
基于全球研究数据注册仓储Re3data.org的医学科学数据
2018-03-22 01:15
中华医学图书情报杂志 2018年9期
吴思竹,李赞梅,崔佳伟,修晓蕾,钱 庆
随着数据密集型科学时代的到来,数据增长迅速,各国均意识到数据的重要性,将大数据提升到战略层面,数据已成为科技发展和科技竞争的重要战略资产。数据仓储是对外服务的平台,它不仅是数据存储的仓库,还提供管理、服务。Re3data.org(Registry of Research Data Repositories)是综合性的全球研究数据存储注册仓储,面向研究者、资助机构、出版者和学术机构呈现永久保存与访问的数据集,致力于推动研究数据的共享传播、提高数据的可见性、促进数据的访问和复用。
Re3data.org由德国研究基金(Deutsche Forschungsgemeinschaft,DFG)资助,德国洪堡大学的柏林图书馆与信息科学学院、德国地理科学研究中心、卡尔斯鲁厄理工学院共同参与建设,于2012年上线,2014年3月与科学数据目录仓储Databib合并,并由DataCite统一接管[1]。为促进注册管理机构的可持续发展,Re3data作为一项数据仓储注册服务于2016年被纳入DataCite[2]。它不仅是欧洲委员会、国家科学基金会等资助机构在其数据管理和共享相关的指导方针和政策中积极推荐使用的仓储,也是《自然》科学数据、PLoS ONE和英国皇家学会等出版社和期刊推荐作者查找、保存和发布数据的仓储平台。大量数据建设或持有者不断向Re3data.org注册仓储数据,其汇集的仓储资源已成一定规模,截至2018年8月收录了2 150个数据仓储,其中包括大量的医学领域科学数据仓储。通过系统分析,能够在一定程度上反映和总结全球医学领域数据仓储建设的现状、经验与不足,为我国解决医学科学数据共享仓储研究和实践中面临的基础技术、共享政策、数据权益、标准规范等方面的问题提供参考和借鉴。
虽然全球已建立了很多数据仓储,如Dryad、DataMed、NIH公共数据仓储等均收录大量医学领域数据资源,但只囊括了部分资源,提供的数据统计功能多针对自身收集的数据情况,不足以反映领域整体数据的汇聚、建设及管理等情况。目前,还没有能够全面揭示各国医学科学数据开放共享程度的网站或系统。Re3data.org面向全球提供科学数据仓储的注册,收录了较广泛的数据仓储,能够在一定程度上反映全球科学数据的开放情况。其网站虽然也提供收录仓储数据的统计分析,但是以全部数据为对象,分析粒度较粗,不能按领域等进行灵活数据遴选和细粒度分析,在分析方法和数据呈现方面也相对简单。因此,研究者结合不同研究需求和目标,基于Re3data收录的科学数据仓储数据开展分析和研究工作。如邹丽雪等侧重分析生命科学领域科学数据仓储的年代、国家、机构、学科领域、开放程度等分布情况,并选取6个典型的数据仓储进行特点分析[3];王辉等从Re3data元数据中遴选14个指标,对1 848个科学数据仓储的责任机构进行定量分析,并通过独立样本t检验方法分析比较了不同学科的仓储数据内容、服务类型、数据访问与上传等方面的差异[4];张莎莎利用Re3data数据分析了英国数据仓储建设情况[5];夏姚璜对比了中国和美国的数据仓储建设特点[6];曾丽莹等对211所高校科学数据知识仓储的分布特点、资源数量和数据管理方式等进行了分析,阐述了对高校科学数据仓储建设的启示[7];Kindling M.提出对2015年Re3data收录的全部数据进行多维度分析,对仓储的可见性和功能性提出了建议[8]。我们主要利用统计分析、共现分析和社会网络分析等方法,并结合可视化图表针对Re3data.org中收录的医学领域科学数据仓储的分布、使用的特殊元数据标准、政策、许可等情况进行分析。
1 数据与方法
1.1 主要方法
Re3data.org使用Re3data Metadata Schema 4.0从多维度描述科学数据仓储和收录数据的基本信息和属性特征,并提供应用程序编程接口(Application Programming Interface,API)数据访问接口。本文主要通过编写Java程序调用API数据接口,用可扩展标记语言(Extensible Markup Language,XML)格式的仓储描述元数据的采集。通过编写XML数据解析和数据清洗程序进行预处理,利用UCNET等工具及统计方法、共现分析和社会网络分析等方法,结合可视化图表对Re3data.org中收录的医学科学数据仓储的分布、资源内容、建设模式和服务模式等进行量化分析,并基于此展开探讨和总结。
1.2 数据选取
本文数据采集时间为2017年8月。Re3data.org是综合性数据仓储,使用德国研究基金提出的DGA分类进行数据组织,将收录的注册数据仓储分为4个一级类目、14个二级类目。涉及到医学领域的大类是Life Sciences,类目下包括Biology和Medicine 2个二级类目。其中,Biology类目包括Basic Biological and Medical、Plant Sciences和Zoology 3个三级类目,该类目下注册了978个数据仓储;Medicine类目包括Microbiology、Virology and Immunology,Medicine,Neurosciences 3个三级类目,该类目下注册了470个数据仓储。两个一级类目下的内容有重叠,一个仓储可能会被分配到多个类目下,如Ensembl Metazoa既属于Biology也属于Medicine类目。本文主要聚焦医学领域科学数据仓储,因此保留Medicine分类下的全部数据仓储的同时也纳入了Biology三级类目Basic Biological and Medical下的数据仓储。由此,共获得871个医学科学数据仓储,去重后最终得到637个数据仓储的注册数据用于本文研究。
2 结果与分析
2.1 医学数据仓储分布
2.1.1 时间分布
医学科学数据仓储创建时间在1905-2017年之间(图1),如图1所示,收录医学科学数据仓储建设的几个高峰是在1992年、2000年、2003年、2006年、2008年和2011年。

图1 医学数据仓储创建时间分布
1982-1984年间,欧洲分子生物学实验室-DNA(The European Molecular Biology Laboratory-DNA,EMBL-DNA)、GeneBank、日本DNA数据库(DNA Data Bank of Japan,DDBJ)先后建立,共同组成全球性的国际DNA数据库,每天实时进行数据和信息交换。同时建立了在线人类孟德尔遗传数据库(Online Mendelian Inheritance in Man,OMIM)、Database of Sequence Tagged Sites等数据仓储。
1990年人类基因组计划启动。1996年,百慕大原则(Bermuda Principles)发布,要求将达到一定规模的基因组序列整合提交到特定公共数据库,进一步促进了基因组数据仓储建设。在这一阶段,Nucleic Acid Database(NDB)、UniProtKB/Swiss-Prot、癌症基因组解剖数据项目仓储等相继建立。
2000-2007年,以高通量为特点的第二代测序技术快速发展。2000年,Ensembl计划建立了Bacteria、Fungi、Genomes等系列数据库,推动基因组自动注释,并将注释与其他有用的生物数据整合和共享;2002年建立了UniProtKB、Wellcome Images和European Variation Archive;2003年,柏林会议发布《关于自然科学与人文科学知识的开放存取柏林宣言》;2006年,经济合作与发展组织(Organization for Economic Co-operation and Development,OECD)颁布《关于公共资金资助的研究数据获取的原则与指南》,极大地促进了数据开放获取,各国和组织机构积极开展开放数据仓储的建设;NCBI建立了HomoloGene、Nucleotide、PopSet、Protein、Influenza Virus Resource和Protein Clusters系列数据库;美国国立癌症研究所(National Cancer Institute,NCI)和美国国立人类基因组研究所(National Human Genome Research Institute,NHGRI)联合启动了肿瘤基因组图谱(Cancer Genome Projects,TCGA),并建立了肿瘤基因组图谱数据门户(Cancer Genome Atlas Data Portal)。
2008-2011年,第三代测序技术在测序通量、时间和成本等方面都有了极大改善和提高。大量基因组项目如英国的“千人基因组计划”和欧洲的“创新药物计划”(二期)等陆续启动并建立了相应的千人基因组计划仓储和Open Phacts仓储等。2009年,《开放透明政府备忘录》《开放数据声明》《开放数据宪章》等重要文件的签署也推动了开放数据运动在全球范围内的兴起和迅速发展。各国政府机构、国际机构和非营利组织积极组织建设开放共享数据仓储,搭建了DRYAD、DATA.GOV.UK、NCBI Virus Variation、NCBI dbGaP和组学原始数据归档库(Genome Sequence Archive,GSA)等仓储,用于促进数据共享和利用。
2.1.2 国家分布
数据驱动科技创新发展已经成为世界共识,各国积极进行数据资源创造、规划和积累,促进数据仓储建设和大数据研究应用。医学科学数据仓储建设涉及全世界五大洲36个国家(图2)。
其中,美国在医学科学数据仓储建设方面实力雄厚,共参与了346个科学数据仓储的建设,所占比例超过50%,并且独立建设仓储数量达241个;英国参与建设数据仓储139个,位居第二(22%),独立建设仓储41个;德国参与建设数据仓储71个(11%),独立建设仓储45个;欧盟参与数据仓储建设58个(9.11%);中国虽然也积极开展数据仓储的建设工作,但建设成果在国际数据仓储库Re3data中注册的数量不多,共有参建仓储17个(含港、台地区)。

图2 Re3data各国家建设科学数据仓储数量比
医学科学数据仓储建设的多国合作网络如图3所示。其中,每个国家可能有多个机构参与同一仓储建设。本文中每个国家在合作仓储建设中只计算了1次。美国、英国和国际组织在多方合作仓储建设方面表现最为突出,而美国、英国和欧盟则构筑了数据仓储建设合作的核心三角,合作密切,共同建立了Ensembl的系列仓储。这三者之间,英国与欧盟、美国与英国之间的合作更为紧密,英、美两国共同参与建设了如GenBank、1000 Genomes和WormBase等多个仓储。国际组织和美国、德国与欧盟、瑞士和英国也有密切合作。
亚洲国家中,中国、日本和韩国与国际组织、欧盟及美国有部分合作。欧洲国家在医学科学数据仓储建设中参与度最高,参与数据仓储建设的国家达20个,占欧洲国家数量的43%。美洲国家在医学数据管理和共享仓储研究和建设上的实力和优势最强,虽然只有3个,但美国和加拿大在数据仓储合作建设和独立建设的数量和应用方面均处于引领地位。其他洲的国家参与情况是,亚洲国家7个,非洲国家3个,大洋洲国家2个。
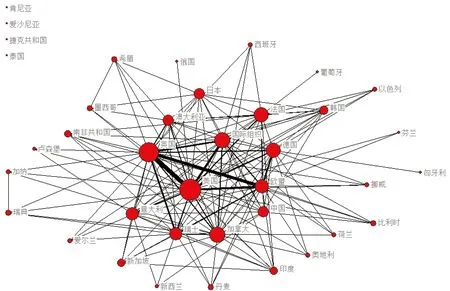
图3 各国医学科学数据仓储建设合作网络
2.1.3 机构分布
参与医学科学数据仓储建设的机构,主要以非营利性机构为主,也包括部分营利性机构。非营利性机构包括政府机构、公益性团体组织(基金、协会)、教育机构(大学、研究所、图书馆、出版社等),营利性机构主要是公司企业。各国均有不同类型机构参与到医学领域科学数据仓储建设,其中美国参与建设的机构居首位(有300余家),英国其次(有100余家)。各国主要机构和其建设的代表性仓储如表1所示。
各国均对医学科学数据仓储建设支持力度较大(图4)。从政府机构的多方、多种形式的参与程度可以看出各国对科学数据资源汇聚和利用的重视程度。以美国为例,美国卫生和人类服务部、美国农业部和美国能源部均参与其中,尤其是美国卫生和人类服务部下属的国立卫生研究院、国家生物技术信息中心等15个机构参与仓储建设。由图4可以看出,在各机构合作中,美国的政府机构、研究所和基金会占据合作核心位置,广泛组织和参与仓储建设合作。其中,美国国家卫生研究院最为突出,除了与医学研究委员会、国家综合医学研究所、国家科学基金会、比尔和梅琳达·盖茨基金会等美国国内机构紧密合作外,也与欧洲生物信息学研究所、英国威康信托基金会、英国生物技术和生物科学研究委员会、瑞士生物信息学研究所和加拿大卫生研究院等密切合作。

表1 各国主要参与医学数据仓储建设的机构
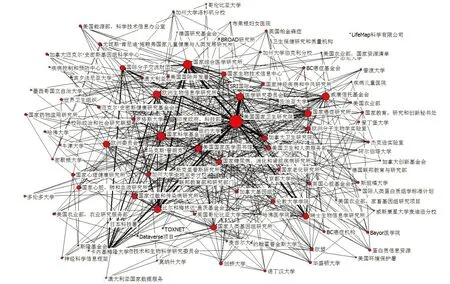
图4 各国参与医学数据仓储建设的机构合作情况
2.2 资源内容
2.2.1 类型和规模
Re3data根据parse.insight调查结果将各仓储中收录的数据类型归纳为15类,其中457个数据仓储记录了收录数据内容类型信息[9]。本文对收录各数据类型的仓储数量进行统计(表2)。

表2 收录不同数据类型的仓储占比
医学领域数据仓储中,收录科学和统计数据的最多,达325个(占51%);收录标准办公文档、纯文本、原始数据和结构化图形、图像数据的超过30%;收录2种以上类型数据的超过64%。其中,大多仓储(57%)都收录了3~6种数据类型,如European Genome-phenome Archive、dbGaP和PhysioBank等;有仓储收录数据类型多达十二、三种,如Canadensys repository、Open Phacts、heiDATA等。 Re3data也记录了部分数据仓储的数据规模,但由于收录数据类型和格式丰富,描述方式不统一,难以统计。仓储收录数据规模的描述,有的以记录条数记录,如UniProtKB包括547 964条手工注释和审核的记录和92 124 243条自动注释和没有审核的记录;有的以研究个数记录,如ClinicalTrials.gov包括237 639个研究;有的以收录内容数量记录,如GenBank包括228 719 437 638个碱基和199 341 377个序列;有的按图片个数记录,如Wellcome Images,包括超过40 000张图片。虽然对仓储规模、收录数据的描述方式和统计数量不是实时更新,但对帮助用户发现和了解所需数据仓储收录内容有一定的参考作用。
2.2.2 内容和质控
Re3data提供了对医学科学数据仓储的关键词和描述摘要。为了更全面地揭示仓储收录内容,本文通过对关键词和从描述摘要中提取的词进行处理和词频统计,绘制了词汇立方云图进行对比(图5)。
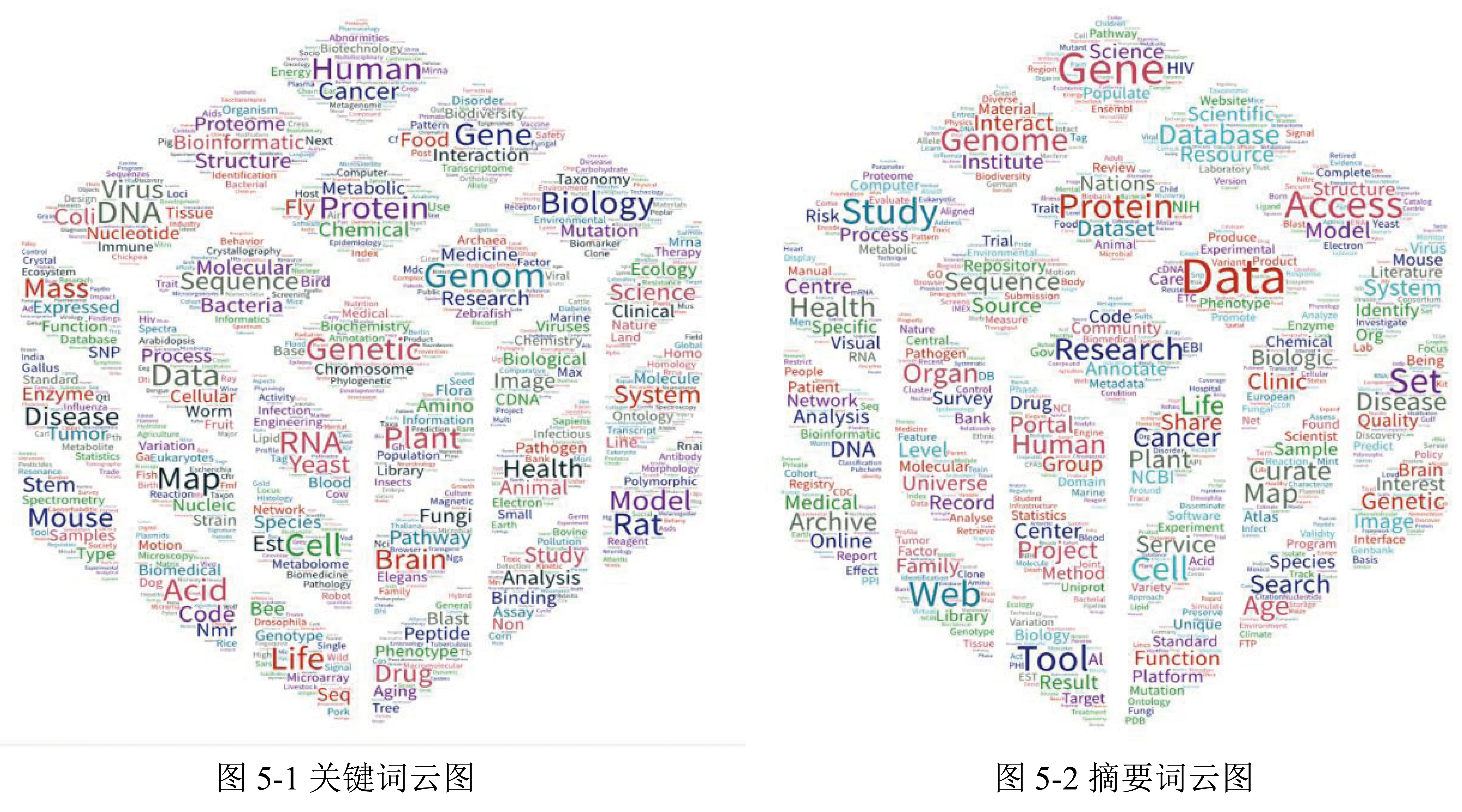
图5 数据仓储收录内容的关键词和摘要词云图
图5-1为关键词云图,图5-2为摘要词云图,图中词的大小表示词频强度,每个立方云图以3面27个方块展示排序结果。关键词云图可以看出医学数据仓储的收录内容,包括蛋白、基因、疾病、细胞、药物、序列等数据,来源对象有小鼠、人类、植物、果蝇、酵母和其他物种,对数据内容描述得较为细致;摘要词云图来自对仓储较为全面的描述,除了揭示收录的数据内容以外,还揭示了数据相关来源或应用是来自或用于研究、实验、调查、项目等。仓储收录的数据类型包括图像、报告、文献、图谱、标准等,仓储建设方式有平台、网站、数据库、工具、在线门户等,仓储或数据的处理和管理环节包括标识、注册、提交、处理、注释、访问、检索、分析、可视化、审编、发现、共享和服务等。数据评估包括评议、效果、质量等。
Re3data没有详细记录各仓储数据质量控制的具体标准和流程,但记录了是否提供了数据质控功能。其中,64.36%的医学数据仓储重视收录数据质量,提供质控功能,33.59%未知是否提供质控,2.05%未提供质控。
2.3 建设模式
2.3.1 平台技术
在Re3data中,标明底层支撑技术的仓储数量不多,仅有181个。其中,38个仓储建设使用MySQL数据库进行数据存储和管理,其他数据仓储则使用商业软件或开源软件进行本地化建设。仓储建设使用了7种软件,包括DSpace、CKAN、Dataverse、Fedora和Eprints等开源软件、非开源软件Digital Commons和商业软件Nesstar。DSpace、Eprint、Fedora和Digital Commons在机构知识库建设中应用广泛,常被用于包括文献、数据等在内的机构知识成果管理、发布、学术工作和影响力展示,注册的仓储中,有10个仓储使用其建设,如DRYAD、WormBase使用了DSpace。Fedora因其功能全面性也被用于电子资源(包括数据资源)的长期保存,Columbia University Academic Commons 等4个仓储是基于其建设的。CKAN目前广泛被作为开放政府数据平台的底层支撑,用于数据发布、查找和利用,有9个仓储是基于其建设的,影响力较大的有英国的Data.gov.uk、澳大利亚的Data.gov.au。Dataverse是由哈佛大学开发维护的用于共享、保存、引用、探索和研究分析的数据仓储软件,使用Dataverse的医学数据仓储有9个。除此之外,5个仓储是使用Nesstar建设的,主要用于处理调查数据、统计数据、多维表和文本资源。
2.3.2 标准规范
2.3.2.1 唯一标识符
Re3data收录的医学数据仓储主要使用5种通用唯一标识符用于数据资源检索、管理和定位,包括国际数字对象标识符基金会(International DOI Foundation,IDF)管理的数字对象标识符(Digital Object Identifier,DOI)、美国国家研究创新机构(Corporationfor National Research Initiatives,CNRI)设计的句柄(Handles,HDL)、美国国家研究创新机构(Corporationfor National Research Initiatives,CNRI)提出的永久唯一资源定位符(Persistent Uniform Resource Locator,PURL)、美国国家医学图书馆设计的档案资源主键(Archival Resource Key,ARK)和国际电信联盟提出的唯一资源名称(Uniform Resource Name,URN)。
其中,DOI是应用最广泛的唯一标识符,有97个仓储使用;其次是HDL,有16个数据仓储使用;PURL、ARK和URN分别有7个、5个和4个仓储使用。其他仓储未明确标注所使用的标识符或是否使用自定义标识符。
2.3.2.2 元数据标准
Re3data收集的标注了使用元数据标准的医学领域数据仓储仅有106个,提及的元数据标准有16个,它们多为国际标准、国家标准和项目标准,在数据仓储中数据的检索、定位、管理、互操作和共享等方面发挥重要作用。其中通用标准有6个、生物领域数据标准6个、地理领域数据标准2个和气象领域数据标准2个。仓储中应用较多的不是医学领域的元数据标准,而是通用元数据标准,包括DDI(Data Documentation Initiative)、DC(Dublin Core)和DataCite元数据标准;其次是生物医学领域的元数据标准DwC(Darwin Core)、ISA-Tab(Investigation Study Assay Tabular)和MIBBI(Minimum Information for Biological and Biomedical Investigations)、Genome Metadata。
此外,随着数据语义化的发展,医学数据语义化标准RDF Data Cub也开始应用于仓储数据资源描述框架(Resource Description Framework,RDF)格式描述存储和下载,如UniProtKB的所有的文件都支持RDF格式下载。医学领域数据仓储使用的16个元数据标准如表3所示。

表3 医学领域数据仓储使用的16个元数据标准
2.4 服务模式
2.4.1 数据访问
数据访问和使用是医学科学数据共享仓储建设的重要目标。Re3data提供注册仓储和数据2个层次的访问级别和条件信息。
Re3data将数据仓储层面的访问级别划分为开放、限制、关闭3类,开放是指用户可以无障碍访问数据仓储,限制是指外部用户能够通过满足一定条件访问数据仓储,关闭是指外部用户无法访问数据仓储,访问限制指需通过成为数据仓储机构成员、系统注册用户或付费等方式方可获得仓储访问的许可。目前,支持对外开放访问的数据仓储有598个(80%),限制访问的有34个,关闭的有5个。
仓储层面访问开放并不意味着数据层面也对外开放。各仓储根据数据的重要性及使用范围设置多种访问级别,保障数据所有者、管理者和使用者的权益。本文中各仓储数据层面的访问级别分为开放、限制、关闭和禁止4种。禁止是指数据集开放或受限访问,发布数据之前用户无法访问。如CancerData.org、ArrayExpress和PharmGKB数据仓储访问都是开放的但在数据访问层面,CancerData.org包括开放、限制和关闭的数据,ArrayExpress包括开放、限制和禁止的数据,PharmGKB包括开放和限制的数据。各仓储数据层面的访问级别设置的多种情况见图6。
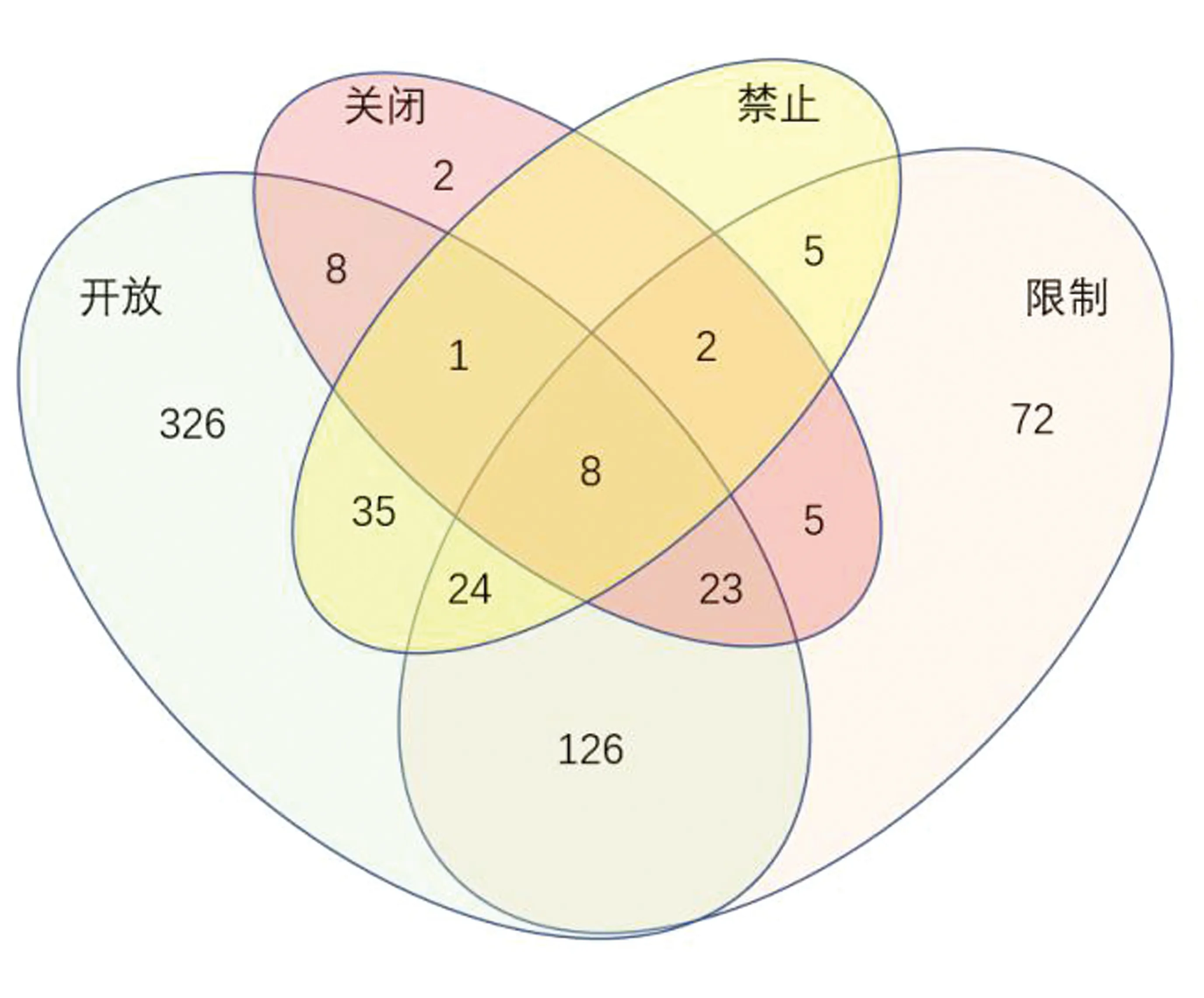
图6 仓储数据层面的访问级别
近50%的仓储数据访问是完全开放的,126个仓储既有开放数据也有限制性数据。限制的数据访问要满足一定条件,如用户需要注册、填写必要的数据使用说明或付费。
2.4.2 政策及许可
544个医学科学数据仓储通过制定和采取不同政策,保障其管理和运维。经归纳,25个仓储注册了4个及以上的政策,221个仓储注册了2个及以上的政策。政策类型主要包括数据发布政策、数据提交政策、数据使用政策、数据管理政策、数据许可政策、隐私政策、数据安全和质量政策、版权政策、标识符政策、数据共享政策。与政策相关的还有服务提供原则、数据转换许可、分类规则等。以注册最多政策的Edinburgh DataShare仓储为例,注册的政策包括提交政策、内容政策、服务政策、存储许可、数据和元数据政策和长期保存政策等7项数据政策。不同仓储应根据自身需要和特点制定政策。还有一些公用性政策,如NIH的公共访问政策、IMEx(International Machine Tools Expo)审编规则、TCGA 工具使用条款等也在多个仓储中使用。
除数据政策,医学数据仓储也提供必要的数据许可,保障其用户的权益和数据创作者及持有者的权益。Re3data中主要记录了数据仓储访问许可、数据上传许可和数据访问许可。
数据访问许可相对统一,现有仓储多应用公认的开放许可或开源软件的许可(表4)。
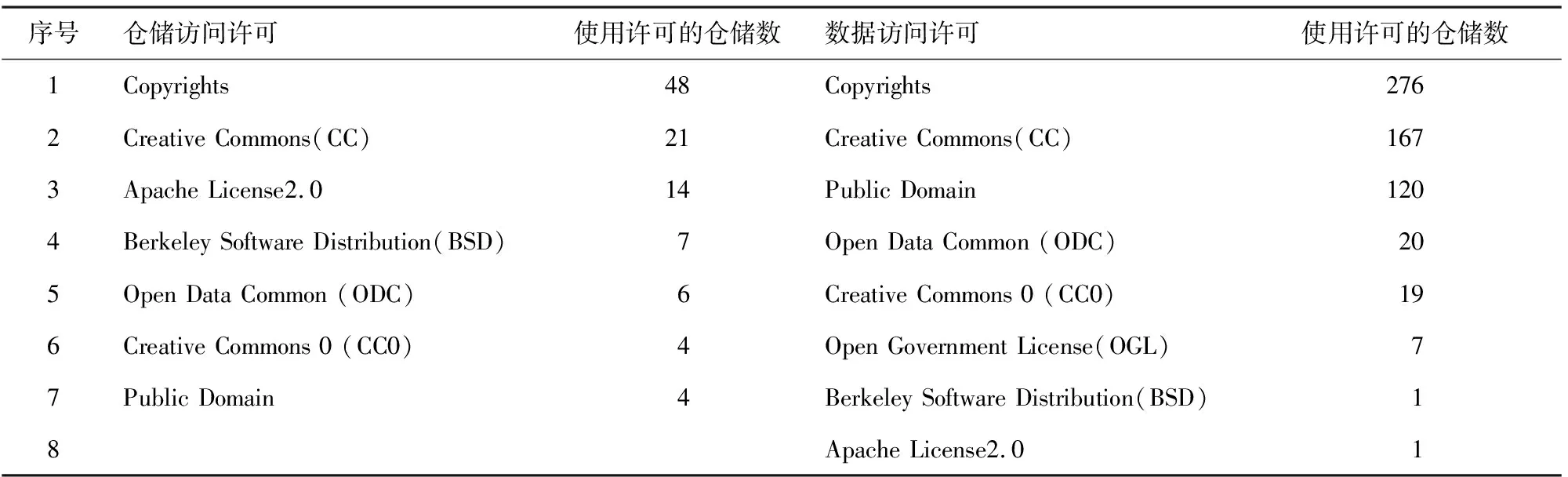
表4 仓储访问许可和数据访问许可的仓储数
数据访问许可有8类,应用最多的是Copyrights、Creative Commons(CC)、Public Domain。数据仓储访问的许可包括7类,应用最多的是Copyrights、CC和Apache License 2.0;数据上传许可因不同数据仓储的建设目标、应用范围不同,在数据内容、格式、数据量、上传途径等方面有较大差别,比较分散,共有143个,包括各仓储数据提交的方法、工具指南、注意条款、许可协议等,如IMEx数据提交指南(IMEx data submission)、TCAG工具使用条款(TCAG Facilities Terms and Conditions)、GenBank流感病毒序列提交指南(Submitting Influenza Virus Sequences to GenBank)等。其中也包括CC0、CC、Apache License 2.0、OGL和Public Domain等通用许可。
2.4.3 数据接口
除了数据的在线浏览和下载外,通过API接口提供计算机数据访问也是很多数据仓储提供数据应用的重要途径。本文中共有292个医学数据仓储提供了数据交互接口信息,其中有8种数据接口方式:文件传输协议(File Transfer Protocol,FTP)、表述性状态传递(Representational State Transfer,REST)、简单对象访问协议(Simple Object Access Protocol,SOAP)、元数据收割协议(Open Archives Initiative Protocol for Metadata Harvesting,OAI-PMH)、SPARQL(SPARQL Protocol and RDF Query Language)、网络通用数据格式(Network Common Data Form,NetCDF)、SWORD和OpenDAP。不同数据接口方式在数据传输性能、数据体量及安全性等方面有一定差别。其中,32%的仓储提供基于FTP的数据交互方式,该方式适于传输大规模数据,数据传输过程安全性较高,但传输需约定数据格式;24%的仓储提供基于REST方式,其数据传输效率高且简单易用,适于对安全要求不高的应用,NCBI和EBI构建的很多仓储都采用了这两种数据交互接口方式,还有部分采用了SOAP方式,用于在分布式环境中交换轻量级的数据信息。提供元数据收割和下载的仓储通常提供OAI-PMH的接口方式。
SWORD主要被用在Dataverse软件支持的仓储中用于数据交互,是针对存储库的轻量级数据传输协议。而开展RDF数据建设的仓储,如BioPortal,支持SPRQL数据查询。不少仓储提供多种接口方式,有11个仓储提供3种接口方式进行数据调用,有50个仓储提供2种不同的接口方式供用户根据自己的需求选择使用。
3 讨论
通过对Re3data收录医学领域科学数据仓储的系统分析,希望能通过多维分析视角,归纳总结全球范围医学科学数据仓储建设和发展的特点和经验。
3.1 欧美国家占据数据仓储建设的高地
无论是在国际层面还是国家层面,医学科学数据仓储建设均受到高度重视,各国积极发布国家级数据政策及战略,并且相继启动开放数据研究计划促进开展数据仓储建设实践,致力于破除“数据孤岛”,推进科学数据资源汇聚和共享,推动数据驱动的科技创新,提升科技竞争能力。其中,欧美发达国家持续推动数据仓储发展和建设,处于领跑地位。英国和德国在自建仓储数量方面仅次于美国,加拿大、瑞士等国积极参与数据仓储合作建设。相比美洲和欧洲国家而言,亚洲国家在全球科研仓储中注册的仓储数量不多,在国际合作的仓储建设中参与能力和可见度还有待提升。
3.2 多方合作共促数据开放共享
学科和机构类型数据仓储是医学科学数据仓储建设的主要类型,开展仓储建设的机构以非营利性机构为主,包括大量政府机构、公益组织和高校研究团体,进行仓储功能建设、技术支撑、制度建立、标准制定、运行维护和宣传推广。
在科学数据仓储建设中,多家机构打破国家、地域、区域、机构限制和突破技术、资源等瓶颈形成跨国家、跨区域、跨机构的合作,不仅扩大了医学科学数据资源来源,也扩展和提高了数据流动、共享的空间和效率。
3.3 开源技术降低仓储搭建门槛
基础平台和关键技术是支撑医学科学数据仓储发展的重要基石,但从Re3data的注册填报数据对其收录的数据仓储的基础支撑技术的揭示并不完整,明确填写了底层技术的仓储数量不多。现有数据显示,较多采用自建开发方式建立,也有不少利用成熟开源软件进行科学数据仓储的建设。应用的开源软件均具有一定的版本更新和技术升级能力,在资源内容管理方面具有相对广泛的应用。开源软件结合本地化改造可以节约技术开发成本,加快和促进数据共享与开放的进程,在一定程度上降低医学科学数据仓储建设的技术难度。
3.4 标准规范建设保障仓储运管
在医学数据仓储运行管理过程中,唯一标识和元数据标准被用于资源识别和定位,规范数据管理流程和用于统一检索与数据交换。本文中医学数据仓储使用的唯一标识符除主要是仓储自定义的唯一标识外,多使用DOI、HDL等通用标识提高数据的可管理性和互操作性。在元数据标准方面,应用到的元数据标准具有一定共性,涉及多类国际或国家级标准,不仅涵盖通用标准,还包括多种特定领域的元数据标准。此外,一些数据仓储开展底层数据语义化建设,使用了W3C推荐的两种语义数据标准,规范数据建设和管理流程。
3.5 数据分级共享提供接口支持
由于医学科学数据仓储存储的数据类型多样,可用性、隐私性、价值程度不一,数据仓储通过设置多种数据访问级别和访问限制条件控制用户访问,包括开放、限制、关闭、禁止等多种级别保护数据创建者、管理者和使用者的权益。此外,医学科学数据服务中,如序列、影像等数据体量较大,数据交互多采用FTP、REST接口支持数据传输和调用。现有数据仓储提供不止一种调用方式满足机器调用和读取,有助于数据的共享和利用。
3.6 采用政策许可保障多方权益
医学数据仓储建设机构和仓储制定数据相关政策和指南引导用户进行医学数据提交、管理和存储。政策内容涉及数据提交、数据存储、数据共享、数据使用等多个环节。从收集的数据来看,各仓储制定或使用的数据政策和指南偏个性化,主要根据各仓储存储数据特点和流程,通用的政策或指南不多。在数据使用许可方面,通用的许可类型较集中为CC0、CC、Copyrights等。通过数据许可可以指导用户结合需求有效使用仓储数据和了解数据使用中可能遇到的知识产权和隐私问题。
4 结语
本文仍存在一些不足,如在处理仓储所属机构数据时,由于数据采用不同语言填写,在数据处理时,对德语的翻译不是非常准确。在处理医学科学数据仓储建设机构名称归一时,由于涉及各国机构较多,仅按名称进行了归并,未对机构层级进行关联归并处理,因此在各国机构数量统计时仅统计到百位和十位的数字。下一步将结合分析结果和经验总结,优化和完善仓储建设和功能。
猜你喜欢
传染病信息(2022年2期)2022-07-15
华北电力大学学报(社会科学版)(2022年3期)2022-06-25
华北电力大学学报(社会科学版)(2022年1期)2022-03-04
华北电力大学学报(社会科学版)(2021年1期)2021-03-01
动漫星空(兴趣百科)(2020年12期)2020-12-12
民族高等教育研究(2020年3期)2020-09-14
祝您健康(2020年4期)2020-05-20
股市动态分析(2016年23期)2016-12-27
股市动态分析(2016年7期)2016-09-29
股市动态分析(2016年4期)2016-09-29
