简单的快速测试,如果测试不通过,只用CPU做成像任务。 实验集群有256个计算节点,每个节点配置2路8核Intel E5-2670 CPU,128GB内存,2块500GB的高速HDD(硬盘驱动器)本地盘做RAID0(磁盘阵列)。节点间50GB/s的Infiniband网络互连。共享存储采用GPFS并行文件系统,实测最高并发吞吐率为4GB/s,超过2GB/s读延迟会显著增加。 实验选用中国东北某工区数据片段,共134GB,约2292万道,每道有1501个样点;共79591个面元;炮检距共73个;总的旅行时场数据量为466GB;每一个面元块有943个面元,对应的旅行时场数据量为20GB;数据块大小为51GB。 实验作业共生成4250个任务,表1列举了作业运行期间分别从共享存储和本地存储读取的数据量,作业使用32~128节点时,只缓存地震数据,旅行时I/O依然在共享存储;超过128个节点,共享存储成为瓶颈,地震数据与旅行时场都启用缓存机制。 表1 运行时数据来源分布 从表1可以看出,作业运行期间共产生了32TB左右的数据输入量,相比原始输入数据,扩大了53倍,未启用旅行时缓存时,本地存储分担了90%的I/O压力,若将地震数据与旅行时场的缓存机制完全打开,可以分流97%的I/O。共享存储与本地存储的平均读速率如图7所示,作业节点数达到128个节点时,本地存储总的读速率为13.3GB/s,平均每个节点只需要达到106MB/s的读速率就可以满足;共享存储的读速率为1.4GB/s,如果再增加作业节点,旅行时的读延迟就会增加,共享存储就会成为性能瓶颈。打开旅行时场的缓存机制后,KPSDM能够继续加速,最多使用237个节点时,总的平均读取速率为19.3GB/s,均摊到每个节点只有83MB/s。 图7 共享存储与本地存储的平均读速率 由于分布式的本地存储提供了极高的聚合带宽,KPSDM程序的可扩展性非常好(图8),甚至出现了超线性加速的情况。出现超线性加速比的主要原因是节点增多后,数据的负载更加均衡,读取数据延迟更低。超过192个节点之后加速放缓的原因是作业运行时间变短、作业收尾时间占比增加。 图8 节点并行的执行时间与加速比 计算节点共16个物理CPU核,32个超线程,线程级的可扩展性测试结果如图9所示。当线程数量从1变化到7时,保持着接近线性的加速比,而从8变化到16时,实际加速比曲线与理想加速比曲线的差距越来越大。造成这种情况的主要原因是每个线程在计算时,读取不同的旅行时场,各个线程之间可以共享的数据非常少,造成三级缓存的命中率随着线程数量的增多而降低。从16个线程增加到32个线程时,程序依然在加速,根据图中的数据可以测算,超线程技术对KPSDM的性能提升了近22%。 图9 线程级并行的可扩展性 为了验证CPU与GPU的协同计算效果,分别使用了NVIDIA的Tesla K40和Tesla K80的GPU测试在单个节点上CPU与GPU在多种组合策略下的性能加速情况,结果如图10所示,可以看出:当搭配单个K40的GPU时,软件性能比仅使用CPU时提高了1.1倍; 当搭配单个K80的GPU时,软件性能比仅使用CPU时提高了2.14倍; 理想状态下,当搭配两个K80时,软件性能应该能够提高4倍以上。然而实际测试显示,使用两个K80时程序性能只提高了3.69倍,因为此时CPU-GPU之间的传输已经成为瓶颈,得不到充足的数据供应,处理器的利用率降低,因而影响了加速比。 图10 CPU-GPU协同计算加速效果 为了提高CPU-GPU之间的数据传输效率,NVIDIA公司已经提出了一种新的高带宽且节能的数据传输方案NVLink[26],其传输速度能够达到传统PCIE3.0速度的5~12倍。这项技术已经被应用在NVIDIA新的Pascal架构的GPU中。因此未来如果搭配使用NVLink传输方案的GPU,将能够获得更好的加速效果。 本文提出了一种异构计算环境下的KPSDM混合域并行算法。该算法从炮检距、成像空间、输入数据三个域拆分任务,保证了任务之间没有耦合,便于实现运行时容错与慢节点处理;另外,根据内存或者显存空间来确定任务大小,保证了任务的数量足够多,有利于充分利用大规模集群的计算资源,实现负载均衡。 对于巨量的地震数据与旅行时场带来的数据I/O问题,利用本地内存和磁盘缓存数据,降低了共享存储的压力。本地内存和磁盘的聚合带宽为KPSDM的可扩展性提供了强有力的保障。实验结果显示,对于实际的地震数据资料,并行KPSDM软件能够在256节点的集群上获得接近线性的加速比,表明该算法具有良好的扩展性。 对于拥有GPU的计算节点,任务能够在节点内部以地震道为粒度进一步拆分,实现CPU与GPU间的动态负载均衡; 同时根据GPU以及CUDA编程语言的特性,从数据传输、数据访问以及处理器利用率等几个方面对GPU上的核心算法进行优化,充分发挥了GPU的计算能力。实验结果显示,搭配使用GPU后,单个节点的程序性能提升达3.69倍,并且在未来新的GPU架构下,仍有上升空间。 参考文献 [1] Addair T G,Dodge D A,Walter W R et al.Large-scale seismic signal analysis with Hadoop.Computers & Geosciences,2014,66(5):145-154. [2] 罗刚,陈继红,孙孝萍等.大规模异构集群地震作业调度与资源管理系统的设计与实现.石油地球物理勘探,2017,52(增刊2):200-205. Luo Gang,Chen Jihong,Sun Xiaoping et al.Heterogeneous cluster scheduling and resource management system for a large number of seismic data processing jobs.OGP,2017,52(S2):200-205. [3] 荣骏召,芦俊,李建峰等.矢量Kirchhoff叠前深度偏移.石油地球物理勘探,2017,52(6):1170-1176. Rong Junzhao,Lu Jun,Li Jianfeng et al.Vector pre-stack depth migration based on Kirchhoff integral equation.OGP,2017,52(6):1170-1176. [4] Gao Y,Iqbal S,Zhang P et al.Performance and power analysis of high-density multi-GPGPU architectures:A preliminary case study.IEEE 17th International Conference on High Performance Computing and Communications (HPCC),2015,66-71. [5] Jack D,Erich S,Horst S et al.Top 500 List.http://www.top500.org/,2017. [6] Shi X,Li C,Wang S et al.Computing prestack Kirchhoff time migration on general purpose GPU.Computers & Geosciences,2011,37(10):1702-1710. [7] NVIDIA.Cuda C Programming Guide.http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html,2013. [8] 赵长海,罗国安,张旭东等.大规模异构集群上Kirchhoff叠前时间偏移并行算法.石油地球物理勘探,2016,51(5):1040-1048. Zhao Changhai,Luo Guoan,Zhang Xudong et al.Kirchhoff prestack time migration on large heterogeneous computing systems.OGP,2016,51(5):1040-1048. [9] Chang H,Van Dyke J P,Solano M et al.3-D prestack Kirchhoff depth migration:From prototype to production in a massively parallel processor environment.Geophysics,1998,63(2):546-556. [10] 王华忠,刘少勇,孔祥宁等.大规模三维地震数据 Kirchhoff 叠前深度偏移及其并行实现.石油地球物理勘探,2012,47(3):404-410. Wang Huazhong,Liu Shaoyong,Kong Xiangning et al.3D Kirchhoff PSDM for large-scale seismic data and its parallel implementation strategy.OGP,2012,47(3):404-410. [11] Rastogi R,Srivastava A,Khonde K et al.An efficient parallel algorithm:Poststack and prestack Kirchhoff 3D depth migration using flexi-depth iterations.Computers & Geosciences,2015,80(7):1-8. [12] Panetta J,de Souza Filho P R P,Da Cungua Filho C A et al.Computational characteristics of production seismic migration and its performance on novel processor architectures.19th Symposium on Computer Architecture and High Performance Computing (SBAC-PAD 2007), IEEE,2007,11-18. [13] Panetta J,Teixeira T,de Souza Filho P R P et al.Accelerating time and depth seismic migration by CPU and GPU cooperation.International Journal of Parallel Programming,2012,40(3):290-312. [14] Li J,Hei D,Yan L.Partitioning algorithm of 3-D prestack parallel Kirchhoff depth migration for imaging spaces.Eighth International Conference on Grid and Cooperative Computing,2009,276-280. [15] Cunha C A,Pametta J,Romanelli A et al.Compres-sion of traveltime tables for prestack depth migration.SEG Technical Program Expanded Abstracts,1995,14:180-183. [16] Alkhalifah T.The many benefits of traveltime compression for 3D prestack Kirchhoff migration.68th EAGE Conference & Exhibition Extended Abstracts,2006. [17] Alkhalifah T.Efficient traveltime compression for 3D prestack Kirchhoff migration.Geophysical Prospecting,2011,59(1):1-9. [18] Teixeira D,Yeh A,Gajawada S.Implementation of Kirchhoff prestack depth migration on GPU.SEG Technical Program Expanded Abstracts,2013,32:3683-3686. [19] 盛秀杰, 金之钧, 彭成.PetroV分布式数据存储与分析框架设计.石油地球物理勘探,2017,52(4):875-883. Sheng Xiujie,Jin Zhijun,Peng Cheng.PetroV distri-buted-data storage and analytics framework design.OGP,2017,52(4):875-883. [20] Li C,Wang Y,Yan H et al.High performance Kirchhoff pre-stack depth migration on Hadoop.Procee-dings of the Symposium on High Performance Computing,Society for Computer Simulation International,2015,158-165. [21] Schroeder B and Gibson G A.A large-scale study of failures in high-performance computing systems.IEEE Transactions on Dependable and Secure Computing,2010,7(4):337-350. [22] Cappello F,Geist A,Gropp W et al.Toward exascale resilience:2014 update.Supercomputing Frontiers and innovations,2014,1(1):5-28. [23] 赵长海,晏海华,王宏琳等.面向地震数据的并行与分布式编程框架.石油地球物理勘探,2010,45(1):146-155. Zhao Changhai,Yan Haihua,Wang Honglin et al.Seismic data processing oriented parallel and distributed programming framework.OGP,2010,45(1):146-155. [24] Dean J and Ghemawat S.MapReduce:simplified data processing on large clusters.Communication of the ACM,2008,51(1):107-113. [25] Qi C,Cheng L and Zhen X.Improving MapReduce performance using smart speculative execution strategy.IEEE Transactions on Computers,2014,63(4):954-967. [26] NVIDIA.NVIDIA NVLink.http://www.nvidia.com/ object/nvlink.html,2016.
4.2 并行算法实现




5 实验结果与分析
5.1 可扩展性与数据吞吐分析



5.2 节点内的并行测试与分析

6 结论
猜你喜欢
山西电子技术(2021年3期)2021-06-28
科技创新导报(2021年31期)2021-05-10
网络安全技术与应用(2020年1期)2020-01-07
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
环球市场(2017年36期)2017-03-09
电脑知识与技术(2016年28期)2016-12-21
现代电子技术(2016年15期)2016-12-01
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
电脑爱好者(2015年21期)2015-09-10
