
基于CPU/GPU异构资源协同调度的改进H-Storm平台
2018-04-19 07:36
计算机工程 2018年4期
(复旦大学 专用集成电路与系统国家重点实验室,上海 200433)
0 概述
随着互联网产业的不断发展,数据计算的规模日趋庞大,大数据的分析处理技术也愈发凸显其重要性。随着智能化时代的到来,使得包括智能交通和自动驾驶中对道路画面的实时识别和处理、智能家居中对人脸的实时检测等在内的各类物联网和智能化应用都对大数据的实时处理和响应能力提出了很高的要求[1]。另一方面,现有的大数据实时处理框架仅挖掘了集群中的CPU计算能力,而CPU其自身的结构特点和并发程序设计的复杂性限制了其对密集计算型应用提供符合性价比要求的实时响应能力。
实时处理系统的主要指标在于数据处理的吞吐量和延时,降低延时的一个优化措施在于降低系统中各个关键节点的处理时间。目前,图形处理器(Graphic Process Unit,GPU)因其计算和缓存结构上的众核优势,越来越多地被应用在协同计算和加速计算上[2]。GPU加速计算将程序中计算密集部分的工作负载转移到GPU上通过多核并行的方式来加快执行,因此将GPU资源纳入到集群中参与可并行化的、数据密集型的计算,可以大大增强集群的计算能力。特别是对于大规模集群计算中的流式实时系统,系统的延时取决于关键节点的延时,采用GPU资源参与计算可以大幅提升整个系统的性能。
Apache Storm[3]是实时数据处理平台的代表,被广泛应用在各类实时数据分析领域。本文以Apache Storm为基础,设计开发Heterogeneous Storm(以下均称为H-Storm)异构计算平台。通过引入GPU计算资源加快集群中节点的数据处理速度和降低关键节点的处理延时,以提升实时处理系统的吞吐量和计算应用的性能。
1 相关研究
1.1 ApacheStorm介绍
ApacheStorm是一个分布式的大数据流处理应用框架,理论上能够可靠地实时处理无限的数据流。如图1所示,Storm集群中主要分为两类节点:控制节点和计算节点。控制节点(Nimbus)负责管理集群资源和调度、监控用户任务;计算节点(Supervisor)负责运行守护进程和启动任务执行的Worker进程;它们通过Zookeeper进行数据交互。

图1 Apache Storm集群的逻辑结构
在Storm集群中运行的每个作业被表示为一个有向无环的拓扑图,称为一个Topology,如图2所示。其中,每个结点是一个组件,组件有2种类型:Spout组件是数据源,负责生产消息(消息被称为Tuple);Bolt组件封装了数据处理逻辑。每个组件都含有一个或者多个Task,Task是最小的处理单元。消息从一个Task分发到另一个Task,Stream Grouping定义了消息分发策略。Executor线程是执行Task任务的基本物理单元,多个Executor线程封装成Worker进程,每个Topology最终体现为多个节点上多个进程的执行。

图2 Apache Storm作业的拓扑结构
1.2 Storm默认作业调度算法
Storm中的默认调度算法,仅考虑了CPU计算资源。它将CPU核心和可用端口封装为资源槽(WorkerSlot),根据每个Topology中指定的需求来进行分配。调度算法一般分为2个阶段:1)将各个组件的Executor线程分配到Worker进程中;2)将Worker进程分配到集群中计算节点上可用的WorkerSlot中。Apache Storm默认的调度算法采用的是基于轮询式(Round-Robin)的平均分配算法,不考虑任务的结构和节点间的数据通信,即首先将Executor线程按序编号后平均分配到Worker中,然后将所有Supervisor节点上的可用WorkerSlot进行交叉排序,直接依序选取需要的若干个WorkerSlot。默认调度算法这种将Topology中所有Worker平均分配到所有节点上的调度机制,会导致集群中可能的负载不均衡。
1.3 Storm和异构集群的研究现状
目前对Storm平台的研究主要集中在两方面:Storm的任务调度策略和基于Storm的大数据处理应用。Storm的调度策略研究主要是为了提高Storm的吞吐量和优化处理延时,同时保证集群的负载均衡。文献[4]提出了Storm的2种任务调度算法,Offline调度算法根据Topology组件间的偏序关系来进行任务调度,Online调度算法则根据运行时监测到的Executor线程间的通信数据来动态地调度任务。文献[5]提出一种新的基于节点资源利用率的资源感知调度算法,该调度算法调度时会考虑各节点的CPU及内存使用信息和每个Topology的资源需求信息。文献[6]提出了一种基于两层图划分的任务调度算法,综合考虑了数据传输速率和任务间的通信模式。文献[7]提出了基于节点通信数据统计来最小化进程间和节点之间通信的Storm调度算法。
基于Storm的大数据应用更是层出不穷。文献[8]提出了基于Storm的实时交通画面处理。文献[9]使用Storm结合Kafka消息队列来实现基于CCL算法的人脸识别系统。文献[10]使用Storm来开发实时视频的分析平台。
上述研究都基于现有的Storm平台,没有涉及到GPU资源在集群中的管理和调度。文献[11]提出的G-Storm,使用GPU来增强Storm的吞吐量,但只是在单机上实现了GPU的调用和消息的批处理,并没有实现集群中GPU资源的调度。GPU与Hadoop的结合方面也有一些探索。文献[12]提出在Hadoop中调用GPU进行运算的四种方法。文献[13]提出在Hadoop框架中使用GPU来对K-means聚类算法进行加速。但由于Hadoop适用于批处理,且Hadoop与Storm存在差异性,因此无法用在Storm上。
上述对Storm和GPU资源调度的研究和应用,都没有能有效地将具有高度并行化计算能力的多GPU计算资源纳入到大规模的计算集群中。因此,研究和设计一个多GPU的任务和计算资源调度算法,通过统一的管理和调度来进一步增强Storm系统的并行计算和实时处理能力,具有很强的研究和应用价值。
2 H-Storm异构计算集群设计
本文提出和设计开发的H-Storm集群同时包含CPU和GPU资源,对应地,用户Topology也包含CPU作业和GPU作业。因此,作为一个异构的计算集群,会需要一个统一的资源管理和任务调度算法。H-Storm的实现主要分为2个部分:GPU资源的发现与H-Storm异构集群的任务调度策略。
2.1 GPU资源的发现
GPU资源的发现分为GPU资源的量化、上报和调用3个部分。GPU资源的量化用于挖掘GPU的并行任务处理能力,上报用于在H-Storm中管理GPU资源,调用即为在H-Storm中运行GPU程序。
2.1.1 GPU资源量化
大规模的Storm集群中往往存在很多Topology同时运行,每个Topology又由若干进程组成,而集群中的GPU资源有限,因此需要将GPU资源量化以提供给多个进程共享使用。本文采用类似原生Storm中CPU资源槽的概念来量化GPU资源。GPU板卡上的主要资源为计算核心和显存,要划分为资源槽时,必须首先考虑GPU的并行执行能力。
本文主要采用Nvidia公司的GPU板卡。Nvidia公司的GPU产品自Fermi架构起实现了并发核心执行(Concurrent Kernel Execution)能力[14],这个特性被称为Hyper-Q特性。并发核心的执行是通过为不同的Kernel指定不同的Stream来实现的,但是仅限于相同GPU Context的不同Stream才能并发执行,意味着一块GPU板卡同一时刻只能被一个进程占用,无法满足Storm集群的并行计算需求。对此,Nvidia提供了多进程服务 (Multi-process Service,MPS)来解决这个问题[15]。
MPS服务允许来自不同进程的核函数能够并发地在GPU上运行,以提高GPU板卡的计算资源共享和带宽利用率,但是要求GPU的计算能力[16]大于3.5,且要求客户端数目不多于16个。MPS服务通过MPS Server来响应和处理来自多个客户端的GPU执行请求,所有的信息传递接口(Message Passing Interface,MPI)子进程通过MPS Server共用同一个Context,通过并发和分时调度来实行多进程的并发执行。
基于MPS,可以实现Storm中多进程的并发。假设有N个Supervisor节点Si(i=1,2,…,N),每个Supervisor节点有Mi个GPU板卡,定义每个GPU板卡Gij(i=1,2,…,N,j=1,2,…,Mi)上的并发度为Pij,则在分配时对于每个节点Si需要满足下列约束:
Pij≤1,SMarch<3.5
(1)
(2)
因为GPU程序一般需要CPU和GPU的协同计算,即CPU负责拷贝输入输出数据,GPU负责计算,所以在衡量GPU的计算资源时,会为每个GPU资源槽分配一个对应的CPU资源槽,并绑定一个端口用于CPU收发处理数据。假设Supervisor节点Si上可用的资源槽数目为Ai(i=1,2,…,N),已经分配的资源槽数目为Ui(i=1,2,…,N),它们之间存在如下的约束关系:
(3)
因此,在分配GPU Worker到计算节点时,必须满足式(1)~式(3)所示的Supervisor节点上GPU/CPU资源槽数目的约束,实现GPU资源的量化和并发任务处理,其资源槽的数目在集群配置文件中指定。
2.1.2 GPU资源上报
在存在GPU板卡的情况下,GPU资源上报和任务调度流程如图3所示。首先通过配置文件将GPU资源量化为GPU资源槽。Supervisor守护进程通过CUDA API自动将查询到的GPU资源信息通过心跳包存储到Zookeeper中。Nimbus根据读取到的GPU资源信息,按照指定的异构调度算法分配GPU任务到指定Supervisor节点上的指定GPU板卡,并将调度信息写回Zookeeper。Supervisor再根据任务信息,启动相应的GPU Worker,创建指定GPU板卡的Context,执行作业。

图3 H-Storm中GPU资源发现与调度流程
2.1.3 GPU资源调用
CUDA作为C语言的扩展,用于开发GPU程序,本文使用JCuda库利用Java的JNI(Java Native Interface)来实现在Java中对CUDA程序的调用。
在H-Storm中,GPU的调用层次如图4所示。GPU Executor运行在GPU Worker中,是实际执行GPU代码的主体。GPU Executor分为两部分,一部分是对数据进行并行处理的CUDA代码(.cu文件),另一部分是实现Spout/Bolt功能的功能实现代码。功能实现代码通过JCuda调用编译和执行CUDA代码。JCuda通过本地的CUDA Runtime和Driver API来执行GPU代码,最终通过MPS服务调用GPU执行。

图4 Storm中GPU组件执行调用层次
2.2 H-Storm异构集群调度策略
在H-Storm集群中,部分Supervisor节点存在一块或者多块GPU板卡,用户作业可能包含CPU组件和GPU组件。GPU组件对节点GPU资源的依赖性和MPS服务的并行度限制,导致H-Storm集群中的调度策略更加复杂。因此,本文设计了H-Storm异构集群中的任务调度策略,主要包括:综合考虑GPU性能及负载的异构任务调度算法;协同计算时CPU/GPU节点的自适应流分发决策机制。
2.2.1 异构任务调度算法
异构任务调度算法实现将Topology中定义的所有GPU和CPU线程分配到节点资源槽中运行,算法考虑了Topology的结构和当前集群的可用资源信息,其伪代码如算法1所示。
算法1H-Storm的异构任务调度算法
Require:cluster集群信息,topologies作业信息
1. functionschedule(cluster,topologies)
2. needSchedulingTopos←cluster.needsScheduling Topologies (topologies)
3. for each topology in needSchedulingTopos do
4. GPUExecutors←getNeedAssignGpuExecutors(topology)
5. GPUWorkerNum←getNumGpuWorkers (topology)
6. executorToGpuWorker←assignExecutorToGpuWorker(topology,GPUExecutors,GPUWorkerNum)
7. executorToNodeSlot←assignGpuWorkerToNodeSlot(cluster,GPUWorkerNum,executorToGpuWorker)
8. assignGpuExecutors(cluster,executorToNodeSlot)
9. end for
10. assignRemainCPUExecutors(cluster,topologies)
11. return
12. end function
首先从Zookeeper中读取并判断当前所有需要调度的Topology,对于每一个Topology执行调度程序。调度程序在获取当前Topology中所有需要调度的GPU线程以及需要的GPU资源槽数目后,通过assignExecutorToGpuWorker函数将其GPU线程分配到指定数目的GPU Worker中。随后,读取当前所有可用的节点GPU资源槽,通过assignGpu WorkerToNodeSlot将已有的GPU Worker进程分配到Supervisor节点可用的GPU资源槽中。
在完成GPU线程分配后,需要分配CPU线程。如果CPU线程和GPU线程完全被分配到不同的进程,那么进程乃至节点之间的通信会导致系统性能的下降。因此,本文采用了CPU和GPU Worker部分复用的策略,即将部分CPU线程分配到空闲的GPU Worker中,以节省通信开销。
1)线程分配到进程的算法
将GPU线程汇聚到有限的Worker进程中所采用的算法参考了文献[4]中提出的偏序思想。2个组件之间存在连接,代表它们之间有流消息的传递,如果将2个存在连接关系的组件Task分配到同一个进程中,可以减少进程或节点的通信数据。
Topology的本质是一张有向无环图,组件之间存在偏序关系,对组件进行拓扑排序后可以得到其依赖关系。因此,简单的分配策略是,按拓扑顺序遍历组件,依次将组件中的线程采用轮询方式放置到Worker进程中。对于每个组件,如果其输入组件已经分配到Worker进程中,那么优先将其按照轮询方式分配到对应的所有Worker进程列表中。拓扑排序保证了输出组件不会早于输入组件进行分配。相应的伪代码如算法2所示。
算法2H-Storm任务调度算法中线程分配到进程的伪代码
Require:topology作业信息,GPUExecutors待调度GPU线程,GPUWorkerNumGPUWorker数目
1.functionassignExecutorToGpuWorker(topology,GPUExecutors,GPUWorkerNum)
2. componentConnections←topology.getGpuComponents()
3. oderedComponentList←DFSComponent(component Connections)
4. Min←executorCount/GPUWorkerNum
5. Max←(executorCount-GPUWorkerNum + 1)
6. maxExecutorNumPerWorker←(Min +α×(Max-Min))
7. executorToSlotMap<-newMap
8. for each component in orderedComponentList do
9. inputComponents←componentConnections.get(component)
10. assignedInputSlots←getAssignedSlotsForInputComp(input Components)
11. if assignedInputSlots exist and not empty and not full then
12. assign executors to slots in round-robin
13. else
14. assign executors to empty slots or not full slots in round-robin
15. end if
16. end for
17. return executorToSlotMap
18. end function
但是这种策略会导致存在连接关系的线程在一个Worker中的聚集,从而导致分配的Worker数目少于用户初始指定的Worker数目。这种情况可以通过引入调控因子α来解决。假设Executor数目为E,指定的Worker数目为W,在不存在空闲Worker的情况下任意一个Worker中的最大线程数Nmax可以表达为:
Nmax=E-W+1
(4)
同样,在负载平均的情况下任意一个Worker中的最小线程数Nmin可以表达为:
Nmin=「E/W⎤
(5)
因此,引入α后,每个Worker中的最大线程数N为:
N=Nmin+α×(Nmax-Nmin)
(6)
当α取0时,N等于Nmin,所有的线程平均分配到各进程中,意味着重点考虑所有线程在进程中的负载均衡,但忽视了任务间的数据传输,会引起更多的传输开销和延时。当α取1时,N等于Nmax,意味着侧重考虑减少进程间的通信开销,但由于进程中的线程数可能较多,首先会造成频繁的内核线程切换;其次多个线程对相同计算资源的占用会增加等待时间;再者,大量的数据拷贝和发送会导致单个发送线程因繁忙而难以及时响应,也会导致Java虚拟机频繁的垃圾回收,从而降低系统性能。因此,针对不同的系统部署,可以通过α在0~1之间的不同取值来获得对上述2种情况的合理权衡。
2)进程分配到节点GPU的算法
Executor线程分配到固定数目的Worker进程中后,需要将Worker进程分配到Supervisor节点上的GPU资源槽中。已知存在N个Supervisor节点Si(i=1,2,…,N),每个Supervisor节点上的GPU板卡数目为Mi(i=1,2,…,N),第i个Supervisor节点上的第j块GPU板卡记为Gij(i=1,2,…,N,j=1,2,…,Mi) (Mi=0代表该节点上不存在GPU板卡),Aij代表Gij上可容纳的总的并行度,Uij代表Gij上已使用的并行度,则Gij板卡的空闲率可表示为:
(7)
GPU板卡的型号不同,其运算性能也不同,H-Storm中使用每秒10亿次的浮点运算数(Giga Floating-point Operations Per Second,GFlops)来衡量GPU板卡的性能。GFlops可按式(8)计算,即GPU板卡中SM(Streaming Multiprocessor)的数目与每个SM中SP(Streaming Processor)处理单元数目的乘积,再乘以GPU的时钟频率。在衡量性能时,同时会考虑GPU的架构,GPU架构一般使用Major表示,越新的架构Major值越大,计算能力越强。
performanceij=multiProcessorCount×
cudaCoresPerMP×clockRate
(8)
H-Storm集群中可能存在多个不同类型的板卡,需要根据其性能对其计算能力进行归一化。在分配GPU Worker到GPU板卡的过程中,通过引入调控因子β(0≤β≤1) 来实现对GPU的性能和空闲度的综合权衡和计算负载的合理分配。定义一块GPU板卡的综合得分为:
scoreij=β×performanceij+(1-β)×spareij
(9)
其中,β参数的选取依赖于集群中的GPU配置,当集群中所有的GPU型号相同时,显然只需考虑空闲度,此时取β为0;当集群中存在性能差异较大的GPU时,计算应用在繁忙但性能很强的GPU上的运行时间反而可能小于在较空闲但是性能很差的GPU上的运行时间,此时应优先考虑性能,即β取值更接近1。因此,面向不同的集群配置,可以通过选取不同的β值来找到合适的均衡点。
算法依据综合得分对GPU板卡进行排序,在选取需要的GPU Worker时从高到低依次选取可用的资源槽。并且,每次选择后必须更新GPU的空闲率。整个过程的伪代码如算法3所示。
算法3H-Storm调度算法中进程分配到节点的伪代码
Require:cluster集群信息,GPUWorkerNumGPUWorker数目,executorToGpuWorker线程分配结果
1.function assignGpuWorkerToNodeSlot(cluster,GPUWorkerNum,executorToGpuWorker)
2. allGpuInfos ← cluster.getAllGpuInfos()
3. GPUScore ← newMap < uuid,score >
4. for GPUInfo in allGpuInfos do
5. uuid←GPUInfo.getUUID()
6. performance←computeGpuPerformance(GPUInfo)
7. spareRatio←cluster.getGpuSpareRatio(GPUInfo)
8. score←(β*performance + (1-β)*spareRatio)
9. GPUScore.add(uuid,score)
10. end for
11. slotIndexToGpuUUID←newMap
12. while (GPUWorkerNum--) do
13. sortGpuScoreByScore(GPUScore)
14. GPUWorkerNumToUUID←GPUScore.remove(0)
15. updateGpuSpareAndScore(GPUScore)
16. slotIndexToGpuUUID.add(GPUWorkerNumTo UUID)
17. end while
18. executorToNodeSlot←computeAssignment(slotIndex ToGpuUUID,executorToGpuWorker)
19. return executorToNodeSlot
20. end function
2.2.2 自适应流分发决策机制
CPU/GPU的协同计算,意味着同一个任务,既可以在CPU上运行,也可以在GPU上运行。协同计算的目的在于充分挖掘集群中异构资源的计算能力,使得H-Storm总的计算能力等于CPU资源和GPU资源计算能力的叠加。在具体实现上,由于CPU和GPU的差异,需要分别用Java和JCuda来实现相同的功能。由于CPU和GPU计算速度的不一致,协同计算的难点在于任务分配的均衡性,在H- Storm中体现为:对于接收到的每一个数据流,应该做何种决策来将数据分发给下游的异构Bolt进行处理。
决策分流是通过为CPU和GPU声明不同的消息流,并使下游的异构Bolt分别从不同的消息流获取数据来实现的。本文采用固定时间窗口内Spout消息的响应延时来衡量CPU和GPU的计算能力,响应延时同时也决定了系统的吞吐量,是较为准确的衡量吞吐量的指标(不选择吞吐量的原因在于系统的吞吐量在计算能力充足的情况下受限于上游的发送速度,不能用吞吐量来反向调控发送速度,否则性能会受制于起始的分发比例)。假设CPU Bolt和GPU Bolt从相同的数据源Spout互斥地获取数据,每隔时间τ进行一次采样,每隔T时间进行一次决策概率调整,决策概率记为γ,代表占比多少的数据将会发送给GPU Bolt,γ的初始值取为50%(即初始时给CPU和GPU Bolt分发等量的消息流)。T时间内CPU流和GPU流的平均响应延时分别记为avg_lat_cpu和avg_lat_gpu,这样相应窗口内的GPU分发占比(记为δ)可表示为:
(10)
于是,综合考虑当前窗口的消息分发比和历史分发比,决策概率可以调整为:
γ′=γ+θ×(δ-γ)
(11)
其中,θ用于调控决策概率γ的更新速度,θ的取值范围为0~1。θ越大,表明决策概率越侧重于当前窗口的响应延时比,也更容易使γ受到局部窗口内突变的影响。
为将调整后的决策概率动态地写入Zookeeper,本文设计了Spout和Bolt之间的信号通知机制,即组件之间可以通过Zookeeper来发送信号,信号通过Zookeeper节点的监控回调机制来实现。Spout组件在回调时会动态修改决策概率。
Spout中分发到不同消息流的机制采用决策概率γ来调控,通过将γ量化为布尔决策窗来提高决策速度。假设γ=0.8,意味着GPU每处理4条消息,CPU将会处理一条消息,因此设置大小为5的决策窗,5条消息按照4∶1的比例分发。整个自适应流分发决策机制如图5所示。

图5 CPU/GPU自适应流分发决策机制
3 性能测试
本文设计了Topology来测试H-Storm的性能,这些测试Topology中的部分组件具有大量的浮点数运算,采用GPU并行计算对这些组件中的计算任务进行加速,进而将H-Storm中实现的异构任务调度器和Storm中原生的调度器进行性能对比。
3.1 测试环境
本文所设计和实现的H-Storm基于Apache Storm 的1.0.2版本,采用7台服务器搭建一个充分异构的H-Storm集群,服务器均为32 GB内存,节点之间的带宽为100 MB/s。其中一个节点配置为Nimbus节点(记为S0),其他6个为Supervisor节点(记为S1~S6)。S1~S3这3个节点上配置了GPU板卡,另外3个节点上不配置GPU板卡,如表1所示。

表1 集群环境中CPU/GPU配置情况
3.2 参数调优
本文设计了一组测试用例用于调度策略中的α参数和β参数的性能调优(α参数见2.2.1节中1)),β参数见2.2.1节中2)),这些参数的取值很大程度上影响了H-Storm的性能。
α参数调控进程中的最大线程数,影响GPU线程在GPU进程中的聚集。为优化H-Storm集群中的α参数,本文设计了如图6所示的Sequential Topology来测试不同的α参数对吞吐量和延时的影响,中间4个Bolt均为GPU Bolt,执行矩阵加法,Checker Bolt校验计算结果。Sequential Topology共有24个GPU线程,封装到6个Worker中。由式(4)~式(6)可知,α参数过大会导致任务在Supervisor节点上的分配不均衡。考虑负载均衡,本文限制α参数的范围为0.00~0.20,这样每个Worker中的最大线程数目变化范围为4~8。

图6测试用SequentialTopology的结构示意图
图7显示在不同α的情况下吞吐量随时间的变化,可以看到在α为0.00时,系统平均吞吐量较大,此时所有的线程平均分配到各进程中;α为0.20时,系统平均吞吐量最小,此时线程集聚会导致计算资源的繁忙。图8显示在不同α的情况下响应延时随时间的变化(响应延时是指一条消息从Spout发出后到其所有衍生的消息树产生的所有消息都被响应的时间,响应延时包含处理延时),显然α为0.00时可取得最低的延时。

图7 α取不同值时的吞吐量

图8 α取不同值时的响应延时
实验结果表明,在α参数为0.00时,GPU线程平均分配到GPU进程中,此时系统有最佳性能;随着α值增大,有更多互相通信的线程被分配到同一进程中,但性能越来越差,说明在使用GPU进行矩阵运算加速的用例中,线程聚集带来的通信开销的节省远比不上线程聚集导致的计算资源的繁忙。因此,在通信开销远小于计算开销的应用场景中,建议使用平均的分配算法,即取α为0.00;而在计算开销远小于通信开销的情况下,建议增大α的取值来减小通信开销(α不能过大,否则会导致集群负载不均衡和发送数据堆积现象)。由此,本文后续工作取α为0.00。
β参数调控GPU性能和空闲度之间的衡量和选取。实验环境中存在如表2所示的GPU参数。其性能参数和GFlops的衡量值见表2。由式(9)可知,β的取值为0~1,β值越大,表示分配时更侧重考虑性能;β值越小,表示分配时更侧重于考虑空闲度。例如,假设集群中每个GPU上有4个GPU资源槽,Topology需要4个Worker,则首先会优先选择3个GTX 1060上的可用Worker, 对于第4个Worker的选择,当β参数大于0.5时,会使用GTX 1060,反之则使用GTX 970。

表2 本文实验环境中GPU参数
本文使用如图9所示的矩阵乘法运算Topology来测试β参数的取值,其中,MatrixReader Spout从文件中读取矩阵A和B,MatrixDealer负责计算矩阵的乘积,MatrixPrinter负责存储运算结果。为了只验证GPU选取的不同带来的性能影响,本文实验未考虑网络传输消耗。

图9 矩阵乘法Benchmark的Topology结构
图10显示了在Worker数目分别为5和15、矩阵维度分别为64和256的情况下,吞吐量和响应延时随β参数的变化。可以看到,当Worker数目为5时,在β参数为0.1时,可取得最大的吞吐量和较低的响应延时,此时计算任务很少,侧重考虑空闲度可获得最大的吞吐量;当Worker数目为15时,在β参数为0.3时,可取得最大的吞吐量和最低的响应延时,此时仍然优先考虑空闲度。在2种情况下,随着β值的增大,即对GPU性能的衡量权重上升后,系统的性能都越来越差,说明对性能的侧重使得任务过多地被分配到性能较高的GPU上,导致其负载过重,系统性能降低。而本文环境中的GPU性能都比较强,在矩阵计算中并没有很大的速度差异,因此对性能的侧重并不能得到计算时间的大幅缩短,反而导致了MPS服务的繁忙,从而性能降低。因此,综合实验结果,本文环境中取β参数值为0.3。
在H-Storm实现中,α参数和β参数均可以在集群配置文件和Topology配置中根据集群状况和应用场景进行设置。

图10 不同矩阵维度下吞吐量和延时随β的变化
3.3 H-Storm任务调度器性能测试
本文使用如图9所示的矩阵乘法Topology来比较H-Storm异构任务调度器和原生的Storm调度器的性能,两者的差异在于其中的MatrixDealer组件,原生Storm任务使用CPU执行计算,而H-Storm异构任务采用GPU并行加速实现。
首先测试在并行度为1时,不同矩阵维度的CPU和GPU Bolt的处理延时,结果如表3所示。随着矩阵维度的增加,CPU和GPU的差别越来越大,当矩阵为512×512时,GPU的加速比达到74倍,可见,GPU Bolt对于关键计算节点的加速效果较好。

表3 不同矩阵维度下CPU和GPU Bolt的处理延时
随后,分别在不同矩阵维度下测试CPU和GPU Topology的吞吐量和延时。图11显示了Worker数分别为5和12的情况下,CPU和GPU Topology的响应延时,可以看到,随着矩阵维度的增加,CPU的响应延时迅速增加,而GPU的响应延时则增长幅度较小,且远低于CPU,这与表2的结果相符。当Worker数目为5,矩阵为512×512时,系统的响应延时降低了77倍。同时,当Worker数目较多时,CPU和GPU系统的响应延时会增加约20%~40%,原因是内核调度和网络传输会导致开销的增加。

图11 Worker数为5和12时响应延时随矩阵维度的变化
不同矩阵维度下CPU和GPU吞吐量的比较结果如表4所示。当矩阵维度为32×32时,GPU Topology吞吐量只有CPU的一半,因为此时计算开销远低于GPU的调用开销;随着矩阵维度的增加,GPU的处理能力越来越强,因此吞吐量也相对于CPU有了巨大的提升,在256×256时能够达到32倍的加速比。对于1 024×1 024的矩阵,CPU的处理延时达到2 s,因此并行度为5时每秒只能处理2个~3个消息,而GPU则达到每秒133个。同时可以看到,Worker数目为12时的吞吐量相比Worker为5时并没有获得理论值的2.4倍增益,一方面是由于CPU和GPU各自的上下文切换开销,另一方面是由于本文的实验环境中100 Mb/s网速的限制,使得GPU的吞吐量受到了限制。尽管如此,GPU在关键节点的加速还是使得Topology取得了可观的吞吐量增益和响应延时优化。

表4 Worker数为5和12时CPU与GPU的吞吐量比较
3.4 自适应分发决策机制性能测试
在H-Storm设计中,自适应分发决策机制通过决策概率γ来调控CPU/GPU数据流的分发,θ用于调控决策概率γ的更新速度,而γ参数是系统自动调整的,不需要手动调节。
对自适应分发决策机制的测试使用了如图12所示的CPU/GPU混合的矩阵乘法Topology。首先设置初始的γ值为0.5。图13显示了在不同θ取值情况下γ的更新情况,图14显示了不同θ取值情况下的吞吐量。其中θ为0.9时γ进入稳定状态较快,并且能保持稳定,此时平均的吞吐量也是最大。由式(11)知,θ最大意味着更新基本取决于这段时间内的响应延时比,因此实验结果证实了响应延时是吞吐量的决定性因素,而且响应延时基本比较稳定,所以基本通过响应延时比来更新γ参数可以获得更快的稳定速度,因此本文随后的测试中取θ为0.9。

图12 动态协同CPU/GPU混合矩阵乘法Topology结构

图13 θ取不同值时调控参数γ的变化

图14 θ取不同值情况下稳定时的平均吞吐量变化
在θ取值为0.9、矩阵维度分别为32×32和128×128的情况下,分别测试只存在并行度为5的CPU Bolt、只存在并行度为5 的GPU Bolt和CPU/GPU同时存在的3种矩阵乘法Topology的性能,用于验证自适应分发决策机制的性能增益。图15显示了3种结构的Topology的吞吐量的比较,可以看到协同调度的吞吐量几乎是单独的CPU和单独的GPU的吞吐量的总和,CPU和GPU的硬件计算能力都得到了充分的利用,达到了自适应分发决策机制所设计实现的H-Storm协同计算的目标。
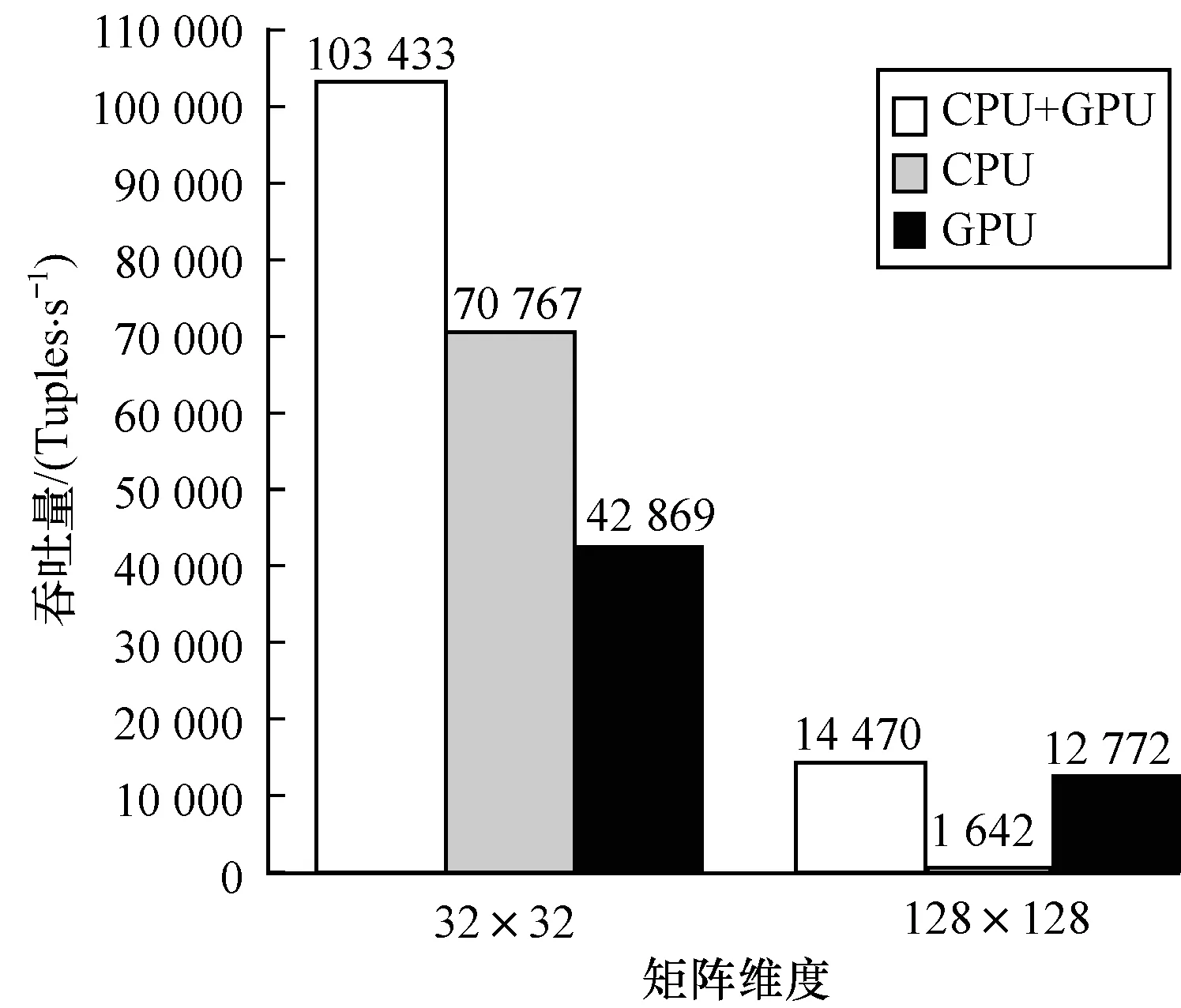
图15 不同矩阵维度下3种Topology的吞吐量比较
4 结束语
本文根据目前大数据密集型计算的复杂性,提出将GPU资源纳入集群中进行关键节点加速和协同计算的技术,并基于Apache Storm实时流处理系统设计H-Storm异构计算平台。首先通过MPS特性实现集群中GPU资源的发现和量化,进而提出H-Storm异构集群的任务调度策略,实现综合考虑GPU性能及负载的任务调度算法和协同计算下自适应的流分发决策机制,最后使用矩阵计算用例进行了参数调优和性能测试。实验结果表明,相对于原生的Storm平台,本文实现的H-Storm平台在512×152矩阵乘法用例下可以达到54.9倍的吞吐量提升和77倍的响应延时下降。H-Storm在实时密集型流计算领域有很大的优势,如何在Storm中动态衡量作业对GPU资源的消耗从而进一步优化调度算法,以及如何在H-Storm平台上运行深度学习将是下一步的研究重点。
[1] 孙大为,张广艳,郑纬民.大数据流式计算:关键技术及系统实例[J].软件学报,2014,25(4):839-862.
[2] 吴恩华,柳有权.基于图形处理器(GPU)的通用计算[J].计算机辅助设计与图形学学报,2004,16(5):601-612.
[3] TOSHNIWAL A,TANEJA S,SHUKLA A,et al.Storm@twitter[C]//Proceedings of 2014 ACM SIGMOD International Conference on Management of Data.New York,USA:ACM Press,2014:147-156.
[4] ANIELLO L,BALDONI R,QUERZONI L.Adaptive online scheduling in Storm[C]//Proceedings of the 7th ACM International Conference on Distributed Event-based Systems.New York,USA:ACM Press,2013:207-218.
[5] PENG B,HOSSEINI M,HONG Z,et al.R-storm:resource-aware scheduling in Storm[C]//Proceedings of the 16th Annual Middleware Conference.New York,USA:ACM Press,2015:149-161.
[6] ESKANDARI L,HUANG Z,EYERS D.P-scheduler:adaptive hierarchical scheduling in apache Storm[C]//Proceedings of Australasian Computer Science Week Multi Conference.New York,USA:ACM Press,2016:26-32.
[7] XU J,CHEN Z,TANG J,et al.T-storm:traffic-aware online scheduling in storm[C]//Proceedings of the 34th IEEE International Conference on Distributed Computing Systems.Washington D.C.,USA:IEEE Press,2014:535-544.
[8] ZHANG W,XU L,LI Z,et al.A deep-intelligence framework for online video processing[J].IEEE Software,2016,33(2):44-51.
[9] RAO L B,ELAYARAJA C.Image analytics on big data in motion-implementation of image analysis CCL in Apache Kafka and Storm[J].WIT Transactions on Engineering and Sciences,2015,3(3):12-16.
[10] 韩 杰,陈耀武.基于Storm平台的实时视频分析系统[J].计算机工程,2015,41(12):26-29,35.
[11] CHEN Z,XU J,TANG J,et al.G-Storm:GPU-enabled high-throughput online data processing in Storm[C]//Proceedings of International Conference on Big Data.Washington D.C.,USA:IEEE Press,2015:307-312.
[12] ZHU J,LI J,HARDESTY E,et al.GPU-in-hadoop:enabling MapReduce across distributed heterogeneous platforms[C]//Proceedings of the 13th IEEE/ACIS International Conference on Computer and Information Science.Washington D.C.,USA:IEEE Press,2014:321-326.
[13] ZHENG H X,WU J M.Accelerate K-means algorithm by using GPU in the hadoop framework[C]//Proceedings of International Conference on Web-Age Information Management.Berlin,Germany:Springer,2014:177-186.
[14] RENNICH S.CUDA C/C++ streams and concurrency[C]//Proceedings of IEEE NVIDIA’11.Washington D.C.,USA:IEEE Press,2011:125-134.
[15] Nvidia Corp.Multi-process service(MPS) overview[EB/OL].[2016-12-02].https://docs.nvidia.com/deploy/mps/index.html.
[16] Nvidia Corp.CUDA toolkit documentation v8.0[EB/OL].[2016-12-02].https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#compute-capability.
猜你喜欢
山西电子技术(2021年3期)2021-06-28
铁道通信信号(2020年8期)2020-02-06
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
电子制作(2017年23期)2017-02-02
火控雷达技术(2016年3期)2016-02-06
集装箱化(2014年2期)2014-03-15
