
基于电子病历的胃癌治疗方案辅助选择
2018-03-21 00:26:48,,
中华医学图书情报杂志 2018年2期
,,
临床决策支持系统的构建离不开知识库,而病历的电子化为临床知识库的构建带来了便利,研究人员可以通过计算机程序处理大量病历中的文本,以实现重要知识的挖掘。病历是医疗业务活动的详细记录,其中隐含着价值巨大的知识。将从病历中提取的信息用于临床决策支持,是近年医疗大数据的研究热点之一。
在临床决策支持方面,国外已有较为成熟的研究。关于决策支持系统对临床治疗作用的研究,Porat, Talya等人[1]研究了全科医生和患者对诊断决策支持系统和咨询影响的看法;Arts,Derk L.等人[2]研究了决策支持系统在实践中预防改善卒中的有效性;针对从病历中提取知识的研究,Nilashi M等人[3]提出了一种基于知识的乳腺癌分类系统;Kung,Robert等人[4]提出了一种从电子病历中识别肝硬化患者身份的自然语言处理算法。在国内,医护人员在撰写病历时存在用语不规范的现象,这就为从病历中提取有用信息带来了一定困难;加之国内医疗信息化起步较晚,即使电子病历系统已实现部分内容结构化,但获取病历中有用知识的难点仍然存在。基于此,国内学者也开展了一些探索性的研究,在病历文本的自然语言处理领域提出了不同的解决方案,推动着国内医疗信息化的不断前进。如栗伟[5]研究了电子病历文本挖掘关键算法,徐益辉[6]研究了中文医疗文本匿名化方法,李国垒等人[7]针对病历信息通过潜在语义分析构建了决策模型,林枫[8]研究了云计算技术在医疗大数据挖掘平台设计中的应用。
本文拟在借鉴中文病历文本处理研究成果的基础上,针对胃癌通过病历文本中的词进行聚类,探索词或词组与治疗方案之间潜在的关系,建立1种决策支持模型。即首先对病历文本进行分词,再根据切分词与病历中抽取的治疗方案的共现频次,对切分词进行聚类,并统计每份病历文本在各聚类中匹配到的词数;基于各类的匹配词数与治疗方案共现情况,探索性地采用Bayes判别思路建立起判别函数用以辅助决策。
1 数据与方法
1.1 数据来源
本文选取了2500份中南大学附属三甲医院2010-2014年已被确诊为胃癌的电子病历(入院病情摘要、诊治过程),将其随机分为两组:1 500份为训练组,用于构建决策支持模型;1 000份为测试组,用于评价决策支持模型。
1.2 病历文本分词
已有研究结果显示,词典结合统计的分词方法是进行领域分词的有效方法[9]。据此,本文采用如下分词策略(图1)。
年龄是影响治疗方案选择的重要因素,但作为连续指标切分后无意义。依据世界卫生组织对年龄分段的划分标准[10],本文将入院病情摘要中的患者年龄进行对应转换,得到原始文本(图2)。
笔者于2015年4月在中国生物医学文献数据库中以分类号=R735.2(即胃肿瘤)进行检索,时间限定为2001-2003年,导出关键词和主题词,归并作为词典1,共包含5 429个词语。
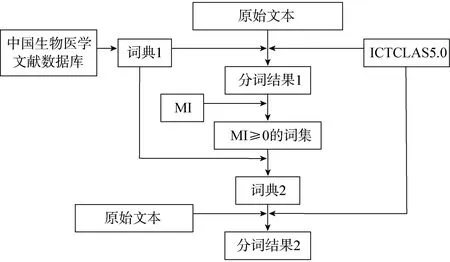
图1 分词策略

图2 病历原始文本示例
利用词典1进行分词并基于分词结果(图3),使用互信息值(MI)计算方法,计算分词碎片中相邻字词的MI值。根据MI≥0,即两个字词具有正相关关系,筛选出11 845个词语。将11 845个词对与词典1中的5 429个词合并去重,构成17 113个词的新词典—词典2,并利用词典2对原始文本再次进行分词。

图3 分词结果
从分词结果发现,经词典2分词后的结果能切分出更多术语,如“蠕动波”“静脉曲张”“无反跳痛”等都被有效切分,但由于不同病历中的检测指标单位描述不同,因此在检测指标上切分效果不好,如血压值基本被切分成“高压值”“/”“低压值mmHg”3个词。该实验也说明,在带数字的检测指标上,本方法不能实现有效切分。此外,受词典中词语的限制,也有错误切分。如“退指指套无血染”应被切分为“退指”“指套”“无血染”3个词,而实验切分则是“退指指”“套”“无血染”3个词。
1.3 辅助决策模型构建
本文建模方法选择Bayes判别分析。Bayes判别的准则是使本应属于某一类的样品,经过规则的判别后在应属类中取得最大的值或后验概率,从而使得该样品被判别为所属类的原则。
1.3.1 切分词处理
分词结果中包含许多不具有实际意义的碎片。在建模前对分词碎片进行处理,具体步骤如下:删除超高频词部分的数字、标点及特殊符号;删除不具备实际含义的单字词,如“鸣”“查”等;低频词使用少且占据了分词结果一半以上,结合分词结果,删除了词频小于11的词。
切分词经处理后,共保留1 207个词。其中大多为两字词,也有3字及3字以上的词。
1.3.2 抽取治疗方案
病历中的诊治过程详细记录了患者住院期间的诊疗经过,包含患者的临床症状的描述、检查检验结果及治疗过程。参考《2013胃癌规范化治疗指南》[11],本文将治疗方案确定为手术治疗、手术治疗+放化疗、放化疗及对症治疗4种。根据出院记录,确定如下治疗方案抽取判定原则[12]。
若文本中出现“手术”相关字样(全麻、根治术、切除、切除术等)且不出现“放疗”“化疗”字样,判定该治疗方案为手术治疗;若既出现“手术”相关字样,也出现“放疗”“化疗”相关字样,判定该治疗方案为手术治疗+放化疗;若仅出现“放疗”“化疗”相关字样,不出现“手术”相关字样,判定治疗方案为放化疗;若既不出现“手术”相关字样,也不出现“放疗”“化疗”相关字样,判定治疗方案为对症治疗。
根据如上判定原则,从训练组病历中抽取治疗方案,其中手术治疗有794例,手术治疗+放化疗的有227例,放化疗的有225例,对症治疗的有254例。随机抽取100份进行人工比对,治疗方案抽取准确率为97%。
1.3.3 构建共现矩阵
统计训练组所有病历中1207个切分词在与每种治疗方案共现的频次,生成切分词与治疗方案共现频次表(表1)。
1.3.4 切分词聚类
采用SPSS 19.0软件,选择类平均法,并采用平方欧式距离进行聚类。本文结合后续模型构建的需要,分别选取3、4、5类建立模型。表2展示了聚类为4类时,各词的所属类别。
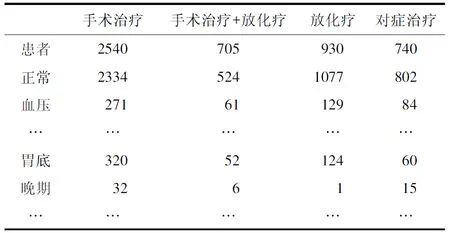
表1 切分词与治疗方案共现频次统计(部分)

表2 聚类结果
1.3.5 建立Bayes判别模型
确定自变量。将判别指标按聚类结果别进行设定,即类1聚类结果为X1,类2、类3、类4分别设为X2、X3、X4。
确定因变量。以Y表示抽取的治疗方案,将手术治疗、手术治疗+放化疗、放化疗、对症治疗4种治疗方案对应赋值1,2,3,4。
统计病历中的匹配词数。将1500份训练组病历文本与4个类中的切分词进行匹配并统计。若某条病历文本能与X1类中的10个词匹配,则计数10次;文本中多次出现同一个词,则只统记1次。表3展示了以聚类为4类为例,1500份训练组病历文本在4个类中切分词匹配数及所属治疗方案分类。
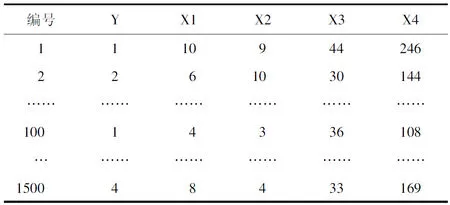
表3 训练组病历文本中匹配词数与治疗方案共现
依据表3中的数据,采用SPSS 19.0计算得出判别方程中的各项系数,所得Bayes判别模型如下:
Y1=-7.868-0.062*X1-0.257*X2+0.394*X3+0.001*X4
Y2=-6.338-0.059*X1-0.312*X2+0.347*X3+0.001*X4
Y3=5.026+0.198*X1-0.347*X2+0.193*X3+0.013*X4
Y4=-6.050+0.251*X1-0.324*X2+0.213*X3+0.013*X4
同时,本文也分别得出了以聚类为3类和5类分别建立的判别模型。
Y1=-7.027-0.12*X1+0.383*X2+0.001*X3
Y2=-6.763-0.135*X1-0.333*X2+0.003*X3
Y3=-5.180+0.035*X1+0.162*X2+0.16*X3
Y4=-6.042+0.079*X1+0.18*X2+0.017*X3
Y1=-7.893-0.030*X1-0.556*X2+0.334*X3+0.132*X4-0.035*X5
Y2=-7.842-0.025*X1-0.634*X2+0.283*X3+0.143*X4-0.036*X5
Y3=-6.063+0.223*X1-0.581*X2+0.146*X3+0.115*X4-0.014*X5
Y4=-6.728+0.269*X1-0.497*X2+0.178*X3+0.089*X4-0.007*X5
2 结果与分析
2.1 分词结果
本文采用了词典分词与统计分词相结合的方法对病历文本进行分词,分词结果主要通过分词准确性及速度2个指标进行评价。本文主要关注分词方法的准确性,未考虑分词速度这一测评指标。因此,在评价过程中,采用召回率、准确率以及综合指标F-1值对分词效果测评[12]。
随机抽取50条记录,删除标点等特殊字符。对抽取的记录进行人工分词,统计每份出院记录切分好的词语总数。利用本文中采用的分词方法进行分词,统计分词结果,并计算切分出的总词数和切分出的正确词数(即人工分词后的词汇在机器分词结果中出现的词汇总数),计算每份记录切分后的准确率、召回率和综合指标F-1值,并以50条记录计算的平均值作为测评结果。
经验证,将词典结合统计分词方法用于病历文本分词的召回率为74.24%,准确率为82.30%,F-1值为78.06%。
2.2 决策模型验证结果
采用测试组的1000份病历数据对建立的3个模型进行验证,其中聚为3类时建立的决策模型判别准确率为48.4%,聚为4类时建立的决策模型判别准确率为51.3%,聚为5类时建立的决策模型判别准确率为60.2%。
结合病历文本对所构建的模型进行分析,发现只要病历中出现“高龄患者”的病历,构建的判别模型手术治疗一类的函数值均不是最高,这也与病历中手术风险过高的描述吻合。若病历中出现了“癌转移”“广泛转移”“淋巴结转移”等词,判别模型对应的放化疗函数值大多为最高值,但这种情况仅限多数病历。该判别模型所判别的治疗方案为“放化疗”与“对症治疗”两种方案的判别值相近,这与原病历中治疗方案为“放化疗”的患者同时也进行“补液”等对症治疗方案有关,即“放化疗”通常都与“对症治疗”同时出现,故本文所建模型也与病历中的情况相符。
此外,通过研究发现“高龄患者”“癌转移”“广泛转移”等词均属于聚类结果中个性化用词的一类,而这类词对个性化治疗方案的选择是有影响的,且对于病历中同时出现“放化疗”和“对症治疗”两种治疗方案,判别模型也能反映出该特征,表明本文构建的判别模型针对年龄及是否存在癌转移两种因素是有一定区分度的,且经模型选择的治疗方案与病历中治疗方案的情况基本相符。
3 讨论与结论
本文基于电子病历中切分词与治疗方案的共现频率,通过文本分词、聚类分析及Bayes判别分析建立起了针对胃癌的辅助决策模型。在研究过程中,发现词典结合统计的分词方法用于电子病历文本有较好效果,这也验证了张梅山[9]提出的领域文本分词方法。通过对切分词的聚类,也发现部分词或词组与治疗方案之间也存在一定关联,如高频词“患者”“正常”“未见”都被聚类为一类,说明无论治疗方案如何,这3个词通常会同时出现;而“触及、明显”2个词被聚为一类,发现多数病历中均表述了“触及明显肿块(肿物、包块)”的表述,表明聚类分析用于挖掘病历中的潜在知识是有价值的。
对于辅助决策模型的准确率不高(60.2%),后续研究可以在两方面进行改进。首先是检查数据的利用,切分词后的检查数据为纯数字,已经失去了意义,但它对于治疗方案的选择是有参考价值的;其次是切分词的处理,对于切分词碎片的取舍也值得进一步研究。综上所述,电子病历的决策支持价值得以体现,所建模型对于胃癌治疗方案的选择有一定的参考价值,但模型是否适用于其他疾病还需进一步实验,以期提高模型的判别精度,从而更好地实现辅助决策的效果。
猜你喜欢
趣味(语文)(2021年9期)2022-01-18 05:52:42
数学小灵通·3-4年级(2020年9期)2020-10-27 03:26:16
文苑(2019年24期)2020-01-06 12:06:50
智富时代(2019年6期)2019-07-24 10:33:16
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
高中生·天天向上(2016年9期)2016-11-22 09:10:34
中国卫生(2016年10期)2016-11-13 01:07:44
中国卫生(2015年10期)2015-11-10 03:14:32
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
