
基于内容特征的科学数据与科技文献关联研究
2018-01-10 07:33黄筱瑾
现代情报 2018年1期
黄筱瑾
(成都理工大学图书馆,四川 成都 610059)
·理论探索·
基于内容特征的科学数据与科技文献关联研究
黄筱瑾
(成都理工大学图书馆,四川 成都 610059)
科学数据和科技文献是科研成果产出的两个重要表现形式。科技数据与科技文献关联分析对于实现集成信息服务、促进知识发现和完善E-science环境具有重要意义。文章从科学数据和科技文献的元数据出发,从两者的元数据描述中提取出表达内容特征的元数据项,并利用向量空间模型进行特征的相似性计算,从而关联科学数据与科技文献。
科学数据;科技文献;元数据;向量空间模型;特征提取
随着科学数据的高速增长和科学数据驱动的科研范式的逐步形成,科学数据在整个科研流程中的重要性越来越受到重视。对于科研工作者而言,学术资源已不再仅仅是指期刊文献和专著等传统文献类型,科学数据和科研记录资料等也逐渐成为科研人员学术信息需求的重点。将科学数据与现有的基于科技文献的科研信息支撑系统有效地关联,提供高质量集成信息服务,进而提高科学研究活动效率,成为一个迫切需要解决的问题。
开展科学数据与科技文献之间的关联对于科学数据的获取与共享、科学数据的复用和科研创新、科技文献的评价与评审乃至学术交流体系的转变等都有极其重要的意义。为此,一些研究者也开展了相关的研究,文献[1]以Elsevier出版集团的科学文献与科学数据关联实践为研究对象,深入分析其4种关联方式;文献[2]分析了科学数据的不同来源以及科学数据与科技文献的不同关联模式;文献[3]分析了当前期刊、出版商、数据库商等不同主体,探索通过期刊与数据互联、数据库服务、科学数据期刊等途径提供关联服务的尝试;文献[4]基于引文进行了科学数据与科技文献关联研究。同时,本文作者在对科学数据与科技文献的关联研究中,提出了基于元数据进行两者的关联,并就关联的模式及可行性进行了分析[5]。在该研究的基础上,本文从科学数据和科技文献的元数据中提取出表达内容特征的元数据项,基于内容特征进行科学数据与科技文献的关联研究。
1 内容特征提取的可行性分析
特征是对一个客体或一组客体特性的抽象结果。科学数据和科技文献的特征都可以分为外部特征和内部特征。科学数据的外部特征是指创建者、数据来源、发布机构、数据量、格式、语种等与其表达内容没有过多关系的特征,内部特征是指数据名称、关键词、摘要(简介)等表达数据内容的特征。科技文献的外部特征是指著者、著者单位、著者机构等,而内部特征是指题名、摘要、主题词、关键词等反映文献内容的特征。如果能提取科学数据和科技文献的内容特征,并建立他们之间的关联,就能将其背后的科学数据与科技文献关联起来。
1.1 科学数据内容特征提取的可行性分析
科学数据是指各类科技活动产生的原始性基础性数据及按照不同需求加工后的数据集和相关信息[6]。作为一种信息资源,科学数据的具体格式和类型包括:观察模拟数据;分类术语表;数学表达式;分子、化学、基因表达式;结构、物理、计算模型;表格、图形、图表、地图、图片;实地与试验笔记等。科学数据由于其具有数据的大量性、不均匀性、不规整性、动力学性、高维性等特点[7],对其特征进行描述是比较困难的。作者对一些科学数据库及共享平台进行了研究分析,其在对科学数据的特征进行揭示时,主要是通过元数据来进行描述的。元数据以其互操作性、可扩展性、语言互用性、可映射性等特点,已成为科学数据管理的基础,目前各科学数据仓储大多使用元数据来描述科学数据的外部特征和内容特征,进行科学数据的管理以及实现不同平台间科学数据的交换与整合。
作者在对国内建设得比较完善的10个科学数据平台做了分析[5]。这些科学数据平台通过元数据来描述数据本身的特征和属性,从而利于科学数据的存储、利用和管理。各科学数据平台多以DC定义的15个基本的核心元数据作为科学数据基本元数据。除此之外,再根据各学科科学数据的特点,进行有效拓展,定义一些和基本元素不重复的新元素。从调查发现,主要的元数据描述项包括数据名称、格式、关键词、摘要(简介)、数据量、语种、分类、数据来源、创建者、其他贡献者、创建日期、发布机构、关联信息、范围(时间范围、空间范围)、联系信息等。
国外的科学数据仓储平台同样通过元数据进行数据描述。Dryad数据库旨在实现对进化生物学领域期刊论文的支撑数据的保存、发现、复用和管理的科学数据仓储[8]。
Dryad的元数据描述以DC元数据元素为基础,融合了其他元数据标准的元素。目前Dryad的元数据元素包括数据名称、类型、作者、国家、提交日期、可获取日期、卷期、DOI识别符、引用、统一资源标识符、描述、主题词、关联信息(来源文献DOI识别符、来源文献PMID号)。PANGAEA[9]是一个地球环境科学领域的数据仓储,PANGAEA允许数据提交者通过使用都柏林核心、DIF或ISO 19115元数据标准进行地球环境科学科学数据的描述。目前PANGAEA的元数据元素主要包括数据名称、关联信息(来源文献DOI识别符)、摘要、空间范围、空间参数、知识共享署名许可协议、引用和责任方信息等。基于此,从元数据中提取科学数据的内容特征既具有高效性又具有可行性。
1.2 科技文献内容特征提取的可行性分析
元数据的目的之一是用于有效地描述文献的原始数据,保存文献数据的内在本质,特别是对于文献类电子资源。虽然,元数据的出现是网络发展的产物,但是从其出现之初,就受到了图书馆界和数据库商的青睐。图书馆在建立数字图书馆时,数据库商对文献类电子资源进行发展、推广和应用时,都迫切需要一种标准和规范来描述文献类电子资源的原始属性,因此,元数据成为对文献原始属性进行描述的一大选择。文献[10]对万方等几个数字图书馆系统元数据使用情况进行了统计。中科院文献情报中心的研究人员也针对期刊论文的元数据描述规范进行了专门的研究,其元数据元素见表1[11]。由此可见,一篇科技文献可以从它的元数据元素中提取题名、主题、描述等来表示科技文献的内容特征。因此,从元数据中提取科技文献的内容特征同样是具有可行性的。
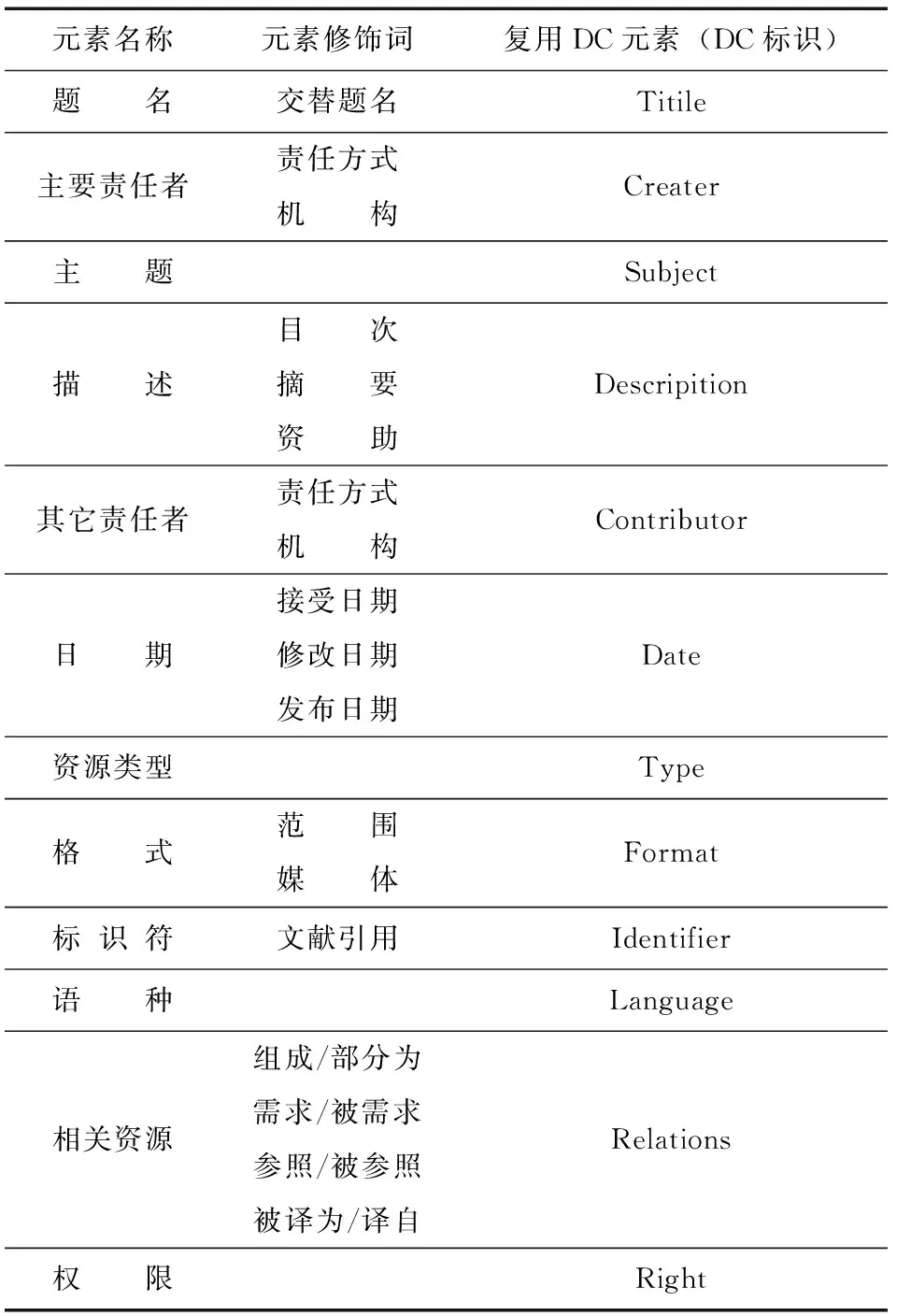
表1 期刊论文元数据构成
由此可见,元数据已经广泛地存在于文献数据库和科学数据仓储中,为两者的关联提供了较为丰富的数据基础。表2中对科学数据与科技文献的元数据元素进行对比,在元数据元素名称上虽然两者的表述方式存在差异,但是其描述的实质内容却是一样的,特别是在内容特征元素的描述上是可以相互映射的。通过提取两者元数据中的标题、摘要、关键词等文本描述字段,可以进行两者内容特征的关联,从而实现科学数据与科技文献的关联。

表2 科学数据与科技文献元数据映射表
2 基于内容特征的科学数据与科技文献关联方法
基于以上的研究分析,本研究通过对科学数据和科技文献元数据项中的内容特征进行提取,并对提取的特征信息进行相似性计算,从而判断科学数据和科技文献是否具有内容相似性,见图1。
利用文本进行相似性计算的方法有多种,本研究主要采用向量空间模型(Vector Space Model,VSM)进行文本特征表示,通过TF-IDF方法进行特征的权值计算,采用余弦相似度计算方法来衡量资源对象的相似性。
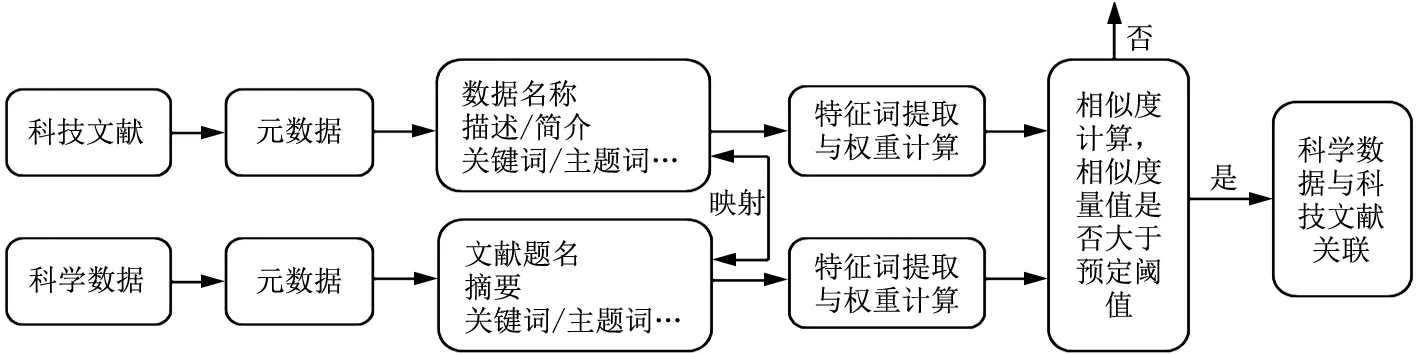
图1 科学数据与科技文献关联图
向量空间模型的基本思想是[12]:设自然语言文本表示为D,预定义的特征词集合表示为(T0,T1,…,Tn-1。通过计算机自动分词并计算出相应特征词的权重(W0,W1,…,Wn-1)后,文本D可用特征项及相应的权重表示为D(T0,W0,T1,W1,…,Tn-1,Wn-1),其中n为文本D所含特征词的个数,Ti为某一特征词,Wi为根据某种规则计算出的该特征词的权重。若不考虑Ti在文献中出现的先后顺序且Ti,i=0,1,…,n-1互异时,可以把(T0,T1,…,Tn-1)看作是一个n维坐标系,(W0,W1,…,Wn-1)则代表该坐标系构成的n维空间中的一个点或向量,这个向量为文本D的向量表示或者向量空间模型。
使用TF-IDF(Term Frequency-Inverse Document Frequency)方法进行特征的权值计算,文献Di中第j个特征词的权值Wij可以通过TF×TIF得到,其中TF(Term Frequency)和IDF(Inverse Document Frequency)分别表示术语频率和逆文档频率。TF用于度量特征词在特定文献的重要程度,其值越大说明这个特征词越能反映文献的核心问题。文献Di中第j个特征词术语频率为:
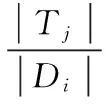
(1)
其中,|Tj|表示在文献Di中特征词Tj出现的次数,|Di|表示Di中所有单词的个数IDF用于度量特征词在整个文献集中的重要性。一般来说,整个文献集包含某一项T的文献越多,则表明这个特征项在该文献集中区分不同文献的能力较差,对特定文献的专指度也比较低,因而其值也就越小。Di中第j个特征词的倒文本率为:
(2)
其中,Num表示文献集中的文献总数,df(j)表示在所有被分析的文献中,包含了特征词Tj的文献数目。根据公式(1)、(2)分别计算出某特征词的TF和IDF值,并将这两个值相乘就得到了该特征词的权值。从科技文献的元数据文本内容中抽取的特征向量表示为D(Ti0,Wi0,Ti1,Wi1,…,Tin-1,Win-1),其中Ti表示第i个文本特征项,Wi表示该特征项的权重,从科学数据的元数据文本内容中抽取的特征向量表示为Sj(Tj0,Wj0,Tj1,Wj1,…,Tjm-1,Wjm-1,其中Tj表示第j个文本特征项,WJ表示该特征项的权重。
当文本以向量形式表示时,文本的相似度用文本特征向量的距离来衡量,即使用向量间夹角θ的余弦来计算,余弦计算正好是一个介于0~1的数,如果向量一致就是1,如果正交就是0,符合相似度百分比的特性:
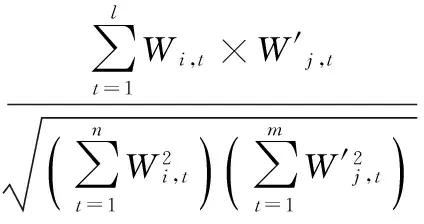
(3)
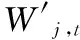
3 实例分析
选用国家地球系统科学数据共享平台中的“青藏高原东缘森林生态系统土壤有机质和养分数据”[13]作为测试数据,在科技文献的选取上,采用人工判定的方法,选取了4篇相关性的文献及2篇不相关的文献,具体见表3。通过对该科学数据与各科技文献的特征向量进行相似性计算,来验证该科学数据与科技文献的相关性是否与人工设定的一致。

表3 实验分析来源数据
我们利用文本特征词提取工具ROST TF-IDF[14]及内容挖掘工具ROST Content Mining分析科学数据及科技文献的元数据中表示内容特征的元素项的文本内容,ROST TFIDF嵌入了tf-idf Chinese模块,根据特征词权重的TF-IDF量化方法原理,对文本进行分词和词频统计,得到“逆文本频率指数”IDF和TF以及TF*IDF的值,见图2。提取出科学数据和各科技文献的特征向量,通过公式3进行科学数据与预先设定的科技文献的相似性计算和判定,结果证明通过向量空间模型计算出的科学数据与科技文献的关联性与人工判断的关联性是一致的。
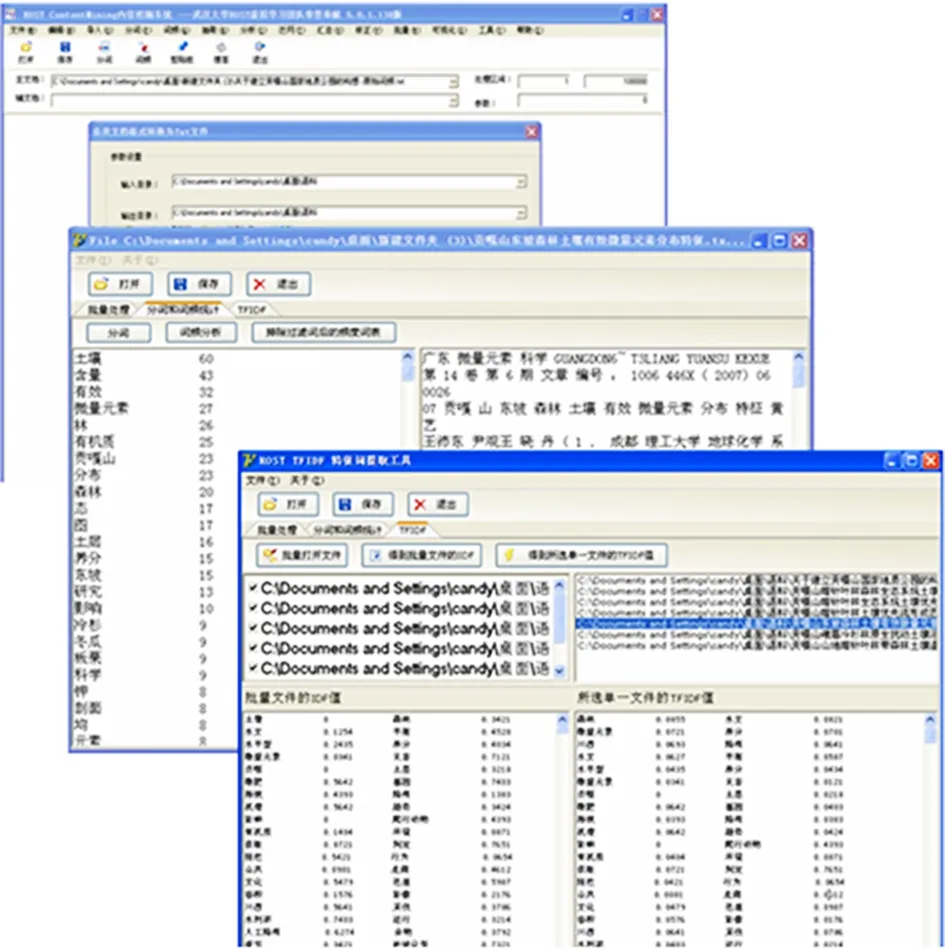
图2 ROST CM使用过程图
4 结 语
近年来,一批具有高使用价值的科学数据共享平台逐步建立起来并投入使用,同时,地球科学、生物学、空间科学、材料科学等学科领域在科学数据元数据的标准、结构、管理体系、互操作性等方面进行了研究,建立了相应的科学数据共享服务的元数据体系结构,这些都为笔者从科学数据与科技文献的元数据中提取内容特征奠定了良好的基础。本文提出了从题名、主题、描述等元数据项中提取科学数据与科技文献的内容特征,通过向量空间模型进行两者相似度计算,从而进行科学数据与科技文献关联的方法。在实践过程中还会涉及元数据收割、元数据映射等相关内容。同时,由于自然语言的复杂性,提取出的特征词在表达对象内容时可能存在语义上的不确定性。针对以上问题,将在今后进行更加深入的研究。
[1]卫军朝.科学文献与科学数据关联实践研究——以Elsevier为例[J].国家图书馆学刊,2017,(3):93-101.
[2]孙文佳,常娥.科学数据与科技文献关联分析[J].图书馆理论与实践,2017,(3):49-53.
[3]邱春艳.期刊文献与科学数据的关联服务研究[J].情报资料工作,2014,(2):63-66.
[4]郭学武.基于引文的科学数据与科技文献关联研究[J].情报科学,2014,(4):59-62,125.
[5]黄筱瑾.基于元数据的科学数据与科技文献关联研究[J].情报理论与实践,2013,(7):27-30.
[6]郑淑容,赵培云.科学数据共享管理:问题及对策[J].中国科技成果,2003,(23):8-10
[7]秦健.元数据与科学数据信息的组织与管理[EB].2004年数字图书馆前沿问题高级研讨班.http://www.docin.com/p-19306708.html,2015-04-04.
[8]黄如花,邱春艳.Dryad数据仓储的元数据管理[J].图书馆杂志,2014,(1):68-73.
[9]PANGAEA[EB].https://www.pangaea.de/?t=Oceans,2017-07-17.
[10]金更达.文献类电子资源元数据发展浅议[J].大学图书馆学报,2003,(6):15-19.
[11]我国数字图书馆标准规范建设:期刊论文描述元数据规范[EB].https://wenku.baidu.com/view/7934fe2bccbff121dd3683 a4.html,2004.5.
[12]刘斌,陈桦.向量空间模型信息检索技术讨论[J].情报杂志,2006,(7):92-93,91.
[13]国家地球系统科学数据共享服务平台.青藏高原东缘森林生态系统土壤有机质和养分数据[EB].http://www.geodata.cn/data/datadetails.html?dataguid=243357923654808&docId=576,2017-07-17.
[14]ROST虚拟学习团队.ROST Content Mining System User Manual[EB].http://wenku.baidu.com/view/e7a62df3f90f76c661371a 76.html?re=view,2017-04-02.
LinkStudyofScientificDataandScientificLiteratureBasedonContentFeatures
Huang Xiaojin
(Library,Chengdu University of Technology,Chengdu 610059,China)
Scientific data and scientific literature are two important forms of scientific research outputs.Link application of scientific data and scientific literature plays a vital part in realizing integrated information service,facilitating knowledge discovery and improving e-science environment.The paper extracted content features from the metadata of both,used vector space model to perform similarity calculation of content features.So then,it associated the scientific data and scientific literature on the basement of content features.
scientific data;scientific literature;metadata;vector space model;feature extraction
10.3969/j.issn.1008-0821.2018.01.008
G257.3
A
1008-0821(2018)01-0056-04
2017-09-13
四川省高校人文社会科学重点研究基地科研项目“社会科学数据与社科文献关联性研究”(项目编号SCAA14B18)。
黄筱瑾(1984-),女,馆员,硕士,研究方向:信息资源组织与建设。
(实习编辑:陈 媛)
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
新世纪智能(数学备考)(2021年9期)2021-11-24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
当代陕西(2019年15期)2019-09-02
计算机技术与发展(2018年8期)2018-08-21
学苑创造·A版(2018年11期)2018-02-01
中国机械工程(2017年22期)2017-12-02
读者(2017年5期)2017-02-15
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
