
基于模拟退火的BP网络隐藏层节点估算算法
2017-12-21 07:51张世睿李心科
合肥工业大学学报(自然科学版) 2017年11期
张世睿,李心科
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
基于模拟退火的BP网络隐藏层节点估算算法
张世睿,李心科
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
单隐藏层BP神经网络在模式识别及数据挖掘等领域应用广泛,而隐藏层节点的数目受到众多因素的影响,因此节点数量的选取一直是一个复杂的问题。文章提出一种基于模拟退火算法(simulated annealing,SA)的单隐藏层BP神经网络隐藏层节点估算算法,基于经验确定隐藏节点数的下界,通过模拟退火不断增加隐藏节点个数直至算法结束,得到最优解。该方法与经验法和试凑法相比具有较强的理论依据,与遗传算法等方法相比不容易陷入局部最小值。实验证明,采用该方法估算隐藏层节点的准确率较高,速度也较快。
BP网络;模拟退火算法(SA);单隐藏层;隐藏层节点数
BP神经网络由于具有很强的自我学习能力,能够逼近任意复杂非线性函数[1],同时还能够解决传统参数方法难以找到合适规则的问题,具有较强的容错性和鲁棒性,已经被广泛应用于模式识别、信息分类和数据挖掘等领域[2-3]。
研究证明,神经网络的学习能力取决于网络隐藏层的结构,其中包括隐藏层的数目和每个隐藏层中隐藏节点的数量。增加隐藏层的数量可以有效降低网络的训练误差,提高网络识别的准确率,但也会使网络的拓扑结构更加复杂,训练时间也会更长;而增加隐藏节点数也可以提高识别的准确率,更容易观察和调整训练效果[4]。采用单隐藏层的3层结构神经网络能够逼近任意连续函数,因此本文仅研究单隐藏层BP网络隐藏层节点的选择问题。
然而隐藏层节点的选择十分复杂,节点的数目受到众多因素的影响,例如,分类的需求、数据集的大小等。与学习算法的激励函数选择相比,确定隐藏层节点数目的研究较少[5]。对于模式识别和数据集分类等问题,如果隐藏层节点数目过少,那么网络的识别准确率会较低;如果隐藏层节点过多,那么训练时间会变长,造成过训练[6]。
隐藏层节点数目选取的方法主要有试凑法[7]、经验公式法[8]、增长法[9]、遗传算法[10]以及三点式搜索等综合优化选取方法[11]。上述方法都有其局限性:试凑法是通过不断地选取网络节点的数量进行测试,直至选择结果满意为止,该方法没有目的性,只能不断盲目地进行试验,计算开销非常大,对于某些节点数较多的网络,计算效率较低;经验公式法缺少相关的理论依据,由于其公式是来自项目和试验中的经验,只能针对特定的数据集有效,不能作为通用的确定隐藏层节点的方法使用;增长法是从一个最小的神经网络结构开始试验,不断增加隐藏层中节点的数目,直至获取满意的数目为止,虽然相关研究较多,但是对于如何终止增长的问题目前没有统一的解决方法;遗传算法由于其固有的爬山能力差、收敛速度慢的问题,会导致在平坦区域搜索结果陷入局部最小值的情况;三点式搜索可能会错过全局最优解。此外,这些算法需要不断地模拟完整的网络训练过程,运行时间较长且开销大。
本文提出了一种基于模拟退火算法(simulated annealing,SA)的单隐藏层BP神经网络隐藏层节点估算算法,利用模拟退火算法局部搜索能力较强、运行时间较短的优势,快速确定网络隐藏层节点数,优化网络结构,提高网络的识别率。
1 基于SA的BP网络隐藏节点估算算法
模拟退火算法是基于统计物理的一种算法,通过引入物理系统中晶体退火过程这样一种自然的机制,采用Metropolis准则接受产生的最优的问题解。该算法最关键的一点就是对于问题的局部最小解采用一定的概率来判断是否接受,以便跳出局部极值点,继续对全局问题进行分解探究,从而得到问题的全局最优解[12]。
本文提出的隐藏节点估算算法利用模拟退火算法的优点,与增长法相结合,首先选取一个初始的隐藏层节点数,通常根据经验选择输入节点和输出节点中较大的一个为初始值,然后对网络进行一定次数的训练,通过模拟退火算法决定是继续增加节点数,还是接受当前节点数为算法的结果。重复上述过程,直至退火完成。
算法需要确定模拟退火的一些参数:
(1) 模拟退火的初始温度。该值应当足够高,从而使得产生的所有解都能够被接受,避免算法陷入局部最优解,因此,设置初始温度为100。
(2) 退火的控制函数。通常采用的公式为:Tk+1=αTk,其中,α为小于1的系数。
(3) 评价函数C(H)。该函数为在隐藏层节点数为H时,经过一定数量的训练后,网络的识别误差率。
算法的执行步骤如下:
(1) 根据具体问题确定网络的输入和输出层的个数M和N,以及网络的激励函数和学习算法,构建基本的网络模型。
(2) 选取初始隐藏层个数,根据经验可知隐藏层的个数通常大于等于输入层和输出层节点的个数,因此选择输入层节点数和输出层节点数中的最大值作为初始隐藏层个数,H=max(M,N)。
(3) 对网络进行训练,训练次数为目标次数的10%,评价函数C(H)即为步骤(3)训练后的识别误差率函数,H为当前隐藏层节点个数,输出为当前训练次数后的网络识别误差率。
(4) 增加网络中隐藏层节点的个数,计算增量Δt′=C(H+1)-C(H),若Δt′<0,则接受H+1作为新的隐藏层节点个数;否则,以概率exp(-Δt′/T)接受H+1作为网络隐藏层节点个数的新解,其中,T为当前温度。
(5) 若连续若干个新解都没有被接受,则终止算法;否则减小T,跳转到步骤(3),直至T减到很小,结束该算法。
2 实验设计与分析
本文以Fisher’sIris数据集作为神经网络的实验数据集,该数据集是一个鸢尾花卉的数据集,分为3种花,每种花各50条数据,共有150条花卉信息。3种花分别为I.setosa、I.versicolor及I.virginica。实验中分别选取每种花的前25条数据作为训练数据集,后25条数据作为测试数据集,因此,共计75条训练数据和75条测试数据。
2.1 BP神经网络结构确定
根据数据集的内容,确定神经网络的输入节点数目为4,分别表示在Fisher’sIris数据集中每种花的特有属性:花萼长度(sepal length)、花萼宽度(sepal width)、花瓣长度(petal length)及花瓣宽度(petal width)。
神经网络的输出节点数目设置为3,分别表示识别为3种花的可能性的大小,最终选择其中较大的一个值所对应的种类作为网络识别的结果去验证网络的识别准确率;对于输入数据,在读入神经网络后会进行处理;根据花的不同类型设置对应的输出节点的值为1,其他值为0,作为训练数据的输出数据。
由于本文的输入数据均为正数,为了保证收敛速度,通过线性归一化方法将数据归一化到[0,1]范围,公式为:
y=(x—xmin)/(xmax-xmin)
(1)
其中,xmin为输入数据的最小值;xmax为输入数据的最大值。
由于输入数据均归一化到了[0,1]区间,因此第1层激活函数选择S型函数,第2层激活函数选择线性激活函数,其中S型函数公式为:
f(x)=1/(1+e-x)
(2)
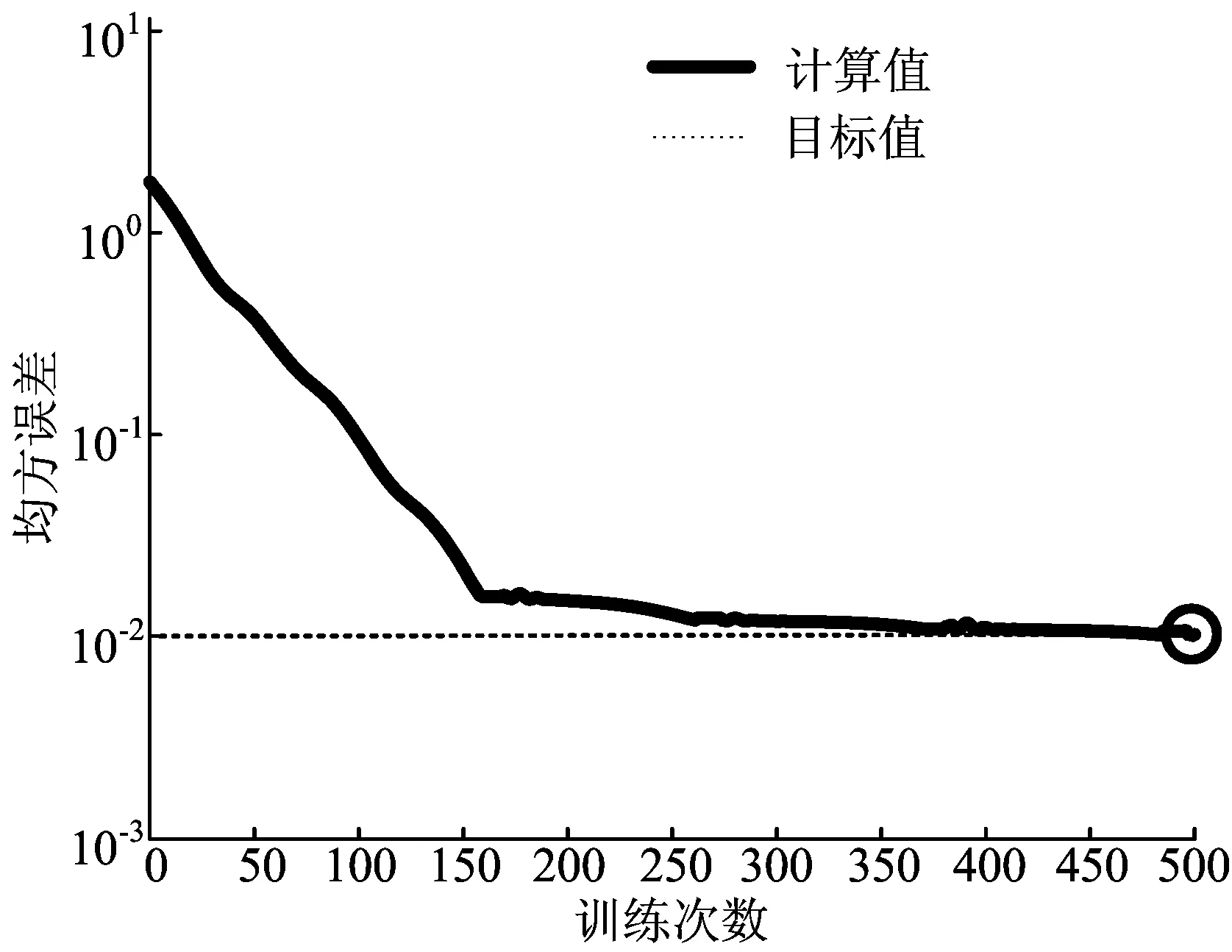
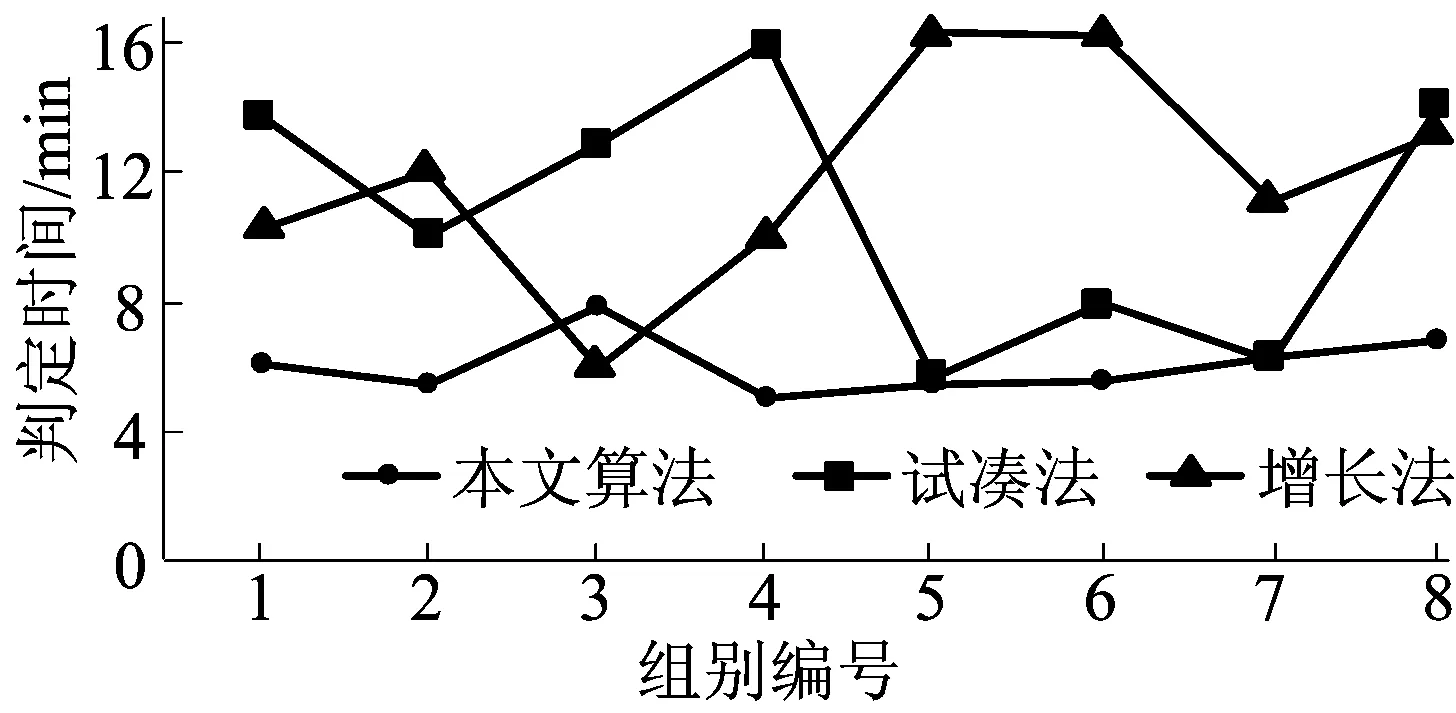
其中,0 训练函数选择有动量和自适应的梯度下降法,这是目前较为常用的一种学习算法,能够快速收敛并得出结果。设置学习迭代次数为500次,目标误差率为1%。 2.2.1 实验结果 确定初始隐藏节点的个数H=4,根据本文提出的算法不断训练网络。 在不同隐藏层节点个数下,训练50次后网络的误差情况如图1所示,当隐藏层节点数为14时,模拟退火算法判断运行结束,最终确定该鸢尾花识别模型的网络隐藏层节点个数为11。 图1 网络训练误差率 从图1可以看出,基于模拟退火算法的BP网络隐藏层节点估算算法没有陷入到局部最小值的困境中,而是继续搜索,最终找到11这样一个比较稳定的值。 为了验证实验结果的准确性,使用11作为该实验中隐藏层节点的个数,建立BP神经网络,对实验中的数据集进行了训练,训练结果如图2所示。 图2 网络训练结果信息 输入测试数据集对该网络的识别率进行了验证,识别率高达98.667%,证明了选取的隐藏层节点数合适,网络识别率较高。 2.2.2 3种方法结果对比 采用本文算法、试凑法及增长法在上述数据集上进行了多次实验对比。 3种方法的判定时间如图3所示。从图3可以看出,本文算法与试凑法和增长法相比能够更快地获得准确合适的隐藏层节点个数,说明本文算法的准确性较高,且速度较快。 图3 3种方法判定时间对比 本文提出了一种基于模拟退火算法的单隐藏层BP神经网络隐藏层节点估算算法,实验证明该算法能够有效且快速地寻找到合适的隐藏层节点个数,网络工作正常,识别率较高。与传统的试凑法和经验公式法相比,本文算法具备了较强的理论依据,结果更可信;与遗传算法等算法相比,又解决了容易陷入局部最小值的问题。本文算法可以作为一种有效的确定单隐藏层BP神经网络隐藏层节点的方法在实践中使用。 下一步的工作将继续完善该算法,确定更优化的初始节点数选取方法以及每次迭代的步长,并将该方法应用在更多的实际数据集中,以期发现方法中存在的问题。 [1] LIPPMANN R P.An introduction to computing with neural nets[J].IEEE ASSP Magazine,1987,4(2):4-22. [2] 王华强,袁浩,杨滁光.自适应模糊神经网络在EPS中的应用[J].合肥工业大学学报(自然科学版),2011,34(2):188-191. [3] 韩江,李雪冬,夏链,等.基于粗糙集的模糊神经网络在故障诊断中的应用[J].合肥工业大学学报(自然科学版),2012,35(5):577-580. [4] CURTEANU S,CARTWRIGHT H.Neural networks applied in chemistry:I.determination of the optimal topology of multilayer perceptron neural networks[J].Journal of Chemometrics,2011,25(10):527-549. [5] ZANCHETTIN C,LUDERMIR T B,ALMIDA L M.Hybrid training method for MLP:optimization of architecture and training[J].IEEE Transactions on Systems,Man and Cybernetics,Part B: Cybernetics,2011,41(4):1097-1109. [6] SUN J.Learning algorithm and hidden node selection scheme for local coupled feedforward neural network classifier[J].Neurocomputing,2012,79(3):158-163. [7] BENARDOS P G,VOSNIAKOS G C.Optimizing feedforward artificial neural network architecture[J].Engineering Applications of Artificial Intelligence,2007,20(3):365-382. [8] MIRCHANDANI G,CAO W.On hidden nodes for neural nets[J].IEEE Transactions on Circuits and Systems,1989,36(5):661-664. [9] ISLAM M A,YAO X,MURASE K.A constructive algorithm for training cooperative neural network ensembles[J].IEEE Transactions on Neural Networks,2003,14(4):820-834. [10] 邓万宇,郑庆华,陈琳,等.神经网络极速学习方法研究[J].计算机学报,2010,33(2):279-287. [11] 高鹏毅.BP神经网络分类器优化技术研究[D].武汉:华中科技大学,2012. [12] 傅文渊,凌朝东.布朗运动模拟退火算法[J].计算机学报,2014,37(6):1301-1308. AnestimationalgorithmofBPneuralnetworkhiddenlayernodesbasedonsimulatedannealing ZHANG Shirui,LI Xinke (School of Computer and Information, Hefei University of Technology, Hefei 230009, China) Single hidden layer BP neural network has achieved widespread success in pattern recognition, data mining and other fields. The number of hidden layer nodes is affected by many factors, so the selection of the number of nodes has been a complex issue. In this paper, an estimation algorithm of hidden layer nodes of single hidden layer BP neural network based on simulated annealing(SA) is presented. The lower bound of the number of hidden nodes is determined based on the experience. Through increasing the number of hidden nodes until the end by SA, the optimal solution is gotten. Compared with experience method and trial and error method, this method has strong theoretical basis. Besides, it is not easy to fall into local minimum compared with genetic algorithm. Experimental results show that this method has higher accuracy and faster speed in the estimation of the hidden layer nodes. BP neural network; simulated annealing(SA); single hidden layer; number of hidden layer nodes 2016-03-30 张世睿(1991-),男,安徽芜湖人,合肥工业大学硕士生; 李心科(1963-),男,江苏徐州人,博士,合肥工业大学副教授,硕士生导师,通讯作者,E-mail:Thinker-lee9268@163.com. 10.3969/j.issn.1003-5060.2017.11.010 TP183 A 1003-5060(2017)11-1489-04 (责任编辑 张淑艳)2.2 实验结果与分析

3 结 论
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
小学生学习指导(低年级)(2021年9期)2021-10-14
中国金属通报(2020年2期)2020-06-30
合肥工业大学学报(社会科学版)(2020年2期)2020-05-14
合肥工业大学学报(自然科学版)(2020年1期)2020-02-24
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
软件(2017年7期)2018-01-24
校园英语·中旬(2017年11期)2017-10-25
