
基于布鲁姆过滤器的面向IP包识别的CPBF算法*
2017-12-15 08:55李龙飞贺占庄史阳春
华南理工大学学报(自然科学版) 2017年7期
李龙飞 贺占庄 史阳春
(西安微电子技术研究所 集成电路设计部, 陕西 西安 710065)
基于布鲁姆过滤器的面向IP包识别的CPBF算法*
李龙飞 贺占庄 史阳春
(西安微电子技术研究所 集成电路设计部, 陕西 西安 710065)
针对现有布鲁姆过滤器在流识别应用中对每个IP包进行相同的处理,未考虑IP包识别失效代价和硬件开销的问题,提出一种面向IP包识别的算法——CPBF(Classified and Pipelined Bloom Filter).该算法通过引入IP头中服务类型作为识别失效代价的判断依据对IP包进行分类,根据分类结果采取不同数目的Hash函数进行映射,降低高失效代价IP包的识别失效率;同时在Hash计算中采用流水机制加速识别速率;基于概率论、微分方程等相关知识对CPBF算法进行了描述和理论分析,最后在FPGA上对算法进行实现和实验.结果表明,与标准布鲁姆过滤器、多维布鲁姆过滤器相比,CPBF在具有较低的识别失效率和硬件开销的同时,也能保持较高的识别速率.
布鲁姆过滤器;CPBF算法;IP包识别;识别失效代价;Hash函数
随着40 Gbps和100 Gbps以太网标准的相继提出,网络带宽已经不再是阻碍服务器性能的瓶颈.相反,CPU处理速度的增长远不及网络带宽的增长,且二者之间的速度差逐年增大[1].因此,在网络带宽变得越来越大,CPU处理速度保持一定的情况下,如何保证CPU对网络数据流的有效处理成了国内外学术界面临的一项极具挑战性的课题.
通过网络流识别将用户更关心的IP数据包优先交付给CPU处理是一种解决CPU处理能力与网络带宽不平衡问题的有效方案.目前主流的技术是通过IP包五元组匹配查询.五元组是指IP包中的源IP地址、目的IP地址、源端口、目的端口、协议5部分组成的向量,表征了一个IP包的基本属性.该技术在HPC、云计算、大数据、数据库和高频交易等领域拥有广泛的应用前景.
IP包识别的研究发展至今,流识别算法可以分为基于软件的流识别算法和基于硬件的流识别算法.由于基于硬件的流识别算法并行性强、匹配查找速度较快,时间和空间复杂度都能很好地满足高速网络的发展需求,且易于SoC集成,因此成为流识别算法的研究热点.在基于硬件的流识别算法中,主要有基于三态内容寻址存储器(TCAM)的算法和基于布鲁姆过滤器(BF)的算法.由于TCAM实现成本比较高,且其存储相对独立导致共享性不好,因此广泛采用基于布鲁姆过滤器的算法[2- 3].作为一种精简的信息查询、识别方案,基于标准布鲁姆过滤器(SBF)不断衍生出多种改进算法以满足高带宽下的高识别速率,这其中以文献[4]中提出的多维布鲁姆过滤器(MDBF)算法为代表.MDBF是通过将一维的元素分解为多维,以并行的方式来提高算法匹配速度.然而, MDBF误判率较高,且由于其采用多个标准布鲁姆过滤器,硬件资源代价大.文献[5]中提出的B2PC算法采用多层的布鲁姆过滤器结构设计,对元素先分组进行识别,最后再对组进行识别.B2PC算法结构复杂,采用多层结构不仅增大了空间复杂度,而且增大了计算复杂度.MDBF与B2PC算法的共同思想是采用多个布鲁姆过滤器来换取匹配速度的提高,以硬件资源换取算法性能.文献[6]中提出的CBFM算法通过构建位矩阵,支持多维元素查询,同时也支持过滤规则的灵活配制.但由于该算法在查询时采用了遍历的方式,因此在查询效率方面略显不足.目前已有的算法[7- 12]还存在一个共同的缺陷是未考虑IP包识别失效代价,即算法对每个IP包进行相同的处理,然而每个IP包识别失效所引起的系统额外操作代价却并不相同.
本研究面向IP包识别应用,提出一种对IP包类型敏感的识别算法——分类流水布鲁姆过滤器(CPBF);文中首先对CPBF及其实现方案进行详细描述,然后基于Xilinx的Virtex 5(model:xc5vlx110)对CPBF算法进行了硬件实现,并对CPBF的性能进行实际评估.
1 标准布鲁姆过滤器
标准布鲁姆过滤器识别算法核心思想是元素集S通过Hash函数组K与一个V向量建立映射关系,其原理如图1所示.

图1 布鲁姆过滤器原理
集合S={s1,s2,…,sn}共有n个元素,通过k个相互独立的Hash函数h1,h2,…,hk映射到长度为m的位串向量V中.布鲁姆过滤器在使用前应先进行元素插入操作,即匹配规则的设定.对于给定的元素si∈S,V中位置为hj(si)的比特都置为1,其中1≤i≤n,1≤j≤k.对于元素识别操作,在判断一个元素x是否属于集合S时,计算hj(x)的值,并判断V中以该值为地址的比特位是否均为1.若各比特位都为1,则x∈S,否则x∉S.
布鲁姆过滤器不存在假阴性现象,但却存在假阳性现象,即布鲁姆过滤器不会识别不出属于集合S的元素,但却会将本不属于集合S的元素误识别为属于S,称这种假阳性现象为识别失效,对应的假阳性概率为识别失效率.为了下文表示方便,用{S,K,V}表示一个布鲁姆过滤器.
向量V中任意一比特位为0的概率表示为p,则任意一比特位为1的概率为1-p.假设Hash函数计算值服从均匀分布,则当集合S中所有元素与向量V映射完成后,V中任一比特位为0的概率为
(1)
当发生假阳性现象时,V中对应的各个比特位都为1,则假阳性的概率f为
(2)
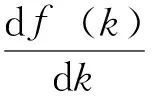

(3)
代入f得f最小值为
(4)

同理,给定f、n可得到在给定假阳性概率f下m与k的关系:

(5)
取m对k的导数,得
(6)
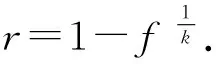
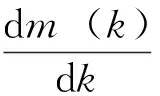
k=-log2f
(7)
为了降低假阳性概率,Hash函数的个数并不是越大越好,因为k越大向量V中的1变得稠密,假阳性的概率会增加.当n=200、m=2 560时,根据式(3)、式(4)得到,k=9时假阳性概率最小,为0.002 135.注意到,k值与处理开销呈线性关系,每个元素的识别都需要经过k次Hash计算和k次存储器访问.由式(4)可以看出m越大假阳性的概率会越小,但过大的m有违布鲁姆过滤器简洁、快捷的思想,因此在实际应用中应该根据式(5)、式(7)选择最优的m以保证占用空间最小且符合指定的假阳性概率.
2 面向IP包识别的CPBF算法
2.1 算法思路
在IP包识别的过程中,当发生识别失效现象后,本应正常处理的IP包被视为优先处理的IP包,并被系统优先进行处理.然而,采用IP包识别方法的根本目的是为了解决系统处理能力和网络带宽之间不平衡的问题,以保证用户更关心的数据包被系统优先处理,因此识别失效现象的发生会给系统资源带来更大的压力,造成系统性能的下降,称这种不利的影响为识别失效代价.因为识别失效现象会造成系统对用户指定数据包处理耗时的增加,即增大了延迟,这对于用户来说是识别失效代价最直接的表现,因此其可以作为识别失效代价大小的判定依据.
CPBF算法的基本思想是,根据IP包识别失效代价的不同,将较多数目的Hash函数映射给识别失效代价较高的IP包,以降低识别失效率;将较少数目的Hash函数映射给识别失效代价较低的IP包,在稍许增加识别失效率的同时提高识别速率,并减小总的识别失效代价.另外,在Hash函数计算中采用流水机制加速算法对IP包的识别,其原理结构如图2所示.
不同于现有的IP包识别算法,CPBF首先会对接收到的IP包分类.本研究希望根据识别失效代价对IP包进行分类,然而这却是一个难题.因为对于一个未知的IP包,现有的算法无法判断它的识别失效代价有多大,换句话说,只有该IP包通过了识别和系统的处理,其识别失效代价才能得以体现.这是一个相互制约的问题.本研究为CPBF设计了一个基于服务类型的IP包分类方法,在IP包进入布鲁姆过滤器之前估计出其识别失效代价,保证CPBF能够按类对IP包进行识别处理.
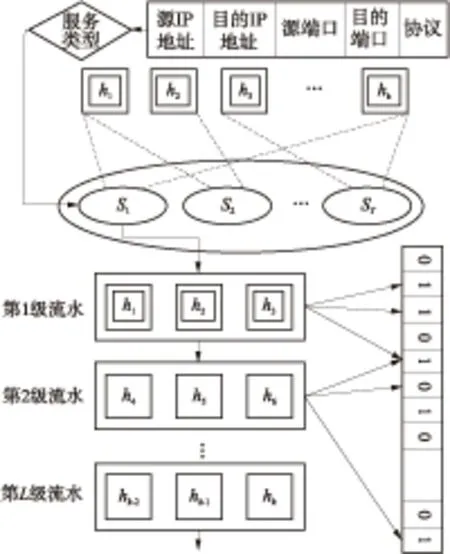
图2 CPBF原理结构
根据IP协议,在IP数据包头部有一个8位的服务类型(ToS).ToS字段最初在RFC 791标准中定义,被划分为2个子字段,前3位为数据包的Precedence域,这3位可划分8个优先级,数值越大表示优先级越高,从而使数据包对应着不同的服务类别.D、T、R和C四位(DTRC域)表示数据包所希望的服务类别.其中,D代表低延迟,T代表高吞吐率,R代表高可靠性,C表示开销低的路由.为了表示更多的优先级,RFC 2474标准对ToS字段进行了不同的定义,把前6位定义为差分服务代码点(DSCP域),用来标记数据包的服务类别;后2位用来携带显式拥塞通知信息(ECN域),比如数据包是否经历了拥塞.与Precedence域定义的8个优先级相比,DSCP域提供了64个不同的优先级,可以满足更多业务的需求[13].
在IETF 制定的这两个标准中,ToS字段只是用户表示的请求,不具有强制性.因此在以往服务种类单一、业务量少的网络环境中,网络硬件设备(例如交换机和路由器)通常会忽略ToS字段.然而现在的网络已经从面向单一的数据应用转变为面向复杂的综合业务环境.在这种情况下,网络硬件设备均会采用ToS字段作为判断依据来为不同的业务提供相应的服务.这也意味着越来越多的业务开始采用ToS字段来标记其所希望的服务类别,以保证业务质量[14- 15].
由于Precedence域和DSCP域的可读性较差,其表示的优先级并不能直接反应出数据包所希望的服务类别,相比之下DTRC域具有更明确的指向性,因此本研究使用RFC 791标准中的DTRC域对IP包进行分类.通过对当前流行的应用进行分析,得到部分应用层协议的服务类型,如表1所示.对于对延迟敏感的IP包,其多为通讯、语音数据,数据包长度小,但单位时间内数量大,一旦布鲁姆过滤器误将其判断为用户更关心的IP包,则会有大量的数据流优先占用系统资源,从而造成系统的额外开销和较大的处理延迟.因此,可以将对延迟敏感的IP包认为是识别失效代价高的IP包.同理,对吞吐率敏感的IP包多为文件传输应用,其发生误识别同样会引起大量IP包抢占系统资源的现象,因此其也属于识别失效代价较高的IP包.对于可靠性敏感、开销敏感的IP包,其多为系统控制应用和一般应用,发生误识别不会引起大量的资源被抢占,属于识别失效代价较低的IP包.

表1 部分协议的服务类型
设集合S被分为T类,S={{S1},{S2},…,{ST}},每一类Si所对应的元素个数为ni,Hash函数个数为ki,识别失效代价为ci,且当i
(8)
由于c1>c2>…>cT,因此降S1低类的假阳性概率f1可以显著减小失效总代价.更进一步,即使fT增大,只要f1足够小,失效总代价仍然会降低.
当集合S中任意一元素映射到向量V后,V中任一比特位为0的概率为
(9)
每类子集合出现假阳性的概率fi(1≤i≤T)为
fi=(1-p)ki=ekiln(1-p)
(10)
令gi=kiln(1-p),则gi∶g1=ki∶k1.取gi对ki的导数并令其为0,使gi取最小值时,得
(11)
将kmin代入式(10),得每类子集合假阳性概率的最小值:
(12)

将每类子集合Si的最小假阳性概率代入式(8),得到S的识别失效总代价的最小值Fmin:
(13)
对分类后的元素进行Hash计算时,CPBF会建立流水加速计算速率,同时降低资源开销.在实际操作中,用户关心的IP包只是海量IP包中很小的一部分,换句话说,会有大量的IP包不能通过CPBF的识别[16].由于布鲁姆过滤器的特性,只有当所有的Hash函数查询值为1时才会视为识别,因此对于不能识别的IP包,CPBF并不需要计算所有的Hash函数.
设Hash函数组K被分为Q级,在平均分配的情况下,每一级的Hash函数的个数为k/Q.CPBF首先计算第一级Hash函数,只有当第一级Hash函数查询值全部为1时,才开始第二级计算,依次类推;否则,直接判断最终结果为不匹配.Q级中任一级流水判断出元素不匹配的概率为
(14)
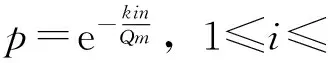
2.2 算法描述
CPBF算法中使用的参数除了SBF算法中的{S,K,V}外,还包括IP包类别T和流水级数Q,因此可用{S,K,V,T,Q}表示一个CPBF.对于一个参数确定的CPBF,T种分类所对应的Hash函数的个数是唯一确定的,因此同时可以根据参数Q确定每一级流水中Hash函数的个数.
CPBF算法的伪代码描述如下:
1. Configure the parameters of CPBF;
2. Mapping kito Sirespectively;
3. Input IP packet P;
4. Get the 5-tuple and ToS values of the packet;
5. CASE (ToS) ∥ value of DTRC
6.the highest invalidation cost: THEN
7.classify P into S1;
8.the medium invalidation cost: THEN
9.classify P into S2;
10.the lowest invalidation cost : THEN
11.classify P into S3;
12.DEFAULT : THEN classify P into S3;
13. Set up the pipeline based on classification;
14. FOR(i=1;i≤Q;i++),THEN ∥Hash pipeline
15.Update the ith level’s Hash key;
16.Calculate 5-tuple’s the ith level Hash result;
17.Check the value in look-up table;
18.IF matching THEN
19. IF i≤Q,THEN
20.Forward back;∥prospective target packet
21. Else
22.packet P is the target packet;EXIT;
23.Else
24.packet P is a normal packet;EXIT;
2.3 算法分析
从下面空间复杂度(指硬件实现时的资源开销)、计算时间(指映射后进行Hash函数计算的时间)、识别失效率(即假阳性概率)3个性能指标来进行理论分析,从而比较CPBF和SBF以及MDBF的性能.
2.3.1 空间复杂度
在参数相同的情况下,SBF的硬件开销最小,最易实现.CPBF在SBF的基础上增加了分类、流水结构,会增加一定的硬件开销.但流水结构中可以实现硬件复用,如果流水级数足够大,一定程度上可以减小硬件开销,但牺牲了对匹配元素的计算速率.因此,同计算时间一样,CPBF的硬件资源开销会受到流水级数的直接影响.流水级数为2时硬件开销最大,但此时CPBF中的Hash函数的硬件开销仍然为SBF中Hash函数硬件开销的一半(设CPBF和SBF中一个Hash函数硬件开销相同).对于MDBF,由于其采用了并行处理的方式,无法实现Hash函数的硬件复用,因此在相同的参数下,其硬件开销在三者中最大.
2.3.2 计算时间
假设每个Hash函数一次计算所需的时间均相等,且时间为t.对于参数为{S,K,V,T,Q}的CPBF,子集合Si中的元素需要进行ki次的Hash计算,那么其总计算时间为
TCPBF=(n1k1+n2k2+…+nTkT)t
(15)
因为CPBF和SBF的总元素个数相同,因此可以得到SBF总计算时间为
TSBF=(n1+n2+…+nT)kt
(16)
假设CPBF中识别失效代价最高的子集合对应的Hash函数个数等于SBF的Hash函数个数,即k1=k,那么可知k≥k2≥k3≥…≥kT.因此可以得到TCPBF≤TSBF.因为采用了流水方式,在实际操作中对于不匹配的元素CPBF所需进行的Hash计算次数会比n值小,因此总计算时间会进一步减小.根据式(14)得到在采用平均分配流水的方式下,n=200、m=2 560时,CPBF中Q级流水的第1级判断出的元素不匹配的概率如表2所示.
表2 第1级流水判断出不匹配的概率
Table 2 Probability of mismatching by the detection of the first level pipeline

Qpk=12k=2420.94940.730930.86320.562640.77500.455060.63170.3277
由表2可见,在2级流水、k=12的情况下,第1级流水有接近95%的概率可以判断出元素不匹配,那么下级流水中的Hash函数将不会再计算,因此总计算时间会减小一半.然而在流水级数较多的情况下,CPBF会进行多次的计算、查找的切换,特别是对最终结果匹配的元素,从而造成总计算时间的增大.因此在流水划分时,应根据实际需求选择合适的流水级数,保证CPBF的计算时间稳定.
MDBF采用多布鲁姆过滤器并行计算,因此其总计算时间由计算时间最长的布鲁姆过滤器决定.在MDBF中,每个布鲁姆过滤器中Hash函数的个数较SBF少,因此其总计算时间TMDBF≤TSBF.对于一个确定的MDBF,无论最终识别结果如何,TMDBF是一个定值.然而对于CPBF来说,受到流水划分和识别结果的影响,TCPBF是一个变值.在参数相同的情况下,以2级流水CPBF为例,对于最终结果匹配的元
素,TCPBF≥TMDBF;对于最终结果不匹配的元素,TCPBF≤TMDBF.如前文所述,在实际操作中,最终匹配的IP包只是很小一部分,因此对于最终结果匹配时,TCPBF≥TMDBF是可以接受的.
2.3.3 识别失效率
对于SBF,在参数{S,K,V}一定时,其识别失效率为定值;对于MDBF,在参数相同的情况下,由于其采用多个布鲁姆过滤器,且每个布鲁姆过滤器中Hash函数的个数较SBF少,因此由式(2)可知其识别失效率较SBF大.由于 CPBF根据元素的识别失效代价不同而采取不同的处理,因此其识别失效率随元素的改变而动态变化.对于高识别失效代价元素,CPBF采用较多数目Hash函数进行映射,因此fCPBF≤fSBF;对于低识别失效代价元素,fCPBF≥fSBF,然而在不考虑识别速率的情况下,可以令Hash函数个数与SBF中Hash函数个数相等,从而使fCPBF=fSBF.
2.4 CPBF集成方案实现
IP包识别在计算机网络ISO标准的数据链路层中实现[17].数据链路层由MAC子层和LLC子层(逻辑链路控制子层)构成.由于MAC子层功能明确、逻辑复杂,在MAC子层进行集成风险较大,因此本研究选择在LLC层实现CPBF与NIC的集成,其耦合方案如图3所示.CPBF与MAC之间采用标准的64位ARI接口,且对MAC透明.CPBF对IP包的处理与IP包缓存相互独立,因此在CPBF不使能的情况下不会对IP包的正常处理造成影响,具有良好的可扩展性.其工作流程如下:IP头提取模块提取出IP包中的IP五元组和ToS,由分类模块根据ToS判断出IP包的识别失效代价并进行分类.Hash计算流水控制模块根据分类结果控制Hash函数模块对IP五元组进行不同的处理.Hash函数模块中采用Toeplitz Hash,因为只需要修改Toeplitz Hash中的Key值便可实现多个不同的Hash函数.因此在流水结构中复用了Hash函数模块等诸多的硬件资源,通过Key值更新模块来实现不同Hash函数的切换,进一步节省了硬件资源.最终输出模块根据识别结果调用DMA将IP包搬移到指定的存储空间.
3 性能评估
基于Xilinx的Virtex 5(model:xc5vlx110)对文中提出的CPBF算法进行硬件实现,所有实验结果使用Xilinx的ISE仿真平台获取.为了对CPBF的性能进行实际评估,同时也实现了SBF算法和MDBF算法.CPBF实现中将IP包根据ToS分为3类,延迟敏感的IP包识别失效代价最高,吞吐率敏感的IP包次之,其他IP包识别失效代价最低,分别对应的Hash函数个数为24、12、9.MDBF实现中维数为5.其他参数三者均相同,分别为n=200、m=4 096、k=12.综合后得到硬件开销如表3所示.
由表3可见,CPBF的硬件开销与流水等级成反比关系.与MDBF相比,CPBF的Slices的使用最大减少了14.9%(Q=6),最小减少了9.8%(Q=2),平均减少了12.4%.与SBF相比,CPBF在流水级数为2、3、4时,Slices的使用分别增加了14.0%、8.1%、2.0%,在流水级数为6时减少了2.1%.随着流水级数的增大,CPBF的Slices开销逐渐减小,主要是因为Hash函数模块在硬件开销中所占的比例逐渐减小.CPBF的BRAMs较SBF增加了12.9%,主要原因是增加了流水机制后,CPBF需要缓存IP包和不同Hash函数的Key值.
表3 不同方案硬件开销对比
Table 3 Comparison of hardware costs under different solutions

算法硬件开销SlicesBRAMsCPBFQ=2827854Q=3783654Q=4740754Q=6711254SBF726247MDBF917572
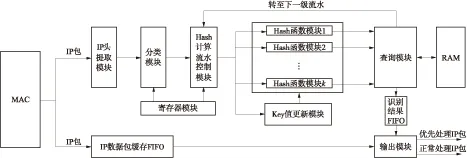
图3 CPBF与NIC耦合示意图
文中使用PALAC中的TGEN模块生成3组IP包对CPBF的识别速率进行评估.PALAC是斯坦福大学计算机系统实验室公开的包分类和测试平台[18].3组IP包个数均为2 000,每个IP包大小为300字节.在生成的3组IP包中,目标IP包,即需要CPBF识别出的IP包分别占总IP包的10%、30%和50%.CPBF和SBF均采用数据总线为64位宽的ARI接口与IP包模块相连,时钟频率为125 MHz,分别得到SBF和CPBF的总识别时间.对SBF的时间做归一化处理,如图4所示.
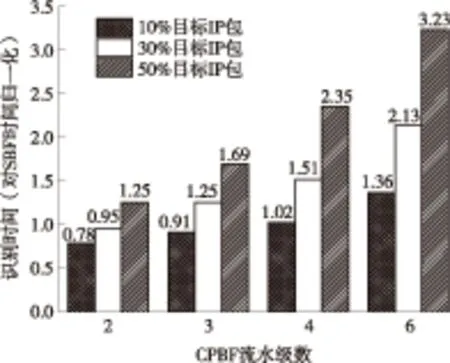
图4 不同目标IP包比例下识别时间对比
Fig.4 Comparison of matching time under different probabilities of target IP
由于3组实验中的IP包个数相等,因此SBF的识别时间为定值,为448 μs.对于CPBF,其识别时间随流水级数和目标IP包的不同而变化.在目标IP包占总IP包10%和30%的两组实验中,在2级流水的情况下CPBF的识别时间均小于SBF,分别减小了22%和5%;在6级流水的情况下,识别时间明显增加.在目标IP包占总IP包50%的实验中,无论采用几级流水,CPBF的识别时间均超过了SBF的识别时间,且流水级数越大,识别时间越长,在6级流水情况下识别时间为SBF的3.23倍.造成CPBF识别时间增大的主要原因是:①CPBF是面向偶发性或间歇性的IP包识别,适宜目标IP包占总IP包比例较小的情况;②流水级数过大造成对目标IP包识别速率的降低,从而导致总识别时间增大.因此在实际使用中,CPBF流水级数不应过大,且以2级、3级流水为宜.
为了对CPBF在实际的网络环境中进行测试,采用某单位工作站网络出口10 min的网络数据进行评测.该工作站有效用户约300人.目标IP包为指定客户机与服务器之间的邮件应用.分别进行了3次采样,采用L7-filter软件的测试结果作为目标IP包数量的真值[19],具体描述如表4所示.
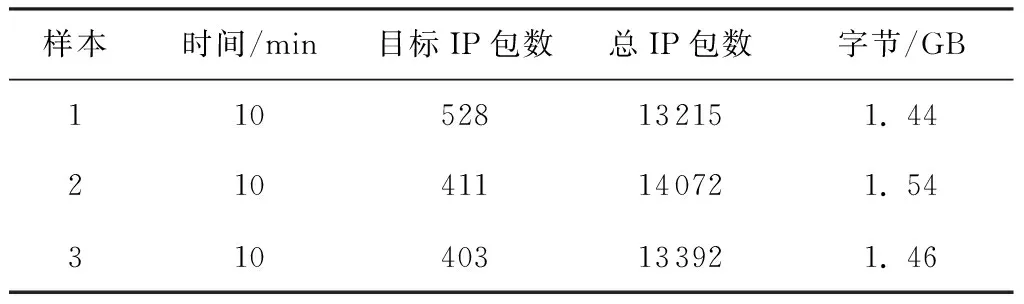
表4 测试数据集

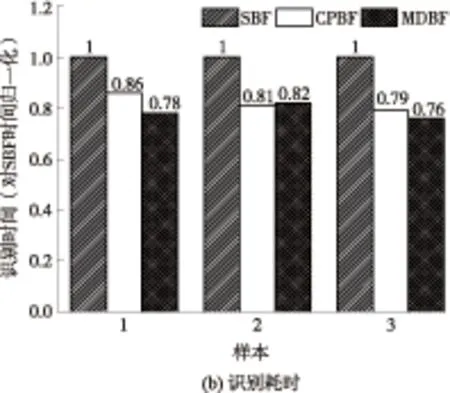
图5 实际网络环境中不同识别算法的实验结果
Fig.5 Experimental results of different matching algorithms under realistic situation
实验中CPBF采用3级流水,其他各项参数以及SBF、MDBF各项参数、实现环境均保持不变.3种算法识别结果与耗时如图5所示.实验结果表明,对于3个样本,CPBF的IP包识别数目均更接近于真实值,即识别失效的IP包数目较SBF和MDBF更低.计算得到3次样本实验中CPBF平均识别失效率较SBF降低了43.2%,较MDBF降低了61.8%;在识别耗时方面,CPBF的识别耗时较SBF平均减少了17%,但较MDBF平均增加了7.8%.综合识别结果和识别耗时,CPBF在识别失效率和识别速率两方面比MDBF表现出了更好的平衡性.
4 结论
本研究立足于识别失效率、硬件实现开销和识别速率,提出一种面向IP包识别的算法CPBF.该算法首先引入了识别失效代价的概念,采用ToS对IP包进行分类,对不同类别的IP包分配不同数目的Hash函数,并采用流水结构加速Hash结构对IP包的识别;给出了一种CPBF算法的硬件实现方式,采用更新Key值和硬件复用的方式进一步减小了硬件消耗;最后,通过实验对CPBF的性能进行了评估,并与SBF和MDBF进行了比较,结果表明,CPBF的识别失效率、硬件开销以及识别速率等方面都有较大改善.针对CPBF还可以进一步关注和探讨如何动态更新CPBF的识别规则集以适应未来更多的应用.
[1] GADELRAB SERAG.10-Gigabit ethernet connectivity for computer servers [J].IEEE Micro,2007,27(3):94- 105.
[2] YU F,KATZ RANDY H,LAKSHMAN T V.Gigabit rate packet pattern-matching using TCAM [C]∥Proceedings of the 12th IEEE International Conference on Network Protocols.Berlin:IEEE,2004:174- 183.
[3] CHAVAN M K,AGARKAR B S.Application of bloom filters in fast packet classification [J].Research Journal of Engineering and Technology,2014,5(2):77.
[4] DEKE G,HONGHUI C,JIE W,et al.Theory and network application of dynamic bloom filters [C]∥Proceedings of the 25th IEEE International Conference on Computer Communications.Barcelona:IEEE,2006:1- 12.
[5] IOANNIS PAPAEFSTATHIOU.Memory-efficient 5D packet classification at 40Gbps [C]∥Proceedings of the 26th IEEE International Conference on Computer Communications.Anchorage:IEEE,2007:1370- 1378.
[6] 王勇,云晓春,王树鹏,等.CBFM:支持属性删减的布鲁姆过滤器矩阵多维元素查询算法 [J].通信学报,2016,37(3):139- 147.
WANG Yong,YUN Xiao-chun,WANG Shu-peng,et al.CBFM:cutted bloom filter matrix for multi-dimensional membership query [J].Journal on Communications,2016,37(3):139- 147.
[7] 亓亚烜,李军.高性能网包分类理论与算法综述 [J].计算机学报,2013,36(2):408- 421.
QI Ya-xuan,LI Jun.Theoretical analysis and algorithm design of high-performance packet classification algorithms [J].Chinese Journal of Computers,2013,36(2):408- 421.
[8] QUAN WEI,XU C,VASILAKOS A V,et al.TB2F:Tree-bitmap and bloom-filter for a scalable and efficient name lookup in content-centric networking [C]∥ 2014 Networking Conference of International Federation for Information Processing.Trondheim:IEEE,2014:1- 9.
[9] YANG TONG,XIE G,SUN X,et al.Towards practical use of bloom filter based IP lookup in operational network [C]∥Network Operations and Management Symposium.Krakow:IEEE,2014:1- 4.
[10] LIM H,LIM K,LEE N,et al.On adding bloom filters to longest prefix matching algorithms [J].IEEE Transactions on Computers,2014,63(2):411- 423.
[11] WU H,GONG J,YANG W.Algorithm based on double counter bloom filter for large flows identification [J].Journal of Software,2010,21(5):1115- 1126.
[12] 周舟,付文亮,嵩天,等.一种基于并行 Bloom Filter 的高速 URL 查找算法 [J].电子学报,2015,43(9):1833- 1840.
ZHOU Zhou,FU Wen-liang,SONG Tian,et al.Fast URL lookup using parallel bloom filters [J].Chinese Journal of Electronics,2015,43(9):1833- 1840.
[13] ANDREW S,TANENBAUM.Computer networks [M].5th ed.New Jersey:Prentice Hall,2011:439.
[14] MOMANY E O,ODUOL V K,MUSYOKI S.First in first out (FIFO) and priority packet scheduling based on type of service (TOS) [J].Journal of Information Engineering and Applications,2014,4(7):22- 36.
[15] FENG S,HU C,MA K,et al.Implementation and application of QoS in power ethernet switch [J].Advanced Materials Research,2014,49(1):338- 343.
[16] TATE J,BECK P,CLEMENTS P,et al.IBM and Cisco:together for a world class data center [M].New York:IBM Redbooks,2013:287.
[17] MOORE A W,PAPAGIANNAKI K.Toward the accurate identification of network applications [C]∥ International Workshop on Passive and Active Network Measurement.Berlin:Springer,2005:41- 54.
[18] GUPTA P,BALKMAN J.PALAC:Packet look up and classification simulator [Z].San Francisco:Stanford University,2000.
[19] ACETO G,DAINOTTI A,DE DONATO W,et al.PortLoad:taking the best of two worlds in traffic classification [C]∥Proceedings of the 29th IEEE International Conference on Computer Communications.San Diego:IEEE,2010:1- 5.
CPBF:anIPPackageIdentificationAlgorithmUsingBloomFilter
LILong-feiHEZhan-zhuangSHIYang-chun
(Department of Integrated Circuit Design, Xi’an Microelectronics Technology Institute, Xi’an 710065, Shaanxi, China)
As the traditional Bloom filters adopt the same process for different IP packages and ignore not only IP package identification invalidation cost but also hardware resource in the process of flow identification, an algorithm called CPBF (Classified and Pipelined Bloom Filter) for IP package identification is presented. CPBF differentiates IP packages depending on ToS (Type of Service), which can reflect their identification invalidation cost in some ways. In order to minimize the identification invalidation rate, different numbers of Hash functions are applied to different types of IP packages. Specifically, pipelined Hash functions are adopted to accelerate the identification speed. Moreover, on the basis of the theories of probability and differential equation, the description and analytical expression of CPBF are deduced. Finally, an implementation of CPBF is conducted on FPGA. The results indicate that CPBF is superior to standard Bloom filter and multi-dimensional Bloom filter because it helps achieve lower identification invalidation rate and hardware resource cost without sacrificing identification speed.
Bloom filter;CPBF algorithm;IP package identification;identification invalidation cost;Hash function
2016- 05- 18
总装备部军用电子元器件型谱系列科研项目(1407XJ0900)
*Foundationitem: Supported by the Scientific Research Project of Military Electronic Components Portfolio of General Armament Department(1407XJ0900)
李龙飞(1988-),男,博士生,主要从事计算机网络硬件加速技术研究.E-mail:longfeisos@163.com
1000- 565X(2017)07- 0090- 08
TP 301.6
10.3969/j.issn.1000-565X.2017.07.013
猜你喜欢
数学物理学报(2022年2期)2022-04-26
中国毕业后医学教育(2020年6期)2020-12-06
计算机与数字工程(2019年7期)2019-07-31
舰船电子对抗(2019年2期)2019-05-23
艺术设计研究(2018年1期)2018-05-19
海峡姐妹(2017年12期)2018-01-31
计算机应用(2016年10期)2017-05-12
作文与考试·初中版(2017年12期)2017-04-19
中学生(2015年12期)2015-03-01
中国教育技术装备(2015年10期)2015-03-01
