
基于布隆过滤的藏区Web站点流量识别
2018-03-16 06:17郭晓军孙海霞张国梁
计算机工程与设计 2018年2期
郭晓军,孙海霞,张国梁
(1.西藏民族大学 信息工程学院,陕西 咸阳 712082;2.东南大学 计算机科学与工程学院,江苏 南京 211189;3.西藏民族大学 西藏光信息处理与可视化技术重点实验室,陕西 咸阳 712082)
0 引 言
目前针对西藏Web站点流量识别方面[1]研究工作较少,因此本文主要研究面向藏区Web站点流量识别的技术。
在Web站点流量识别方面,国内外学者已经进行了一些研究工作,多数以静态的网络流量记录文件为数据对象。Ihm等[2]对现代Web站点流量的结构进行了海量数据分析,指出由于当前Web站点页面内容包含丰富媒体应用使得Web流量结构复杂而不易识别;Ben等[3]通过对静态包记录数据集中报文的TCP/IP头部字段分析来分析和提取其中的Web流量,但该方法没有对在线网络流量做测试,未能获知其效果;Katerina等[4]从流持续时间、Request个数、会话传输字节数来描述恶意Web流量,但必须要求有先验知识,需要人工辅助分析,无法实现自动判断,无法应用于大流量网络环境;David等[5]基于其校园网24小时的流量记录文件,使用BroIDS系统和TCP 80端口来进行提取Web流量,识别准确度受到限制,且该方式仅适用于与静态的流量记录文件。从以上工作可以看出,多数Web流量识别算法均以静态网络流量文件为对象,且缺少在大流量网络环境中的实时验证,识别正确率较低。
针对上述问题,本文提出了一种面向藏区Web站点流量识别算法TWTBF,该算法基于Bloom Filter[6],将能够反映藏区Web站点流的多个特征字段映射为BF中的位数组,形成识别规则,然后在设定假阳率的情况下,通过多个Hash函数来计算待识别数据包相应特征字段的Hash值来判断是否为Web流量包,有效解提高了Web站点识别算法的准确性和大流量网络环境的鲁棒性。
1 Bloom Fitler原理
Bloom Filter(BF)是一种空间效率很高的随机数据结构,其核心思想主要是通过多个不同的Hash函数来解决“冲突”。它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。它是一个判断元素是否存在于集合中的快速算法。
1.1 具体过程
(1)BF初始化。初始状态时,Bloom Filter是一个包含s(s≥0)个二进制位的位数组Array,每一位都置为0,如图1所示。
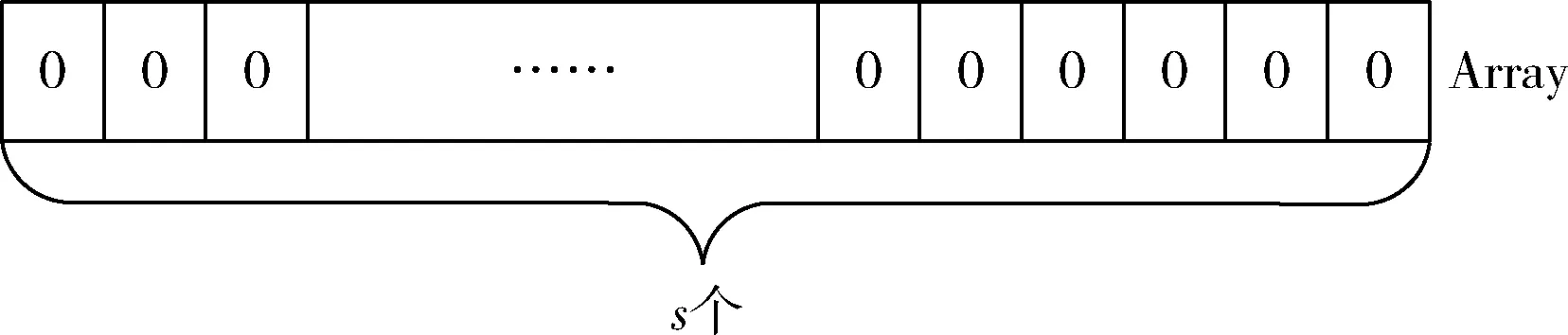
图1 Bloom Filter的位数组Array
(2)映射关键字集合D。假设关键字集合D={d1,d2,……,dt},t(t≥0)。BF使用q个相互独立哈希函数(Hash Function),H1()~Hq()它们分别将集合D中的每个元素di映射到Array数组中。对集合D任意一个元素di,分别计算哈希值H1(di)~Hq(di),并在Array中将H1(di)~Hq(di)所对应位置上的二进制位设置为1,如图2所示。
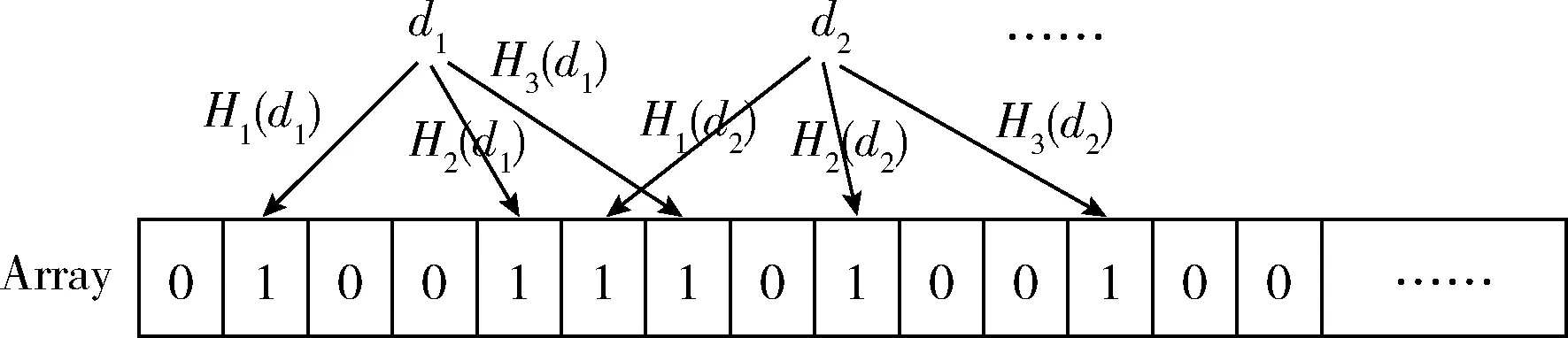
图2 BF映射集合D中元素的示例(q=3)
(3)判断未知元素x是否属于D。BF在判断x是否属于D集合时,只需要使用q个哈希函数对x分别计算出哈希值H1(x),H2(x),…,Hq(x)。若H1(x),H2(x),…,Hq(x)所代表的Array位置的值都为1(即q个位置都已被设置为1),那么就认为x∈属于集合D(即x为集合D中的元素),否则就认为x∉不属于集合D(即x不是集合D中的元素)。图3中给出了一个判断示例,由于哈希值H2(x1)在Array所代表的位置的二进制位值为0,因此x1不是集合D中的元素,而x2则属于集合D。
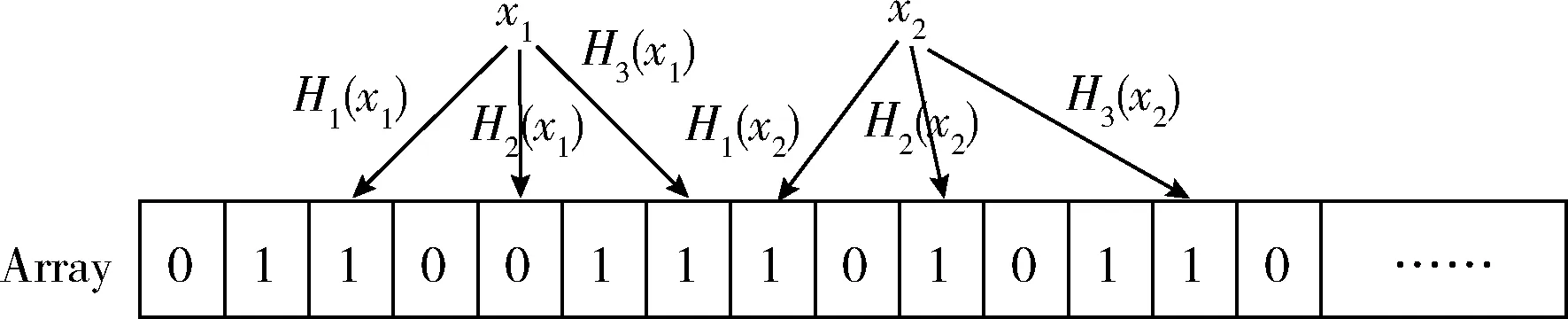
图3 BF判读未知元素x1,x2是否属于集合D
1.2 参数选择
从1.1节及文献[5]可知,BF涉及4个关键参数,表1给出了这些参数名称及其含义。

表1 BF的参数及含义
由于BF不是一个完全精确的方法,它允许通过极小的假阳率(即假阳性的概率)来换取大量存储空间的节省,其假阳率δ可通过式(1)计算
(1)
当s,t给定时,使得δ达到最小值时的q值为
(2)
此时δ为
(3)
而s可由式(4)计算
(4)
上述过程的具体推理,请参考文献[6],本文此处不再赘述。
2 藏区Web站点流量提取过程
藏区Web站点流量提取主要是指在高速大流量网络环境下,如何根据藏区Web流量的特征快速准确地从被管网络海量数据包中识别出藏区Web站点流量的数据包,进而准确获得浏览藏区Web站点过程的流量,为其它应用提供纯净的藏区Web站点流量数据。
2.1 Web流量特征选择
目前,Web服务主要使用传输层TCP协议[7]的80端口、应用层HTTP协议来建立连接、传输数据。然而,却不能使用这两个特征来唯一标识Web服务,这是因为一方面采用HTTP协议的不一定是Web服务,例如SSDP(simple service discovery protocol)服务也使用HTTP协议[8]实现,如图4所示;而另一方面,即使同时使用TCP 80端口、HTTP协议的也未必是Web服务,如图5所示,此流量是大白菜装机维护工具桌面应用工具获取数据时产生的流量。
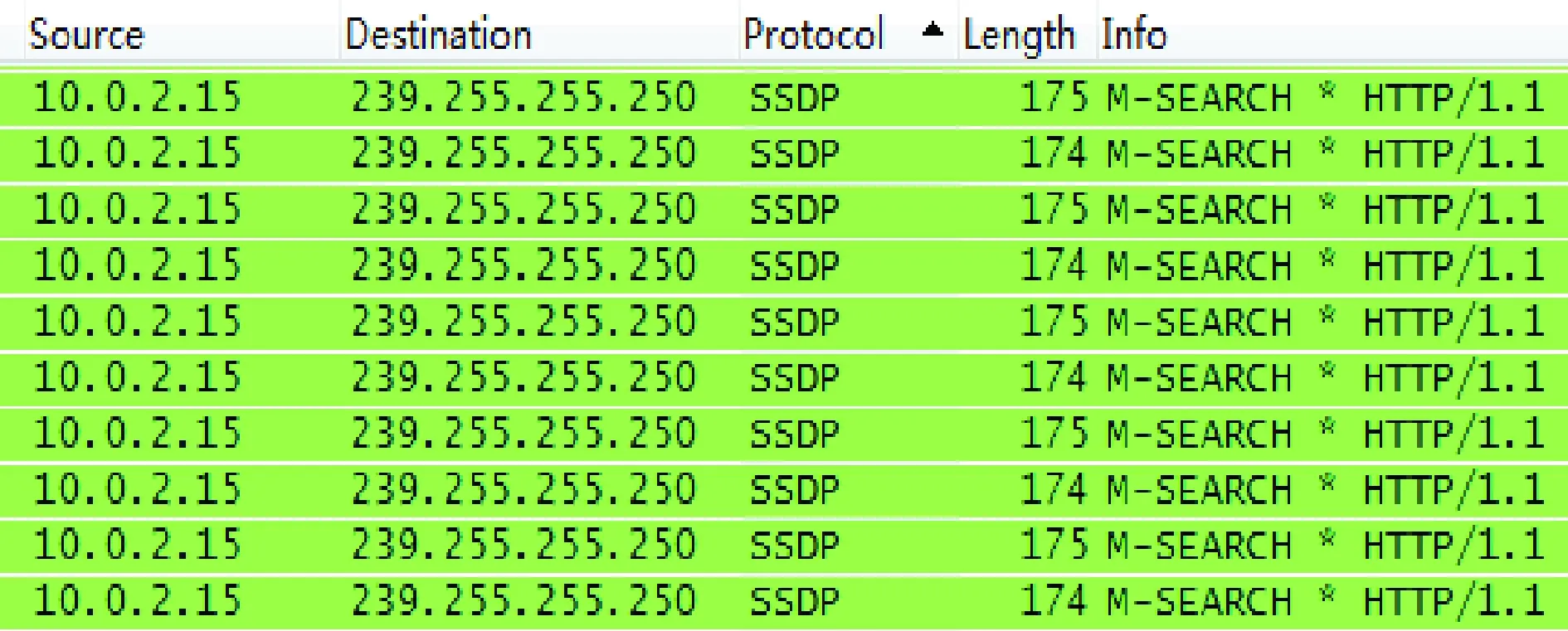
图4 使用HTTP协议的SSDP服务
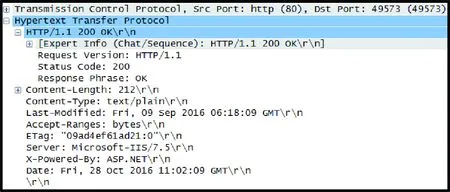
图5 同时使用TCP 80端口和HTTP协议的应用流量
由此看见,在大流量的网络环境下,由于流量类型复杂,仅根据端口号80和协议标识很难准确识别Web流量。为提高识别Web流量的准确性,本文根据大量的实际Web流量观察和分析,可采用IDTCP,80,8080,text/html,Server,Date等6个关键字作为识别Web流量特征。其中,IDTCP=6为IP头部中“协议”字段TCP协议的编号。80,8080分别为TCP头部中的端口号,text/html为HTTP头部中“Content-Type”字段的值,Server、Date分别为HTTP头部的字段名称。
因此,本文的关键字集合D={IDTCP,80,8080,text/html,Server,Date},t=|D|=6。
2.2 Hash函数选择
Hash函数[9]是指能够将关键字(key)的值直接映射为数组记录中的某个元素的函数,以加快查找速度。该数组记录也叫散列表(hash table)。
在BF中,Hash函数的作用是将关键字集合D中的所有元素快速地映射到位数组Array中。目前常用的Hash函数构造方法有直接寻址法、平方取中法、随机数法、除留余数法等多种方法。为简单起见,本文此处直接借用文献[9]中已有的Hash函数作为BF中Hash函数的选择范围,如图6所示。至于BF中Hash函数的个数,由式(2)给出的Hash函数个数q、集合D的势t以及Array位数组s之间的关系决定。
图6 常用Hash函数
2.3 提取过程
在确定Web站点特征后,提取Web站点流量过程实质上就是根据这些特征构造Bloom Filter,然后利用该Bloom Filter从被监管网络的大流量环境下的流量中正确识别出Web流的首个数据包,在此基础上,再将该Web流的后续数据包过滤出,该过程的具体流程如图7所示。
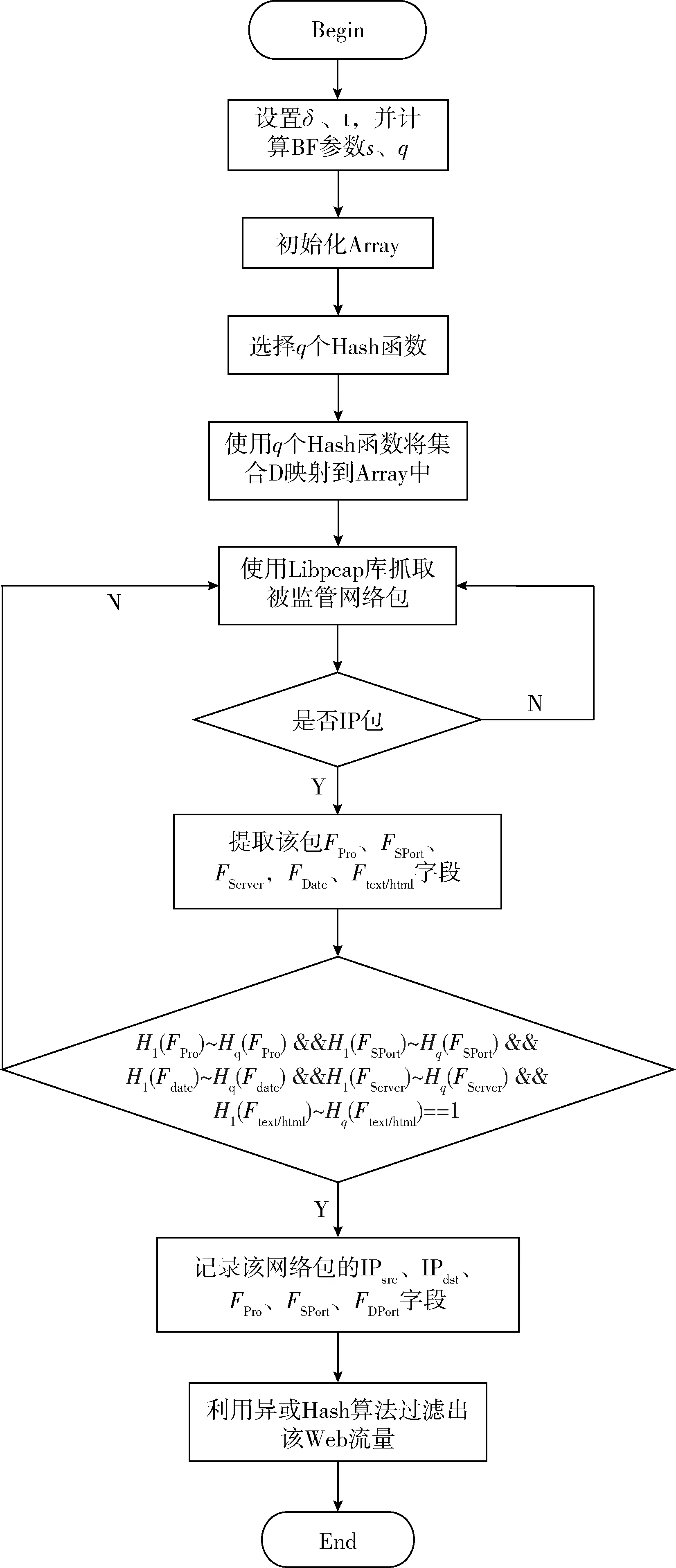
图7 藏区Web站点流量提取流程
其中,IPsrc、IPdst、FPro、FSPort和FDPort字段分别代表网络包的源IP地址、目的IP地址、IP头部中的协议字段、源端口和目的端口。FServer、FDate分别代表HTTP头部中的Server字段和Date字段,Ftext/html表示Content-Type字段的值。在确认Web站点流量的首个数据包后,本文利用文献[10]中的异或Hash算法来过滤出该Web流量后续的网络包。
3 实验过程与结果分析
本文使用C语言实现了Bloom Filter及所提出的Web站点流量提取方法。为测试该算法性能,本文将其部署在局域网内一台安装双网卡的服务器GATE上(软硬件配置见表2),并使用Libpcap库[11]捕获网络包,实验的网络拓扑结构如图8所示。

表2 GATE软硬件配置参数
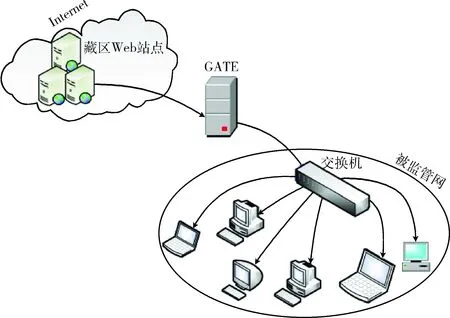
图8 实验拓扑结构
3.1 准确性
准确性是指本文所提算法所能正确识别出的Web站点流的情况,此处用识别准确率θ表示,即在设定δ值的条件下,正确识别出的Web站点流量首个数据包数量与所有测试Web站点总数(WSNum)的比例。本文测试了4个不同δ值下的识别准确率θ,实验结果如图9所示。
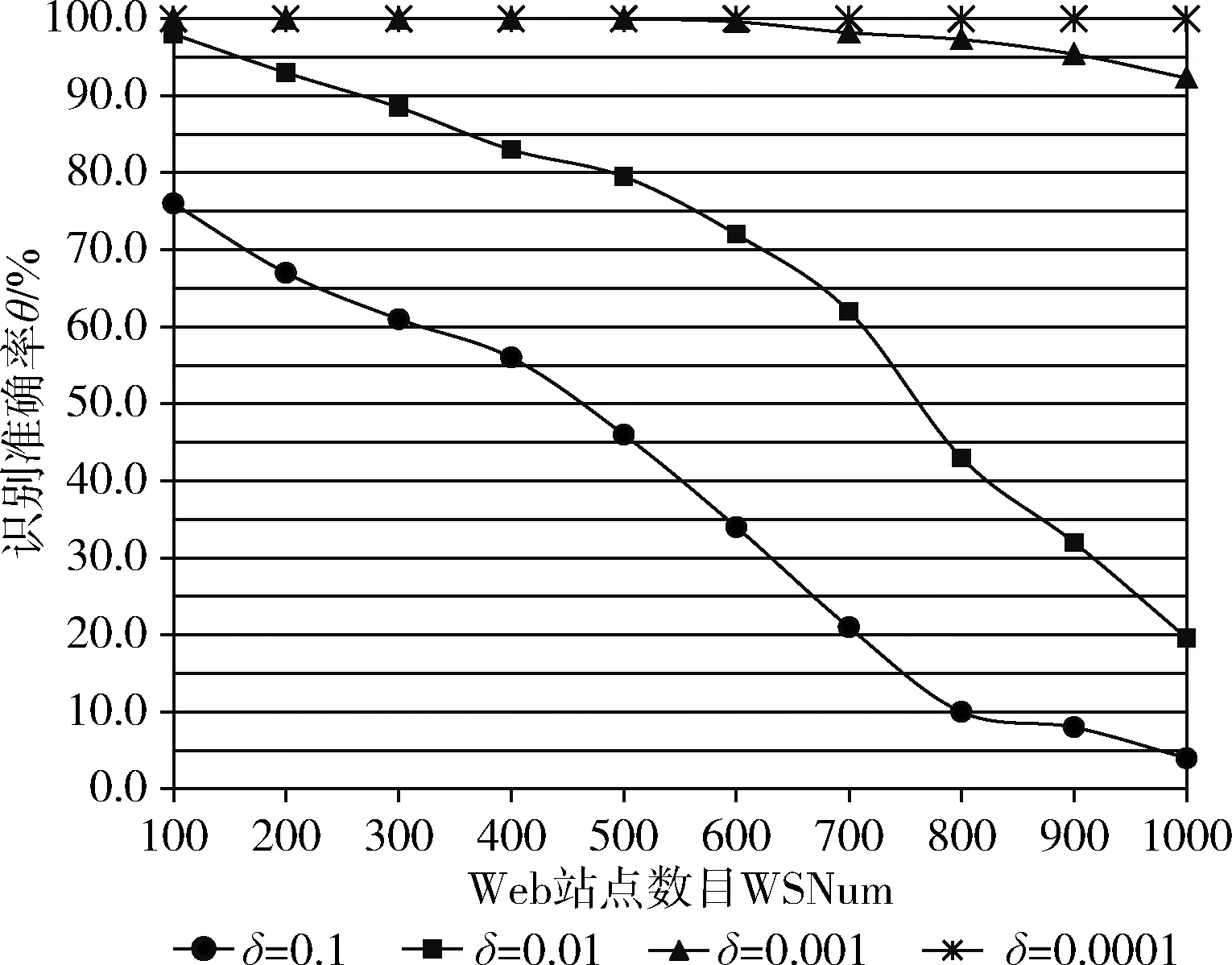
图9 不同δ值对应的识别准确率θ
从图9中可以看出,当δ值较大时(δ=0.1,δ=0.01),随着测试Web站点总数的增加,识别准确率θ会呈现明显的下降趋势。这是主要是因为,δ值较大BF的位数组Array长度s较小,在对较多Web站点流量的首个数据包后应用q个Hash函数产生的碰撞次数会大大增加,从而导致对数据包的误判概率增加,因而会降低识别准确率θ。但当δ值较小时(δ=0.001),Hash函数产生的碰撞次数会明显下降,此时θ的下降趋势也明显缓慢,基本保持在92.3%以上。而当δ=0.0001时,此时BF完全能正确识别所有测试的Web站点流量的首个数据包,识别准确率θ基本为100%。可见,δ值的越小,就越能取得较好的识别效果。然而,δ值变小时,BF的Array位数组大小s、Hash函数个数q也会极大增加,会增加识别过程中的计算复杂度。因此,应该根据实际问题选择恰当的BF参数。表3给出了不同δ值所对应的s、q值。
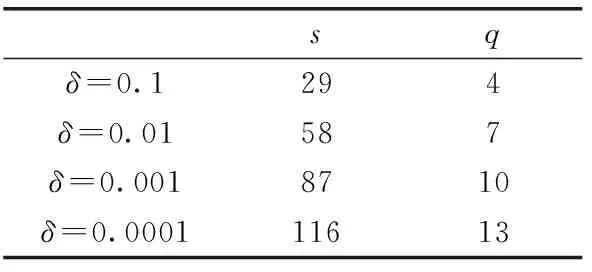
表3 不同δ所对应的s和q
3.2 鲁棒性
鲁棒性指TWTBF算法在被管网络不同背景流量下,完成所测试Web站点流的识别的时间。主要用于衡量TWTBF算法对网络噪音流量的抵抗能力。
本文在不同本地网络背景流量下对TWTBF算法进行了测试,结果如图10所示。被管网络背景流量采用工具iPerf[12]生成。该图表明,在测试Web站点流保持不变情况下,背景流量增加对TWTBF算法识别Web站点流量的时间影响并不明显。这主要由于一方面GATE主机上的千兆网卡能以极高的效率捕获局域网背景流量,另一方面TWTBF算法主要采用Hash映射,能快速地对数据包的字段进行计算,判断该包是否为Web流的首个数据包。此两方面的优势决定了TWTBF算法在不同背景流量表现出了较好的鲁棒性。另外,图10也说明随着测试Web站点数量的增加,TWTBF算法识别Web站点所花费时间也在以近似线性的方式增加。
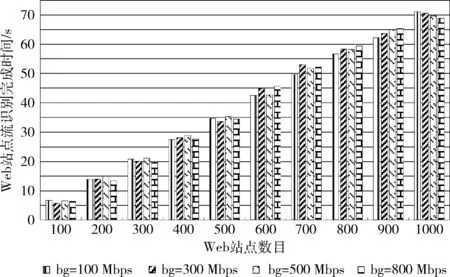
图10 被管网背景流量对TWTBF算法识别时间的影响
4 结束语
藏区Web站点流量准确而快速的识别有助于研究藏区内Web站点信息泄露评估、渗透测试、指纹信息提取等方面的内容。本文提出了一种面向藏区Web站点的流量识别方法,通过精确Web站点流量特征和引入Bloom Filter结构来有效保证在被管网大流量条件下对Web站点流量识别的准确性和鲁棒性,并在真实网络环境下进行了实验验证,取得了较好的实验效果。下一步打算在Web站点多流归并、加密Web流量识别、更大规模被管网络试用等方面开展研究工作。
[1]McIlwain C.Racial formation,inequality and the political
economy of Web traffic[J].Information,Communication & Society,2016,19(7):1-17.
[2]Ihm S,Pai VS.Towards understanding modern Web traffic[C]//Proc of the ACM SIGCOMM Conference on Internet Measurement Conference.New York:ACM,2011:295-312.
[3]Newton B,Jeffay K,Aikat J.The continued evolution of Web traffic[C]//Proc of IEEE 21st International Symposium on Modelling,Analysis and Simulation of Computer and Telecommunication Systems.New York:IEEE,2013:80-89.
[4]Goseva-Popstojanova K,Anastasovski G,Dimitrijevikj A,et al.Characterization and classification of malicious Web traffic[J].Computers & Security,2014,42(5):92-115.
[5]Gugelmann D,Ager B,Lenders V,et al.Towards understanding upstream Web traffic[C]//Proc of International Wireless Communications and Mobile Computing Conference.New York:IEEE,2015:538-544.
[6]Xylomenos G,Ververidis CN,Siris VA,et al.A survey of information-centric networking research[J].IEEE Communications Surveys & Tutorials,2014,16(2):1024-1049.
[7]Zhou D,Song W,Wang P,et al.Multipath TCP for user coo-peration in LTE networks[J].IEEE Network,2015,29(1):18-24.
[8]Grigorik I.Making the Web faster with HTTP 2.0[J].Communications of the ACM,2013,56(12):42-49.
[9]Arash Partow.Available Hash functions[EB/OL].[2016-10-22].http://www.partow.net/programming/hashfunctions/#AvailableHashFunctions.
[10]Fu C,Bian O,Jiang H,et al.A new chaos-based image cipher using a hash function[C]//Proc of IEEE/ACIS 15th International Conference on Computer and Information Science.New York:IEEE,2016:1-9.
[11]Luis Martin Garcia.Libpcap library[EB/OL].[2000-07-13/2016-09-24].http://www.tcpdump.org/.
[12]Wang Q,Yin S,Gnawali O,et al.Demo:OpenVLC1.0 Platform for research in visible light communication networks[C]//Proc of of the 21st Annual International Conference on Mobile Computing and Networking.New York:ACM,2015:179-181.
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
电脑报(2022年13期)2022-04-12
电脑报(2020年24期)2020-07-15
西藏研究(2020年1期)2020-04-22
人民调解(2019年5期)2019-03-17
电脑爱好者(2017年22期)2017-12-04
中国卫生(2016年5期)2016-11-12
初中生之友·中旬刊(2015年4期)2015-06-10
图书馆建设(2015年10期)2015-02-13
西南学林(2014年0期)2014-11-12
