
基于YOLOv2的行人检测方法研究
2018-04-11 01:44:39刘建国王帅帅
数字制造科学 2018年1期
刘建国,罗 杰,王帅帅,关 挺
(1.武汉理工大学 现代汽车零部件技术湖北省重点实验室,湖北 武汉 430070;2.武汉理工大学 汽车零部件技术湖北省协同创新中心,湖北 武汉 430070)
行人检测就是判断场输入的图形或视频中是否有行人并快速准确地判断出行人的位置。行人检测一直是目标检测领域的一项重要内容,其研究具有较大的理论意义和实际应用价值,相关研究成果可以运用于智能驾驶系统、智能机器人、行人分析等领域。行人检测不同于普通目标检测,复杂的背景、不同的光照条件、不同的相机拍摄视角等因素都会对检测结果造成一定影响,加之行人的衣着多样化,人与人之间的遮挡以及行走姿势个性化,使得行人检测非常具有挑战性,同时也亟待解决。
目前行人检测方法可以分为基于背景建模的方法和基于统计学习的方法[1],基于统计学习的方法又可以分为传统的行人检测方法和基于神经网络的行人检测方法。传统的方法主要基于人工设计特征提取器,通过提取HOG(histogram of oriented gradient),Haar,LBP(local binary patterns)等特征,训练分类器进行行人检测,并取得了令人瞩目的成果。其中,具有代表性的是Dalal于2005年提出的梯度方向直方图HOG[2]特征,它结合线性支持向量机作为分类器,取得了不错的效果,后续大多数算法都是在此基础上进行了延伸。2009年Wang等[3]结合HOG特征和LBP特征处理行人遮挡,提高了检测精度。但人工设计的行人特征很难适应行人的大幅度变化,且高运算复杂度限制了实际应用。为了克服传统方法手工设计特征泛化性差的缺点,相关学者将深度模型应用于行人检测。Ouyang等[4]根据人体不同部位之间的相互约束,运用深度模型学习行人身体不同部位特征来解决行人遮挡问题,完成行人检测。近些年,深度学习在目标检测领域取得了重大突破。2012年,Hinton及他的学生Krizhevsky[5]将深度学习应用于图像处理,并在当年的国际大规模视觉识别大赛上取得了第一名的成绩,其Top-5错误率为15.3%,远超过高达26.2%的第二名。2015年,谷歌的Loffe等[6]和微软的何凯明等[7]研究人员都分别将图片分类任务Top-5错误率降低到5%以内,超过了人类极限。目标检测领域学者从中受到启发,提出了一系列基于深度学习的目标检测框架。从RCNN(region convolutional neural network)[8],Fast-RCNN[9],Faster-RCNN[10]到YOLO(you only look once)[11],SSD(single shot multibox detector)[12],YOLOv2[13],目标检测的速度和准确率一直在不断攀升。其中YOLOv2是目前速度和准确率综合表现最好的网络。本文借鉴目标检测中最先进的成果,提出基于YOLOv2的行人检测方法,在YOLOv2网络第一层卷积层前添加底层特征提取层,对图片中行人进行选择性预处理,突出行人特征,区分背景干扰,然后根据行人呈现高宽比固定的特点,聚类分析得到初始候选框anchor的个数及维度,提升检测效果。将本文的方法在INRIA数据集上进行测试,检测效果有明显提升。
1 YOLO算法原理
华盛顿大学Joseph Redmon等人针对区域提名(region proposal)目标检测方法的不足,先后提出了YOLOv1和改进版YOLOv2。不同于其他目标检测网络,YOLOv1网络先将图像划分成S×S的网格,对于每个网格预测B个边界框(bounding boxes)。每个边界框包含5个待预测值:x,y,w,h和置信度。(x,y)是目标窗口的中心坐标,w和h是目标窗口的宽度和高度。置信度Confidence指Pr(Object)×IOUtruthpred,其中IOUtruthpred指真实框和预测框IOU,IOU指两个区域交集和并集的比值,Pr(Object)指目标出现的概率。除了预测边界框,每个网格还要预测C个分类的概率Pr(Classi|Object),它表示检测到的物体属于某一类的概率。YOLOv1没有使用区域提名步骤,直接回归完成了位置和类别的判定,使得其检测速度得到了质的飞跃,实现了端到端的回归方法。检测步骤如图1所示。
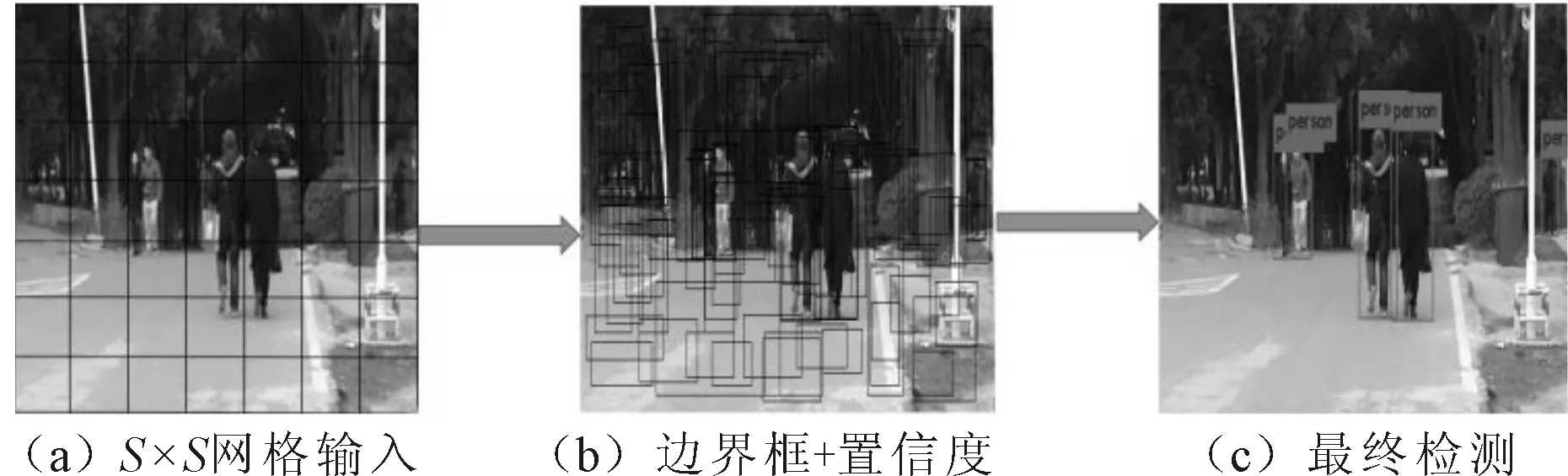
图1 检测示意图
预测的窗口属于某个分类的得分公式为:
Pr(Classi|Object)×Pr(Object)×IOUtruthpred=
Pr(Classi)×IOUtruthpred
(1)
作者设计的损失函数如下:
(2)
根据候选框和分类概率Pr(Classi|Object)在网络预测数据中的维度和重要程度不同,作者给予候选框较高的损失权重λcoord,同时给予分类概率Pr(Classi|Object)较低的损失权重λnoobj,并用候选框的平方根来减小候选框位置的准确性对预测结果的影响。上面函数中,前2项预测候选框,后3项依次预测的是含目标的置信度,不含目标的置信度和目标类别。
YOLOv2参照SSD和YOLOv1网络结构设计了新的基础网络结构Darknet-19,其网络结构包含19层卷积层和5层最大池化层,在保持原有的检测速度下,大大提高了检测准确率。YOLOv2在YOLOv1的基础上使用了很多技巧,其中包括去掉全连接层,模型只剩下卷积层和池化层,因此可以随时改变输入图片的尺寸,增强模型的泛化能力。YOLOv2借鉴Fast RCNN 的anchor机制预测候选框,采用K-means[14]聚类方法来选择anchor boxs个数和宽高维度,由anchor直接预测目标的类别和位置等一系列技巧。
2 基于YOLOv2的行人检测模型
虽然YOLOv2在目标检测领域取得了最佳检测效果,但并不完全适用于行人检测。笔者针对具体应用,在YOLOv2的基础上作出相应改进,使其适用于行人检测,主要改进如下:
(1)在第一个卷积层之前加入底层特征提取层。YOLOv2网络会对输入的整幅图片进行无差别特征提取,但行人检测过程中,图片中的行人仅仅是图片极少的一部分。因此,在YOLOv2网络之前增加底层特征提取层,对输入图像进行预处理,突出行人特征,减小计算量和分析难度。
(2)对数据集目标框进行聚类分析,选择最优anchor个数和宽高维度。YOLOv2的anchor参数是由VOC2007和VOC2012数据集聚类确定的,其数据集中类别丰富,得到的anchor参数具有普适性,但却不适用于行人检测。在行人检测时,无论行人处于什么样背景,行人姿态怎么变化,行人在图片中的长宽比始终是一个相对固定的比值,呈现瘦高的框,因此需要对行人数据集进行聚类分析,重新确定anchor个数和宽高维度。
2.1 底层特征提取层
YOLOv2应用于行人检测过程中,卷积层会对图像进行无差别特征提取,这将导致计算的浪费,同时,行人图像多以车辆,道路为背景,加上行人的非刚性特征,往往导致YOLOv2网络在特征提取过程中学习到错误的特征,干扰最终的检测结果。为了减少背景和行人的非刚性特征对检测结果的影响,笔者对行人图像进行图像预处理,突出行人结构特征。根据传统的行人检测方法,选择纹理特征作为图像预处理计算,实验结果表明,与不进行纹理特征预处理相比,改进的方法能够有效提高检测精度。LBP纹理特征用来描述图像局部纹理特征的算子,它反映了图像每个像素与周围像素之间的关系,描述了图像的表面性质[15]。但由于纹理只是一种物体表面的特性,并不能完全反映出物体的本质属性,因此仅仅利用纹理特征是无法获得高层次图像内容的。与颜色特征不同,纹理特征不是基于像素点的特征,它需要在包含多个像素点的区域中进行统计计算。作为一种统计特征,纹理特征常具有旋转不变性,灰度不变性,且对光照变化不敏感,同时对于噪声有较强的抵抗能力。原始的LBP算子定义在3×3的窗口内,以窗口中心像素为基准,将周围的8个像素的灰度值与其进行相减,若周围像素值与中心像素值差值大于零,则该像素点的位置记为1,否则记为0。这样,3×3邻域内的8个点经比较可产生8位二进制数,即LBP码,得到该窗口中心像素点的特征值,并用这个值来反映该区域的纹理信息。LBP特征值计算公式为:
(3)
式中:(x,y)代表3×3邻域中心,其像素值为gc;gp表示邻域其他像素点的值;S(x)为符号函数,其定义如下:
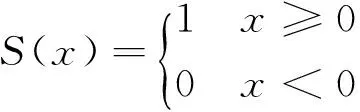
(4)
LBP特征值计算过程如图2所示。

图2 LBP计算过程示意图
选择LBP纹理预处理作为底层特征提取层运算,从图3(a)与图3(b)对比可以看出,行人背景的区别转化成了纹理差异,突出了行人的特征。实验表明,对图片进行LBP纹理特征预处理后,降低了模型的漏检率。

图3 预处理效果图
2.2 目标框聚类分析
YOLOv2借鉴Faster-RCNN的方法,引入了anchor,anchor是一组尺寸固定的初始候选框。Faster-RCNN的anchor是人工设定的,其设定的好坏将极大的影响目标检测的精度和速度。在训练网络时,随着迭代次数的增加,候选框的参数也在不断调整以接近真实框。因此,Joseph Redmon提出了维度聚类的方法,通过K-means方法对目标框作聚类分析,网络根据数据集目标框的特点,学习行人特征,找到统计规律,最终以K为anchor的个数,以K个聚类中心box的维度为anchor的维度。YOLOv2对VOC数据集的聚类结果为5,因此其anchor的个数为5。笔者同样采用K-means聚类方法,对INRIA[16]数据集进行聚类分析,得到anchor的个数和宽高维度。传统的K-means聚类方法使用的是欧式距离函数,这就意味着较大框会比较小框产生更多的错误,因此YOLOv2的作者采用IOU(候选框与真实框的交集除以并集),这样就与候选框的尺寸无关了。最终的距离函数为:
d(box,centroid)=1-IOU(box,centroid)
(5)
本文的聚类目标函数为:

(6)
式中:box为候选框,truth为目标真实框,K为anchor的个数。
笔者采用递增的方法来选择K值。随着K值的增大,目标函数变化越来越缓慢,变化线的拐点可以认为是最佳的anchor个数。目标函数变化曲线如图4所示,当K值大于4时,曲线变得平缓,因此选择K值为4,即anchor的个数为4。

图4 目标函数变化趋势图
3 实验与分析
3.1 训练与测试样本数据集
目前,关于行人检测的数据集有很多,INRIA行人数据集是最常用的静态行人数据集,分为训练集和测试集两部分,训练集包含614张正样本图像和1 218张负样本图像,正样本中含有2 416人。测试集包含288张正样本图像和453张负样本图像,正样本中有1 126人。INRIA数据集拍摄条件多样,存在光照条件变化,行人互相遮挡,背景较复杂等情况,是具有代表性的行人数据集。
3.2 实验平台
本文实验硬件配置如表1所示。

表1 软硬件配置
3.3 分类网络预训练
分类网络预训练是行人检测的重要环节,为减少训练时间,采用Daimler[17]数据集对Darknet-19进行预训练,每训练10轮让网络调整每一层的权重,使网络从分类算法切换为检测算法的过程中能更好地适应行人检测的任务。
3.4 实验结果对比
3.4.1聚类分析
采用对数据集目标框进行聚类分析的方法得到了适合数据集的anchor个数和宽高维度。笔者提出的方法与目前最具代表性的目标检测框架之一Faster-RCNN以及YOLOv2生成候选框的方法对比,聚类分析得到的候选框数量较少,减小了计算的浪费,加快了检测速度,同时能保证更高的平均重叠率,对比结果如表2所示。

表2 候选框对比表
3.4.2底层特征提取层
在行人检测中,漏检和误检是共同的问题。为判断行人检测方法的优劣,笔者选择LAMR[18](log-average miss rate)指标来作为评判的标准。LAMR指标表示的是FPPI(平均每张图片误检数)在[10-2102]上与漏检率之间的关系。以INRIA数据集作为实验数据,在FPPI一定(一般为10-1)[19]时,比较本文的方法与Faster-RCNN、YOLOv2以及传统HOG+SVM的检测效果,实验结果如表3所示。

表3 实验结果对比表
从表3可以看出,在误检率一定时,本文方法的漏检率远低于传统的HOG+SVM方法,同时相比于直接将YOLOv2运用于行人检测,加入底层特征提取层的方法将漏检率降低了1.94%,表3所列的方法中,本文的方法达到了最佳检测效果。将训练好的模型用来检测行人,检测示例如图5所示。图5中显示了直接应用YOLOv2和本文方法检测效果对比,图5(a)为直接应用YOLOv2的检测效果,图5(b)为是本文方法的检测效果,从图5对比可以看出,本文的方法降低了漏检率。

图5 检测效果对比图
4 结论
以YOLOv2为基础,通过加入低层特征提取层,维度聚类分析等方法成功将目标检测算法移植到行人检测。以INRIA数据集为实验数据,根据行人在图像中呈现高宽比相对固定的规律,聚类分析选择较少的anchor个数,并保证了更高的平均重叠率,同时增加了底层特征提取层,选择纹理特征算子对图像进行预处理,将行人背景差异转化成了纹理差异,突出了行人轮廓,降低了行人的漏检率,验证了该方法优越性。本文还存在训练样本较少,模型泛化能力不够等情况。结合其他辅助信息,提高行人特征表达能力,进一步提升检测模型的鲁棒性和实时性,这是行人检测的研究方向,也是下一步工作的研究重点。
参考文献:
[1]Paul viola, Michael J Jones, Daniel snow. Detecting Pedestrians Using Patterns of Motion and Appearance[J]. International Journal of Computer Vision,2005,63(2):734-740.
[2]Dalai N,Triggs B.Histograms of Oriented Gradients for Human Detection[C]∥ Conference on Computer Vision and Pattern Recognition. Sandiego:[s.n.], 2005:886-893.
[3]Wang X,Han T X,Yan S. An HOG-LBP Human Detector with Partial Occlusion Handling[C]∥ Proc. 2009 IEEE 12th International Conference on Computer Vision. Kyoto: IEEE Press,2009:32-39.
[4]Ouyang W,Wang X.Joint Deep Learning for Pedestrian Detection[C]∥IEEE International Conference on Computer Vision(ICCV).[S.l.]:IEEE,2013:2056-2063.
[5]Krizhevsky A,Sutskever I,Hinton G E.Imagenet Classification with Deep Convolutional Neural Networks[C]∥Advances in Neural Information Processing Systems.[S.l.]:[s.n.],2012:1097-1105.
[6]Loffe S,Szegedy C.Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate Shift[C]∥Internation Conference on Machine Learning. [S.l.]:[s.n.],2015:448-456.
[7]He K M,Zhang X,Ren S,et al.Delving Deep into Rectifiers:Surpassing Human-level Performance on Imagenet Classification[C]∥2015 IEEE International Conference on Computer Vision. Santiago: IEEE, 2015:1026-1034.
[8]Girshick R,Donahue J,Darrell T,et al.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J]. Computer Science, 2013(10):580-587.
[9]Girshick R.Fast R-CNN[C]∥IEEE International Conference on Computer Vision. [S.l.]:IEEE,2015:1440 -1448.
[10]Ren S,He K,Girshick R,et al.Faster R-CNN:Towards Real-time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015(1):1-6.
[11]Redmon J,Divvala S,Girshick R,et al. You Only Look Once:Unified,Real-time Object Detection[C]∥2016 IEEE Conference on Computer Vision and Pattern Recognition.[S.l.]:[s.n.],2016:779-788.
[12]Wei L,Dragomir A. SSD:Single Shot Multi Box Detector[C]∥ European Conference on Computer Vision. [S.l.]:[s.n.],2016:21-37.
[13]Redmon J, Farhadi A. YOLO9000: Better, Faster, Stronger[C]∥Proceeding of IEEE Conference on Computer Vision and Pattern Recognition. [S.l.]:[s.n.],2017:135-142.
[14]张素洁,赵怀慈.最优聚类个数和初始聚类中心点选取算法研究[J]. 计算机应用研究,2017,34(6):1-6.
[15]Ojala T,Harwood I.A Comparative Study of Texture Measures with Classification Based on Feature Distributions[J].Pattern Recognition,1996,29(1):51-59.
[16]INRIA. Person Dataset [DB/OL].[2017-12-8].http:∥pascal.inrialpes.fr/data∥human/.
[17]Daimler. Daimler Pedestrian Detection Benchmark Dataset[DB/OL].[2017-12-8].http:∥www Gavrila.net Reserk_d/Daimler_Mono_Ped_Detection_Be/daimler_mono_ped_detection_be.html.
[18]Wojek C,Dolla P,Schiele B,et al.Pedestrian Detection:An Evaluation of State of the Art[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2012,34(4):743-761.
[19]李海龙,吴震东,章坚武.基于卷积神经网络的行人检测[J].通信技术,2017(8):662-667.
猜你喜欢
光学精密工程(2022年13期)2022-08-02 08:53:30
计算机工程与应用(2022年1期)2022-01-22 07:46:48
计算机工程与科学(2021年4期)2021-05-11 01:59:36
软件(2020年3期)2020-04-20 01:45:18
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:00
电子制作(2018年19期)2018-11-14 02:37:08
火力与指挥控制(2018年3期)2018-04-19 11:43:39
Coco薇(2017年8期)2017-08-03 15:23:38
自动化学报(2017年11期)2017-04-04 02:52:58
Coco薇(2015年5期)2016-03-29 23:22:15
