
基于多视图矩阵分解的聚类分析
2018-04-23 04:00张祎孔祥维王振帆付海燕李明
自动化学报 2018年12期
张祎 孔祥维 王振帆 付海燕 李明
在计算机视觉和模式识别领域,输入数据的维数过高会增加计算的复杂度,使得对数据的处理变得困难.为了降低数据的维数,通常采用矩阵分解的方法.矩阵分解的方法将数据矩阵分解成多个矩阵的形式,其中一个矩阵可以很好地逼近原始矩阵,在保留原始信息的条件下,同时可以从高维到低维的映射,学习更好的特征描述方法.这样这种矩阵分解的方法有多种,如SVD(Singular value decomposition)、QR 分解、NMF(Nonnegative matrix factorization)等.
NMF可以将原始数据分解为基矩阵和系数矩阵的乘积.基矩阵的作用类似人脸的各个不同局部块的描述,系数矩阵为原始数据在这些基向量的线性组合的权重.对于给定的数据矩阵X,在学习到对应的基矩阵U之后,对应的系数矩阵V便可以描述原始矩阵.最近的研究表明,NMF在人脑识别等领域已经超过基于SVD的方法[1−3].
虽然单视图的NMF提高了原始数据的有效性,但是图像可以从不同的视图进行描述.这些视图可以是不同的数据集,也可以是侧重于不同角度的特征提取方法,所以,这些视图具有多种特征:有的是视觉底层特征、有的是视觉美学特征,甚至有中层语义特征.这些特征往往可以互补地描述图像[4],因此,多视图学习相比较于单视图的方法能更有效地利用视图之间的互补信息.而在实例检索[5]任务上,Multi的思想[6]也被用于获得更加精确的检索效果.目前,利用多视图来进行聚类分析的方法主要有两种:多视图谱聚类和多视图K均值聚类.其中,多视图谱聚类有文献[7−11]等.虽然这些方法性能的相比单视图的谱聚类有所提高,但是多视图谱聚类需要为每一个视图都计算亲和矩阵,视图越多,计算的复杂度也更大.相比之下,多视图K均值聚类不需要计算亲和矩阵,只需要利用原始特征即可.多视图K均值聚类又分为基于指示矩阵的方法和基于NMF矩阵分解的方法.基于指示矩阵的方法有RMKMC[12]和DEKM(Discriminatively emmbedded K-means)[13]等,这种方法是从样本角度来形成聚类质心,且这种方法的准确率依赖于指示矩阵的初始值.而基于NMF矩阵分解的方法是从维数的角度来进行降维,从而形成聚类质心.具体地,关于矩阵分解多视图学习方面的研究有很多:在文献[14]中,Kumar等利用全局和局部2种视图的特征,提高了单视图NMF在人脸识别问题上的准确率;文献[15]利用稀疏编码框架来对多视图特征学习进行研究;文献[16]中,Akata等提出Collective-NMF算法令多种特征数据共享相同的系数矩阵,这等同于先串联各种特征然后进行NMF分解.然而Liu等认为这种共享系数矩阵具有太强的约束,提出一种弱化的约束,旨在保证每种特征的一致性,即视角间的一致性保持[17].
但是,以上这些方法没有考虑相同样本在不同视角中的空间结构关系,这种局部空间结构在半监督学习、流形学习等多个领域的方法中具有重要的意义.典型的计算空间局部结构约束的方法有 Locality preserving projection(LPP)[18]和Spectral Regression[19]等.Cai等在文献[19]的算法中,通过引入局部结构约束达到了大幅度提高实验准确率的效果.
因此,本文提出了一种基于局部结构约束的多视图特征学习方法,称之为MultiGNMF.这种方法的主要目标是相似的数据在每个视图都有相近的相似性.因此,我们通过构建亲和矩阵来将每个视图的空间结构加入到目标函数中,并提出迭代规则来解决这个优化问题.然而,MultiGNMF等多视图学习方法要求特征矩阵的值是非负的,而实际中并不能总是保证这一限制条件.为了消除这一限制条件,本文又提出了一种基于多视图学习的MultiGSemiNMF算法.
文章主要结构分为4个部分:在第1节,简要回顾一下基于矩阵分解的特征学习方法,并将局部结构约束引入多视图学习框架中,提出基于局部结构约束的多视图NMF分解算法—MultiGNMF;在第2节,针对MultiGNMF等多视图学习方法只适用于非负矩阵的缺点,提出MultiGSemiNMF算法,并对其进行详细介绍;第3节对所提的算法进行实验验证和分析;最后,第4节对本文的工作进行总结.
1 基于非负矩阵分解的特征学习方法及其存在问题
在这一节,我们首先介绍基于NMF分解的单视图特征学习方法.然后,考虑到多视图特征比单视图特征能更好地描述图像,且分解后的系数矩阵应与原始特征据的空间结构相似,我们提出了基于局部结构约束的多视图特征学习方法—MultiGNMF.下面将分别介绍NMF和MultiGNMF这两种特征学习算法.
1.1 NMF特征学习方法
下面介绍NMF的求解过程.
定义X=[X.,1,···,X.,N]∈RM×N为输入数据矩阵,每一列都描述的是一个数据,U∈RM×K为基矩阵,V∈RN×K为系数矩阵,即新的描述子,两者的乘积是对原始矩阵的逼近,如式(1)所示,其中K是一个变量,它决定了特征最终学习的特征维数.
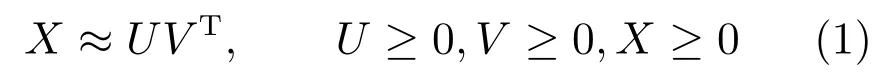
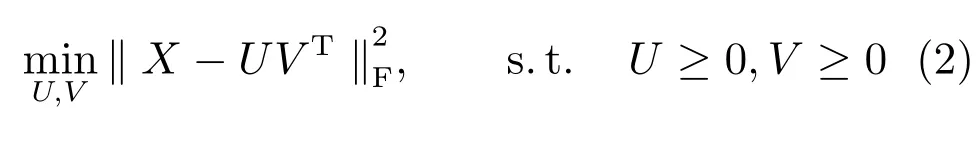
采用KKT(Karush-Kuhn-Tucher)条件,分别引入拉格朗日因子Ψ和Φ将U≥0,V≥0这两个约束条件变成无约束优化问题,如式(3)所示.

对于同时满足U和V的条件下对于式(3)这种无约束优化问题是非凸优化问题,没有精确的求解方法.文献[19]提出了乘子更新法则来迭代求解上述最小化约束问题.迭代过程如式(4)和(5)所示.


1.2 MultiNMF特征学习方法
NMF是基于单视图的特征学习方法,然而,对同一个样本而言,不同视图的多种特征往往可以互补地描述图像.基于此,文献[17]提出了对每种特征保持弱化的一致性约束的多视图学习方法—MultiNMF.现将MultiNMF介绍如下.定义X为G个视图的输入特征数据矩阵,为第f个视图的特征矩阵.其中,Mf为第f个视图的特征维数,N为样本数据的数量.对应地,定义基矩阵U=U1,···,UG和系数矩阵V=V1,···,VG,Uf∈RMf×K,Vf∈RN×K.其中,K为定义的新特征维数.Liu在文献[17]中提出Soft-regularization的方法认为,对每个视图映射后的特征Vf需要保持一致性的约束,但是允许存在差异性,差异的大小采用欧氏空间中的lF范数来度量.于是,可以得到Liu的方法定义的损失函数如下式(6)所示.
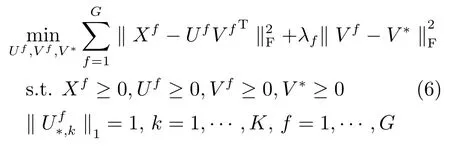
方程的解需要采用乘子更新法则来进行迭代求得,具体过程这里不再赘述.
1.3 MultiGNMF特征学习方法
局部空间结构约束的思想主要是保持样本的局部空间结构不变(近似不变),这种局部空间结构在多个领域的方法中具有重要的意义.而MultiNMF没有考虑相同样本的原始数据与降维之后数据的空间结构关系,因此,本文提出了基于NMF矩阵分解的局部结构正则化约束多视图学习方法,称之为MultiGNMF.下面对MultiGNMF方法进行详细介绍.
1.3.1 局部结构正则化约束
局部空间结构近似不变的具体含义就是:如果两个样本xi和xj在原始空间中相似,那么我们认为它们在映射后的空间中(分别用Vi,.和Vj,.表示)也应该有近似的相似程度,即原始数据与映射后的数据有相似的局部结构关系.
根据以往文献的考察,我们采用数据的亲和矩阵W来表征局部结构关系.计算亲和矩阵的方法很多,在没有监督信息的前提下,一般采用数据之间的欧氏距离构建亲和矩阵W.定义一个正整数变量k,一个样本i与其他样本的权重可以如此计算:对所有样本与该样本的距离进行从小到大的排序,如果样本j在前k个,那么Wij=1;否则,Wij=0.还有其他的方法不采用0/1值作为权值,而是直接用数据之间的核函数值作为权值.典型的核函数有高斯核,线性核等.不同的计算方法适应于不同的研究内容,在文档特征中采用线性核表现更好,在图像视觉特征中高斯核可能更适合.在和其他的方法比较的过程中,我们采用比较通用的高斯核函数值作为权值,从而就可以得到原始数据的亲和矩阵W.但是,这些方法的性能受参数的影响较大.最近,Nie等[20]提出了一种无参数构建亲和矩阵W的方法,该方法不需要任何参数,很好地解决了构图过程需要反复调节参数的问题.但本文提出的MultiGSemiNMF和MultiGNMF算法直接应用无参数构图后缺乏普适性,因此本文仍然使用高斯核函数来构建亲和矩阵,在以后的工作将深入研究无参数构图和本文方法的结合.对于经过映射后的数据Vi,.和Vj,,,仍用欧氏距离来度量它们之间的相似程度,如式(7)所示.利用亲和矩阵W,我们便可以构造用于约束局部结构的平滑惩罚因子.对于第f个视图的平滑惩罚因子Rf,公式如下:

其中,L=D−W为拉普拉斯矩阵,D是一个对角矩阵.
1.3.2 目标方程的构建及求解
将平滑惩罚因子引入多视图特征学习Multi-NMF的框架中,我们得到MultiGNMF方法的目标函数如下:

Liu在文献[17]中建议用对角阵Q归一化U和V,即UVT=UQ−1QVT.其中,Qf定义如下:
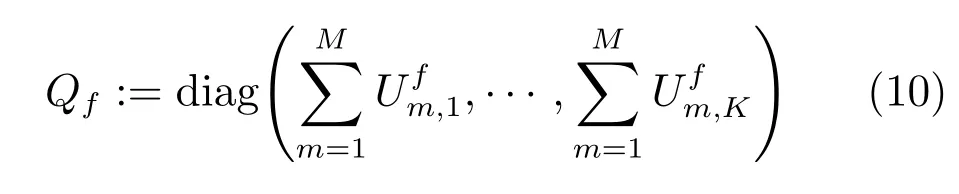
diag(·)表示对角矩阵.这样,经过归一化后,.因此,式(9)可以改写成:

由此,我们可以得到整体的损失函数定义如式(12)所示.
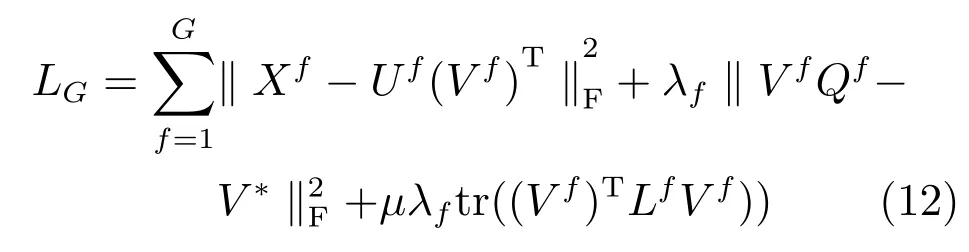
MultiGNMF在Uf≥0,Vf≥0的约束下最小化LG是一个带约束的优化问题.采用迭代的方法求解.引入拉格朗如因子后,MultiGNMF的第f种特征损失函数为式(13).

L1分别对U和V求导,求导结果如下:


根据文献[17],我们在每次迭代得到U和V之后,按照式(10)进行归一化处理,即:

在优化U和V之后,将它们视为常量,对L1求导得到V∗的更新表达式如下所示:

NMF和MultiGNMF都要求U≥0,V≥0,X≥0.这种非负性约束来源于在现实世界中大部分数据是非负的,系数的累加也是非负的.然而,实际情况中,我们提取到的图像特征往往存在负数,这就使得以上两种特征学习方法存在局限性.为了消除这个局限,我们提出一种对负数特征也适用的多视图特征学习方法—ultiGSemiNMF,我们将在下一节对其进行详细介绍.
2 MultiGSemiNMF特征学习方法
在第1节中我们分析了各种基于NMF矩阵分解的特征学习方法的优越表现,不过这些方法有一个重要的约束:所有数据都必须是非负的.在物理世界中可能大部分数据保持这个特性,但是,在图像处理中有些特征,如由小波变换得到的三分法特征、结构特征等,并没有保持非负性的条件,如果强制向正数方向映射,往往含有一定的失真.这就使得基于NMF的特征学习方法有一定的局限性.如何将NMF算法拓展到对负数矩阵也适用,文献[13]中进行了详细探究.其中一种方法是SemiNMF,下面我们对其进行介绍,并由此引出本文所提算法—ultiGSemiNMF.
2.1 SemiNMF特征学习方法
SemiNMF中的数据与NMF中的数据一致,但是,SemiNMF算法对原始数据X和基矩阵U不带有非负性约束,只需系数矩阵V≥0.由此,我们可以得到SemiNMF的目标方程和损失函数分别如式(18)和(19)所示:

SemiNMF在V≥0的约束下最小化Lsemi是一个带约束的优化问题.采用迭代的方法求解,求解过程我们将在第2.2节具体介绍.
2.2 MultiGSemiNMF特征学习方法
SemiNMF这种方法具有很好的描述性,同时相对NMF有较大使用范围和较高性能.于是,为了克服基于NMF的各种特征学习方法只适用于非负数据的缺点,本文提出基于SemiNMF的多视图特征学习算法,我们称之为MultiGSemiNMF.下面将对这种方法做详细的介绍.
2.2.1 目标方程
多视图学习过程中我们需要遵守几个准则:1)每个视图学习的新特征需要保持一致性;2)在学习前的特征和学习后的特征对样本之间的局部结构进行度量,需要保持这种结构的一致性.于是,我们得到弱化的一致性约束项和局部结构正则化约束项tr((Vf)TLfVf).我们将多视图学习的准则应用到SemiNMF,于是,我们可以得到MultiGSemiNMF算法的目标函数如式(20)所示.

其中,Qf的引进是为了使方程满足的约束条件.而的约束条件是为了每一种特征的数据归一化处理,那么对应的系数矩阵也变得归一化,具有比较性.又因为.所以,在U归一化之后如果对X也进行归一化处理,V便也达到归一化的目的.而X为原始数据我们能更好的操作,故在求解过程中只需要在每次迭代U之后对其进行归一化即可.所以,式(20)可以简写成(21),但是我们需要求解前对原始数据X进行归一化操作,在每次迭代后对U进行归一化.

由此,我们可以得到MultiGSemiNMF算法的整体损失函数如下所示:

其中,L=D−W为拉普拉斯矩阵,D是一个对角矩阵,W为样本在原始空间关系的亲和矩阵.各变量的具体含义及计算方法详见第1.3节.
2.2.2 方程求解
MultiGSemiNMF在Vf≥0的约束下最小化LGSemi是一个带约束的优化问题.对于每个视图的特征,引入拉格朗日因子后,MultiGSemiNMF的第f个视图特征的损失函数为

损失函数在变量U和V下不是一个凸优化问题没有精确的数值解,采用迭代优化方法求解,具体计算步骤如下:
1)对V取随机矩阵或者采用K-means算法得到的系数矩阵.
2)固定V更新U.将L2中只有变量U,变成一个无约束优化问题,对其求导,获得U的解析解.其中VTV∈RK×K在一般情况下是一个半正定的矩阵,在不可逆的情况下,用伪逆矩阵来代替(Matlab中的pinv函数).
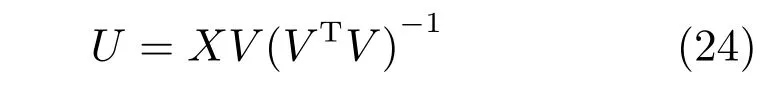
3)固定U更新V.将U固定,L2中只有变量V,对其求导=0,采用KKT条件Φj,kVj,k=0获得式(25)的优化问题.

式(25)是一个典型的定点等式问题,求解f(x)=0,可以变成x=g(x)的形式,迭代式子xi+1=g(xi)由于存在V≥0的约束条件,式(25)中的各项需要保持绝对的非负性.所以,我们采用拆分的方法.通过拆分,XTU=(XTU)+−(XTU)−,UTU=(UTU)+−(UTU)−,其中的拆分函数定义如式(26)所示.这样式(25)便变成多个非负矩阵之间的线性组合.

文献[21]提出一种满足定点等式的x=g(x)形式,将式 (27)所示,代入到式 (25)中(V UTU−XTU+λf(V−V∗+µLV))ikVik0,由于KKT条件约束βikVik=0,当Vik6=0时,必然存在(V UTU−XTU+λf(V−V∗+µLV))ik=0,式(27)满足式(25);反之,当Vik=0也满足.综合考虑,式(27)满足KKT条件.迭代式(27)的收敛性证明方法可以详见文献[21−22].
4)交替迭代第2)步和第3)步,直到损失函数值小于阈值或损失函数值变化小于阈值.
5)在优化U和V之后,将它们视为常量,利用式(17)更新V∗.MultiGSemiNMF与Multi-GNMF的不同之处在于缺少了Uf≥0的约束,因此不仅适用于特征矩阵非负的情况,在特征矩阵中存在负数时,也表现良好.式(28)是各种变量的迭代方程.

3 实验设计与分析
为了验证MultiGNMF算法和MultiGSemiNMF算法的有效性,我们在4个公共的图像数据库中和其他几种多特征学习算法比较图像聚类效果.下面分别从实验设置、评估指标和实验结果及分析这三部分作详细介绍.
3.1 实验设置
3.1.1 数据库
实验中所用的数据库为CMU PIE人脸数据库、UCI手写体数字图像数据库、3-Sources文本数据库和ORL人脸库.表1详细介绍这4个数据库的统计特性.具体介绍如下:
CMU PIE人脸数据库包含41368张32×32像素的人脸图像,这些数据是68个人按照指定的13种姿势角度和43种不同光照条件下采集人脸的图像.在实验中,我们从每个人的一个角度中随机选择42幅图像,构成2856幅人脸图像.如果按照人脸作为聚类中心的话,那么数据可以分成68个集群.在本次实验中,我们用图像的像素值(二维图像按行展开)和HOG(Histogram of oriented gradient)特征作为CMU PIE的两个视图.
UCI手写体数字数据库有UCI大学构建数字0~9的手写体图像,数据库包含2000个样本.我们利用手写体图像的低频傅里叶变换和原始像素值作为不同的视图.
3-Sources文本数据库包含BBC、Reuters和Guardian三种流行的网上新闻资源.其中,有169条新闻被这三个新闻网报道过.我们选取这169条新闻作为测试样本,这三个新闻网分别作为三个视图来进行聚类分析.这些新闻的主题包含商业、娱乐、健康、政治、运动和科技,我们将其作为我们聚类的标签.
ORL(Olivetti research laboratory)人脸库是英国剑桥大学Olivetti研究所制作的人脸数据库,它共包含400张的人脸图像.这些数据是40个人在不同的时间、变化的光线、面部表情(张开/合拢眼睛、微笑/不微笑)和面部细节(戴眼镜/不戴眼镜)下拍摄的.所有的图像为实验者的正脸,带有一定程度的朝上下左右的偏转或倾斜,相似的黑暗同质背景.所有图像的大小均为28×23像素.在本次实验中,我们用图像的像素值(二维图像按行展开)和低频傅里叶变换系数值作为ORL的两个视图.
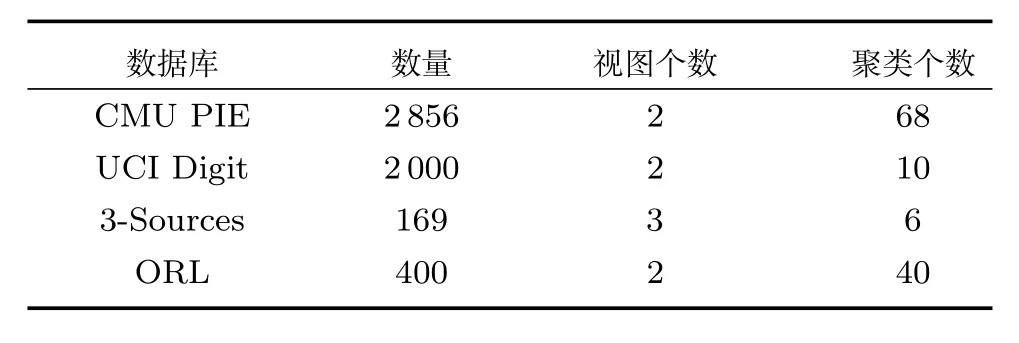
表1 4个数据库的资料Table 1 The information of four databases
3.1.2 对比算法
为了更全面地评估本文提出的算法,我们比较了近期多种典型的多视图学习算法.下面对它们进行描述.
1)单视图算法(BSV和WSV):我们对每个视图利用NMF算法进行特征学习,将学习的系数矩阵作为特征.统计每个视图的效果,我们取每个视图该算法对应的最好效果为BSV和最差效果为WSV.
2)ConcatNMF:这是一种前向融合的学习方法.其算法可以简单理解为,首先将每个视图的特征串联成一个向量(矩阵)作为数据新的特征,然后利用非负矩阵分解算法进行特征学习,所有算法流程和度量标准与单视图的方法一致.
3)ColNMF:一种多视图学习方法,采用一致性准则,如式(29)所示,所有的视图共享相同的系数矩阵.与ConcatNMF类似,不过每个视图添加了权重和归一化约束.min

4)Co-reguSC:一种改进的谱聚类算法,在文献[23]中被Kumar等提出.每个视图采用谱聚类学习作为基本的聚类学习算法,与MultiNMF算法相似的是,在视图之间采用弱一致性准则约束各个视图的映射矩阵之间的关系,如式(30)所示.在实验中我们采用高斯核核函数,该算法的详细介绍可以参考文献[23].
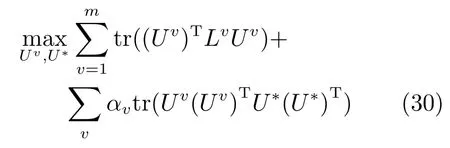
5)MultiNMF:本文算法的基准算法,采用弱一致性约束的多视图NMF学习方法.
6)Sc-ML:是一种改进的Co-reguSC算法.Dong等在文献[24]中提出,利用格拉斯曼流行距离中的一种投影距离来定义不同视图学习的子空间之间一致性准则.
7)MMSC:是一种多模态的谱聚类方法.不同的模态(也就是图像特征)共享一个相同的图拉普拉斯矩阵,也就是最后的聚类指示矩阵G.该算法的详细介绍可以参考文献[10].

8)AMGL:是一种多视图谱聚类方法.但是不同视图所占的权重是自动学得的,不需要有额外的参数来指导训练.该算法的详细介绍可以参考文献[11].
3.2 评估指标
本文采用以往文献中的经典评估方法:AC(精确度)和NMI(归一化互信息)来度量图像数据聚类的评估指标.给定一幅图像,定义为图像的标签类别,为图像对应的聚类中心的类别标签,AC可以用如下式(31)来定义.其中n为所有的测试图像数量,是一个脉冲函数,函数中两个参数相同则返回1,否则返回0.是一种将聚类中心的标签映射到图像集已知的对等标签,其中我们采用Kuhn-Munkres[25]的映射方法.

给定两个数据集的所有聚类中心,它们之间的互信息可以用式(32)计算.
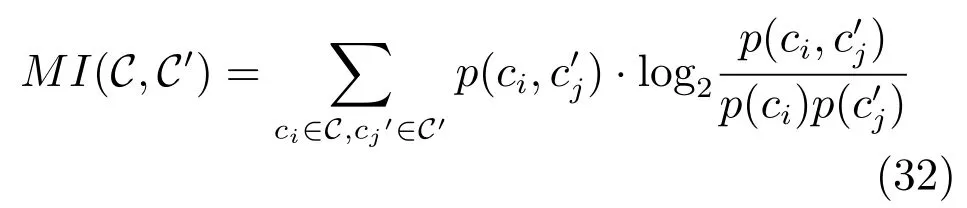
其中,p(ci)和表示在所有测试图像中被分到各自对应聚类中心的概率,在这里我们用数量比率代表概率,表示一个图像被同时分到这两个聚类中心ci和的概率,同样我们用数量比代替概率(注意在这里聚类算法计算得到的聚类中心的编号可以为任意的顺序).在实验中,第一个聚类中心集为图像的已知类别标签,同一个标签的图像为一个聚类中心,第二个聚类中心集为聚类算法得到的标签,标签可以为任意的顺序标签.归一化的互信息为互信息除以最大的聚类标签熵,其中H(C)=−Pip(ci)log2p(ci),p(ci)指属于聚类中心ci的图像数量比率.

3.3 实验结果与分析
3.3.1 聚类的准确性验证
在本文提出的方法需要计算各个数据之间的局部结构关系,我们采用高斯核函数值作为权值,即.变量k=5,这种参数设置在非大量样本数据库中使用的较多.在式(12)中所有的变量我们设定为λf=0.01(f=1,···,G),µ=10,与算法MultiNMF和MultiGNMF保持一致.
在定义了参数之后,计算每个视图图像之间的亲和矩阵,每种方法我们都运行20次,取所有次数运行结果的平均值和方差作为最终的算法效果评估值.经过20次的实验运行,我们统计了各种算法在4个数据库上的AC和NMI值,如表2和表3所示.
在表2和表3中我们可以看到本文提出的算法在聚类分析中相比较其他多视图学习算法在准确度和归一化互信息两个指标下都有较好的表现.同时我们注意到Co-reguSC和SC-ML算法也采用了局部结构约束的条件(谱聚类算法是一种基于数据样本图结构的算法),MMSC也采用了一致性约束,本文算法同样超过该类算法.在比较本文提出的算法MultiGSemiNMF和MultiGNMF算法中,我们发现基于MultiGSemiNMF的算法相对于MultiGNMF算法聚类效果上也有提升,即使所有特征并没有负数或零,这证明在特征学习中MultiGSemiNMF算法比MultiGNMF算法在一些应用场景中具有更好的表现,且MultiGSemiNMF消除了MultiGNMF算法要求所有特征非负的限制,因此也有着更为广阔的应用平台.

表2 不同方法在4个数据库中的AC值Table 2 The AC values by different methods in four databases

表3 不同方法在4个数据库中的NMI值Table 3 The NMI values by different methods in four databases
3.3.2 参数对算法性能的影响
在式(12)中有G个参数变量λf,它的物理意义是不同视图对学习过程的重要性进行权衡.如果我们具有一些先验知识,带有噪声的视图特征可以适当减少权重,被认为重要的视图如文本标签信息等可以适当增加权重.在我们的实验中没有先验知识,同时数据已经归一化处理,所以所有的λf定义为相同的数.但是λf的大小会影响聚类效果,λf越小则对系数矩阵的一致性约束越松弛,反之,λf为无穷大的话所有系数矩阵为相同的数值.
下面我们在两个数据库CMU PIE和UCI Digit上用MultiNMF、MultiGNMF和MultiSemiNMF三个算法做聚类分析,准确率AC作为指标度量不同的λf值对实验的影响.我们设定λf为0.001,0.005,0.002,0.01,0.02,0.05,0.1,图1和图2描述了对应的聚类效果.
从图1和图2中我们可以看到,在Multi-NMF、MultiGNMF和MultiSemiNMF三个算法中,MultiGSemiNMF算法的准确率最高,且受参数影响很小,在较小或者较大的值均能有稳定的表现.MultiGNMF算法最不稳定,但是在大部分实验中仍能超过基准算法MultiNMF.三种算法均在λ=0.01时有较高的表现.
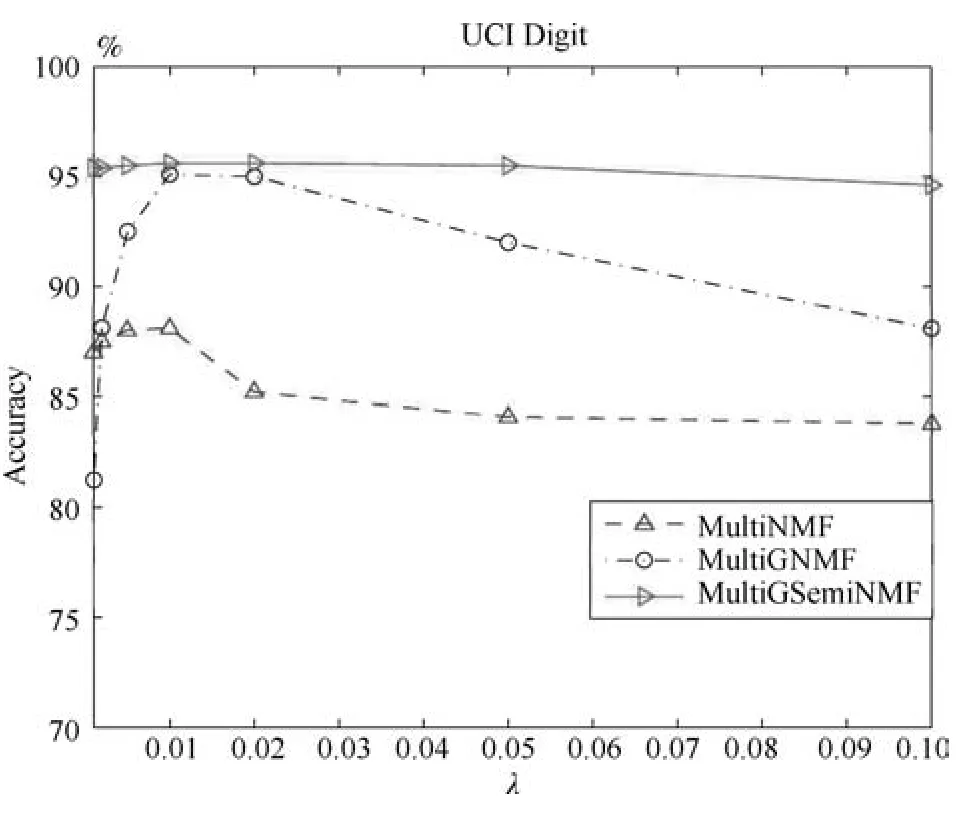
图1 在UCI Digit数据库中参数λ对本文算法的影响Fig.1 The in fluences ofλon UCI Digit database

图2 在CMU PIE数据库中参数λ对本文算法的影响Fig.2 The in fluences ofλon CMU PIE database
本文提出的算法MultiGSemiNMF和Multi-GNMF需要构建一个样本亲和矩阵,在损失函数其中有一个参数k,k值越大样本的局部结构约束越多,反之局部结构约束越少.不同的k值对聚类效果有一定影响,在与其他算法的比较中,我们采用其他算法一样的k值,在这里我们另外分析k值对本文提出算法的影响.在UCI Digit数据总库,我们选取k=5,10,15,20构建亲和矩阵(λ=0.01),用聚类的准确率AC来评估算法效果,如图3所示.
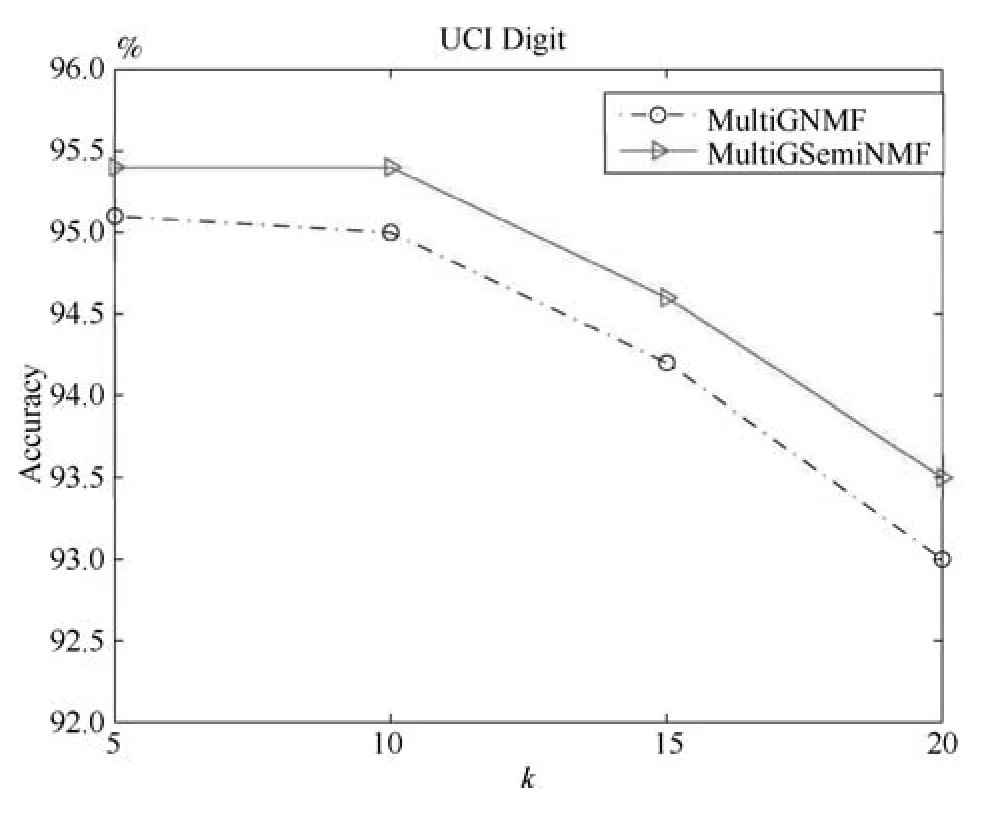
图3 在UCI Digit中参数k对本文提出算法的影响Fig.3 The in fluences ofkon UCI Digit database
从图3我们看到参数k对本文算法有一定的影响,k值越大虽然能更充分地保留样本之间的局部空间结构关系,但是从图中的结果来看聚类准确度随着k的变大有降低的趋势.过度的保留空间结构关系并不能提升算法的效果,反而可能产生过度拟合的副作用,因为样本的结构关系是基于原始特征的距离计算得到,而原始特征并不能充分描述样本信息,其中或多或少含有冗余和噪声.同时,也可以看出,无论参数k取何值时,MultiGSemiNMF算法的性能都优于MultiGNMF算法.
4 总结
本文提出了两种多视图学习的方法:Multi-GNMF算法和MultiGSemiNMF算法.Multi-GNMF和MultiGSemiNMF算法都是基于样本局部结构空间约束的非负矩阵分解多视图学习方法.
本文首先介绍了一种单视图学习方法:NMF矩阵分解.然后,NMF算法的基础之上,在以往多视图学习的框架准则下,本文提出了基于样本局部结构空间约束的非负矩阵分解多视图学习方法MultiGNMF.但是,MultiGNMF方法只适用于非负的特征矩阵.MultiGSemiNMF算法则不限于此.
为了验证本文提出的多视图学习算法的性能,我们在公有的图像数据库中做聚类分析.实验中和以往的算法比较,实验结果表明本文提出的算法相对于其他基于矩阵分解的多视图学习方法有更好的表现.同时实验中分析了算法中的参数变化对算法性能的影响,实验结果表明MultiGSemiNMF对参数变化具有很好的鲁棒性.在未来的工作中,我们将探索一种新的基于局部结构约束的多视图学习方法.
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
雷达学报(2017年6期)2017-03-26
小学阅读指南·低年级版(2017年1期)2017-03-13
电脑知识与技术(2016年13期)2016-06-29
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
人生十六七(2015年6期)2015-02-28
