
时间与位置感知的活动个性化推荐方法
2018-04-19 07:37,
计算机工程 2018年4期
,
(上海理工大学 光电信息与计算机工程学院,上海 200093)
0 概述
目前,智能手机已经普及,其他移动设备也广泛应用。通过这些移动设备,人们的位置信息可以被获取和共享。在获取和得到这些位置信息后,一些有特色的应用就可以被开发出来。如位置导航可以依据当前位置搜索到达目的地的最佳路线、基于位置的搜索可以展示周边的服务设施、如文献[1]基于位置的社交网络能够使大家可以分享自己的位置,并与周围的人建立联系。
这些包含位置信息、时间信息、社交信息、活动信息的数据积累下来后,可以提供增值服务。例如,可以分析用户的活动规律,也可以为用户进行地点选择、活动选择、场所选择提供依据,甚至系统主动针对以上方面提供推荐。
目前,学术界研究较多的是一些位置推荐方法,而对于活动推荐方法的研究并不多,活动推荐是一个有价值的研究课题,如今人们的生活节奏在加快,各种活动也日益的丰富多彩,而怎么样为用户推荐他所感兴趣和喜欢的活动,从而来提高生活质量和品质具有重要意义,与此同时,活动推荐对各大商家也具有重要的商业意义,比如,商业促销活动怎么样来吸引潜在客户,从而来实现商业利益的优化提升等。文献[2]提出了一个基于用户历史活动记录的活动推荐方法,该方法仅仅通过比较目前的活动过记录与过去活动记录序列的相似性来进行活动推荐。文献[3]提出了根据用户的属性信息来进行活动推荐的方法,然而,在现实中,很难获得用户的具体属性信息。这些方法没有能够利用朋友间的相互关系,因而无法对用户没有尝试过的活动进行推荐。在文献[4]中,提出了一个新颖的社会活动推荐系统,该系统能够基于背景声音识别、用户在线交互历史数据计算其偏好及社会关系亲密度为用户进行活动推荐,但是该方法中没有针对时空环境进行推荐。文献[5]提到为群组提供活动推荐,但是它们并不能为某一个单独的用户提供个性化活动推荐。总之,目前还很少综合利用时空信息和用户社交信息为用户提供个性化活动推荐的方法。
为此,本文提出一种时间和位置感知的个性化活动推荐(Time and Location-aware Activity Recommendation,TLAR)方法。
1 相关工作
协同过滤是推荐领域最常用的方法。通常,协同过滤可以分为2种类型:如文献[6-7]邻域模型和矩阵分解模型。基于邻域的协同过滤方法包括基于用户的协同过滤方法和基于物品的协同过滤方法。而矩阵分解模型则是通过矩阵分解建立用户和隐类之间的关系,物品和隐类之间的关系,最终得到用户对物品的偏好关系。协同过滤比较适合于物品和用户的二元关系。
地理位置推荐是一个热门的研究领域。不同学者提出了不同的方法。文献[8]基于内容和协同过滤方法上提出了一种基于模型的方法。文献[9]提出了一种结合用户的签到行为、用户特征及位置兴趣点的语义特征,并将蚁群方法与改进的混合协同过滤方法结合起来进行个性化位置推荐。近年来,引入社交关系进行地理位置推荐逐渐流行。例如,文献[10]提出了一种基于分类层次偏好树来提取个人偏好,同时结合位置社交网络中的用户信任关系来进行位置推荐的方法。文献[11]提出了一种分层模型的位置推荐方法,将地理位置社交网络中的数据分为历史位置层和社交关系层,在历史位置层中,考虑用户的历史签到位置序列具有幂律分布和瞬时效应这2种特性,引入pitman-Yor模型来分析用户的历史位置签到数据,计算出下一次签到位置的概率,结合社交关系,加入社交关系层的朋友数据信息,得出所有可能位置的概率分布,按照TopN方法给出推荐列表。
考虑时间因素进行推荐也引起了研究者的兴趣。例如,文献[12]提出一种融合标签流行度和时间权重的矩阵分解推荐方法,该方法同时考虑用户使用标签的频率与用户兴趣随时间变化的特点,首先根据标签的流行度和时间特征刻画用户对资源的偏好,然后采用梯度下降法对用户-资源矩阵进行分解,最后利用分解后的特征矩阵对目标用户进行预测并推荐。文献[13]提出融合时间特征和协同过滤的兴趣点推荐方法,首先利用基于位置社交网络中大量的签到数据提取用户签到的相似性特征以及时间的差异性,连续性特征,在此基础上利用相似性特征进行用户过滤,然后采用基于连续时间槽的余弦相似度计算用户间的相似度,最后给出时间特征和协同过滤的兴趣点推荐方法。
针对活动推荐,文献[2-3]提出考虑用户的历史活动信息以及用户属性的方法。文献[14]提出一种基于语义和规则的业务活动推荐方法,通过定义面向业务活动的基础本体模型并在此基础上构建了基本推理规则,推荐方法访问知识库并将生成最终的推荐结果呈现给用户。除此以外,文献[4-5]引入社交信息增强推荐效果也被提了出来。上述方法没有综合考虑时间、位置特性以及社交信息的综合作用。
随机游走已经被用于推荐系统中。文献[15]采用概念格从数据中挖掘知识,利用用户特征属性和社交网络图建立概念格,提出了弹性随机游走方法,并在此基础上用概念格知识知道随机游走,提出了融合概念格和随机游走的方法,度量了用户之间的相似性,方法最终根据相似度进行朋友推荐,实验表明方法提高了准确性。于是可以将随机游走方法应用在异构信息网络模型上。
以上的推荐方法各有其特点,但是并没有能够将社交关系、地点、时间、活动等信息加以综合利用,而这正是本文方法的特点。
2 活动异构信息网络模型和随机游走方法
时间和位置感知的活动推荐问题可以描述如下:对于一个用户当知道其地理位置和时间的条件下,需要在其地理位置半径r内,为其推荐感兴趣的活动。
于是结合异构信息网络模型,提出了一种时间位置感知的活动推荐方法。该方法依据签到数据在活动异构信息网络上先获取与该用户相关的子图,然后再在该图上根据边上的权重进行随机游走,最后产生活动推荐。
2.1 活动异构信息网络模型
一个异构信息网络中包含了一组属于T(T>1)个类别的对象,即X={Xt},其中Xt是属于第t种类型的对象集合。信息网络可以表示为加权网络图G=
在异构信息网络中,对象有以下类型:
1)用户。
2)地点。
3)活动。
在该异构信息网络中,关系有以下类型:
1)用户与用户:朋友关系。
2)用户与地点:用户到过某一地点,访问关系。
3)用户与活动:用户参加过某一项活动,参与关系。
4)地点与活动:某一地点中发生了某一活动,发生关系。
值得注意的是,上述关系的表达中,用户与地点、用户与活动、地点与活动的关系是与时间相关的。假设将一天分为若干个时间段,那么,在不同时间段中,该关系是否存在可以依据实际中数据而定。
2.2 时间和位置感知的个人异构信息网络
个人异构信息网络图的构建主要包括子图的构建以及对子图的边进行赋予权重这2个部分。
首先构造好子图。本文介绍的活动异构信息网络图是针对所有人员的。然而,目的是要为某一人员在特定地点、特定时间下推荐活动,因此,需要从整体图上获取相关的子图,以此为依据进行活动推荐。
子图的构建主要考虑:
1)时间因素:仅仅考虑用户在某个时间点访问过的地点、用户在某个时间中执行的活动。
2)地点因素:仅仅考虑用户到过的附近的某个地点。
同时为了考虑社会关系的影响,将其朋友引入,对于朋友的地点、活动也通过时间和地点因素加以筛选。
另一方面,活跃用户常常代表了一种有选择经验的人士,他们的意见具有很大的参考价值,也可以把他们引入,他们的地点、活动也通过时间、地点因素进行筛选。
其次对构建好的子图的所有的边赋予权重,对子图中每一条边依据其在历史数据中出现的相对频率赋予一个权重,定义权重的方法如下:
在构建好的子图中,边的类型可以分为3类,即<用户,用户>,<用户,地点>和<用户,活动>,可以分别用3个集合U,P,A来表示该类型边的集合。对每一个被推荐的用户t,假设与其直接相连的边的边数为n,则|Ut|+|Pt|+|At|=n,设w()为某条边的权重函数。
(1)
对于<用户,用户>类型的边,其权重为:
对于<用户,地点>,<用户,活动>类型的边,其权重将按照该边在训练集中占的频率并根据此频率对其所在的集合进行进一步分配。例如对于<用户,地点>类型的边pti(i=1,2,…,|pt|),其频率为:
那么其权重为:
(2)
根据这两部分方法,构建了如图1所示的用户异构信息网络图。它经过了时间和地点的筛选,并为每条边附上相应的权重,用字母w表示。
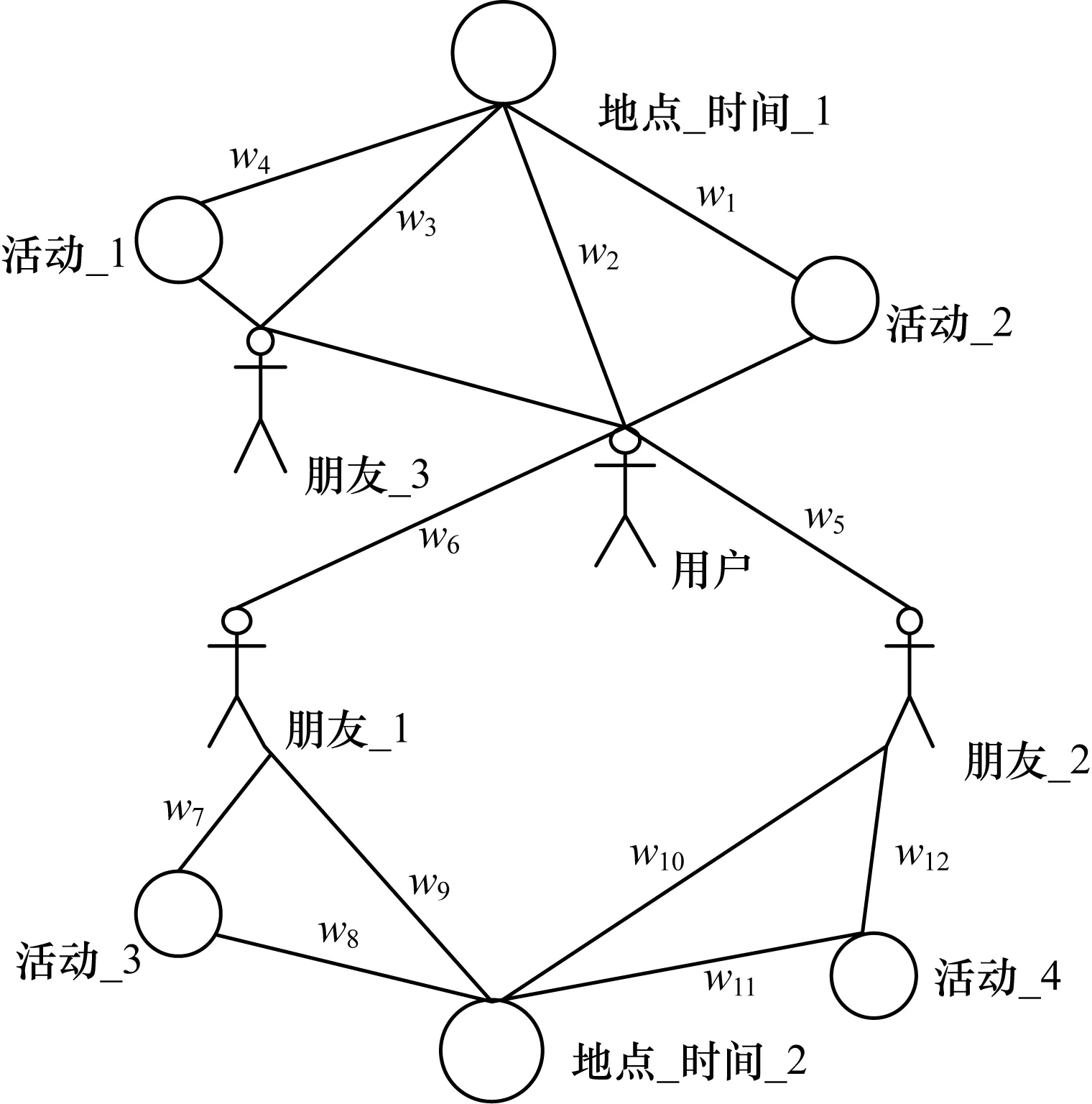
图1 子图模型
方法1子图的构建方法
输入1)uid为用户ID,space为地点,time为时间;2)Locs(uid,space,time)为用户uid在时间time内到达在space内的地点;3)Acts(uid,space,time)为用户uid在时间time内在space内的活动;4)friend(uid);5)ActiveUser(space)为在该space内的活跃用户
输出PG
1.Create new user vertex u for the user with //uid 根据uid//创建用户结点
2.X←X∪{u}//更新结点集合
3.Call function addActandLoc(uid) //构建用户,地点//时间,活动组成的三维模型
4.for each ufof friend(uid) do //循环遍历用户朋友结点
5. uf←new user vertex for uf//创建新的结点
6.X←X∪{uf}//更新结点集合
7. Ef←new edge between u and uf//创建新的边
8. E←E∪{Ef}//更新边的集合
9. CalladdActandLoc(uf.uid) //构建用户连入朋友的//三维模型
10.end for
11.for each uaof ActiveUser(Space) do //循环遍历活跃//用户的结点
12. ua←new user vertex for ua
13. X←X∪{ua}
14. Ea←new edge between u and ua
15. E←E∪{Ea}
16. Call addActandLoc(ua.uid)//构建用户连入活跃//用户的三维模型
17.end for
18.function addActandLoc(uid)//依次迭代构建
19.for all l in Locs(uid,space,time) do //循环遍历已//有模型中的地点结点集合
20. Xl←new location vertex for l
21. X←X∪{Xl}
22.end for
23.for all a in Acts(uid,space,time) do //循环遍历已有//模型中活动结点集合
24.Xa←new activity vertex for a
25. for each l in Xl
26. if ActLoc(a,l,time)=True //如果活动和地点//时间之间没有连接的边
27. El←new edge between a and l //两者之间创建//新的边
28. E←E∪ {El}//更新边集合
29. end for
30.X←X∪{Xa} //更新结点集合
31.end for
32.end function
2.3 基于随机游走的活动推荐
在构造了针对某一用户的图PG
2.3.1 随机游走方法
随机游走是基于物理中“布朗运动”相关的微观粒子的运动形成的一个模型,后来这一模型作为数理金融中的重要的假设,指的是证券价格的时间序列将呈现随机状态,不会表现出某种可观测或统计的确定趋势,即证券价格的变动是不可预测的。在计算机领域,随机游走则主要用来进行一种关系的传递分析,文献[16]经常被用于图的结点相关性排名。在随机游走过程中,从某个特定节点开始,以一定的概率随机选择与该顶点相邻的边向其他结点游走,在每次游走过程中都会记录游走过的结点以便于用于排名,持续这种游走过程,一段时间后将会趋于一个稳定的状态,此时可以输出被记录的结点的访问次数用于排序结点。如果一个图有许多的结点,随机游走的话将会快速的远离开始结点,从而可能导致更多访问的是一些不那么重要的结点。为了避免并解决这个问题,本文采用一种重启的随机游走方法(Random Walk Restart,RWR)在这个方法里每次游走时都会有一个恒定的概率返回到起始节点,于是那些离起始结点比较近的结点将会比那些离起始结点比较远的结点有更多的机会被访问到。RWR的数学表达式为:
pt+1=(1-a)·s·pt+a·q
(3)
其中,pt,pt+1和q是列向量,pt第t步中的顶点概率分布,pit是第t步到达顶点i的概率。列向量q为重启动向量,表示初始状态,qi表示初始状态下在顶点i的概率,列向量中设置用户顶点值为1,其余为0,s是转移概率矩阵,它的元素sij表示顶点i下一步到达顶点j的转移概率。a为直接回到原始顶点的概率。稳定概率分布使用该公式进行计算,直到p收敛。
2.3.2 活动推荐方法
本文利用RWR方法为用户进行个性化活动的推荐。选择用户节点u为出发结点,当u开始游走时,产生一个0~1之间的随机数,当该随机数落在与用户u直接相连的边对应的权重区间,就沿着该边向着下一个结点随机游走,依次类似这样的方法游走,如果到达的结点为某一活动节点时,就为它的计数上面加1,这样依次迭代结束后,可以按照活动的计数次数将活动排序,并将结果输出。
活动推荐方法如下:
方法2基于随机游走的活动推荐方法
输入PG
输出RankedActList
1.for i < iterNum do
2. p←rand(0,1)//随机概率
3. if p 4. curNode←u //停止不走 5. else 6. curNode←SelectNextNodeByWeight (curNode) //依据当前结点产生随机概率落在边的权重区间,来选择游//走的下一个新结点 7. if curNode is activity then //如果游走的结点是活动//结点 8. curNode.visitNumber←curNode.visitNumber+1 //记录下活动结点遍历的次数 9. end if 10.end if//一次游走迭代完成 11. i←i+1; 12.end for //最终迭代次数完成 13.RankedActList←Sort(Activities)//最终活动推荐//列表 上述方法中SelectNextNodeByWeight( )方法表示当前结点依据产生的0~1之间的随机数落在某条边对应的权重区间,通过结点随机产生的概率落在某条边的权重上,就把该边的另一个结点做为要选择的新当前结点。方法的时间复杂度由构建用户子图和随机游走这两部分组成,构造用户子图时间复杂度为线性,所以,时间复杂度主要依赖于为边赋权重以及依据边的权重随机游走的时间,而这部分的时间又取决于迭代的次数即子图的边的个数,综合考虑,方法时间复杂度为O(X2)。在实际上,并不是任意顶点之间都会有边。 在实验中,将比较常见的方法和本文提出的活动推荐方法在实际数据集上进行了对比,并采用统一的指标进行了对比评价。 下面是具有代表性的2种方法: 1)流行活动推荐(Popularity Activity Recom-mendation,PAR)方法:将在预定的半径范围中、相同的时间段内最为流行的活动推荐给用户。 2)基于社会关系的活动推荐(Social Based Activity Recommendation,SAR)方法:将在朋友中、相同的时间段内最为流行的活动推荐给用户。 在实验中,选取这2种方法同本文提出的方法进行了比较。 在真实的Foursquare数据集[17]上评估了本文的方法。选取Foursquare上洛杉矶签到的数据进行实验,该数据有表示用户ID的字段、场所ID字段、经度字段、维度字段、签到时间戳字段,以及活动类别字段等。对于数据集,进行了分析并提取实验所需的字段,并根据时间戳字段的时间先后顺序选取了时间最近的其中10万条数据组成数据集进行实验测试。 表1给出了数据集的组成,其中的数据按年度分布如图2所示。 表1 数据集统计信息 图2 数据集时间分布 根据主题活动的性质,一般都与时间关系密切。比如晚上经常会去酒吧等,为了方便描述推荐活动,将数据集里的时间戳字段分成了4个时间区段:0—6时对应标志1;7—12时对应标志2;13—18时对应标志3;19—24时对应标志4。分别代表着24 h中的凌晨、上午、下午、和晚上4个时间区段。 同时,将数据集中涉及到的活动类型进行了归纳,形成了8种主题活动,如表2所示。各个活动类型包含了更细的子活动,如表3所示。各个活动类型的流行度如表4所示。对于活跃用户的选取,是根据数据集中用户执行活动的频率高低选取频率较高的一部分用户作为活跃用户。 表2 数据集活动类型 表3 数据集主题活动字段下子活动的数目 表4 数据集主题活动的流行度 对实验的评价和指标采用精度和召回率2个评测指标,计算的公式如下: (4) (5) TLAR方法有一些配置参数,比如重启概率取值0.1,根据随机游走的方程迭代收敛后得到。地理位置活动半径取值1 000 m,考虑到如果距离范围过大将失去空间上下环境活动推荐的现实意义,如果距离范围过小,那么构造子图的结点和边数将会有限,影响活动推荐的效果。这里在测试集数据上就针对距离的不同对PAR和TLAR进行实验,距离范围分别为500 m、1 000 m、1 500 m,实验结果表明,PAR在这3个距离范围内,精度和召回率将会随着距离的扩大而减小,TLAR在这3个距离范围内,精度和召回率基本没有什么变化,对比实验结果如图3和图4所示。 图3 PAR和TLAR的精度对比 图4 PAR和TLAR的召回率对比 在对应的这3个不同的距离范围,本文对PRA和TLAR推荐的平均时间也进行了实验对比,如图5所示。 图5 PRA和TLAR的平均时间对比 由分析可知,推荐的时间效率随着距离范围的扩大而减慢,主要是因为距离范围扩大后构造子图的边数明显增多,方法迭代的次数也将明显增加,由此时间效率将会变慢。 对于选取出来的10万条数据集,分别按比例1为9∶1,比例2为8∶2,比例3为7∶3,分为3组对本文的方法TLAR进行实验。推荐活动个数依旧为3个,分别取3组实验的最后平均精度、平均召回率做对比分析,实验结果表明,这3组比例分割得到的结果非常相近,误差在千分位,实验对比结果如图6所示。 图6 3种比例分割下TLAR的实验结果对比 因而,最后实验的配置参数,重启概率为0.1,半径为1 000 m,数据集分割比例为9∶1。 将TLAR方法同流行活动推荐方法(PAR),基于社会关系的活动推荐方法(SAR)进行实验对比,详细的对比实验结果如图7、图8所示。随着推荐个数的增加,TLAR的精度是越来越小,召回率越来越大,但是同PAR、SAR进行对比,无论是精度还是召回率TLAR都具有明显的优势。 图7 3种方法精度对比 图8 3种方法召回率对比 PAR将地理位置距离内最流行的活动推荐给用户,并没有考虑到社交朋友关系,也没有考虑到上下文时间关系;SAR考虑的只是社交朋友关系和上下文时间关系,并没有考虑到地理位置信息关系;而本文的TLAR同时融合了地理位置、时间、社交朋友关系和区域内活跃用户这些上下环境信息来进行随机游走推荐。另外,TLAR的方法时间复杂度为O(X2),因此,本文提出的TLAR考虑因素全面,且推荐效果优势明显。 目前,利用位置信息进行活动推荐的研究并不多,本文提出的TLAR利用用户的社交信息,能够实现时间和空间感知的活动推荐。构造个性化的异构信息网络子图模型,然后进行随机游走产生推荐。实验结果表明,该方法在考虑因素和推荐效果上有着明显的优势。下一步将继续丰富上下文环境,使用本文构造的模型进行朋友推荐等其他方面的推荐。 [1] 于亚新,李玉龙,刘 欣,等.LBSNs 中基于用户活动和社交信任的好友及位置推荐算法[J].小型微型计算机系统,2014,35(10):2262-2266. [2] KUMAR G,JERBI H,GURRIN C,et al.Towards activity recommendation from lifelogs[C]//Proceedings of the 16th International Conference on Information Integration and Web-based Applications & Services.New York,USA:ACM Press, 2014:87-96. [3] CABALLERO A,GARCíA-VALVERDE T,PEREíGUEZ F,et al.Activity recommendation in intelligent campus environments based on the eduroam federation[J].Journal of Ambient Intelligence and Smart Environments,2016,8(1):35-46. [4] 杨 曜,郭 斌,於志文.一种基于背景声音识别的移动社会活动推荐系统[J].计算机科学,2014,41(10):62-66. [5] PURUSHOTHAM S,KUO C C J,SHAHABDEEN J,et al.Collaborative group-activity recommendation in location-based social networks[C]//Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Crowdsourced and Volunteered Geographic Information.New York,USA:ACM Press,2014:8-15. [6] SARWAR B,KARYPIS G,KONSTAN J,et al.Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th International Conference on World Wide Web.Washington D.C.,USA:IEEE Press,2001:285-295. [7] YEHUDA K.Factorization meets the neighborhood:a multifaceted collaborative filtering model[C]//Proceedings of ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2008,426-434. [8] JIANG D,GUO X,GAO Y,et al.Locations recommendation based on check-in data from location-based social network[C]//Proceedings of the 22nd International Conference on Geoinformatics.Washington D.C.,USA:IEEE Press,2014:1-4. [9] 徐雅斌,孙晓晨.位置社交网络的个性化位置推荐[J].北京邮电大学学报,2015,38(5):118-124. [10] 林树宽,柳 帅,陈祖龙,等.基于分类层次偏好树和用户间信任度的位置推荐方法[J].小型微型计算机系统,2015,36(8):1677-1681. [11] 孔晓笛,周健勇.基于分层模型的位置推荐方法研究[J].计算机与数字工程,2015,43(3):468-472. [12] 郭 娣,赵海燕.融合标签流行度和时间权重的矩阵分解推荐算法[J].小型微型计算机系统,2016,37(2):293-297. [13] 宋亚伟,司亚利,刘文远,等.融合时间特征和协同过滤的兴趣点推荐算法[J].小型微型计算机系统,2016,37(6):1153-1158. [14] 张 龙,应 时,贾向阳,等.一种基于语义的业务活动推荐方法[J].计算机科学,2014,41(9):185-189. [15] 李宏涛,何克清,王 健,等.基于概念格和随机游走的社交网朋友推荐算法[J].四川大学学报(工程科学版),2015,47(6):131-138. [16] WANG Y,YOON B J,QIAN X.Co-Segmentation of multiple images through random walk on graphs[C]//Proceedings of 2016 IEEE International Conference on Acoustics,Speech and Signal Processing.Washington D.C.,USA:IEEE Press,2016:1811-1815. [17] NASIROV N,ALBAYRAK S.Modelling user’s location check-ins on location-based social networks[C]//Proceedings of the 23rd Signal Processing and Communications Applications Conference.Washington D.C.,USA:IEEE Press,2015:2246-2249.3 实验与结果分析
3.1 实验数据集

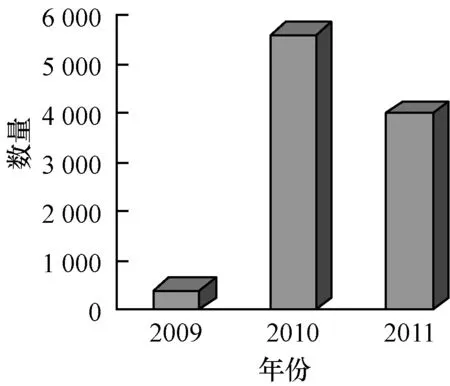



3.2 评价方法和指标
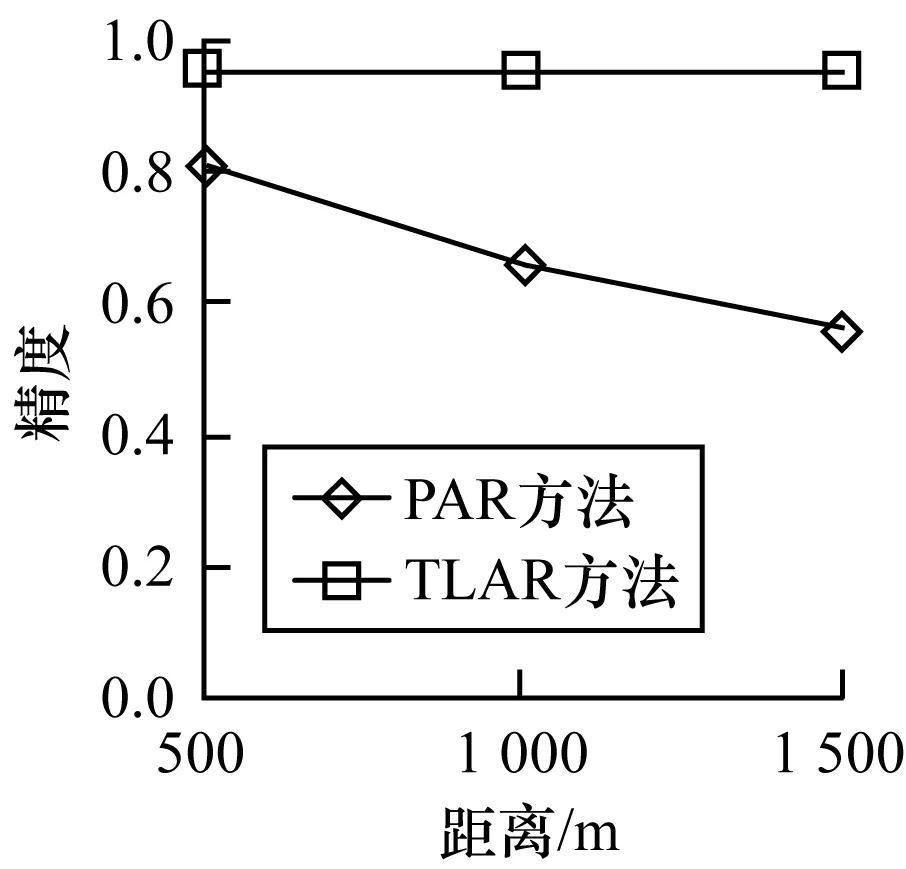


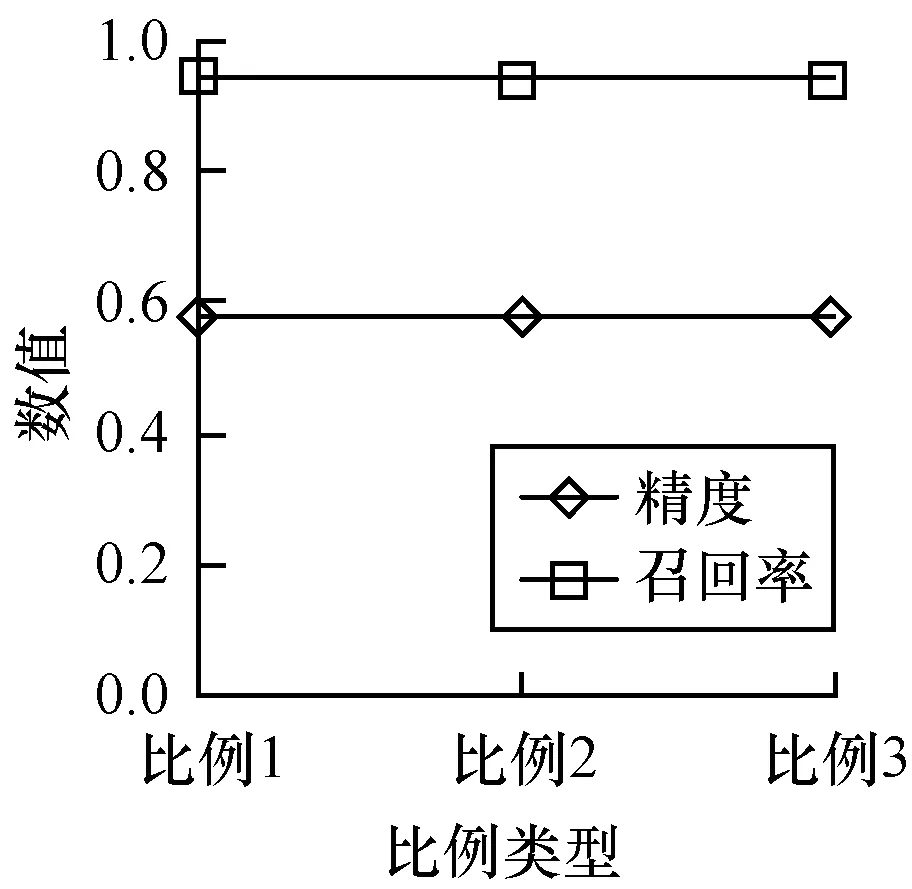
3.3 实验结果


4 结束语
猜你喜欢
意林彩版(2022年2期)2022-05-03
电子制作(2022年1期)2022-01-28
好日子(2021年8期)2021-11-04
电子制作(2021年14期)2021-08-21
第一财经(2020年4期)2020-04-14
同济大学学报(自然科学版)(2019年2期)2019-04-02
计算机与数字工程(2019年3期)2019-03-26
文苑(2018年17期)2018-11-09
西华师范大学学报(自然科学版)(2018年3期)2018-09-26
科技视界(2013年23期)2013-08-22
