
多模态维度情感预测综述
2018-04-23 04:00李霞卢官明闫静杰张正言
自动化学报 2018年12期
李霞 卢官明 闫静杰 张正言
情感是人们日常生活中常见的一种心理现象.对情感的准确识别是利用情感进行交流的前提,在日常人际交往中有着重要的作用.对于智能机器,只有能够对人的情感状态进行快速准确的判断,才有可能进一步理解和响应人类情感,从而实现与用户进行自然、友好、和谐地交互[1].例如在智能汽车系统中,对驾驶员的情感状态进行实时监测,并根据监测结果给予必要的响应便能够有效避免事故的发生;在智能电话服务系统中,对来电者的情感状态进行自动判断,根据判断结果给予合适的响应或将控制线转接给人工处理,便能有效地提高服务效率和质量.
人的情感是通过面部表情、身体姿态、声音以及生理信号等多种模态表现出来的.情感判断可以基于这些模态中的一个或多个来进行,但是单个模态的信息存在信息不全面、容易受噪声干扰等缺陷,目前越来越多的研究者开始综合运用多个模态的信息进行情感判断.多个模态的信息能够互相印证、互相补充,从而可以为情感判断提供更加全面准确的信息,提高情感判断的性能.D0Mello等[2]对2009~2013年出现的多模态情感识别系统进行元数据分析发现,相比于单模态情感识别系统,平均性能提高了9.83%,这充分肯定了多模态信息融合对提高情感识别性能的有效性.
要对人的情感状态进行判断,首要的任务是建立情感状态的表示模型.在情感识别领域,常用的情感表示模型主要有离散情感模型和维度情感模型.离散情感模型使用快乐、悲伤、愤怒等形容词标签表示情感,虽然此种表示方式非常简单、直观,但无法区分情感的细微差别,也无法描述情感的演变过程.维度情感模型用几个取值连续的维度将情感刻画为一个多维信号[3].由于每个维度的取值可以连续变化,因此可以对情感的细微差别进行区分,同时可以通过对情感状态的实时标注跟踪情感状态的演变过程.同时,心理学的研究表明,一些情感维度的取值情况与人的记忆、注意等认知行为具有密切联系[1],这使得机器更容易根据维度情感预测结果来理解和响应用户的情感行为.
随着手机、平板等各种便携录像、录音设备,以及iwatch等智能可穿戴设备的出现,人们随时随地获取视频、音频及生理信号成为可能,这为多模态维度情感预测提供了数据基础,拓展了多模态维度情感预测的应用领域.在多模态交互式对话系统中,系统中的虚拟人可以根据用户的语音、面部表情和姿态预测用户的维度情感,并根据预测结果选择合适的词语与用户进行对话,将用户的情感状态向某个特定的情感状态进行引导.
多模态维度情感预测是综合运用情感的多个表现模态对各个情感维度的取值进行预测,是一个复杂工程,包括建立多模态维度情感数据库、从各个模态中提取特征、选择与设计预测模型、信息融合等环节,每个环节的处理对最后的预测性能都具有重大影响.本文综述了多模态维度情感预测各个环节的研究现状,对比和分析了不同方法对预测性能的影响,并总结出多模态维度情感预测面临的挑战及发展趋势.
1 维度情感模型
离散情感模型和维度情感模型是情感识别领域广泛使用的两种情感表示模型.离散情感模型使用形容词标签将情感表示为几种相对独立的情感类别(例如Ekman提出的快乐、悲伤、愤怒、恐惧、厌恶和惊讶六种基本情感[3]).离散情感模型因其简单直观的优点,在情感识别领域得到了极其广泛的应用.但是存在许多缺点:1)情感的类别总是运用某个词语表示,导致运用此模型能够表示的情感范围有限,同时导致情感的编码与文化和语言具有密切的联系[4],从而限制了情感编码的普适性;2)很多情感类别之间存在高度的相关性[5],但在此模型下很难对这种相关性进行度量和处理;3)情感的产生、发展和消失是一个过程,而此模型无法描述情感的发展进程.
为了克服离散情感模型的缺点,研究者建立了维度情感模型.维度情感模型认为情感是一种高度相关的连续体,运用几个取值连续的基本维度将情感状态描述为多维空间中的某一个坐标,每个维度是对情感的某一方面的度量[5].对于情感具有哪些维度,心理学家并没有统一的认识,其中认同度最高的一种模型为“愉悦(Pleasure)–唤醒(Arousal)–支配(Dominance)”模型或PAD模型,此模型认为情感具有愉悦维、唤醒维和支配维三个维度.愉悦维也称为效价(Valence)维,是对人的愉悦程度的度量,从一个极端(苦恼)到另一个极端(狂喜);唤醒维也称为激活(Activation)维,是对生理活动和心理警觉水平的度量,如睡眠、厌倦等为低唤醒,清醒、紧张等为高唤醒;支配维也称为注意(Attention)维或能量(Power)维,是指影响周围环境及他人或反过来受其影响的一种感受,高的支配度是一种有力、主宰感,而低的支配度是一种退缩、软弱感[5−6].Russell在对PAD模型进行深入研究时发现,支配维更多地与认知活动有关,愉悦和唤醒两个维度就可以表示绝大部分不同的情感,他采用环状结构模型表示复杂的情感[5].在环状结构模型中,每个维度的取值极限构成一个圆,圆的中心表示中性的情感[7],愉悦和唤醒是两个相互正交的维度,情感均匀地分布在圆环的内部[5],此模型称为愉悦–唤醒模型(也称为效价–唤醒模型或VA模型),运用此模型可以表示多数基本情感,如图1所示[8].由于愉悦–唤醒模型的简单和实用性,很多维度情感预测的研究都是在这两个维度上进行的.理论上讲PAD模型能够表示无穷多种情感,但它仍然不能表示人类所能体验的所有情感,例如“惊讶”就处在了此情感空间的外部[2].为了更完整地描述情感,一些研究者将期望(Expectation/anticipation)维作为第四个维度,强度(Intensity)维作为第五个维度[9].期望维是对个体情感出现的突然性的度量,即个体缺乏预料和准备程度的度量;强度指的是个体偏离冷静的程度.Fontaine等[10]的研究表明,第四个维度的加入能够将“惊讶”与其他的情感类型区分开来,基本能够区分日常生活中的所有情感.因此,在维度情感预测中,也有不少是基于前四个维度进行的.
近年来,维度情感预测受到了越来越多的关注.其主要优势在于:1)维度情感模型相比于离散情感模型具有更强的表示能力,尤其是在处理自然的数据时优势更加明显,此时情感状态的范围非常广泛,很难用有限的几种情感类型描述[4];2)运用维度情感模型可以对情感的发展变化过程进行跟踪[4];3)运用维度情感模型可以对情感的相似性和差异性进行度量[9];4)心理学研究表明,人类的决策、推理、记忆、注意等认知都与PAD模型中的三个维度存在密切关系,例如,Lang等研究表明愉悦维度决定了欲求动机系统和防御动机系统哪个被情感刺激激活,而唤醒维度决定了每个动机系统被激活的程度[11].由此可见,在人机互动中,运用维度情感模型比运用离散情感模型更利于机器充分理解人的情感并做出合适的反应.

图1 愉悦–唤醒模型Fig.1 Pleasure-arousal model
2 维度情感标注
维度情感模型虽然具有很多优点,但是维度情感预测直到最近几年才得到人们的更多关注,主要原因是这种表示方式比较抽象,标注比较困难.
维度情感标注工作是基于情感量化理论完成的,目前没有一个统一的方法.SAM(Self-assessment manikin)系统是一种被多数研究者认可的维度情感量化方法,它基于PAD模型建立[12],使用卡通小人的形象表示PAD模型中三个维度的取值.图2是效价维、唤醒维和支配维的取值分布[12],以卡通小人眉毛和嘴巴的变化表示效价维的取值;以心脏位置出现的震动程度以及眼睛的有神程度表示唤醒维的取值;以图片的大小表示受控制的程度.在某个维度标注的过程中,只需从对应的卡通小人中选出一个最符合当前情感状态的即可.使用的小人数目由对此维度进行量化的数目决定,一般为5个或9个.每个小人对应的具体数值没有一个严格规定,使用9个小人时,对应的9个数字可以是1~9的整数,可以是−4~4的整数,也可以是[−1,1]的9个等间隔的值[13].相比于其他情感量化方法,SAM系统具有简单、快速、直观的优点,并且避免了不同人对同一词语的不同理解造成的差异,从而获得的标注结果方差较小、不同标注者间的一致性较高[14],因此SAM系统经常被用于维度情感的标注任务中.在每个卡通小人的下方标注数字并与小人一起呈现于屏幕上,允许标注者点击两个数字之间的任意位置,即可以实现对目标维度的连续赋值[13].
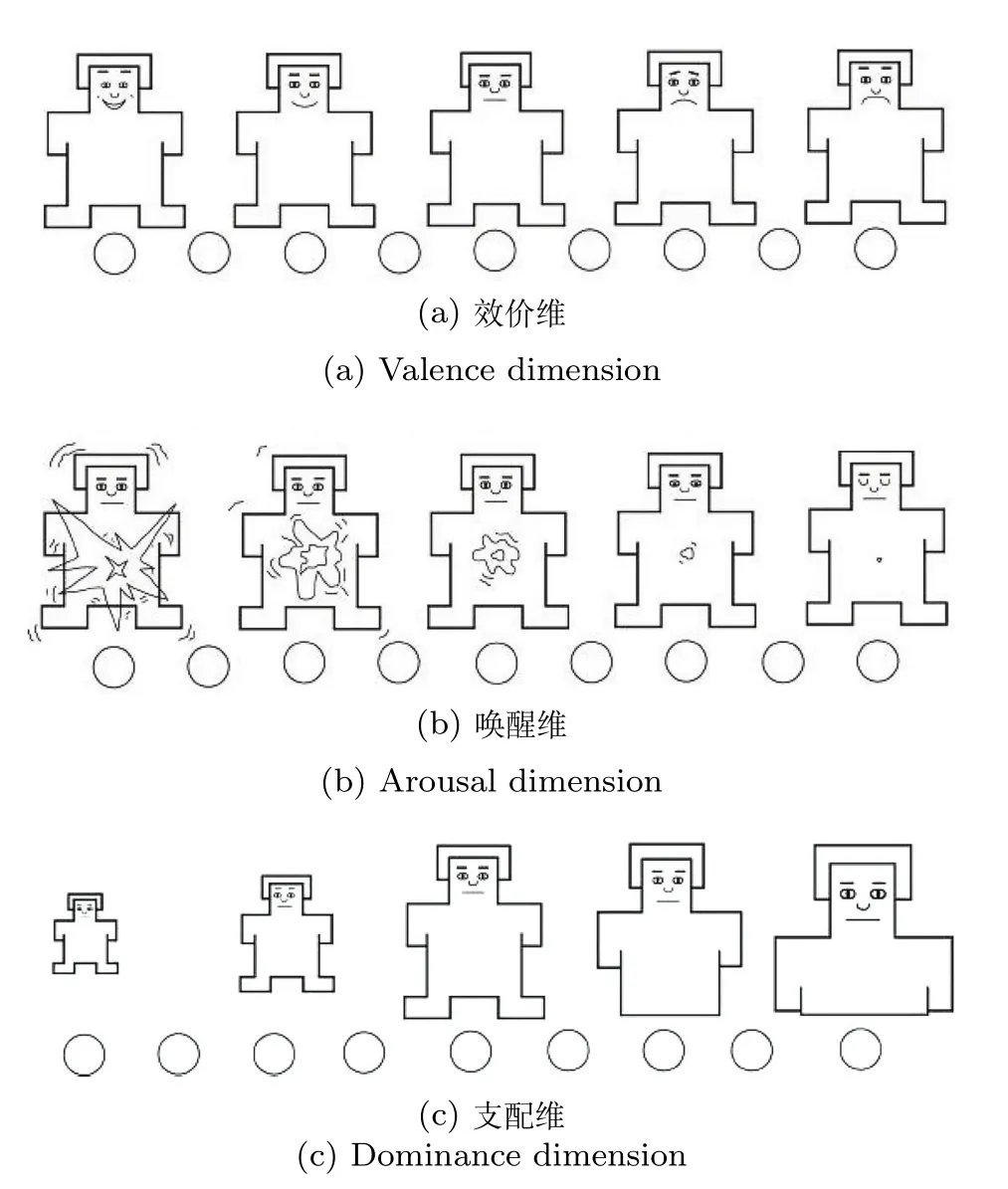
图2 SAM系统Fig.2 SAM system
情感是一个不断变化的过程,为了对每个情感维度的取值进行实时跟踪,研究者开发了很多标记工具,FEELtrace[7]和ANNEMO[15]是两个常用的标记工具.FEELtrace是基于效价–唤醒环状模型建立的,如图3所示[7],将以效价维和唤醒维为主轴的圆呈现于电脑屏幕上,标注者只需根据自己感知的情感用鼠标拖动圆形光标到合适的位置即可同时对效价维和唤醒维赋值[7].ANNEMO是一种基于网页的维度情感标记工具,如图4所示[15],它将视频和标记光标同时显示于一个窗口,用户在观看视频的同时,对视频中对象的某个情感维度进行时间连续的标记[15].与FEELtrace相比,ANNEMO使用更加方便,而且一次只对一个维度进行标记,得到的结果更加精确.

图4 ANNEMO标注示例Fig.4 Example of ANNEMO annotation
3 维度情感预测的性能评估指标
维度情感预测问题主要可以分为两种类型,一是根据一个或多个维度的取值将维度情感预测问题退化为一个分类问题[9],此分类问题既可以是按照某个维度的取值分成正与负(或积极与消极)两种类型的两分类问题[16],又可以是按照某个维度的取值分为低、中、高三种类型的三分类问题[17],还可以是在效价–唤醒空间中用四个象限代表四个类别的四分类问题[18]等;二是对每个维度的连续取值进行预测,此时维度情感预测问题是一个回归问题[19].
当维度情感预测问题退化为分类问题时,称为维度情感分类,此时预测性能的评价指标与离散情感识别使用的评价指标相同,主要有整体分类准确率(Accuracy)、召回率(Recall)、精确率(Precision)、F1-score等.设共有A,B两种类别,nTP是A类样本正确分类的样本数,nFN是A类样本错误分类的样本数,nFP是B类样本错误分类的样本数,nTN是B类样本正确分类的样本数.则整体分类准确率定义为
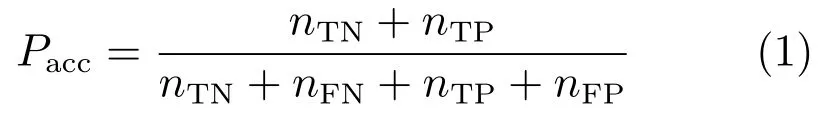
A类样本的分类准确率或召回率定义为[20]
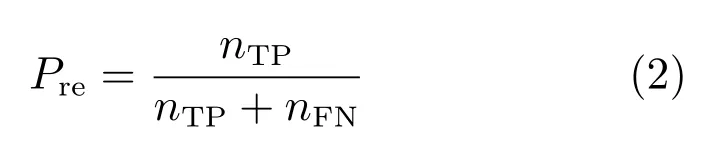
A类样本的分类精确率定义为[20]
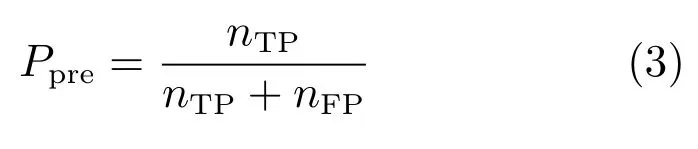
A类样本的分类F1-socre定义为[20]
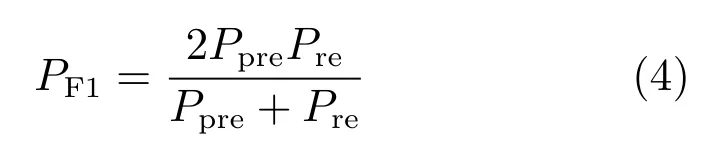
当维度情感预测为回归问题时,称为连续维度情感预测,此时预测性能的评价指标是一个不断探索的问题,早期的文献一般采用均方误差(Mean squared error,MSE)度量估计的性能.设是估计标签,θ是真实标签,n为样本数目,分别是和θ的方差,分别是和θ的期望,则MSE定义为[21]

MSE描述了预测与真值的偏差,但MSE对于异常值敏感,以及对θ与的相对变化趋势无法进行描述,因此并不能很好地描述预测与真值的吻合度.鉴于MSE的缺点,Pearson相关系数(Pearson correlation coefficient,CC)被用来作为连续维度情感预测的评价指标,其定义为[21]

CC的取值范围为[−1,1],反映了预测与真值具有线性关系的紧密程度.图5给出了两组效价维的预测与真值的对比图[21],从图5可以看出,CC能够很好地反映预测与真值的协同变化关系.但是,由于CC对预测的幅值不敏感,无法对θ与的偏差进行度量,因此仍不能很好地描述预测与真值的吻合程度.为了更好地描述预测与真值的吻合程度,AV+EC 2015[22]竞赛中开始使用一致性相关系数(Concordance correlation coefficient,CCC)作为预测性能的评价指标,其定义为

CCC结合了CC与MSE的优点,既反映了预测与真值的协同变化关系,又反映了预测与真值的偏差,因此能够更好地反映预测与真值的吻合程度,是目前广泛使用的连续维度情感预测性能评价指标.图6给出了CC相同,而CCC不同的预测与估计的吻合程度对比[23],显然CCC高的吻合程度更高.

图5 具有不同MSE和CC的效价维的预测与真值的对比图Fig.5 Comparison of the prediction and truth values of valence dimension with different MSEs and CCs
4 多模态维度情感预测研究现状
人类的情感可以通过面部表情、身体姿态、语音、生理信号等多个模态表现出来.面部表情和身体姿态都是可视的,有时也将它们统一看作视觉模态;语音信息可以从听觉途径获得,也称为听觉模态.从这两个(或多个)模态中进行情感判断与我们的日常生活经验相符,而且它们可以通过非侵入性的传感器获取,相对来说简单方便成本低,因此一直以来基于这几个模态中的一个或多个进行情感判断都是一个重要的课题.近些年随着可穿戴传感器的出现,使得生理信号的实时获取成为可能,这促进了生理信号在情感识别研究中的运用.
面部表情是人们日常交流中理解对方情感的主要线索之一[24−25].面部表情的最大优点是它对六种基本情感的表现具有普遍性,并与文化背景无关[26].因此早期的情感识别主要集中于运用面部表情进行六种基本情感的识别.在维度情感模型下进行情感预测,面部表情自然也是经常使用的重要线索之一.
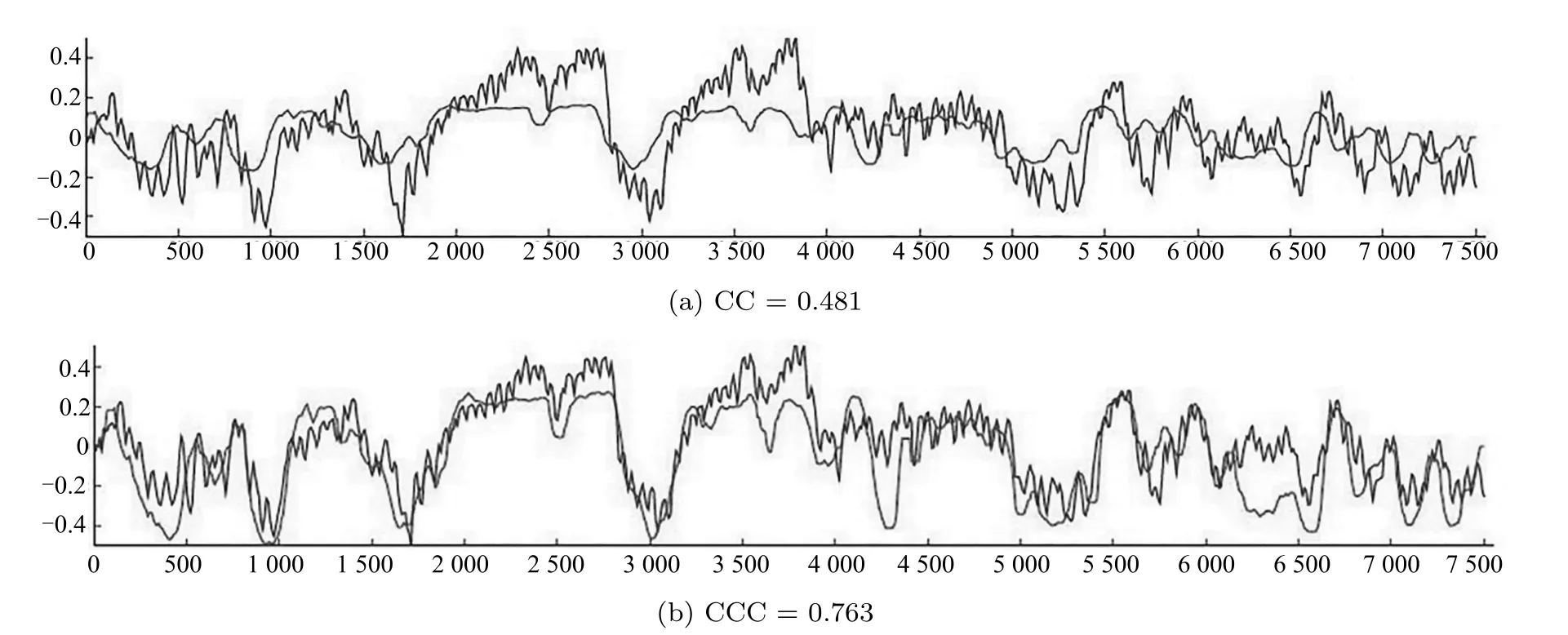
图6 CC相同的条件下唤醒维的预测与真值的对比图Fig.6 Comparison of the prediction and truth values of arousal dimension with the same CC
Ekman和Friesen的研究[27]表明身体姿态比面部表情能够为维度情感预测提供更多的信息.因此很多维度情感预测的工作是基于身体姿态进行的,Gunes等[28]运用头部运动的幅度和方向,点头和摇头的频率对五个情感维度的取值进行了预测.
目前,运动捕获系统也经常用于获取面部和身体行为信息,它通过在面部和身体的固定位置放置一些标记,记录人的运动行为.IEMOCAP[14]和CreativeIT[29]数据库都提供了由运动捕获系统获取的面部和身体行为数据.
听觉模态是可用于情感识别的一个重要模态,声音信号中既有明确的语言信息又有非语言的声学信息,这些信息都可用于情感状态的推断[9,30].很多实验[31−32]都表明使用音频信息比视频信息能够获得更好的维度情感预测效果.因此,不管是进行单模态还是多模态维度情感预测,听觉模态都非常重要.
心理学的研究表明,人的情感与人的中枢神经系统和自主神经系统等都具有密切的联系.人的不同情感活动会引起大脑的不同部位发生不同的反应[33];能够激起人的交感神经系统活跃,从而引起肾上腺素和去甲肾上腺素分泌增多,心血管系统发生一系列变化[33];能够引起内外腺体变化,从而影响激素分泌量的变化[33]等.因此,脑电图(Electroencephalography,EEG)、皮肤电活动(Electrodermal activity,EDA)、肌电图 (Electromyography,EMG)、心电图(Electrocardiogram,EKG 或ECG)、眼电图 (Electrooculogram,EOG)、心率、呼吸率等[4,34]生理信号也常用来进行维度情感预测.
上述这些模态可以单独用于情感预测,但是单个模态存在信息不全面、容易受噪声干扰等固有缺陷,造成依赖单个模态的情感预测系统在鲁棒性、精确性等方面都不能满足使用要求,这在很大程度上限制了它的应用[2].而且,心理学领域的研究和情感识别领域的实验结果都表明同时考虑多个模态的信息确实能够提高情感识别的效果,因此,多模态情感预测受到了人们极大的重视.构建一个多模态维度情感预测系统一般包括多模态维度情感数据的收集、各个模态中的特征提取、预测模型的设计和选择、信息融合和其他影响因素的处理.
4.1 多模态维度情感数据库
在日常生活中,各种情感状态的出现具有不平衡性,为了获取丰富而全面的情感数据,情感数据的收集一般是在实验室进行的.由于表演的情感与自然的情感在很多个方面都存在差异,目前一般不直接要求对象表演某种情感,而是设计某种场景来诱导对象的情感,这样获得的情感数据也被认为是自然的数据.近年来研究者们在多个场景下收集了多模态情感数据,并在不同的维度上进行了标注,常用的多模态维度情感数据库有SEMAINE,RECOLA,IEMOCAP,CreativeIT,DEAP,VAM等.
SEMAINE(Sustained emotionally colored machine-human interaction using nonverbal expression)数据库[35]是为了实现计算机能够与人类进行流畅的、富有情感的对话而建立的.目前公开的数据是在被称作Solid SAL(Sensitive artificial listener)的场景下获取的,此场景模拟了人机对话的过程,由人扮演了机器角色与用户进行对话.机器角色根据用户的情感状态选择词语与用户进行对话,使得对话不中断,并将用户的情感状态向某个特定的情感状态引导.共有24个用户分别与四个不同性格的机器角色进行对话,每次对话都记录了用户和机器角色的正面视频和音频,以及用户的侧面视频.标注人员按照视频帧率逐帧给出了用户在对话过程中的情感状态在唤醒维、效价维、支配维、期望维和强度维五个维度上的取值.
RECOLA(Remote collaborative and affective interactions)数据库[15]共记录了46个参与者的情感数据,这些参与者两人一组被分成23组,每组通过远程视频会议讨论某个灾难场景下逃生的方案,并达成一致意见.数据库中包含所有参与者在讨论过程中的面部视频和音频数据,以及其中35个参与者的ECG、EDA数据.标注人员按照视频帧率逐帧给出了参与者前5分钟讨论过程中的情感状态在效价维和唤醒维的值.
IEMOCAP数据库[14]共记录了10个演员(5男,5女)的情感数据,这些演员一男一女组合被分成5组,每组按照脚本或即兴进行对话表演.同一对话内容由相同的演员表演两次,每次使用运动捕获设备记录对话一方的面部表情、头部姿势和手部运动数据,同时记录对话双方的视频和音频数据.数据库中共有174段对话,每一段对话都被分割成了语句,每个语句呈现的情感状态在效价维、唤醒维和支配维三个维度上的值用1~5的整数进行了标记.
CreativeIT数据库[29]共记录了16个演员的情感数据,这些演员两人一组被分成了8组进行即兴表演,共进行了50次表演.每次表演过程中,都记录了表演双方的视频和音频数据,以及使用Vicon动作捕获系统获取的演员全身动作数据.标注人员按照视频帧率逐帧给出了每个演员表演过程中的情感状态在效价维、唤醒维和支配维三个维度的取值.
DEAP数据库[13]记录的是32个参与者在观看音乐视频时的EEG信号、外围生理信号,以及其中22个人的正面视频.每个参与者都观看了40段音乐视频,并将自己在观看音乐视频过程中感受到的情感在唤醒维、效价维和支配维上给出了1~9之间的连续自我评估.
VAM数据库[36]中的素材来自德国的电视脱口秀节目Vera am Mittag.其数据分为三部分:VAM-video集、VAM-audio集和VAM-faces集.VAM-video集中的数据是从节目中分割出的1421条语句对应的嘉宾视频.VAM-audio集中的数据是从上述语句中选出的1081条比较好的语句对应的声音信号,并由标注人员对每条语句展现的情感状态在唤醒维、效价维和支配维三个维度上用[−1,1]的5个等间隔值进行标注.从VAM-video集中选取了大部分时间都是说话者正面图像的视频,并从中提取出说话者的面部图像,构成了VAM-faces集,共包含1867张图片.标注人员对VAM-faces集的图片中对象的情感状态在唤醒维、效价维和支配维三个维度上用[−1,1]的5个等间隔值进行标注.
表1总结了常用维度情感数据库的数据获取场景、参与者数目、记录的模态、标注的情感维度、标注者人数、使用的标注工具或标注方法、标签的取值范围及取值类型.
现有的数据库多数是在特定场景下诱导得到的,在一个场景下训练的系统在另一个场景下或在真正自然的场景下的泛化能力如何,是一个值得研究的问题,这依赖于多个场景以及真正自然的场景下多模态维度情感数据库的建立.构建多模态维度情感数据库与构建多模态离散情感数据库相比,除了要面临情感状态的出现不平衡、完整的多模态信息不容易捕捉等共同要面临的困难外,维度情感标签的标注也是一大困难.众所周知,情感是一个变化的过程,对于多模态情感数据给出时间连续的维度情感标签比按段给出维度情感标签要更有使用价值.但时间连续的维度情感标注不仅是一个耗时、耗力的乏味工作,而且由于时间连续的维度情感标注是一个比较精细的过程,因此标注结果与标注者自身的偏好、经验等都有着密切的关系.为了降低标注者自身的因素对标注结果的影响,常采取的方法[15]有:1)选择多个标注者共同完成标注任务;2)选择与标记对象具有相同母语的标注者;3)在标注工作开始之前对标注者进行训练使其能够尽量客观地给出维度情感的标注,并且能够熟练地使用维度情感标注工具;4)对多个标注者的标注结果进行插值、标准化等一系列后期处理,进一步减少标注偏差.
4.2 特征提取
无论是多模态还是单模态维度情感预测,也无论是维度情感预测还是离散情感识别,各个模态的特征提取都是非常关键的.特征提取后得到的特征维数往往较高,并且可能包含过多的冗余信息,从而影响最后的预测性能,因此常在特征提取之后进行特征选择和降维.表2总结了维度情感预测文献中使用的模态以及各个模态的特征提取、特征选择和降维方法,同时总结了预测模型和信息融合方法.
所有可以用于情感识别的特征都可以用于多模态维度情感预测中.如,视觉模态的几何特征、纹理特征(Gabor[37],LBP[38],HoG[39],Haar[40]等)、时空几何特征和时空纹理特征(LBP-TOP[41],LPQTOP[42],LGBP-TOP[43],时空Haar[44]等);音频信号中的声学特征(梅尔倒谱系数、对数频率能量系数、线性预测系数、线性预测倒谱系数、谱质心、频谱流量、感知线性预测系数、共振峰频率及其带宽、频率微扰和振幅微扰、声门参数等[4,8])及其函数;音频信号中的语言特征(BoW(Bag of words)[4],BoC(Bag of concepts)[4],BoNG(Bag-of-N-grams)[45],BoCNG(Bag-of-character-N-grams)[45]等);生理信号的时域特征(过零率、均值等)、频域特征(高频能量、低频能量等)、时间–频域特征(希尔伯特–黄谱、离散小波变换等)等[46−47],都可用于维度情感预测中.
特征提取后得到的特征维数往往比较高,并且可能包含的冗余信息过多,从而影响最后的识别性能.因此常在特征提取之后进行特征选择和降维,常用的特征选择和降维方法CFS(Correlation-based feature subset selection)[18],PCA(Principal component analysis)[48],SPCA(Supervised PCA)[48],KPCA(Kernel principal component analysis)[50],LDA (Linear discriminant analysis)[50],GDA(General discriminant analysis)[50]等都可以用于维度情感预测中.这些经典的特征提取、特征选择和降维方法使用广泛,在很多综述文章(如文献[4,8−9,70]等)都有论述.

表1 常用维度情感数据库总结Table 1 Summary of the frequently used dimensional emotion database

表2 维度情感预测文献总结Table 2 Literature review of the dimensional emotion prediction

表2 维度情感预测文献总结(续)Table 2 Literature review of the dimensional emotion prediction(continued)
近年来,深度学习技术得到了突飞猛进的发展,在很多领域都得到了比较成功的应用.运用深度学习技术进行特征提取和选择,不仅可以减少人工的干预,减少手工提取和选择特征的复杂性和盲目性,而且提取的特征对于识别问题来说能够突出目标本质的差异性而忽略无关的差异性,从而能够提高目标识别的准确性[71].因此,研究者们也将深度学习技术应用到情感识别领域进行各个模态的特征提取和选择.
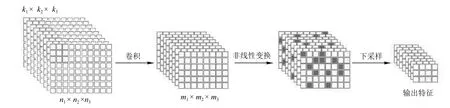
图7 单层卷积神经网络的三个阶段Fig.7 The tree phases of the single layer convolutional neural network
最常用于特征提取的深度网络是卷积神经网络(Convolutional neural network,CNN),它由多个单层卷积神经网络进行多次堆叠而成.单层卷积神经网络一般包括卷积、非线性变换和下采样三个阶段,如图7所示[72].每层的输入和输出为由一组向量构成的特征图.卷积阶段的卷积核决定了对输入特征图的观测模式,不同的卷积核得到不同的特征;非线性变换对卷积阶段得到的特征进行筛选;下采样也称作池化,其在减少数据量的同时能保留有用的信息.在CNN最后一层的输出特征图后接一个全连接层和分类器,即可实现分类或识别.CNN每一层的输出都可看作是输入信号的特征,可以单独用于不同的任务.卷积神经网络的特点决定了其非常适合对图像进行特征提取,因此在多模态维度情感预测中,CNN经常被用于提取视觉模态的特征(如文献[67−69]).对于其他模态的特征也可使用CNN进行特征提取,例如Zheng等[73]将语音信号转换为一系列二维矩阵,作为CNN的输入来提取语音特征;Poria等[74]将文本中的每个词语根据word2vec词典以及词性表示成一个306维的向量,一个句子中的所有词语对应的向量连接成一个向量作为CNN的输入进行特征提取.遗憾的是运用CNN提取非视觉模态的特征只是用于离散情感识别中,在维度情感预测中未见文献报告.使用CNN进行特征提取遇到的问题主要是数据量不足,从而导致过拟合现象,为了解决此问题一般采取的方法是,先使用其他库训练CNN,然后在目标库上进行特征提取,例如Chao等[69]使用在CFW和FaceSrub数据库上训练的CNN获取面部的表示.
由于情感的产生、发展和消退是一个过程,为了获取更多的情感信息,研究者们试图使用各种时空特征(时空几何特征[23,61]、时空纹理特征[23,61]等)来提高维度情感预测的性能.由于LSTM(Long short-term memory)具有对时间序列进行建模的能力,因此也经常用来提取特征或提高特征的区分能力.Zhang等[65]为了消除自然环境下的加性噪声和卷积噪声对维度情感预测的影响,基于LSTM的结构构建了循环去噪自编码(Recurrent denoising autoencoder,RDA)系统,对传统声学特征进行特征增强,获得了很好的效果.WÖllmer等[18]将LSTM与动态Bayesian网络(Dynamic Bayesian networks,DBN)相结合得到LSTM-DBN关键词检查器来获取二值的语言特征.
堆叠自编码(Stacked autoencoder,SAE)可以通过无监督的预训练和有监督的微调来确定系统的参数、提高特征的可区分性,因此也常用来进行特征提取或对传统特征进行抽象.SAE是以自编码器(AutoEncoder,AE)为基本单元堆叠而成的一种深度网络.AE的结构如图8所示,包括编码器和解码器两部分,输入信号通过编码器得到编码,再通过一个解码器得到输入信号的重构,重构与输入信号对比得到重构误差.编码器的输出编码即为抽象化的特征并作为下一层AE的输入.逐层最小化重构误差,确定编码和解码参数,即可以实现SAE的无监督预训练,在最顶层添加一个分类器,运用有标签样本,通过有监督学习可以实现对系统的参数微调.但是对于SAE的层数以及每层神经元的个数一般需要使用者根据自己的经验确定.Yin等[20]提出了一种生理数据驱动的方法确定SAE的结构,并使用SAE获取了各种传统生理信号特征的抽象表示,进而实现维度情感分类.

图8 自编码器的结构Fig.8 Structure of autoencoder
4.3 预测模型
维度情感预测可以是一个分类问题也可以是一个回归问题,当其是一个分类问题时,常用的分类器如支持向量机(Support vector machine,SVM)、K-最近邻分类器、隐马尔科夫模型(Hidden Markov model,HMM)等[9]都可用于完成维度情感分类的任务;当维度情感预测是一个回归问题时,常用的回归模型如支持向量回归(Support vector regression,SVR)、关联向量机 (Relevance vector ma-chine,RVM)等[9]都可用于连续维度情感预测.
情感的产生、发展和消退是一个过程,能够对各个模态的时间动态信息进行建模,对提高维度情感预测的性能是有益的,而RNN(Recurrent neural networks)正具有这样的优点,因此RNN及其变形经常被用于维度情感预测中.RNN的网络结构如图9所示,图9右边是左边网络按时间展开的结果[71].t时刻的输出不仅与t时刻的输入有关,而且还与历史状态有关,因此它能够对时间序列进行建模.但是当t时刻依赖的信息越来越久远时,RNN学习到这些信息会越来越困难,此时RNN的变形LSTM显示了优越性,它对长期信息进行有选择的记忆是一种默认行为,不需要付出很大的代价,因此LSTM更加适合进行维度情感预测,很多文献都使用了此模型(如[67−69]等).LSTM 模型只能使用历史信息,但未来信息对维度情感预测也是有用的,为了将未来信息也用于维度情感预测中,一些文献(如[21,31])使用了BLSTM(Bidirectional LSTM)模型,为了充分发掘特征与标签之间复杂的关系,也有很多文献(如[62,64])使用了由BLSTM堆叠构成的深度BLSTM(Deep BLSTM,DBLSTM)模型.

图9 RNN的网络结构Fig.9 Network structure of RNN
传统RNN以平方误差为代价函数,而维度情感预测的目标是最大化预测标签与实际标签的相关性,同时最小化它们的平均偏差,为了更好地实现这个目的,Weninger等[75]将RNN的代价函数由平方误差更改为CCC,大大提高了连续维度情感预测的性能.Banda等[76]为了发挥RNN能够对较长的上下文依赖性进行建模的优点,并加快收敛速度提高泛化能力,使用了NARX-RNN(Nonlinear AutoRegressive with eXogenous inputs recurrent neural network)模型进行情感预测,也获得了不错的效果.Pei等[66]将深度神经网络(Deep neural network,DNN)与切换卡尔曼滤波器(Switching Kalman filter,SKF)相结合提出了DNN-SKF框架,先对输入特征和情感维度之间复杂的非线性关系用DNN进行建模,然后用分段线性的SKF对情感的时间动态进行建模,进而实现连续维度情感预测.
4.4 信息融合
理论上讲,综合考虑多个模态以及其他信息能够提高情感识别系统的性能,但是一个不恰当的融合方法不仅不能提高识别的性能,可能还会降低识别的性能,文献[77]仅用音频或视频模态进行情感识别,所得平均识别率分别为0.506和0.500,但是运用音视频双模态融合进行情感识别的平均识别率仅为0.47.近些年研究者对信息融合进行了非常广泛的研究,提出了很多融合方法,其中用于维度情感预测的融合方法除了常见的特征层融合、决定层融合和模型层融合方法外,针对维度情感预测的特殊性,很多研究者将各个维度之间的关系用于维度情感预测过程中,这类融合方法称为标签层融合.
特征层融合也称早期融合,概念简单、容易理解和操作,被广泛应用于维度情感预测中[51,78].Eyben等[32]为了将多个模态的行为事件(例如微笑、摇头、叹息等)用于各个情感维度的预测中,使用特征层融合的思想提出了基于串的融合方法,这也可以看作特征层融合的一个变形.为了充分发掘不同模态之间复杂的非线性关系,研究者提出了很多深层的特征融合方法,并将其应用于维度情感预测中,Yin等[20]提出的基于多融合层的SAE集成分类器(Multiple-fusion-layer based ensemble classifier of SAE,MESAE)框架中,多个模态的生理信号特征先经过SAE进行抽象,再通过一个基于连通图的分层融合网络进行融合得到最后的抽象融合特征.特征层融合中,最难处理是不同模态数据的异步性,为了处理这个难题,Chen等[63]在LSTM框架中将具有不同持续时间的特征输入到网络的不同层,短时音频特征输入到第一隐层,长时视频特征输入到第二隐层,最长时间的ECG特征输入到第三隐层.
决定层融合也称后期融合,也是一种操作简单的融合方法,有着广泛应用.在多模态维度情感预测任务中,常用的决定层融合方法有求加权和[60]、求平均[79]、求中值[23]和线性回归[22]等.为了对不同模态的预测结果之间复杂的关系进行建模,近年来一些先进的机器学习技术也被用来进行决定层融合,如Kalman滤波器[67]、极端学习机(Extreme learning machine,ELM)[64]、DLSTM[62]等.但是,决定层融合中默认的各个模态相互独立的假定与实际情形不符,这也限制了最后的预测性能.
模型层的融合是设计一个模型将多个模态的信息以及其他方面的信息相结合来获取最终的情感预测结果.设计同时实现多模态信息融合和维度情感预测的模型技巧性较强、困难较大,文献中的工作也不是太多.Soladi´e等[55]设计了一个模糊推断系统,将视频、音频和上下文相关特征进行融合,并对情感的效价维、唤醒维等四个维度的取值进行预测;Metallinou等[53]提出了一个高斯混合模型(Gaussian mixture model,GMM)融合多个音视频特征,并对情感的唤醒维和支配维进行跟踪;Lin等[54]使用了误差加权半耦合隐马尔科夫模型(Error weighted semi-coupled hidden Markov model,EWSC-HMM)将音视频特征在模型层面进行融合,并实现维度情感分类;Wu等[80]提出了双层半耦合隐马尔科夫模型(Two-level hierarchical alignment-based SC-HMM,2H-SC-HMM),能够对视频和音频两个模态的时间阶段内部以及时间阶段之间的关系进行对齐矫正,在此基础上对音视频信息进行融合并实现维度情感分类.
上面三类融合方法是经典的信息融合方法,在多模态离散情感识别和多模态维度情感预测中都有应用,但是对多模态维度情感预测来说,所能使用的信息除了多模态信息外,还有各个维度之间的关系,将这些信息融入到多模态维度情感预测的过程中对于提高维度情感预测的性能是有益的,这种融合方法称为标签层融合.Nicolaou等[21]基于心理学的研究结果(情感的各个维度之间是有密切联系的)首次将情感的各个维度之间的关系应用于多模态维度情感预测中,提出了一个输出相关(Output-associative,OA)融合框架来利用各个情感维度间的相关性.在此框架中,对每个模态都使用LSTM分别对唤醒维和效价维进行预测,将每个维度在每个模态上的预测结果作为输入再一次使用LSTM 得到每个维度的最终估计,如图10所示[21].此种OA融合框架与决定层融合类似,最大的特点是使用了不同维度的预测结果来进一步得到某一维度最后的预测;此融合框架中共进行了前后两次回归运算,这两次回归运算使用的回归模型并不限于LSTM,可以使用其他的回归模型代替.实际上很多文献也做了这样的工作,例如Nicolle等[56]使用了局部线性回归来融合基于不同模态的各个维度的预测.Nicolaou等[57]使用RVM代替LSTM,提出了OA-RVM回归框架,并将输入特征与初步预测一起输入到一个RVM 中,得到最后的预测.Huang等[61]在使用OA和OA-RVM时将某一个时刻及其之前某一段时间的预测和输入特征连接,输入到下一个回归模型中实现对这一时刻的维度情感预测,以此来对上下文信息进行建模.Nicolaou等[59]为了利用每个情感维度之间以及每个维度与各个模态的特征之间的关系,借助CCA的思想提出了CSR(Correlatedspaces regression)模型,此模型先将所有模态的特征和标签运用CCA映射到变换空间,然后在变换空间中学习特征到标签的映射,在测试集中只需将在变换空间中的估计映回原始标签空间即可.CSR模型使用了各个维度的相关性并且同时实现了特征的有监督降维和多模态融合,也获得了较好的效果.

图10 OA融合框架Fig.10 OA fusion framework
4.5 其他信息的影响和应用
多模态维度情感预测的性能不仅受多个模态的特征提取、预测模型选取以及信息融合的影响,而且受许多其他因素的影响,要获取好的预测性能需要全面考察所有的影响因素.
在对每个情感维度进行实时标注时,人的观察、评估以及反应都需要时间,这造成了标注结果与情感表现之间有一个延时,此延时与标注者、标注的维度、观察的行为都有关系[81].用合适的方法处理这种延时有助于提高维度情感预测的性能.Huang等[61]将标签的前N帧和特征的后N帧去掉实现标签和特征在时间上的对齐,对最后的预测标签采用光滑滤波实现预测标签的延时以与基准标签在时间上对齐.文中根据最后的预测性能寻找最佳延时,获得了很好的预测效果.Nicolle等[56]认为特征与实际维度情感之间具有更强的相关性,于是利用特征与延时标签的相关系数构建了延时概率分布,基于此概率分布进行特征选择,大大增强了预测结果的健壮性.Mariooryad等[81−82]通过最大化情感表现与延时标签的互信息获取最佳延时,并对标签进行平移弥补延时造成的影响,在基于面部和声音特征的维度情感分类中,这种弥补相对于基准获得了超过7%的增益.
5 对比与分析
维度情感预测一般是在自然的数据库上进行的,这是一个比较困难的任务.为了提高情感预测的性能,研究者在特征提取、信息融合、预测模型的设计以及发掘维度情感预测性能的影响因素等方面都做了不懈努力.但是,由于文献使用的数据库、实验方法、分析的时间粒度、性能评价指标、使用的维度以及对每个维度的处理方法等都不尽相同,因此很难进行详尽的对比分析.这里仅对一些具有可比性的结果进行对比分析.表3和表4是在常用数据库上
进行连续维度情感预测和维度情感分类的对比总结,给出的预测性能是相应文献中各个维度预测性能的平均值,其中文献[22,47]中基于视频特征的预测结果是基于纹理特征和几何特征所得预测结果的平均值,文献使用多种方法的,这里只列出获得最好预测性能使用的方法.
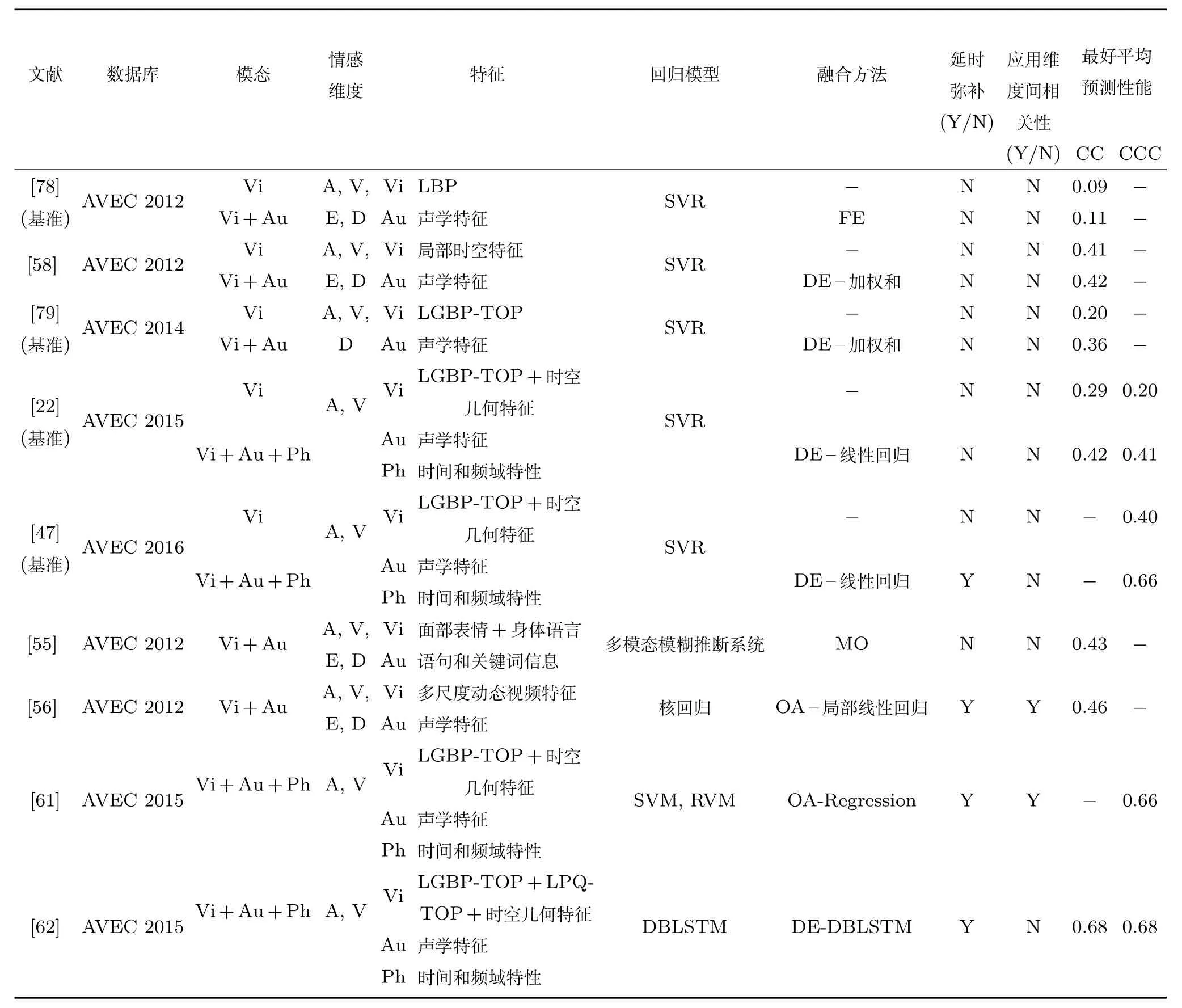
表3 连续维度情感预测对比总结Table 3 Comparison and summary of continuous dimensional emotion prediction

表4 维度情感分类对比总结Table 4 Comparison and summary of dimensional emotion classification
情感的产生、发展和消退是一个动态过程,在特征提取时考虑时间变化,在模型设计时考虑上下文的依赖关系,都被证明对提高维度情感预测的性能是有效的.文献[58,78]基于视频的预测中,在相同条件下使用局部时空特征的预测结果明显比使用静态LBP特征的预测结果好.从2014年开始,AVEC比赛都是以时空特征(包括时空纹理特征和几何特征)为基准视频特征,虽然与AVEC 2012使用的数据库不同,也大概可以看出,与AVEC 2012基于视频特征的基准预测结果相比有了大幅的提高.在选择分类/回归模型时,使用能够对上下文的动态依赖关系建模的模型比使用静态模型的效果要好.文献[31]采用LSTM模型对上下文信息进行建模,使用AVEC 2011大赛组提供的音频特征进行维度情感分类,平均准确率比AVEC 2011的基准平均准确率有了大幅度的提高.
各个模态的信息具有互为补充、互为印证的关系,合理地利用它们来提高各个情感维度的预测性能也是非常有效的.从表3可以看出,多模态维度情感预测系统的性能普遍优于单模态维度情感预测系统.多模态信息融合算法对预测性能的影响是巨大的,文献[55]使用的多模态模糊推断系统的预测结果与AVEC 2012基准双模态预测结果相比具有很大的提升.文献[80]使用的2H-SC-HMM 模型,具有对音视频两个模态的时间阶段内部以及时间阶段之间的关系进行对齐矫正的能力,在SEMAINE库上进行维度情感分类的平均准确率达到了87.5%,相比文献[54]使用的EWSC-HMM模型完成相同任务的平均准确率78.13%有了大幅的提高.
多模态维度情感预测是一项复杂的工程,其性能受到多种因素的影响,好的预测系统往往综合考虑了各个方面的影响因素.文献[56]使用多尺度动态视频特征,考虑了反应延时问题,使用局部线性回归融合从每个模态获得的各个维度的预测结果,获得了目前AVEC 2012数据库上最好的预测性能(平均CC=0.46).文献[61]处理了标注延时的问题,考虑了情感的各个维度的相关性问题,使用基于输出相关融合框架的多模态系统在AVEC 2015数据库上获得了优异的预测性能(平均CCC=0.66).文献[62]利用DBLSTM具有对上下文的依赖性进行建模的优点,将其应用于单模态预测和对每个模态的预测结果进行融合的过程中,而且在进行单模态预测时进行了特征选择,同时处理了标注延时的问题,获得了AVEC 2015数据库上目前最好的预测性能(平均CCC=0.68).
6 总结与展望
多模态维度情感预测涉及了心理学、生理学、社会科学等多个学科,它的发展依赖于多个领域的成果和发现.随着人工智能的发展和人机互动的迫切需要,多模态维度情感预测受到越来越多研究者的关注,近年来取得了很大进展.本文通过对多模态维度情感预测研究现状的认识,思考总结出其面临的挑战及发展趋势如下:
1)各个情感维度的标记是一个十分耗费时间和精力并且需要一定技巧的工作,这限制了维度情感数据集的建立.因此,充分应用有限的现有数据,采用弱监督或半监督学习提升预测的泛化能力是一个亟待解决的问题.
2)多个模态的情感数据一般是通过多种传感器获取的,在获取过程中很难做到记录的同步性,并且不同的模态对情感状态的表现也不是同步的,在进行多模态维度情感预测中如何更好地处理这些异步性是一个挑战性的问题.
3)各个模态蕴含的情感信息互为补充、互为印证,而且受数据的获取条件以及个体的刻意控制等很多因素的影响,会出现一个或多个模态信息的缺失,因此如何更好地建立模型实现多模态信息融合是一个需要研究的问题.
4)情感的维度信息与其他信息(如情感的类别信息、社会行为信息等)都具有密切的关系,在维度情感预测过程中如何充分利用这些信息提高维度情感预测的性能是一个有趣的问题.
5)在现有的多模态维度情感预测中,对于生理信号和语言信息(语音识别出的语言或文本中的语言)的使用十分有限,但是显然这两种信号能够为维度情感预测提供有用的信息.因此如何从这两种信号中挖掘出对维度情感预测有用的信息是值得研究的.
6)随着深度学习技术的发展以及在各个领域的成功应用,多模态维度情感预测领域也不可避免地受到影响,并且目前也有了一些应用.但是如何更好的将深度学习技术应用于维度情感预测的各个环节,深度学习技术在各个环节的应用能否优于传统的机器学习技术,以及运用深度学习技术提升的预测性能相对计算成本的增加是否相匹配等,都是需要充分研究的问题.
7)由于人机互动的实时性需要,提高多模态维度情感预测性能的同时降低计算量,使多模态维度情感预测能够实时地进行具有很大的实际应用意义.
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
昆明医科大学学报(2022年3期)2022-04-19
当代陕西(2022年4期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
当代陕西(2020年22期)2021-01-18
中华诗词(2019年7期)2019-11-25
