
医学文献主题新颖性探测方法对比分析
2018-03-21 01:18:26,,,
中华医学图书情报杂志 2018年2期
,, ,
新异检测的主要目的在于建立二分类器,已在众多领域实现应用,如电子安全监测系统、健康信息及医学诊断检测、复杂商业系统监测及系统错误检测、图像处理及视频监测、无线传感器网络监测,以及文本挖掘领域。由于新异检测的应用领域广泛,不同领域的数据特点不同(包括维度、格式、连续性),因此新异检测缺少统一的方法。在各个领域中开展的新异检测中,产生的各种计算方法按照假设理论的不同,可以划分为5类:概率分析方法。通常对正常数据进行密度值估算,假设训练数据中低密度值区域包含正常数据概率低。基于模型的方法(如神经网络算法)。利用训练数据构建回归模型,当异常数据映射到回归模型中,得到的回归值与真实值差距是一个较高的探测值。基于领域的方法。试图通过训练数据划定正常数据的边界,建立一个包含的正常数据的领域。基于距离的计算方法。假设异常数据距离正常数据较远,有最近邻计算方法以及聚类分析方法。信息计算技术(譬如墒计算,Kolmogorov计算方法)。计算训练数据中的信息含量,假设异常数据显著的改变信息含量。其中,前3种方法需要充足的训练数据,但实际检验阶段较为迅速。
文本挖掘领域的新异检测是从给定的文献集或新闻文献中探测新主题或新事件[1]。2002-2004年连续举办的文本检索领域权威的国际性评测会议TREC会议(Text Retrieval Conference,TREC)[2-4]进行了语句级别的文本内容新颖性探测赛事(Novelty Track),其中清华大学、中国科学院均使用了词重叠法,表现优异。国内文献关于主题新颖性探测较为经典的是杨建林[5]的关于文献主题新颖度计算。本文通过实证研究,证实其算法的计算结果与同行评价相一致。
1 文本挖掘领域新异探测相关概念
本文涉及3个文本挖掘领域新异探测概念。
一是新颖性文献。一定主题下,一篇文献的主题内容,对比其时间序列中排名在其之前的文献,对于读者而言未曾见过,则这篇文献为新颖性文献,否则认为其不具备新颖性,其概念内涵不包括文献创造力评估。
二是新颖度。新颖度用来衡量当前待探测文献与之前出现的文献相比,包含了多少新颖性的具体量化指标。本文给定一个新颖度阈值,如果待探测文献的新颖度大于该阈值,则认为该文献为新颖性文献。新颖度实质是相对值,如文献A比文献B新颖度大,表示文献A比文献B与之前文献内容重复的地方少。
三是文献主题新颖性探测。文献主题新颖性探测用于自动识别主题新颖的文献。在生物医学科技文献中,按时间排序,以文献为单位进行新颖性探测,找出带有新颖性的文献集合的探测过程。
2 材料与方法
2.1 数据收集
在基础医学与临床医学的分类基础上,选取近2年的查新课题,通过检索获得较为精确的、相关的检索结果,交予专家组,保证评估时专家对文献的掌握能力、评估结果的可信程度、分析过程的效率。选取生物医学领域的8个研究主题(表1),利用PubMed数据库,检索出相关文献。文献标题能够反映该文献的主要研究内容及结论,故选择保留检索得到的相关文献标题作为实验文献集合,详见表1。

表1 实验主题及文献数量列表
*学科领域按照中国国务院学位委员会和教育部《学位授予和人才培养学科目录(2011)》(SCADC)[6]的医学学科进行分类
2.2 数据预处理
数据预处理的主要任务是将自然语言转换为规范统一的生物医学词汇。因为叙词能够有效规范统一同一医学概念的不同自然语言表达,避免新颖度计算误差。本文使用美国国立医学图书馆开发的一体化医学语言系统[7](Unified Medical Language System,UMLS)的超级叙词表,运用MetaMap[8]在线概念抽取软件,选择知识来源2017版本。将各个主题下的自然语言映射到超级叙词表中的概念词,运用MetaMap概念抽取软件[9]统计概念词,并导入MySQL数据库。在MySQL数据库中提取标题部分的语句数据,删除停用词[10]。
2.3 新颖度计算方法
词重叠法(简称重叠法)一直用于语句级别的新颖性探测。基于共词的逆文档频率量化法(简称量化法)用于文献主题新颖性探测,首次出现用于杂志评估。本文拟以文献自然语言构建数据集,从同一主题按时间排序的文献中,运用重叠法和量化法探测出新颖文献。对比专家调查得出的新异结果,对新异探测方法进行可行性评估及算法对比分析。
2.3.1 词重叠法
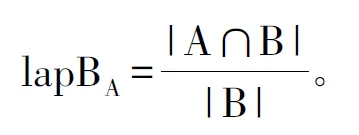
设文献j先于文献i出现,两篇文献的向量表示为:
Si=(W1(Si),W2(Si),…,WN(Si))
Sj=(W1(Sj),W2(Sj),…,WN(Sj))
其中,N为所有待探测语句经自然语言处理得到的不同概念词的总数。
语句新颖度[11]计算公式为:
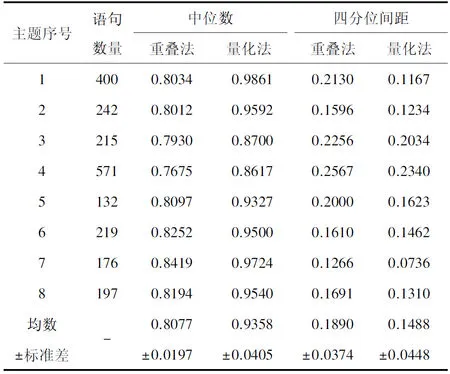
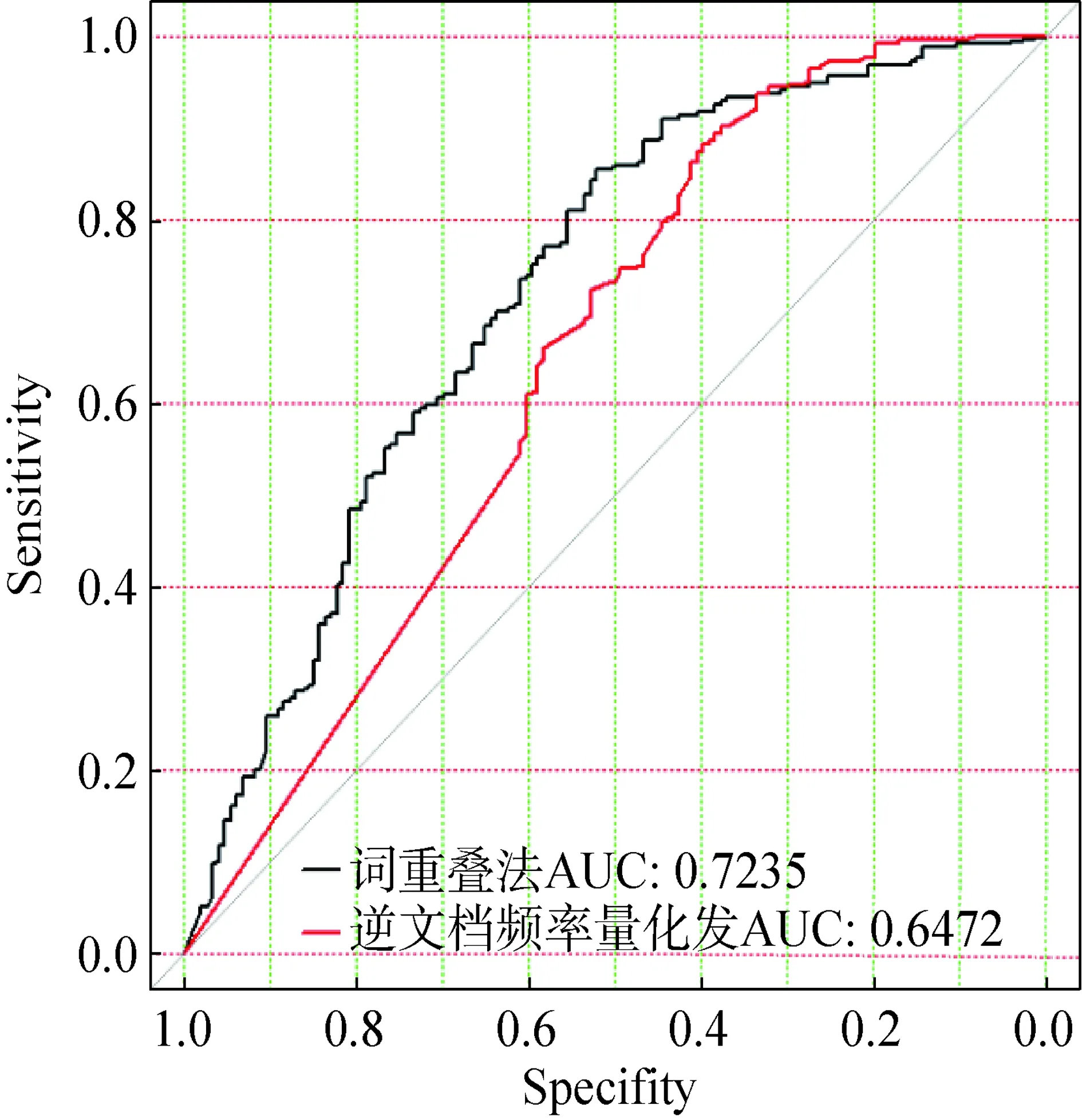
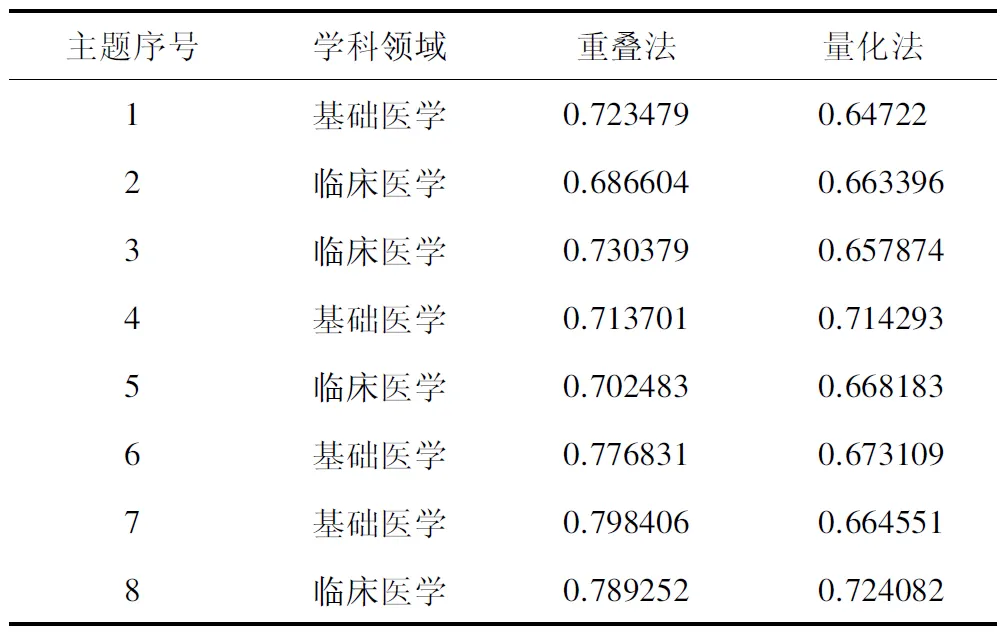
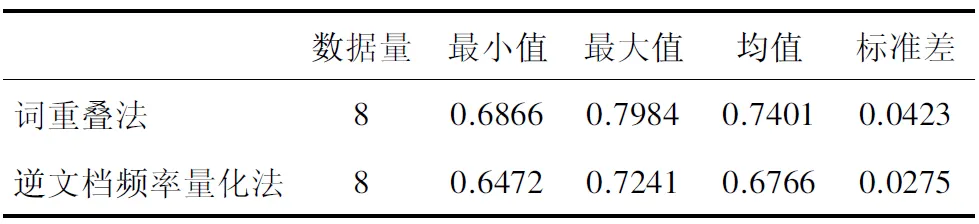
OverlapNov(Si)=1-max(0 公式(1) 计算过程是先计算当前语句与之前所有语句的词重叠度,选择重叠度最大的结果作为当前语句与之前所有语句的重叠度,通过减法运算计算出当前语句的新颖度。 2.3.2 基于共词的逆文档频率量化法 国内学者杨建林基于文档发表先后、关键词对共现等原则提出了词对逆文档频率(Inverse Document Frequercy of keyword Pair,KPIDF)的主题新颖度度量方法[5]。 文档D中所有以其自身为参照的概念词对逆语句频率的平均值,称为该文档的新颖度,记为NOV(D),计算公式为: 公式(2) 其中ti、tj为文档D的第i和第j个概念词。若ti、tj为文档D中共同出现的2个概念词,在文档D之前的所有文档中同时包含概念词ti、tj的文档数记为N,则称N+1为以文档D为参照的概念词对ti、tj的文档频率,称N+1的倒数为以文档D为参照的概念词对ti、tj的时间逆文档频率,记为WPIDF(D,ti,tj),n为文档D包含的概念词的总个数。 2.4.1 参考答案 参考答案用于新异探测结果评价。通过调查问卷的形式,将每个主题的文献发送至4组共计36位相关专家(表2),按照给定的顺序阅读文献,找出新颖性文献,标识为1。其判断标准同新颖性文献标准,即一定主题下,一篇文献的主题内容,对比其时间序列中排名在其之前的文献,对于评论专家而言具有未曾见过的信息。若每篇文献有5位及以上专家标识为新颖的文献,则记为新颖文献,标记为1,否则为0。将本实验算法得出的新颖度列为一列,专家评分列为一列,利用Ruby语言进行结果分析。 2.4.2 评估方法 ROC曲线[12](Receiver Operating Characteristics curve)于20世纪50年代在统计决策理论中被提出,用来说明分类器命中率和误报警率的关系。Spackman[13]将ROC算法引入到机器学习研究领域中,并说明了ROC曲线评估算法细则,ROC被广泛用来评估分类模型性能[14]。 通过使用AUC(area under the curve)来量化ROC曲线,并通过比较AUC值大小来评判分类模型性能。AUC的值越大,说明分类模型的性能越好。最理想的分类模型AUC值等于1,random分类模型AUC值为0.5。AUC在 0.5-0.7时的准确性较低,在0.7-0.9时的准确性一般,在0.9以上时的准确性较高。 本文利用ROC曲线及AUC值评估2种新颖性探测方法,调用R语言library(pROC)[15]程序实现证实新颖性探测方法对文献主题新颖性判定的能力。选择最佳阈值,即ROC曲线上假阳性和假阴性的总数最少的点,对2种方法的性能进行综合对比分析。 表2 不同主题评估专家情况列表 主题1文献的新颖度计算结果见表3(部分数据)。表3为主题1,即细胞自噬相关基因的调控作用,以新颖度计算结果。首先,我们对主题1超级叙词的映射情况进行分析,400篇文章映射出超级叙词的数量从1到15不等,主要取决于标题包含的信息。Metamap提取较为完全,如序号25的文献提取出anabolism,autophagosome,autophagy,autophagy-related,rotein 8 family,function,mechanism,molecular,plants,social role等超级叙词。如果提出序号348的文献标题为“TRPML3.”,其映射的超级叙词为“mcoln3 gene”。2种算法的新颖度值均为1,说明之前347篇文章中均未出现该词。 8个主题文献新颖度均不服从正态分布。用中位数、四分位间距描述计算结果分布状态见表4。 *No为metmap从文献中抽取的词数量,#参考答案判定为新颖性文献标识为1,否则为0 表4 8个主题语句计算结果统计学描述列表 观察8个主题下新颖度计算结果的数据描述,中位数均值较小的是重叠法为0.8077,量化法为0.9358。两种算法的均值较高,探测的新颖值均值大有以下原因:第一,因为本文为保证参考答案获取的正确性选取数据量偏少(132-571条之间),数据量少重复性可能降低,势必造成新颖值大;第二,期刊刊发前会进行查重、同行评议等,一定程度降低了文献的重复程度;第三,量化法的均值较高,该方法将1篇文献中的超级叙词两两组配后,与前文对比取逆文档频率后求和,逆文档频率增加了新颖度值,即使与之前重复3次,亦有1/4的新颖度增值,而词重叠法直接重叠便不计值。 四分位间距数均值较大的是词重叠法为0.1890,逆文档频率量化法为0.1488。四分位间距越大,样本数据分布越离散。结合中位数和四分位间距,认为词重叠法的新颖度计算结果波动幅度较大,即词重叠度算法的公式更加敏感,能够将更好地将语句内容间差异表现在数据上。 本文将8个主题文献的新颖度计算结果集合入1个文档(共计2 153篇),对2种算法进行相关性分析,得出相关系数为0.7144,表示2种算法中度相关。 本文利用R语言对8个主题的两种算法绘制ROC曲线(图1),其中横坐标为假正率(特异度specificity),纵坐标为真正率(敏感度sensitivity)。 图1 主题1的2种算法的ROC曲线 图1为主题1文献集2种方法的ROC曲线,其最佳界阈值方法2为0.712(0.521,0.854),方法3为0.862(0.397,0.882)。R语言计算得出5个主题2种方法的AUC值见表5。 表5 8个主题2种方法的AUC值列表 若以学科领域区分,4个临床医学的重叠法AUC值均值为0.727,量化法AUC值均值为0.678;4个基础医学的重叠法值均值为0.753,量化法的均值为0.675,说明重叠法在基础医学数据的表现优于临床学科,量化法在2个学科的数据表现相差不大(仅0.03)。2种方法8个主题的AUC值数据均符合正态分布。采用最大值、最小值、均值和标准差描述评估结果数值分布状态见表6。 表6 三种方法AUC指标统计描述 表6显示,词重叠法的AUC值均值较高,为0.7401,逆文档频率量化法AUC值均值为0.6766。 使用R语言对2种算法的AUC值进行样本均值t-检验,P=0.2158(<0.05),表示2种算法AUC值均值差异具有统计学意义。综合表5的统计结果,词重叠法AUC值除主题2以外均在0.7-0.9之间,说明该方法对于判断新颖文献具有一定的准确性;逆文档频率量化法只有主题4和主题8处于0.7-0.9之间,其余均在0.5-0.7之间,说明该方法对于判断新颖文献准确性较低。因此,词重叠法的评估结果优于逆文档频率量化法。 本文证实了生物医学领域文献主题新颖性探测的可行性,可为文献推荐、文献评价、专题前沿分析、期刊评价和作者评价提供一定的参考。本文证实词重叠法能够更好地将语句内容间差异表现在数据上,词重叠法对判断新颖文献具有一定准确性,评估结果优于逆文档频率量化法,差异具有统计学意义。本研究还有以下不足。 第一,文献主题新颖性探测的特点之一在于其时间原则,即早出现的新颖性好,数据结果与实际经验相符;之二在于实验数据和测试数据的划分,测试数据的新颖性之间是相互影响的。本文使用的2种方法均未区分实验数据和测试数据,在后续研究中尝试使用背景数据等评估当前文献的新颖性。 第二,自然语言的使用降低了对关键词或者主题词的依赖。关键词和主题词的信息存在无法获取、标引滞后的问题。本文数据存在标题长短提取词数量差异较大的情况,对数据计算结果有一定的影响。本文向专家发放的评估资料均要求以标题的新颖程度为主要评估对象,符合本文的实验数据。在后续研究中,会权衡受控词和自然语词之间的权重,提供更加稳定的抽取词数量。 第三,本文的8个主题按照《学位授予和人才培养学科目录(2011)》(SCADC)的医学学科进行分类,有临床医学4个、基础医学4个。实验结果显示,重叠法在基础医学AUC值的表现优于临床学科,该研究结果值得进一步探讨。2.4 算法评价方法

3 结果与结论
3.1 主题新颖度计算结果
3.2 两种算法的评价结果
4 讨论
猜你喜欢
心理学报(2020年11期)2020-11-13 05:41:28
广州化工(2020年19期)2020-10-18 10:44:46
高考·上(2020年3期)2020-09-10 07:22:44
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
中国知识产权(2018年2期)2018-03-03 09:04:24
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
创新作文·初中版(2014年7期)2014-09-01 03:03:40
语文知识(2014年4期)2014-02-28 21:59:52
中国军转民(2013年9期)2013-08-15 00:43:44
心理学报(2013年12期)2013-02-03 03:23:11
