
基于病情自述和知识图谱的疾病辅助诊断
2018-04-18 11:07:46张利萍芮伟康
计算机应用与软件 2018年2期
张利萍 邢 凯, 周 慧 芮伟康 丁 玲
1(中国科学技术大学苏州研究院 江苏 苏州 215123)2(中国科学技术大学计算机学院 安徽 合肥 230022)3(苏州工业园区疾病防治中心 江苏 苏州 215021)
0 引 言
医疗诊断在大数据驱动下朝着智能化方向发展。人工智能可以通过对医疗数据智能化的推理和表示辅助诊断和治疗。因医疗文本是医疗数据中应用最广泛的一种形式,很多人工智能医疗辅助诊断研究基于医疗文本。如Apixio的iris[1]主要利用医生诊断记录和笔记了解病人情况。IBM Watson[2]主要依据医学文献关联症状和诊断结果。Babylon人工智能健康咨询系统[3]根据用户与在线人工智能系统对话列举的症状给出初步诊断结果。随着人们对健康的关注,国内使用搜索引擎和浏览健康网站了解健康问题的网民分别是69.3%和75.6%[4]。统计“好大夫在线”网络咨询的数据,每天有3万多病情描述产生,一年有近千万的数据。病情自述是患者对自身疾病症状或健康情况的描述,包含了潜在的疾病知识。这样规模的不规范数据仅靠人工来判读效率低、代价高昂。利用机器学习的手段进行疾病知识发现、特征构建和智能辅助判别是未来的趋势。
知识发现实质上是一系列任务,包括内容分析[5],查询与推荐[6],文本分类[7]和文本聚类[8]。虽然典型的LDA[9]主题模型可以用于从海量文本中发现结构化知识,但在短文本上效果不好。在文本知识挖掘中,出现很多研究开始将图论、统计和图模型[10]等结合。其中知识图谱在医疗文本挖掘和辅助推理中受到关注和研究。微软Azure是一款人工智能医疗辅助服务,通过健康搜索数据建立用户搜索意图知识库,将医疗知识库和用户搜索意图知识库结合完成知识图谱构建,让机器理解问题进行语义计算,提供辅助问诊和自动问答。Hyland等[11]使用概率生成模型将无结构化的文本统一到结构化的知识图谱,推理医疗实体间概率关系。Salid等[12]则使用Wiki临床医疗相关页面内容构建有向知识图谱,每个节点是与疾病和医疗状况相关的一些症状,利用知识驱动和深度学习结合的方法提供诊断、治疗等相关的方案。 Shi等[13]提出一种模型对异构医学文本组织融合形成概念图谱,基于语义推理从知识图谱上自动获取知识实现了很好的推理结果。智能诊断需要医疗知识支持和对用户语义的理解,所以对病情自述的挖掘具有研究意义。
病情自述是用户对疾病的描述,体现用户认知的最佳个性化数据。病情自述包含了疾病引起的特征(症状、病因等)和描述疾病时的文本特征。通过同一疾病的病情自述的研究,可以发现该疾病的疾病知识和描述特征。而每个有效的描述都是几个特征以团的形式的组合。频繁出现的特征团可以作为判别疾病类型的知识依据。基于特征团的语义关联,我们提出为各类疾病构建知识图谱。从知识图谱上抽取疾病的结构化特征,使用它对病情自述进行文本表示,并进行病情自述的疾病类型分类。最后实验构建了6种疾病的知识图谱,并对其进行分类识别研究。分类结果微平均和宏平均都在80%,可以用于疾病辅助诊断。知识图谱构建过程是无监督的,适合影评和商品评论等文本的特征结构化分析和用户语义挖掘。基于知识图谱进行的病情自述分类可以用于初步诊断病情自述的疾病,从而服务于疾病知识推荐。
1 特征关联网络
一般的文本语义网络是根据特征共现构建,而同一类型的文本,如病情自述,特征还具有一定的概率关联关系。每种疾病的病情自述包含了其特有的症状和特征。描述疾病时,特征之间存在概率和语义的关联。为了挖掘特征出现的模式,基于同一疾病的病情自述文本,为其构建特征关联网络,具体的过程如下。
1.1 文本预处理
选择同一疾病的病情自述文本集。为了提取疾病相关的所有可能特征关键词,首先对文本数据进行清洗,剔除重复和无效的病情自述文本。然后使用中科院的NLPIR汉语分词系统分词和词性标注。为保证疾病词和症状词能正确分词,导入准备的疾病和症状词典,然后去除停用词和无意义的单字,得到初步的特征关键词集合。在该疾病病情自述文本集合中,计算关键词集中每个词的TF-IDF值。发现大量词TF-IDF高,但是与疾病是没有关系的。根据标注的词性分析,与疾病相关的词性主要有名词n、形容词a/an、动词v以及发现的新词。通过词性过滤词集,对符合词性的词TF-IDF排序,如图1所示,颈椎病病情自述集合中提取的关键词的TF-IDF折线图,其中(“脖子”,0.055 3),(“麻木”,0.046 0)。根据词性过滤后的特征关键词,TF-IDF越高,与疾病特征相关度越大。在这个过程中,我们得到了一个疾病描述时所有相关特征词。这些特征词总结了疾病的相关症状和潜在特征词。

图1 通过词性过滤后的关键词TF-IDF值
1.2 概率关联和语义关联
特征或者症状的出现是疾病辅助诊断的关键信息。对于不同疾病病情自述,特征词不同,特征出现的模式也不同。对于同一疾病的病情自述文本,在得到特征关键词之后,为了挖掘该疾病描述的特征关键词之间的模式,我们从概率关联和语义关联建立疾病特征关联网络。若一个疾病的特征关键词集是W,关键词wi∈W,wj∈W,那么wi出现时wj出现的概率p(wj|wi)如公式所示:
(1)
式中:p(wj|wi)是wi到wj的有向的概率关联度;c(wi,wj)是wi和wj关键词对共现次数,c(wi)是词wi的词频。比如“颈椎”与“麻木”共同出现的短文本数是47,“颈椎”词频为443,“麻木”词频为148。p(颈椎|麻木)=47/148,而p(麻木|颈椎)=47/443。
根据概率中值过滤低概率关联的特征词对。如果特征词对之间相互的有向关联都被过滤掉,那么他们之间的概率关联度不高,去除关联。如果两个关键词总是一起共现,共现次数少,词频都相对低,那么对疾病描述属于弱语义,就是与疾病不相干的词。基于概率关联构建特征关联网络FG=(W,E,K)。图的节点是特征词,W是节点集,E是边集,边代表特征词对存在共现关系且满足概率关联。对于存在概率关联的关键词wi和wj,三元组
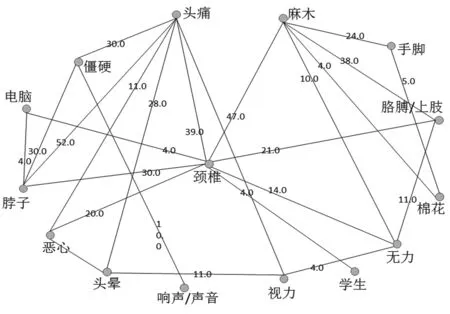
图2 颈椎病病情自述的特征关联网络
2 知识图谱构建和结构化特征抽取
不同疾病类型的病情自述文本对应的特征关联网络是其疾病特征和特征关系的表现。基于特征关联网络,可以发现描述一个疾病时所用特征和特征出现的团模式。每个团可以作为一个疾病判别知识,团之间存在一定的语义关联。基于此为每类病情自述建立可视化的疾病知识图谱。从而利用知识图谱进行知识发现和推理。
2.1 特征词团
图论中,一个clique是无向图G中的完全子图。如果一个clique不被其他clique包含,就称为图G的极大团。顶点最多的极大团是图G的最大团。术语clique来自文献[14],在社交网络中使用完全子图来模拟社交团体,团体内的人彼此认识。在文本数据挖掘方面,我们曾提出使用clique在人物关系的关键词网络[15]中找出核心的人物关系词。这里使用clique找出病人对同一疾病描述时所用特征的团模式。
在特征关联网络中,首先找到频繁特征词团。频繁特征词团是特征关联网络的一个完全子图,团内的特征词共同出现描述病情。每个特征词团呈现了描述疾病时使用的特征词之间的关联性和语义关系。在特征关联网络FG中,使用python提供的network包的find_cliques找出节点数在3以上的极大clique,且clique中所有特征词在文本中共现。这是因为一个有效的疾病描述文本要包含3个以上的特征词。如颈椎病病例自述文本的几个特征词团:3-clique[′颈椎′,′电脑′,′脖子′];4-clique[′棉花′,′无力′,′麻木′,′上肢′];6-clique[′颈椎′,′响声′,′低头′,′转头′,′声音′,′僵硬′]等。特征词团的词常被一起使用来描述疾病的词组,可以作为疾病类型推理判别时的知识。
2.2 知识图谱
特征词团是病情自述文本所使用特征的多样性模式。团之间可能存在多个相同特征词,当两个团之间相同特征词数相对每个特征词团中特征词数占权值较大时,团之间存在语义关系。根据团之间的这种语义建立知识图谱KG=(C,E,W)。每个节点是一个特征词团,C是特征团的集合。每个有向边是两个团之间相对语义关联,有向边集为E。关键词团ci∈C,cj∈C,如果ci与cj相同特征个数不等0,那么三元组
(2)
这种方法建立了特征词团的有向知识图谱。疾病特征团数节点数Size(cliques),过滤入度小于Size(cliques)/10的节点。根据W求中值,过滤小于中值的有向边,当特征词间两条有向边都存在,两条有向边转成一条无向边。最终完成知识图谱构建,如图3,给出了颈椎病的部分知识图谱展示。疾病知识图谱构建过程是无监督的,适用于所有疾病类型的病情自述文本。同时可以用于同类文本,如同一电影影评,同一商品评论的特征结构化。

图3 知识图谱形式
3 非结构化的病情自述文本结构化表示
3.1 结构化特征抽取
通过知识图谱的构建得到了一类疾病常用的特征和描述该疾病时常用特征模式间的关系。分析疾病知识图谱可以发现,特征团因过滤了低语义关联的边在知识图谱上出现了小世界现象,一些特征团通过相同的特征词关联相互连通,而与其他团分离,以一个独立的子图出现。根据连通子图,分解知识图谱合并特征团内的特征,能够完成结构化特征抽取。得到的结构化的特征类似于话题形式,每个结构化特征记作topic,最终抽取的疾病的结构化特征记作topics。从每个疾病的知识图谱上进行结构化特征抽取的算法过程如下:
算法基于知识图谱抽取疾病结构化
Input:疾病知识图谱KG
Begin:
repeat
1)从KG中划分连通子图,节点数在1和30之间,摘除子图g;
2)合并g中所有特征词团的关键词得到话题topic,加入topics;
3)处理DG中因摘除子图出现的孤立节点;
until DG为空
End.
Output:topics
通过知识图谱中连通图的划分和特征团的合并,得到了结构化的特征知识。每个结构化特征内部的所有特征词存在语义的关联维度低,可以用作病情自述文本的表示。
3.2 结构化表示
经典的文本表示法是向量空间模型。因为病情自述的疾病特征太多,特征稀疏,分类效果不好。这里我们提出使用知识图谱得到所有疾病的结构化特征去完成病情自述的结构化表示。计算每个结构化特征与病情自述的Jacarrd相似系数。设病情自述文本d,疾病相关的特征词有m个,d可以表示成d=(w1,w2,…,wm),其中特征词是无序的。计算d与第j个topic的Jaccard相似度J(d,topicj),如式(3):
(3)
式中:J(d,topicj)记作Jj。分子是d和第j个topic共同的特征词数,分母是两者包含的所有特征词。假设有K个结构化特征,病情自述文本表示为d= (J1,J2,…,Jj,…,JK)。
4 病情自述的辅助诊断和评估
病情自述文本辅助诊断是根据病情自述文本包含的特征判断其可能的疾病类型。基于确诊的病情自述训练分类器,能用于对新的样本进行疾病辅助判别。无论对一个疾病的识别,还是多个疾病的识别,实质是文本的分类问题。所研究的类为正样本,其他类为负样本,设TP:正确分类的正样本数;TN:正确分类的负样本数;FP:负样本误分类为正样本数;FN:正样本误分类为负样本数。对该类识别的评估参数有准确度Accuracy、精确度Precision、召回率Recall和F1值四个方面,计算如下:
(a)Accuracy=(TP+TN)/(TP+FP+TN+FN)
(b)Recall=TP/(TP+FN)
(c)Precision=TP/(TP+FP)
(d)F1=(2×Precision×Recall)/(Precision+Recall)
对于二分类的评估,不能单独考虑分类准确率,要基于以上四个标准参数。对多分类结果的评估,单从准确率评估也是不合理的。要从整体的分类正确率和每个类的分类评估进行。引入两个参数:微平均Micro-average和宏平均Macro-average[16]。微平均也就是整个分类的准确率,是正确识别的样本数与整体测试样本数的百分比。宏平均根据每个类的F1求算术平均得到。
5 实验与结果
5.1 实验数据和实验设置
抓取“好大夫”网站中网络咨询服务中已经确诊的6种疾病的病情自述文本:颈椎病1 878例、高血压1 826例、冠心病1 919例、老年性白内障1 320例、新生儿黄疸1 849例、腰椎间盘突出1 936例。每类文本选择1 000例分别构建知识图谱。基于知识图谱抽取结构化特征,每个疾病因为特征和特征模式不同,得到的结构化特征个数也不同,分别是颈椎病7个、高血压9个、冠心病11个、老年性白内障2个、新生儿黄疸11个、腰椎间盘突出9个。如颈椎病的特征形式见表1。6种疾病得到49个结构化特征。将其余病情自述的样本进行成结构化表示,每个结构化特征是一个feature,形成49维的数据,作为疾病判别的实验样本。
实验1,对一个疾病的识别。一类疾病为正样本,其他几类疾病随机抽样为负样本,使用SVM训练分类器。对比实验设置三种,一组使用LDA生成结构化知识,即话题,每个疾病的话题个数设置与我们提取的该疾病的结构化特征数一样,然后使用相同方法结构化表示病情自述,使用SVM分类。另外两组用空间向量模型表示文本,分别使用SVM和KNN分类。
实验2,对多个疾病的分类识别。利用SVM分类6种病情自述文本。

表1 颈椎病病情自述文本的结构化特征
5.2 实验结果
5.2.1实验1结果和分析
对实验样本随机划分训练集和测试集。从训练样本中选择颈椎病为正样本,其他5个疾病抽样的总数与正样本相同,为负样本。采用几种分类方法,分类结果对比见表2。结果表明,基于知识图谱提取的结构化特征表示病情自述进行的分类结果比基于向量空间模型表示的分类结果好。基于LDA提取的话题表示病情自述文本的分类结果最差。说明提出的无监督知识图谱得到的结构化特征表示病情自述在疾病识别任务中具有优势。为了保证实验的鲁棒性,进行了多个疾病的多次相同实验,我们的方法其实验结果稳定,每个疾病识别率都在80%以上。

表2 不同分类方法比较 %
5.2.2实验2结果和分析
实验样本随机2:1划分训练样本和测试样本,使用训练样本,训练SVM多分类器。首先使用libsvm库提供的方法得到cost和gamma最优参数设置cost=100,gamma=0.01。然后对6种病情自述文本的测试样本分类,结果如表3,预测类型对应行,行和是预测为该类的样本数。实际类型对应列,列和是该类实际测试样本数。
根据表3,计算多分类的微平均和宏平均对分类进行评估。整个的分类正确率,即微平均值是83.4%。对每个类计算其召回率Recall,精确度Precision和F1,结果见表4。对所有类的F1求算术均值得到多分类的宏平均值84%。多次实验结果稳定。
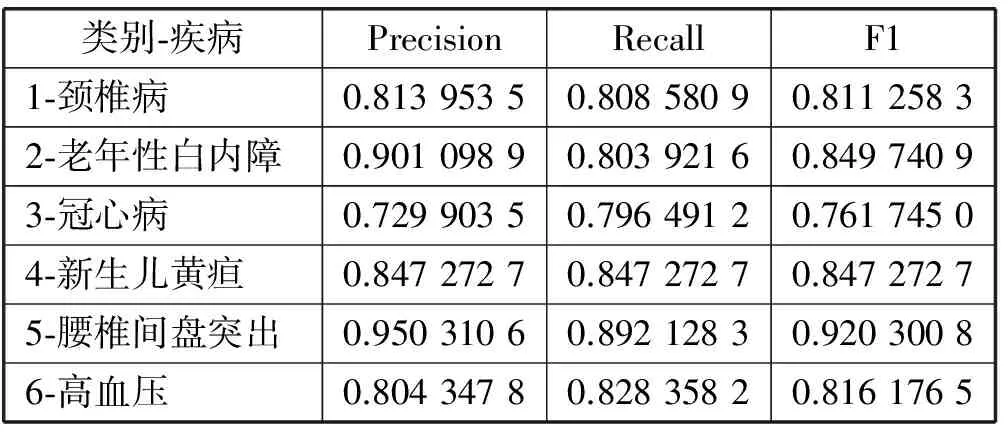
表4 6种疾病判别结果评估
对分类后的样本进行人工审核,经过专业分析,整体分类结果可以或能被接受应用于病情自述文本疾病类型的辅助诊断。根据进一步分析发现,一类误诊样本中,多被判为四类,四类误诊样本中多被判成一类,而两种疾病,颈椎病和腰椎间盘突出具有医疗联系。同样,在三类和六类中也有这种现象,而冠心病和高血压医疗中属于一种常见的并发性疾病。对于整体的疾病分类率来说,识别效果可以用于辅助诊断,而且在这样的研究中,可以发现疾病和疾病间的关系。因此根据病人病情描述状况,可以提供病人可能相关的疾病诊断信息,进行个性化疾病知识推荐。
6 结 语
随着人们对健康的关注,很多网民会通过网络咨询疾病问题,产生了海量的病情描述文本。针对病情自述文本的多样性,本文提出了基于一种为确诊同一疾病的病情自述文本创建疾病知识图谱的方法,该过程是无监督的。知识图谱是根据病情描述时的特征团模式进行的知识关联,能够表现疾病的特征和描述疾病的常用模式关系。然后,基于知识图谱提取结构化特征完成病情自述文本结构化文本表示。实验疾病判别的结果取得了预期的效果。基于知识图谱完成的结构化表示,是一种新的结构化知识提取方法,不仅可以用于病情自述结构化知识提取,也可用于同类或同样电影的影评、同类或同一商品的评论的特征分析和结构化特征抽取。从疾病判别多分类结果看,整体的准确率和识别率符合疾病诊断特点,可用于识别病情自述文本,进行初步诊断。本文是对病情自述的智能诊断研究,其中知识图谱构建和结构化特征抽取的方法具有一般性,适合同类文本的知识挖掘研究。
[1] Hodson H.Google knows your ills[J].New Scientist,2016,230(3072):22-23.
[2] Neti C,Ebadollahi S,Kohn M,et al.IBM Watson+Data analytics:a big data analytics approach for a learning healthcare system[Z].Newsletter,2016.
[3] Middleton K,Butt M,Hammerla N,et al.Sorting out symptoms: design and evaluation of the Babylon check’automated triage system[J].arXiv preprint arXiv:1606.02041,2016.
[4] 苏春艳.当“患者”成为“行动者”:新媒体时代的医患互动研究[J].国际新闻界,2015,37(11):48-63.
[5] Jiang D,Leung K W T,Ng W.Fast topic discovery from web search streams[C]//Proceedings of the 23rd international conference on World wide web.ACM,2014:949-960.
[6] Zhou T C,Lyu M R T,King I,et al.Learning to suggest questions in social media[J].Knowledge and Information Systems,2015,43(2):389-416.
[7] Chen M,Shen D,Shen D.Short text classification improved by learning multi-granularity topics[C]//International Joint Conference on Artificial Intelligence.AAAI Press,2011:1776-1781.
[8] Jin O,Liu N N,Zhao K,et al.Transferring topical knowledge from auxiliary long texts for short text clustering[C]//Proceedings of the 20th ACM international conference on Information and knowledge management.ACM,2011:775-784.
[9] Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of machine Learning research,2003,3(1):993-1022.
[10] Lu Y,Zhai C.Opinion integration through semi-supervised topic modeling[C]//Proceedings of the 17th international conference on World Wide Web.ACM,2008:121-130.
[11] Hyland S L,Karaletsos T,R?tsch G.Knowledge Transfer with Medical Language Embeddings[J].arXiv preprint arXiv:1602.03551,2016.
[12] Hasan S A,Zhao S,Datla V,et al.Clinical question answering using key-value memory networks and knowledge graph[Z].TREC,2016.
[13] Shi L,Li S,Yang X,et al.Semantic Health Knowledge Graph:Semantic Integration of Heterogeneous Medical Knowledge and Services[Z].BioMed Research International,2017.
[14] Luce R D,Perry A D.A method of matrix analysis of group structure[J].Psychometrika,1949,14(2):95-116.
[15] 刘锦文,邢凯,芮伟康,等.基于信息关联拓扑的互联网社交关系挖掘[J].计算机应用,2016,36(7):1875-1880.
[16] Calvo R A,Lee J M.Coping with the news:the machine learning way[C]//Proceedings of Ausweb 2003 Conference,Gold Coast.2003.
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19 13:34:44
少先队活动(2020年12期)2021-01-14 01:47:40
计算机教育(2020年5期)2020-07-24 08:53:00
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
中成药(2017年3期)2017-05-17 06:09:01
领导科学论坛(2016年9期)2016-06-05 14:59:58
计算机工程(2015年8期)2015-07-03 12:20:35
中文信息学报(2015年4期)2015-04-21 08:29:12
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
