
基于MPI并行算法的农作物生长环境的数据分析
2017-12-18 11:34李得原
南方农业·下旬 2017年10期
李得原
摘 要 为了提升作物生长模型的运算速度,MPI并行算法由于自身所具有的优越性而被广泛地应用。基于此,对MPI并行计算的农作物生长环境的数据展开分析。首先,概述MPI并行计算方法,然后分析MPI并行算法在农作物生长环境的数据应用情况。
关键词 MPI;并行算法;农作物;生长环境;数据
中图分类号:TP301.6 文献标志码:B DOI:10.19415/j.cnki.1673-890x.2017.30.063
最近几年,作物模型的地区性运用需求持续性递增,被广泛地运用在地区性生产力预测与预警、气候改变走向研究中。作物模型在地区性的运用过程中,需与气象模型、生态环境模型以及GIS等主要技术相整合,同时受到地点、参量以及时段等多种因素的共同作用,一般会出现模型运算量的剧增,模型驱动式变量的数据量变多以及运算时间偏长等问题[1],因而,如何借助分布式计算环境来增强作物模型在多个时间段、多个地点以及多个尺度环境的运算性能,是作物模型范围内急需解决的一个难题。而MPI则是其中重要的计算工具,本文正是据此来对农作物生长环境的数据展开分析。
1 MPI并行计算法概述
MPI并行计算法是一类根据信息传输的并行式编程技术。传输消息接口是一类编程接口标准,而非具体化的编程语言。换言之,MPI界定了一组具备可移植性编程接口[2]。此计算方法具备PVM的大多数优点之外,同时还拥有如下的特征:第一,实现途径多样,且适用于数类研发工具与基础性的研发语言;第二,有效地对消息缓存区加以管理;第三,在数类并行计算机系统结构中有效地运作;第四,开展异步通信程序,无论是发送还是接收过程,完全可以和运算重叠展开;第五,异步实施时,对于运用者的其他软件并不会导致后果;第六,是完全能够移植的标准式平台。
2 MPI并行算法在農作物生长环境的数据应用分析
MPI并行算法的前提条件是对子模型组分进行并行式处理,把运算任务区分成主从联系,并行处理的粒度并不大,然而运算数据对应的通信时间则较长。因此,本文所确定的方案为把并行处理的粒度提升至子模型层面,即把生长模型的运算任务当作一个任务项目,试图将其区分成一系列能够并行实施的子任务,即{T1,T2,T3,…Tp|P表示子任务的数目},使得任务运算完成之后,确保Ti任务能够马上开始相同的运算速度,据此达到提升运算速度的目的。Ti+1任务的构成主要是数个子模型组分的运算关系式,即{M1,M2,M3,…Mx|X表示的是子模型组分运算的关系式数},x大小主要决定于子模型组分内部的数据依赖式联系。在作物生长相关的模型内,Dev子模型的计算方法所涉及到的函数式无需其他公式输出的数据,即能够视作T1任务;Biomass计算方法公式与Parition计算方法公式的数据互相之间存在着依赖性,能够被一同视作T2任务;Orgmake计算方法公式充分地依赖其他4个子模型的运算结果,即能够视作T3任务。据此为原则,获取子模型层的并行调度方案A,并表示成A方案。
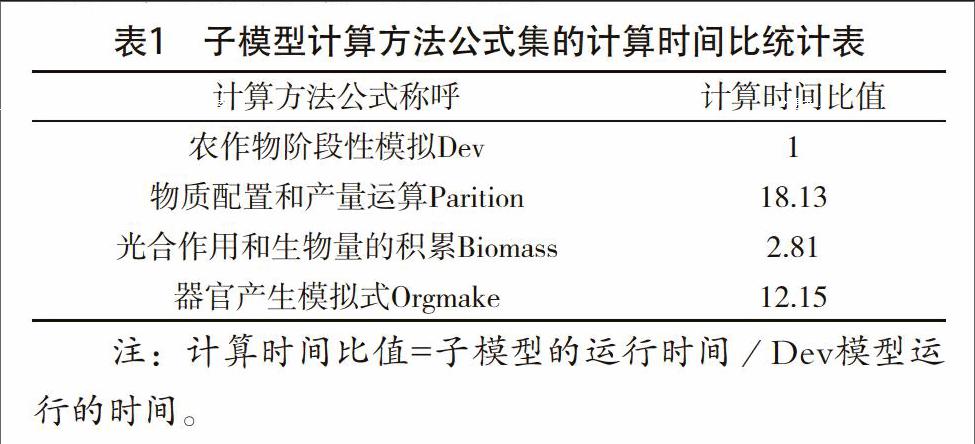
因为分配的处理器不同,对应的运算任务及其量也存在着差异,从而会导致部分处理器和其他处理器率先完成任务之后处于空闲的状态。因而,能够通过尽量地在处理器之间均衡地配置运算的任务,从而达到负载均衡的状态,也就是让全部的处理器均可以持续性地实施上述任务,提升处理器使用的效率。基于计算方法A的前提下,检测串行模式环境中农作物生长的模拟流程,对比不同子模型运算方法关系式的实施时间比,目的在于达到静态负载的均衡状态。设置了单个单机上串行流程的检测实验:即通过农作物大麦1个生长季所对应的气温数据当作模型驱动式变量,检测得到Dev子模型的运作时间是1s,具体的运算时间见表1。
基于表1的相关数据分析可以发现,各子模型计算方法的公式对应的实施时间差别显著。其中,Biomass与Parition计算方法公式的输入和输出的数据相耦合,2个计算方法公式的运行时间比比值是20,远远地超出Dev计算方法公式的计算时间。在以上提及的流水线式并行计算方法A项目内,若把DEV子模型计算任务单独视为一项任务,必然导致其所在的处理器完成计算任务后,不得不等待执行数据传输操作,使得处理器长时间处于空闲的状态。出于维持各个处理器内部的负载均衡目的,把Dev计算方法的公式与Biomass甚至是Parition计算方法公式合成一项运算的任务,从而获取优化之后处理的子模型层并行式优化调度的方案B,并表示成B方案。
另外,方案A与方案B采纳的是数据平均分割法,即把各个运算的节点根据实施一样的任务,不同的仅仅为数据。同时用年作为单位来配置输入的数据,每一个运算的节点处(PC)通过平均的方式分配若干年份的相关数据[3],同时将它们依次展开完善的模拟运算,节点内部所采纳的是流水线式的并行计算方法。根据最后的运算结果可知,B方案优于A方案。
3 结语
并行程序主要是通过互联网环境时开展多处理器计算资源的一种有效性方式。以往的并行运算主要借助于高昂的高性能服务器方式,最终实现高成本的目的。在最近几年中,PC级微处理器的性能日益提升,同时高速互联网日益成熟和推广,从而替在廉价数核的PC级集群环境中,借助于高速与低成本的方式为并行运算提供了良好的条件。当下,并行计算方法已广泛地运用在地质勘察、分子动力学、气象预报以及虚拟性植物等研究范围中,从而在一定程度上提高了科学运算的效率。
参考文献
[1]王萃寒,赵晨,许小刚,等.分布式并行计算环境[J].计算机科学,2013,30(10):252-261.
[2]姜海燕,朱艳,汤亮,等.基于本体的作物系统模拟框架构建研究[J]中国农业科学,2015,42(4):1207-1214.
[3]严美春,曹卫星,罗卫红,等.小麦地上部器官建成模拟模型的研究[J].作物学报,2011,27(2):222-229.
(责任编辑:赵中正)endprint
猜你喜欢
农民致富之友(2019年7期)2019-05-23
农民致富之友(2018年3期)2018-03-28
农业与技术(2017年20期)2017-11-17
今日农药(2017年6期)2017-07-20
价值工程(2016年30期)2016-11-24
电脑知识与技术(2016年24期)2016-11-14
科学与财富(2016年28期)2016-10-14
作文周刊·小学一年级版(2016年14期)2016-05-10
农民致富之友(2009年4期)2009-04-28
