
深度信念网络的等效模型及权值扩展算法研究
2017-12-20 06:00高强王明
电测与仪表 2017年23期
高强,王明
(华北电力大学电气与电子工程学院,河北保定071003)
0 引 言
机器学习作为人工智能技术的新发展,被广泛应用于计算机视觉、语音识别[1]、手写体识别[2]、人脸识别[3]和图像处理等领域。其中,由Geoffrey Hinton[4]提出的深度信念网络(Deep Belief Network,DBN)是机器学习中最重要的网络结构之一,不同于支持向量机(Support Vector Machine,SVM)使用数学方法和优化技术来构造超平面进行分类,其使用大量的数据训练提取特征,得到最终的模型来进行分类和识别。在实际的绝缘子故障识别应用中,具有较好分类能力的深度信念网络是一个较好的检测手段。数据是模型训练的关键,数据量要足够大,模型的泛化性才能好,否则得到的模型不能形成对整个数据的描述,存在过拟合现象。
目前人们对DBN的应用研究[5-9]已经非常多,但是DBN理论上的模型不够清晰,实际应用中还存在很多小样本问题。关于神经网络中的小样本问题,大部分的出发点都是扩充样本数或者间接利用小样本来辅助优化网络模型,如文献[10]中利用小样本对神经网络可能的组合参数进行模拟训练和测试,选取最优化的一组神经网络参数,进而提高对特定样本的识别效果;文献[11]中则是利用原始小样本数据训练神经网络,得到与原始数据样本规律相近的扩充数据样本,利用扩充的数据样本再来进行网络运算;而文献[12]则利用前期收集的系统的可靠性数据来对样本进行扩充。或者利用小样本数据来进行模型参数估计和预测[13-14],也是小样本问题的主要方向,暂时还没有还没有应用在图像分类上的相关算法。本文研究了深度信念网络的等效模型,基于此模型提出了区间化扩展权值的方法,通过扩展权值,增大样本和权值的匹配范围,提高小样本模型的分类性能,进而有效提升绝缘子的分类性能。
1 深度信念网络的等效模型研究
DBN具有多层结构,是一种能量模型,其可视层和隐含层的联合组态能量表示为:

式中vi、hj分别是可视层和隐含层的节点状态;ai、bj分别为可视层和隐含层节点对应的偏置值;wji为可视层与隐含层之间的连接权重值。隐含层节点的输出为:

隐含层的输出hio(n)=[h1h2...hM]T,权值wj(n)=[w1w2...wM]T,M是隐含层神经元的个数。对能量公式(1)进行整理。将式(2)代入式(1)中,得:

求解DBN收敛的结果,就是使式(4)达到最小。
为了看清楚DBN的行为,设输入的样本是一个已知的“信号”与噪声的混合波形,即:

式中s(n)表示样本中同类的相同部分;n(n)为随机干扰;上标l表示样本序号,共有L个样本,信号与噪声互不相关,即且
1.1 偏置的表达

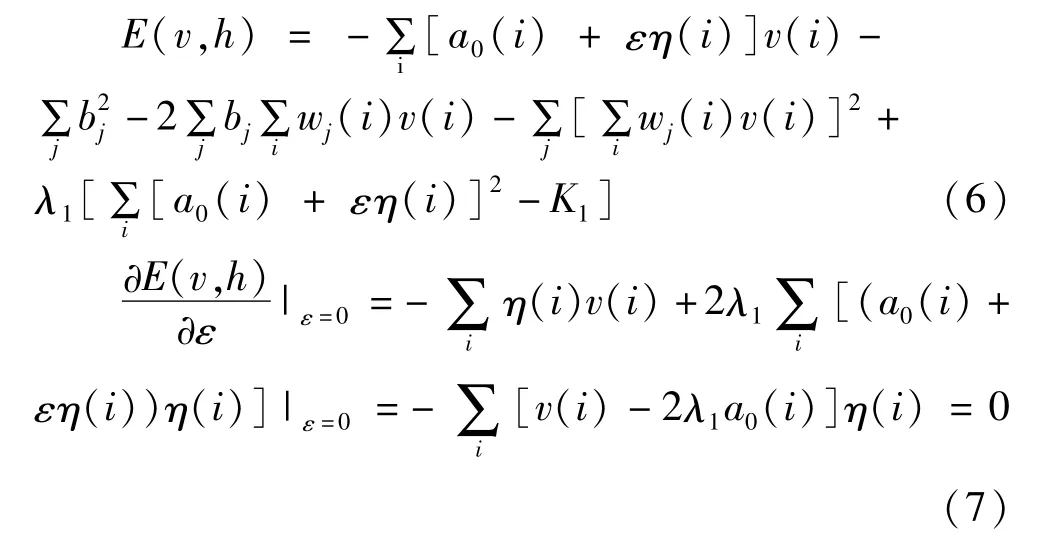
由于η(n)是任意函数,因此,要求:

即:

在多个样本输入的情况下,用 v(l)(n)表示不同的样本,若共有L个样本,可以得到由式(9)构成的方程组:

所有的样本求和得:
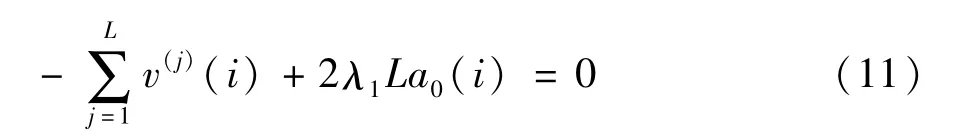
可得:

将 a0(i)代入式(4),得:
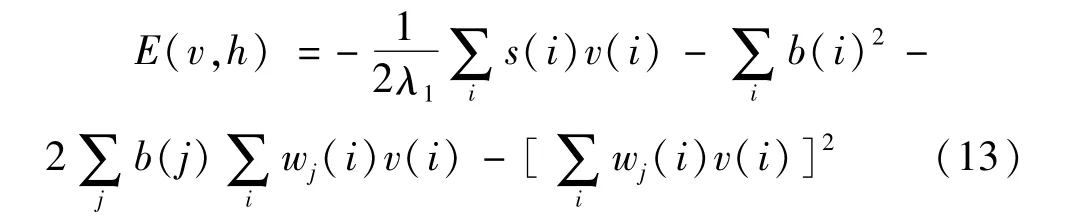
同样,采用求解ai的变分法对bj求解,同样用序列形式 b(n),设 b(n)=b0(n)+εη(n),代入式(13)求解得:

将式(14)代入(13)得:

1.2 权值的收敛
对于权值,采用同样的推导方法,利用变分法求解权值 w1(n),设 w1(n)=w10(n)+εη(n)代入式(15),对其整理求解得:

其中,k3为常数,由以上推导可以看出当权值收敛于信号时,DBN网络可以得到最优解。当样本数量很大时,信噪比较大,噪声趋近于0,权值收敛会很接近于信号,此时分类效果很好。
2 DBN等效模型结构
由于DBN是并行处理结构,即网络在同时处理每一个数据,看上去比较复杂。如果采用串行结构表示,是非常简单明确的。根据以上的参数推导过程,假定DBN网络只有一个隐含层,且隐含层只有2个神经元,对两类样本进行分类,两类样本v1(l)(n)和v2(l)(n)分别为:
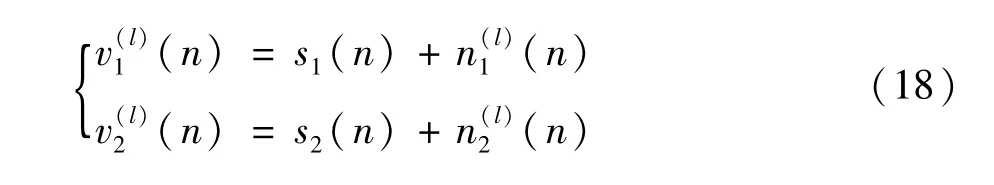
即每一类样本中都有一个相同的本类信号s1和s2,权值 w1(n)和 w2(n)是提取的样本特征,则 DBN的等效模型与通信系统的最佳接收机形式完全一致,如图1所示。
对DBN的训练是寻找最佳权值的过程,也就是寻找最匹配的“信号”,使分类效果最好。因此,找到的“信号”大致接近真实的信号时,就是一个解,但不一定是最优解。希望训练模型得到的最优解,就是权值 w1(n)和 w2(n)分别收敛于信号 s1和 s2。
在实际应用中,隐含层神经元个数往往大于2,其等效模型为多个最佳接收机的并联结构。此时,不再是一个权值对应一个信号,而是多个“部分信号”组合起来表达一个“信号”,训练使系统的能量公式达到最小,权值收敛到各自的“部分信号”时,整个网络达到收敛。多层DBN网络基本重复前一层的结构。

图1 基本DBN结构的等效模型Fig.1 Equivalentmodel of basic DBN structure
依据最佳接收机理论可知,DBN网络的分类性能就是系统的抗噪声性能。只有当样本数量足够大时,即噪声服从正态分布时,才能得到最佳的性能;从权值的推导中也可看出,样本数量足够大,权值收敛会更接近于信号,获得更好的分类效果。因此,在小样本的情况下,信噪比小,权值很难收敛于信号,接收机一般得不到最佳性能。如何解决小样本情况下的这些问题,需要进一步研究。
3 BP网络的权值区间化算法
区间数是不确定性理论的延伸和发展,由于各种测量和运算的不精确所带来的数据误差,以及信息不完全所带来的数据缺乏导致得到的结果是一个不确定的数[15]。实际存在各种不同的客观情境以及人主观思维的不确定性,对事物的属性往往有着不确定性的判断,所以只能给出一个大概的范围,不能清楚地得到事物的属性值,这就需要区间数来刻画此类问题。因为它符合人类的思维特征,也符合现实情况。
基于此思想,针对小样本情况下模型泛化性差问题,我们对权值中的每一个分量在一定的经验值或理论值范围内进行若干细分,进行区间化扩展,即原来权值每一个分量都被扩展成与其本身紧密相关的一个小区间内的多个数,以提取更多相似的样本信息,来改善小样本情况下训练模型的泛化性。并对BP算法进行相应的区间化改进,扩大搜索范围,以增加样本与权值的匹配范围,提高样本识别率,改进模型性能。
设DBN网络有m个显层神经元,n个隐含层神经元,输入的一个样本为S=[s1s2s3...sm],权值矩阵为W,扩展后的权值矩阵为W′,即W1扩展后为 W1′=[W11W12W13...W1k],将每一个权值区间化扩展到k维,每一个区间化的权值中的分量都对应着一个隐层输出,则隐层输出扩展为k批,第j批DBN隐含层结点和输出结点的操作特性为[16-17]:

其中,netlj为隐层输出,Wlji为权值W的第l个分量的第j个扩展值的第i维,f仍为激活函数。网络误差定义为区间化后的所有扩展值的均值,即:

Elj是权值第l个分量第j个表征矢量的误差,EK即为第j批扩展值的网络误差;yl是第l个输出神经元的期望值;Vlj是输出神经元的实际值。则误差信号为:

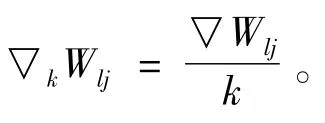
4 区间化算法的性能分析
4.1 区间化权值后的判决性能
在信号检测与估值[18]理论中,图1给出的DBN模型为最佳接收机模型,对样本的分类问题与对确知信号进行检测是完全一致的。在分析信号检测性能时,与信噪比和互相关系数等紧密相关。因此,区间化权值处理,没有改变模型结构,其性能是一致的。同样,假定DBN网络只有一个隐含层和2个隐层神经元,对两类样本进行分类。
设发送端发送的样本y=s1+n1,即发送样本为第一类;且W1和W2已训练至收敛,即W1=s1,W2=s2,此时,最佳接收机正确判决时满足:
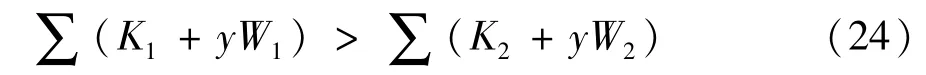
设两类样本的数量相同,可不考虑偏置 K1、K2的影响,当信号与噪声互不相关,即∑sini=0时,则上式转化为:

在样本功率归一化的情况下,样本与自身的相关性取得最大值,等于1;样本与其他信号的相关性均小于1,故不等式必然成立,能实现正确判决。两个数据大小差距为:

当权值进行区间化扩展后,网络判决式修改为:

W11,W12,...,W1n均为 W1的区间化扩展值,与W1紧密相关,即扩展值与信号s1也紧密相关,同理,W2m与s1相关性小,即任意的∑s1W1m>∑s1W2m。则上式一定成立,并可写为:

而区间化权值与标准权值紧密相关,所以W1m≈W1,同理 W2m≈W2,所以式(28)近似为:
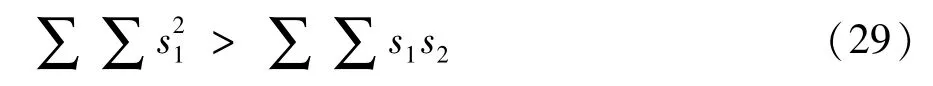
两数据的大小差距为:

由式(30)可知,在权值被扩展后,训练过程中信号被重复提取,重复提取的部分其相关性累加,要大于信号和非本类信号相乘的累加结果,判决式两端的数据差距会更大,更容易得到出二者之间的大小对比关系,其判决效果相较于单个权值时要更明显,判决性能要更好。
4.2 实验研究
为了验证上述算法和推导的有效性,实验选用MNIST和CIFAR-10数据库以及自建的绝缘子库来进行测试,因为暂时没有用于图像分类的小样本相关算法,所以将结果与传统DBN算法进行了比较,性能指标包括训练样本正确识别率和测试样本正确识别率。
(1)MNIST数据库测试
实验以MNIST手写体数据库为例,MNIST手写库总共有10类手写体数字,选取不同类别的图像为实验对象进行分类,分别测试不同样本类别数和不同样本数情况,权值区间化算法和传统DBN网络的分类性能对比如表1所示。
由表1可知,在不同的类别数情况下,权值区间化算法相比传统DBN网络,测试识别率均有提高,模型泛化性得到了一定提升,这是因为权值区间扩展后,样本与匹配的范围扩大,分类判决时的判决界限更清晰,能更好的对样本进行分类。随着样本数的减少,整体识别率逐渐降低,这是由于样本数不足,训练模型提取特征不够具有代表性引起的。随着分类类别数的增加,表现出较差的结果,这可能是由浅层神经网络自身的学习机制导致的。从表中也可看出,在样本类别数增加时,区间扩展算法对提高模型测试识别率有着更好的效果。

表1 MNIST库不同类别样本实验结果对比Tab.1 Experimental comparison results of different categories of MNIST
(2)CIFAR-10数据库测试
实验以CIFAR-10数据库为例,选取汽车和船为实验对象进行分类,每类图片选取100张,DBN网络采用三层隐含层,分别为60-200-200,实验当隐元数减半的情况下权值区间化与传统算法的结果对比如表2所示。

表2 CIFAR-10不同网络隐元数实验结果对比Tab.2 Experimental comparison results of CIFAR-10 in different hidden elements
从表2的测试结果可以看出,本文的权值区间扩展方法在CIFAR-10数据库上同样能对小样本问题取得一定的改进效果,在隐元结构改变时,也能保持其提高性能。
(3)绝缘子数据库测试
由于目前并没有公开的绝缘子数据库,本文采集了两个类别的绝缘子,用于绝缘子故障识别。该数据库中有900张绝缘子样本图像,其中包括600张正常的绝缘子,300张有故障的绝缘子,图片分辨率都为4 096。实验分别选取相同数量的正常和故障绝缘子图片作为训练集,再分别选取100张正常和故障绝缘子作为测试集,测试不同数量的训练样本情况下,不同网络的分类识别情况如表3所示。

表3 绝缘子库不同训练样本数实验结果对比Tab.3 Experimental comparison resultswith the number of training samples in insulator
由表3的实验结果可看出,对绝缘子故障识别的实验,权值区间化的DBN网络相比传统DBN网络有明显的提升效果,特别是在样本数较少,每类50张时,传统模型泛化性很差,采用权值区间化算法能有效的提升故障绝缘子的正确识别率。
5 结束语
本文研究了深度信念网络的等效模型,对DBN网络的意义进行了更加明确地阐述,指出了DBN训练需要大量数据样本的原因;并基于此模型提出了一种区间化权值的DBN网络算法,可以补偿小样本情况下,提取的特征不够全面的缺点,进而提升DBN性能,提高图像分类识别率;通过推理论证了算法的优越性。在MNIST和CIFAR-10数据库中的实验证明了这一结论的可靠性,并验证了其在实际的绝缘子故障识别中有一定的应用前景。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
中国交通信息化(2016年2期)2016-06-06
电力建设(2015年2期)2015-07-12
电测与仪表(2014年6期)2014-04-04
