
运动预测的多示例学习目标分块跟踪方法
2018-04-24 07:58冯俊凯舒莉何军石佩生
现代计算机 2018年8期
冯俊凯,舒莉,何军,石佩生
(四川大学计算机学院,成都 610065)
0 引言
遮挡是目标跟踪过程中常见的情况,图像中目标被局部或全部遮挡,会对目标跟踪造成极大的干扰,如何在目标局部受到遮挡的情况下,也能有效地跟踪目标,是评价跟踪算法鲁棒性的关键指标之一[1]。传统的跟踪与检测算法在跟踪过程中易出现错误积累,从而导致目标飘逸或丢失。将多示例学习思想融合进跟踪过程中,则可以较好的实现目标的长时间稳定跟踪[2-3]。跟踪-学习-检测(Tracking-Learning-Detection:TLD)相结合的算法[4]是目前常用的跟踪算法,它可以有效解决目标全部被遮挡后重新出现时的定位问题,但当目标被局部遮挡时,这类算法常常发生定位漂移的问题。而基于遮挡检测的跟踪算法[5]可以较好地解决局部遮挡问题,但对目标完全被遮挡的情况效果较差。子块跟踪方法可以同时有效解决局部遮挡与完全遮挡的情况[6-8],它将目标区域划分为数个子块,将其分为候选块与非候选快,之后对候选块进行独立跟踪,根据子块的位置定位目标位置。如果候选块区域被遮挡,则更换候选块,进行跟踪。
已有的子块跟踪算法,或是由于不更新子块信息,或是由于只更新候选块的信息,不更新非候选块,导致并不能很好地适应目标较大的逐步形变。并且在使用多尺度滑动窗口对图像上所有目标可能出现的位置进行检测时,检测算法速度较为缓慢的情况。为解决上述问题,提出一种带运动预测的改进多示例学习目标分块跟踪方法。该方法使用Online AdaBoost作为基础检测器,弱分类器为随机蕨丛林,并结合多示例学习的思想来解决学习模型的误差积累问题。在对某一帧图像检测前首先预测目标大致位置,之后对预测位置附近的区域进行检测来减小计算量,缩短检测耗时。为适应目标较大的逐步形变,在定位完成后更新学习模型时,首先判断是否有某个子块被遮挡,之后更新所有未受遮挡的子块对应的学习模型。
1 多示例学习目标分块跟踪
1.1 多示例学习
多示例学习将传统监督学习的学习样本划分成包,每个包包含多个示例。它并不为每个示例都进行标记,而是对整个包进行标记,一个包中至少含有一个正示例,则该包为正包,反之为负包。假设Bi表示多示例学习的第i个包,bij表示包Bi中的第j个示例,令Yi为包 Bi的标记,且 Yi∈{0,1},yij为 bij的标记,且 yij∈{0,1},则,通过Online AdaBoost方法训练学习器,并通过Noisy-OR模型[9]判断新包的类型P(Yi|Bi):

其中P(yi|xij)为各示例的似然概率,计算方法如下:

式中H(x)为采用Online AdaBoost训练的强分类器。sigmoid函数为
在跟踪过程中,第一帧给出初始目标位置。学习器将第当前帧目标初始位置及附近的一定数目的等大小的图像块,以及它们的仿射变换,作为一个正包;在正包区域之外,选取一定数量的等大小的块作为负包,进行训练。在随后的帧序列中,检测器使用学习器上一帧学习到的模型,对目标可能出现的区域进行检测,选取可能性最高的位置作为这一帧目标的预测位置,并更新学习模型。
1.2 Online AdaBoost分类器
Online AdaBoost算法对模型的训练,分为模型初始化和模型更新两个阶段。在模型初始化阶段,Online AdaBoost算法与经典AdaBoost相似[10]。而在模型更新阶段,Online AdaBoost算法并不是对检测到的目标位置重新学习建模,而是保留上一帧学习到的t个错误率最低的弱分类器,替换剩下T-t个错误率较高的弱分类器为本次学习过程中产生的最优弱分类器来实现模型更新。本文使用随机蕨森林作为弱分类器。
蕨(ferns)是一种简化的树[11],随机蕨森林即是一种随机森林的衍生算法,它高效,精确,并且能够适应在线更新[12]。随机蕨森林首先随机的选择一个特征子集,用以生成数个蕨,分类时使用半朴素贝叶斯的方式,即公式(3),综合各个蕨的分类结果计算最终结果。
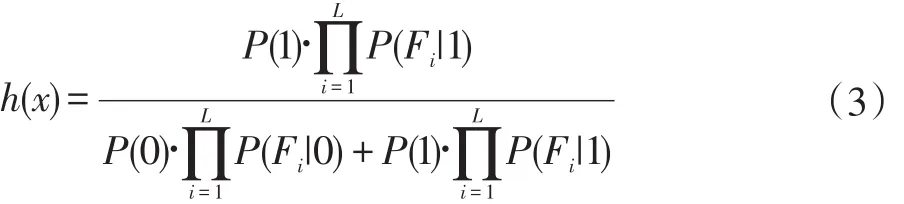
公式中,y∈{0,1},是图像子块的标记。L为特征子集的总数,Fi为特征子集。单个蕨会在图像样本上随机的做S次2bitBP[13](2bit Binary Patterns)特征提取运算,每次提取得到一个特征值xi∈[0,3],S次提取运算后得到由xi组成的特征向量x,作为一个特征子集。每个特征都有四种可能取值,因此单个蕨是一棵深度为S+1的完全四叉树,非叶子节点的每一层都是一个特征,根据特征值的不同走向不同的分支。叶子节点则是不同特征向量所表示的图像块是否是目标区域的后验概率,S个特征就会产生4s个叶节点。
1.3 目标分块跟踪
为解决局部遮挡问题,需要将目标区域分成若干子块,从子快中选出数块作为候选快,之后对每个候选块进行独立跟踪,当某个跟踪的子块被遮挡,可以换其他非候选块进行跟踪。
首先将目标区域均匀分割为K块,如图1所示,所有块的集合记作P。需要注意,K越大,每个子块所包含的信息越少,跟踪效果越差,本文K为8。分块时,记录每块的位置信息和偏移信息,以供定位目标时使用。中,是每个块的第一个像素坐标(即最左上角的像素坐标)为每块的宽和高。设为t帧的目标坐标,t为帧序号,则Ok中各值的计算方法如下:

计算每个滑动窗口ƒj和子块Pi之间特征向量的相似度Sij,得到Sij最大的M个子块构成候选块集合SP,余下子块放入非候选块集合UP。本文实验中M=4。之后对候选块进行独立跟踪,如果某个候选块在跟踪过程中遭遇遮挡,则从非候选块集合中选择一块替换被遮挡的候选块进行跟踪定位。在每一帧的所有候选块定位完成后,根据各候选块的位置与其偏移信息,定位目标在当前帧的最终位置。

图1 目标区域分割
2 运动预测与子块模型更新
2.1 运动预测
检测算法在t帧需要对图像中所有目标可能出现的区域进行检测,以确定目标的位置,通常这个区域是整个图像。在结合多尺度滑动窗口之后,分类器需要对大量的图像块进行分类,这个过程非常消耗时间。在现实情况中,视频中的目标较少会进行无规则的运动,因此对其运动情况进行快速预测,可以有效减少检测器需要检测的区域。
本文使用拉格朗日插值算法对目标运动情况进行近似拟合,算法公式如下:

其中n为插值次数。li(x)为插值基函数,可以表示为:
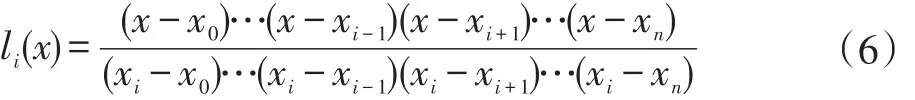
拉格朗日插值算法的具体数学定义请参见文献[14]。分别使用两次插值算法,根据已有目标运动信息,对目标中心点在X轴与Y轴上的运动情况进行拟合,两部分结合以预测下一帧目标的大致位置。该算法应用中,xi是作为插值节点的帧序号,yi是在xi帧中目标中心位置的X轴或Y轴坐标,x则为需要预测的那一帧的帧序号。考虑到只需要预测下一帧目标的中心位置,在这里x=xn+1,计算结果为xn+1帧的X轴或Y轴坐标。拉格朗日插值算法计算速度很快,但是在插值节点数量过多时会产生Range现象,插值节点数量的不同会影响预测精度。如图2所示,实验发现,每次预测插值节点数量定为2效果最好,这也意味着,事实上两次预测均为线性预测,因此式(5)可以简化为两点式:
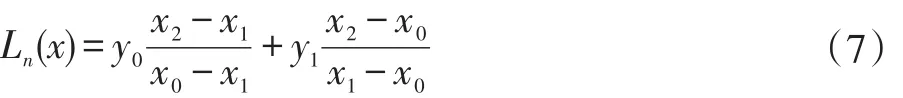
从视频第三帧开始,每次执行检测算法检测t帧目标位置之前,先令x0=t-2和x1=t-1,x2=t时的计算结果即为目标的预测位置,之后检测器对其周围区域进行检测。如果检测失败,则对整个图像进行检测。如果依然失败,说明目标受到大面积遮挡,接下来的帧将不执行预测,直到重新检测到目标。
3.2 改进的子块模型更新策略
在理想情况下,第一帧之后的帧序列,每一帧都能检测出M个候选块对应的目标子块根据分块时记录的每块偏移信息,对整体目标进行定位,可以使用如下方法进行定位:
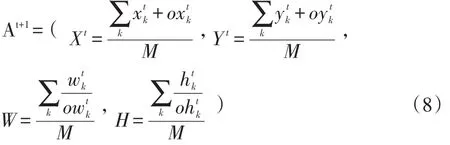

图2 五种场景共3059帧环境下不同节点数量预测值与实际值的平均误差
方法中的Xt,Yt表示目标区域第一个像素所在坐标,Wt,Ht表示目标区域的宽和高,k表示候选块集合SP中的块序号。定位算法计算后的结果即为本帧目标所在区域At+1。在没有遮挡的情况下,可以在得到t+1帧目标区域后,重新分块、提取样本、使用Online Ada⁃Boost的算法,更新每一个目标子块对应的学习模型。但如果目标区域遭到遮挡,目标的检测与学习模型的更新都可能会出现问题。
当目标出现局部遮挡,并且遮挡出现在候选块区域,检测时就能发现。检测器在对当前帧进行检测时,如果某一块出现在多尺度滑动窗口内所有的样本检测概率均小于50%的情况,则认为该块受到遮挡。候选块中某一块SPk被遮挡时,可以从非候选块集合UP中选择一块,替换SPk对当前帧进行检测。如果依然被遮挡,重复此过程。如果遮挡出现在非候选块区域,检测时由于只检测候选块区域,所以不会影响目标的检测,但同时检测阶段也无法发现目标被遮挡。
当检测与定位完成后,如果直接更新所有子块的学习模型,被遮挡区域的更新将会产生巨大的误差,因此在更新前,需要使用t+1帧的目标位置,对UP集合内的子块做一次自检测,即使用每个子块的检测器,对其在t帧对应的目标区域的子块作为样本进行分类,分类结果为正的概率即为该子块的自检正确率,过程如图3。自检正确率小于50%的子块认为被遮挡,本次不对其学习模型进行更新。结合在线多示例学习分类器,本文算法整体如下:
算法1运动预测的多示例学习分块目标跟踪算法
输入:·图像序列 I1,I2,···,In,并给出第一帧 I1的初始目标区域A1;
执行:
·将A1分割为K块,计算并记录每块信息Pk;
·选择自检率最高的M块作为候选块,其余块为非候选块;
·为每一个子块作为目标区域,建立检测器,并训练学习模型;

3 实验结果及分析
为验证本文提出的多示例跟踪方法的有效性,本文从公开的跟踪测试视频库中选取五种场景共3059帧的图像序列进行测试,同时对改进前的多示例学习分块目标跟踪(MFT[8])算法,以及常用的 TLD[13],MIL[15],CT[16]三种算法与本文改进后的算法进行比较。在实验中,每个随机蕨提取6次特征,每个蕨森林拥有8个蕨,强分类器由5个随机蕨森林构成,更新时设置t=3,即保留3个错误率最低的随机蕨森林。每次更新运动预测完成后,检测区域为以预测点为中心,长宽均为max(length,width)*0.8的矩形区域进行检测。其他算法的参数参考相应文献。在误差表示上,使用中心误差与重叠率。中心误差表示跟踪结果的中心与实际目标的中心之间的欧几里得距离;重叠率为跟踪标注的矩形框与目标真实位置的矩形框的重叠比率,计算方法为 overlap=area(A∩B)/area(A∪B),其中 A,B 为跟踪标注的矩形框与目标真实位置的矩形框,area()计算面积。
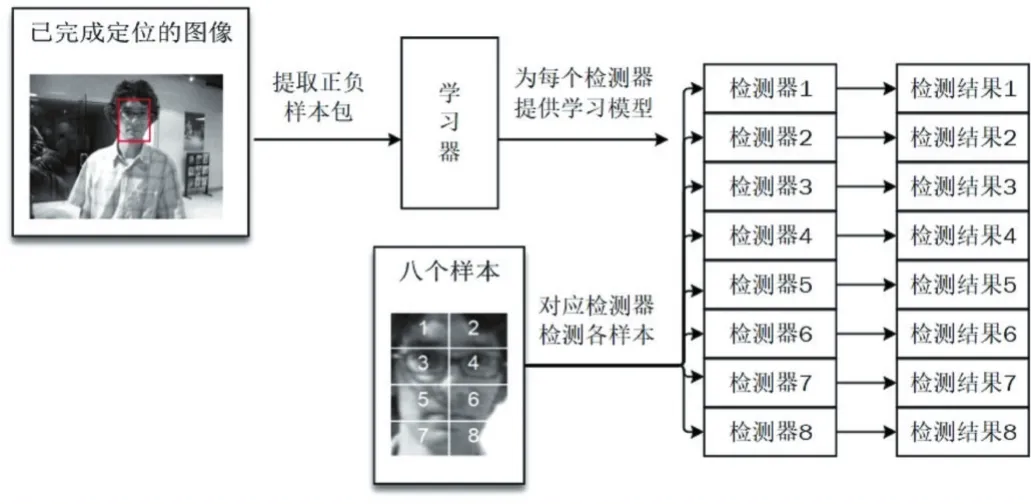
图3 自检正确率计算过程,此处8个样本对应8个检测器
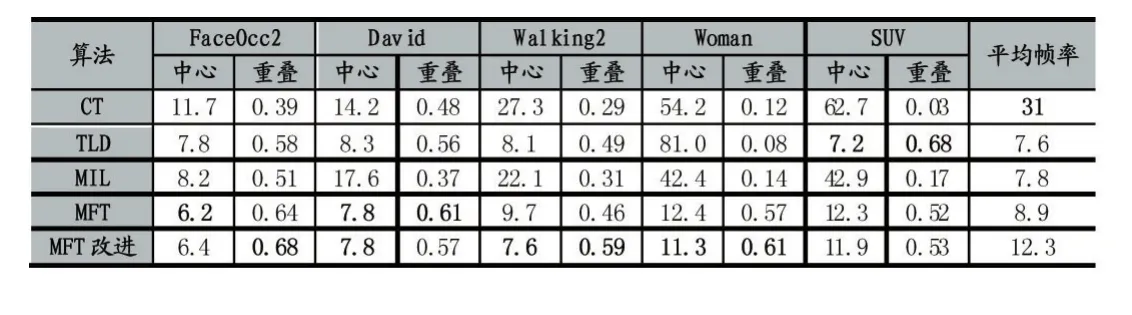
表1 各算法在各场景下的中心误差,重叠率与平均帧数
如表1所示,在算法的处理速度上,本文算法相比改进前的MFT算法有明显提升,但处理速度的提升幅度并不如检测面积缩小的那么大,原因在于本算法并没有降低学习阶段的计算量,而且在学习模型更新前加入了遮挡检测,学习模型更新时要为所有未遮挡的子块进行更新,加大了计算量。目标分块的方法需要对每一个子块分别建立学习模型与检测器,虽然这将使计算量提升,但各子块间的学习与检测计算完全独立,互相之间并无同步问题,使用多线程计算后处理速度并不比TLD与MIL算法慢。CT算法则主要是基于压缩感知的特征降维,降维后特征提取简单,分类过程也是朴素贝叶斯分类器,处理速度非常快。

图4 各算法在各场景下的跟踪结果
在算法的精度上,改进算法相比原算法有小幅提升。在FaceOcc2与David场景中,MFT改进算法与原算法差别不大,可能是这两个序列跟踪的目标是人脸,整个跟踪过程中目标形状并未出现变化,而在Walk⁃ing2与Woman中跟踪的是走动的行人,行人身体的小幅摆动在受遮挡之后,使改进算法的表现更好。
从图4可以更清晰的看出各个算法的跟踪效果。FaceOcc2与David是两种对人脸进行跟踪的场景。在FaceOcc2中,背景基本保持不变,各算法均能保持较好的跟踪,但是最后一张图片中,在帽子与书本同时遮挡面部的情况下,改进前与改进后的多示例分块学习算法都跟踪却失败了,这是因为改进后的算法在更新学习模型之前,会先进行遮挡检测,发现遮挡后不更新被遮挡的子块,使被帽子遮挡的子块不会被更新,而改进前的算法则不会更新非候选块,这样的策略导致在书本遮挡之后,目标被遮挡面积过大,跟踪失败。
在Walking2、Woman与Suv中,目标都是在运动中遭到遮挡的,这里可以明显看出改进前与改进后的多示例学习分块跟踪算法都有较高的鲁棒性。在Walk⁃ing2场景中,目标受到相似物体的遮挡时,预先预测目标位置以减小检测区域的改进算法与跟踪-学习-检测相结合的TLD算法能更好的跟踪目标。Suv场景中,目标在运动中经常遭到树木的完全遮挡,CT算法与MIL算法在前期跟踪就失败了,而MFT与其改进算法在整个跟踪过程中均有较好表现,可见本文算法在局部遮挡与完全遮挡后目标重新出现两种情况下均能实现稳定的跟踪。
4 结语
目标跟踪是计算机视觉领域的重要研究内容,应用场景广泛。本文在多示例学习目标分块跟踪方法的基础上进行改进,在对图像进行检测前首先预测目标的大致位置,以减少检测区域来提升算法处理速度,同时在更新学习模型前先检测目标是否被局部遮挡,之后更新所有未被遮挡的子块,以提高跟踪会发生形变目标的能力。试验表明,算法改进后,算法处理速度有明显提升,并且在被跟踪目标有一定程度形变时,跟踪精度也有所提升。但算法改进后,依然不能对变化较大的目标进行稳定跟踪,这是下一步工作需要解决的问题。
参考文献:
[1]薛陈,朱明,刘春香.遮挡情况下目标跟踪算法综述[J].中国光学与应用光学,2009,2(5):388-394.
[2]X Qi,Y Han.Incorporating Multiple SVMs for AutoMatic Image Annotation.Pattern Recognition,2007,40(2):728-741.
[3]Viola P,Platt J C,Zhang C.Multiple Instance Boosting for Object Detection[C].International Conference on Neural Information Processing Systems.MIT Press,2005:1417-1424.
[4]J Gall,A Yao,N Razavi.Hough Forests for Object Detection,Tracking,and Action Recognition[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2011,33(11):2188-202.
[5]邢晨,薛模根,袁广林,等.基于Online AdaBoost的偏振图像目标跟踪[J].合肥工业大学学报(自然科学版),2011(11):1650-1654.
[6]Naik N,Patil S,Joshi M.A Fragment Based Scale Adaptive Tracker with Partial Occlusion Handling[C].TENCON 2009-2009 IEEE Region 10 Conference.IEEE,2009:1-6.
[7]Adam A,Rivlin E,Shimshoni I.Robust Fragments-Based Tracking Using the Integral Histogram[C].IEEE Computer Society Conference on Computer Vision and Pattern Recognition,New York,USA,2006:798-805.
[8]才华,陈广秋,刘广文.遮挡环境下多示例学习分块目标跟踪[J].吉林大学学报(工学版).2017,47(1):281-287.
[9]Zhang C,Platt J C,Viola P A.Multiple Instance Boostingfor Object Detection[C].Advances in Neural Information Processing Systems,2005:1417-1424.
[10]邢晨,薛模根,袁广林,等.基于Online AdaBoost的偏振图像目标跟踪[J].合肥工业大学学报(自然科学版),2011(11):1650-1654.
[11]M.Ozuysal,P.Fua,V.Lepetit.Fast Keypoint Recognition in Ten Lines of Code.CVPR,2007,5.
[12]Zdenek Kalal,Jiri Matas,Krystian Mikolajczyk P-N Learning:Bootstrapping Binary Classifiers by Structural Constraints.CVPR,2010 June 13-18.
[13]Z.Kalal,J.Matas,K.Mikolajczyk.Online Learning of Robust Object Detectors During Unstable Tracking.OLCV,2009.3,5,7.
[14]李庆扬.数值分析[M].清华大学出版社,2008.
[15]Babenko B,Yang M H,Belongie S.Robust Object Tracking with Online Multiple Instance Learning[J].IEEE Transactions on Pattern Analysis&Machine Intelligence,2011,33(8):1619.
[16]Zhang K,Zhang L,Yang M H.Fast Compressive Tracking[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(10):2002-2015.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
电子产品世界(2022年4期)2022-04-21
房地产导刊(2022年4期)2022-04-19
老年教育(2021年5期)2021-05-25
计算机系统应用(2021年2期)2021-02-23
计算机应用与软件(2020年5期)2020-05-16
计算机应用与软件(2020年1期)2020-01-14
新生代(2019年10期)2019-10-18
计算机测量与控制(2019年4期)2019-05-08
娃娃乐园·3-7岁综合智能(2016年2期)2016-10-24
