
基于LSTM算法在新闻分类中的应用
2018-03-18 09:06朱肖颖赖绍辉陆科达
梧州学院学报 2018年6期
朱肖颖,赖绍辉,陆科达
(1.2.3.梧州学院 大数据与软件工程学院,广西 梧州 543002)
0 引言
随着经济的发展,互联网成为了人们生活不可缺少的一部分,方便了人们生活的方方面面。但互联网上的新闻信息鱼龙混杂,且每天都以爆炸式的趋势在增长,用户想大致浏览新闻信息非常困难,想在大量的信息中精准地获取自己感兴趣的信息更是难上加难,因此迫切需要对互联网新闻信息进行有效的分类整理。文本分类技术是实现信息重组、文本数据挖掘的基础,可以在很大程度上解决互联网新闻信息杂乱无章的问题,帮助用户快速准确地定位所需信息,是当下处理大规模数据信息的重要手段。针对大规模新闻数据信息整理的问题,不少学者将文本分类技术引入其中,如张志平采用“中文新闻信息分类与代码”文本分类体系[1];徐保鑫等将朴素贝叶斯算法应用到我国的新闻分类中[2];蓝雯飞等的研究采用卷积神经网络新闻分类体系[3]。但张志平等的研究只是针对小规模的数据,在处理大规模数据的过程中算法模型需要耗费大量的时间;徐保鑫等使用的朴素贝叶斯算法属于传统机器学习分类算法,在训练模型的过程中需要手动提取文本特征,处理效率较差;蓝雯飞等采用的CNN算法由于自身的卷积功能对文本的整体结构有一个统揽的能力,所以在短句子配对上占有一定的优势,而在处理长句子时,卷积神经网络只能处理窗口内的信息,相邻窗口信息的融合需要借助后一层卷积层,这加大了对卷积窗口和移动的步长参数的依赖,即存在调参难度大的问题。因此本文利用TensorFlow平台搭建了基于LSTM循环神经网络的新闻分类算法,从时间上、质量上对新闻分类进行了优化。
1 LSTM算法概述及框架结构
1.1 LSTM算法概述
LSTM(Long Short Term Memory Network,长短期记忆网络)算法是一种能长久储存序列信息的循环神经网络,在语言分类模型、机器翻译、语音识别等领域都得到了广泛的应用[4]。LSTM适合处理和预测时间序列中延迟和间隔相对较长的重要事件,可以通过刻意的设计来避免长期依赖问题。实践证明,记住长期的信息是LSTM算法自身具备的能力,不需要付出很大的代价。
LSTM是一种特殊的RNN(Recurrent neural network,循环神经网络),RNN作为神经网络的总称,常用于处理一系列的序列数据,是深度学习中序列处理的关键技术[5]。目前已在语音识别、语言处理、机器翻译、视频识别等领域取得突破性的进展,然而梯度消失现象制约着RNN的实际应用。为了解决该问题,研究人员提出了许多解决方法,其中最为成功且应用最为广泛的就是加入门限机制的RNN,而LSTM就是门限RNN中使用最广泛的一个。LSTM的特别之处在于通过新增输入门、输出门和遗忘门3个门限来改变自循环的权重,通过这种方式,只要模型参数固定不变,就可以保证不同时刻的积分尺度动态改变,从而有效地避免梯度消失/梯度膨胀的问题。
1.2 LSTM算法框架结构
由于LSTM由RNN演变而来,在介绍LSTM算法模型的框架结构之前,先来介绍一下RNN的模型结构,方便大家理解。RNN的算法结构如图1所示。
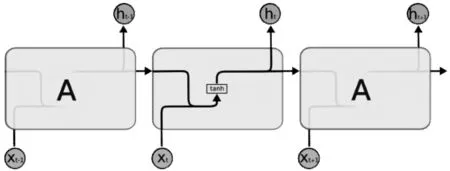
图1 RNN的算法结构
由图1可知,传统RNN中每一步的隐藏单元只是执行一个简单的tanh操作。
LSTM的算法结构如图2所示。
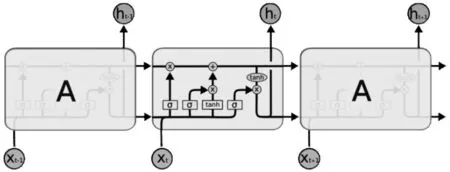
图2 LSTM的算法结构
图2中各标记的含义如下页表1所示。
表1 LSTM算法结构标记含义表
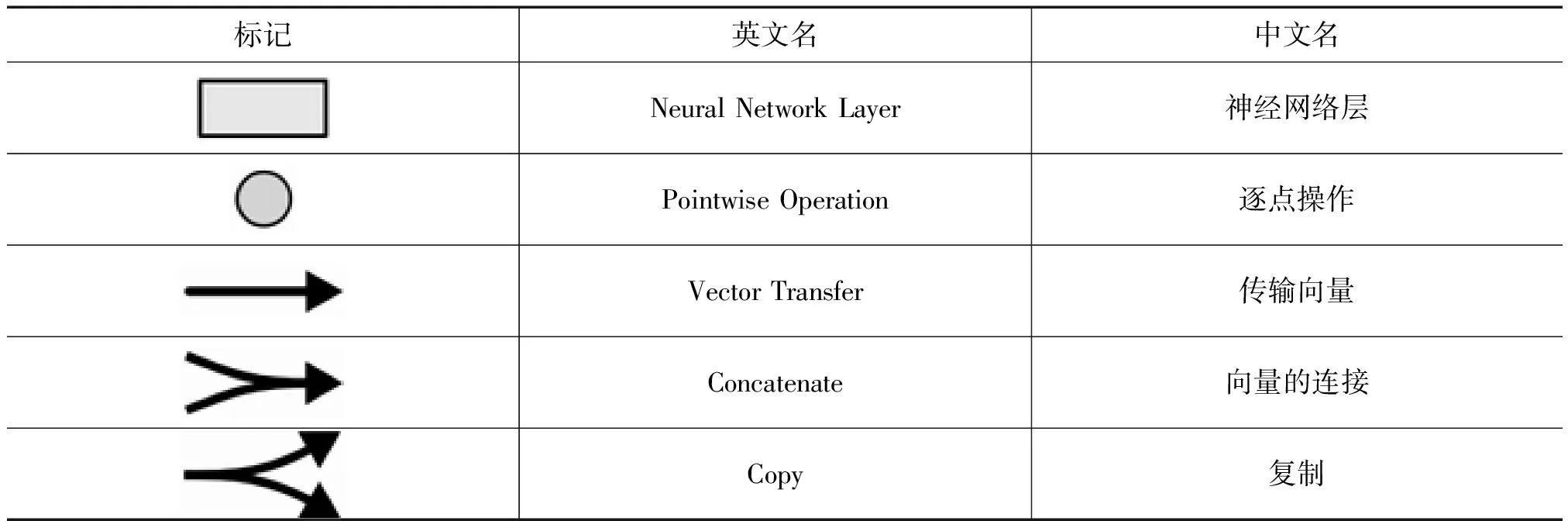
标记英文名中文名Neural Network Layer神经网络层Pointwise Operation逐点操作Vector Transfer传输向量Concatenate向量的连接Copy复制
由图2可知,LSTM的网络结构大体上和传统RNN相似,重复结构A看起来也比RNN要复杂一些,但分开解释就变得很简单了。
LSTM的关键之处在于cell的状态和横穿cell的水平线,cell状态的传输类似于一个简单的传送带,传送带结构如图3所示。信息横穿整个cell的过程中只做少量的线性操作,即这种结构能轻松地实现信息横穿而不做任何改变。但这样的结构无法实现信息的添加和删除操作,从而引入了“门”结构,“门”结构如下页图4所示。“门”结构的引入实现了对信息的自主选取通行,而这一功能的实现主要依靠一个sigmoid神经层和一个逐点相乘之间的相互操作。
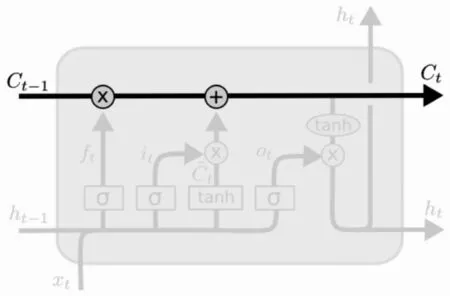
图3 传送带结构
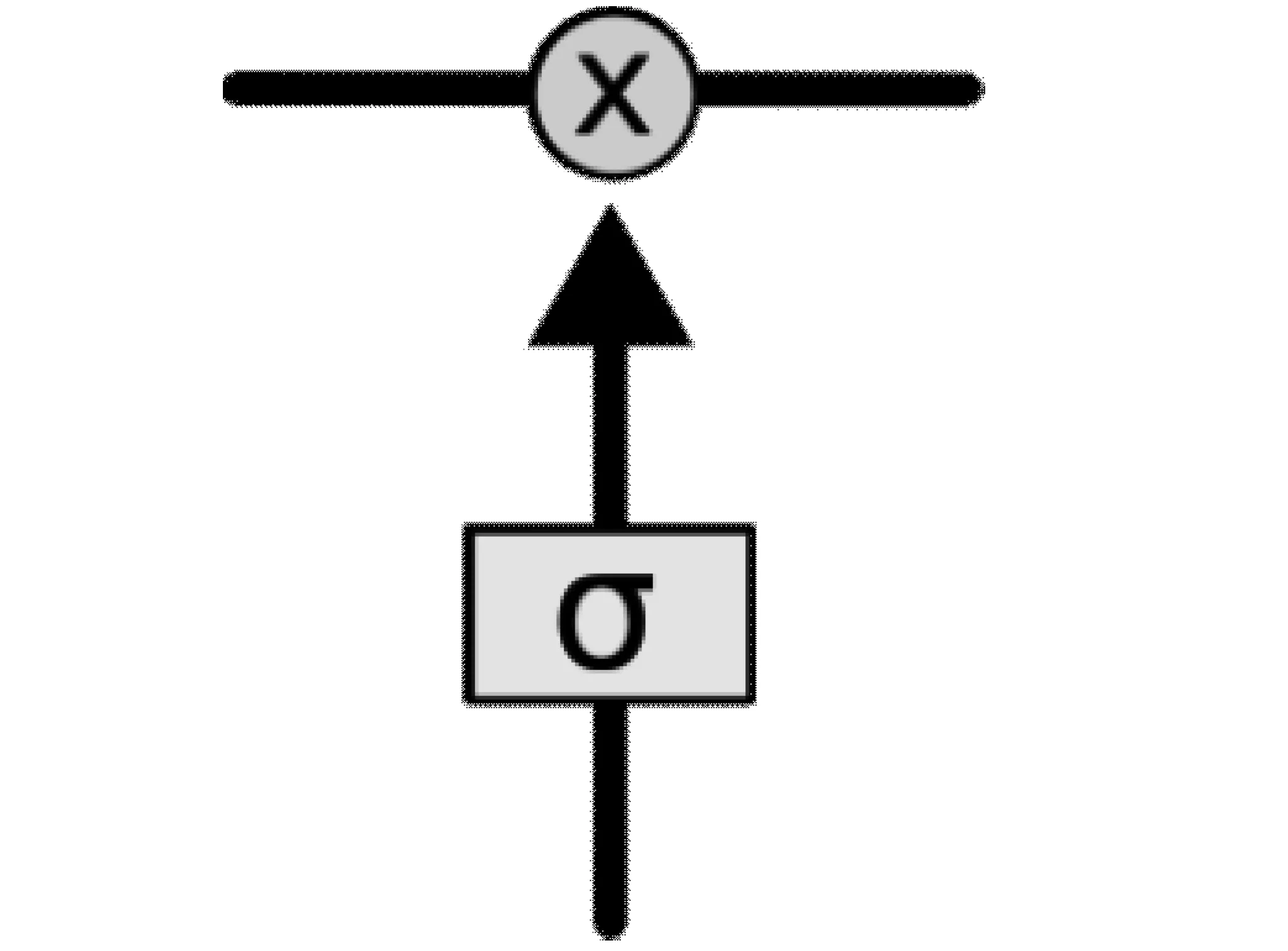
图4 门结构(sigmoid层)
sigmoid神经层输出的都是实数,而且都处在0和1之间,0和1表示允许信息通过的占比,其中0表示“不允许任何信息通过”,1表示“允许所有信息通过”。
(1)遗忘门
在信息通过cell时,遗忘门(forget gate layer)可以决定哪些信息应该被遗弃。A结构中,输入的ht-1和xt就是通过cell的信息,而输出的信息为一个处在0和1之间的实数,实数和cell状态中的Ct-1一样,表示让Ct-1的各信息通过的占比。遗忘门结构如图5所示。
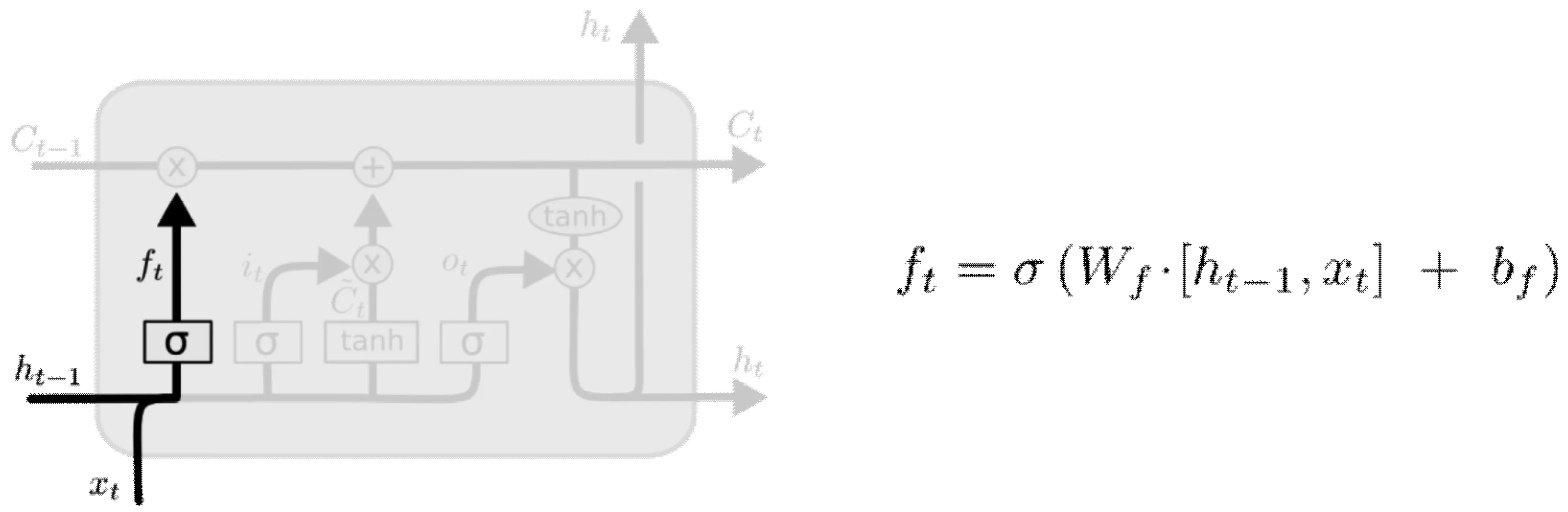
图5 遗忘门(forget gates)
(2)传入门
传入门(input gate layer)用于决定哪些信息需要加入到cell状态中,这个过程分两个步骤,首先,由sigmoid 层决定更新的信息有哪些,而tanh层则会生成一个向量,此向量表示用于更新的备选内容Ct。其次,会将第一步骤中的两部分信息联合起来,对整个cell的状态进行更新。传入门结构及更新cell状态分别如下页图6、图7所示。
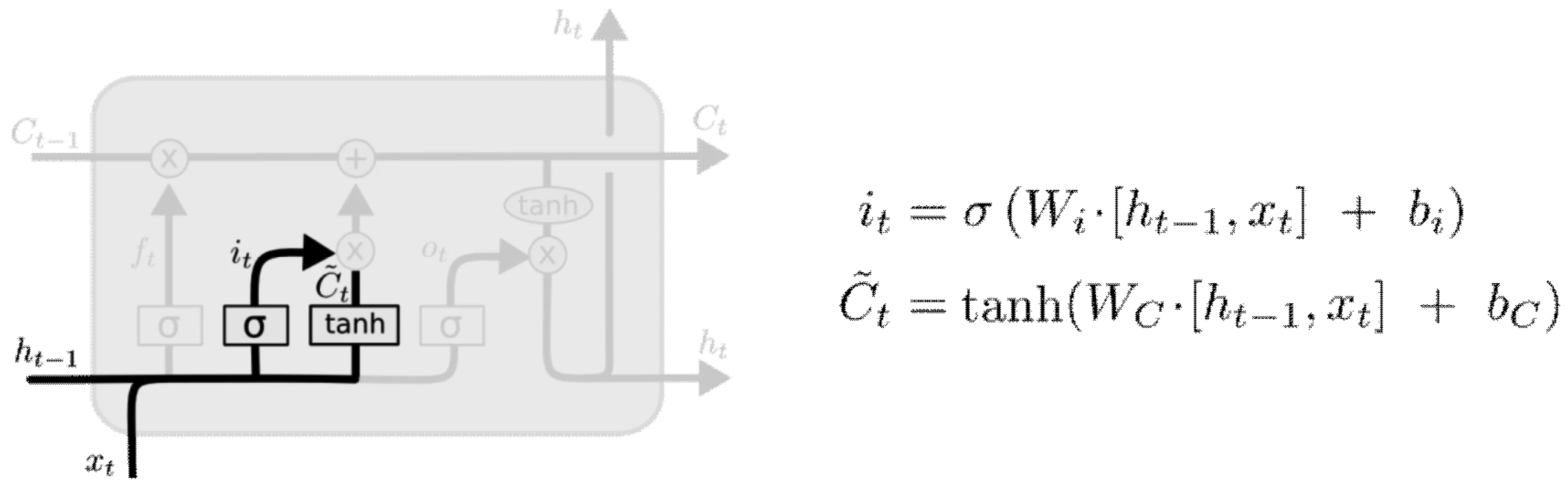
图6 传入门(input gates)
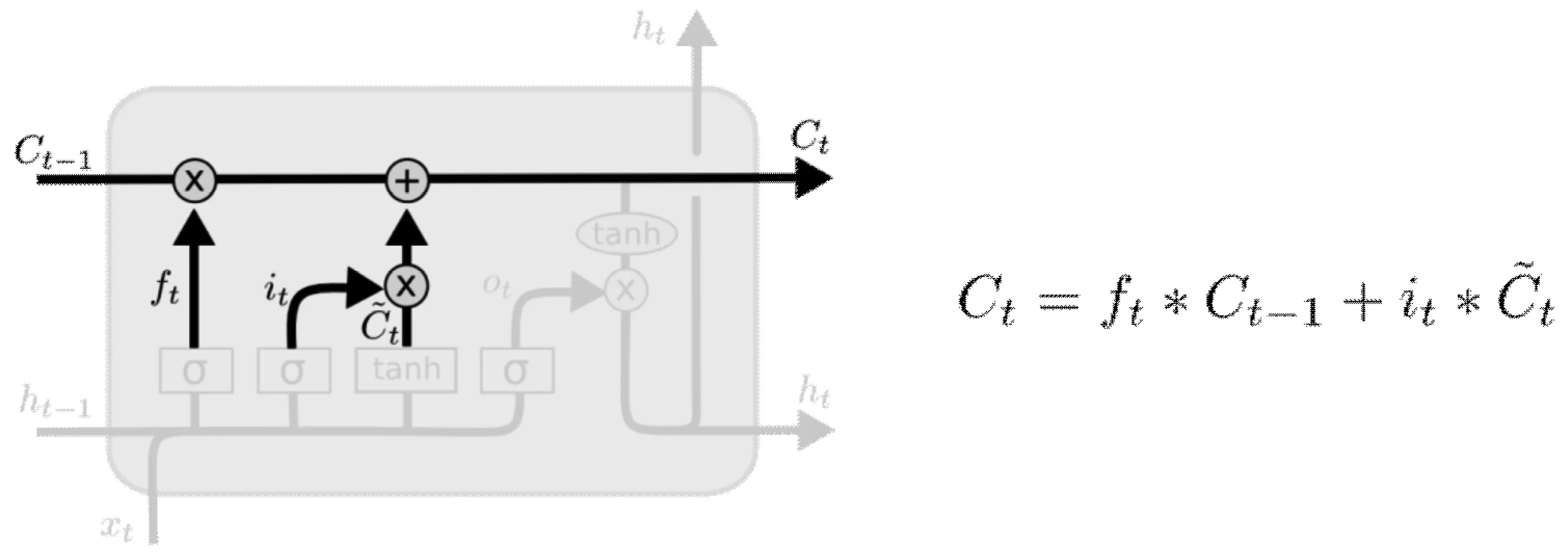
图7 更新 cell 状态
(3)输出门
输出门(output gate layer)用于决定最终输出什么样的信息,这里输出的信息主要由cell状态中的Ct决定,但又不全是Ct,还需要经过过滤的处理。这个过程也分为两个步骤,首先,由sigmoid层决定哪些信息应该被输出,而此时的tanh层会对Ct进行过滤处理,将Ct的值归到-1和1之间。其次,再将第一步中sigmoid层的输出和tanh层的输出进行权重相乘,从而得到最终的输出结果。输出门结构如图8所示。
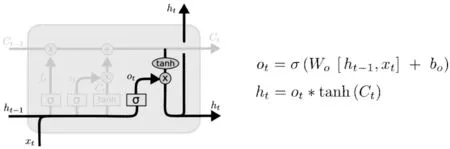
图8 cell 输出
3 LSTM算法模型结构
本文采用LSTM算法处理新闻分类的过程主要分成数据预处理(数据爬取和数据清洗),特征提取,模型训练,测试结果总共4个阶段,具体如图9所示。
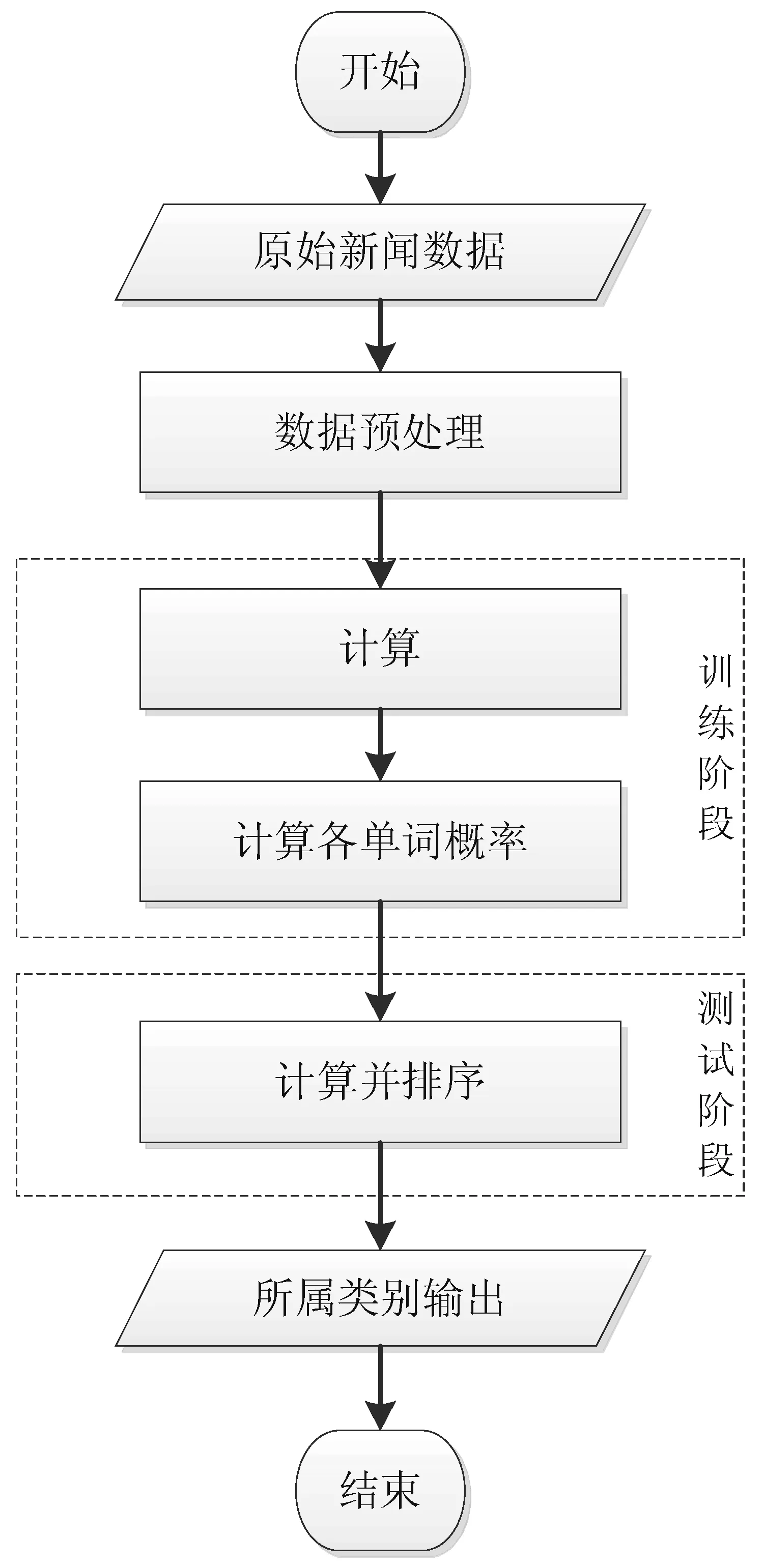
图9 LSTM算法处理流程
3.1 数据获取与预处理阶段
使用Python语言从“中国新闻网”上爬取新闻标题,数据规模达两百多万,其中,爬取的新闻标题附带有新闻类别标签,需要对爬取的所有原始数据进行转码,删除数字和空字符处理,并使用jieba分词器分词,去除标点符号,删除停用词。jieba分词有全模式jieba.cut和搜索引擎模式jieba.cut_for_search。
输入:原始新闻标题
输出:序列分词文件
如输入:seg_list = jieba.cut_for_search(“清华大学计算机系冠名教授基金捐赠仪式举行”,cut_all=True)
输出:清华,大学,计算机,系,冠名,教授,基金,捐赠,仪式,举行
处理过程中由于新闻标题分类数据分布不均衡,会在一定程度上影响模型的准确度,为了达到数据均衡,笔者剔除掉了数据量少于3万条的类别和一些明显没有区分度的新闻类别,处理过后的数据集总共包含20个分类类别的220万条新闻的标题和对应的分类。其中20种分类如下:互联网、体育、健康、人文、军事、动物、历史、娱乐、房产、国内、教育、数码、旅游、时尚、汽车、游戏、社会、科技、艺术、财经。
3.2 特征提取阶段
本阶段对分词后的新闻列表进行特征提取,由于本文使用的是LSTM神经网络算法,首先将新闻列表数据映射为LSTM算法能处理的数据,并根据特征提取算法选出特征向量,本实验采用keras的Tokenizer来实现,具体步骤为:
Step1:将新闻标题处理成单字索引序列,字与序号之间的对应关系靠字的索引表。
Step2:所有分类标签使用数字从1开始映射,生成一个分类标签映射的列表,通过与数字映射生成一个字典,分别是{分类名称:数字}方便映射和查找。
Step3:将标题直接进行单字转换映射,生成基于字的映射字典,得到一个6820个字的字典。
Step4:将字映射为数字。
Step5:预训练word2vec向量。
word2vec使用分布式词向量的表示方式,通过训练模型将每个词映射成K个维度的实数向量后,再通过词与词之间的距离来判断它们之间的语义相似度[6]。word2vec有CBOW模型(Continuous Bag-of-Word Model)和Skip-gram模型(Continuous Skip-gram Model)两个重要的模型,本文采用CBOW模型预训练词向量,CBOW模型包含输入层,输出层和投影层三层结构,在已知wt上下文wt-2,wt-1,wt+1,wt+2 的基础上预测当前词wt,CBOW 模型处理结构如图10所示。
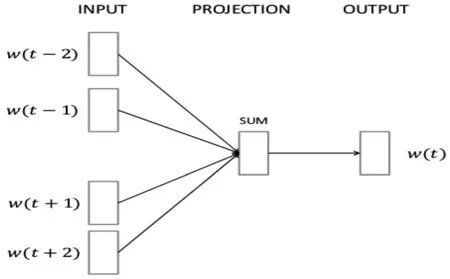
图10 CBOW模型结构图
在word2vec中,使用层次Softmax函数和负采样(Negative Sampling)来近似计算,目的是减少训练的时间,提高计算速度并改善训练后的词向量质量。NEG与层次Softmax函数相比,不再使用复杂的哈夫曼树,而是采用随机负采样的方法,降低负样本的概率同时增大正样本的概率。在CBOW模型中,已知词w的上下文为Context(w),需要预测词w,因此对于给定的Context(w),词w就是一个正样本,其他词就是负样本,对于一个给定的样本(Context(w),w),尽可能使它最大化。
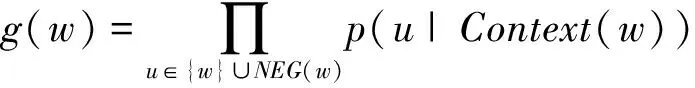
其中,NEG(w)表示负样本集合,正样本标签为1,负样本标签为0,其概率计算公式如下:
本实验先利用特定语料数据训练后的word2vec词向量做文本分类任务,在一定程度上能提升了词向量的表达能力。再使用Scikit-learn将数据按7∶1∶2的比例分为训练数据、验证数据和测试数据。
3.3 分类模型训练阶段
在新闻样本训练阶段,根据LSTM算法思想搭建LSTM模型,将文本处理成向量的 Embedding 层,这样每个新闻标题被处理成一个word_dict x 256 的二维向量,其中word_dict为每条新闻标题的长度,256为每一行的长度,整体代表这个词在空间中的词向量。操作流程如下:
Step1:LSTM层输出1维长度为256的向量。
Step2:Dropout层设置初始参数为0.5,避免产生过拟合现象。
Step3:Dense(全连接层)将向量长度收缩到20,对应上文提到的20种新闻分类。
LSTM训练模型结构如图11所示。
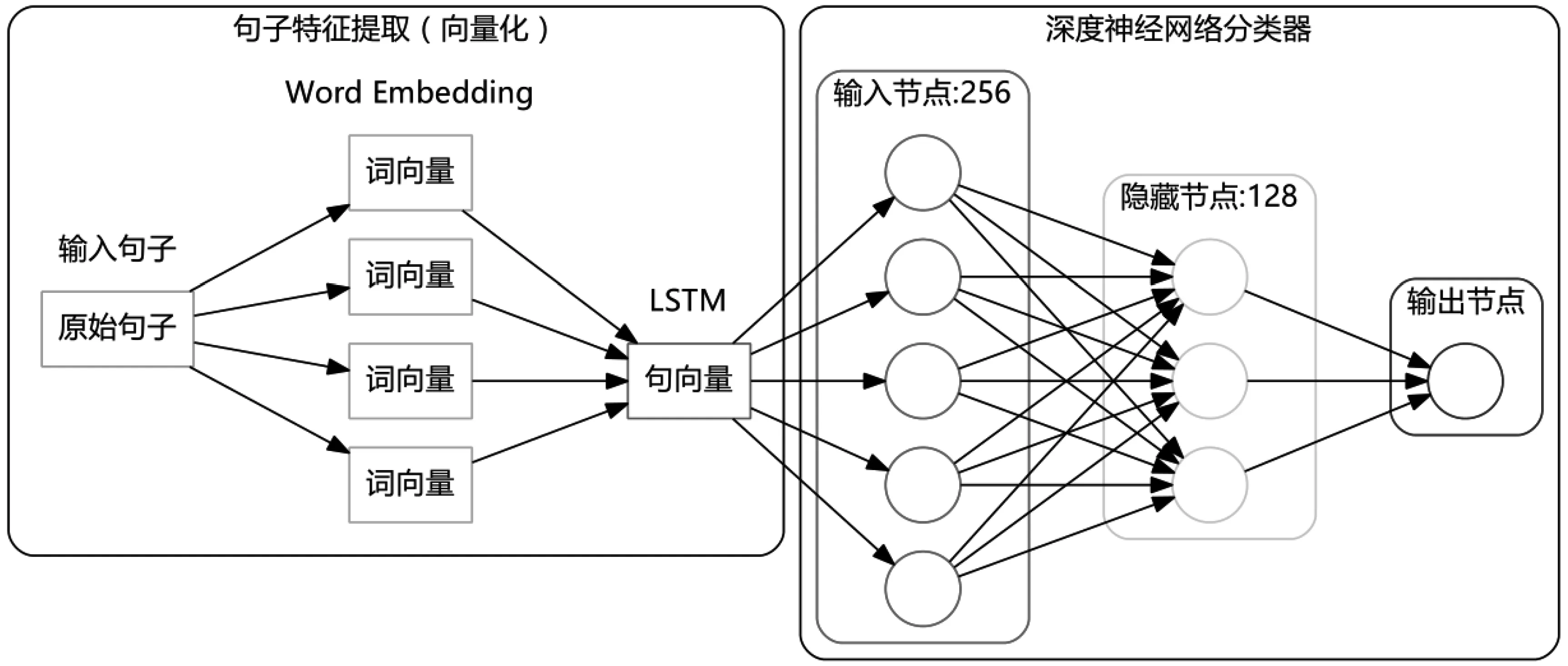
图11 LSTM训练模型结构
由于训练的结果为多分类,所以同步使用激活函数softmax,损失函数cross-entropy,优化器adam,训练过程中的batch_size设置为128,epoch设置为80,实际训练一个轮次大约10分钟,10个轮次后损失变化慢慢变小,最终准确率约为84%,实验结果如下页图12所示。
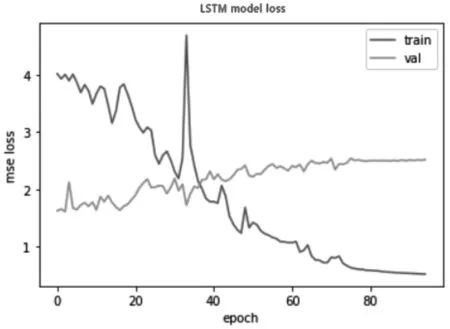
图12 LSTM模型训练loss-epoch关系
3.4 分类模型测试阶段
为了验证训练后的LSTM模型对新数据分类的准确度,本文采用准确率(Accuracy)作为评价分类模型的指标,将其中一个类别作为分类正类别,其余作为分类负类别,公式如下:
Accuracy=(TP+TN)/(P+N)
其中TP为被正确地划分为正类别标签的新闻数量,TN为被正确地划分负类别的新闻数量,P表示实际为正类别的新闻样本数量,N表示实际为负类别的新闻样本数量。
输入:测试训练集
输出:分类结果
测试结果如图13所示。
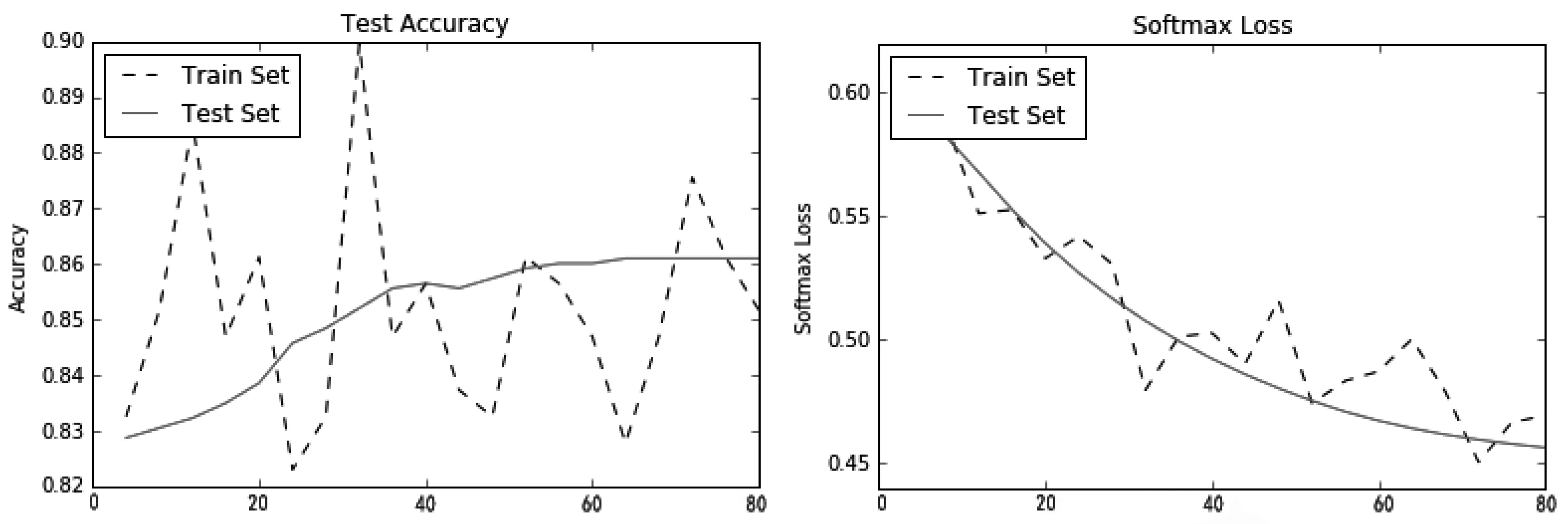
图13 测试训练结果图
可见,通过输入测试数据,输出结果的准确率能达到86%。
4 实验结果及分析
为了验证LSTM算法的准确度及效率,本文搭建了一个hadoop集群,由1个主节点master和4个从节点slave构成,硬件配置为Intel(R)Xeon(R)CPU E3-1270 V2 @ 3.50GHz,外加一块NVIDIA GTX1080 的GPU,内存为32GB,系统为Ubuntu 16.04,实验数据集来自Python爬取的两百多万新闻标题,实验过程将数据按7∶1∶2的比例分为训练数据集、验证数据集和测试数据集。
根据新闻标题对新闻进行分类的结果如表2所示,由表可知,军事和体育类的新闻准确率能达到98%以上,互联网类新闻的准确率相对较低,才87.5%,由于体育类和军事类相较于其他类别而言,训练数据较多。可见,不同的分类,预训练的规模不同最终的准确率也不同,由此可知,想要让LSTM算法模型的优势得到充分发挥,用于训练的数据规模必须得到保证。
表2 新闻分类矩阵

新闻标题分类一准确率分类二准确率分类三准确率东风-41已达服役标准跻身世界最先进导弹行列军事98.10%国内1.62%科技0.24%NBA总决赛落幕勇士横扫骑士成功卫冕体育99.8%汽车0.06%财经0.04%IBM帮美政府造目前最快超级计算机互联网87.50%科技8.51%财经1.21%
5 结束语
本文对LSTM算法进行了简要的论述和分析,并利用TensorFlow平台搭建了基于LSTM神经网络的新闻分类算法。实验结果表明,对海量的新闻数据信息使用LSTM神经网络新闻分类算法是一种有效的分析处理方法,模型准确度高且具有良好的扩展性,但由于实验室中实验器材以及实验环境方面的限制,本文仅利用有限的几台服务器搭建了实验环境,语料库数据量才两百多万,数据规模相对较小,此后,笔者将适当的添加集群节点数和扩大数据规模,加大对分类模型的训练,为本文算法的分类效果提供更多的论据。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
活力(2019年22期)2019-03-16
活力(2019年22期)2019-03-16
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
喜剧世界(2016年9期)2016-08-24
高中生学习·高三版(2016年9期)2016-05-14
