
一种面向相似查询的轨迹索引方法
2017-12-08 03:15周向东陈海波
计算机应用与软件 2017年11期
王 飞 庞 悦 周向东 陈海波
1(复旦大学计算机科学技术学院 上海 200433) 2(国网上海市电力公司 上海 200122)
一种面向相似查询的轨迹索引方法
王 飞1庞 悦1周向东1陈海波2
1(复旦大学计算机科学技术学院 上海 200433)2(国网上海市电力公司 上海 200122)
轨迹数据具有重要的应用价值,轨迹索引技术得到广泛的研究与关注。传统索引方法存在节点重叠、缺乏动态划分空间能力和丢失大量原始信息等问题,为此提出一种面向相似查询的轨迹索引方法GeoSAX。该方法将原始轨迹分成若干等长子段并采用基于Geohash的空间编码;对编码后的整条轨迹设计了基于HBase存储的索引架构;实现相似轨迹查询。GeoSAX不仅节点间没有重叠,还能依据数据量的大小对空间动态划分,同时保留指定精度的轨迹信息。在真实的航运和出租车数据集上进行的对比实验表明,与传统方法相比GeoSAX具有更好的轨迹查询性能。
轨迹索引 相似查询 Geohash 空间编码 HBase
0 引 言
近年来随着移动设备的普及和GPS定位技术的发展,现实生活中产生了海量移动对象的轨迹数据,如船舶的航运线路,出租车接送乘客的路线等。轨迹是移动对象运动过程中在不同时刻的位置序列,因此轨迹可以看作是一种多元时间序列数据[1]。轨迹数据有着非常重要的应用价值,如可以根据风暴的移动轨迹辅助预报自然灾害[2];可以根据人们的运动轨迹挖掘出一些行为习惯从而为人们的生活提供智能的个性化服务[3]。移动对象轨迹数据的模式挖掘是当前的研究热点之一。
轨迹的各种应用均需要底层轨迹数据库支持快速高效的查询功能,如最近邻查询、区域查询和轨迹查询等。对于海量轨迹数据,不可能对每个查询请求顺序扫描全部数据,在一些对时间要求很高的场景中响应时间必须足够快,因此需要索引技术来提高海量轨迹数据的分析和挖掘效率。
轨迹索引技术得到了广泛的研究与关注。传统的轨迹索引通常采用R树以及R树的扩展方法[4-7],一般支持点查询和区域查询[8]。R树索引中的兄弟节点存在重叠,会引起多次查找的问题;为维持树的高度平衡,索引更新代价较大;一般不具备相似轨迹查询的能力。支持相似轨迹查询的索引一般采用划分空间[9-10]和提取特征[11-12]等方式。当前采用划分空间的索引保留了移动对象的空间信息,但基本上都是固定划分空间,实际数据的分布可能并不均匀,对于索引而言,这样会导致查询效率降低。基于特征提取的索引通过降维找到相似轨迹,但是通常无法保留原始空间信息。轨迹数据的急剧膨胀使得传统集中式索引的查询效率大大降低,分布式轨迹索引技术已经引起国内外学者的关注。当前分布式索引方法主要用于点查询和区域查询,针对相似轨迹查询的索引研究还比较少。
针对传统方法存在的不足,本文提出一种面向相似查询的轨迹索引方法GeoSAX。该方法将原始轨迹分成若干等长子段,每个子段采用Geohash编码,所有子段的Geohash编码组成一个符号串即GeoSAX表示,相似的轨迹具有相同的表示。对于海量轨迹数据,我们设计了基于HBase存储的索引结构,可以对相似查询快速响应。GeoSAX不仅可以根据数据量动态划分空间,还保留了指定精度下的原始轨迹信息。本文在真实的航运数据和纽约出租车数据上进行了充分的实验来评价验证本文提出的方法,实验结果表明GeoSAX能获得比已知基准方法更好的搜索性能。
1 相关工作
原始轨迹数据通常规模巨大,因而将轨迹序列压缩表示非常重要。举例来说,假设某个城市有1万辆出租车,每5秒种釆集一次出租车的位置来追踪其轨迹,那么一天收集到的轨迹数据就有4 GB左右[1]。分段聚集近似PAA[13],符号聚集近似SAX[14]和可索引的符号聚集近似iSAX[15]三种时间序列表示方法计算简单、压缩效果良好,被广泛使用。PAA把时间序列分成若干等长子段,各子段用段内均值表示。SAX首先将时间序列转换成均值为0标准差为1的标准序列,假设标准化后的序列近似服从正态分布,之后对标准序列使用PAA分割,最后根据正态分布的概率区间将PAA表示的序列离散化为符号串。iSAX是Shieh等[15]在SAX基础之上提出的一种根据数据量大小动态变化的符号化表示,用不同基数大小表示的二进制位来标记数据的密集程度。
在空间范围中有三种类型对象:点、区域和轨迹。按照空间对象的类型,Zheng[8]等将时空查询分为点查询、区域查询和轨迹查询三种。点查询是指查询符合给定条件的移动对象,如查询经过某地的移动对象。区域查询是指查询符指定时空区域的移动对象,如查询某个区域内的移动对象。轨迹查询是指查询与给定的整条轨迹具有某种时空关系的整条轨迹,如查询某条轨迹的相似轨迹。
面向点查询和范围查询的轨迹索引主要是基于R树以及R树的扩展方法,分为四种:移动对象历史位置索引,如固定网络的R树索引结构FNR-tree[4];移动对象当前位置索引,如基于固定网络的快速更新索引机制IMORS[5];移动对象未来位置索引,如时间参数化的R树TPR-tree[6];移动对象过去、现在和未来的全时空位置索引,如BBx-index[7]。面向相似轨迹查询的轨迹索引方法有多种,如基于空间划分的轨迹索引[9-10]和基于特征提取的轨迹索引[11-12]。
基于空间划分的轨迹索引,采用划分空间单元格或立方体的方式对空间编码来建立索引。Bakalov等提出轨迹索引方法TRSTJ[9],首先使用PAA方法对轨迹降维,然后将降维后的轨迹二维空间切分成相同大小的单元格,并为每个单元格分配一个符号,最终一条轨迹被表示成一个字符串。Thach等提出TraSAX[10],该方法对单元格的x轴使用字母编码,y轴使用数字编码,使得一个单元格同时由字母和数字编码组成。
基于特征提取的轨迹索引,提取轨迹的特征并编码来建立索引。Bashir等[11]使用PCA、谱聚类等方法提取视频中的动作轨迹特征,并表示成字符串。Pao等[12]提取鼠标移动轨迹的步长和角度特征,并使用Isomap对轨迹进行表示。
在大数据的背景下,分布式轨迹数据库的研究已经引起国内外学者的关注。Li等[16]结合车辆数据的实际特点,设计了基于Bigtable的存储模型,可以查询出租车在某段时间内的运行轨迹。Ma等[17]对海量的轨迹数据采用分布式文件系统HDFS存储,可以检索指定车辆的轨迹。
2 GeoSAX轨迹索引算法
2.1 基于Geohash算法的空间编码
Geohash算法是一种常用的二维空间编码方法,在众多领域有着广泛的应用[18-19]。地球经度区间范围是[-180,180],二分为左区间[-180,0)和右区间[0,180],左区间编码为0,右区间编码为1,纬度区间同理,依次对经纬度空间进行划分,得到Geohash编码。如上海金茂大厦的经纬度坐标(31.235 253 6 N,121.503 402 3 E),在二进制编码总位数为3下得到的二进制Geohash编码是111,在二进制编码总位数为4下得到的二进制Geohash编码是1110,如图1所示,其中基数可以理解为对空间划分的细致程度。
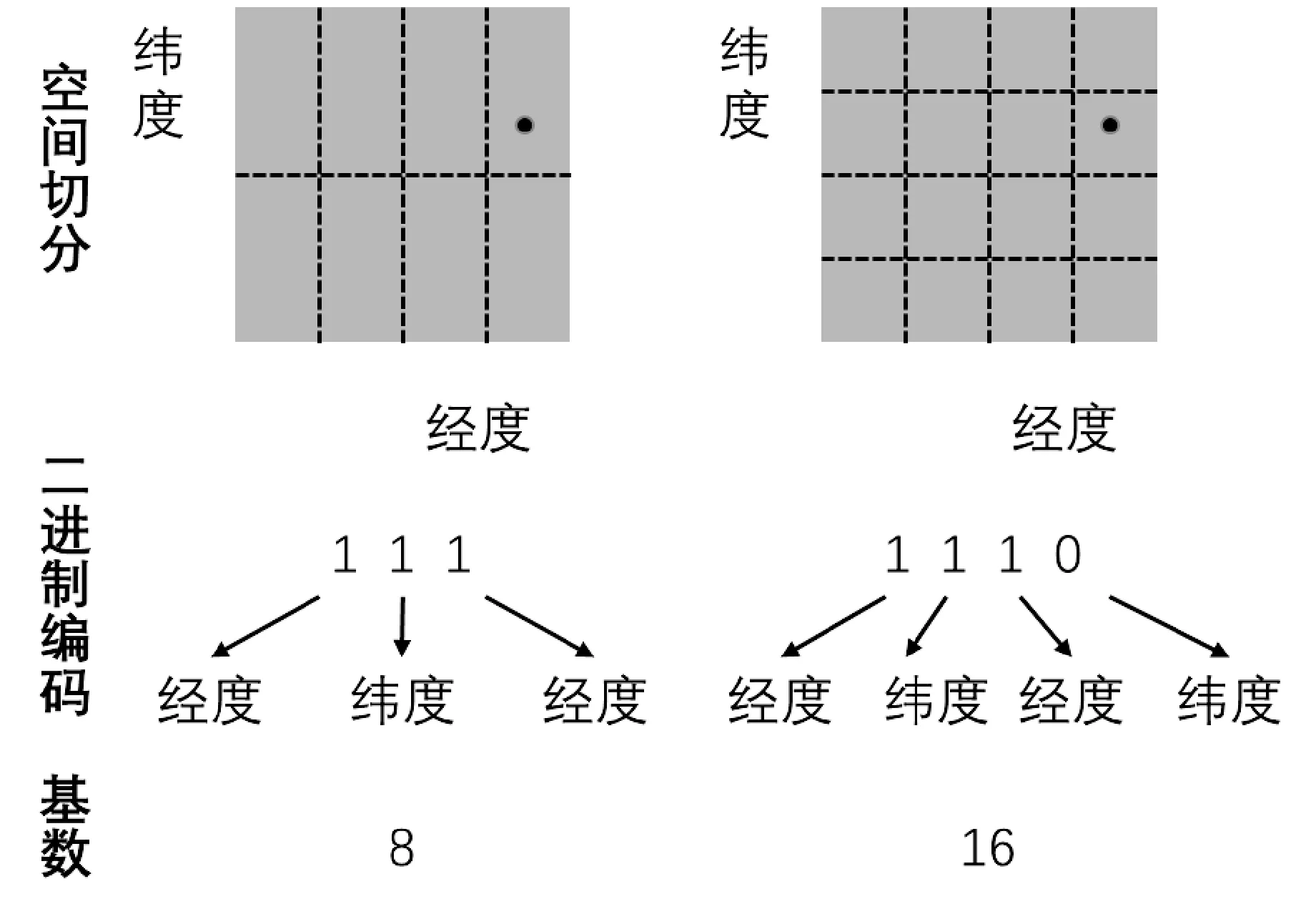
图1 Geohash算法的空间编码
iSAX离散化时会指定基数,即对正态曲线的划分,如a=4表示将正态曲线等概率的切分为4份。基于Geohash的空间编码同样需要指定基数,即空间切割的精度。Geohash可以同时对经度和纬度进行切割,假设对经度和纬度编码位数之和为t,Geohash切割的基数设置为2t。Geohash组码时奇数位存放经度编码,偶数位存放纬度编码,故每次升高基数时,如果经度和纬度的编码位数相同则经度的位数加一,如果当前经度的位数大于纬度位数则纬度位数加一。参见图1。
2.2 GeoSAX表示
图2展示了GeoSAX的索引结构,图中轨迹被分为3段,初始基数均为4。当某一索引节点包含的轨迹数量超过指定阈值,该节点分裂为两个新的索引节点,原先的索引节点作为中间节点,图中的节点{11,01,10}分裂产生 {11,010,10}和{11,011,10}两个新的叶子节点。图3展示了索引节点{11,011,10}的空间划分情况。

图2 GeoSAX索引示意图
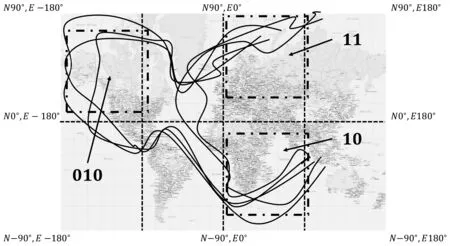
图3 GeoSAX索引节点示意图
下面描述GeoSAX表示的生成过程。
第一步,本文采用PAA模型将原始轨迹数据从n维降到w维。给定轨迹:
T={
(1)
式中:n表示轨迹长度,lngi和lati分别表示第i个轨迹点的经度和纬度。
使用PAA轨迹约减为:
(2)
式中:w表示约减后的维度,w≪n,每个子段用其均值代替:
(3)
第二步,本文将PAA的表示离散化为符号,不同于SAX,这里使用基于Geohash的空间编码单个轨迹位置进行编码,得到:
(4)
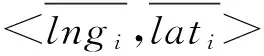
通过Geohash编码可以得到单个轨迹点在指定精度下的压缩表示,进而得到整个轨迹的压缩表示。对于压缩表示,可以执行Geohash的反过程得到单个轨迹点在指定精度下的信息,进而得到整条轨迹在指定精度下的信息。
2.3 GeoSAX索引构建与相似查询
GeoSAX索引是树形结构的,第一层可以看作是多叉树,且第一层所有节点基数相同,即对原始空间采用同样的切分精度。从第二层开始,叶子节点根据数据的密集程度进行二分裂,则以第一层节点为根节点的子树是二叉树。GeoSAX索引构建因此可以看作是对多叉树和二叉树混合在一起的树的构建,GeoSAX索引建立详细过程如算法所示。
GeoSAX索引建立算法
1) 输入:轨迹ts, 当前索引节点node,空间的初始划分基数a,轨迹分段数w和节点分裂阈值th
2) 输出: GeoSAX索引添加轨迹ts
3) G=GeoSAX (ts,索引参数)//获取ts的GeoSAX表示
4) if当前节点存在GeoSAX表示为G的后继节点
5) node=获取GeoSAX表示为G的后继节点
6) if node 为叶子节点
7) if node没满 //小于节点分裂阈值th
8) node直接插入ts
9) else//节点已满,需要分裂
10) 新建一个中间节点newnode
11) newnode.insert(ts)
12) for each originTS in node
13) newnode.insert(ts)
14) 删除node节点
15) 将newnode作为当前节点的后继节点
16) else// node为中间节点
17) node.insert(ts)
18) else
19) 新建一个GeoSAX表示为G的叶子节点L
20) 叶子节点L直接插入ts
GeoSAX索引相似查询假设相似的两条轨迹具有相同的GeoSAX表示。GeoSAX索引是层次且没有重叠的,因而可以遍历索引树找到对应的索引节点,获取其索引的所有轨迹,分别计算这些轨迹与查询轨迹之间的距离,返回距离最小的轨迹作为相似查询结果。轨迹s和t的距离定义如式(5)所示,其中n表示轨迹长度,i=1表示经度,i=2表示纬度。
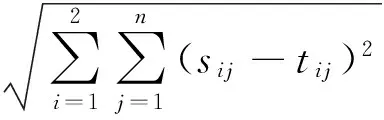
(5)
2.4 GeoSAX索引在HBase中的存储设计
HBase是列存储、高性能、可伸缩、实时读写的分布式数据库,可以存储海量数据,我们将原始数据和GeoSAX索引分别存储在HBase上的两张表。原始数据表中的Rowkey为轨迹编号。GeoSAX索引表中Rowkey为索引节点编号。HBase查询速度受限于网络带宽,因此将原始数据表中value设置为原始轨迹序列化后的byte数组,GeoSAX索引表中value设置为节点对应的参数序列化后的byte数组。如表1所示。
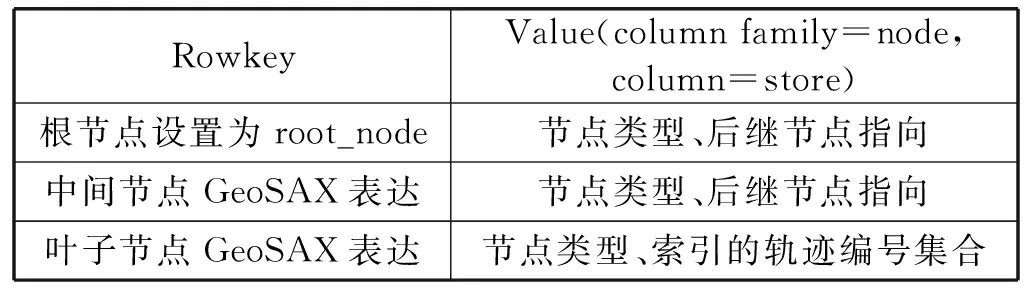
表1 GeoSAX索引表设计
3 实验设计
3.1 实验数据和环境
(1) 航运数据
www.vesselfinder.com是一个在线免费航运船舶跟踪网站,可以获得全球船舶的轨迹,我们从该网站爬取40 000条船的轨迹,每条轨迹包含200个位置的经纬度坐标,位置采集间隔为5分钟。
(2) 出租车数据
纽约出租车和轿车委员会在其网站公开了整个纽约的出租车出行记录,包括每一趟出租车上下客的时间、经纬度坐标和出行距离等信息。我们选取13年部分出租车的轨迹,将每辆出租车每天的上下车坐标序列作为一条轨迹,共有12 759辆出租车,2 052 061条轨迹,202 288 485个轨迹点。
(3) 实验环境
实验采用由HBase-0.98.13和Hadoop-2.4.0搭建的10个节点构成的HBase集群,其中master节点内存32 GB,slave节点的内存16 GB,每个节点的硬盘1 TB,操作系统为Ubuntu14.04,网络带宽1 000 Mbit/s。
3.2 实验设计
本文主要研究整条轨迹的相似查询,属于轨迹查询,而绝大多数基于R树的轨迹索引主要用于点查询和区域查询,TRSTJ[9]算法可以用于轨迹查询,所以本文将TRSTJ作为对比算法而不考虑与基于R树的轨迹索引作为对比。TRSTJ采用固定空间划分的方式,而GeoSAX轨迹索引是根据数据量的大小对空间进行动态划分的方式。为了验证GeoSAX索引方法的有效性,我们在同样运行环境下,分别对GeoSAX、TRSTJ和原始数据顺序扫描三种方法,在不同基数在下随机相似查询100次,并比较他们的查询性能。在航运数据中GeoSAX的分裂阈值设置为200,在出租车数据中GeoSAX的分裂阈值设置为1 000。
3.3 实验分析
(1) 航运数据索引
从图4中可以看出,顺序扫描与空间划分无关,基数对顺序扫描没有影响,不同基数下顺序扫描的时间相同。GeoSAX和TRSTJ均对空间进行划分,建立了相应的索引机制,因而均比顺序扫描要快得多。

图4 航运数据上的查询性能对比
从图4中还可以发现,相同基数下GeoSAX的查询性能均比TRSTJ要好,如基数为256时GeoSAX查询速度是TRSTJ的5倍,基数为1 024时,GeoSAX查询速度是TRSTJ的3倍。这是因为TRSTJ对空间采取固定划分方式,所以TRSTJ索引中数据分布很不均匀,极少数的索引节点索引了大多数的轨迹,大多数的索引节点只索引了少部分的轨迹。因而TRSTJ大部分的查询发生在极少数的索引节点上,而这些索引节点又索引了大量轨迹,查询需要扫描节点上索引的所有轨迹,该查询已经退化为顺序扫描,性能大大降低。以基数256为例,统计TRSTJ和GeoSAX单个索引节点索引的轨迹数量的情况。如图5所示,对于TRSTJ中索引1~9条轨迹的索引节点,其数量占总的索引节点数量的72.68%,而GeoSAX占65.10%;TRSTJ中索引1 000条以上轨迹的索引节点,其数量占总的索引节点数量2.26%,而GeoSAX的分裂阈值为200,不存在索引1 000条以上轨迹的索引节点。从图6可以看出,TRSTJ中索引1~9条轨迹的索引节点,其索引的轨迹数量占总轨迹数量的7.69%,而GeoSAX只占1.69%;TRSTJ中索引1 000条以上的索引节点,其索引的轨迹数量占总轨迹数量的68.57%,而GeoSAX的分裂阈值为200,不存在索引1 000条以上轨迹的索引节点。
与TRSTJ相比,GeoSAX索引节点索引轨迹的数量分布相对均匀。GeoSAX可以随着数据量的大小动态调整索引结构,当单个节点包含的轨迹数量超过指定阈值节点则分裂,虽然增加了查询的深度,但是在每个索引节点上查询时间大大缩短,从而提高了整体查询的性能。
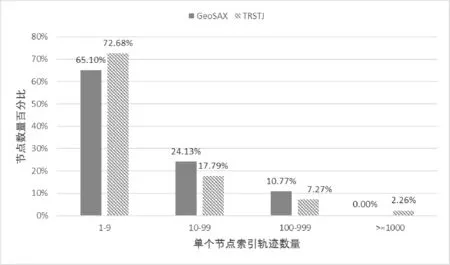
图5 基数为256时索引节点分布情况
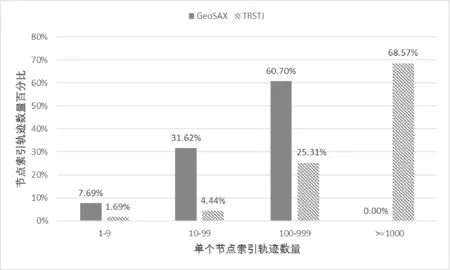
图6 基数为256时轨迹数量分布情况
此外,从图4中还发现, 随着基数的增长,GeoSAX和TRSTJ的性能均得到提升, 同时两者的性能差距逐渐缩小。这是由于TRSTJ和GeoSAX的索引节点数都在增长,每个索引节点对应的轨迹数量缩小,扫描单个索引节点的时间缩短,从而提升了整体的查询性能。但是索引基数并不能无限制扩大,因为这样会引起索引空间膨胀,占有过大存储空间等问题。因此,GoeSAX显示出可以在合理的基数的情况下,获得更好的查询效率。
(2) 出租车数据索引
航运数据是全球的船只,而纽约出租车数据仅在纽约地区,故纽约出租车数据的初始基数要比航运数据大得多,即初始空间划分要更加细致。
图7中是对纽约出租车数据进行查询,可以看出,GeoSAX和TRSTJ的查询表现与航运数据是相似的。顺序扫描与空间划分无关,GeoSAX和TRSTJ均建立了相应的索引机制,均比顺序扫描要快得多。相同基数下GeoSAX的查询性能同样均比TRSTJ要好,如基数为8 388 608时GeoSAX查询速度是TRSTJ的112倍,基数为16 777 216时,GeoSAX查询速度是TRSTJ的48倍。航运数据轨迹量是百万级,而轨迹点则有2亿多,我们的查询仍然可以在可接受的时间范围内给出相似查询结果。

图7 出租车数据上的查询性能对比
4 结 语
本文总结了现有轨迹索引存在的问题,提出一种面向相似查询的轨迹索引方法GeoSAX。该方法将原始轨迹分成若干等长子段,每个子段均采用基于Geohash的空间编码,设计了基于HBase存储的轨迹索引方法GeoSAX。索引不仅节点之间没有重叠,还可以根据数据量的大小对空间动态划分,并保留了指定精度下的轨迹信息。实验表明,在相同基数下GeoSAX搜索性能均优于已知的基准索引方法,在海量数据下GeoSAX对相似轨迹查询可以快速响应。本文提出的方法以仅包含经纬度位置信息的二元轨迹情况为例,但是可以很方便的扩展到包含速度、方向等其他信息的多元轨迹情况。下一步研究将侧重于包含众多信息的多元轨迹索引建立方法。
[1] 龚旭东. 轨迹数据相似性查询及其应用研究[D]. 合肥: 中国科学技术大学, 2015.
[2] Sefidmazgi M G, Sayemuzzaman M, Homaifar A. Non-stationary time series clustering with application to climate systems[M]//Advance trends in soft computing. Springer, 2014:55-63.
[3] 郭黎敏, 高需, 武斌, 等. 基于停留时间的语义行为模式挖掘[J]. 计算机研究与发展, 2017(01):111-122.
[4] Frentzos E. Indexing objects moving on fixed networks[C]//International Symposium on Spatial and Temporal Databases. Springer, 2003: 289-305.
[5] Kim K, Kim S, Kim T, et al. Fast indexing and updating method for moving objects on road networks[C]//Web Information Systems Engineering Workshops. IEEE, 2003: 34-42.
[7] Lin D, Jensen C S, Ooi B C, et al. Efficient indexing of the historical, present, and future positions of moving objects[C]//Proceedings of the 6th international conference on Mobile data management. ACM, 2005:59-66.
[8] Zheng Y, Zhou X. Computing with Spatial Trajectories[M]. New York, NY:Springer Verlag, 2011.
[9] Bakalov P, Hadjieleftheriou M, Tsotras V J. Time relaxed spatiotemporal trajectory joins[C]//Proceedings of the 13th annual ACM international workshop on Geographic information systems. ACM, 2005:182-191.
[10] Thach N H, Suzuki E. A symbolic representation for trajectory data[C]//The 24th Annual Conference of the Japanese Society for Artificial Intelligence, JSAI, Nagasaki,2010:1-4.
[11] Bashir F I, Khokhar A A, Schonfeld D. Real-Time Motion Trajectory-Based Indexing and Retrieval of Video Sequences[J]. IEEE Transactions on Multimedia, 2007,9(1):58-65.
[12] Pao H K, Fadlil J, Lin H Y, et al. Trajectory analysis for user verification and recognition[J]. Knowledge-Based Systems, 2012, 34(5):81-90.
[13] Keogh E, Chakrabarti K, Pazzani M, et al. Dimensionality Reduction for Fast Similarity Search in Large Time Series Databases[J]. Knowledge and information Systems, 2001,3(3):263-286.
[14] Lin J, Keogh E, Wei L, et al. Experiencing SAX: a novel symbolic representation of time series[J].Data Mining and knowledge discovery, 2007,15(2):107-144.
[15] Shieh J, Keogh E. iSAX: disk-aware mining and indexing of massive time series datasets[J].Data Mining and Knowledge Discovery, 2009,19(1):24-57.
[16] Li Q, Zhang T, Yu Y. Using cloud computing to process intensive floating car data for urban traffic surveillance[J].International Journal of Geographical Information Science, 2011,25(8):1303-1322.
[17] Ma Q, Yang B, Qian W, et al. Query processing of massive trajectory data based on mapreduce[C]//Proceedings of the first international workshop on Cloud data management. ACM, 2009:9-16.
[18] Jiang J, Lu H, Yang B, et al. Finding top-k local users in geo-tagged social media data[C]//Data Engineering (ICDE), 2015 IEEE 31st International Conference on. IEEE, 2015:267-278.
[19] Liu R, Buccapatnam S, Gifford W M, et al. An Unsupervised Collaborative Approach to Identifying Home and Work Locations[C]//Mobile Data Management (MDM), 2016 17th IEEE International Conference on. IEEE, 2016:310-317.
AMETHODOFTRACKINDEXFORSIMILARITYSEARCH
Wang Fei1Pang Yue1Zhou Xiangdong1Chen Haibo2
1(SchoolofComputerScience,FudanUniversity,Shanghai200433,China)2(StateGridShanghaiElectricCompany,Shanghai200122,China)
Because the tracking data have important application value, the track index technology has been widely studied and concerned. Traditional indexing methods have many problems such as node overlap, lack of dynamic partitioning of spatial capabilities and loss of a large number of original information. Therefore, we propose GeoSAX, a track index method for similarity search. In this method, the original tracking was divided into several equal segments, and spatial coding based on Geohash was adopted. We designed an indexing architecture for the whole track after encoding, which was based on HBase storage. Thus, the similarity search was realized. GeoSAX not only does not overlap between nodes, but also dynamically divides the space according to the size of the data, while preserving the track information of the specified precision. Contrast experiments on real shipping and taxi data sets show that GeoSAX has better track search performance than traditional methods.
Track index Similarity search Geohash Spatial coding HBase
2017-03-28。国家高技术研究发展计划项目(2015AA050203);国家自然科学基金项目(61370157);国家电网公司总部科技项目(52094016000A)。王飞,硕士生,主研领域:轨迹索引,时间序列。庞悦,博士生。周向东,教授。陈海波,高工。
TP3
A
10.3969/j.issn.1000-386x.2017.11.001
猜你喜欢
四川劳动保障(2021年9期)2022-01-18
数学小灵通·3-4年级(2020年10期)2020-11-10
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
无锡职业技术学院学报(2019年4期)2019-12-27
文萃报·周五版(2019年13期)2019-09-10
小学生必读(中年级版)(2018年6期)2018-09-05
现代装饰(2018年5期)2018-05-26
今古传奇·故事版(2017年24期)2018-02-07
中国三峡(2017年2期)2017-06-09
