
教育大数据下个性化资源推送服务框架设计
2018-01-04 23:38李宝张东红
中国远程教育 2017年9期
李宝+张东红

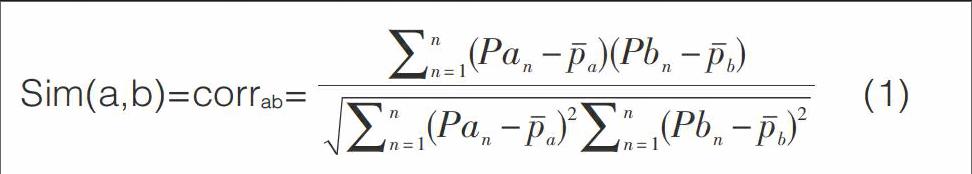
【摘 要】
从学习者角度出发,立足于学习者个体的静态数据和学习中产生的动态学习行为数据,采用动态数据为主、静态数据为辅的获取方式确立学习者特征模型。参照Hadoop中的数据处理技术,从数据收集层、数据存储层、数据分析层和呈现层构建学习者个性化学习资源推送框架。最后,结合个性化资源推送框架,对个性化资源推送服務的实现途径进行分析,提出基于资源最邻近、基于相似用户矩阵库、基于特征匹配、基于学习者反馈和基于内容等混合推荐方法实现个性化学习资源的推送,以期对个性化学习资源推送的研究提供指导。
【关键词】 教育大数据;个性化学习;学习者特征;Hadoop;个性化资源推送
【中图分类号】 G434 【文献标识码】 B 【文章编号】 1009-458x(2017)09-0062-08
一、引言
随着新兴技术和媒体的快速发展及应用,技术俨然已经在教育信息化中扮演着重要的角色。近年来,教育大数据、学习分析、自适应学习等概念出现,高等教育、继续教育等学习方式在移动学习、泛在学习等基础上有了改变,逐步衍生出新型的学习方式——个性化学习。《2017年新媒体联盟中国高等教育技术展望:地平线项目区域报告》中提到:个性化学习和教育大数据的管理问题对于中国高等教育中影响教育技术应用来说是富有难度的挑战(金慧, 等, 2017)。个性化学习指的是在学习中要满足不同学习者的需求,其中自然要考虑不同学习者的个体差异。学习分析恰恰为获取学习者个体差异提供了解决方案,学习分析主要是运用学习者在学习过程中产生的教育数据及分析模型来发现信息和社会联系并预测和建议学习的技术(Siemens, 2012)。因此,学习者个体特征的构建是个性化学习的前提。个性化学习资源推送的实现需要依靠学习分析技术从海量的教育大数据中挖掘有价值的数据,从而分析出学习者的特征,为个性化资源推送提供依据。如何从教育大数据中分析或构建出学习者特征,如何依据学习者特征进行推送,已经成为个性化学习资源推送领域的重要议题。
二、文献回溯
从教育大数据的文献整理发现,近年来教育大数据下的研究逐步倾向于学习分析、个性化学习、自适应学习等。如杨现民(2016)提到,教育研究者已经在探讨大数据时代背景下教育模式的转变、学习方式的变革等,甚至逐步开始探讨学习分析、数据挖掘等;孙洪涛和郑勤华(2016)通过教育领域大数据的构成与特征分析,对教育大数据技术在国际范围内的典型案例实践进行探讨,主要聚焦于适应性教学、精准管理支持等方面;裴莹和付世秋(2017)通过整理国内教育大数据的研究热点,发现2015-2016年教学决策等问题受到关注,要求教师能够结合学习分析结果制定针对学习者的个性化教学路径;贺超凯和吴蒙(2016)结合edX平台上学习者学习分析行为记录来归纳学习行为特征,结合学习行为分析结果来判定学习者是否可以完成学习任务及获取证书。综合教育大数据研究现状来看,目前个性化学习是热点问题,但重点针对教育大数据下个性化学习资源推送服务的研究一直处于探索阶段。
通过对个性化学习资源推送服务的文献梳理,目前的研究主要集中于利用静态数据、动态数据或者静态和动态相结合的方式完成个性化学习资源推送。其中,利用静态数据完成个性化资源推送服务的研究主要依靠调查学习者受教育程度、感知技术易用性、自我效能感等个体差异的数据或者利用学习风格量表的测量来完成。如Rishi D. Ruttun(2012)重点从认知差异、计算机领域知识与学习绩效、导航与学习态度等考虑个体差异性;Raymond A. Noe(2013)从五大个体特征维度(随和、责任、情绪稳定、外向性、经验开放)、自我效能感、热情等考虑个体差异性;Uros Ocepek等(2013)通过学习者学习风格的调查结果和学习资源的类型之间进行匹配,依据不同学习风格学习者对于资源的偏好来实现个性化资源推送。研究中利用动态数据搜集完成个性化资源推送主要集中于根据学习者学习行为、学习偏好、学习习惯自动调整以满足学习者个性化学习的需求。如Xu Jia-Liang等(2012)在对传统向量空间方法的基础上进行修改,采用递归算法获取学习者的兴趣;Wang Shu-Lin和 Wu Chun-Yi (2011)通过知识内容规范、建立学习者档案袋、学习行为监测等建立自适应泛在学习系统,应用语义感知和协同过滤实现个性化资源推送;Sergio Gomez和Panagiotis Zervas(2014)利用语义感知系统UoLmP实现自适应和个性化移动学习;牟智佳和武法提(2016)提出通过个人信息、学业信息、关系信息、偏好信息、绩效信息等构建电子书包学习系统的学习者模型,以学习者模型作为资源推送的依据;Seo Young-Duk和 Kim Young-Gab(2017)通过给相似学习者推送同一主题或者利用数据分析将学习中利益相关的学习者进行相互推送。近年来,研究者更加偏向于静态数据和动态数据相结合方式来实现个性化学习资源的推送。如吴青和罗儒国(2014)提出了在显式获取学习者学习风格的基础上,运用J48算法挖掘学习者学习过程中的行为特征,建立学习者学习风格模型;李宝和张文兰(2015)通过Felder-Silverman量表等前测静态数据和对学习者学习中的行为进行挖掘分析相结合的方式构建学习者特征模型,并采用协同过滤和相似度匹配实现个性化资源推送。
从三种实现个性化学习资源推送的方式来看,利用动态数据构建学习者特征模型的前提必须是有大量的学习行为发生,有了教育中的行为数据才可以分析出学生的个体特征。显然,该方法对于刚进入平台的学习者不太容易实现,会产生“冷启动”的现象;而利用静态数据的调查结果分析学习者特征,往往会由于问卷填写不准确造成结果的模糊或不明晰,同样无法有效地实现个性化资源推送。鉴于此,本研究立足于静态数据和动态数据相结合的方法来分析学习者特征,对刚刚进入平台学习的学习者,首先进行学习风格的调查,之后结合学习过程中的行为数据分析来构建学习者特征模型,最后采用学习者特征和资源库特征相互匹配的方法实现学习资源的个性化推送。
三、教育大数据中学习者特征的构建
在获取学习者特征的过程中,主要采用动态获取数据分析为主、静态获取数据分析为辅的形式来构建学习者个体特征。静态数据获取主要适用于没有平台学习经历的学习者,采用调查的结果作为参考依据;动态数据获取适合于有学习行为发生的学习者,只要有大量的学习行为数据,就可以进行分析。
(一)静态学习者特征的数据获取方式
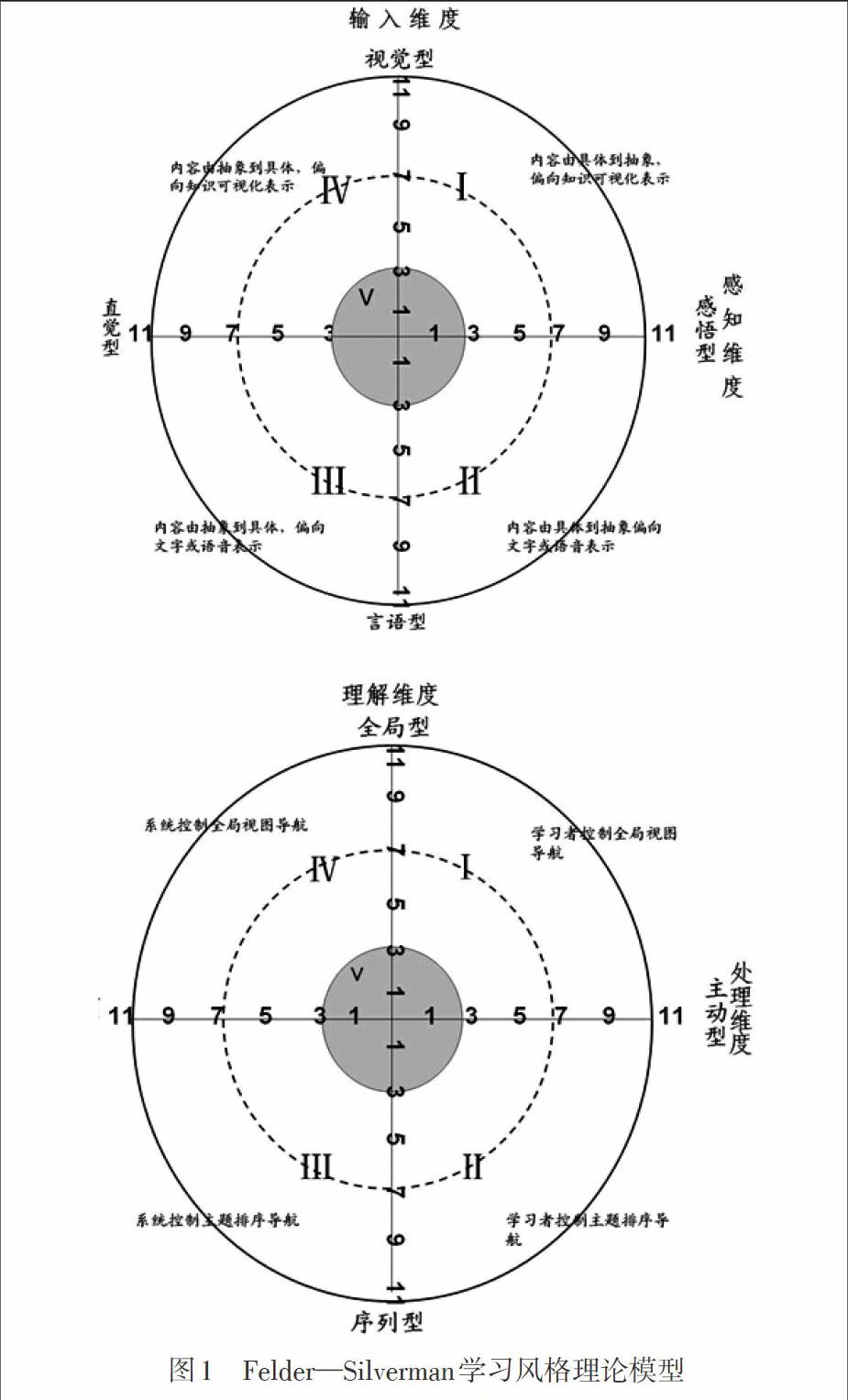
文献研究中出现过的学习风格量表较多,有Felder-Silverman学习风格量表(信息加工、理解、输入、感知四个维度)、Kolb的检验学习风格量表(聚敛型、发散型、通话型、顺应型四个维度)、Myers Briggs人格类型的学习风格量表(水平维度、垂直维度、深度维度三个维度)、VARK量表(视觉型、听觉型、读写型、动觉型四类学习风格)、格拉峡—里奇曼学习风格量表、多元智能理论学习风格量表和赫尔曼的大脑四象限分工及优势测定量表等。目前,研究中使用Felder-Silverman学习风格量表的频率较高。Felder-Silverman学习风格量表按照信息加工、理解、输入和感知四个维度进行组织,每个维度都有11道题,由于每个维度划分成两种类型,所以每道题有a、b两个选项内容与之对应。如图1所示(李宝, 等, 2015),每种维度的取值可能是:11a、9a、7a、5a、3a、a、11b、9b、7b、5b、3b、b中的一种。其中,“a”和“b”表示学习风格,“a”和“b”前系数表明程度,分值在1-3属于学习偏好弱,5-7说明学习偏好适中,9-11说明学习偏好强烈。本研究进行静态数据的获取主要利用该量表进行,如果学习者之前没有参加平台任何课程的学习,注册进入平台后需要先填写该量表,根据调查结果初步建立学习者静态的个体特征。
(二)动态学习者特征的数据获取方式
动态学习者特征的数据获取方式主要是从教育大数据中进行挖掘和分析产生的。大数据是随着信息化时代数据的扩展和膨胀,从数据科学研究中诞生的一个研究前沿问题,主要由海量交易数据、海量交互数据、海量数据处理三项技术趋势汇聚而成(Philip Chen & Zhang, 2014)。学习平台中的数据大多集中于海量交互数据,涉及学习者在课程学习平台、讨论社区、媒体数据资源交互、协作学习、虚拟聊天等产生的海量交互数据。在对这些海量的动态交互数据进行处理时,可以借鉴大数据中海量数据处理的技术,依靠数据密集型处理架构,通过公共云等方式对数据进行存储,利用开源码的Hadoop分布式文件系统对数据进行分布处理(Kambatlaa, Kollias, Kumarc, & Gramaa, 2014),如图2所示。
在Hadoop中主要由分布式文件系统(Hadoop Distributed File System, HDFS)和MapReduce引擎两部分组成。HDFS在底层,主要存储Hadoop集群中所有存储节点上的文件;MapReduce在HDFS的上层,利用MapReduce数据处理框架对数据进行分析,该框架同样适合于针对学习者的个性化学习过程。最底层的应用数据、数据库、行为日志、其他数据源都可以看成学习者学习过程的数据。其中,其他数据源可以从学习者参与任何平台课程学习中去获取;针对底层的数据在数据集成层以元数据的形式集成,或者将某个学习者参与其他平台学习中产生的一些数据直接利用Sqoop工具导入到数据集成层,数据集成层主要是采集与学习者学习有关的数据;在文件存储层,采用主从架构,分布式文件系统HDFS由一个NameNode和若干个DataNode组成。DateNode管理存储文件的Block,数据在文件存储层会将一个数据文件分成多个Block,一般的存储大小为64M或者128M;数据存储层主要是进行分布式列存储的HBase数据库设计,HBase其实也是Hadoop系统中用于海量结构化数据存储,可以根据学习者过程数据的利用方式设计数据库存储方式;数据存储后,在编辑模型层主要利用MapReduce进行数据预处理,将学习过程的数据处理分为Map和Reduce两个阶段。Map阶段,程序处理大量的数据从而得到一系列的学习行为数据的关键字Key和對应的值Value,一个关键字名称与一个值相对应;Reduce阶段,将得到的所有关键字和对应的值进行聚合运算,同一关键字Key对应的所有Value聚合到一块。这种方法可以利用关键字Key将同类学习者、同类知识点单元等对应学习过程的数据属性值聚集到一起,聚集起来的学习过程动态数据在数据分析层进行清理、转换、迁移、分析后,可以构建出学习者的特征或者产生学习者学习行为分析数据。
(三)学习者特征的确立
在建立学习者特征模型之前需要判断学习者是否首次进入平台学习,如果是,采用静态数据获取的方式建立学习者特征模型;如果不是,需要结合首次进入获取的静态数据和学习行为发生后获取的动态数据进行对比,确认学习者模型。学习者模型分析中需要利用数据存储层存储的数据,然后在分析层对学习者的个体特征、学习状态、偏好类型、学习路径、交互关系等进行分析,建立学习者状态数据库、网络交互关系库和特征模型库。同时,还需要考虑是否存在某一方面具有相似特征的学习者,利用Mojtaba Salehi(2001)等提出的Pearson相关分析方法分析学习者之间是否具有相似性,计算公式如下:
式中Pan、Pbn表示学习者所处某个状态的特征值,[Pa]、[Pb]表示a学习者和b学习者特征的均值。
相似用户特征库的建立一方面确立了学习者特征,另一方面将同一特征的学习者聚集到群库中,在进行个性化资源推送时,可以将其看成同一类学习群体,考虑基于学习者群体或相似用户特征库的推荐。数据分析层将相似用户特征库连同学习者状态数据库、交互网络数据库和特征库一起存放在MySQL集群中,为个性化资源推荐提供依据。
四、个性化资源推送服务框架
在分析和构建了学习者特征模型之后,为了进一步有效地实现教育大数据中学习者个性化学习资源推送的目标,基于学习者特征模型构建了基于教育大数据中学习者个性化学习资源推送框架。框架的构建参照Hadoop中MapReduce数据处理框架进行设计,主要包括数据收集层、数据处理层、数据分析层和呈现层四个方面(如图3所示)。
(一)数据收集层
数据收集层主要收集学习者的静态数据和动态学习行为数据。学习者进入平台学习某一课程时,首先利用Sqoop工具导入学习者在平台之前学习其他课程产生的行为数据并将其放在数据收集层,同时采用Flume收集学习者学习风格量表的调查数据、学习平台的日志数据、搜索引擎的记录、学习内容和学习讨论等学习行为、共享信息的记录、浏览学习内容的日志记录、消息评论等学习行为数据。Flume本身就是一个分布式和高可用的海量日志聚合系统,支持在系统中定制各类数据的发送方,主要用于采集数据。因此,使用Flume在数据收集层中可以将学习者参与平台学习产生的各类数据聚合到系统当中,解决了海量数据收集的问题。利用Flume收集到的所有数据最终分解成多个Block文件,并将其存入HDFS分布式存储系统。
(二)数据处理层
数据处理层对数据收集层采集并存储的海量数据进行处理,包括对数据进行关键词提取、分类、聚类、去重和协同过滤等过程。关键词提取主要针对学习行为中隐含学习者特征的数据进行关键字段的提取,关键词提取之后的数据字段需要依据特征标记进行分类,分类过程中如果出现相似特征的数据需要聚集在一块。例如,对同一学习者的特征数据或具有相同特征数据的学习者集群等,都可以考虑将其聚集起来;聚集起来的数据特征库需要进行去重,完成数据的清理工作,方便数据从数据仓库中的调用和节省数据存储占用的空间;去重或清理后的数据,需要采用协同过滤的方法将某些特征学习者感兴趣的资源聚集起来,主要是为分析层和个性化推荐的实现提供便利。整个数据处理层的所有数据在MySQL数据库集群作为中间结果进行存储,数据在处理层进行清洗和过滤后,就可以进入到数据分析层。
(三)数据分析层
数据分析层重点对学习者学习偏好的类型特征进行分析,同时也会结合前期问卷调查的结果构建学习者特征模型。数据分析层还需要完成学习者学习所处状态、学习互动水平、学业完成水平、学习路径特征的分析,最后在该阶段需要建立学习者特征模型库、学习者学习所处状态记录的数据库、相似用户矩阵库、交互网路关系库。其中,学习者特征模型库重点记录学习者学习偏好或学习风格等;学习者状态数据库主要记录学习者目前所处学习的位置以及完成学业情况等;相似用户矩阵库针对学习者特征、学习状态等比较类似学习者群集而成;交互网络关系库主要记录学习者之间交互讨论的学习社会网络关系,重点关注学习者与哪些学习者、学习内容等发生学习的交集行为。数据分析层产生的模型库、数据库、矩阵库、关系库等数据并存在MySQL数据库中。
(四)呈现层
信息呈现层则依据获取分析层得出学习者模型的结果,推送符合学习者的个性化学习资源并展示在客户端,即将个性化资源呈现给学习者之前呈现层需要完成学习者数据特征与数据库数据特征的相似度匹配。匹配需要将分析层分析的数据和数据仓库中资源特征库、知识模型库、学习路径集群进行相似度计算。其中,学习路径集群是将学习者学习中可能产生的学习路径汇总而成,不同的学习路径有不同的标记方式。在匹配的过程中产生相似学习者并建立用户关联模型库,最后达到学习者与学习资源、学习状态、学习路径、知识点内容等有效的匹配。匹配过程的实现其实就是完成个性化资源的推荐,如图3中推送机制所示,主要依靠基于资源推荐、基于相似用户矩阵推荐、基于特征推荐、基于学习者反馈推荐和基于内容的推荐等实现途径。匹配完成后,需要系统平台结合匹配结果相似度最大的资源推送给相应的学习者,完成资源在呈现层的展示,满足在呈现层符合学习者的个性化学习需求。
五、个性化资源推送的实现途径
在个性化资源推送框架中提到的基于资源推荐、基于相似用户矩阵推荐、基于特征推荐、基于学习者反馈推荐和基于内容的推荐等途径,其具体推荐的过程还需要进一步对实现过程和算法进行研究。个性化资源推送实现的过程主要依靠两个步骤:第一步,对知识点内容进行资源特征标记,存储在资源特征库中;第二步,结合学习者特征与资源库的资源特征,考虑个性化学习资源如何推送给相应的学习者。
(一)学习资源的特征标记
知识内容的规范采用Han和Fu(1994)提出的利用节点树的形式将知识点进行归类,每个知识点都有父节点,采用向量的矢量坐标标记知识点位置。如图4所示,树节点中每一个位置都有其相应的坐标。在知识树节点划分的过程中,首先按照知识点单元进行划分,每一个知识单元就是一个主节点,然后,在主节点中每一个节点按照学习的感知阶段、迁移阶段、创新阶段等不同状态的学习目标划分学习知识内容。因为不同阶段,同一知识点可以依据学习目标划分成不同学习状态,比如针对同一知识内容的学习却有概念掌握、交流讨论、学习迁移、学习创新等不同的阶段,而且各阶段的学习要求和目标会有所差异。最后,结合不同学习状态下知识点内容又划分不同的内容呈现方式,包括文本、图片、课件、视频、音频、作品等不同呈现类型。
从图中可以看出,整个树状图的根节点是具体的知识点,剩下树状图中的每一个节点都是围绕根节点展开的一系列學习活动设计或者知识内容的细化和延伸。
(二)个性化学习资源推送的实现
1. 基于资源最邻近的学习资源推荐
2. 基于相似用户矩阵库的资源推荐
在学习者模型构建中已建立相似用户矩阵库或相似用户特征库,在进行推送的过程中,可以参考类似学习者参与的讨论主题、浏览的学习资源、学习的路径选择等情况,将其推送给相似学习者集群中其他的学习者,并建立用户关联模型库,方便后续的推送。同时,资源特征库中存储了学习路径集群,具备海量学习者可能采用的学习路径。在相似用户矩阵库中,如果有某个学习者的特征和已经完成该内容学习的学习者表现出较高相似度,则可以按照已完成内容学习的学习者所经历的学习路径作为参考,完成个性化资源的推送服务或活动引导。
3. 基于特征匹配的资源推荐
基于特征匹配的资源推荐主要是考虑学习者特征与资源特征之间的相似度来实现推送的,资源特征与学习者特征相似度越高,优先选择推送该资源的概率就越大。进行相似度匹配的过程可以参考学习者之间相似度计算的方法,但是除了该方法之外,在进行相似度匹配时还可以利用欧式距离计算其相似度的大小。假设在将学习状态、学习者特征、知识库特征分别放在三维的坐标中,那么对于其中某一个具备学习者特征Lm的学习者来说,在资源特征库要找出和其相似度最大的资源Cn,就得在三维坐标中计算学习者特征Lm和资源特征Cn两点之间的欧式距离 ,如果满足相似度Sim=1/[1+Dist(Lm,Cn)]的值最大,即是保证Dist(Lm,Cn)最短,学习者特征与资源库特征的相似度越高。这是因为资源库中的资源特征是按照分叉树的向量方式标记的,同类知识点资源的呈現方式也会存在差异,所以计算出的距离值也会有所不同,只需要找出最短适合的欧氏距离就可以实现特征的匹配。
4. 基于学习者反馈的资源推荐
在个性化资源推送的过程中,当系统将符合学习者特征的资源推送给学习者之后,推送的资源对于学习者来说是否有效还值得检验。基于学习者数据反馈是一种有效调整个性化资源推送的途径。Wang Shu-Lin等(2011)采用公式[Pic=Pic×β](其中β≤1)来计算学习者对于推荐资源的偏好程度。式中[Pic]表示学习者反馈后推荐的概率值,可以将其称为后验推荐概率;[Pic]表示系统一开始结合学习者特征预测的最大推荐概率,可以将其称为先前推荐概率;β表示学习者对于推荐资源清单中的资源进行点击、参与等的使用或喜欢程度,由于推荐过程中可能存在知识点内容或教学设计方式不符合学习者的个体特征,造成部分推荐资源清单上的资源未访问或者学习者不感兴趣。β的值是用学习者对推荐资源感兴趣的清单数量除以实际推荐给学习者资源的清单数量,如果学习者对于推荐资源清单上所有资源感兴趣,那么[Pic]和[Pic]的值相等。除此之外,[Pic]就小于[Pic],如果出现这种情况就需要系统在后续推荐中进行调整。
5. 基于内容的资源推荐
基于内容的推荐系统主要根据学习者历史评价资源数据构造学习者偏好资源,然后计算资源库特征与学习者偏好资源的相似度,将相似度最大的资源推送给学习者。该类推荐方法首先应该完成学习者之前对资源的评论或者感兴趣的程度,主要获取学习者学习行为数据或者访问资源的频率、点击率等数据,确定学习者的偏好资源。假设资源库资源特征用向量[Rj=(R1j ,R2j,…,Rkj)]表示、学习者偏好资源特征用向量[Pi=(P1i,P2i,…,Pki)]表示,其中K表示关键词的个数。
在推送过程中主要采用余弦相似度方法计算学习者偏好资源与资源库资源相似度的值,计算公式为:
其中,K值为关键词的个数,Wmj表示特征词在资源Rj中的重要程度(权值),Wmj计算方法使用TF-IDF公式,具体公式可以参照余正涛和高盛祥(2004)的研究。
在实际应用过程中,以上五种个性化资源推送实现的方法可以考虑在不同的阶段使用不同的最佳推荐方法。如果是一个初次进入平台学习的学习者,可以使用基于资源最邻近的学习资源推荐方法和基于内容的资源推荐方法。首次进入平台学习的学习者,因为教育大数据中的“数据”处于“冷启动”状态,缺乏具体的动态学习行为数据,只能依靠学习者点击和浏览的资源分析出资源的特征,然后按照资源库中资源之间的特征匹配找出和学习者浏览资源特征最邻近的资源推送给学习者。另外,在推送过程中,可以依照前期学习风格量表的调查分析学习者特征,依据不同学习风格特征的学习者对于资源的偏好完成资源类型的个性化推荐,即基于内容的资源推荐。显然,采用基于资源最邻近和基于内容的资源推荐在实际个性化资源推荐服务的应用中处于初级阶段。后期学习中,学习者学习行为的数据产生后,就可以结合应用基于相似用户矩阵库的资源推荐方法和基于特征匹配的资源推荐方法。整个资源推荐过程需要参照教育大数据下个性化资源推荐的框架,重点从数据收集层、数据处理层、数据分析层完成学习者特征的挖掘和构建。虽然采用了多种推荐方法的分阶段和联合使用,但是有效的个性化资源推送必须达到个性化的效果,即学习者主体要满意。因此,在最后阶段可以考虑基于学习者反馈资源推荐方法的使用,通过推送资源的清单和学习者实际访问资源的清单对比,进而在后续推荐过程中进行修改和调整,完善个性化资源推荐的实现途径。
六、结语
教育大数据中个性化学习资源推送是学习者个性化学习环境下重要的学习支持服务环节,正是出现了个性化学习资源推送服务机制,个性化学习才能做到真正意义上的“自适应”和“个性化”。本研究首先结合Hadoop中MapReduce数据处理框架为参照分析学习者个体特征,重点从数据收集层、数据存储层、数据分析层和呈现层构建出学习者个性化学习资源推送框架,并对推送服务的实现途径进行分析,从五种推荐方法的实现过程及算法分析个性化资源推送的机制。本研究的不足之处是在资源推荐实现方面缺乏具体的实例分析,这也是下一步研究的方向,需要针对个性化学习资源推送服务进行实践研究,逐步完善和修正个性化学习资源推送框架和实现途径。
[参考文献]
贺超凯,吴蒙. 2016. edX平台教育大数据的学习行为分析与预测[J].中国远程教育(6):54-59.
金慧,胡盈滢,宋蕾. 2017. 技术促进教育创新——新媒体联盟《地平线报告》(2017高等教育版)解读[J]. 远程教育杂志(02):3-8.
李宝,张文兰. 2015. 智慧教育环境下学习资源推送服务模型的构建[J]. 远程教育杂志(3):41-47.
牟智佳. 2014. 电子书包中基于教育大数据的个性化学习评价模型与系统设计[J]. 远程教育杂志(5):90-96.
裴莹,付世秋,吴峰. 2017. 我国教育大数据研究热点及存在问题的可视化分析[J]. 中国远程教育(5):1-8.
孙洪涛,郑勤华. 2016. 教育大数据的核心技术、应用现状与发展趋势[J]. 远程教育杂志(5):41-49.
吴青,罗儒国. 2014. 基于网络学习行为的学习风格挖掘[J]. 现代远距离教育(1):54-62.
杨现民,唐斯斯,李冀红. 2016. 发展教育大数据:内涵、价值和挑战[J]. 现代远程教育研究(1):50-61.
余正涛,高盛祥,纪鹏程. 2004. RDAQAS中问句相似度计算方法研究[J]. 昆明理工大学学报(理工版)(2):40-44,71.
Han, J., & Fu, Y. 1994. Mining multiple-level association rules in large databases. IEEE Transactions on Knowledge and Data Engineering,11(5):798-804.
Jia-Liang Xu, & Jiao Guo. 2013. Study of Personalized Service About WAP Based on Recursive Learning. 2012 International Conference on Information Technology and Management Science (ICITMS 2012)Proceedings,443-449.
Kambatlaa, K., Kollias, G., Kumarc, V., & Gramaa, A. 2014. Trends in big data analytics. Journal of Parallel and Distributed Computing, 74(7):2561-2573.
Noe, R. A., Tews, M. J., & Marand, A. D. 2013. Individual differences and informal learning in the workplace. Journal of Vocational Behavior, 83(3): 327-335.
Ocepek, U., Bosnic, Z., Serbec, I. N., & Rugelj, J. 2013. Exploring the relation between learning style models and preferred multimedia types. Computers & Education, 69(11): 343-355.
Philip Chen, C. L., & Chun-Yang, Zhang. 2014. Data -intensive applications,challenges, techniques and technologies: A survey on Big Data.Information Sciences, 275:314-317.
Rishi, D., & Ruttun, R. D. 2012. Macredie. The effects of individual differences and visual instructional aids on disorientation, learning performance and attitudes in a Hypermedia Learning System. Computers in Human Behavior, 28(4): 2182-2198.
Sarwar, B. M., Karypis, G., Konstan, J. A., & Riedl, J. T. 2001. Item based collaborative filteringrecommendation algorithms. In Proceedings of the 10th international world wide web conference of ACM, 285-295.
Gomez, S., Zervas, P., Sampson, D. G., & Fabregat, R. 2014. Context-aware adaptive and personalized mobile learning delivery supported by UoLmP. Journal of King Saud University-Computer and Information Sciences, 26(1): 47-61.
Shu-Lin Wang, & Chun-Yi Wu. 2011. Application of context-aware and personalized recommendation to implement an adaptive ubiquitous learning system. Expert Systems with Applications,38(9):10831–10838.
Siemens, G., & Baker, R. S. J. D. 2012. Learning Analytics and Educational Data Mining: Towards Communication and Collaboration. In B. S. Simon. Proceedings of the SecondInternational Conference on Learning Analytics & Knowledge. New York: ACM, 252-254.
Young-Duk Seo, Young-Gab Kim, Euijong Lee, Doo-Kwon Baik.2017.Personalized recommender system based on friendship strength in social network services. Expert Systems With Applications, 69:135-148.
責任编辑 韩世梅
猜你喜欢
教学与管理(理论版)(2017年3期)2017-04-10
电脑知识与技术(2016年28期)2016-12-21
教育教学论坛(2016年46期)2016-12-19
中国教育信息化·高教职教(2016年10期)2016-12-10
中国信息技术教育(2016年21期)2016-12-05
电脑知识与技术(2016年24期)2016-11-14
中国教育信息化·高教职教(2016年5期)2016-08-04
