
语言生态监测的多样性计量评估模式*
2018-03-26 08:05肖自辉范俊军
学术研究 2018年1期
肖自辉 范俊军
语言生态近十年来已成为语言学研究的新热点。为应对语言生态问题,促进语言资源的保护和利用,我们曾提出语言生态监测观点,a肖自辉、范俊军:《语言生态的监测与评估指标体系——生态语言学应用研究》,《语言科学》2011年第3期。并对语言生态监测的概念、内涵、目标和内容作了阐述。近年来,通过对一些区域的语言生态状况进行持续调查和观察,我们感觉到,建立语言生态监测的可操作模式,对于语言生态监测和语言生态的保护很有必要。
一、语言多样性及语言多样性监测
语言多样性是语言生态的一个重要特性,通常是指一定地理区域内不同语言的数量。bLewis, M. Paul(ed.), Ethnologue: Language of the World.16th edn, Dallas: SIL International, 2009,Online: http://www.ethnologue.com/。语言的数量反映了语言丰富度,但它只是语言多样性的一个方面。语言多样性还包含语言使用的均匀度,即语言使用人口的分布情况。例如,甲地和乙地都使用着10种活态语言,说明这两个地区的语言丰富度相同。但甲地每种语言的使用人口均占总人口10%,而乙地90%的人口使用同一种语言,10%的人口使用其他9种语言,显然甲地的语言均匀度要高于乙地。
语言多样性还意味着语言种属的多样性和结构形态的多样性。这与自然界生物圈的物种多样性类似。语言种属多样性是指语言谱系多样性(phylogenetic diversity),或者说“在某区域内语言所属的不同谱系的数量”。Nettle指出,谱系可以定义为不同层次,如语族、语系等。aDaniel. Nettle, Linguistic diversity]. Oxford:Oxford University Press, 1999, pp.149-150.语言结构多样性(structural diversity)是指语言结构的变体数量,如语序、形态、音类等等。语言作为一个复杂的符号系统,其结构类型具有多样性。因此,衡量某个地域或某个社群的语言多样性,应从多方面要素考察。本文主要讨论语言多样性的丰富度和均匀度及其相关要素的计量测定,而谱系多样性和结构多样性的测度问题留待另文讨论。
语言多样性测量和评估在语言生态监测中有重要地位。语言多样性监测是对特定区域的语言丰富度、均匀度、谱系多样性和结构差异度等要素进行周期性调查、观察和测量,对相关数据进行量化分析,揭示一定区域语言多样性等级状况,展示语言数量、语言转用、语言接触、语言消长等状况和趋势,对语言生态系统评估和预警,为语言生态保护提供决策依据。
语言多样性监测对象具有地域性,它包括一定地域范围的全部语言(或方言)及其自然和社会环境系统,而非只针对某个单一语言或方言。语言多样性监测的内容至少包括三方面:一是区域内语言和方言的数目;二是区域内语言和方言的使用人口数,包括各语言和方言的总使用人口,以及不同语言能力者的数量;三是区域内各语言和方言使用人口所占总人口的比例。
语言多样性监测评估,具体要回答以下问题。1.一定区域的语言和方言多样性现状如何?哪些区域是语言多样性保护的热点?2.一定区域内的语言和方言多样性在过去几十年内发生了多大程度的变化?哪些区域语言生态的变化较为突出?语言多样性变化的方向、数量、程度和速度如何?3.语言文字政策会促使语言和方言多样性怎样变化?4.本土传统语言和方言的数量和使用人口的现状及变化趋势如何?外来语言的数量和使用人口情况如何?
针对这些问题,我们参考国外有关语言多样性问题的研究,借鉴自然生态学的生物多样性监测评估方法和模式,提出语言多样性监测的工作内容,包括:(1)明确语言多样性监测与评估所针对的具体语言问题;(2)确立语言多样性监测的指标体系;(3)选取和设置语言多样性监测区域;(4)统一调查方法;(5)语言多样性数据的采集和分析处理;(6)语言多样性评级;(7)建立语言多样性监测数据信息网络。
二、国外的语言多样性计量评估研究
就我们所见到的文献而言,美国的世界民族语文研究院(SIL)b网址:https://www.sil.org/。和语界组织(Terralingua)c网址:http://terralingua.org/。开展了语言多样性的调查和计量研究。SIL发布的《民族语》(Ethnologue: Languages of the World)d网址:http://www.ethnologue.com/。提供了世界语言的数量,各语言使用人口的数量、分布等数据,并定期修订。2000年第14版开始用计量方法测定每个国家语言多样性指数。例如,2009年第16版列出中国语言多样性指数是0.536。语界2010年发布了《语言多样性指数》报告,eDavid Harmon, Jonathan, The Index of Linguistic Diversity: A New Quantitative Measure of Trends in the Status of the World’s Languages. Language Documentation and Conservation, http://n fl rc.hawaii.edu/ldc, 2010,4: 97–151, Archived from the original (PDF) on 18 November 2014.这可能是世界语言多样性趋势的第一个计量分析报告。该报告包括两项测量:一是世界语言多样性测量;二是本土语言多样性测量。从全球7299种语言中随机选取1500种作为统计样本,通过人口数据对不同年份的语言多样性指数进行计算,得出各年指数以及发展变化趋势。该报告指出,1970年至2005年全球语言多样性减少20%,本土语言多样性在世界大多数地区急剧减少;世界上16种最强势语言则增加了45%—55%的使用人口。
国际上对语言多样性调查和监测及相关政策的制定,都依赖于语言多样性指数(diversity index)这个多样性数值指标。计算语言多样性指数的方法有两种:一是葛林伯格(greenberg)评估法,二是语界的评估法。
(一)葛林伯格的语言多样性评估方法
美国语言学家葛林伯格于1956年提出了语言多样性的计量方法。aGreenberg, Joseph H.,“The Measurement of Linguistic Diversity”,Language, 1956, 32 (1)这种方法主要计量一定区域语言多样性状况及族群交流概率。他提出了八种计量模式。实际上,只有前面七种用于评估语言多样性,最后一种用于评估语言交流率,即随机选择两个个体能互相通话(即有共同语)的概率。七种计量模式中,模式A和模式B最常用。
模式A: 单语不加权法。在某地随机选择两个人,将他们说同一种语言的概率作为计算语言多样性指标。若人人都说同一种语言,两人说同一种语言的概率就是1;若人人都说不同的语言,概率就是0,因此指数在0~1之间。单语不加权计算公式为:
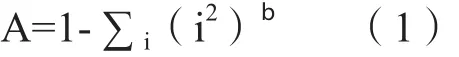
b A就是单语不加权法得出的多样性指数,∑i(i2)就是区域内所有语言各自使用人口除以总人口数平方的加和。比如,既定区域有M、N、O三种语言,有1/8的人说M,3/8说N,1/2说O,则A=1-[(1/8)2+(3/8)2+(1/2)2]=0.593。
模式B:单语加权法。单语加权法考虑了语言相似度。若两对语言的分布概率相同,差别越大则语言多样性越高。设rMN表示语言M、N的相似度,M、N相似率越大,rMN越大。确定权重(相似率)的方法是:随机选择若干固定的基本词汇,计算不同语言中这些词汇的相似比(数值在0~1之间)。公式为:

c mn是在全体人口中随机有序的抽取两个单语人,第一个人使用语言M,第二个人使用N的概率。rMN就是配对的两种语言之间的相似率。
模式A和B都是基于每个人只使用一种语言(母语)的假定,而其他模式则考虑多语状况。例如,模式C和D是拆分人数计量法。在计算语言使用人数时,将每个双语人等价为2个单语人,如使用M、N的双语人,等价为使用M语的单语人和使用N语的单语人;三语人等价为3个单语人,如此类推。这种计量模式也分加权和不加权两种,分别采用上面模式A和B的计算公式计算。
模式E和F:随机说话人计量法。将使用人口按其实际语言能力情况分类,如某地有M、N、O三种语言,根据语言能力将语言使用者分成:使用M的单语人,使用N的单语人,使用O的单语人,使用M、N的双语人,使用M、O的双语人,使用N、O的双语人,使用M、N、O的三语人。这种模式也分加权和不加权,分别采用式(1)、(2)计算。区别在于,计算前要先对每种等价单语人进行有序配对,多语人组合对应的每种等价的单语人配对均分多语人组合的概率。
模式G:随机说话人—听话人计量法。这种方法考虑到多语者交流时语言互懂情况,仅有不加权模式,与方法E类似,区别在于假设多语人等概率使用其自身某种语言。
(二)语界的语言多样性指数
语界的多样性指数,计算不同年份全球所有语言使用人口各占全球人口的比例平均数的变化,它反映了语言多样性历时变化。计算过程如下:
(1)计算出某年不同语言的使用者占全球(区域)总人口的比例。计算公式是:Fly=Nly/Py。
式中,Nly=某年(y)将语言l作为母语使用人口数量;Pym=某年(y)的区域总人口。
(2)计算人口比例F的几何平均数,计算公式是:M = (F1.F2.F3...Fn)1/n。n=语言总数。
(3)得出语言多样性指数,计算公式是:Iy=Iy-1(My/My-1)。
式中,Iy=某年(y)语言多样性的指数;
My=某年F值的几何平均数;
My-1=前一年F值的几何平均数。
将1970年的多样性指数设置为1.0,此后每年指数增加,说明多样性增加;指数减少,则说明多样性减少。如果维持初始值,则表明全球变化趋势较为平坦。当全球指数是0.8时,表示多样性指数比1970年下降了20%。
三、语言多样性综合评估模式
上述模式数据主要基于每种语言使用者占总人口的比例,即语言均匀度。这种方法虽然简便,但存在以下问题:两个模式只考虑语言多样性,不考虑方言多样性,因而对大区域(如国家、地区甚至全球)评估比较合适,对小区的评估却有所不便。语界评估法只考虑母语,葛林伯格评估法考虑了多语,但都没有考虑母语和其他语言的地位和作用差别。两个计量模式的指标也过于单一,没有考虑传统本土语言在语言多样性系统中起到的价值和作用,也没有考虑到外来语言情况及其对语言多样性的影响。因此,我们认为,语言多样性计量评估应是多指标综合评估,以丰富度和均匀度为基础,兼顾本土语言和方言丰富度、外来语言数量和方言渗透度等要素,建立相应要素权重来计量和测定。
综合计量评估性设立四个指标。1.语言和方言a本文所指的方言是少数民族语言的大方言、汉语大方言的方言片,如藏语的康方言、粤方言广府片等,不含次方言、方言小片和方言点。丰富度指标,测定一定空间范围内的语言和方言数目以表达语言的丰富程度,数据主要是一定区域的语言和方言数。2.语言和方言均匀度指标,判断语言和方言的使用者分布情况的数值。3. 传统本土语言和方言b本文所指的传统本土语言和方言,是指在当地使用时间在10代及以上的语言和方言。的丰富度指标,测定区域内本土语言和方言的数量,用于比较语言的特殊价值。4. 外来语言和方言的比例指标,测定区域内外来语言和方言使用人口与区域总人口之比,用于比较语言多样性系统的潜在受干扰程度。
具体评估步骤如下。
第一步:设计指标权重。语言多样性指标权重是权衡指标内容项相对重要程度的量值。指标权重关系是否科学合理,直接影响计量评估结果的效度和信度。我们采用专家咨询法确定权重,选择语言学、生态学、环境科学等领域29位专家,独立对各项指标进行两两比较,按百分制打分,最后计算各专家权重平均值,确定各要素指标的最终权重。权重系数如表1所示。

表1 语言多样性的指标权重
第二步:明确评价指标的归一化处理。
语言多样性各指标的具体数据来源不同、数值不同,需要归一化处理。计算式如下:
S = S' /Amax; A = 1/Amax
式中 S 为归一化后的评价指标; S’为归一化前的评价指标; A 为归一化系数;Amax为某指标归一化处理前的最大值。
第三步:计算语言多样性综合评估指数。
语言多样性综合评估指数是语言和方言丰富度、语言和方言均匀度、特有的本土语言和方言的丰富度、外来语言和方言的数量和比例4个评价指标的加权求和,其计算过程如下。
(1)计算语言和方言丰富度指数。
语言和方言丰富度,即区域内语言和方言的数量,再作归一化处理。计算式是:
SF= ( Sy×A1+ Sf×A2)/2
Sy是区域内语言的数量,Sf是区域内方言的数量;A1是语言数量的归一化系数,A2是方言数量的归一化系数。
(2)计算语言均匀度。考虑到计算的语言类别包括语言和方言两类,而语言又包括了下属的方言,为避免重复计算,此处的语言均匀度实际就是方言均匀度。均匀度采用葛林伯格的单语加权法或随机言语者加权法。计算式是:SJ=1-∑ab(ab)(rAB)
ab是将两种方言配对(包括两种相同的方言),能够随机选择到说这种方言的两个人概率。rAB就是配对的两种方言之间的相似率。
(3)计算传统本土语言和方言的丰富度。传统本土语言和方言的丰富度即传统本土语言和方言的数量。计算式是:ST= ( S3×A3+ S4×A4)/2。式中,ST为归一化后的传统本土语言和方言丰富度;S3为传统本土语言种数;A3为传统本土方言归一化系数;S4为传统本土语言种数;A4为传统本土方言归一化系数。
(4)计算外来语言和方言渗入度。外来语言和方言渗入度是指既定区域外来语言和方言的使用人口与总人口数之比。计算式为:SW=S5/S0×A5。式中,S5是外来语言和方言的使用人口数;S0为区域内总人口数;A5是外来语言和方言归一化系数。
(5)加权求和。最后对这几个指标值进行除权相加。其中,外来语言和方言的数量和比例为本型指标,即指标的属性值越小越好,故对其作适当转换。语言多样性综合型指数为:
EI = SF× 0. 41+ SJ× 0.37+ ST×0. 11 + ( 1 - Sw)×0. 11
第四步:对语言多样性状况分级。
语言多样性的最终评估,采用层级划分比较直观和方便,尤其是对象样本较少的时候,可直接对语言多样性状况作出定性判断,得出具体区域语言多样性的现状,并对该区域语言多样性状况进行定级。这样可以对语言生态保护的政策制定和实施行动提供切实的依据。为避免分级限制过细和出现过多跨级现象,我们将语言多样性分为高、中、一般和低四个等级。语言多样性计量指数在0至1之间,而且数值越接近1,表明多样性越高。因此,语言多样性等级与对应的数值分配情况具体见表2所示。

表2 语言多样性状况分级表
有时,为尽快了解某个区域语言多样性大概状况,通常可采用语言多样性快速监测评估法——单语不加权法,即利用随机取样的两个个体说不同语言的概率来对语言多样性进行快速监测与评估。此法原型来自生物学的辛普森指数,它在自然生物学中常用来快速测定群落物种多样性指数。a陈廷贵、张金屯:《十五个物种多样性指数的比较研究》,《河南科学》1999年第17期。
综合计量评估模式需要复杂而长期的数据,如单语人数量、双语人数量、外来语言数量及使用人口等等。因此,应建立一个语言生态的周期普查系统和工作机制,以逐渐实现在科学时间密度内扩大数据样本的范围和种类,使语言生态的监测评估更科学有效。语言生态监测还处于探索阶段,目前没有科学的指标体系和有效的计量模式。无论采用何种方式,只要有科学性、客观性和可操作性,都值得一试。
猜你喜欢
东方少年(2022年28期)2022-11-23
今日农业(2021年15期)2021-11-26
计测技术(2020年6期)2020-06-09
新世纪智能(高一语文)(2019年11期)2020-01-13
新世纪智能(高一语文)(2019年11期)2020-01-13
河南畜牧兽医(2020年21期)2020-01-10
特别健康(2018年4期)2018-07-03
消费导刊(2017年24期)2018-01-31
北京航空航天大学学报(2017年3期)2017-11-23
现代企业(2015年2期)2015-02-28
