
改进型迭代Web挖掘技术在信息门户建设中的应用研究
2016-12-21 10:09刘啸
电脑知识与技术 2016年28期
关键词:并行算法
摘要:高校在进行信息化系统建设时,关注点放在信息门户建设和优化两个方面。运用Web数据挖掘技术,找到用户真正关注、需要的内容,就是系统设计人员所关心的信息门户的优化问题。该文通过引入本地计算思想,将迭代式的数据挖掘算法进行扩展。使用该数据挖掘算法,研究和设计了一种基于此算法的数据挖掘模型,并以某高校信息门户中日志数据为数据源,进行数据准备,以本算法进行热门路径分析和频繁项目集挖掘。根据挖掘结果,进行实际分析,提出完善信息门户建设的建议。
关键词:信息门户;Web挖掘;迭代算法;并行算法;本地计算
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)28-0006-03
Abstract: In the information system construction in colleges and universities focus on information portal construction and optimization of two aspects. Use Web data mining technology, find out what users really concern, need, is the system designers care about information portal of optimization problems. In this paper, by introducing the local computation of ideas, to expand an iterative algorithm to data mining. Using the data mining algorithm, research and design a data mining model based on this algorithm, taking the university information portal log data as the data source, data preparation, this algorithm is a popular path analysis and frequent itemsets mining. According to the mining results, actual analysis, put forward the perfect Suggestions for the development of information portal.
Key words: Information portal; Web mining; iterative algorithm; parallel algorithmic; local computing
1 数字化校园与信息门户建设的现状
数字化校园的概念是利用计算机、通讯、网络等技术,对学校中教学、科研、管理以及生活服务有关的所有信息资源进行全面的数字化,进而运用科学规范的管理对这些数字化资源进行整合和集成,实现功能应用、用户信息管理、用户权限和资源分配的统一[1]。进入21世纪,各个高校都开展了自己的数字化校园建设工程。
数字化校园建设一般可分为三个阶段。第一阶段,主要是校园网建设和一些局部范围的网络应用系统建设。第二阶段,除了对校园网进行全面升级,在管理信息系统和信息服务系统建设方面做了大量工作,在这一阶段各种功能的系统如雨后春笋般应运而生。通过第二阶段的建设,虽然高校管理信息化水平明显提高,但是各种各样的应用系统、海量的信息以及众多的服务,让用户面对时显得头晕脑胀。有的时候一项工作往往涉及多个系统,于是用户需要反复登录到不同的应用系统中。同时,各个应用系统之间又都是异构的,无论是后台操作系统、数据库服务器,还是前台的开发工具都存在很大差别。这样的现状对于提高管理水平、共享信息资源、实施科学管理都构成了障碍。第三阶段,信息化建设的全面规划与建设阶段。其中最为常见的做法就是规划建设各个高校自己的信息门户网站[2]。信息门户能够提供服务、进行信息展示、实现外部访问的接入。对各个信息应用系统而言,门户是一个出口,通过它各个应用功能向用户提供其所需的数据和服务;而对于用户来说,门户就像通往整个信息化校园的一扇门,单点登录功能使得用户登录门户后获得与身份相匹配的各功能子系统所提供的交互式服务,同时还可完成与其他用户的信息交流。个性化服务是门户系统另一大优势,信息门户应该向不同属性的用户组别智能化地提供不同的信息资源,使得用户能够在最短时间内获得有效的服务。
然而,随着信息门户的广泛应用,如何进行有效的信息集成将会成为新的热点。我们要不断地根据不同用户的需要进行信息的组织,以实现精准数据、用户、权限、应用、流程、内容等各个方面的高度整合。信息门户这个看似简单的Web页面背后蕴含了数字化校园建设的核心内容。因此,如何将Web数据挖掘的思想和方法应用到信息门户中,帮助设计人员从海量的信息中发现抽取有价值的内容,成为了高校信息门户建设中的一个热点方向。
2 Web数据挖掘技术在信息门户建设中的应用分析
数据挖掘(Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(Knowledge-Discovery in Databases)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程,其通过统计、在线分析处理、情报检索、机器学习、专家系统和模式识别等诸多方法来实现上述目标。
Web数据挖掘(Web Data Mining)是建立在对大量的网络数据进行分析的基础上,进行数据的提取、筛选、转换、关联规则挖掘和模式分析,最后做出经验性的判断[3]。Web数据挖掘是面向发现的数据分析技术,对文档的内容、可利用资源的使用以及资源之间的关系进行分析,用以预测客户的个性化行为以及用户习惯,从而帮助进行决策和管理,减少决策的风险。
Web数据挖掘技术的主要功能是实现网络数据的智能化处理,从而能够利用有效的数据挖掘技术,收集、获取感兴趣的信息,得到和抽象出大量信息的关系模型,挖掘出更深层次的信息[3]。高校在进行信息化建设时,关注点放在信息门户的建设和优化两个方面。信息门户网站是基于网络技术的一种新的高校管理平台构架,平台中的信息可以说是海量的。如何能从门户页面背后精准地找到用户真正关注、需要的内容,就是系统设计人员所关心的信息门户的优化问题[4]。将数据挖掘的思想和方法应用到高校信息门户中,可以获得各类型用户的信息反馈、不同类型用户的共同特征、页面的访问频度、访问时间、访问路径等信息,帮助信息门户建设的设计人员从海量的信息中得到真正有价值的知识,以指导他们的决策,为提高信息门户服务性提供依据。Web数据挖掘技术,就旨在发现隐藏在Web数据中潜在的有价值的信息,通过对日志、内容、结构进行数据挖掘,挖掘出有用的知识模式,从而为设计人员提供决策支持,进而完善信息门户建设。
高校信息门户是在不停发展的,大致分为四个阶段:
① 单的门户:只能集合单个的网络地址
② 信息门户:实现基于内容过滤、定向搜索的信息平台
③ 应用集成门户时代:实现应用集成和单点登录
④ 信息集成门户时代:实现应用整合、内容整合、信息整合、流程整合以及用户协作。
由此可见,进入信息集成门户时代,如何做好整合工作就成为信息门户建设领域中新兴的研究热点。为构建一个好的信息门户网站就要求设计者能够根据不同类型使用者的需要来组织内容,实现数据、用户、权限、应用、流程、内容等各个方面的整合达到较高程度。
信息门户中,通常被用于Web数据挖掘的数据来源有:服务器日志数据、代理服务器端数据、Web页面内容以及Web页面超链接关系信息以及用户登记信息。
① 服务器日志数据:用户浏览Web服务器时,会产生Servicelogs、Errorlogs和Cookie logs三种类型的日志文件。
② 代理服务器端数据:信息门户的服务器日志记录了用户对信息门户网站的访问,而通过代理服务器日志,还可以了解用户对其他网站的访问情况。这有利于搜集用户关心的信息,从而将这部分信息加入到门户网站中,提高门户网站的服务性和吸引力。
③ Web页面内容以及Web页面超链接关系信息。
④ 用户登记信息:高校信息门户较一般的门户网站,用户分类较为明显。包括学生用户、教管用户、教师用户等,而这些都可以通过让用户直接填写登记信息准确掌握。如果将用户登记信息与访问日志相结合,将能更大提高数据挖掘的准确度。
搜集到这些数据后还不能直接进行数据挖掘,需要对数据进行预处理。通过数据预处理得到简洁的精准数据。数据预处理包括:
① 数据清理:消除无关项,缩小被挖掘对象的范围。用户在访问过程中对图片、视频等资源的下载也会被记录到日志中,在数据挖掘前对这些冗余的记录进行清理,采用删除特定后缀的日志记录方法。对采集的日志中扩展名为.jPg,.CSS等日志记录直接删除。
② 用户唯一性识别:用以识别使用同一主机或代理服务器的不同用户。用户口和日志中的Cookie logs虽然都可以用于分辨用户,但在实际情况下以此不能准确确定每个用户。通过制定规则,简化用户唯一性的识别,规定将不同m的访问认为是不同用户,相同m采用不同操作系统或浏览器视为不同用户。由此,近似的实现用户唯一性识别。
③ 用户会话识别:用以将每个用户的访问信息划分为对立的会话进程。用户会话S(user session)是一个二元组
④ 完善访问路径:用以补充由于用户通过本地缓存访问网页时造成的路径信息不完整的情况。当用户请求的页面与上一次请求的页面之间无超链接,通过历史引用日志判断当前请求来自的页面。由此将没有记录的页面请求补充到访问序列中,完善访问路径。
⑤ 事务识别:用以根据挖掘任务的需求将事务作分割或合并处理。
3 基于改进型迭代算法的web数据挖掘思想
1) MapReduce模型
MapReduce是一种高效的编程模型,它依托于分布式计算系统,能够对大规模数据集的处理提供支持。为了实现合理的任务调度,该模型会对计算任务进行进一步的细化和分解,细化后的子任务能够智能化地探测各节点的计算能力,选择合适的节点来对分配的数据进行处理,以提高整个系统的效率。
2) 多服务器并行算法
由于智能移动通信设备的普及,如今的网络应用数据量呈几何级增长,使得Web挖掘面临计算和传输的双重压力,在很多应用场合单一的远程服务器已不堪重负,多服务器并行计算势在必行。多服务器并行算法的基本思路是,将所有的计算过程细化分解再分配到分布式服务器上,通过互联网,所有计算进程以服务的方式对用户需求进行支持[7]。众所周知,网络传输速度和进程计算速度不在同一个数量级,所以计算与存储统一整合有利于网络系统的数据处理,让分布式集群本地保存输入数据,能够大大降低数据传输开销。
3) 改进型迭代算法
关联规则的挖掘通常包括2个步骤,一是频繁项集的查询,二是分析频繁项集得到关联规则[7]。本算法关注的是频繁项集的查询,过程如下。
① 设置置信度最低阀值和支持度最低阀值。
② 查询空闲节点:分析并明确挖掘任务需求,任务调度中心向节点域请求节点计算性能情况,得到服务节点的信息。将得到的服务节点信息发送给算法存储单元。
③ 获取局部项集:服务节点对各个本地的数据库进行扫描,得到事物数目、项出现频率,然后通过下面算法得到局部候选项集1:
a) frequent=new find_frequent_1-itemsets();
b) gen=new apriori_gen();
c) L1=Frequent (D);
d) for(k=2;Lk-1≠Φ ;k++) {
e) Ck=gen(Lk-1, sup_min);
f) for each node t ∈ D{
g) Ct=subset(Ck,t);
h) for each candidate c ∈ Ct
i) c.count++;}Lk ={c ∈ Ck|c.count≥sup_min} }
j) return L= ∪ k Lk;
k) 其中,以k-itmeset代表K维项目集;LK代表具有最小支持度的最大项目集;Ck代表候选最大项目集。
④ 局部项集算法进行迭代:上一步得到了局部候选项集1,将其发送至主控节点可以计算出全局项集1,再通过全局频繁项集1,发送到服务节点得到精度更高的局部频繁项集1,而局部项集2可以由局部项集1得到。再一次迭代执行挖掘流程及局部项集算法,扫描本地数据库,得到项的出现次数,新局部候选项集2及结果发送至主控节点[7]。最终得到满足所需的频繁项集,根据置信度阈值得到关联规则[7]。
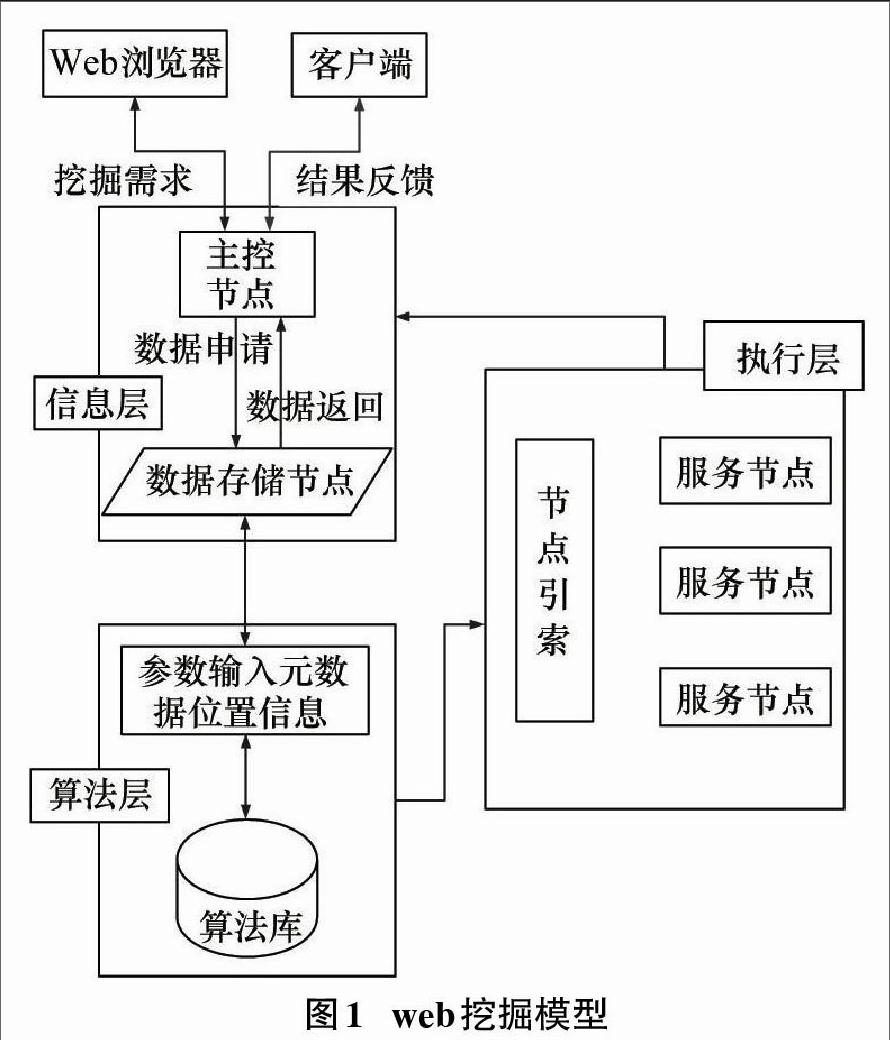
4) 基于改进算法的Web 挖掘模型
本模型中所有计算服务进程通过主控节点进行调度和管理,数据存储节点负责提供具体的挖掘方法。服务节点的职责是将其可实现的功能及本节点的性能资源情况进行统一模式化并存储进XML文件,并进行智能化处理。主控节点掌控全局,根据服务节点的处理得到最终的结果。整个系统分为3层:信息层、算法层和执行层。信息层对用户挖掘需求进行获取、分析和研判,生成挖掘算法特性需求;算法层实现相应的挖掘算法,并根据算法需求调取适用算法并传递给执行层;执行层进行数据挖掘得到结果并返回给信息层主控节点[7]。模型如图1所示。
4 结论
信息门户建设工作目前在广大高校中正迅速铺开,但大多还处于起步阶段。对于基础数据的收集和共享数据库的完善仍需要一段时间才能完成,在这项工作中必须要面对的一个问题就是数据的选择问题,这也是数据挖掘的另一用武之地。
本文基于传统迭代方法原理,结合MapReduce和多服务器并行算法思维,提出了一种改进型迭代算法,并根据此算法提出了一种网络挖掘系统架构模型,力求提高web数据挖掘效率,并运用此技术对门户网站上的各种数据源进行挖掘,找到相关的一些知识模式,以指导网站管理员更好地运作站点和向用户提供更好的服务。
参考文献:
[1] 李军怀, 周明全, 耿国华, 等. XML在异构数据集成中的应用研究[J].计算机应用, 2002, 22(9): 10-12.
[2] 程苗. 基于云计算的Web数据挖掘[J]. 计算机科学, 2011(增1): 146-149.
[3] 管忆军, 王勇, 何德牛. 一种采用函数迭代运算的数据流挖掘方法[J].广西民族大学学报, 2012, 18(1): 45-49.
[4] 彭宏玉, 柴旭光, 陈晓纪. 基于层次迭代思想的聚类算法的研究[J]. 唐山学院学报, 2011, 24(3): 86-87, 91.
[5] 赵洪英, 蔡乐才, 李先杰. 关联规则挖掘的Apriori算法综述[J]. 四川理工学院学报: 自然科学版, 2011, 24(1): 66-70.
[6] 赵虎. 云计算环境下的关联数据挖掘算法实现[D]. 成都: 电子科技大学, 2011.
[7] 刘啸,刘玉龙. 基于改进型迭代算法的web数据关联规则挖掘.科技导报,2015,33(3):90-94.
猜你喜欢
中国新通信(2019年21期)2019-03-30
南方农业·下旬(2017年10期)2017-12-18
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
数学理论与应用(2016年4期)2016-05-17
电子设计工程(2014年18期)2014-02-27
中国信息化·学术版(2013年6期)2013-09-30
科教导刊(2009年13期)2009-01-18
