
EarnCache:一种增量式大数据缓存策略
2017-12-08 03:15:45郭俊石罗轶凤
计算机应用与软件 2017年11期
郭俊石 罗轶凤
(复旦大学计算机科学技术学院上海市智能信息处理重点实验室 上海 200433)
EarnCache:一种增量式大数据缓存策略
郭俊石 罗轶凤
(复旦大学计算机科学技术学院上海市智能信息处理重点实验室 上海 200433)
在共享的大数据集群中,租户竞争可能导致内存资源分配不公平以及利用效率低下。为了提高缓存利用效率和公平性,针对大数据应用的特性,提出一种增量式缓存策略称为EarnCache,即文件被访问得越多,获得的缓存资源就越多。利用文件被访问频率的历史信息,将缓存分配与替换问题抽象成优化问题,给出解决方案。并在分布式存储系统中实现了EarnCache及MAX-MIN等不同算法,进行性能分析。实验表明,EarnCache可以提高大数据缓存效率和总体资源利用率。
大数据 缓存分配 增量式
0 引 言
随着大数据应用对实时运算需求的提升和内存价格的下降,使用内存来缓存数据、加速运算逐渐成为一种趋势。大数据集群通常由多个计算框架、应用或者终端用户共享,而大数据海量的特征决定了无法将数据全部放入内存,因而内存资源竞争不可避免。大数据应用通常为分析型事务,数据显示出相似的访问热度;另一方面,大数据的数据块较大(如HDFS[6]默认64 MB),缓存替换代价比传统KB级别的页式存储高得多。针对大数据应用的特性,以提高集群使用公平性和缓存效率为目标设计特定内存资源管理策略,成为一个重要问题。
文献[2]针对大型Web行用,提出将所有数据放在内存中提供服务。文献[1,11]在底层分布式文件系统之上,实现了额外的一个缓存层,使用类似HDFS[6]的数据管理方式管理缓存。文献[4]则进一步实现了一个可基于内存的分布式文件系统,引入Lineage和Checkpoting机制保证数据一致性和可用性。文献[10]缓存MapReduce[3]的中间结果以加速MapReduce类型的应用。文献[7]发现了并行计算All-or-Nothing的特性,即并行的一波计算任务中,缓存部分任务数据对加速整体计算没有明显作用。文献[5,14-15]分别提出了动态资源分区的方法来保证公平性,同时尽量最大化总体性能。文献[8]扩展了MAX-MIN公平性算法[12-13],加入概率阻断,以防止作弊行为,提高共享缓存的公平性。
本文提出一种增量式的大数据缓存分配策略,称为EarnCache,从存储系统角度出发,根据文件被访问的频率分配内存资源。主要工作包含:1) 提出一种增量式缓存分配机制;2) 将缓存资源分配与替换问题归纳成一个最优化问题并提供解决方案;3) 实现EarnCache的原型,并在其上进行实验验证方案的有效性。
1 系统框架与算法设计
在共享的大数据集群上,缓存资源竞争十分常见。为了提高缓存使用效率,应当将“热”数据保留在缓存中。大数据应用通常为分析型事务,数据表现出相似的被访问热度。而在共享集群中,不同应用、用户的数据文件之间则会表现出不同的热度。EarnCache从文件的角度出发,考虑缓存分配的方案。理想情况下,最近最常被访问的文件应当获得更多的缓存资源。基于文件被访问的历史信息,尤其是最近的访问信息,EarnCache实现了一种增量式的缓存分配方案,即一个文件最近被访问得越多,就会获得越多的内存来缓存数据。
本节将首先介绍EarnCache的总体系统架构设计,然后分别介绍使用历史访问信息进行缓存分配的方案设计和缓存替换的算法设计。
1.1 系统框架设计
EarnCache是一个块式存储系统,整体框架,如图1所示。整个系统由一个中心的主节点(Master)和一系列位于存储节点上的工作节点(Worker)组成。主节点负责维护元数据,并根据历史访问信息进行缓存分配(详见1.2节);工作节点负责数据的读写,并在收到缓存数据块请求时,根据主节点的缓存分配结果进行缓存替换。
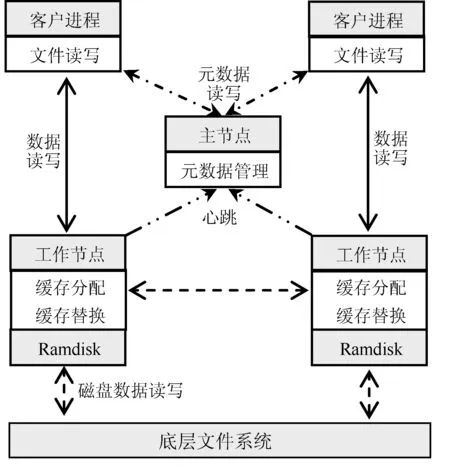
图1 系统架构图
一个数据块被访问的流程可以总结为:1) 客户进程询问主节点,获得数据块的位置;2) 客户进程向数据块所处的工作节点请求数据;3) 工作节点将尝试从缓存中读数据块,如果读到,则将数据返回给客户进程;4) 如果缓存中不存在该数据块,则尝试从底层文件系统读,并尝试将读到的数据缓存到内存中(详见1.3节)。
1.2 增量式缓存分配
EarnCache利用最近历史访问信息进行缓存分配,EarnCache从访问数据量的角度出发定义了考察窗口,并只关注该窗口内的文件访问信息。表1列出了所有分配方案中用到的参数及其定义。
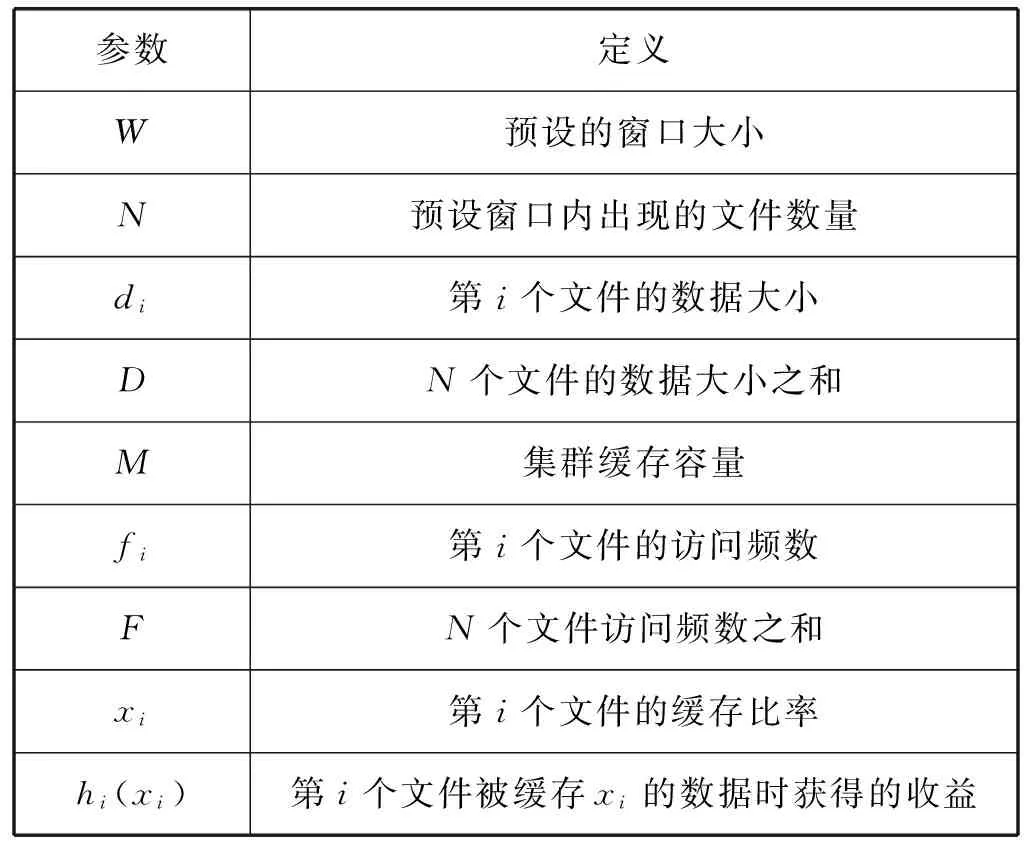
表1 参数定义
文件的缓存比例越高,该文件的缓存收益就越大,本文将第i个文件的缓存收益定义为:hi(xi)=lnxi,该函数为凸函数意为缓存比例的基数越大,增加缓存比例获得的缓存收益增加越少。于是总体收益可表示为式(1),服从于式(2)的约束:
(1)
(2)
在任意给定时刻,xi是优化目标中的唯一变量,针对凸函数fi·lnxi可使用拉格朗日乘子法进行求解。定义拉格朗日函数为:
(3)
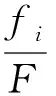
(4)
式(4)表明,分配给某个文件的缓存量正比于其在窗口内被访问的频数,这与EarnCache增量式分配目标一致。在主节点进行缓存资源分配时,如果某个文件的分配量超出其总体需求量,EarnCache则会把剩余的资源平均分配给其他文件使用。
1.3 缓存替换
工作节点负责数据的读写,当读取的数据块来自于底层文件系统时,工作节点会尝试将数据块缓存到自己的内存中。缓存过程如图2所示,当缓存某个文件F的数据块时,如果当前系统有足够空闲缓存,则将直接缓存数据块;否则在文件F缓存实际使用量小于分配量时,将从其他已缓存文件处获取缓存资源,即踢出其他某一文件R的缓存块并将资源分配给文件F。EarnCache选择实际缓存使用量超出分配量最多的文件作为R,从而防止缓存资源使用过于集中,保证公平性。EarnCache尝试这一过程直到回收的缓存量足够F缓存新的数据块为止。
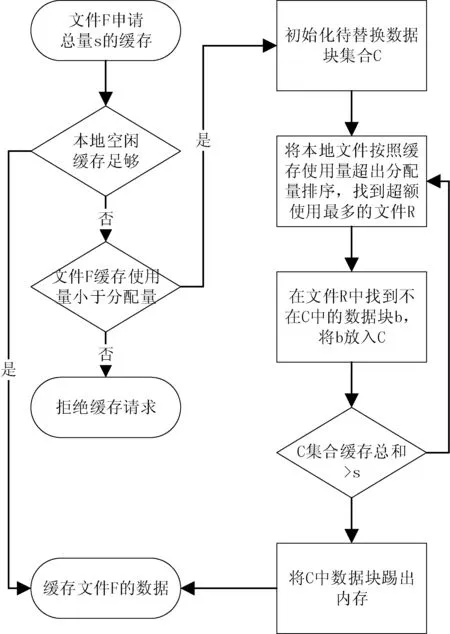
图2 缓存替换流程图
2 实验分析
本文基于Tachyon[4]实现了EarnCache的原型。实验使用HDFS作为底层分布式文件系统,使用Spark作为上层计算框架。测试集群由5台Amazon EC2 m4.2xlarge型号机器组成,其中一台为主节点,其余四台为工作节点。每个集群节点配置有32 GB内存,其中12 GB为工作内存,20 GB作为缓存资源;集群总共分配80 GB作为缓存数据的资源。实验默认设置预设窗口W的大小为1 000 GB;每个数据块的大小为128 MB。
实验主要通过运行Spark扫描任务来对比EarnCache和LRU、LFU、MAX-MIN等缓存替换算法的性能。实验环境包含三个文件的扫描任务,一次测试包含以不同模式进行三个文件(FILE-1,FILE-2,FILE-3)的扫描任务。ROUND:以FILE-1, FILE-2, FILE-3顺序循环访问。ONE:以FILE-1, FILE-2, FILE-1, FILE-3模式访问,FILE-1的访问频率高。TWO:以FILE-1, FILE-2, FILE-1, FILE-2, FILE-3模式访问,FILE-1和FILE-2的访问频率较高。实验默认设置三个文件的大小均为40 GB。
2.1 总体运行时间对比
我们分别设置三个文件大小相等(40 GB)和不等(70 GB,40 GB,10 GB)两种情况,然后将EarnCache在不同访问模式下与不同缓存替换算法进行比较,平均运行时间的结果。如图3所示。可以发现EarnCache的性能是最好的,这是因为EarnCache算法可以让更多的数据块缓存命中,直接从内存中被访问。同时我们也发现,EarnCache的性能并没有预期的好,尤其是和LRU、LFU算法比较,这是因为:1) 由于实验设置,EarnCache只能缓存部分文件,所以只能达到部分加速的效果;2) 没有保证缓存局部性(locality),即很多数据块是通过访问其他节点的缓存获得的。
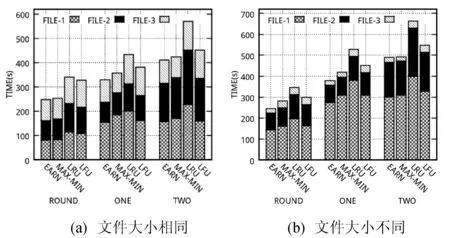
图3 程序运行时间对比
2.2 数据块访问方式分析
为了更好地说明缓存局部性问题,我们分析了EarnCache从本地缓存、远程缓存和底层文件系统(UFS)访问数据块的比例构成,如图4所示。可以发现,EarnCache从本地或者远程缓存中访问的数据块数量是最多的,这佐证了EarnCache的缓存使用效率是最高的,也解释了时间性能更好的现象。同时,EarnCache从远程缓存读的数据块数量也是最多的。如果上层计算框架能够利用缓存本地性信息,那么EarnCache的性能将有进一步提升。
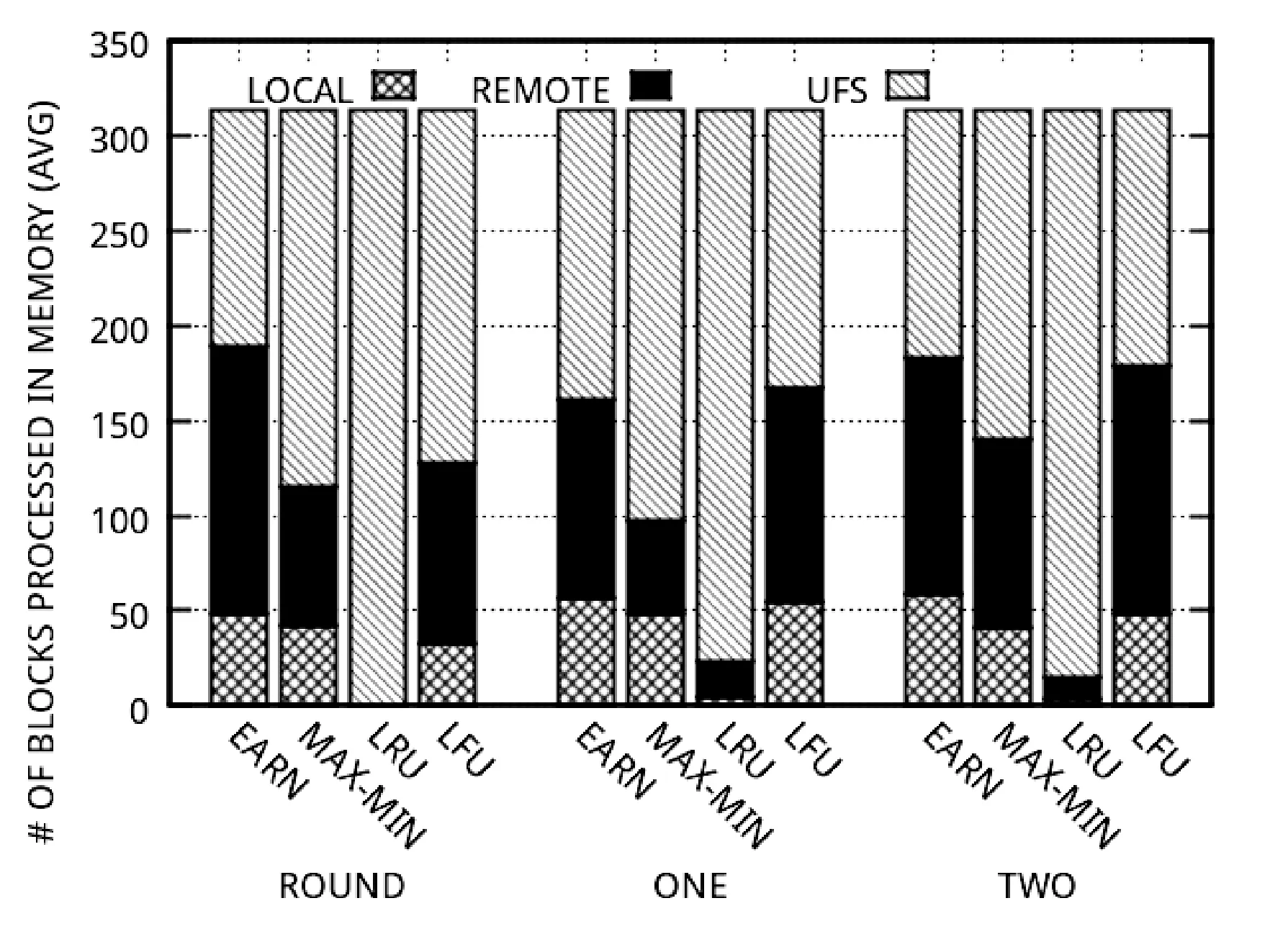
图4 数据块访问方式分布图
2.3 资源的动态分配
观察发现EarnCache和MAX-MIN两种算法的时间性能比较接近,这是因为实验设置决定了两者的缓存分配方案差别不大。但是MAX-MIN无法动态重分配资源,当三个大小相同的文件中有两个文件不再被访问时,缓存分配方案的变化如图5。EarnCache算法可以保证随着预设窗口的移动,缓存方案逐渐变化,继续被访问的FILE-1逐渐获得其他文件的缓存资源;而MAX-MIN则依然保持每个文件持有大致相同量的资源。
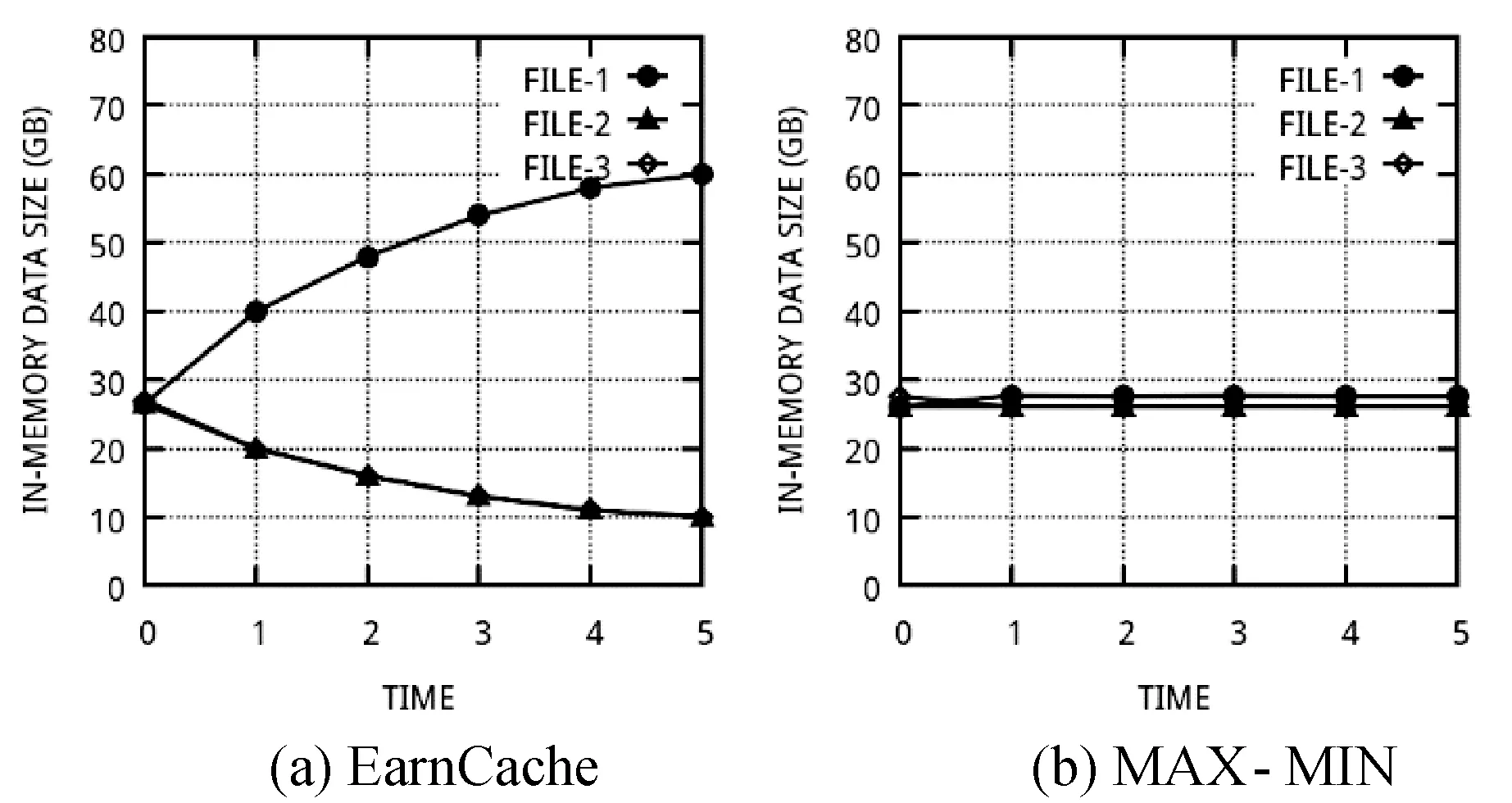
图5 FILE-2与FILE-3不再被访问时的资源动态分配图
2.4 预设窗口大小的影响
最后我们分析了预设窗口大小对性能的影响。如图6所示,当预设窗口太小时,总体缓存效率和性能下降明显,而当窗口大小与数据集大小相比足够大时,EarnCache可以有效地管理缓存资源,提升缓存使用效率。
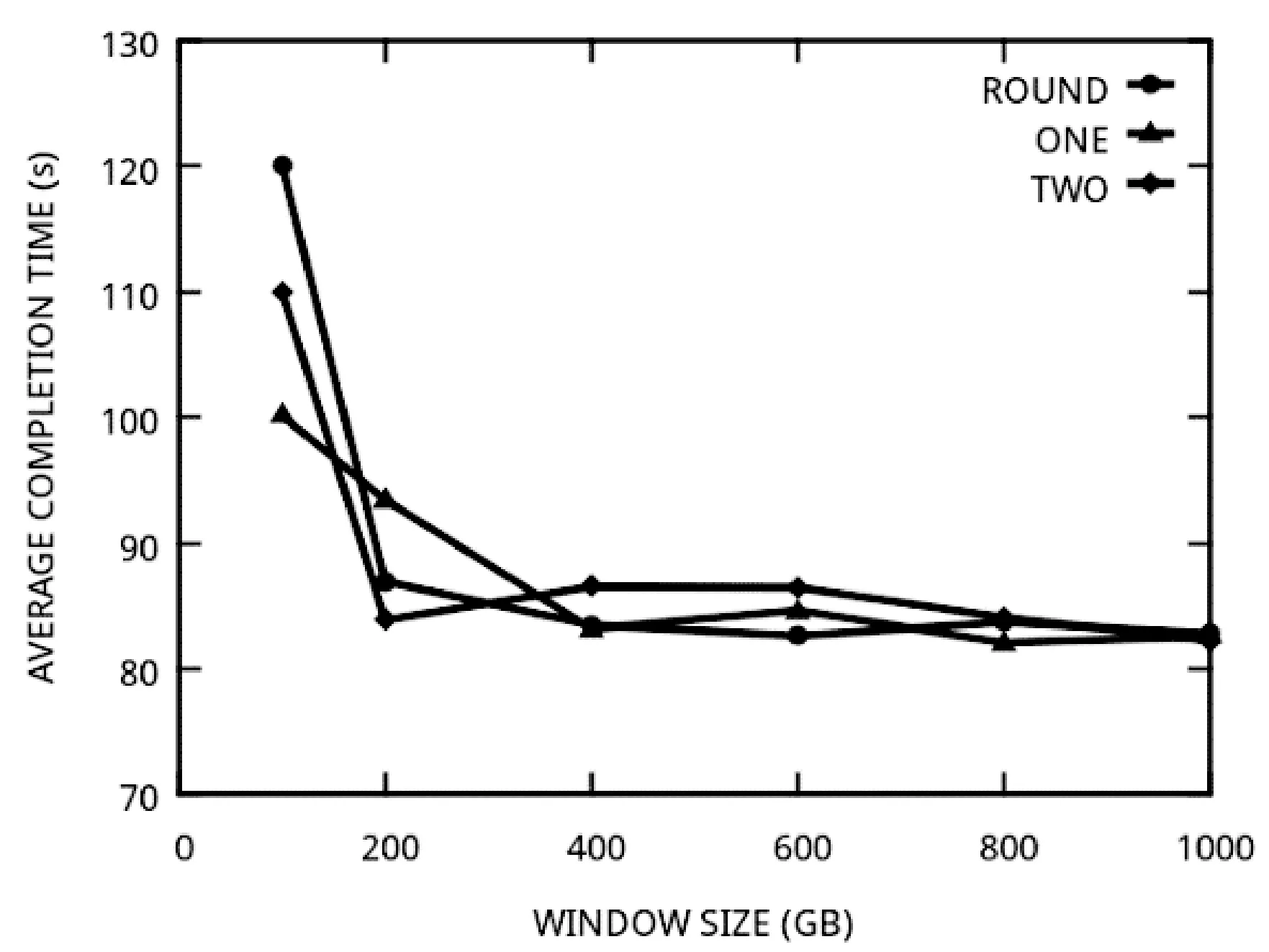
图6 预设观察窗口大小对性能的影响
3 结 语
在大数据应用中国年使用内存来缓存数据、加速运算逐渐称为一种趋势,而在共享的分布式集群中,内存资源的竞争不可避免。为了保证缓存分配的公平性以及提高缓存资源使用的效率,本文提出了一种增量式缓存管理方案称为EarnCache。基于大数据应用多为分析型事务以及数据块缓存替换代价大的特性,利用文件被访问频率的历史信息,本文将缓存分配与替换抽象成一个优化问题并给出解决方案。对比实验表明,EarnCache可以提高大数据缓存效率和总体资源利用率。
[1] Zhang J, Wu G, Hu X, et al. A Distributed Cache for Hadoop Distributed File System in Real-Time Cloud Services[C]//ACM/IEEE, International Conference on Grid Computing. ACM, 2012:12-21.
[2] Ousterhout J, Agrawal P, Erickson D, et al. The Case for RAMCloud[J]. Acm Sigops Operating Systems Review, 2011, 54(4):121-130.
[3] Dean J, Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters[C]//Conference on Symposium on Opearting Systems Design & Implementation,2004:107-113.
[4] Li H, Ghodsi A, Zaharia M, et al. Tachyon:Reliable, Memory Speed Storage for Cluster Computing Frameworks[J]. Proceedings of the ACM Symposium on Cloud Computing, 2014,37(3):1-15.
[5] Li Y, Feng D, Shi Z. Enhancing both fairness and performance using rate-aware dynamic storage cache partitioning[C]//International Workshop on Data-Intensive Scalable Computing Systems,2013:31-36.
[6] Shvachko K, Kuang H, Radia S, et al. The hadoop distributed file system[C]//Mass storage systems and technologies (MSST), 2010 IEEE 26th symposium on. IEEE, 2010:1-10.
[7] Ananthanarayanan G, Ghodsi A, Wang A, et al. PACMan: coordinated memory caching for parallel jobs[C]//Usenix Conference on Networked Systems Design and Implementation,2012:20-20.
[8] Pu Q, Li H, Zaharia M, et al. Fairride: Near-optimal, fair cache sharing[C]//13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16). USENIX Association,2016:393-406.
[9] Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing[C]// Usenix Conference on Networked Systems Design and Implementation. USENIX Association,2012:2-2.
[10] Zhang S, Han J, Liu Z, et al. Accelerating MapReduce with Distributed Memory Cache[C]//IEEE, International Conference on Parallel and Distributed Systems, ICPADS 2009, 8-11 December 2009, Shenzhen, China. DBLP, 2009:472-478.
[11] Luo Y, Luo S, Guan J, et al. A RAMCloud Storage System based on HDFS: Architecture, implementation and evaluation[J]. Journal of Systems & Software, 2013, 86(3):744-750.
[12] Ma Q, Steenkiste P, Zhang H. Routing high-bandwidth traffic in max-min fair share networks[C]//Conference proceedings on Applications, technologies, architectures, and protocols for computer communications. ACM, 1996:206-217.
[13] Cao Z, Zegura E W. Utility max-min: an application-oriented bandwidth allocation scheme[C]//INFOCOM '99. Eighteenth Joint Conference of the IEEE Computer and Communications Societies. Proceedings. IEEE. IEEE Xplore,1999,2:793-801.
[14] Tang S, Lee B S, He B, et al. Long-term resource fairness: Towards economic fairness on pay-as-you-use computing systems[C]//Proceedings of the 28th ACM international conference on Supercomputing. ACM, 2014: 251-260.
[15] Ghodsi A, Zaharia M, Hindman B, et al. Dominant resource fairness: fair allocation of multiple resource types[C]//Usenix Conference on Networked Systems Design and Implementation. USENIX Association, 2011:323-336.
EARNCACHE:ANINCREMENTALBIGDATACACHINGSTRATEGY
Guo Junshi Luo Yifeng
(ShanghaiKeyLabofIntelligentInformationProcessing,SchoolofComputerScience,FudanUniversity,Shanghai200433,China)
In shared big data clusters, there exists intense competition for memory resources, which may lead to unfairness and low efficiency in cache utilization. In view of this and based on the characteristics of big data applications, we propose an incremental caching strategy called EarnCache. The basic idea is that the more frequently a file is assessed, the more cache resource it gains. We utilize file accessing information, and further formulize and solve cache allocation and replacement problem as an optimization problem. EarnCache and other cache replacement algorithms like MAX-MIN are implemented on a distributed file system and analyzed in detail. The experimental evaluation demonstrates that EarnCache could enhance the cache efficiency for shared big data clusters with improved resource utilization.
Big data Cache allocation Incremental
2017-03-02。郭俊石,硕士生,主研领域:数据库与知识库。罗轶凤,博士。
TP3
A
10.3969/j.issn.1000-386x.2017.11.008
猜你喜欢
当代陕西(2022年6期)2022-04-19 12:12:22
中学生数理化·中考版(2019年9期)2019-11-25 09:39:44
当代陕西(2019年13期)2019-08-20 03:54:22
电脑与电信(2018年12期)2018-03-23 02:37:36
高中生学习·高二版(2016年11期)2016-12-01 20:00:48
电信科学(2016年9期)2016-06-15 20:27:25
中国卫生(2015年3期)2015-11-19 02:53:16
电子设计工程(2015年16期)2015-02-27 12:07:58
华东理工大学学报(自然科学版)(2014年1期)2014-02-27 13:48:36
测绘科学与工程(2014年5期)2014-02-27 07:06:14
