
国外医药类学科知识库联盟构建经验与启示
2018-03-21 01:34:00,
中华医学图书情报杂志 2018年2期
,
学科知识库(“Subject Knowledge Repository”或“Disciplinary Knowledge Repository”)是基于学科的开放存取仓储,是对某一学科或几个学科的各类资源进行收集、保存并通过互联网实现开放存取的知识库[1]。学科知识库联盟是由同学科或几个学科的多个成员机构构成,根据成员机构的自身特点选取适合的联盟模式,组成专业性强且内容丰富的集成性学科知识库。国外医药类学科知识库联盟的构建已日臻成熟。2009年美国总统奥巴马签署的《2009综合拨款法案》确立了PubMed Central(PMC)的强制公共存取政策永久生效,从而确保了PMC收录论文的数量与质量。加拿大Multiple sclerosis (MS)协会要求凡是受到资助的项目,其同行评议的出版物都要在6个月内进行开放获取。此规定于2013年生效,MS协会鼓励在该日期前获资助的研究也遵守此规定。Open DOAR列出的健康与医学学科的机构知识库共338个,其中大多数知识库已运营超过10年[2]。
本文主要对10个国外医药类学科知识库联盟(以下简称“医药库联盟”)进行分析,归纳联盟运营模式与资金来源、存储与共享政策、技术支撑与资源建设、科研数据管理与学科服务、科研影响力等多方面的特征,总结其构建经验,以期为我国医药库联盟的构建提供参考。本文主要采用调查法和经验总结法,对10个国外医药库联盟进行有目的、有计划、有系统地搜集其现实状况与历史状况的材料,归纳分析其运营的实际情况,使之系统化、理论化,从而具有指导意义。
1 国外医药类学科知识库联盟构建实例分析
笔者以联盟运营时间、主要运营机构、成员机构规模几方面作为主要参考标准,选取的10个医药类学科知识库联盟为arXiv、PubMed Central(PMC)、Europe PubMed Central(EPMC)、bioRxiv、CancerData、Dryad、InterNano Nanomanufacturing Repository、Mathematics in Medicine Study Groups、National Science Digital Library、Nature Precedings。
这些联盟的运营时间基本都在5年以上,arXiv甚至超过了25年。其主要运营机构均为较大型的学术机构,如美国国家生物技术信息中心、美国冷泉港实验室(CSHL)、马萨诸塞大学阿默斯特分校分级制造中心、诺丁汉大学、Maastro Clinic的医学信息知识工程团队等,以确保联盟构建的各方面条件均有保障。联盟的主要机构成员都不低于10个,且均具备较高的学术能力,多为科研院所、实验室、研究小组、出版机构、各种协会与学会、大学学院、图书馆、大型企业等,如arXiv的220个成员机构来自全球约24个国家,bioRxiv约99个成员几乎都来自欧洲的Scientific Community,Dryad的20个主要成员包括美国科学促进协会、美国遗传协会、进化研究学会、系统生物学家学会、剑桥大学出版社等。
1.1 联盟运营模式与资金来源
运营模式与资金来源是构建医药库联盟的基石。从运营模式来看,arXiv由康奈尔大学图书馆负责其行政、财务和发展等,下设成员咨询委员会和科学咨询委员会处理相关事务;PubMed Central的运营机构是美国国家生物技术信息中心,还配备了成立于1999年的监督机构——PMC国家咨询委员会。其他联盟的管理模式基本上都是根据选举或其他原则成立顾问委员会负责联盟的运营,如Europe PubMed Central由科学顾问委员会与基金委员会进行管理并处理战略导向问题;bioRxiv由Cold Spring Harbor Laboratory管理运营,并由洛克菲勒大学、美国微生物学会、HighWire Press等17个机构的人员组成的顾问委员会协助管理;Dryad由其成员选举出12名代表组成董事会进行管理,负责数据共享政策协调,以促进Dryad长期可持续发展;InterNano Nanomanufacturing Repository由马萨诸塞大学阿默斯特分校科学与工程图书馆和成员机构选派代表组成13人的顾问委员会负责运营。由单独机构运营的有以下3个联盟:CancerData由Maastro Clinic的医学信息知识工程团队负责运营,Mathematics in Medicine Study Groups由英国数学医学研究组和加拿大数学医学研究组运营管理,Nature Precedings由英国自然出版集团运营。与其他机构合作运营的有National Science Digital Library,该联盟之前与康奈尔大学、哥伦比亚大学、大学大气研究联盟合作运营,现在单独与大学大气研究联盟合作。
资金来源上,arXiv由康奈尔大学图书馆提供37%的运营费用,Simons 基金每年至少提供约10万美元的资助,其他约220个成员机构需支付会员年费。年费分为4个层次,从1 000美元到4 400美元不等,所有会员机构每年提供的资金至少约30万美元,此外会员也可通过联盟协议获取付款折扣。其他联盟基本都由一个主要机构提供资金,几个合作伙伴配合进行协助,如PubMed Central主要由美国国立卫生研究院(National Institutes of Health,NIH)提供资金,Bill & Melinda Gates Foundation、Agency for Healthcare Research and Quality、Food and Drug Administration等11个机构或基金协助资助;Europe PubMed Central由以维康基金为代表的 Europe PMC Funders Group约28个研究基金提供资助;CancerData的主要资金来源是Maastro Clinic,荷兰癌症协会、荷兰大学医疗中心联盟、荷兰生物信息中心、荷兰科学中心等也有资助;Dryad构建最初的资金来源于美国国家科学基金会及其合作伙伴,Dryad在英国的镜像由大英图书馆负责,资金来源于大英图书馆、牛津大学、数字管理中心以及Charles Beagrie公司等;InterNano Nanomanufacturing Repository由美国国家科学基金会和马萨诸塞大学阿默斯特分校图书馆提供资金;Mathematics in Medicine Study Groups主要由工程与物理科学研究委员会、伦敦数学学会、牛津大学出版社提供资助;Nature Precedings由英国自然出版集团和大英图书馆、欧洲生物信息学研究所、科学共同体与维康基金合作资助。单独机构资助的只有bioRxiv和National Science Digital Library,bioRxiv由Cold Spring Harbor Laboratory提供资金,National Science Digital Library由美国国家自然基金提供资助。
从运营管理和资金来源看,目前医药库联盟有两大发展趋势,即“广而泛”或“专而深”。走“广而泛”道路的联盟,其发展策略着眼于全球,机构成员、资金来源都是全球性的。由于联盟庞大、事物繁多,其运营管理一般需要在主导机构的统筹规划下,设立多个委员会分工协作。为确保工作流程的精准高效,还设立了监督机构。该趋势最具代表性的联盟是arXiv和PubMed Central。走“专而深”道路的联盟,其发展更侧重于专业性、区域性,联盟规模偏小,其机构成员基本集中在某一地区或某一团体,由机构成员组成的一个委员会进行运营管理,也有单独机构或机构合作进行管理的,资金来源由单独机构资助或一个主要机构资助并由其他机构协助。该趋势代表性联盟有CancerData、Mathematics in Medicine Study Groups。
1.2 存储与共享政策
存储与共享政策(表1)是医药库联盟学科资源收集与利用的标准。
从表1看,存储政策基本包括提交方式、公开程度、版权政策、隐私要求、元数据要求及语种、格式等。这些联盟中绝大部分要求创作者或版权持有者提交文档或数据,不允许第三方个人/机构提交。arXiv还规定所有合著者必须都同意并提供提交人所在机构。InterNano Nanomanufacturing Repository虽允许作者以外的人提交,但若出现侵权行为,提交人将承担完全责任。公开程度方面完全公开的较多,有些联盟为能够在更大程度上吸引学科资源,会设置不同的公开协议,如PubMed Central设置了“完全参与”协议、“NIH资助参与”协议、“选择性存储”协议以满足不同成员的要求。几乎所有联盟都对版权政策和隐私要求进行了明确规定,且会根据自身特点有所侧重,如arXiv、bioXiv之类的预印本联盟更注重避免与出版商之间的版权纠纷,Europe PubMed Central、Mathematics in Medicine Study Groups则注重解决满足资助机构的OA要求时所引发的版权问题,CancerData着力于临床数据版权纠纷的解决,Dryad、InterNano Nanomanufacturing Repository通过严格的审查制度弥补版权政策的不足,National Science Digital Library和Nature Precedings在解决版权纠纷的同时也高度重视用户的隐私问题。为保证存储质量,各联盟也几乎都有明确细致的元数据要求,一般体现在对资源的准确性、完整性、学科性、权威性、资源类型、科研数据的标准化与结构化方面,甚至对提交环境的要求。对语言与格式的要求,除Dryad比较详细外,其他联盟均较为宽松。
10个联盟的共享政策几乎都采用知识共享署名许可证方式,主要涉及5个许可证:国际创作共用署名许可证、国际知识共享署名许可证4.0(CC BY 4.0)[3]、公共领域通用许可证(CC0 1.0)[4]、国际署名相同方式共享许可证(CC BY-SA 4.0)[5]、非本地化署名许可证3.0(CC BY 3.0)[6]。其中使用最多的是国际创作共用署名许可证,该许可证下包含国际创作共用署名-非商业许可证4.0(CC BY-NC 4.0)[7]、国际创作共用署名-没有衍生品许可证4.0 (CC BY-ND 4.0)[8]、国际创作共用署名-非商业没有衍生品许可证4.0(CC BY-NC-ND 4.0)[9]、国际创作共用署名-相同方式共享-非商业性授权许可证4.0(CC BY-NC-SA 4.0)[10]等次级许可。
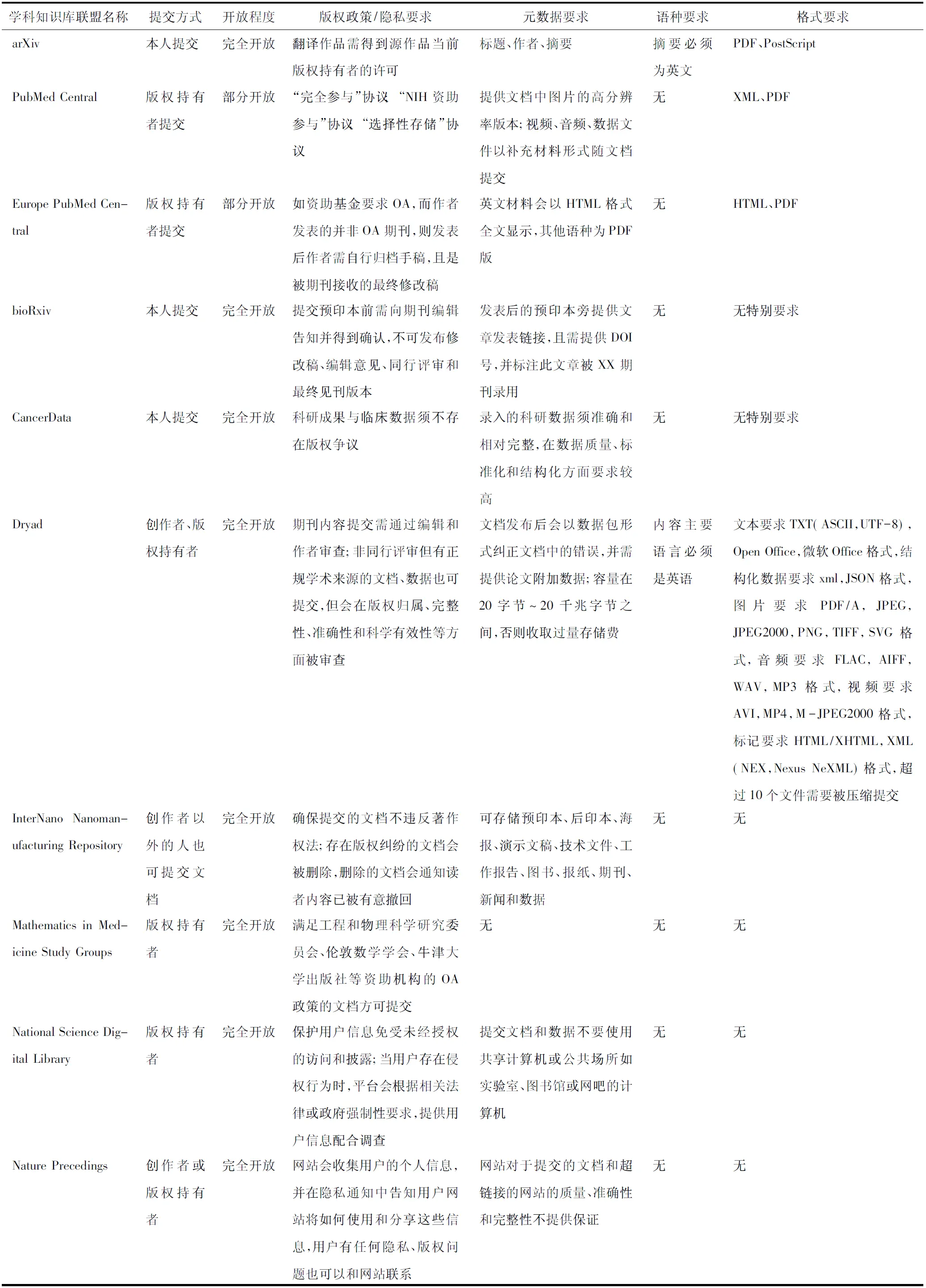
表1 医药类学科知识库联盟构建的存储政策
联盟通常会根据不同资源的开放要求及版权考量,采用适合的共享许可证。此外,PMC和EPMC禁止使用爬虫程序进行批量检索与下载,如需下载,可通过FTP站点支持或使用EPMC-OAI service、and RESTful and SOAP web services。
1.3 技术支撑与资源建设
技术支持与资源建设是构建医药库联盟的支撑。10个联盟平台构建所用的系统软件一般是EPrints、Fedora、Drupal、Custom、DSpace,辅助软件工具包括系统网关(如PubChem Power User Gateway)、搜索软件(如Basic Local Alignment Search Tool、SNP Database Specialized Search Tools)、文件格式转换软件(如DICOM图像转换、OAI-PMH2.0)、API、图像存储软件、数字对象标识软件(如DataCite)、发送接收软件(如Frequency-weighted Link),阅读软件包括Open Reading Frame Finder等。此外,arXiv利用Atlassian Confluence 5.10.8软件进行知识管理与协同,其强大的编辑和站点管理特征能够帮助团队成员之间共享信息、文档协作、集体讨论和信息推送。
开源系统与各种软件是构建医药库联盟的硬件支撑,其软件支撑则是学科资源的建设。10个联盟的资源量级存在很大差异:从千万级到几百级不等,从资源数量、涵盖学科、文献类型等也可看出医药库联盟在向两个方向发展。
一是“大而泛”。联盟的资源存储量至少都是几十万,如arXiv存储1 360 418条预印本记录、PubMed Central 存储约470万篇文章、bioRxiv存储约208 601条记录、Europe PubMed Central存储内容包括约3 320万条摘要(其中2 810万条摘要来自PMC)、460万篇全文文章。“大而泛”的发展方向有两个:一是涵盖的学科多。如bioRxiv 涵盖生物化学、生物工程、生物信息学、生物物理学、癌生物学、细胞生物学、生态学、流行病学、进化生物学、遗传学、基因组学、免疫学、微生物学、分子生物学等27个学科,arXiv收录的预印本除了物理、数学、计算机、定量生物学、定量金融、统计、电气工程、系统科学和经济学之外,也在向新的学科不断扩张;二是致力于对某学科资源的全覆盖。如PubMed Central几乎覆盖生物医学、生命科学学科的所有的期刊资源,其中完全开放的期刊2 090个、被美国国立卫生研究院资助要求开放的期刊330个、选择性开放的期刊4 531个;Europe PubMed Central不仅覆盖期刊资源,还向专利、医学记录和临床指南发展,它收录了420万个专利、675 698篇医学记录、859篇英国公立医疗系统的临床指南。
二是“精而深”。该类医药库联盟的资源量级一般在几百到几万,侧重对某个细化学科的精深研究。如CancerData收集了约522个癌症学数据集,其中包括多媒体资源、图像资源、临床记录、出版物、文献、实验数据等多种类型的资源;Mathematics in Medicine Study Groups收录的资源涉及医学生物学的有152种,涉及数学建模类的有147种,它主要致力于数学与医药学科的关联研究。
1.4 科研数据管理与学科服务
10个联盟几乎都提供科研数据管理与特色学科服务。如arXiv近期与天体物理数据系统合作,致力于科研数据的共享与存储;PMC鼓励将与论文有关的任何补充数据包括图表、视频或研究数据作为辅助文件与文章一起存放在PMC中,并指导用户对标记数据进行引用。此外,美国国立生物技术信息中心(National Center for Biotechnology Information,NCBI)的一些科研数据存储政策也是不断变化的。如从2017年9月起,dbSNP数据库和dbVar数据库停止接收非人类的变异数据提交,从11月起停止呈现非人类变异数据的比对,但继续提供已存储数据的FTP站点下载,之后非人类基因变化数据提交到EBI(European Bioinformatics Institute),可见学科科研数据管理已开始在全球范围内统筹规划。EPMC提供跟踪数据引用服务,引用多个数据库如European Nucleotide Archive、UniProt、PDB、OMIM、refsnp、RefSeq等记录的文件可以被搜索,当某个特定数据库被引用时,用户可以设置一个RSS提醒,可见对科研数据的管理已不仅仅是存储与共享,而是更注重数据的引用与利用以及数据科研价值的再创造。
CancerData是一个癌症患者在肿瘤治疗过程中创建的具有医学影像和医学特征的共享数据库。它也提供数据集服务,以专题为单位将数据集成后进行共享。当然这些数据集也包含一些私人收藏数据,如需访问要特别咨询登记,可见集成化也是数据管理的一个新方向。Dryad是以开放元数据的方式,使用户的数据通过第三方服务被发现,也向用户提供数据使用统计信息。Dryad还规定科研数据中涉及人类受试者信息时必须匿名,并在适用的法律与道德准则下进行。InterNano Nanomanufacturing Repository内包含很多专业数据库,如工艺数据库、过程数据库等,目的是为促进跨实验室数据共享,特别是学科内专利数据的共享,可大大提高科研效率。
在学科服务上,除学科导航、检索历史保存、参考文献提取、设置RSS提醒、用户个性化定制等一般性学科服务外,PMC Publisher Portal允许出版商发布和跟踪新的应用程序、更新联系人信息、查看和下载使用统计等,可见学科服务要考虑到成员机构的需求。EPMC为用户提供引文网络并通过RIS格式将引文导入参考文献管理程序,还可通过BioEntites标签找出哪些文章引用了目标文章,也可通过链接找到源数据库等服务。此外,EPMC还会从文章中挖掘基金符号、疾病、化学品、生物体、基因本体术语和进入编号,可见细化与特色化也是学科服务的发展方向。BioRxiv开放用户对文章的评论功能,读者也可直接联系作者与其交流,用户的文章也可直接从BioRxiv向期刊投稿。BioRxiv的文章被谷歌学术、CrossRef等搜索工具索引,更新的文章会在推特上发布,可见与搜索引擎及社交媒体合作推广学科资源也是一个新方向。CancerData则是通过提供许多相关网站的外部链接,如荷兰癌症协会、荷兰大学医疗中心联盟等,方便用户了解更多的学科机构与网站。Dryad除了提供引文导入、引文管理等服务外,最大的特色是为用户定制一个“数据管理计划”,并提供在线数据管理规划工具如dmptool或dmponline的咨询,可见为用户提供科研帮助和培训会使学科服务更深入和人性化。InterNano Nanomanufacturing Repository的学科服务重视用户培训,如提供Integrative Graduate Education and Research Traineeship系列讲座或举办一些报告会、研讨会等。National Science Digital Library的学科服务注重学科应用程序的开发与更新,如Schoology、Canvas程序的更新、OERC平台的改进、学习管理系统的开发、系统的智能化融入服务,可见学科服务水平的提高也需要更多计算机软件技术的支撑。
1.5 科研影响力
科研影响力是医药库联盟的价值体现。一个联盟的科研影响力可从几个方面来体现,如成员机构和收录资源的数量与质量,资源的上传、点击和使用情况,在社交媒体上的粉丝数及活跃度,甚至包括搜索引擎对该词条的搜索结果和百科网站对该联盟的介绍等。
目前大多数联盟统计的是资源上传量,如arXiv2017年月均提交文件10 293份,Europe PubMed Central、CancerData、InterNano Nanomanufacturing Repository按年份和文献类型统计资源上传量,bioRxiv每年按月份统计资源上传量,National Science Digital Library、Nature Precedings按学科统计资源上传量,Dryad统计资源总量与30天内上传量。
统计点击量和下载量的联盟并不多,仅有arXiv和National Science Digital Library统计点击量,如arXiv提供当日的点击次数(不包括镜像),National Science Digital Library收录资源的最高点击量为1 560次。提供下载量的联盟有arXiv、Dryad和National Science Digital Library,不过arXiv统计的是月下载量(如2018年1月下载量为1 058 057 882次),Dryad统计的是总下载量和30天内下载量(如Dryad总下载量2 349 590次,30天内下载量36 999次),National Science Digital Library提供的是每篇文章的下载量,只有EPMC提供每篇文章的被引用次数统计(被引次数最多的为141 727次)。本文认为与资源的上传量相比,资源的点击、下载、标记、被引量更能体现其学术价值。
通过百科网站和搜索引擎了解陌生词汇是网络时代人们解决未知问题的首选途径,arXiv、Dryad、National Science Digital Library、Nature Precedings有维基百科介绍,PubMed Central有百度百科介绍。利用搜索引擎对医药库联盟进行搜索所得到的结果数量从1 000多条到几千万条不等。其中最少的是InterNano Nanomanufacturing Repository,在百度中搜索的结果为10 100条,在Google中搜索的结果为4 340条;最多的是PubMed Central,在百度中搜索的结果为2 190万条,在Google中搜索的结果为3 520万条。这充分反映了网络正深刻改变着学术交流的方式,说明医药库联盟的构建要充分利用互联网。10个联盟中,arXiv、Europe PubMed Central、bioRxiv、Dryad开通了社交平台,且bioRxiv的每个细分学科如癌症生物学、神经科学、基因组学等都有twitter主页。这4个联盟中开通twitter最早的是Europe PubMed Central(2009年4月开通),推文最多的是bioRxiv(2.21万篇),twitter粉丝最多的也是bioRxiv(高达1.79万)。Europe PubMed Central和Dryad创建了博客,Dryad还开通了facebook。现在社交媒体广泛流行,已成为了解用户需求、加速用户反馈、推送学科资源和宣传联盟内容最便捷的方式。
2 国外医药类学科知识库联盟构建对我国的启示
2.1 依据发展战略制定适合的发展路径
目前医药库联盟逐渐向“广而泛”和“专而深”两个方向发展。不同的发展方向在联盟模式、成员构成、运营管理、资金来源等方面也不尽相同,因此我国医药库联盟构建的第一步就是要确定自己的发展战略。
“广而泛”联盟的构建模式可采用分布采集模式和层级构建模式[11]。分布采集模式要求每个成员机构都要构建自己的学科知识库,层级构建模式需要构建管理级、支撑级和资源级。这两种模式适合成员机构数量多、成员构成复杂、资源量大、技术资金实力雄厚且分工明确的联盟。如arXiv、PubMed Central、Europe PubMed Central、bioRxiv、Dryad,他们的成员机构众多、事务繁杂,其运营管理一般都由一个综合实力雄厚的机构来负责,处理行政、财务、发展等宏观决策问题,下设成员咨询委员会、科学咨询委员会或其他顾问委员会负责具体事务,甚至还会有监督机构。在资金问题上,“广而泛”的联盟单靠运营主体或基金完成资助比较困难,一般都需要通过广收会员费来支持。
“专而深”联盟的构建模式宜采用集中存储模式[11]。该模式是由一个大型学术机构带领几个中小型学术机构共同构建,适合成员机构数量少、成员构成简单、资源量有限、仅对某个学科进行深入研究的联盟,该类联盟一般由一个单独机构运营即可,如CancerData,Mathematics in Medicine Study Groups,Nature Precedings。“专而深”的联盟规模较小,一般可由单独机构来资助,或由主要资助机构搭配合作伙伴协助完成。
2.2 参考国际标准制定存储与共享政策
10个国外医药库联盟的存储政策和共享政策的内容是一致的,可见国际医药库联盟的发展已趋于成熟和稳定,我国在构建时应参考国际标准。
存储政策包括提交方式、公开程度、版权政策、隐私要求、元数据要求、语种、格式等。从提交方式看,一些联盟(如arXiv、Dryad)明确规定要求本人或版权持有者提交。本文更赞同InterNano Nanomanufacturing Repository的做法,只要不出现侵权行为,可由作者以外的人代为提交。如科研机构的科研管理部门可以对本机构学科成果统一进行整理提交,既准确无误又能提高效率。就开放程度而言,10个国外医药库联盟根据开放协议、文献类型等确定不同的开放程度。如PubMed Central有3种开放协议供成员选择,其中“完全参与”协议是发行商承诺从一个特定发行日期开始,全部开放所有卷期内容,“NIH资助参与”协议是所有NIH资助的文章要在PMC以作者名义存储文章的最后版本。“选择性存储”协议是出版商从多个期刊中将选定OA的文章或被Wellcome Trust,Bill & Melinda Gates Foundation等资助要求OA的文章存储到PMC。总的来说,决定开放程度的原则应以既能保护作者权益,又能最大限度地分享学术成果为宗旨。不同的开放程度还可用不同的字体颜色来区分,一目了然,便于用户查找。
版权和隐私问题上,10个医药库联盟的重点在于解决与出版商之间的版权问题、与资助机构OA要求引发的版权问题、与资源提供者之间的版权问题,以及版权政策的弥补措施、隐私问题的解决办法等。联盟在构建时需要对可能出现的版权问题进行细致全面的考量,并提出相应对策。如arXiv要求“翻译作品需得到源作品当前版权持有者的许可”。bioRxiv要求“提交预印本前需向期刊编辑告知并得到确认,预印本系统不可发布修改稿、编辑意见、同行评审和最终见刊版本,可在发表后的预印本旁提供文章发表链接,且需提供DOI号,并标注此文章被XX期刊录用;已发表的文章不可在预印本系统发布,提交到预印本系统的文章发表时需签署同意OA许可条款并支付相关费用;作者可使用预印本系统里文章ID直接投稿,期刊会从预印本系统提取文章,文章一旦被提取,在被期刊收录、撤稿或拒绝前,不得再存储到任何一个机构或者学科的知识库”。PMC用户需完全遵守版权限制,超出著作权法合理使用原则允许的,需获版权人书面许可。
好的联盟必然要求其存储资源必须具有高质量。如arXiv的科学咨询委员会制定了提交文件的内容要求,CancerData在数据质量、标准化和结构化方面都要求较高。因此我国在构建医药库联盟时,也需设立专门的部门对存储内容质量进行要求和把关。此外,笔者赞同Dryad在存储内容超过规定容量时收取过量存储费用的办法。此举既可以缓解恶意占用存储空间的行为,又可以缓解资金压力。在语种和格式要求上,虽然大部分联盟要求比较宽松,但笔者赞同Dryad较为严苛的做法。我国医药库联盟的中文成果必须配英文翻译,格式要求细致才能有效解决不同格式或格式转换过程中造成的数据错误和丢失,保证学术成果的可读性。
共享政策几乎都是采用知识共享署名许可证方式。10个药库联盟主要涉及5个许可证,这些许可证虽然侧重点不同,但主要从以下几个方面进行规定:分享——在任何媒介或格式下再传播;署名——必须给予姓名标注,提供许可证链接,并声明创作是否经过修改;非商业性——不得将本创作用于商业目的;没有衍生品——不得对本创作进行重混、转换或依据本创作进行再创作等;不得增加额外限制——在许可证允许的情况下,不得增设任何法律或技术限制;相同方式共享——如果对本创作进行了重混、转换、依据本创作进行再创作,必须依据本创作采用的许可证分发再创作。此外,近年来“copyleft”运动也逐步兴起,其支持者认为“在尊重创作权的基础上,创造性作品在非营利前提下,应当使用创作共用许可使作品获得更多自由使用与修改的权利。对于创作者而言,最大的问题不是版权,而是默默无闻。”因此各联盟可根据资源的开放要求及版权考量使用不同的的许可证,有效避免版权纠纷。要促进科研成果的进一步共享,需要更多的科研资助机构提出共享要求,要求被资助的项目申请者在不损害知识产权和隐私政策的前提下,尽可能减少限制、及时开放。如英国的一些资助机构(如RCUK、STFC、AHRC)等都有明确的科研成果、科研数据的共享政策[12]。
2.3 选择与发展策略相适应的软件并建设资源
软件平台的选择和学科资源的建设需要与联盟的构建策略相匹配。“大而泛”联盟平台的构建一般选择Eprints、Drupal、Dspace,使用的软件主要是团队协同与知识管理工具及各种数据库检索、阅读查询、用户网关等软件或工具。由于该类联盟收录的数据库较多,多源异构数据库的融合和跨库检索技术的研发也十分重要。此外,由于不同用户差异较大,可以考虑加强智慧平台的构建,针对不同用户的需求,重新聚类文献资源,提供个性化服务;根据用户的需求和喜好,对学科资源进行个性化编辑。还可引进网络机器人探测技术,对海量资源的用户使用情况进行统计分析和整合,对用户数据进行关联规则挖掘、聚类分析和趋势预测等。如深圳大学设计了USSER平台,已开始对此课题进行初步探究[13]。“大而泛”的联盟涉及的相关学科比较多,需要收录的资源数量庞大,基本上都是千万级、百万级的数量,收录文献类型也众多,涵盖期刊、图书、专利、临床报告等。
“专而深”的联盟一般会根据自身收录资源的特色确定其所使用的系统和软件,系统平台构建一般会选用Custom或Fedora。在软件选择上,如CancerData收录大量多媒体和图像资源,因此需要使用图像转换工具、离线媒体处理工具以及图像存储发送和接受的软件等。CancerData还利用AR技术将一些临床图像和多媒体资源利用三维显示、交互传感、将虚拟和现实环境相互补充、叠加,加强读者对临床资源的感知。走“专而深”道路的联盟涉及的学科更集中,讲求细分学科的全收录或者学科特色资源构建,一般都是几百到几万的数量。
2.4 加强数据管理,创新学科服务
对于医药类学科而言,科研数据的管理与利用尤为重要。调查结果显示,国际医药库联盟对科研数据的存储与管理已逐步细化完善。一是加强了与学科内其他数据系统的合作,特别是国际性合作,逐步实现科研数据全球范围内的统筹与共享;二是以存储政策的形式规定,提交的学科论文必须配有对应的科研数据,并提供科研数据备份服务,鼓励科研人员将整个科研周期的数据都上传至联盟平台进行备份,既可以确保数据不会丢失,又可以理清科研脉络,便于科研溯源;三是提供跟踪数据引用服务,加强对数据再利用工作的深入调查,对科研数据的再生科研价值进行分析与评估;四是提高对科研成果和临床数据的质量控制,录入的科研数据须准确和相对完整,在数据质量、标准化和结构化上都要有相应的具体要求等。数据存储、管理、共享的目的是为了更好地利用已有数据、减少重复劳动,因此数据管理政策的制定应紧紧围绕此原则展开。
医药库联盟提供的学科服务应以学科资源为基石,以智能技术为手段,以创新提升为目标。具体来说,一是保证基本的学科服务质量,如学科导航、检索历史保存、参考文献提取、引文导入管理;二是提升学科服务在个性化、人性化和细节化方面的水准,如为用户定制数据管理计划,让作者添加更新记录,并与原始材料一起发布,以显示研究进展,有利于科研谱系的构建;三是为资源使用者与资源提供者之间创建更多的交流平台,为成员机构之间创建更多的合作交流平台,同时为成员机构的科研成果下载、引用情况提供数值统计,以便成员机构充分了解本机构学科成果的价值;四是提供更多学科相关网站的外部链接,增加对资助基金的介绍,为用户提供申请基金课题的培训,提供使用各种文献、数据、引文管理工具的培训,提供利用SPSS、Nvivo R或ArcGIS等进行数据处理的培训。
2.5 充分利用网络资源,提高科研影响力
无论医药库联盟走“大而泛”还是“专而深”的道路,其奋斗目标都是拥有较高的科研影响力,提高途径主要有以下几种。一是联盟善用资源使用统计、合理整合学科资源,对资源的点击、下载、引用、标记、评分等数据进行统计,这些统计数据正是分析资源价值的依据。对点击、下载量大的学术资源,联盟平台可以对其做出推送;对引用、标记、评分高的学术资源,联盟平台可对其学术信息进行更深入的学术挖掘,做一些同类型论文的比较分析、高被引和零被引的原因剖析等知识挖掘工作。二是善用社交平台广泛宣传推广,有效利用社交媒体深层开发潜在用户,更快速、便捷地与学科用户沟通。如我国的医药库联盟在利用twitter、facebook等国际社交平台做好国际宣传交流的同时,也要利用好微博、微信、博客、百度贴吧、丁香园等国内社交平台。三是从搜索引擎来看,据《中国互联网络发展状况统计报告》显示,84.5%的用户依靠搜索引擎获取网站信息[14],因此医药库联盟应先着力百度搜索与百度百科信息的完善。虽然Google当下无法在中国大陆地区使用,但其在国际搜索引擎中还是很有影响力的,应使我国的医药库联盟顺利在Google搜索中被检索和链接。此外,还要做好搜索引擎优化,使网站各项基本要素适合搜索引擎的检索原则,以便更容易被搜索引擎优先排序[15]。同时为了增强国际影响力,更应利用维基百科对我国构建的医药库联盟进行详实的词条编辑。
3 结语
本文通过对国外较知名的10个医药库联盟进行调查分析,从联盟模式、运营管理、资金来源、存储与共享政策、科研数据管理、学科服务、技术支撑、资源建设、科研影响力等方面探讨了其构建特征,分析了目前医药库联盟“大而泛”和“专而深”两大发展趋势。
走“大而泛”发展之路的联盟,宜采用分布采集和层级构建模式,运营主体一般由大型科研机构负责,下设各职能委员会及监督机构,成员机构多为科研院所、实验室、大学学院、各种协会与学会等具备较高科研能力的机构。资金来源主要由运营机构和资助基金提供,辅以会员会费。存储和共享政策多元化,需要满足不同机构成员的版权要求和资助基金的OA政策。平台架构较为复杂,对系统软件的种类与功能要求较高。资源数量庞大、涵盖细化学科较多、文献类型收录广泛,甚至趋向某类型学科资源的全收录。由于收录的科研数据庞大,联盟可对海量科研数据做分析,挖掘其科研价值,走学术化学科服务道路。
走“专而深”发展之路的联盟,宜采用集中存储模式,运营主体一般由单个机构独立运营或由成员机构推选的职能委员会负责,资金由运营机构和合作基金共同提供。成员机构数量不多,因此存储和共享政策相对简单。平台架构较为简单,对系统软件的选择更强调与资源的适配性,资源构建侧重于某个细化学科的精深发展。由于科研数据和用户数量有限,联盟对于科研数据更侧重为用户定制个性化管理策略,走精细化学科服务道路。
无论走哪种发展道路,医药库联盟都应充分利用网络资源,提高自身的科研影响力,希望本文能为构建我国医药库联盟提供参考。调研分析可能存在一些不足与缺陷,克服这些不足、继续深入研究是我们未来的探索方向。
猜你喜欢
大学(2021年2期)2021-06-11 01:13:28
今日农业(2020年24期)2020-12-15 16:16:00
遵义(2017年24期)2017-12-22 06:10:49
股市动态分析(2016年23期)2016-12-27 19:00:03
中国卫生(2016年12期)2016-11-23 01:10:10
股市动态分析(2016年7期)2016-09-29 11:17:42
股市动态分析(2016年4期)2016-09-29 08:37:34
股市动态分析(2016年29期)2016-08-04 21:18:52
电子产品可靠性与环境试验(2016年6期)2016-05-17 03:52:12
中国火炬(2015年2期)2015-07-25 10:45:24
