
适用于PDF文本内容的高效模式匹配算法*
2018-03-21 00:56朱玲玉王旌舟陈庆春
通信技术 2018年3期
朱玲玉,王旌舟,陈庆春
0 引 言
模式匹配在网络入侵检测、生物序列数据库比对(DNA)、信息检索、生物计量学等领域得到了广泛应用。模式匹配按同时匹配模式串的个数,分为单模式匹配和多模式匹配,其中KMP[1]、BM[2]为经典单模式匹配,AC[3]、WM[4]算法为经典多模式匹配。每种模式匹配算法都有其最优、最坏匹配复杂度,针对不同模式串的类型,其算法各有优点。
随着信息时代和大数据时代的快速发展,网络安全监管快速兴起,网络空间安全成为了热点。PDF是Portable Document Format(便携文件格式)的缩写,是全世界电子版文档分发的公开实用标准。作为一种通用文件格式,PDF能够保存任何源文档的所有字体、格式、颜色和图形,而不关心创建该文档使用的应用程序和平台。网络中越来越多的文件开始倾向于采用PDF这一主流的文本保存格式。随着PDF文档的广泛使用,PDF文件内容的保密性和安全性问题日益凸显。本文结合PDF文件格式及其编码规则,分析研究BM、QS[5]算法,并分析了一类适用于PDF文件的高效匹配算法,以支持涉密PDF文件内容的高效管控应用。
1 PDF文件格式及编码规则
PDF文档是8 bit字节序,以二进制流保存。深入理解PDF文件的格式,需从其对象、文件结构(逻辑结构)、文档结构(物理结构)、内容流和编码4方面理解[6]。
PDF文件实质由一系列对象构成,这些对象分别有8种基本数据类型,即逻辑对象、名字对象、字典对象、字符串对象、流对象、数组对象、数值对象和空对象。这些基本数据类型的对象是直接对象,可被标识,以便作为间接对象被其他对象引用。文件结构(物理结构)由文件头(head)、文件体(body)、交叉引用表(xref)和文件尾(trailer)构成。PDF文件具有层次化结构,其根部为文档目录字典对象,根据其引用的对象获得其他对象内容,进而找到文本内容。例如,可以从文件尾部找到根/root,找到其引用对象的catalog,再通过字典目录中的信息/pages找到页面对象pages,依次找到page对象,最后通过/content找到其文本内容流和编码信息。
PDF文本内容在操作符TJ/Tj的前面,其文本内容以16进制表示,一般情况表示在一对尖括号里面,如<2B0955853D96>TJ,其编码一般有unicode编码、GBK编码和CID编码[7]。大多数PDF文件的文本内容都存在一个映射关系,如GBK编码的,TJ前面16进制的文本内容可通过cmap文件(GBK编码映射)映射到真正文本的内容。由于中文字符是宽字符(多字节字符)且数量巨大,为减小PDF文件的大小,中文汉字使用CID编码,即PDF文件的文本内容不是Unicode编码。为了得到能够显示的Unicode编码,需要一个从CID编码到Unicode编码的转换过程。无论怎么映射,其文本内容显示基本就是以16进制表示的,4个字符为一个字。进行敏感信息(关键字)查找时,也是从TJ前面的内容出发。以下首先概要介绍一些经典的模式匹配算法,然后在此基础上,提出一种适合PDF文本内容匹配的高效算法。
2 经典单模式匹配算法
2.1 模式匹配
迄今为止,国内外学者在KMP、BM等经典匹配算法的基础上,提出了不少改进的单模式匹配算法,如BMH、QS等。此外,存在大量利用移位表、匹配方向的改进算法。这里介绍经典的单模式匹配算法,如基于后缀比较的BM算法和基于下一字符的QS算法。
所谓模式匹配即给定字符集ξ,给定文本串T,长度为n,有:

给定模式串P,长度为m,有:

在文本串T中匹配到给定的字符串P,若字符串P出现在文本串T中,即:

则匹配成功且匹配的位置为i。
2.2 BM算法
BM算法是Robert S. Boyer和J.Strother Moore于1977年共同提出的一种亚线性的单模式匹配算法。实际应用中,BM算法相对于其他算法,被普遍认为是一类高效算法。它的基本思想:基于后缀匹配,从右至左进行匹配,通过已获得的信息(移位表)跳过文本串中的某些字符,实现最大程度的移位。
BM算法分为2部分——预处理和匹配过程。预处理阶段利用模式串信息构建移位表,即BM坏字符表(bmBc)和BM好后缀(bmGs)。这是该算法的核心。
2.2.1 预处理过程
预处理过程建立坏字符表、后缀表。坏字符是指从左至右进行匹配时,一旦失配,该字符被称为坏字符。好后缀是指模式串左边出现了模式串右侧的字符串。以模式串“GCAGAGAG为例”构建坏字符表和好后缀表,结果如表1、表2所示。
坏字符规则存在2种情况:一是失配字符出现在模式串中,令失配字符对齐模式串中靠右的字符,如图1所示;二是失配字符未出现在模式串中,无论怎么移位,该字符都会产生失配,即移位至失配字符的下一位,如图2所示。所以,模式例坏字符表计算结果如表1所示。
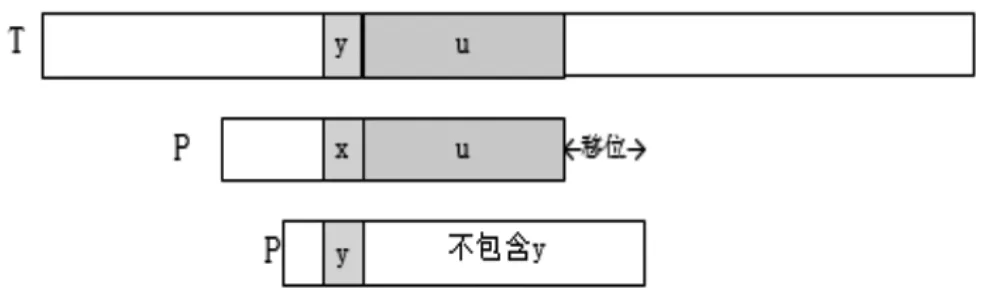
图1 有失配字符坏字符移位
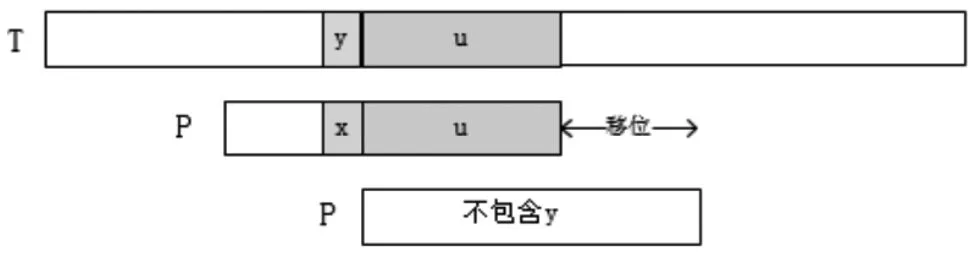
图2 无失配字符坏字符移位

表1 BM坏字符表
好后缀的计算规则也存在2种情况:一是模式串中左侧存在已匹配全部字符,移位对齐已匹配的字符且前一字符不等于失配字符,如图3所示;二是左侧存在已匹配的部分字符(后缀),移位与之对齐,如图4所示。所以,模式例的好后缀表的计算结果如表2所示。
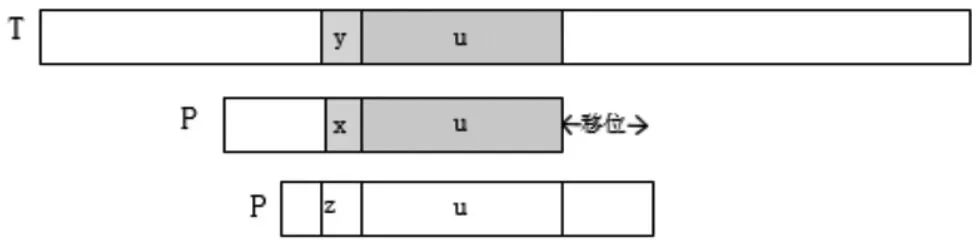
图3 无失配字符好后缀移位
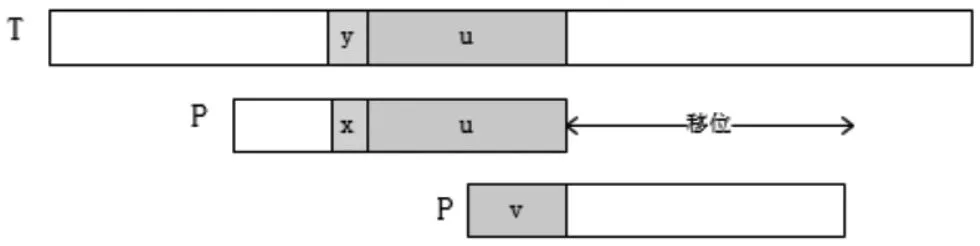
图4 有失配字符发好后缀移位

表2 BM好后缀表
2.2.2 匹配过程
建立好后缀坏字符表后,从右至左开始匹配。一旦发生失配,比较好后缀和坏字符表,取最大值进行移位,进行下一次匹配,而对已匹配成功的返回其位置。
该算法在文本串长度为n、定位长度为m的模式串中,其预处理阶段的时间、匹配过程、最优时间复杂度分别为 O(m+σ)、O(mn)、O(m/n)。
2.3 QS算法
QS算法是Daniel M.Sunday提出的一种简单快速单模式匹配算法,也称Sunday算法。Sunday通过对模式串扫描的顺序不同给出了三种算法,其中有QS算法、MS算法和OM算法。MS算法的扫描顺序为移位的大小降序,OM算法的扫描顺序取决于其字符出现频率的大小。
QS算法实质是BM算法的一种简化版本,其实现更简单,仅利用了BM算法中的坏字符规则。基本思想:在进行字符串匹配时,无论匹配方向从左至右还是从右至左,无需考虑匹配顺序,由于发现不匹配会至少移动一位,因此须考虑该匹配窗口的下一字符是否出现在模式串中,利用BM算法的坏字符规则计算其移位后再进行匹配。因此,可利用下一字符来实现最大跳跃,使之最大位移为m+1。
2.3.1 预处理过程
预处理过程实质是利用BM坏字符规则建立移位表。移位表建立也从字符是否在模式串及其位置考虑。若模式串中并未出现下一字符,则移位跳过该字符,再在匹配窗口进行匹配;若在,移位与之对齐。移位计算公式为:
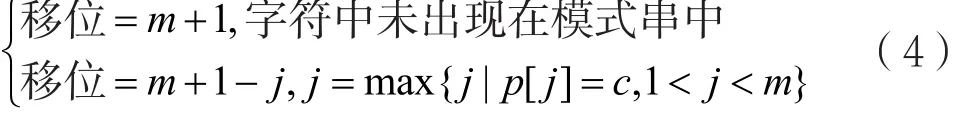
以BM算法的模式串为例,其移位表qsBc如表3所示。

表3 QS下一字符移位表
2.3.2 匹配过程
建立好下一字符移位表后,无需像KMP、BM算法按顺序进行字符比较,即一旦发生不匹配,考虑该匹配窗口的下一字符,判断是否存在于模式串中,移位后继续进行匹配。
该算法在文本串长度为n、定位长度为m的模式串中,其预处理阶段的时间、空间、匹配过程、最优时间复杂度分别为 O(m+σ)、O(σ)、O(mn)、O(n/(m+1))。该算法的问题在于,当出现下一字符移位距离小于失配字符的移位距离时,将导致QS算法效率大打折扣。
一般情况下,QS算法适用于短模式和大字符集的情形下,实现简单。
3 改进算法
3.1 算法思想
基于BM算法中的坏字符移位规则思想和QS算法的下一字符思想,结合PDF文件文本内容的编码特点,提出了一种适用于PDF文档内容匹配的快速算法。
该算法匹配顺序和BM算法一样,采纳后缀匹配,即在模式匹配窗口中,从右自左进行字符的比较。若模式串已经和文本串成功匹配,将利用QS的下一字符思想,比较该匹配窗口的下4个字符和模式串的前4个字符。一旦发生不匹配,必然会发生移位,且至少移动4位(PDF文本内容的一个字为4个字符)。因此,利用QS算法的下一字符思想,该匹配窗口的下4个字符可以考虑是否出现在模式串相应位置,然后利用BM算法的坏字符计算规则得到移位表进行移位,使最大移位为m+4,提高匹配的效率。
3.2 算法预处理过程及匹配过程
该算法包含预处理过程和模式匹配过程。预处理阶段,需要计算坏字符移位函数Skip。移位函数计算和BM坏字符表的计算有一定区别。改进算法中无需计算模式串中的每一字符的移位。由于是从右至左开始匹配,不匹配移位至少4位。由于是大字符集,所以考虑每一字的最高位字符的移位表。移位表计算如下:

匹配过程如下。从右至左开始匹配,一旦不匹配,立刻利用该匹配窗口的下4个字符,判断其最高位的字符是否出现在模式串中的相应位置上。如果没有,说明这4个字符也不可能与模式串匹配成功,则直接移位m+4;否则,移位模式串到其对应处。
3.3 算法实例
以PDF文档为例,考虑如下的文本串:
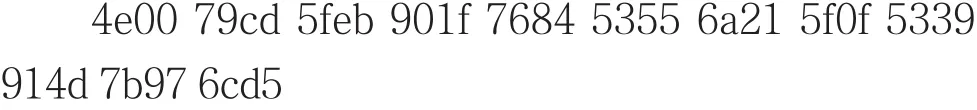
模式串:5339 914d。
首先进行预处理,如表4所示。

表4 Skip表
第一次:4e00 79cd 5feb 901f 7684 5355 6a21 5f0f 5339 914d 7b97 6cd5 5339 914d
T[6]≠P[6],则考虑匹配窗口的下4个字符的高位b。字符b未在模式串相应的高位出现,此时T[11]≠P[3]≠P[7],移位12位。
第二次:4e00 79cd 5feb 901f 7684 5355 6a21 5f0f 5339 914d 7b97 6cd5 5339 914d
T[19]≠P[7],则考虑匹配窗口的下4个字符的高位5。字符5未在模式串相应的高位出现,此时T[23]≠P[3]≠P[7],移位12位。
第三次:4e00 79cd 5feb 901f 7684 5355 6a21 5f0f 5339 914d 7b97 6cd5 5339 914d
T[31]≠P[7],则考虑匹配窗口的下4个字符的高位9。字符9在模式串相应的高位出现,T[35]≠P[3],移位8位。
第四次:4e00 79cd 5feb 901f 7684 5355 6a21 5f0f 5339 914d 7b97 6cd5 5339 914d
发现匹配,考虑匹配窗口的下4个字符,发现字符7未出现在模式串相应的高位,即移位后不可能出现匹配,则移位12位。
第五次:4e00 79cd 5feb 901f 7684 5355 6a21 5f0f 5339 914d 7b97 6cd5 5339 914d
匹配结束。
改进算法与QS算法一样,可能存在一个问题,即当下4个字符存在于模式串且可能靠模式串右边一点,但该匹配窗口的最右端的字符并未出现在模式串中,这时只根据下4字符判断移位,可能会使移位距离减小,增加比较的次数。因此,可考虑利用BMH算法[8]的最后一个字符的移位表和下4字符的移位表进行比较,选择最大移位。某些情况下,选两者进行比较,可能会提高效率。
4 测试结果
模式匹配需高效定位模式串。为了更好地对以上提到的算法及改进的算法进行性能分析,对其整个匹配过程所需时间进行了测试。实验环境为win7 64位操作系统,配置为Intel(R)Core(TM)i7-2670QM CPU @2.20 GHz 2.19 GHz,内存为4 GB,C语言编程。由于PDF文件解析过程相对复杂,这里实验文本采用模拟PDF文本内容的txt文本进行实验,其文件大小为8.76 MB,内容为2 296 856个汉字,即9 187 584个字符,然后对其分别进行字符长度为 4、8、12、16、20、24、28、32、36、40的模式串匹配。为减小误差,分别对每种匹配算法、不同长度模式串测试10次取其平均值,测试结果如表5所示。

表5 不同模式串长度、不同算法CPU耗时 /ms
从表5可以看出,改进的适合PDF文本内容的匹配算法更高效,时间复杂度更小,对比如图5所示。

图5 PDF文档内容搜索时间对比
针对不同长度的模式串,对BM、QS、改进算法的匹配次数进行比较,如图6所示。

图6 PDF文档内容匹配次数对比
匹配算法效率跟模式串有一定关系,QS、BM算法匹配效率与模式串长度密切相关,QS、BM算法最大移位距离与模式串的长度m有关,其最大移位距离为m+1、m。其中,QS是BM的简化版,实现简单,但存在下一字符在模式串中导致移位距离相对于BM减小的情况。
由图5、图6可以看出,相比于经典算法,改进算法的时间耗时和匹配次数最小,整体呈现出长度越大耗时越小的趋势。
此外,针对改进算法,对模式串占比情况进行匹配次数和时间耗时的测量,结果如图7、图8所示。
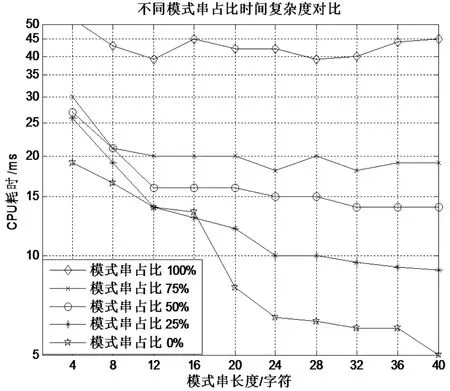
图7 PDF文档内容搜索时间
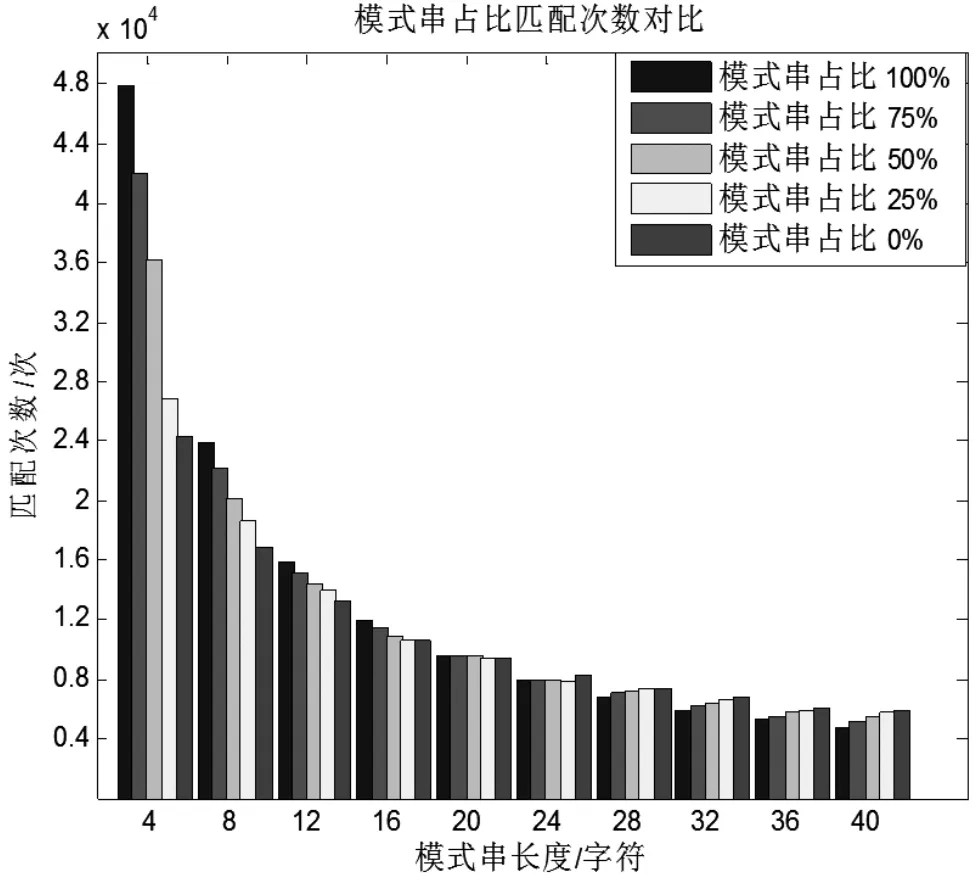
图8 PDF文档内容匹配次数对比
由图7、图8可以看出,模式串长度越大、模式串占比越小,时间耗时越小;但同样占比情况下,模式串的长度越大,匹配次数一般先减小后增大,但总体性能都较好。
改良算法利用BM、QS各自的优点,结合PDF文本内容编码方式,利用BM的坏字符规则和QS的下一字符思想,只生成每个字高位的移位距离,使最大移位距离为m+4。由图5、图6可知,所提算法的匹配效率高于BM、QS都高,提高了PDF文本环境中仿真性能。
5 结 语
本文通过对PDF文件格式和文本内容的分析,分别阐述了BM算法、QS算法的基本思想及匹配过程,提出了一种适合用于PDF文件文本内容的匹配算法。实验证明,改进算法在时间性能上有一定提高,实现也更为简单,但存在与QS算法一样的问题。目前,PDF文件的格式越来越复杂,还需进一步改进,使其在实际应用中更实用。
[1] Knuth D E,Morris J H,Pratt V R.Fast Pattern Matching in Strings[J].SIAM J. Comput.,1977,6(01):323-350.
[2] Boyer R S.A Fast String Searching Algorithm[J].Communications of the Acm,1977,20(10):762-772.
[3] Aho A V,Corasick M J.Efficient String Matching:An Aid to Bibliographic Search[J].Communications of the Acm,1975,18(06):333-340.
[4] Wu S,Manber U.A Fast Algorithm for Multi-pattern Searching[Z].Report TR-94-17,Department of Computer Science,University of Arizona,Tucson,AZ,1994.
[5] Sunday D M.A Very Fast Substring Search Algorithm[J].Communications of the Acm,1990,33(08):132-142.
[6] Inc A S.PDF Reference:Version 1.7[Z].2006.
[7] Adobe Systems Inc.Adobe Technote 5014:Adobe CMap and CIDFont Files Specification,Version1.0[EB/OL].Adobe Systems Inc.http://partners.adobe.com/public/developer/en/font/5014.CIDFont_Spec.pdf.
[8] Horspool R N.Practical Fast Searching in Strings[J].Softw. Pract. Exp.,1980,10(06):501-506.
猜你喜欢
电机与控制应用(2022年4期)2022-06-27
国际医学放射学杂志(2021年3期)2021-11-30
电子制作(2021年11期)2021-06-17
电子制作(2019年13期)2020-01-14
移动信息(2018年1期)2018-12-28
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
雷达学报(2018年3期)2018-07-18
计算机系统应用(2018年4期)2018-05-04
中国新通信(2016年17期)2016-11-17
电脑知识与技术·经验技巧(2016年1期)2016-03-14
