
大数据时代高校助学评审体系的构建与思考
2016-12-21 10:05张皓
电脑知识与技术 2016年28期
关键词:数据挖掘
张皓


摘要: 贫困生认定是高校助学工作中的重点和难点。大数据时代的到来,给高校应用信息化手段开展助学评定工作提供了技术支持,该文对如何在基于数据挖掘等理论基础上设计高校助学体系阐述了总体框架,并对其中部分关键技术进行了分析。
关键词: 助学体系;数据挖掘;AHP
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)28-0001-03
贫困生资助工作是高校扶助家庭困难学生顺利完成学业的一项重要举措,如何构建科学的助学体系是高校乃至全社会所面临的一个重大课题。自2007年国家在普通高校中施行助学政策以来,我国高校的助学体系已逐步形成了由“奖贷助补减”等多项措施全面并行的局面,使无数贫困学生从中受益。然而,目前高校贫困生资助工作依然存在着一些困难和问题。其中,缺乏科学合理的贫困生认定标准是目前高校在贫困生资助工作中普遍遇到的主要困难【1】。对于刚入学的新生来说,能提供为判别依据的仅有一张家庭经济情况调查表,而且更令人遗憾的是表中“家庭人均年收入”这最关键的一栏信息无从考证,出现有些学生瞒报少报家庭收入或者夸大家庭经济困难的现象,而当地的民政部门也不可能详细掌握每家每户的普通百姓的具体收入情况,这就给贫困生的甄别带来了极大的障碍。随着大数据时代的到来,如何运用各种信息处理技术来解决贫困生认定工作中的难题成为各高校研究的热点之一。本文将对应用数据挖掘和AHP等技术来构建助学评审系统做初步的探讨。
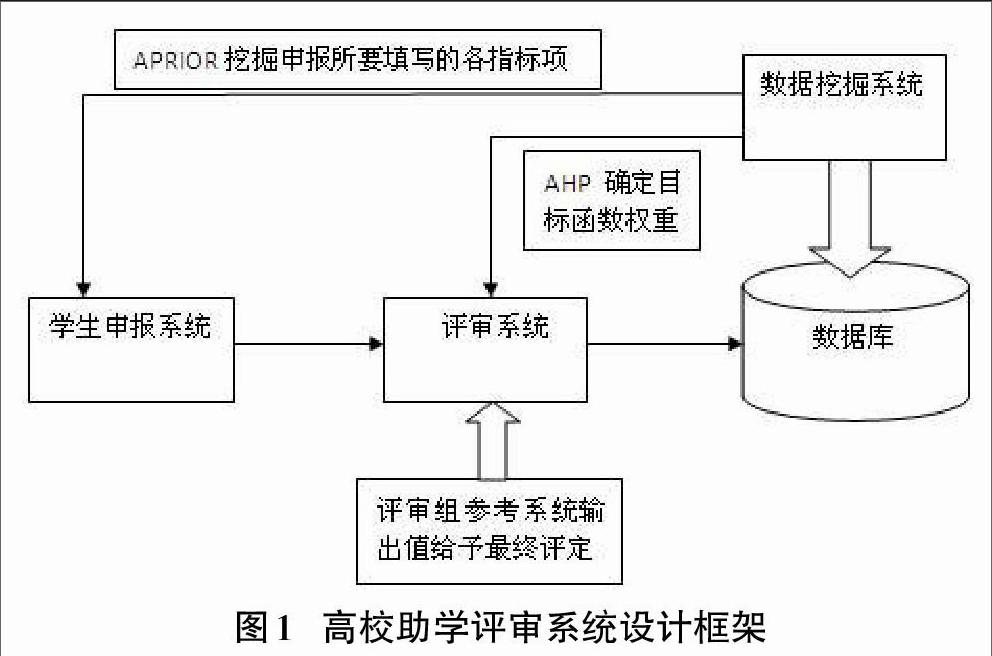
1 高校助学评审系统总体设计框架
近十年来高校助学工作的开展和取得的成果为我们积累了宝贵的经验,不少高校学生工作者纷纷撰文,就贫困生认定的具体工作细节提出了许多宝贵的建议和方法。本文所要阐述的运用数据挖掘技术设计出的评审系统与之并不排斥,即并非完全摈弃过去传统的评审模式,而是为助学评审环节提供一个尽量科学的参考。最终的评审结果必然还是由评审老师酌情认定而不应由机器自动“识别”。因此,本文所提出的助学评审体系是建立在如图1所示的设计框架之上。
2 助学评审体系中的数据挖掘等关键技术探讨
数据挖掘技术问世以后在很多领域有了优秀的表现。于是有些高校工作者开始考虑将数据挖掘技术应用于助学评审工作[2]中来。常用的挖掘技术是使用关联规则(改进APRIOR算法等)推出学生信息与贫困程度的关联程度,但笔者以为,仅凭单纯的挖掘就得出结论是欠准确的,因为k频繁集的背后也许有尚不为知的k+1 项起作用,在置信度不高的条件下有误导的可能。例如校园一卡通消费情况,由“月消费在200元以下”这个事件推出“贫困”的置信度可能达到了70%以上,但也说明了有30%的可能是由于该生在减肥或是食堂菜不爱吃等其他原因。如果将该生身高体重比、性别、家庭月收入、体育馆每周光顾次数等相关事件加进来统计则有可能会帮助判别该生是否是在减肥,但随之而带来的问题是事件集的膨胀和支持度的下降。不论何种情况,该学生的情况不能简单地只由几个事件(以下称为“评价指标”)就下结论,而应尽可能地综合考虑其他各项“指标”,避免一叶障目妄下定语。需要强调的是,本文中关联规则的运用有所不同,它仅仅是第一步和最后一步:用来发现和验证评价指标。
2.1利用关联规则发现和验证评价指标
评审体系应由许多评价指标共同构成。评价指标的确定要遵循以下原则:1)科学性;2)可行性;3)可测性;4)动态完善性【3】。表1列出和总结了目前高校在贫困生认定中最常用的指标【4】。其中位于顶层的指标可称为一级指标,一级指标以下的分指标称为二级指标,依此类推。指标最初可以是专家设计或经验总结,以后随着数据库中的信息量日益增多和完善,可运用数据挖掘技术“发现”并增加潜在的评价指标。其实现的主要手段就是利用关联规则。关联规则是数据挖掘中最基本的技术之一,其原理是:假设I={i1, i2···im}是一个项目集合,T={t1, t2···tn}是一个(数据库)事务集合,其中每个事务ti是一个项目集合,并满足ti?I。则一个关联规则即是一个如下形式的蕴涵关系:
支持度的值过小则表明此关联事件有可能只是偶然发生,而置信度如果太低则表示从X推断出Y的可靠度不高。Aprior算法是实现关联规则的主要算法,并有各种改进版本,其原理主要是通过迭代地
发现频繁集来实现,本文由于篇幅限制不再介绍。实际工作中我们大可不必自己编程去实现Aprior算法,有些数据库软件如SQL Server 2008等自带了关联算法并可设置其各种参数,另外还有诸如SPSS、Weka等挖掘工具软件,我们可以利用这些现成的工具很方便地进行挖掘,所要做的只是数据清洗和最终的发现与验证工作。接下来再通过设置合理的置信度和支持度,并可结合重要性(即改善度lift)等其他参数进行综合分析,从而判断所挖掘出的评价指标是否成立。例如一卡通消费情况,如果将其作为一项评价指标,则由其生成的关联规则在支持度和置信度上应不能低于其他常用指标太多,否则就难以“置信”,要考虑撤销该指标或降低权重。
2.2 构建评价目标函数的思路与分析
指标项确立以后就是考虑如何构建评价函数的问题。分两步:第一步是要如何确定这些指标项各自对应的权值;第二步是函数形式的确立。有的文献中给出了以模糊数学理论为基础建立模糊矩阵的方式进行判别,本文由于篇幅限制仅以最简单的目标函数法来说明问题。即构造以下形式的目标函数来作为最终的判别输出:
其中是指标项的对应权重。
该目标函数最终输出值即为该生的评价指数。而在此函数式中,如何确定各指标项和对应的权值则是构建该目标函数的关键。
这里顺便提一下神经网络和决策树。神经网络远比这个目标函数复杂,它是一种非线性结构,依靠大量数据样本进行反馈式训练来自适应调整节点权重,适合精确分类输出。但如果用庞大的数据开销和算法复杂度去换取“绝对”精确的分类有“杀鸡用牛刀”之嫌。决策树是一种树型结构,树中的各节点是由算法(目前最常用的是C4.5算法)生成,且最终的叶子节点性质为属性。但是我们希望评价体系最终输出的是一个可供参考和比较的值而非属性。尽管可以用把值离散化为一个个区间上的属性的方法,但这样做会加大构造树的复杂度。还有最重要的一点是,树型的判别结构并不适合助学评价系统。我们所期望的值是由系统中所有指标项的共同影响来决定的,而不是从某个节点开始就直接滑向了叶子。
2.3运用AHP算法实现评价目标函数的构建
美国运筹学家Saaty教授提出过一种AHP算法(Analytic Hierarchy Process)[5],它为解决这一问题提供了途径。这是一种多准则决策方法,且非常适合求各层次指标的权重,步骤如下:
1)构造判断矩阵:
对同级的所有指标依次构造两两对比的判决矩阵:
其中aij取从1-9的整数。 aij越大则表示指标Ui相对比Uj的影响力更大。aji取aij的倒数。这里aij的初始值是由专家填写或由经验产生的,虽然有些主观性,但由于后期还可由评定结果进行反馈训练和调整,因此并不影响建立模型的科学性。
2)规范化列并确定各指标的权值:
3)一致性检验:
计算一致性比例:
其中C.I= ,是矩阵的特征值,而的值可由查表得到。的值越小越好,通常取<0.1,若满足此条件则认为通过一致性检验。
有关AHP层次分析法中的判断矩阵构造在许多文献中多有论述,其各种改进算法在此不再一一列举。本文仅使用了最简单的和法定义说明问题。以最顶层的一级指标为例,假设判断矩阵如表3所示:
即学生家庭情况的权重设置为0.5374,学生本人情况权重为0.2680,师生评定情况权重为0.1946。以下省略了一致性检验过程。以此类推可得到二级三级各指标的相应权重。
3 设计贫困生申报系统与评定系统用户界面
以数据挖掘和AHP层次分析实现的评审系统最终以友好的软件界面形式展现给用户。申报系统面向学生,由学生本人按实际情况填写软件所要求的各指标项,并可以加装智能判断:例如事先将全国各地经济数据分为若干片,根据学生填写的父母年龄职称职务工作情况等进行初步判断,如果与数据库里的相同条件下平均收入水平差距超过临界值则给出警示;还可要求学生必须填写正确的家庭收支情况,发现“入不敷出”数据则要求学生必须填写其他经济来源或强制重填,否则无法提交等等。评审系统则由评审老师或评审小组使用,根据系统生成的参考评价值F(a)对学生贫困程度给予最终评定和排序。
4 系统开发工作的前景
大数据时代的到来为我们改变和创新高校助学评审模式提供了契机,但种种客观条件的限制使得数据挖掘技术并未能广泛应用到实处,如何应用该技术解决高校贫困生评定工作中遇到的困难仍将是一个任重而道远的过程。然而不积跬步,无以至千里,随着我们锲而不舍的数据积累和挖掘工作的不断深入,必定会在不久的将来给高校助学系统的研发带来新的变革。
参考文献:
[1] 王东红.大数据时代高校贫困生资助工作的思考[J].经济研究导刊,2014(35).
[2] 周丽娜.关联规则在学生助学系统中的应用研究[J].考试周刊,2012(62).
[3] 杨金保.基于模糊综合评价的高校贫困生认定方法研究[J].佳木斯大学社会科学学报,2010(28).
[4] 庞艳桃.高校学生经济状况认定指标体系及模型研究[J].华中农业大学学报:社会科学版,2008(3).
[5] 赵玮. AHP的算法及其比较分析[J].数学的实践与认识,1995(1).
猜你喜欢
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
河南科技(2014年23期)2014-02-27
电子设计工程(2014年18期)2014-02-27
