
大数据背景下高校家庭经济困难学生精准认定评价因素研究
2018-04-04 04:06:46魏金婷陶俊清郝明洋芈凌佳田顺利
东华大学学报(社会科学版) 2018年2期
魏金婷,陶俊清,郝明洋,芈凌佳,田顺利,严 军,李 静
(a. 纺织学院;b. 学生处;c. 统战部;d. 科技成果转化中心;e. 人文学院;f. 学生就业服务中心;g. 理学院,上海 201620)
高校家庭经济困难学生的资助工作作为国家整体扶贫工作中的重要部分,受到社会各界的高度关注。习近平总书记多次强调,扶贫工作要在精准扶贫、精准脱贫上下更大功夫。这也为高校开展家庭经济困难学生的资助工作指明了方向。国家资助政策在高校落实的过程中,家庭经济困难学生的认定工作是精准扶贫的第一步。然而,家庭经济困难学生群体的家庭情况是不断变化的动态过程,原有评价因素的设置、认定方式的确定还存在着一系列问题,尚未形成一套相对科学、精准的认定机制和评价体系。大数据技术作为当今计算机领域最前沿的技术,其核心价值在于通过数据挖掘、应用等技术环节,从多样化的海量数据中快速获得高价值的信息[1],为高校开展家庭经济困难学生的精准认定工作提供了新的思维、视角和方法,为确定评价因素、构建评价体系提供数据印证和科学预判,使家庭经济困难学生的认定工作更加精准。
一、 目前高校家庭经济困难学生精准认定环节中存在的问题
(一) 认定指标以经济收入为主,造成结果偏差
目前,不少高校家庭经济困难认定以家庭人均月收入作为主要认定指标,通过与当年最低生活保障标准作比较判别家庭经济困难等级。然而,家庭收入数据一样的家庭可能由于地区差异、劳动力健康情况、家庭负债情况、固定资产等方面的不同造成家庭经济能力的差距。城市居民最低生活保障标准与大学生教育费用负担也缺乏科学的对标依据。认定指标简单化的做法方便操作,却不够精准。《关于进一步加强和规范高校家庭经济困难学生认定工作的通知》(教财厅[2016]6号)指出,各高校要根据各地指导标准,结合学校所在城市物价水平、高校收费水平、学生家庭经济能力等因素,确定家庭经济困难学生的认定标准和资助档次。高校分配资金和名额要把建档立卡家庭经济困难学生、农村低保家庭学生、农村特困救助供养学生、孤残学生、烈士子女以及家庭遭遇自然灾害或突发事件等特殊情况的学生作为重点资助对象。这对认定标准提出了更高要求,需要建立系统的认定指标,最大程度体现学生家庭经济真实承担能力。
(二) 认定依据材料准确性受限,导致结果存疑
在初次认定中,对高校家庭经济困难学生的认定,一般是基于贫困证明、家庭情况调查表等各种生源地证明开展,认定信息来源比较有限,准确性和参考价值有待验证。由于我国还未建立国家、社会、家庭层面的基础收入数据库,个人收入信息不透明,在实际操作中存在技术难题,比如家庭纯收入难以精确测算、收入测定成本过高、难以全面实现等,所以,我国各高校在判断学生的家庭经济供给能力方面还存在诸多困难。[2]此外,从生源地相关部门认定到高校的判断和认可,都有可能存在人为因素影响认定结果。高校经济困难学生认定工作每学年进行一次,认定程序基本为:学生本人提出申请、认定评议小组民主认定、院(系)认定审核等。人为因素较多,也会导致基础认定精准度降低。
(三) 认定程序被动式启动,导致结果错漏
《上海市高等学校家庭经济困难学生认定工作指导意见》提出,认定工作须坚持实事求是,在学生本人提出申请的基础上,实行民主评议和学校评定相结合的原则。这种方式要求学生要主动申请、多方认证,容易出现符合条件的学生因自卑心理不愿意申请或者因不了解资助政策错过申请机会的情况。刘彦等[3]在《独立学院学生资助育人工作的精准认定及精准资助探究》中提出:“大一刚入学学生,辅导员和班委对其都不是很熟悉,故无法做到精准认定,自然无从谈起精准资助,这就导致作假的‘伪贫困生’的出现。”认定程序启动方式被动化容易遗漏一些真正贫困的学生,也让一些投机取巧的学生通过捏造证据、制造假象成为“伪贫困生”。这就需要最大限度获取学生就学、生活的大量数据和可靠信息,方便筛选出真正符合条件的学生,由高校主动出击,降低认定的错漏率。
在高校开展家庭经济困难学生的认定过程中,以上这些主观、客观存在的因素极易导致认定结果出现偏差、存疑或错漏。欲实现认定的高效率、精准性,则需要依赖于认定信息的完善程度,依赖于认定标准的科学程度。大数据平台的建设与联通是进一步提高认定精度的工作方向。
二、 大数据对高校家庭经济困难学生精准认定的意义
(一) 提供充足的数据资源
当今世界,正在从数据时代走向大数据时代。[4]学生在校园中生活、学习、娱乐等所产生的数据状态均能够被客观地采集和记录,可以说大数据实时采集、面向所有个体,具有高度全面性和完整性[5]。通过这些海量、客观、及时、准确的数据,资助部门可以持续观测到学生经济状况的变化。相较传统的数据仓库,大数据拥有更为丰富、充足和客观的数据,同时拥有更加精准的查询、筛选和分析等技术,可以通过学生的用餐消费、网络消费、话费消费等数据真实地反映学生的经济状况及生活状态。大数据提供的这些真实客观的数据资料,经过精确有效的科学运算,能够得出精准认定所需要的学生经济困难及其程度认定的量化指标,这也是精准认定工作的必然要求。
(二) 为提高认定效能提供技术条件支撑
大数据技术可以利用关键词、图表、定位搜索等技术策略,及时且有效地收集到学生的动态信息。区别于以往的随机样本及分析方法,大数据的数据量巨大,应用的样本也是全部样本,这样可以快速地过滤掉海量数据的异常部分,准确、高效地识别出有效数据。大数据技术从最初的家庭经济困难学生信息的客观收集,到过程中的动态管理,再到监管环节,都依靠可量化的数据指标,弱化辅助操作和人为因素的影响。同时,在这些精准数据的基础上,资助部门可以通过对数据进行横向、纵向二维分析,将定性数据转化为定量数据,实现数据的全量化分析,拓展数据的量化维度,提供不同的量化层级[6],实现数据分析过程的准确化,从而提升认定工作的精准度和效能度。
(三) 做到对现有评价体系的数据印证和科学预判
运用大数据开展精准认定工作,能够确保认定流程的科学性、规范性和客观性,能够有效避免资助错配、误判等情况的发生。与此同时,大数据通过对采集到的海量数据进行存储和分析,能够很快地掌握数据之间的关联性,从大量的数据中深入分析出其中隐藏的规律和发展趋势。因此,将大数据技术运用到精准认定工作中,能够准确地把握精准认定的各个因素,并且快速地挖掘其中各个因素之间的关联规律。可以说,大数据不仅能够呈现出最真实客观的数据状态,同时还能够实现对未来发展的科学预判,实现对现有的家庭经济困难学生认定标准和体系的数据印证,为家庭经济困难学生精准认定评价因素、评价体系的构建提供依据。
三、 家庭经济困难学生大数据精准认定评价因素的构建与实证研究
(一) 大数据下家庭经济困难学生精准认定数据收集原则
1. 合法性
大数据时代的今天,保护个人隐私和数据安全是一个亟待解决的问题,大数据的安全和隐私保护等问题十分重要。家庭经济困难学生的数据涉及学生家庭及个人隐私,因此,需要格外注意运用大数据的合法性和保密性。
2. 全面性
大数据有利于指标体系的完整构建,使之能够全方位反映学生家庭经济的真实情况。然而,数据库内部信息碎片化,外部信息孤立化,缺乏统一标准,融合性不强,不能互联互通,给全面分析带来困难。要真正解决这些问题必须进行顶层设计,构建更加完整的指标体系。
3. 有效性
大数据的数据总量大,但价值密度低。因此,在抓取高校家庭经济困难学生认定评价因素的原始数据时,挖掘的方向和对数据的清洗非常关键,盲目追求海量数据反而会降低指标的有效性。
(二) 家庭经济困难学生精准认定的体系评价因素构建
1. 维度划分
大数据挖掘的重点是内容数据和行为轨迹数据。这两个维度覆盖面较为全面,既有静态数据又涉及动态数据,在家庭经济困难学生认定评价因素的构建中,也应遵循大数据的全面性特点,将构建因素分为静态和动态两个维度。
2. 因素划分
基于充分尊重隐私和合法性的考虑,本文以东华大学家庭经济困难学生为对象展开调研,在充分界定导致学生家庭经济困难因素的基础上,听取专家意见,将可能导致学生发生经济困难的项目分为四类:人、社会、自然、经济。
3. 项目划分
在有效性筛选方面,积极总结和吸收兄弟院校相关经验,依据上海市高校开展家庭经济困难认定的实际情况,经反复修订,初步构建出具有普遍性的困难认定评价因素:一级指标为大数据动、静态指标及单列指标;二级指标为因素指标,分为人、社会、自然、经济四个部分;三级指标为16个项目指标,分别为家庭人口数、残疾重病人口数、生源地、房屋结构、劳动力人口数、非劳动力人口数、自然灾害、劳动力工作性质、劳动力受教育程度、赡养/抚养支出、因学支出、在校收入与消费、烈士子女、孤儿、残疾、直系亲属重大疾病。
(三) 大数据下家庭经济困难学生精准认定评价因素的实证研究
1. 数据印证
以东华大学2013—2018年全部家庭经济困难学生为数据样本,依照学校现行家庭经济困难学生认定办法与本研究的评价指标体系进行困难学生认定,并将结果进行双向验证。运用大数据技术提取2013—2018年五年间困难认定个人描述中的所有关键词,并将关键词代入前述因素一一验证,在反复论证的基础上,可见前述项目因素基本可以涵盖数据库中筛选出的所有关键词,故指标因素设置较全面。
2. 评价指标计算
第一,对当年家庭经济困难学生申请中个人情况描述的语句按照本科生、研究生及两者综合分别进行统计,筛选个人描述中出现频率较高的关键词(如收入、父母、身体等),计算各高频关键词的出现次数(词频),并由高到低对关键词进行排序,同时根据各关键词的词频与困难学生总数的比例求得词频百分数。由于关键词众多,仅提取频率最高的30个,如表1所示。
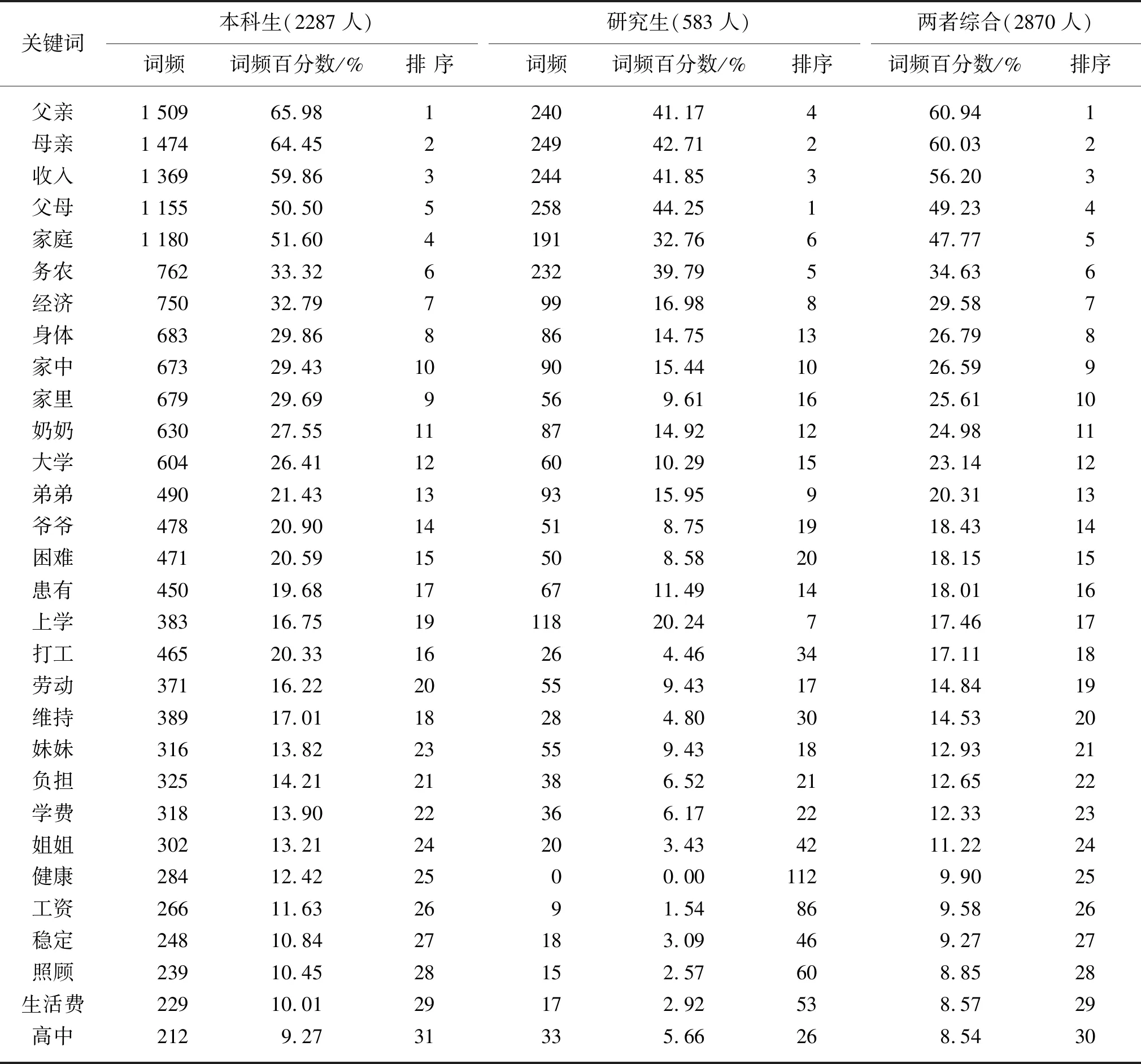
表1 家庭经济困难学生个人情况描述词频分析
第二,按照上文的评价体系各因素,对筛选出的关键词进行分类归纳。如表2所示(仅提取频率最高的30个)。
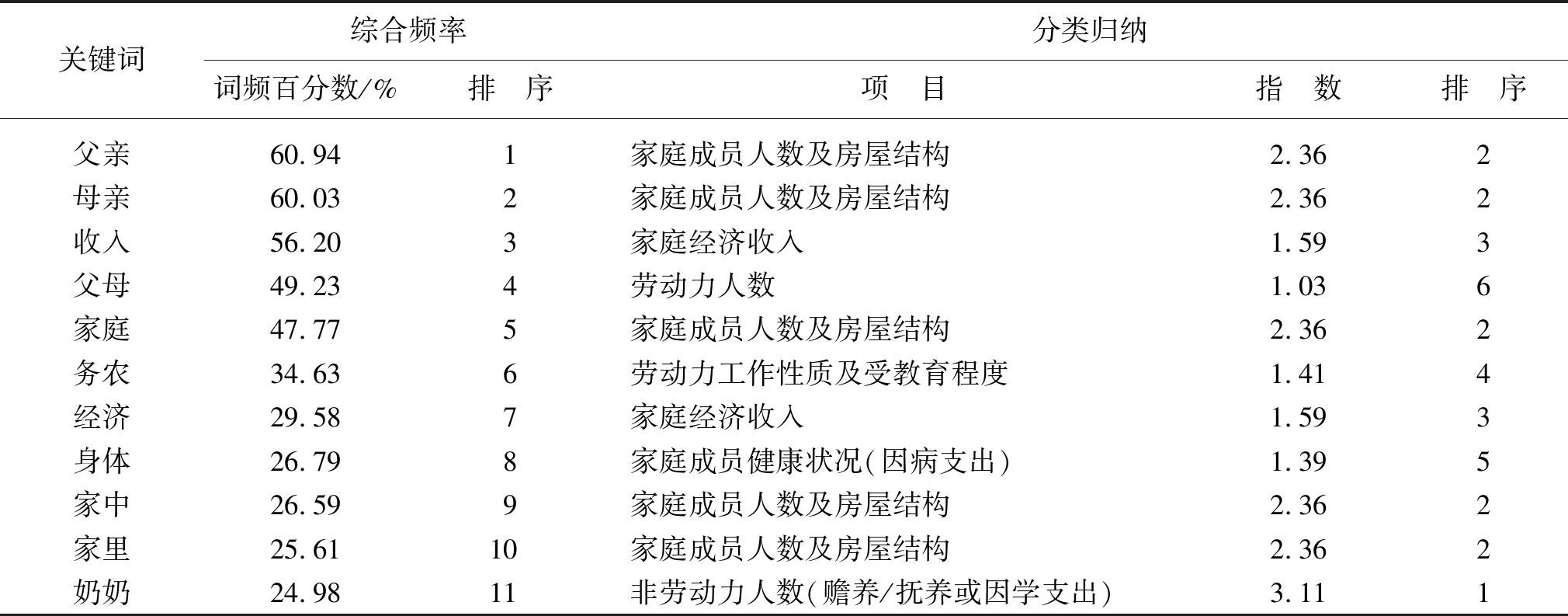
表2 家庭经济困难学生个人情况描述关键词分类
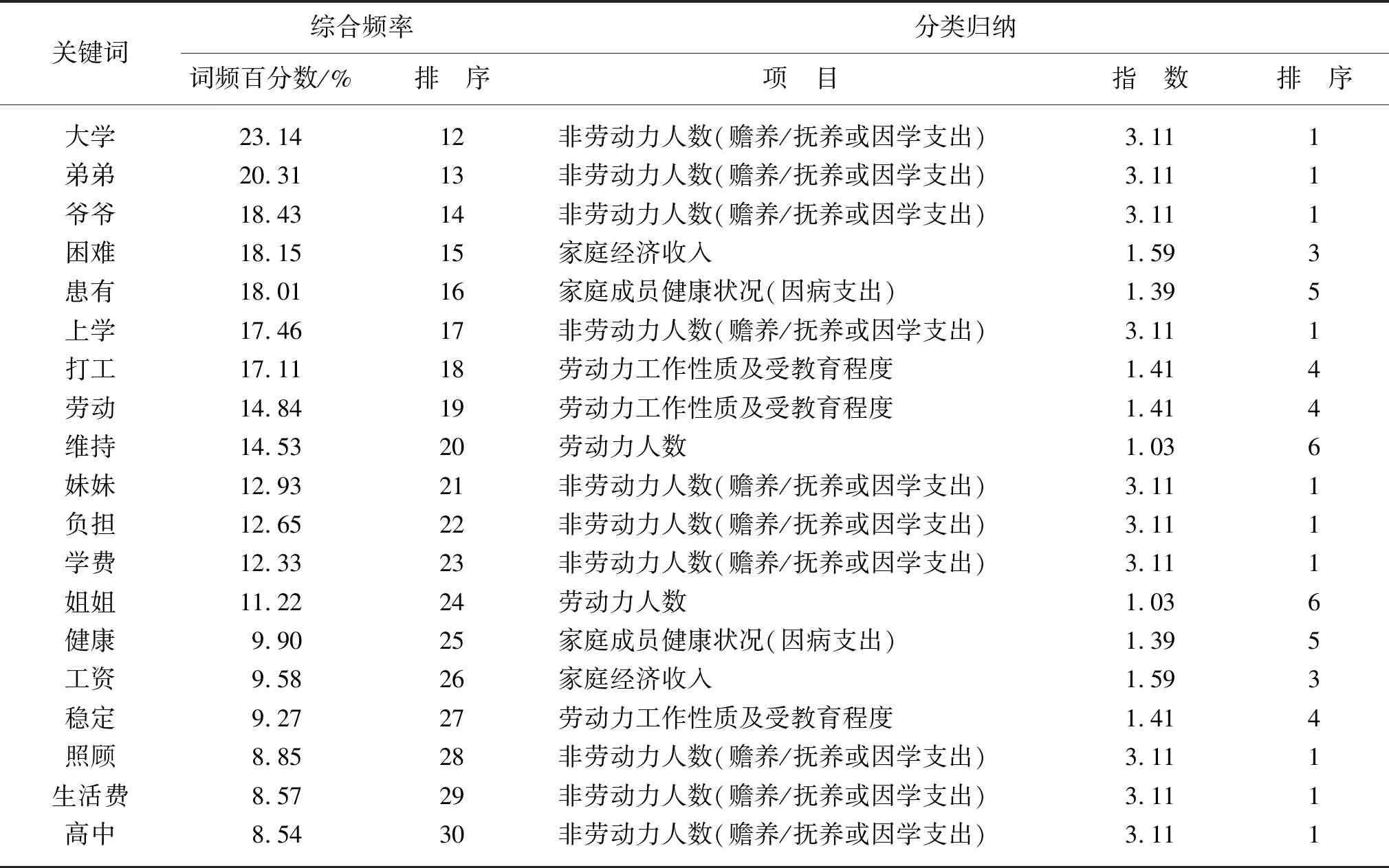
(续表)
第三,根据所包含关键词的词频对各项目进行加权求和,从而得出各项目的“项目指数”,最后根据“项目指数”由高到低对项目进行排序。如表3所示(全部数据)。

表3 家庭经济困难学生个人情况描述关键词指数分析
在所有评价因素中,影响度从高到低依次为赡养/抚养或因学支出、家庭成员人数及房屋结构、家庭经济收入、劳动力工作性质及受教育程度、家庭成员健康状况(因病支出)、劳动力人数、生源地、天灾。
四、 结论
(一) 六类因素可作为家庭经济困难学生认定的主要参考因素
由词频数据分析可知,家庭经济困难学生认定的主要参考因素分别为赡养/抚养或因学支出、家庭成员人数及房屋结构、家庭经济收入、劳动力工作性质及受教育程度、家庭成员健康状况(因病支出)、劳动力人数。在认定操作过程中,可主要从以上因素进行综合考虑。但需注意的是,精准认定因素是相对的、动态的。其相对性在于同样的家庭人均收入水平,不同生源地学生的家庭经济状况是有差别的;动态性在于,随着社会经济的发展,认定因素需要作相应调整,不能一成不变。
(二) 赡养/抚养或因学支出因素在精准认定中需要引起重点关注
与传统观念中以家庭经济收入为主的认定指标不同,通过大数据提取分析实证研究发现,赡养/抚养或因学支出对家庭经济困难的影响度远高于其他影响家庭经济困难的因素。因此,对于高校家庭经济困难生的精准认定而言,应在赡养/抚养或因学支出一项予以重点关注,即综合考虑家庭多子女情况及直系老人赡养情况。
(三) 关注学生生活就学动态评价因素,建立科学复核认定机制
根据关键词指数分析可以发现,在困难学生精准认定评价各因素中,动态属性比静态属性占有更大权重。因此,在高校家庭经济困难学生精准认定的过程中,需定期观测学生生活、学习、就餐等数据,以及家庭成员健康情况变化、劳动力人数变化、生源地变化、自然灾害等情况真实反映学生经济状况及生活状态的信息,做到人工与大数据交叉复核,并根据动态数据不断调整精准认定的初认定结果,实现精准认定的动态化。
