
基于预测模型的HDFS集群负载均衡优化与研究
2018-05-22 07:34于磊春陈健美
计算机应用与软件 2018年5期
于磊春 陈健美 刘 响 胡 杨
(江苏大学计算机科学与通信工程学院 江苏 镇江 212013)
0 引 言
互联网技术的发展给人们的生产生活带来了大量数据。随着大数据的出现,“云”技术也应运而生,主要涉及云存储和云计算。HDFS集群作为云存储平台的典型代表,为大数据的存储带来了极大的便利,在很多大型公司中得到广泛应用,比如一些大型医疗机构涉及到的病人的影像文件存储、三大运营商所收集的用户信息数据的存储分析都需要HDFS的支持。谈及分布式集群,负载均衡一直是影响其性能效率的关键因子。通常情况下,当HDFS端负载出现不均衡情况时,整个Hadoop集群的mapreduce部分的计算将会得到制约,使其无法充分利用本地化计算。 HDFS集群架构主要是由一个主节点(NameNode)和众多数据节点(DataNode)组成,同时为了进一步提高集群高可用还包括一个SecondaryNode节点,其中主节点至关重要,它是用来管理所有数据节点信息,数据节点的读取操作都是经过主节点调度;数据节点主要负责与主节点进行通信,并且主要功能是存储文件数据块。HDFS集群最突出的特点:“一次写入,多次读取”。默认的HDFS集群属于Hadoop生态系统的一部分,Hadoop系统中自带负载均衡机制,该机制主要负责一旦集群中出现节点之间负载不均衡的情况时做出相应的负载调整,从而确保整个集群中节点的资源分配均匀性。然而,默认的负载均衡算法策略中关键因子阈值的设定不仅存在着衡量指标的单一化,而且对于指标信息的选取和设定存在滞后性和主观性,对集群负载均衡的效果不佳。现如今,研究HDFS集群负载均衡的人员在考虑传统负载均衡局限性的基础之上综合考虑了节点异构以及文件属性对于负载均衡策略的影响。文献[1]仅仅在默认的负载均衡模型的基础之上,综合考虑了节点的自身特性对于集群负载均衡的影响,却忽略了节点处理对象文件属性对集群负载均衡的作用。文献[2]结合异构集群的特点和文件的响应时间进行研究,却对于指标信息的选取具有滞后性。在文献[3]的基于实时负载的HDFS负载均衡改进和实现的研究中,对于阈值的设定中仅仅考虑了节点特性的影响,而且对于指标的选取具有滞后性和主观性。本文在分析了默认的负载均衡策略中阈值设定以及对于该策略优化的一些算法基础之上,引入预测模型对于节点处理对象文件属性进行时序性预测,同时对于阈值的衡量在考虑节点特性的基础上综合文件属性的预测值进行衡量,最终将衡量得到的阈值引入负载均衡算法策略进行负载优化。实验证明,该策略进一步提高了集群的整体工作效率。1 问题阐述HDFS作为云存储的典型代表,属于Hadoop生态体系的核心之一,Hadoop集群的搭建重要特点是可以使用大量的廉价PC机进行集群的搭建。廉价的PC机随着集群的启用不能确保整个工作流程期间各自相互之间的性能一致性。PC机之间会随着作业的执行产生很大的差异,比如:cpu的处理能力差异、内存大小差异、存储空间的差异等,所以在考虑集群负载均衡的时候,不能忽视节点的差异性给集群负载均衡带来的影响。另外,HDFS作为云存储平台,最大的作用是进行大量数据文件的存储,存储的文件格式也是多样的,比如:图像文件、视频文件、文本文件等,文件格式的差异也如同节点的差异可能对集群的负载均衡带来不一样的影响。综上分析:一个数据块进行数据文件存储时可能会存放不同的类型文件,比如:一个数据块存放的全部是文本文件,另外一个数据块存放的是文本文件和图像文件两种类型文件,那么这两个数据块存放在不同的节点上是否给相应的节点的负载带来不同的影响呢?同时,结合HDFS具有“一次写入,多次读取”的特征,需要考虑一个节点一旦存储了经常被访问的文件数据块必然会引起该节点的繁忙程度的增长,这种含有文件热度比较高的数据块一旦在一些节点中存在,必然会引起整个集群的负载发生倾斜。另外,当节点中存储的文件长时间不被访问势必会降低节点的负载。综上可知文件属性也是影响集群负载均衡的关键因素。为了进一步优化阈值指标衡量过程中的滞后性,本文采用基于优化的灰色马尔科夫预测模型对文件属性进行预测,从而优先计算出预估阈值的大小,以便负载预先调整。
2 灰色马尔科夫预测模型
当前,在预测研究领域中,灰色模型预测中经典代表GM(1,1)模型与马尔科夫预测模型相结合作用于时间序列问题的预测运用十分广泛,两者的单独使用对于预测的准确性上有所局限,发挥的作用极小。灰色马尔科夫预测模型在很多应用实践中证明了其对于解决序列中波动情况比较大的时候预测准确度较高的预测模型。因此对于HDFS这种分布式集群来说,数据随着时间、网络等各方因素的变化产生的波动性相对较大,并且这一模型结合了灰色预测对于样本所需数据量较小、计算相对简单等特点,之后对灰色预测产生的结果再进行马尔科夫修正,从而进一步提高了预测的精度,非常适用于文件属性预测。模型的建立思路:首先建立GM(1,1)模型,求出其预测曲线;接着以平滑的曲线为基准划分若干动态的状态区间,计算出马尔科夫预测未来状态,从而得到预测值的区间,取区间的中点,从而得到预测精确度较高的预测值。
2.1 GM(1,1)模型GM(1,1)模型是基于关联空间、光滑离散函数等概念定义灰导数与灰微分方程,进而用离散数据列建立微分方程形式的动态模型。设非负原始数列:x(0)={x(0)(1),x(0)(2),…,x(0)(n)}
(1)
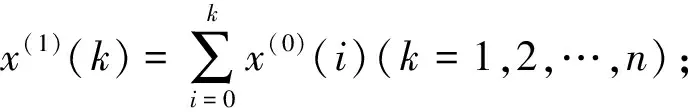
(2)
式中:x(0)(k)为灰导数,a为发展系数,z(1)(k)为白化背景值,u为灰作用量。上述微分方程的优化白化微分方程为:
(3)

(4)
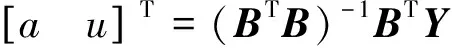
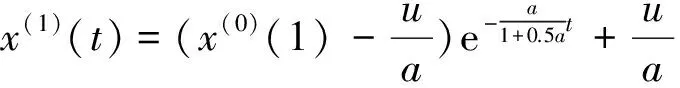
(5)
式(5)是累加生成序x(1)={x(1)(1),x(1)(2),…,x(1)(n)}的预测模型公式,它是仅对一次累加的预测,通过下式还原预测值:
x(0)(k+1)=α(1)x(1)(k+1)=
x(1)(k+1)-x(1)(k)=
(6)
特别说明:对于紧邻均值生成序列z(1)(k)中λ的值,当原数据非常平滑,那么取λ=0.5,当数据波动但是变化不是很强烈时,取λ的范围在(0,0.5),也就是数据权重相对较大,当λ取值在(0.5,1),表明新访问的数据权重较大。
2.2 马尔科夫修正模型
马尔科夫模型描述了一类随机变量随时间而变化的随机函数,是数学中具有马尔科夫性质的离散时间随机过程,用于描述随机过程统计特征的概率模型。
一个系统由N个状态S={s1,s2,…,sn},随着时间的推移,系统从一个状态变化为另一个状态。Q={q1,q2,…,qn}为一个状态序列,其中qi∈S,在t时刻的状态为qt,对于系统的描述要给出当前时刻t所处的状态st以及之前的状态s1,s2,…,st-1,那么t时刻处于状态qt的概率为P(qt=st|q1=s1,q2=s2,…,qt-1=st-1),该模型称为马尔科夫模型。
特殊情况,当前时刻的状态只决定于前一时刻的状态叫一阶马尔科夫模型,即:P(qt=si|q1=s1,q2=s2,…,qt-1=sj)=P(qt=si|qt-1=sj)。状态之间的转化概率表示为aij,aij=P(qt=sj|qt-1=si),其表示由状态i转移到状态j的概率。其必须满足两个条件:
3 基于预测模型的负载均衡策略
通过分析可知,主要针对文件属性中文件被访问的频率、文件未被访问的时间这两个因素进行预测,并将预测值代入阈值多衡量指标模型。
3.1 预测指标定义
文件被访问频率f:在集群客户端设置两个变量countin和countout分别统计单位时间间隔内某一文件被取出和存入的次数,两者相加便可得到该文件被访问总次数,文件在单位时间间隔内被访问的总次数越多,文件在未来可能被访问的几率也就越大。
文件未被访问时间t:某一个文件在HDFS集群中长时间不被外界进行访问(也就是不被进行存取以及追加),说明此文件在该节点中处于一种比较稳定的状态;随着时间的推移,一旦越来越多的文件趋于稳定的状态,该节点的负载也将会相应减小,此时说明该文件处于热度相对较小情况;可以在客户端定义ftime变量以及设定一个计时器统计单位时间间隔内该文件没有被进行读取和追加操作的时间。
3.2 基于预测模型的文件属性估算
对于文件被访问频率f、文件未被访问时间t两个影响因子均采用灰色马尔科夫预测模型,原始数据序列分别为该文件在前n个等时间间距内的访问频次和文件在前n个等时间间距内的未被访问时间。估算流程如下:
第二步:为了求出白化微分方程中的发展系数a和灰作用量u,采用最小二乘法来对待识别量进行估计计算,这里需要说明的是:对于紧邻均值序列z(1)(k)的λ的取值 ,λ为新旧数据的权重,为突出新数据优先的思想,也就是最近的数据访问特征应当具有更大的权重系数,λ的取值为0.75。
第三步:将第二步所求的af、uf、at、ut分别代入对应的白化微分方程求得文件i访问频次和未被访问时间的时间相应函数分别为:
第四步:由于用户访问的随机性和数据变化的突变性,需要采用马尔科夫模型对GM(1,1)模型预测值进行优化,大致如下:
(1) 首先分别计算文件预测访问频次与文件预测未被访问时间估计值与实际值之间的残差ε(k)。
(2) 根据第一步所计算的相对差值以及检验精度对差值的要求,将相对差值划分为6个状态区间如下:

状态A1A2A3A4A5A6状态区间[0.2,+∞)[0.1,0.2)[0,0.1)[-0.1,0)[-0.2,-0.1)(-∞,-0.2)
其中m为状态数。
通过状态转移概率矩阵和当前时间段拟合值的状态,可以预测下一时刻灰色预测值的相对差值的状态。取相对差值状态区间的中值作为灰色预测模型所预测结果的修正值,得最终k+1时段文件预测访问频次值与文件未被访问时间值:
其中σf、σt分别为相应的状态区间的中值。
3.3 动态阈值计算策略
为了进一步打破阈值设定的主观性和指标信息的滞后性,在建立阈值计算模型的过程中,主要还是从两方面因素来考虑:一个是空间,一个是时间。
空间上,仍然选择的是节点存储空间使用率的标准差,该指标能够很明显地反映出集群中空间使用的分布情况和离散状态,指标值越小,说明集群越趋向于均衡;反之,集群越不均衡。
时间上,在原有综合考虑连接数和网络平均流量的基础之上[3],综合考虑节点内部影响因子对节点的繁忙程度的影响,即所处理的文件对象属性因子。分析可知,连接数越多,表明节点与外界的输入输出越频繁,而集群中数据文件的传输依托的是网络传输,这两者从节点的自身角度来表明节点的繁忙程度。另外仔细分析,节点中所存储的对象文件,它的特性也对节点的繁忙程度起到了至关重要的作用,一个文件越是被频繁访问,带来的影响不仅是增加了该文件所处节点的负载,也增加了该节点的磁盘输入输出的频次,因此很大程度影响到节点的繁忙程度。因此,一旦一个文件在节点中长时间不被访问,那么也会降低节点的磁盘输入输出的频率,从而降低了节点的繁忙程度。综上,在阈值计算的时间选择因素上,决定对节点的繁忙程度采取多指标衡量模型[8]来进行研究。
基于预测模型求得的k+1时刻预估的文件访问频次和文件未被访问的时间,结合集群的磁盘使用率和节点的繁忙程度来对阈值的取值动态进行调整,阈值的取值只能在0~100之间,建立阈值的计算模型:
threshold=k1×α+k2×λ
计算模型中,k1+k2=1,α表示节点的空间使用率标准差,λ为节点的繁忙程度值。
3.4 建立基于预测值的节点繁忙程度函数计算模型
综合3.3节的分析,设定节点繁忙程度模型如下:
λ=u1·wnet+u2·wconnect+u3·wf+u4·wt
定量描述节点负载量的有效性主要是采用线性加权法[8]来建立模型,它主要利用各个衡量指标相对于总的目标值来说所占的份量的不同,从而根据各个指标在相应环境下依据其重要程度设置系数。将带有这些系数的指标值最后相加得到目标的值。这里对于阈值计算中节点的繁忙程度值计算就是采用这种思想,综合考虑了四个因素:连接数、网路数、预估文件访问频率(单位时间间隔内某个文件访问频次与节点总访问频次之比)wf、预估文件冷冻率(单位时间间隔内某个文件未被访问时间与总时间之比)wt。对于对应系数的计算,这里采用的是多属性策略理论[8]中的AHP构权法,首先建立层次结构模型;然后形成了判断矩阵;通过线性代数中对于特征值的计算方法从而得到不同指标对应的系数值。采用∂1、∂2、∂3、∂4分别表示的连接数、网络数、预估文件访问频率、预估文件冷冻率。
利用上述四个变量,形成判断矩阵:
表1是层次分析法中用来构造判断矩阵的1~9标度法给出的具体数值对应含义。
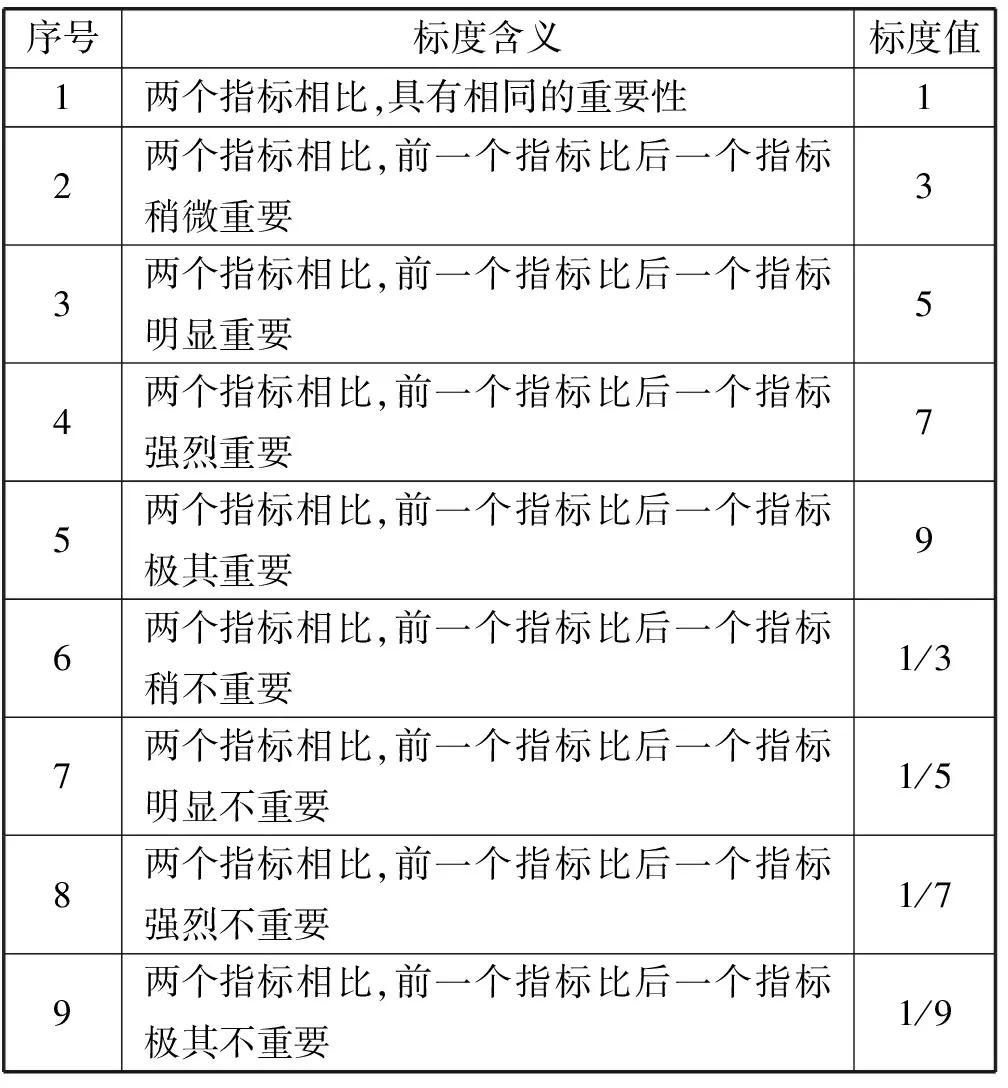
表1 标度表
(注:表中没有列出的2,4,6,8,1/2,1/4,1/6,1/8值是上述含义相邻判断的中间值)
根据标度表结合四个指标之间的关系可以得出判断矩阵:

使用MATLAB计算出矩阵A的最大值矩阵λmax=4.187 3,将上述A矩阵按列进行归一化处理后得到的矩阵B:
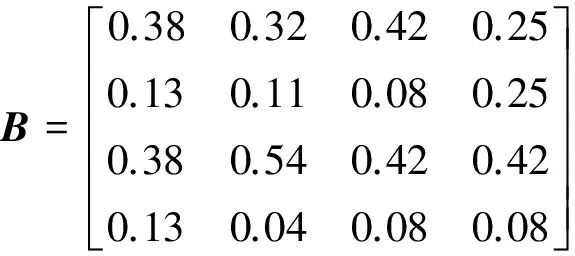
通过表2对构造的判断矩阵进行一致性检验。
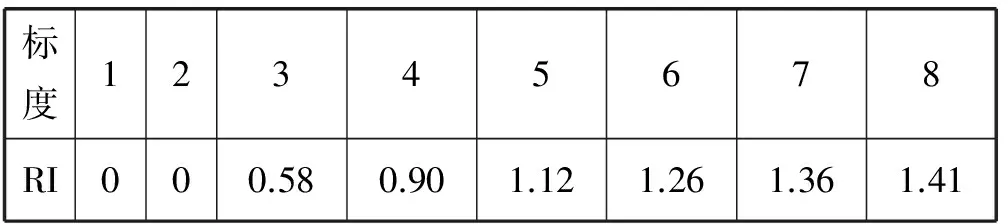
表2 Saaty一致性指标表(RI)
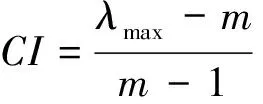
λ=0.34·wnet+0.14·wconnect+0.44·wf+0.08·wt
将结合文件特性的预估值计算得到的预估节点繁忙程度值代入阈值计算模型,从而可以预估出k+1时刻的阈值。结合预估的负载值在实际k+1时刻到来之前提前做出负载调整策略,从而更好地提高集群的工作效率。
3.5 阈值优化算法及流程
为了优化HDFS集群负载均衡器,采用了预测模型进行分析,其中为了能够准确预估未来时刻文件属性的变化值,在集群客户端使用了关键函数:currentTimeMills()时间计数器函数、CalculateFileCur()文件访问频次统计函数、CalculateUnknownTime()文件未被访问时间统计函数等。
大致算法流程如图1所示。
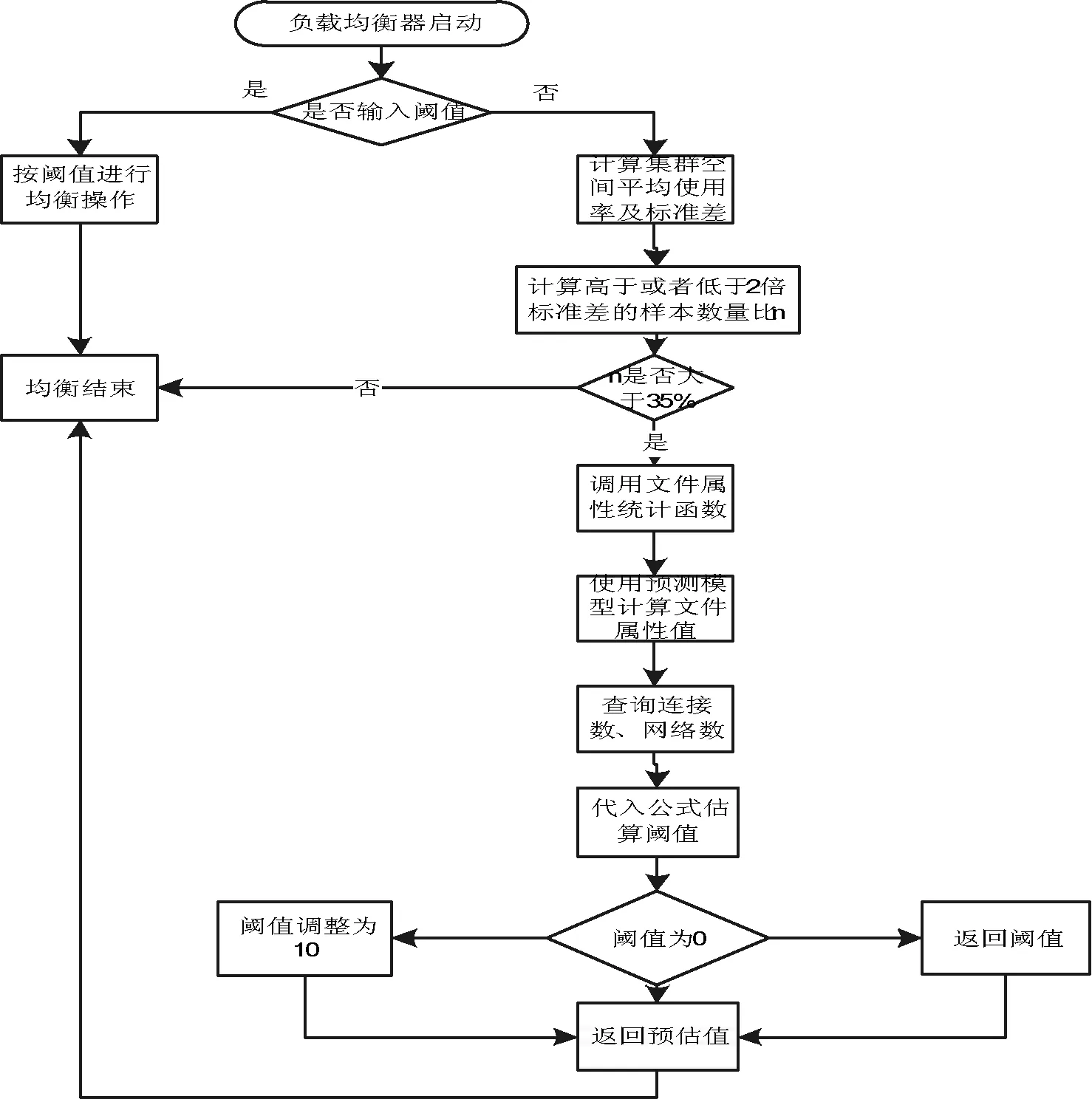
图1 优化的负载阈值策略流程图
集群的负载均衡效果指标主要是集群的空间使用率大小分布。首先需要计算HDFS集群的空间存储利用率。然后计算整个集群的空间使用率的平均值从而计算其标准差。在策略调整过程中,注重的是整体效果,因此需要对一些个列进行剔除,从而确保不会做多余的操作。一般存在个别异常影响整体均衡的集群计算出来空间使用率标准差比正常的稍大,所以对于阈值的设定不宜过小。另外,为了避免系统做一些多余判断影响系统整体的执行效率,需要在对阈值设定计算之前进行判断:先计算高于或者低于2倍空间标准差的样本数量比n,如果n大于35%,集群将会处于不均衡的环境,否则是均衡的。
4 实验与分析
4.1 实验环境配置
对于表3中的集群配置,选择使用三个机架,Client和Namenode处于一个机架,另外六个Datanode分别处于两个机架,1、2、3处于第二机架,4、5、6处于第三机架。
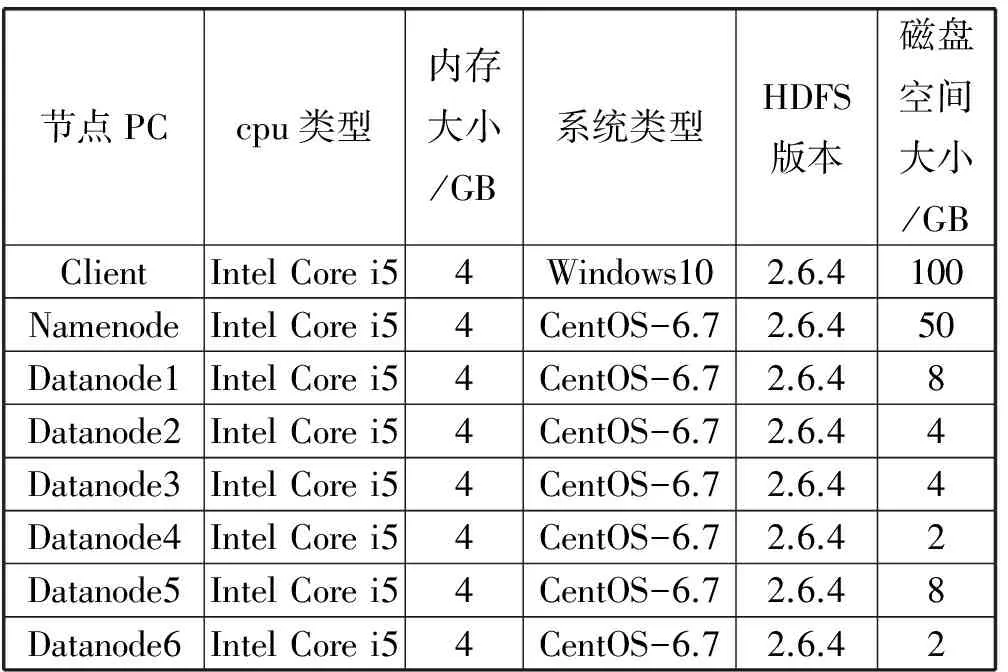
表3 HDFS集群环境搭建配置
4.2 实验内容
本文实验主要分为两个部分,第一部分主要是验证基于灰色马尔科夫模型对于集群运行过程中文件两个影响因子的预测准确性;第二部分实验重点验证本文提出的基于文件属性预测值的阈值动态计算模型在负载发生倾斜的集群中均衡调整效果以及测试比较三种负载均衡策略下集群作业执行响应时间效率。
对于第一部分实验,实验过程中,在客户端使用myeclipse来实施HDFS集群管理过程中,需要建立一个java测试类Test.java,在该类中分别定义两个数组来统计k-1时刻之前所有时段的文件访问频次大小和文件未被访问时间大小,文件的访问频次以及文件未被访问时间。通过在HDFS源码中分别对其设定变量fcount和tnon来进行统计,对于分段时间的大小,在实验过程中分别取时间间隔T为1 min、2 min、3 min三种情况。最后在Test类中对于三个不同切分时段所统计的文件访问频次和文件未被访问时间值代入预测模型算法中进行预测计算与实际值进行比较。
对于第二部分实验,首先需要在当前k时段将文件属性预估值结合节点实时连接数和网络数因子进行阈值计算。其中连接数就是集群live状态下的节点数目,这个数值可以通过集群中的log日志进行实时查询;网络数就是集群下处于live状态的节点网络流量数,可以查询集群/dev文件中的数值。最后在当前时段预测出k+1时段阈值的估计值。
由于本次实验着重对于阈值计算模型中时间影响因子的研究,因此在实验中对阈值计算模型中k1值取0.1,k2值取0.9,这样取值表明:当集群处于均衡状态下时间的权重稍大,偏向于时间均衡效果。
4.3 实验结果分析
对于第一部分实验测试,需要进行不同情况下文件两大属性预测值与实时文件属性实际值的对比,大致分为如下几种:
(1) 不同文件类型在相同切分时段的阈值预测值与实际值比较,如表4所示。注:切分时段T取2 min,当前时刻记为t时刻,t+2 min时刻文件访问频次预测值记为N1,t+2 min时刻文件访问频次实际值记为N2,t+2 min时刻文件未被访问时间预测值记为T1,t+2 min时刻文件未被访问时间实际值T2。
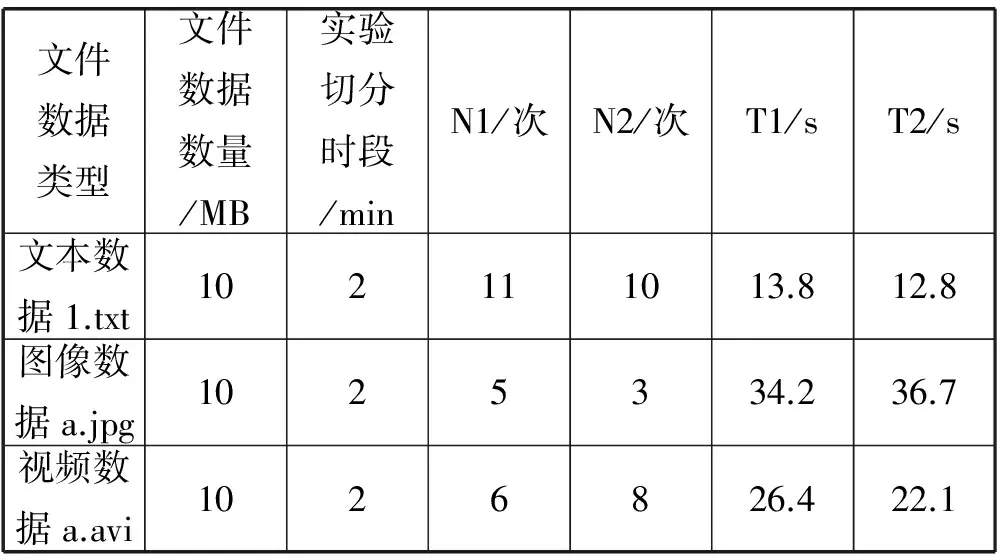
表4 不同文件类型在相同切分时段对比结果
(2) 相同文件类型不同文件数量在相同切分时段预测值与实际值比较,如表5所示。注:同上。
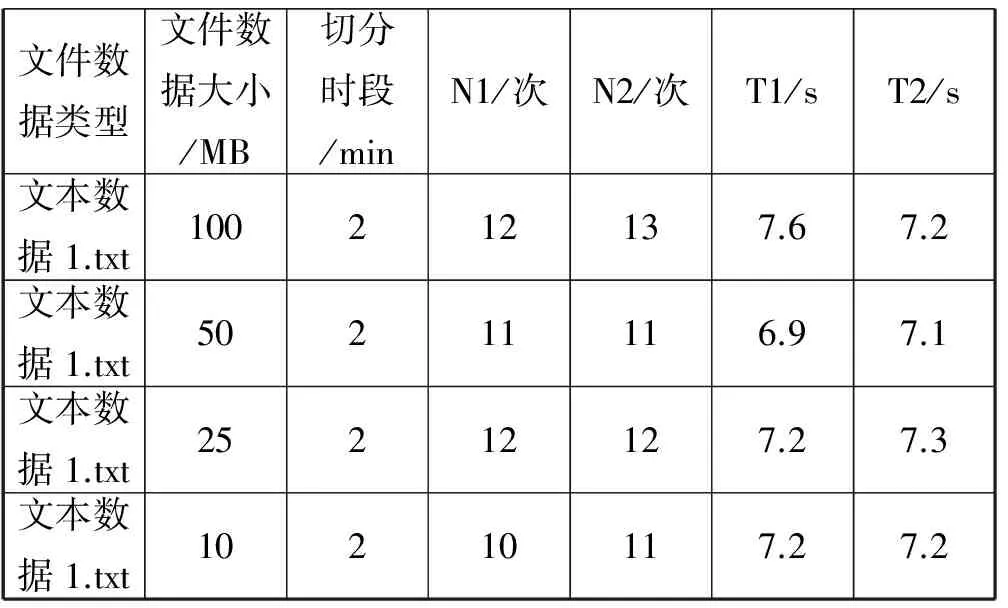
表5 相同文件类型不同文件数量在相同切分时段预测值与实际值比较结果
(3) 同一文件类型同一数量在不同切分时段情况下预测值与实际值比较,如表6所示。注:当前时刻记为t时刻,t+T时刻文件访问频次预测值记为NT1,t+T时刻文件访问频次实际值记为NT2,t+T时刻文件未被访问时间预测值记为TT1,t+T时刻文件未被访问时间实际值记为TT2。
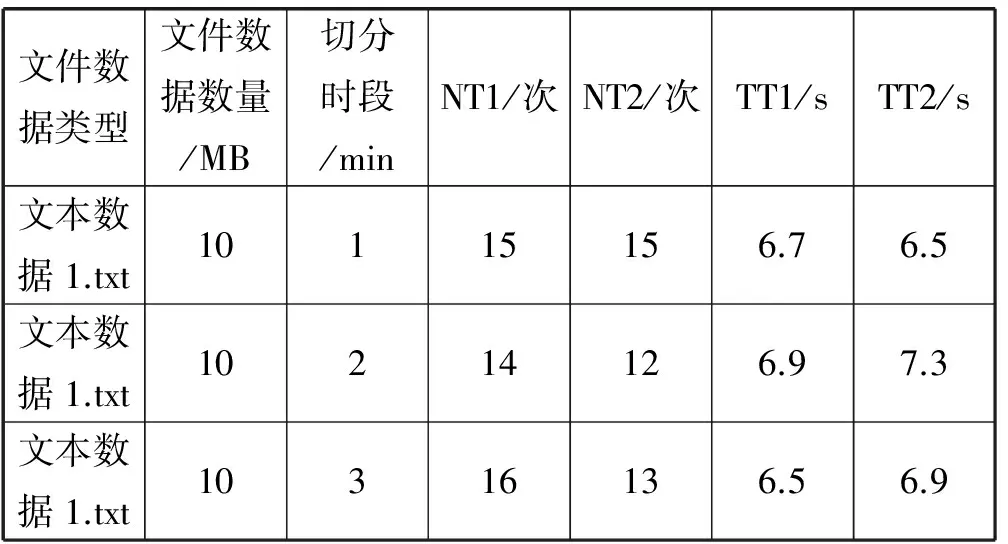
表6 同一文件类型同一数量在不同切分时段情况下预测值与实际值比较结果
综上表4、表5、表6,分析可知:影响预测结果的最关键因素是切分时段的大小,划分的越小准确率越高;文件类型对于属性的预测有一定影响作用,在对于存储复合数据类型的集群中需要将文件类型纳入预测考虑因素。综合来看,使用灰色马尔科夫模型对于集群文件属性的预测相对准确度较高,比较适合该集群的预测。
对于第二部分实验测试,主要使用的是Hadoop集群自带的wordcount程序代码对日志文件中进行读取,并统计文本文件中单词的出现次数。首先需要对集群中六个Datanode存储节点手动存储不同数量的文本文件,另外在客户端采用循环机制分别对六个Datanode中文本数据进行不同频次的读取,从而使得集群中出现负载不均衡情况。此时启动集群默认负载均衡器rebalancer,测试程序wordcount运行结束过后,对集群中六个Datanode节点存储空间进行统计,如表7所示。
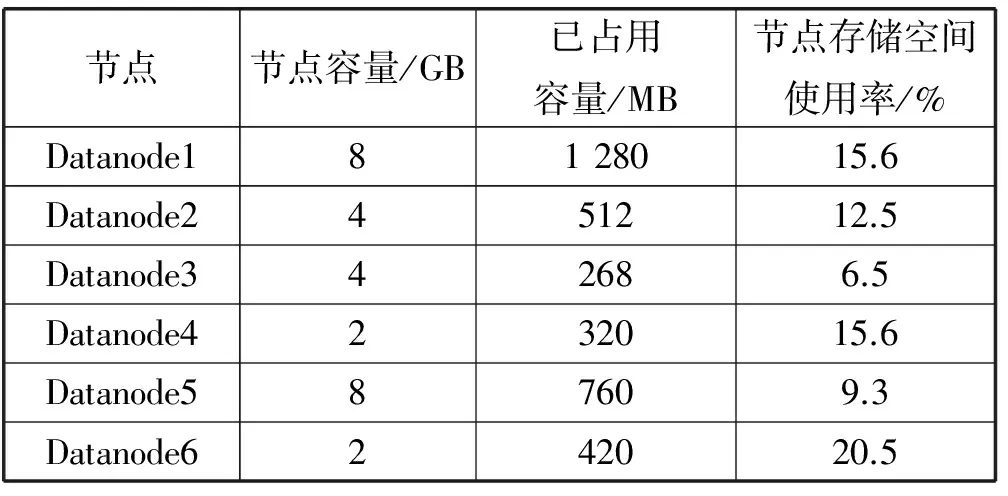
表7 手动初始集群状态及默认负载策略调整情况
从表7可以看出,集群中六个存储数据节点空间负载明显出现不均衡状况,启动负载均衡器后,集群默认负载均衡策略中使用阈值是10。通过对集群节点平均空间使用率分析可知此时集群平均空间使用率为12.4%,那么系统负载均衡分析策略便会认为节点空间使用率在2.4%~22.4%之间系统是均衡的。上述节点使用率均在这个范围之类,从而启用默认的负载均衡器进行均衡之后节点各自利用率是不变的,没有起到明显的负载均衡效果。之后启用本文所提出的基于文件预测属性值优化的负载均衡器重新测试后的空间使用率结果如表8所示。
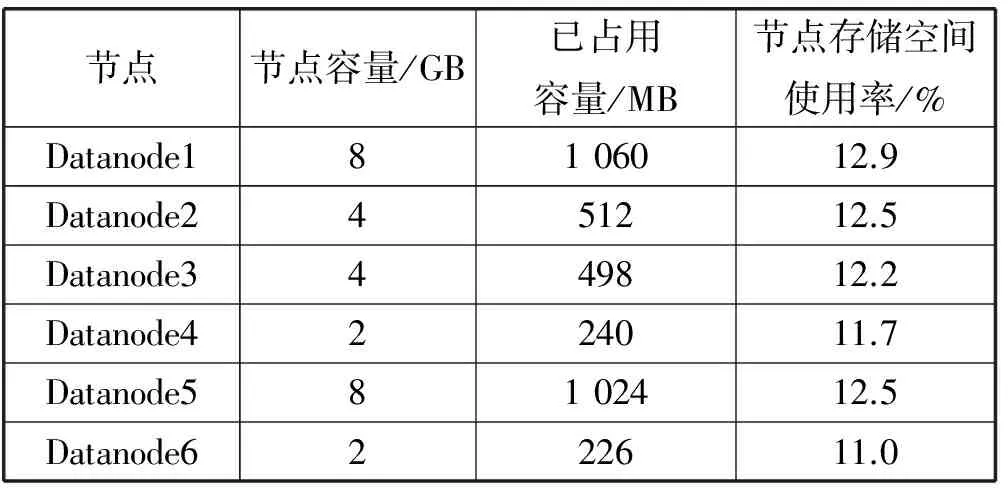
表8 基于预测模型分析的负载策略阈值优化负载调整情况
从表8可以看出此时Datanode1、Datanode3、Datanode4、Datanode5、Datanode6之间进行均衡操作,从而空间使用率的最大值与最小值之间差距发生了很明显的缩小,且存储利用率基本处于平均值附近,此时通过查询阈值大小为3.743 201 65,集群处于比较优良的均衡环境。
最后,分别启用上述默认负载均衡器以及本文提出的基于预测模型优化的负载均衡器之后,还另外启用了基于实时负载优化的负载均衡器,然后分别进行三种均衡状况下执行集群example中的wordcount程序,比较相应的集群执行响应时间。实验主要是将节点1作为client端分别向集群提交作业15次,得出作业执行响应时间如图2所示。
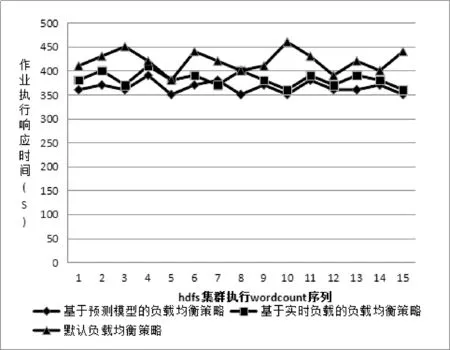
图2 不同均衡策略下执行wordcount的响应时间
从图2可以清楚地看出本文提出的基于预估模型的负载均衡策略相比于默认的以及基于实时负载调整的策略在时间效率上有了不少的提升,进一步提高了整个集群的负载均衡效率。
5 结 语
本文重点对Hadoop生态系统中云存储的典型代表HDFS集群负载均衡策略中阈值的设定进行了研究。通过分析集群存储对象以及集群节点特性,结合优化后的灰色马尔科夫预测模型对文件属性的预测,对阈值计算模型中的重点影响因子节点繁忙程度采用多指标综合衡量分析,从而进一步提高了阈值计算的准确性。最后将预估的阈值代入负载均衡策略进行检验,实验结果表明对于优化后的负载均衡策略在实时性和准确性上都能有很好的反映。下一步将进一步对节点处理对象的文件类型等方面对集群负载的影响进行细化研究。
参 考 文 献
[1] 张松,杜庆伟,孙静,等.Hadoop异构集群中数据负载均衡的研究[J].计算机应用与软件,2016,33(5):31-34.
[2] 刘琨,钮文良.一种改进的Hadoop数据负载均衡算法[J].河南理工大学学报:自然科学版,2013,32(3):332-336.
[3] 陈晨,张东.基于实时负载的HDFS负载均衡改进与实现[J].计算机安全,2014(12):21-25.
[4] Box G E,Jenkins G M,Reinsel G C.Time Series Analysis:Forecasting and Control[M].John Wiley & Sons,2013.
[5] Fan Kai,Zhang Dayang,Li Hui.An Adaptive Feedback Load Balancing Algorithm in HDFS[C]//5th IEEE International Conference on Intelligent Networking and Collaborative Systems,2013.
[6] 杜雯.一种新的灰色马尔科夫预测模型及其应用[J].黄冈师范学院学报,2013,33(3):55-59.
[7] Tom White.Hadoop权威指南[M].3版.北京:清华大学出版社,2015.
[8] 康承坤,刘晓洁.一种基于多衡量指标的HDFS负载均衡算法[J].四川大学学报(自然科学版),2014,51(6):1163-1169.
[9] 张松,杜庆伟,孙静,等.基于预测的云计算热点数据副本因子决策算法[J].计算机与现代化,2015(2):62-66.
[10] 徐玖平,吴巍.多属性决策的理论与方法[M].北京:清华大学出版社,2006.
[11] Liu K,Xu G,Yuan J.An improved hadoop data load balancing algorithm[J].J Networks,2013,8(12):2816.
[12] HadoopHDFS[EB/OL].(2011-10-18).[2011-10-25].http://hadoop.apache.org/hdfs/.
[13] 武娟,黄海,钱锋,等.基于多变量动态算法的Hadoop负载均衡优化与实现[J].电信科学,2012,28(12):83-87.
[14] 林伟伟.一种改进的Hadoop数据放置策略[J].华南理工大学学报(自然科学版),2012,40(1):152-158.
[15] 李成森,黄桂敏,周娅,等.一种基于节点信息的负载均衡算法[J].桂林电子科技大学学报,2016,36(6):449-453.
[16] Qiao Y,Bochmann G V.Load balancing in peer-to-peer systems using a diffusive approach[J].Computing,2012,94(8-10):649-678.
[17] Xiong N,Xu K,Chen L,et al.An effective self-adaptive load balancing algorithm for peer-to-peer networks[C]//26th IEEE International Conference on Parallel and Distributed Processing Symposium Workshops & PhD Forum,2012:1425-1432.
[18] 徐华锋,方志耕.优化白化方程的GM(1,1)模型[J].数学的实践与认识,2011,41(7):163-167.
[19] 徐骁勇,潘郁,丁燕艳.基于灰色马尔可夫链预测模型的HDFS云存储副本选择策略[J].计算机应用,2011,31(s2):39-42.
[20] 张国帅.基于累积法的灰色马尔科夫预测模型及其应用[J].统计与决策,2011(8):157-158.
[21] Sudharshan V,Schopfm J.Using regression techniques to predict large data transfers[J].International Journal of High Performance Computing Applications,2003,17(3):249-268.
[22] Dhruba Borthakur.The Hadoop Distributed File System:Architecture and Design[EB/OL].(2008-09-02).[2010-08-25].http://hadoop.apache.org/common/docs/r0.16.0/hdfs_design.html.
[23] 刘琨,肖琳,赵海燕.Hadoop中云数据负载均衡策略算法的研究与优化[J].微电子学与计算机,2012,29(9):18-22.
[24] 陈有孝,林晓言.灰色-马尔科夫改进的预测方法[J].统计与决策,2005(16):36-38.
[25] 邵静,王利超,刘新平.灰色马尔科夫模型及其应用[J].纺织高校基础科学学报,2009,22(3):370-374.
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
今日农业(2021年19期)2022-01-12
安徽工程大学学报(2021年5期)2021-11-30
有色金属(矿山部分)(2021年4期)2021-08-30
电子产品世界(2021年6期)2021-02-10
中国现代医生(2020年2期)2020-04-09
军事运筹与系统工程(2019年4期)2019-09-11
信息化建设(2019年2期)2019-03-27
电子制作(2018年11期)2018-08-04
智富时代(2018年12期)2018-01-12
