
基于情感词典的藏语文本句子情感分类
2018-04-16 07:53闫晓东
中文信息学报 2018年2期
闫晓东 黄 涛
(1.中央民族大学 信息工程学院,北京 100081;2.国家语言资源监测与研究少数民族语言中心,北京 100081)
0 引言
随着 Web 2.0 的蓬勃发展,用户参与网站内容的制造,互联网上产生了大量的用户参与的、对于诸如人物、事件、产品等有价值的评论信息。潜在的用户就可以通过分析这些信息,挖掘人们对某一事物的观点和看法,从而进行有效的商业决策、政治决策等。处理如此海量的数据,采用人工的方式是难以胜任的,如何借助计算机帮助用户快速地对这些网络文本进行自动分析处理,提取出有用的情感信息已成为当下许多研究人员的研究重点。文本情感分析就是对带有情感色彩的词语、句子以及文本进行分析、处理、归纳和处置的过程[1]。目前,对中英文文本情感分类方面的研究相对成熟。但是,藏语文本的情感倾向性分析的研究相对滞后。而随着藏文网页和藏文数字图书馆等网络信息的内容日渐丰富,越来越多的藏族同胞在网上用藏文表达自己的观点和看法,藏语文本的情感性分析已成为迫在眉睫的研究课题。在句子情感倾向分析的基础上,可以很方便地进行篇章的情感倾向分析,甚至可以得到海量信息的整体倾向性态势,因此,句子级别的情感分类具有重要的研究价值,也是本文的研究重点。
1 相关工作
情感分类是自然语言处理方向的热点之一,国内外已经有很多关于文本情感分类的研究。总的来说,可以分为基于机器学习的方法和基于情感词典的方法。机器学习方法的基本思想是根据已知训练样本求取对系统输入输出之间依赖关系的估计,使它能够对未知输出作出尽可能准确的预测。2002年,Pang等人[2]使用常用的机器学习技术进行倾向性判断,比较支持向量机(SVM)、朴素贝叶斯(NB)、最大熵三种方法的倾向性判断效果,实验表明SVM的分类效果最好。文献[3]针对新闻文本的分类进行研究,分别利用朴素贝叶斯方法和最大熵方法将新闻文本分为正面情感类和负面情感类,并采用词频和二值作为特征项权重,最终取得了较好的分类效果,最高分类准确率达到90% 以上。基于情感词典或知识系统的方法,利用已有的语义词典,通过判定句子中包含情感词的语义倾向,加上句法结构等信息,间接得到句子的情感倾向[4]。Riloff和Shepherd[5-8]提出了一种基于语料的方法,通过构建情感词典来实现情感分类。之后Riloff和Wiebe[9-11]运用 Bootstrapping算法,用文本中的代名词、动词、形容词、副词等元素作为特征,还依照段落中句子位置的不同给予不同的对待,来实现对语料数据的主客观分类。朱嫣岚[12]等在文献中通过人工构建正负种子情感词的词集,利用HowNet计算候选词语与种子情感词之间的语义相似度来确定其情感极性。
藏语文本情感分类方面,国内外的研究都尚未成熟,相关的文献资料也非常有限。文献[13] 采用藏语三级切分体系对藏语文本进行分词和词性标注,并借助手工建立的藏文情感分析用词表,与已有的特征选择方法相结合提取情感特征,用相似度分类算法进行藏文文本的情感分类。文献[14]采用基于统计和基于词典相结合的方法对藏文微博进行情感分析,发现该方法的准确率明显高于基于TF-IDF的藏文微博情感分析的准确率。
针对藏语语料库本身的缺乏,难以进行复杂模型的训练,也无法进行横向对比,基于藏语结构的特殊性,本文提出了一种基于情感词词典的藏语文本句子情感分类的方法,首先构造了基础的藏语情感词词典、否定词词典、双重否定词词典、程度副词词典、转折词词典,然后基于这些词典,针对藏语文本的特征,构建了一个适合藏语文本情感分类的规则集,最后使用这个规则集对藏语文本句子进行情感分类。
2 情感词典的构建
极性词典是文本情感分析的基础。利用高质量的情感词典,实际的应用系统采用简单快速的方法就可以得到很好的效果。由于藏文信息处理起步较晚,相关的标注语料较为有限,另外藏语也没有像中文(HowNet)和英文(WordNet)那样具有揭示概念与概念之间以及概念与属性之间的关系为基本内容的常识知识库,因此本文通过纯手工的方法构造研究所需的藏语情感词典。
2.1 基准情感词典的构建
情感词又称为极性词,在人们表达情感中起着非常重要的作用,虽然有些词语在不同的语境里意义有一定的差异,有些甚至截然相反,如“你好厉害呀,居然每道题都做对了”和“你看你损人好厉害啊”,前者所表述的意思是对方的优点,即学习能力很强,而后者想要表述的意思是对方的缺点,即品德不好。但总的来说,大部分情感词在表达情感的时候没有太大的差异。因此,构建一个基础情感词典是十分重要的。
为了能够比较完善地扩展基础情感词典,本文从当前比较健全的藏语大词典中找出情感色彩较为浓厚的词语,通过人工标注,将情感词分为正向情感词和负向情感词,并参照大连理工大学的中文极性词典的极性强度标准给情感词标注极性强度,多次校对后将其加入到基础情感词典中。情感强度以数值1、3、5、7、9划分为五个强度等级并用于情感值计算,9表示情感强度最大、最强烈,1表示情感强度最小;情感极性以1代表褒义正向,2代表贬义负向。经统计,该基础情感词典一共包含2 306个情感词,其中正向情感词1 136个,负向情感词1 170个。情感词典具体格式如表1所示。

表1 情感词典格式
2.2 否定词典和双重否定词典的构建
否定词(NA)和双重否定词(DNA)在基于规则的藏语情感判别中有着至关重要的地位,若是只考虑情感词,在很多情况下计算出来的情感倾向会与实际的情感倾向完全相反,如“(干净)”和“(不干净)”。否定词使得词的情感极性发生改变,双重否定词不改变情感极性,但情感语气有加强的作用。借鉴文献[15],我们构建并完善了否定词词典和双重否定词词典,如表2所示。

表2 否定词词典和双重否定词词典示例
其中,否定词的总个数为26,双重否定词的总个数为11。
2.3 程度副词词典和转折词词典的构建

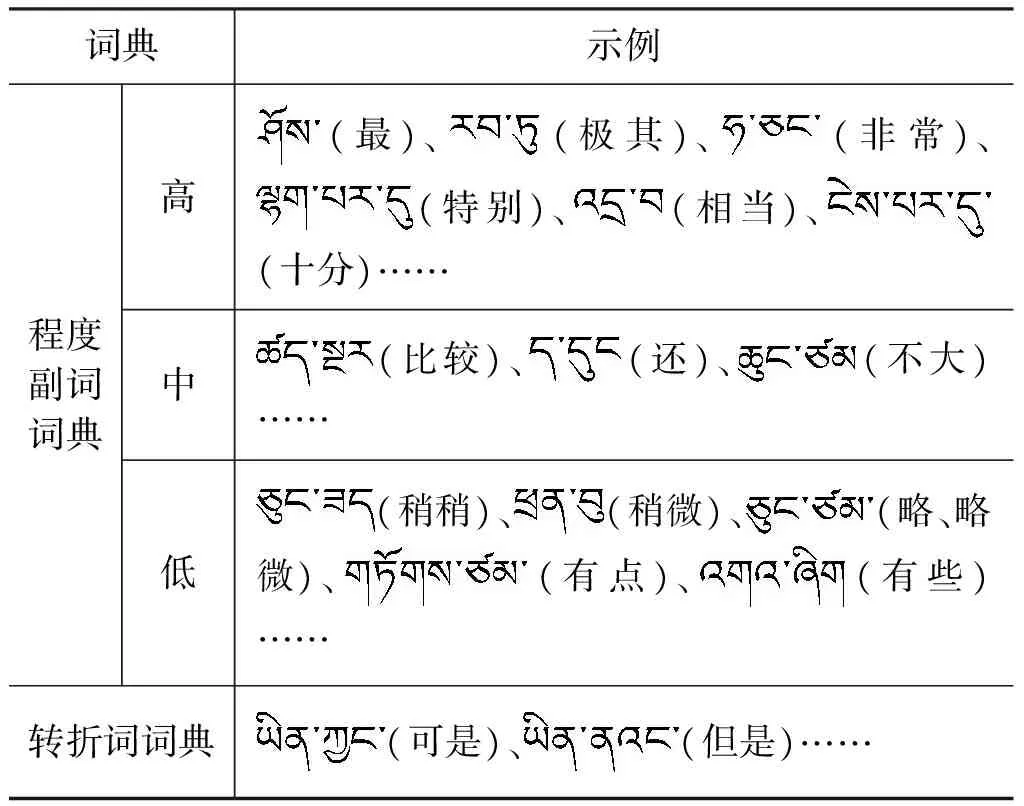
表3 程度副词词典和转折词词典示例
其中,程度副词的个数为71,转折词的个数为6。此外,不同的程度副词具有不同的程度量,本文根据程度的大小把程度副词分成高、中和低三类,其数量分别为40、5、26。
3 藏语句子情感分类
3.1 情感短语识别和极性计算

本文基于所构建的情感词词典以及程度副词、否定副词等修饰词词典,并根据藏语文本的结构特征,对句子中的情感短语进行识别。在藏语中程度副词位于被修饰词前,而与中文及英文不同的是,藏语的否定词可能位于被修饰词的前面构成否定短语,也可能位于被修饰词的后面;或者被修饰词前面后面同时存在,构成双重否定句。对于一个含有情感词语的藏语情感文本,首先查看情感词前面的词语是否属于程度副词词典或否定词词典,再查看情感词后面的词语是否属于否定或双重否定词词典,如果有一个匹配成功,则获取这个词组作为情感短语。
文献[16-17]对中文副词连用进行了细致地研究,本文借鉴其思想并结合藏语的特点,将极性词与其修饰词构成极性短语,并给出了极性强度的计算公式,如表4所示。


表4 情感短语的极性计算
3.2 藏语句子情感计算
(1) 未识别出转折词
在句中未识别出转折词,句子的情感值按照式(1)来计算。
(1)
E(S)代表未识别出转折词的句子在经过情感计算后最终的情感值。E(Gi)表示的是句子中第i个情感短语的情感权重值。
(2) 识别出转折词
在绝大多数含有转折词的句子中,转折词的个数只有一个,因此这里讨论只含有一个转折词的句子。如果转折词前、后都有情感词,则反转转折词之前的情感词极性;如果转折词之前有情感词,转折词之后没有情感词,则反转该情感词的极性;如果转折词之前没有情感词,之后有情感词,则对该情感词的情感分值倍乘一定的权值。计算如式(2)所示。
(2)
E(S)代表句中识别出转折词的句子在经过情感计算后最终的情感。Sb表示句中转折词前面那一部分子句,Sa表示句中转折词后面那部分子句。
对于一个待判定的藏文句子,其情感得分的绝对值大小表示情感的强度,若其情感得分为负值,我们认为其极性为消极;若其情感得分为正值,则将其判定为积极;若情感得分为零,则认为该句子是中性的。
4 实验结果及分析
4.1 实验数据
在少数民族语言方面尚无公开的语料,对少数民族语言评测的准确率也尚无标准。而且由于少数民族语言的使用范围小和掌握人数较少,对语料的标注工作也有很大的困难。本文通过从各大藏语论坛,藏语微博中收集了一个用于情感分类测试的文本语料库,经过统计,该语料库的藏语句子数目一共为988句,其中包括423个正向句子、376个负向句子,以及189个中性句子。此外,在非中性句子中,包含情感短语的句子有134个,转折词的句子有57个,只包含情感词的句子有608个。
4.2 实验评价指标
本文所采用的评价指标为准确率P、召回率R和F值,这也是在自然语言处理中经常采用的三个实验评测指标。准确率是测试得到的情感句子总数与测试得到的句子总数的比率,衡量的是检索系统的查准率,计算如式(3)所示。
(3)
召回率(recall rate),另名查全率,是测试得到的结果中正确情感句子数和测试语料中所有的情感句子总数的比率,衡量的是模型系统的查全率,如式(4)所示。
(4)
F值通过召回率R和准确率P计算得到,是一项新的评价指标如式(5)所示。
(5)
4.3 实验结果及分析
本文在以上所描述的情感分类算法的基础上,用Java实现了藏语句子情感分类系统。为了验证本文所提出的情感分类算法的有效性,我们使用所有资源语料进行情感分类测试实验。实验测试结果如表5所示。
从表5实验结果可以发现,本文提出的基于情感词典的藏语文本句子情感分类方法在一定程度上可以对藏文句子进行情感分类。其中,中性类别的召回率达到95.76%,但其准确率只有67.53%,说明有很多带有情感的句子没有被系统识别出来,并被错误判定为中性。究其原因,应该是本文构建的藏文情感词典的规模不够大,覆盖率不够高。
5 总结与展望
本文构建了一个用于藏语句子情感分析的极性词典,将修饰词和极性词构成极性短语作为极性计算的基本单元,并考虑了转折词对藏语句子情感极性的影响,提出了一种基于词典的情感分析方法,取得了不错的效果。然而本文是采用人工的方法建立情感词词典,这种方法在一定程度上费时费力,仅靠情感词词典匹配的方法来完成藏语句子情感分类是不够的。因此,下一步研究工作主要有:改善现有的关键词匹配算法,提高情感词典的自动扩建能力等。
[1]赵妍妍,秦兵,刘挺.文本情感分析综述[J].软件学报,2010, 21(8):1834-1848.
[2]Pang B,Leeand L,Vaithyanathan S.Thumbsup Sentiment Classification Using Machine Learning Techniques[C]//Proceedings of EMNLP’02,2002.
[3]徐军,丁宇新,王晓龙.使用机器学习方法进行新闻的情感自动分类[J].中文信息学报, 2007, 21(6):95-100.
[4]李钢,程洋洋,寇广增.句子情感分析及其关键问题 [J] .图书情报工作, 2010, 54(11):114-117.
[5]Riloff E,Shepherd J.A corpus-based approach for building semantic lexicons[C]//Proceedings of the Second Conference on Empirical Methods in Natural Language Processing,1997:117-124.
[6]Riloff E,Shepherd J.A corpus-based bootstrapping algorithm for semi-automated semantic lexicon construction[J].Journal of Natural Language Engineering,1999,5(2):147-156.
[7]Riloff E,Wiebe J, Phillips W.Exploiting subjectivity classification to improve Information extraction[C]//Proceedings of the 20th National Conferenceon Artificial Intelligence(AAAI-05),2005.
[8]Riloff E,Patwardhan S,Wiebe J.Feature subsumption for opinion analysis[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing(EMNLP-06),2006.
[9]Riloff E,Wiebe J.Learning extraction patterns for subjective expressions[C]//Proceedings of the 2003 Conference on Emprical Methods in Natural Language Processing,2003:105-112.
[10]Wiebe J,Riloff E.Finding mutual benefit between Subjectivity analysisand information extraction[J].IEEE Transactions on Affective Computing,2011,2(4):175-191.
[11]Riloff E,Wiebe J,Wilson T.Learning subjective nouns using extraction pattern bootstrapping[C]//Proceedings of the Seventh Conference on Natural Language Learning(CoNLL-2003),2003.
[12]朱嫣岚,闵锦,周雅倩,等.基于 HowNet 的词汇语义倾向计算[J].中文信息学报,2006,20(1):16-22.
[13]李海刚,于洪志.藏文文本情感分类系统设计[J].甘肃科技纵横,2011,40(01):106-107.
[14]张俊,李应兴.基于情感词典的藏文微博情感分析研究[J].科技创新论坛,2014,220-222.
[15]杜雪峰.藏文句子倾向性分析研究[D].北京:中央民族大学硕士学位论文,2015.
[16]尹洪波.否定词与副词共现的句法语义研究[D].北京:中国社会科学院研究生院博士学位论文, 2008.
[17]黄涛.藏文短文本情感倾向性分析研究[D].北京:中央民族大学硕士学位论文,2017.

闫晓东(1973—),博士,副教授,主要研究领域为少数民族语言信息化处理、自然语言处理。E-mail:yanxd3244@sina.com

黄涛(1992—),硕士研究生,主要研究领域为少数民族语言信息化处理。E-mail:274185218@qq.com
猜你喜欢
客联(2022年2期)2022-04-29
读与写(2021年9期)2021-11-21
西藏研究(2021年1期)2021-06-09
西藏研究(2021年1期)2021-06-09
读与写(2020年36期)2020-11-26
布达拉(2020年3期)2020-04-13
西夏学(2019年1期)2019-02-10
科学导报·学术(2018年40期)2018-10-21
中央民族大学学报(自然科学版)(2018年1期)2018-06-27
西藏研究(2017年3期)2017-09-05
