
基于贪婪算法的参与式感知激励分配机制
2018-03-16 06:18杜景林
计算机工程与设计 2018年2期
王 程,周 杰,2,杜景林
(1.南京信息工程大学 电子与信息工程学院,江苏 南京 210044;2.日本国立新泻大学 工学部电气电子工学科,新泻 950-2181)
0 引 言
激励机制对参与式感知有着重要的意义[1-4]。在有限的激励预算下,任务发布者为了获取特定时间特定区域的数据向中央服务器发出请求,移动用户作为感知数据采集者将数据发送给中央服务器,激励预算就会分配给被选中的移动用户[5]。文献[6]首次提出逆向拍卖激励机制,主要思想:参与者收集感知数据并且将投标价格和数据一起发送到中央服务器,中央服务器会选择最低的投标价格的数据。这种激励机制是通过最大化收集数据的数量来提高感知结果的精度,但是忽略了数据在时间和空间上的分布,在激励预算不足以获取足够的数据并且缺失的数据集中在某个区域中的时候,由于插值的原因,会导致数据重构的结果不精确。GIA考虑了参与者的位置和感知覆盖范围,将GBMCA(greedy budgeted maximum coverage algorithm)和RADP-VPC(reverse auction dynamic pricing)相结合,增加参与者的人数并且激励参与者移动来扩大感知覆盖范围[7-9]。文献[10]提出了两种系统模型:一种是以平台为中心的模型,该模型为参与者提供了报酬共享的平台;另一种是以用户为中心的模型,用户可以更好地控制他们收到的报酬。IEA[11]运用进化算法迭代优化机制,在有限的预算约束下,以最大化感知覆盖范围为优化目标,来选择有效的参与者,并且提出虚拟报酬这一概念,激励退出感知活动的参与者重新加入。然而,以上文献都没有考虑到数据的分布情况。针对以上问题,本文提出了一种激励机制,该方法考虑了数据的时空分布,不是通过最大化感知数据的数量而是根据数据的分布情况,将激励预算分配给提供最有效数据的区域来最小化感知结果的平均误差。在对平均误差、数据数量和分布之间的关系进行研究后,发现较大数量和更加均匀分布的数据可以提高感知结果的精度。本文将激励分配作为优化问题,通过贪婪算法对其进行优化。
由于激励预算是有限的,收集到的感知数据是不可能覆盖整个目标区域的,因此文献[12]使用数据插值的方法来对缺失的数据进行重构。文章指出,在参与感知系统中,测量的密度是不均匀的,所以需要激励参与者在目标区域收集数据,并且需要控制每块区域的测量密度。
1 系统模型
1.1 模型描述
由文献[12]可知,当子区域的分配足够细致的话,每个子区域中的一个样本就可以为感知任务提供足够的数据精度。根据任务发布者的环境数据需求,将感知任务的整个区域和持续时间划分在子区域集合R={r=1,2,3,…,n}中。在每个子区域中,只需要目标环境参数的一个样本。
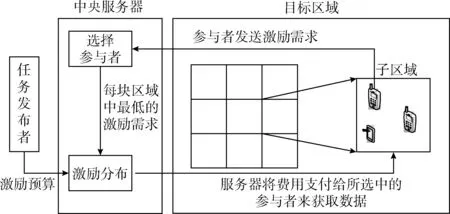
图1 参与感知过程
在目标区域内,Z(ri)是变量Z(r)在点ri(i=1,2,3,…,n)处的属性值。未知点变量Z*(r)是根据n个已知的变量值加权求和后得到的,即
(1)
其中,λi是第i个位置处的测量值得未知权重,表示各空间样本点观测值对估计值的贡献程度。权重λi取决于测量点、预测位置的距离和周围f测量值之间关系的拟合模型。选取λi需要满足无偏性和估计方差最小这两个条件。根据方程组(2)来求解权重系数λi
(2)
其中,r和ri表示的是未知点和第i个样本的位置。μ是拉格朗日常数。γ(ri,rj)表示变量Z(r)在ri和rj两点之差的方差的一半,可由式(3)得到
(3)
通过求解克里金方程组可以得到权重系数λi,然后再由式(1)得出估计值。
本文用ε来表示感知结果的平均误差和所有子区域R真值的比,误差主要积累在无数据样本的子区域中,有
(4)
根据式(4),可以发现平均误差是与有数据样本的区域有关的。
1.2 样本数量和分布与平均误差之间的关系
1.2.1 样本数量
(5)
1.2.2 样本分布
(2)不同区域的数据重要性随着环境的改变而改变。例如,图3(b)显示了市区噪声水平的读数。噪声水平在区域“A1”改变巨大,而区域“A2”相对于区域“A1”改变比较稳定。如果大量数据是从区域“A1”收集来的,那么插值结果就会更加准确。显然,更高的权重应该给环境变化剧烈的地区,例如在图3(b)的“A1”。
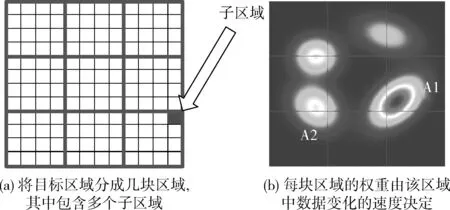
图3 样本数据在区域中的分布权重
将整块区域分成区域集合A={a=1,2,…,n}。用Xa,∀a∈A来表示落在每个区域中的样本集。样本落在每个区域的概率
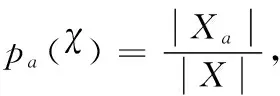
(6)
除此之外,不同区域的数据的重要性是由环境数据改变的程度决定的。当数据改变稳定的话,那么只需要较少的数据样本就可以获得准确的感知结果。因此,每个区域的权重可由区域中的数据读数的标准偏差得到
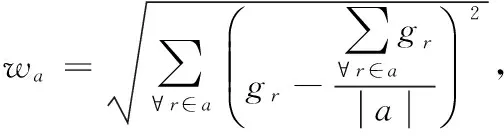
(7)
(8)
(9)
2 激励机制模型求解
考虑到本文中的优化问题是和样本数量和分布相关的,那么可以将式(4)中的平均误差作为目标函数。根据式(9)
(10)
(11)
步骤1 初始化,赋初值
将所有区域分成两个子集——选中的集S1和未被选中的集S2。在步骤1先把所有的区域放进S2中,S1为空集。
步骤2 每次迭代过程中区域的选择
如果S2中的区域r被选中,那么就从S2移动到S1,形成一个新集S1,那么式(11)目标函数的变化为
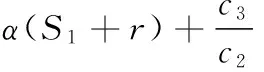
(12)
ir是区域r中最低的激励需求。式(11)目标函数每单位激励的变化为
(13)
每次迭代过程中,选择提供最有效数据的区域r,那么区域r就从S2移动到S1。将激励ir分配到选中的区域r,最低激励需求的参与者将数据发送到中央服务器后获得报酬。
步骤3 循环
耗尽激励预算B或者所有区域已被选中,则终止算法,否则一直重复步骤2。
3 仿真实验
3.1 程序设置
本文将从固定的无线传感器网络收集的环境感知数据作为真值,并且利用从公园收集的轨道数据[15]来模拟参与者的移动轨道,这个轨道数据集包含了41个参与者在特定一天中的移动轨道。下面本文采取以下步骤来设置实验:
(1)设置区域R和激励需求ir:本文将矩形感知区域分成4×4的区域,将持续时间分成24个时间点,因此|R|=16×24=384。把41个参与者的移动轨道放入这个感知区域,每个参与者的激励需求在[1,20]中随机生成,通过参与者的轨道和激励需求来计算ir,∀r∈R。
3.2 仿真结果
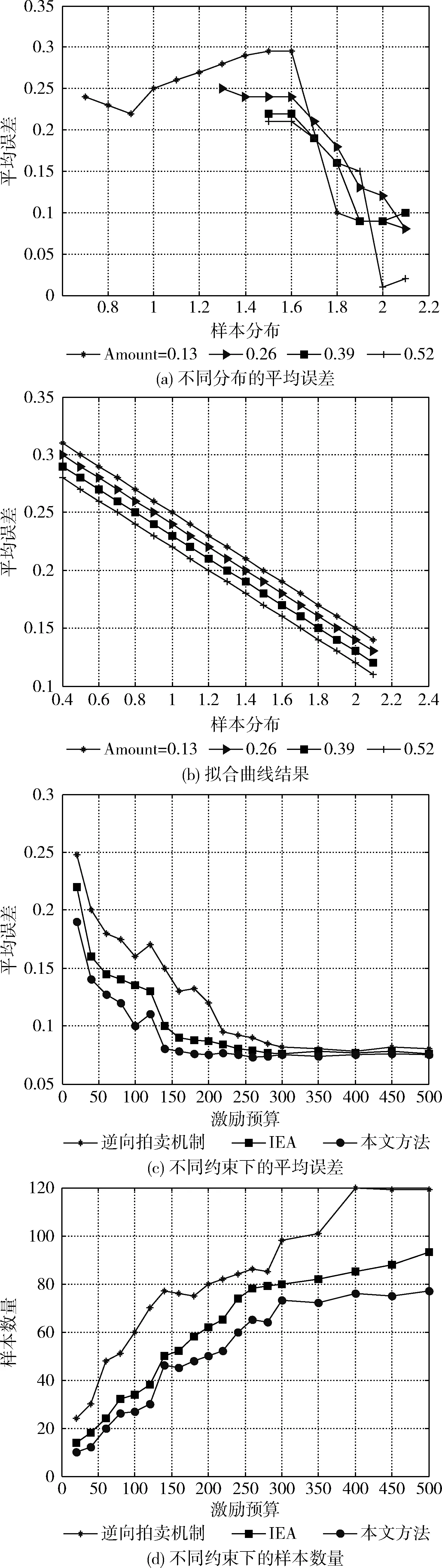
图4 仿真结果
ε=0.3777-0.0642α-0.1247β
(14)
通过这个表达式,可以发现样本分布要比样本数量对平均误差的影响更大。图4(b)表示根据式(14)得出的预测误差。真实误差和根据40 000个样本集得出的预测误差之间只有0.021的差距,这个差距是非常小的,在接受范围之内。
本文将12月8号收集的温度数据作为真值,将本文方法与逆向拍卖机制和IEA的性能进行比较。图4(a)和图4(b)表示随着激励需求B的变化,这两种方法在所选区域中的平均误差和样本数量。
从图4(c)可以看出,当预算不够时,本文方法的平均误差与逆向拍卖机制和IEA的差距越来越大。当预算在20的时候,逆向拍卖的误差是0.248,IEA的误差是0.22,而本文方法的误差只有0.193(比逆向拍卖机制少了22%,比IEA少了13%),这是因为本文方法在数据分布均匀的区域给了更高的激励来收集数据。
从图4(d)可以看出,本文方法所需要的区域比逆向拍卖机制和IEA都要的少,给足够的预算,3种方法的数据精度是差不多的。本文方法所需要的数据样本比逆向拍卖机制的少42%,比IEA少26%,减少了移动设备的能量消耗,为每个参与者增加了72%的激励,这样可以鼓励移动用户提供高质量的数据。
4 结束语
本文提出的在预算约束条件下的参与感知激励机制可以达到更高的数据精度。与现有的激励机制不同,本文方法不仅考虑了样本的数量还考虑了样本的分布。本文研究并用公式表示平均误差,样本数量和样本分布之间的关系。将平均误差最小化问题转化为每块区域的激励分配优化问题,提出了一个贪婪激励分配算法来解决优化问题。大量真实数据集的模拟验证了该机制的有效性。与现有的逆向拍卖机制和IEA进行仿真结果对比,验证了本文的激励分配机制可以增加感知数据的精度,提高参与者的利益。
[1]CHENLongbiao,LIShijian,PANGang.Smartphone:Pervasivesensingandapplications[J].ChineseJournalofComputers,2015,38(2):423-438(inChinese).[陈龙彪,李石坚,潘纲.智能手机:普适感知与应用[J].计算机学报,2015,38(2):423-438.]
[2]RugeL,AltakrouriB,SchraderA.Soundofthecity-conti-nuousnoisemonitoringforahealthycity[C]//InternationalWorkshoponSmartEnvironmentsandAmbientIntelligence.IEEE,2013:670-675.
[3]DevarakondaS,SevusuP,LiuH,etal.Real-timeairqualitymonitoringthroughmobilesensinginmetropolitanareas[C]//TheACMSIGKDDInternationalWorkshoponUrbanComputing.ACM,2013:1-8.
[4]WANGHao.Resarchonincentivetechnologyinparticipatorysensingnetwork[D].Harbin:HarbinEngineeringUniversity,2014:13-14(inChinese).[王浩.参与感知网络激励技术研究[D].哈尔滨:哈尔滨工程大学,2014:13-14.]
[5]ZHAOLuming.Theresearchandimplementofincentivemecha-nismbasedonparticipatorysensing[D].Beijing:BeijingUniversityofPostsandTelecommunication,2015:7-8(inChinese).[赵露名.基于参与式感知的激励机制的研究与实现[D].北京:北京邮电大学,2015:7-8.]
[6]LeeJS,HohB.Sellyourexperiences:Amarketmechanismbasedincentiveforparticipatorysensing[C]//IEEEInternationalConferenceonPervasiveComputingandCommunications.IEEE,2010:60-68.
[7]JaimesLG,Vergara-LaurensI,LabradorM.Alocation-basedincentivemechanismforparticipatorysensingsystemswithbudgetconstraints[J].Dissertations&Theses-Gradworks,2012,25(3):103-108.
[8]JaimesLG,Vergara-LaurensI,ChakeriA.SPREAD,acrowdsensingincentivemechanismtoacquirebetterrepresentativesamples[C]//IEEEInternationalConferenceonPervasiveComputingandCommunicationWorkshops.IEEE,2014:92-97.
[9]JaimesLG,Vergara-LaurensI,RaijA.Acrowdsensingincentivealgorithmfordatacollectionforconsecutivetimeslotproblems[C]//Communications.IEEE,2014:1-5.
[10]YangD,XueG,FangX,etal.Crowdsourcingtosmartphones:Incentivemechanismdesignformobilephonesensing[C]//InternationalConferenceonMobileComputingandNetworking.ACM,2012:173-184.
[11]Kumrai T,Ota K,Dong M,et al.An incentive-based evolutionary algorithm for participatory sensing[C]//Global Communications Conference.IEEE,2014:5021-5025.
[12]Mendez D,Labrador M,Ramachandran K.Data interpolation for participatory sensing systems[J].Pervasive & Mobile Computing,2013,9(1):132-148.
[13]WANG Ting.Research on 3D interpolation approaches based on Kriging with anisotropic spatial structures[D].Nanjing:Nanjing Normal University,2013:1-65(in Chinese).[王亭.顾及各向异性的三维Kriging空间插值方法研究[D].南京:南京师范大学,2013:1-65.]
[14]Ji HY,Ohm SY,Min GC.Brightness preservation and image enhancement based on maximum entropy distribution[M]//Convergence and Hybrid Information Technology,2012:365-372.
[15]Solmaz G,Akbas MI,Turgut D.Modeling visitor movement in theme parks[C]//IEEE,Conference on Local Computer Networks.IEEE Computer Society,2012:36-43.
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23
音乐天地(音乐创作版)(2022年1期)2022-04-26
南京理工大学学报(2022年1期)2022-03-17
甘肃教育(2020年14期)2020-09-11
中华诗词(2020年12期)2020-07-22
中国公路(2017年11期)2017-07-31
计算机技术与发展(2017年1期)2017-02-22
华人时刊(2016年13期)2016-04-05
中国商论(2016年33期)2016-03-01
现代企业(2015年8期)2015-02-28
