
词向量聚类加权Shark-Search的主题爬虫策略研究
2018-02-09 07:18程元堃廖闻剑
计算机与数字工程 2018年1期
程元堃 廖闻剑 程 光
(1.武汉邮电科学研究院 武汉 430074)(2.南京烽火软件科技有限公司 南京 210019)(3.东南大学计算机科学与工程学院 南京 210019)
1 引言
互联网的飞速发展给我们的日常生活带来了许多实质性的变化,同时伴随而来的是数据量的急速增长。面对庞大的主题各异的网页文本内容,我们需要借助一些工具帮助我们更有效率地找到有价值的信息。通过搜索引擎进行主题爬虫可以基于用户给定的一个主题,根据相关算法,选择爬取与用户定义主题相似度达到某一定阈值的网页,从而在一定程度上减少下载无关的页面信息以节省宝贵的网络带宽资源。
基于主题内容评价的爬行策略,以De Bra、Herseovici等研究的Fish-Search及Shark-Search等算法为代表。标准的Fish-Search算法将网络爬虫抓取网页的过程比作鱼群在水中捕食的过程,算法中的每个URL链接代表一条鱼[1~2]。当用户给定一些种子链接和一些查询需要的参数,该算法能够建立一个变化的链接优先级爬行的列表,根据网页页面是否与主题相关分别给出1和0.5的打分,根据分值来对爬行URL队列进行排序。Fish-Search算法的动态性和相对的简单易行使它在主题爬虫中取得了广泛的应用,然而它对相关性的判断是离散的二值判断,URL列表的优先级设置不够合理。在Fish-Search算法的基础上,Herseovici提出了Shark-Search算法[3~5]。Shark-Search算法的改进主要体现在对网页与主题相关性进行模糊评分,不仅考虑到了父网页内容对子网页内容的影响,同时考虑到了子链接周围文本的“主题聚集”现象以及锚文本的重要作用[6]。
如何在保证主题爬虫的效率前提下提高爬取网页内容与用户指定主题的相关度是技术难点。基于此,本文提出了一种词向量聚类加权Shark-Search算法的主题爬虫策略,根据词向量的空间距离计算文本间的相似度,利用相似度加权改善预测子链接的评分算法,从而达到改进对用于主题爬取的Shark-Search算法的目的。
2 关键技术
2.1 Shark-Search算法
Shark-Search属于启发式算法,它对当前页面的每一个子链接进行预测,计算其指向的子页面与主题的相关程度[7]。
子链接的预测值由以下式(1)计算:
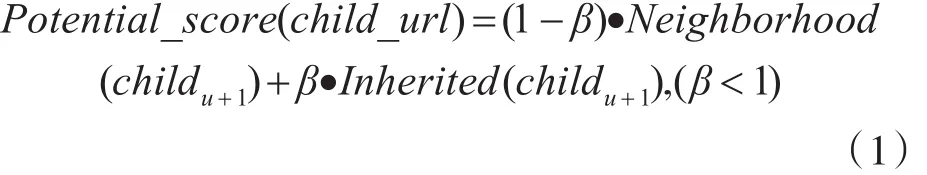
其中,Inherited是从父节点继承的相关性评分,由主题Topic和父网页的相似性计算得到,如式(2)所示:

current_url表示child_url结点的父节点,score(C,current_uri)计算在当前主题C下current_url的评分,α为衰减因子<1,μ为相关度阈值。
邻近链接Neighborhood的评分与锚文本和锚文本的上下文紧密相关,如式(3)所示:
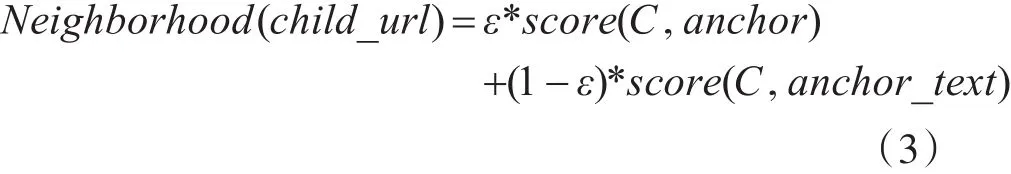
根据锚文本与主题C的相似性score(C,anchor)以及锚文本附近的文字与主题C的相似性score(C,anchor_text)算出。
公式中的score为计算两文本主题相关度的函数,通常返回0~1之间的数,数字越大说明两文本的主题越相关。Shark-Search算法使用的是向量空间模型间计算文本的相似度,使用特征向量之间的余弦距离作为相似度评判标准,结果值取0~1之间的实数。
大多数网页中内容相关的链接和文本通常连续出现,Shark-Search算法正是利用这一特征,把链接的上下文信息(包括链接和文本)作为计算Potential_score的重要因素以辅助决策待访问链接对于用户指定主题的文档相关性。它充分利用了网页文本的信息来对子链接指向的网页文本主题进行预测,比Best first、Fish-Search算法对网页文本主题影响因素考虑的更为全面。但它也存在一些局限性,例如该算法对于文本主题相关度的计算简单,会导致爬取过程中忽略掉很多可能蕴含与用户主题高度相关信息的页面;而“隧道问题”是面向主题的网络爬虫都需要面对的问题,它指的是大量无关或者低相关主题页面指向与主题相关的页面的现象,在爬虫和主题页面之间存在着大量的无关、低相关页面需要一个隧道被打通。
2.2 词向量聚类
由几个少数关键词组成的主题往往难以准确反应用户的主题需求,直接使用主题词进行匹配会使爬虫漏掉很多与主题相关度较高但主题词出现频率低的页面内容。
针对以上问题,本文基于词向量在向量空间上的相似度可以用来表示词语语义上的相似度[8~13],扩展主题词。在计算文本主题相关度时,利用词向量聚类的方式来提升待访问链接文本内容的质量,最后以余弦距离作为权重加权邻近链接Neighborhood的评分,得到最终的子链接预测值。
文本主题相关度的计算过程如下:
1)在维基百科数据源上下载中文版本维基百科语料库数据,用结巴分词工具完成分词后,使用gensim里面的基于神经网络模型的特征词抽取工具word2vec训练得到词向量模型MODEL。
2)根据用户的主题需求,在1)中获取与主题词相似度较高的词作为补充,扩展主题词。
3)计算扩展后主题词列表的向量均值,将其作为该主题的中心词向量。
定义1 主题i的关键词集合为Keywordi={w1,w2,…,wn},其中 wk(1≤k≤n)表示代表主题 i的某个关键词,在MODEL中获取每个主题词的词中词映射到空间向量的维度,因此,可以得到主题i样本的词向量集合:

得到一个(n*K)的矩阵:

计算向量均值,得到主题i的中心词向量:
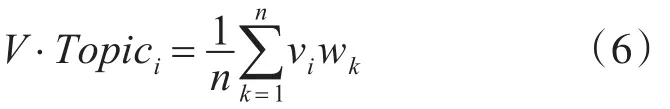
4)对于待访问链接网页文本信息,分词后在MODEL中获取每个词的词向量;采用余弦相似度作为距离评估方法,使用DBSCAN聚类算法对分词结果进行去噪处理,得到质量提升的网页文本内容特征词集合。
5)针对用户指定主题i的中心词向量,计算它与特征词集合中每个词的词向量的余弦相似度,最终结果取平均,作为该链接与主题i的余弦相似度权值。
定义2 待访问链接网页文本内容经步骤4)去噪处理后表示为 Ttext={t1,t2,…,tm},其中 tj为文本中某词,获取其词向量 vtj={y1,y2,…,yK},计算词和主题i中心词向量V⋅Topici的余弦相似度,有
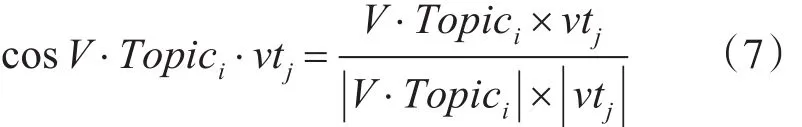
据此,得到待访问链接与主题i的余弦相似度:
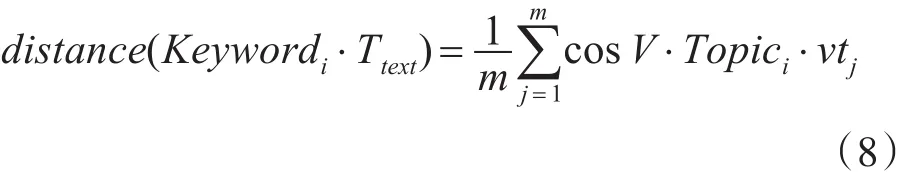
distance(Keywordi⋅Ttext)即为计算得出的待访问链接网页与主题相似度权值。
2.3 改进的邻近链接评分算法
利用上文中提到的词向量聚类对Shark-Search算法进行改进,用主题评分机制替换原有的邻近链接Neighborhood的评分方式[15],避免仅凭链接上下文对Neighborhood(child_url)得分造成影响。首先修改score(C,anchor)的计算方式,当仅由单一的主题词对网页内容进行匹配时,很容易忽略在网页中出现频次较少但对主题相似度贡献较大的词,因此,经由词向量扩充后的主题词列表在网页文本内容中逐一匹配并统计每个主题词出现的频次,然后取归一化值相加求平均,这样可以提升主题词直接出现在网页中的情况对最后子链接预测值的贡献。
针对标准的Shark-Search算法对于文本主题相关度计算简单的问题,利用词向量聚类的方式对邻近链接进行了加权,采用如下式(9)进行计算:

由以上表述可知,改进的邻近链接评分算法如式(10):
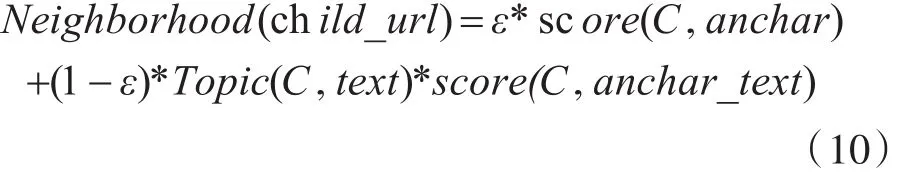
改进后的邻近链接评分算法,扩展了主题词,避免了爬虫在爬取过程中只选择当前与主题相近的链接,而忽视那些可能蕴含与主题高度相关的页面链接,导致较低的评分的高价值链接由于长期得不到处理而被舍弃。同时,引入词向量聚类加权可以更好地表示子链接网页文本内容与主题的相似度,在限定的时间内能够发现更多的主题相关页面。
3 实验结果与分析
在实现了Fish-Search和Shark-Search算法的基础上,根据提出的改进的邻近链接评分算法,对Shark-Search算法进行了改进,并通过实验对比3种算法的实际效果,其中主题相似度评价指标采用查准率。实验中选取了与军事相关的主题,并挑选了4个门户网站的军事板块链接作为种子进行爬取测试。

3.1 参数选取
Shark-Search算法中需预先设定4个参数,通过查阅文献,已证明当β=0,α=0.5,ε=0.8时实验效果最好[6],爬取深度随爬取效率动态调整。聚类过程采取密度聚类的方式,DBSCAN算法存在半径Eps和MinPts(在半径Eps内含有点数目的阈值)两个参数需要根据分词结果聚类的效果进行调参,在本文的对比实验中,将MinPts设置为自适应值int(log2(len(text_list))),len(text_list)是文本分词后词列表的长度,且在Eps=0.8时,分词后的聚类效果最好。
3.2 实验结果
表1列举了4个军事相关主题分别在Fish-Search、Shark-Search和词向量聚类加权Shark-Search算法上进行对比实验的结果。实验结果表明,词向量聚类加权Shark-Search算法与前两种算法相比,在限定时间内性能有明显提升,相较Fish-Search算法平均提升了158%,比Shark-Search算法提升了约13%。同时,在获取指定数目主题相关网页个数的前提下,得到三种算法随时间变化趋势如图1所示。
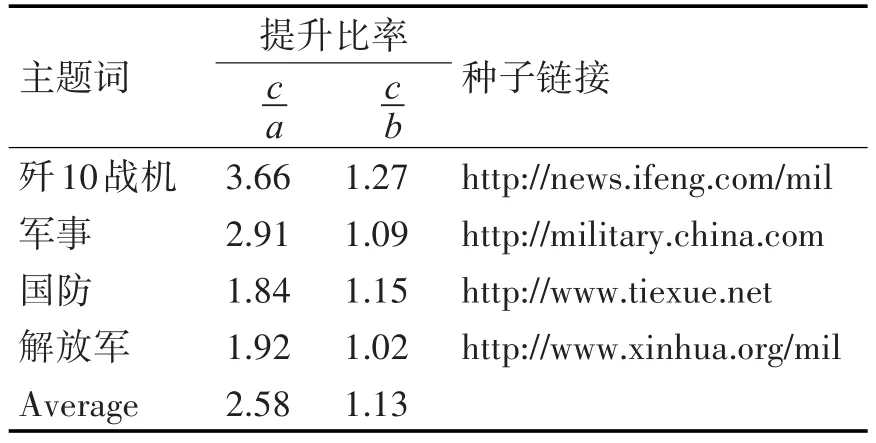
表1 Fish-Search(a)、Shark-Search(b)和词向量聚类加权Shark-Search(c)三种算法查准率对比
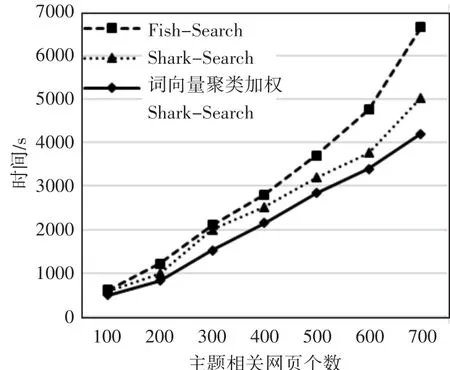
图1 三种算法爬取有效数量时间变化趋势
从图1可以看出,词向量聚类加权Shark-Search算法在效率上明显高于其他两个算法,且相较于另两种算法,本算法在整个爬取过程中一直保持稳定。
4 结语
本文提出词向量聚类加权Shark-Search算法的主题爬虫策略,通过改进Shark-Search算法中对邻近链接的评分机制,解决了原算法由于主题词单一以及相关度计算方式简单导致爬取过程中容易忽略与主题相关度较高的高价值链接的问题,使得在限定时间内能够下载更多的主题相关网页,通过实验证明了本算法的有效性。同时如何在保证爬虫查准率和效率的前提下降低算法复杂度,这是值得继续研究的。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
成都信息工程大学学报(2021年6期)2021-02-12
数码设计(2019年5期)2019-12-20
汽车文摘(2019年3期)2019-03-04
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2018年2期)2018-04-18
中学科技(2016年7期)2017-05-16
档案管理(2014年6期)2014-10-30
