
德国国家队列组织模式及其启示
2018-03-21 00:26,,,
中华医学图书情报杂志 2018年2期
,,,
随着世界医疗卫生条件的改善,心血管疾病发病率有所下降,但迄今为止心血管疾病、癌症、慢性呼吸系统疾病和糖尿病等慢性疾病仍是最主要的死亡原因[1]。国家卫生计生委发布的《中国疾病预防控制工作进展(2015年)》显示,近年来,我国慢性病发病率呈快速上升趋势,慢性病导致的死亡人数已占86.6%,其导致的疾病负担占70%[2]。我国医疗卫生体系经济负担增大,劳动力损失严重。卫生经济学分析显示,提高公众健康水平最有效的方式仍是疾病预防[3-4]。在大数据和精准医疗时代,以预防为主的人群队列研究已经成为发现慢性疾病病因、减少发病率的主旋律。
人群队列研究是通过对一定的人群进行随访和纵向观察,揭示疾病病因、评价预防效果,将知识转化为临床早期诊断和干预策略[5],从而降低疾病发生率,减轻社会医疗负担,是解决目前医学和健康重大问题的有效方法之一,是医学逐步走向精准、提高效果的必经之路。国外已累积了几十年的经验,其中人群队列规模达到50万左右的有欧洲10国的European Prospective Investigation into Cancer and Nutrition (EPIC)[6]、美国的精准医学计划[7]、英国的Million Women Study (MWS)[8]和UK Biobank (UKB)[9]、瑞典的LifeGene[10]等。2013年,德国开展了由国家财政支持的大规模前瞻性队列研究——国家队列(The German National Cohort,GNC)研究。它是由亥姆霍兹和莱布尼兹协会、多所大学及其他研究机构合作进行的跨学科研究项目,旨在解决发病率较高的慢性疾病的病因和机制问题。本文主要从GNC的组织模式、数据采集和数据管理3个维度进行分析,以期为我国队列研究的组织模式和数据管理提供参考和借鉴。
1 德国国家人群队列简述
德国国家队列的主要研究目的在于研究心血管疾病、肿瘤、糖尿病、神经退行性/精神疾病、肌肉骨骼疾病、呼吸道传染病等几种主要慢性疾病发展的原因及其临床前阶段和功能健康损害,分析社会经济及心理因素对慢性疾病的影响,寻找慢性疾病早期的临床生物标志物,开发有效的疾病预测工具,改进风险预测模型,制定个体化预防策略。
德国国家队列一般人群的随机样本将通过18个研究中心,随机抽取年龄在20-69岁间的10万名男性和10万名女性。该项目计划持续25-30年,除前期准备阶段外,共分为4个阶段实施:第一阶段对20万受试者进行基线评估,第二阶段在每个研究中心随机抽取20%的受试者(约40 000人)进行二级评估,第三阶段对受试者进行包括疾病、死亡、生活中危险因素的改变等因素的后期随访,第四阶段对数据和样本的队列进行流行病学分析[11]。德国国家队列将为德国提供重要的基于人群的流行病学的中心资源,有助于制定应用于重大疾病的早期检测、预估以及早期预防的新的定制型策略。
2 组织模式
GNC主要有研究中心、整合中心和权限中心3种类型的组织单位(图1)。
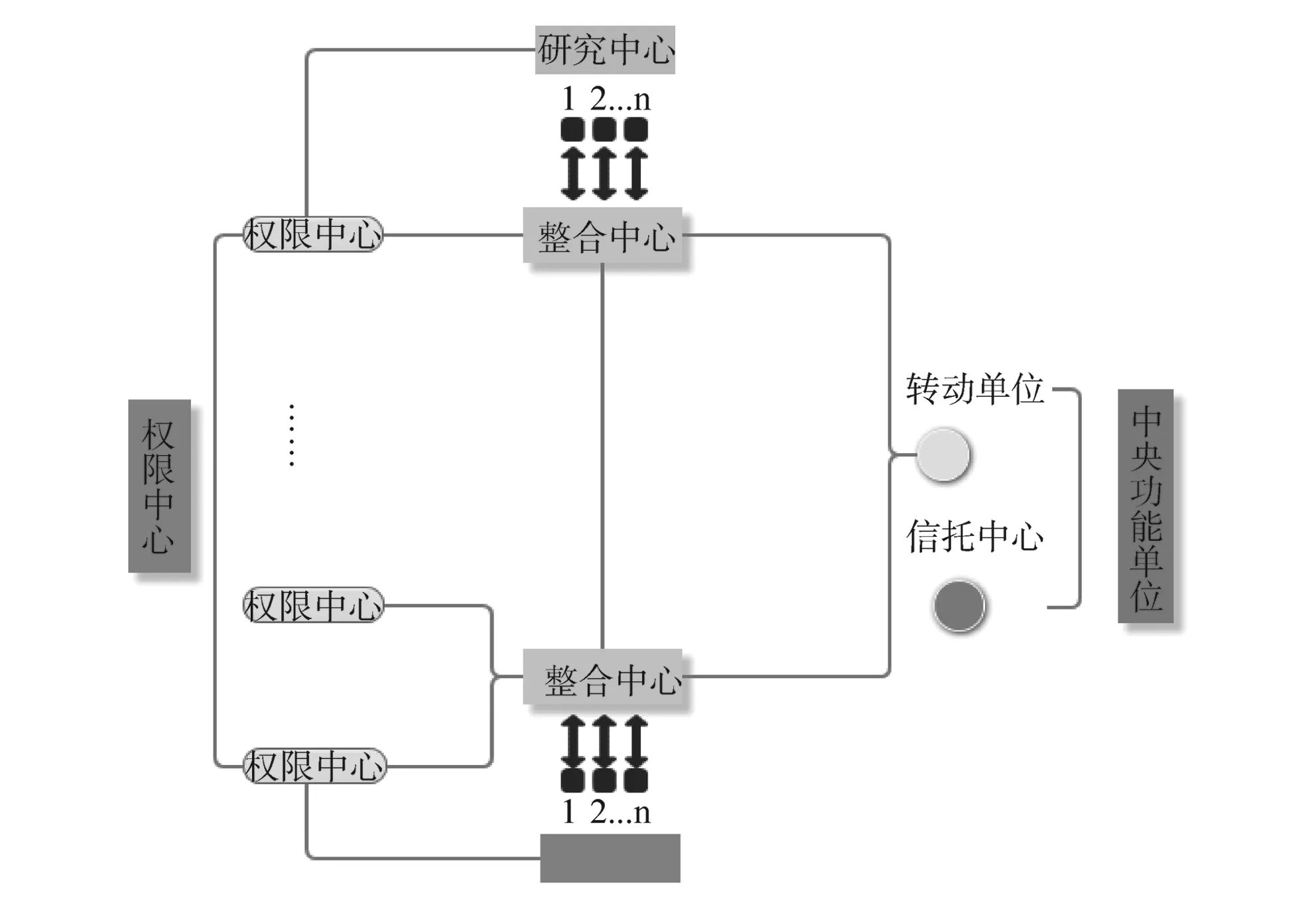
图1 GNC数据管理组织结构
2.1 研究中心
GNC建立了18个研究中心,其主要任务是进行项目管理和数据采集,其中项目管理包括受试者的招募、项目计划和日程安排、对受试者的编码,数据采集包括对受试者进行面试和问卷调查、体检和生物样本采集。此外,研究中心还要负责对采集的数据和生物样本进行质量检查与检测及对当地的辅助数据(登记处卫生局的医疗服务信息及死亡率等)进行采集。
2.2 整合中心
GNC共设立了2个整合中心,在国家层面上对数据和生物样本进行整合和处理,其主要功能包括对所有研究数据进行中央存储和质量检查,如自动检测研究数据的一致性和完整性,对数据进行标准化处理;向研究中心和权限中心提供标准化后的研究数据;为科学家提供一个数据分析的技术平台。此外,2个整合中心以相同的方式提供服务并存储所有研究数据,以保证所有主流程的冗余和服务高效性,确保在一个整合中心发生故障时能够及时接入到另一个整合中心。
2.3 权限中心
GNC共计划设立3-5个权限中心。权限中心的主要任务是接收整合中心提交的标准化研究数据,对特定主题数据进行质量比较和检查,处理和解释“复杂”类型的专题研究数据(如磁共振成像或心电图数据),从国家层面采集一些较难采集的辅助数据(如社会保障数据),对中心专题任务进行数据跟踪。
2.4 其他中心
当需要处理个人数据或在中央层面重新确定研究对象的任务时,需要建立信托中心。信托中心的主要任务是集中备份个人标识数据,为受试者数据编码生产伪代码,重新识别中心任务。此外,GNC还设立了转运单位,主要承担与数据分析相关的管理工作,如对内外科学专家进行数据分析时所需的数据和分析结果进行传输。
3 数据采集
德国国家队列项目数据的采集分为两个阶段,第一阶段为基线评估阶段,即对所有受试者进行问卷调查、生物样本采集及基础体检;第二阶段为后期随访阶段,随机抽取40 000名受试者进行问卷调查和医疗检查。按采集方式分类,采集数据可分为问卷调查数据、医疗设备数据和生物样本数据。
3.1 问卷调查数据
在基线评估和后期随访阶段,问卷和表格是不可或缺的一部分。问卷和表格主要采集个人医疗信息和识别数据,如姓名、性别、出生日期、出生地、地址、电子邮件、电话、传真等。其中,出生日期和性别除了可用于计算年龄和分配受试者编码外,还可用于实验的分类研究,如只采集特定年龄段、首次患某种疾病的女性信息等。此外,医疗保险信息还可用于辅助数据的采集,生活和工作地址等数据可被用来评测环境数据(如农村和城市、噪音、空气质量、辐射等)对慢性疾病的影响。
3.2 医疗设备数据
指受试者在研究中心进行体检(心血管检查、动脉硬化、踝臂指数、糖尿病相关测量等)时所产生的数据,分为电子化体检数据、非电子化体检数据和磁共振成像(Magnetic Resonance Imaging,MRT)数据3种。
3.3 生物样本数据
在分子组学水平进行表型分析的生物材料是国家队列研究的基本组件。生物样本的选取需满足以下几个标准:样本可提供不同类型的信息且能够进行信息分析;样品采集可行性较大且在样品采集、处理、储存和运输至中央生物库等步骤均能遵循SOPs标准,不会对受试者身体产生较大的负面影响;样品采集、处理和储存成本较低。根据此标准,GNC确定采集的生物样本种类主要有血液、尿、唾液、粪便、鼻拭子。在国家队列的基线评估阶段,各研究中心会完成对受试者生物样品的采集工作。
除了上述数据,德国国家队列还将社会保障数据和环境监测系统数据作为辅助数据,用于跟踪疾病的发生、发展和治疗过程,作为受试者健康状态暴露和疾病(病因学)的补充信息。德国约85%的人有法定健康保险,除公务员和个体经营者外,大部分雇员亦须缴付法定社会保险,包括失业保险、长期护理保险和法定退休保险。德国社会保险制度中的数据由雇主每年提交给研究所,该数据包括员工的社会人口学统计信息、就业部门等。根据辅助数据,国家队列可了解受试者的职业史和享受的卫生服务,如门诊、住院和开处方药的历史及所处地区的噪音、大气、辐射等环境状况。
4 数据管理
GNC数据管理流程包括数据采集、预分析处理、运输、长期存储、检索和分析共享,各单位在严格遵守标准操作程序(Standard Operating Procedure,SOP)的前提下各司其职(图2)。
4.1 数据采集和处理
GNC数据采集工作主要由各研究中心完成。研究中心向当地登记办公室随机抽取的受试者发出邀请,受试者同意后,预约受试者进行检查和测试。对受试者经问卷调查、访谈和体检产生的纸质数据,利用电子数据捕获表单应用程序(electronic data capture forms application,EDCF)提供的电子表单进行数据采集和存储[12],之后自动地对数据的合理性和一致性进行检查。在网络可用的情况下,数据将被立即传输至整合中心的研究数据库进行整合,否则则被临时存储在本地服务器上。
从医疗设备中采集的电子数据,先在本地进行原始数据存储,然后以电子数据的形式自动传输到整合中心进行中央存储和归档。在数据存储、导出和传输至整合中心的过程中,将使用由整合中心统一协调用于所有研究中心的标准临床接口(如DICOM,HL7),而医疗设备产生的磁共振成像数据由MRT图像数据管理系统专门管理。
对于生物样本数据,为确保生物样本在传输过程中的质量,研究中心会对采集的生物样本进行预处理。所有研究中心利用自动化机器人系统将每个受试者的血液、尿液、唾液、鼻拭子和粪便等分后,采用分布式生物存储方式,运输至生物样品实验室(及时分析)或中央生物存储库(长期存储)存储。
关于辅助数据,各研究中心从当地卫生局采集受试者的卫生服务信息及死亡信息,然后将受试者的个人识别数据传输至信托中心,用于重新编码及备份个人识别数据。对于研究中心无法获取的辅助数据,GNC会从国家层面上获取法律规定社会保障数据、环境监测数据及就业数据等,并将这些数据直接传输至整合中心进行整合,便于各研究中心查看和导出受试者的数据。

图2 GNC数据存储和处理
4.2 数据存储和整合
整合中心对不同类型的数据进行分类存储和整合,存储的数据包括研究数据原始值及对其改动的日志,如日期、原因和执行人。其中研究数据存储在研究数据库中,生物样本存储在中央生物存储库中,而MRT数据由MRT图像数据管理系统专门管理。整合中心内含版本管理系统,以保证存储数据的数据模型和软件版本不变。所有数据以固定时间进行备份,如有需要,在一定时间内能够迅速恢复数据。
4.3 数据分析和使用
GNC数据使用需进行申请、审批、移交和成果共享等流程。
4.3.1 使用申请
GNC对数据申请者有一定的要求:研究人员必须隶属于卫生健康相关研究机构;大学、研究机构、基金会和行业机构等第三方只能向国家队列协会和访问委员会提交申请使用数据,不能直接与受试者联系,但受试者在此过程中享有决定权,可同意或拒绝申请者的请求;对于国际项目,需与德国科学家团体进行合作且接受德国道德规范;保险公司、雇主、警察或其他执法机构无权申请数据和生物样本。
4.3.2 审批流程
使用和访问委员对数据申请者的申请权限证明进行检查,以确保数据申请者享有申请权且未被受试者拒绝,以及数据使用的范围符合国家队列相关道德标准,并将检查结果提交给国家队列协会办公室,由办公室下结论。如果申请者的申请符合要求,国家队列协会办公室则将合格项目提交给董事会,由董事会对项目进行审批。GNC具有对数据及生物样本获取和使用的最终决策权,以确保数据和生物样本被科学、合理地使用。
4.3.3 数据移交
转运单位在将数据集移交给申请者之前,需要与申请者签订相关合同,以规定数据使用条件、研究目的、拟进行分析、使用时间表和结果共享。所有申请者必须遵循相同的道德标准,数据和生物样本只能在规定范围内使用。
GNC是所有数据和生物样本的合法所有者,有权对未经授权使用或滥用数据和生物样本的个体或机构采取法律行动[13]。此外,使用数据和生物样本的用户需要向GNC付费,以支付数据采集、处理、整合和分析等过程中产生的费用,可以酌情对希望从数据中获得经济利益的组织收取更高的费用。
4.3.4 成果共享
使用数据的研究人员必须同意将分析结果提供给GNC,包括实验方法、分析过程及结果等信息,GNC会将这些信息公布在公共领域(如网页)。基于国家队列数据所写的论文需发表在指定期刊上,以方便其他研究人员查阅,而且有利于受试者了解其参与研究的结果。
国家队列网站会定时更新可申请使用的数据和生物样本以及被授予或拒绝申请的研究人员和机构。在国家队列网站中,受试者可以看到有权访问其数据的研究人员或机构,且有权禁止访问者对其数据的访问。
4.4 数据质量管理与控制
为确保国家队列研究顺利进行,需建立数据质量管理体系,以控制和保证数据质量。数据质量管理体系主要包括内部质量管理和外部质量管理。
4.4.1 内部质量管理
研究中心:主要负责数据采集工作,是数据质量保证与控制的第一关。即使研究中心的数据库在进行数据在线收集工作,中央质量办公室也可访问所有的脱敏研究数据。在数据质量保证与控制方面,研究中心按照SOPs标准采集数据。在完成数据初步输入后,改动时间、原因、人员名称、数据变更类型及研究人员的反馈和改进建议等都会被记录在质量协议中,便于保证研究数据的质量,确保最终研究结果的可靠性。研究中心的数据质量管理工作由其质量控制负责人全权负责,直接向研究中心主任进行报告。
权限中心:对于研究中心收集的数据,权限中心将自动生成统计结果(仅包含脱敏参与者的数据)。这样不仅可以判断研究中心收集数据的平均水平,也可明确总数据中缺失的数据类型。权限中心将统计数据提供给中央质量办公室的管理人员,以评估数据质量并及时提出必要的质量改进措施。每个权限中心负责特定研究主题数据(如来自ECG及MRI的数据)的质量保证与控制评估。此外,权限中心需制定质量要求,若质量出现问题及时与整合中心进行沟通并采取措施。
中央质量办公室:负责监督与数据质量有关的各流程,确保所有流程都依据SOPs标准执行,并对传输到中央管理处研究数据库的数据进行科学评估,而且需派代表参加质量管理工作组的会议。
4.4.2 外部质量管理
外部质量管理的主要任务是审查研究数据的质量,主要以专家小组(如实验室专家)实地考察的形式实施,然后由专家小组撰写质量审查结果报告,并针对审查结果,与中央质量办公室进行分析和讨论。
5 启示
随着我国社会经济的发展和人们生活方式的转变,以心脑血管疾病、慢性阻塞性肺部疾病、糖尿病、精神障碍和重性精神病等为代表的慢性病发病率呈现快速上升趋势[14]。我国进行人群队列研究已有60多年的历史,如对煤矿工人、化工染料行业工人、金属矿业工人和石棉工人在从业过程中所接触的有害环境物质暴露和疾病发生的相关性研究,北京首都钢铁公司总医院在20世纪70年代在北京首都钢铁公司及周围农村地区进行心脑血管病危险因素调查[15],首都医科大学附属北京朝阳医院于2006年在唐山开滦地区建立包含101 510名人群的研究队列[16]及中国国家前瞻性队列——中国慢性病前瞻性研究(China Kadoorie Biobank,CKB)[17]等。我国所开展的多个大型人群队列在揭示我国居民疾病病因学方面取得了一系列原创性的研究成果,但仍存在一些问题,落后于德国和英国等医疗体系发达的国家。
我国现有队列研究的不足及德国国家队列对我国队列研究的启示如下。
5.1 数据质量管理方面——统一数据标准、多源分类存储
数据的分类管理既有利于数据的管理维护,也为数据的整合挖掘提供了便利。GNC的各研究中心均采用相同的设备器材、操作流程和标准采集数据,这从根本上保障了数据采集的一致性。针对不同种类数据,GNC分别设立了不同类型的数据库进行分类整合存储。当前我国人群队列数据采集是对医疗记录实行综合采集,增加了数据共享、交换、合并的难度。联盟的原始队列间的操作流程不统一,会导致数据质量良莠不齐,甚至由于采集流程、环境和技术不同导致采集数据不可用。因此,在队列数据采集之前,需分配相同的设备器材,采用统一的操作流程、标准采集数据,便于从根本上保障数据采集的一致性。此外,对于不同种类数据进行分类整合存储,既有利于数据的管理维护,也便于进行多源数据的整合挖掘。
5.2 数据广度和深度方面——使用辅助数据、减少分析误差
辅助数据的使用及MRI技术的实施是德国国家队列的显著特色。通过对受试者的脑、心脏、全身等进行MRI,有助于提高数据的完整性和减少数据分析误差。辅助数据的使用能够提高国家队列的科学价值,具体体现在:辅助数据的获取不受个体约束,可帮助减少数据分析中的系统误差和随机误差,有助于采集数据的完整性和准确性。
然而,目前我国开展的队列研究主要围绕传统环境暴露、生活习惯、 饮食、遗传因素在疾病发生中的作用开展,缺少对疾病病理、环境暴露、社会和行为及遗传因素导致的个体间变异的识别。关于人群社会、经济和心理因素的队列研究尚未见报道,导致很多人使用药物无效。队列研究应充分考虑环境、社会与遗传等多因素之间的交互作用对疾病发生、发展的影响。
5.3 数据共享方面——明确受试者权益、规范共享流程
GNC规定数据申请者禁止直接向受试者申请数据,这既有利于保护受试者隐私,也有利于保证数据使用的道德规范。虽然数据申请者不能向受试者申请数据,但受试者在数据申请的过程中享有决定权,有权允许或禁止申请者使用或访问其数据,这表明了对受试者权利的尊重。目前我国各人群队列采集的数据主要用于内部研究,受试者对其数据不享有任何权利,参与性差。这既不利于保护受试者的隐私,也不利于各机构研究者之间的交流和队列研究的可持续性发展。今后我国应从法律层面明确受试者的权益,保证数据使用遵循道德规范;加强大型队列研究的宣讲,让受试者明确自己的权利和义务,调动公众参与的积极性;倡导开放式队列研究理念,促进队列研究价值的深度发掘;设立国家队列协会,统一管理队列数据共享事务,鼓励数据使用和结果的共享,扩大队列数据影响力,促进我国卫生健康事业的发展。
猜你喜欢
中国心血管杂志(2022年2期)2022-11-25
中国心血管杂志(2022年4期)2022-11-25
中学生数理化·高一版(2021年2期)2021-03-19
中国心血管杂志(2021年6期)2021-01-02
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
中国心血管杂志(2019年3期)2019-01-04
军营文化天地(2018年2期)2018-12-15
产品可靠性报告(2017年7期)2017-09-05
数学学习与研究(2017年3期)2017-03-09
