
基于Storm的工业流水线实时分析系统设计与实现
2017-12-08 03:15:46陈志云肖楚乔
计算机应用与软件 2017年11期
陈志云 肖楚乔
(华东师范大学计算机科学与软件工程学院 上海 200062)
基于Storm的工业流水线实时分析系统设计与实现
陈志云 肖楚乔*
(华东师范大学计算机科学与软件工程学院 上海 200062)
随着全球云计算、大数据、物联网和人工智能等技术在工业领域的兴起,数据成为了工业4.0时代的核心驱动力。为了弥补Hadoop分布式系统在实时工业数据处理中显现的不足,提出基于Storm的工业流水线实时分析系统。该系统通过嵌入SDK实时采集终端数据,利用Nginx服务器将数据转换成日志文件,并采用分布式消息系统Kafka缓存,消息流入Storm进行分析处理后,将结果存入HBase中。最后从系统的保障性,并行性和实时性等方面进行分析,表明该系统非常可靠地将各个终端收集到的工业数据实时转换成有价值的信息输出,方便数据资源的汇总与优化。
工业大数据 Storm Kafka
0 引 言
近年来,各发达国家均从战略层面提出了一系列大数据技术研发计划,我国也在2013年提出了《大数据技术与产业发展白皮书》[1-2]。并且随着德国“工业4.0”,美国“制造业回归”和“中国制造2025”的提出,各行各业的决策正在从“业务驱动"转变到"数据驱动”[3-4]。如何利用大数据分析技术将得到的工业数据再创造成新的知识与价值,成为了第四次工业革命的最终目标之一[5-6]。面对设备控制器、制造系统、流水线等设备层产生的更为复杂多源、实时易变的海量工业数据,如何实时地将各个地区的工业数据上传到上层的制造执行管理系统MES,帮助企业优化资源配置,整合分散在各个系统中的数据资源,提供智能预测,已成为制造业面临的新挑战[7-8]。
工业大数据可广泛应用于企业的整个生产过程,例如研发设计、供应链、生产制造、营销与服务环节。在设备仿真阶段,玛莎拉蒂通过数字化工具加速产品设计,将研发效率提升30%。在生产制造环节中,通过生产线、生产设备等抓取数据,再利用无线通信传输数据,从而对生产本身实时监控[9-11]。不仅如此,IBM、EMC、华为等企业也都在开源大数据软件之上研发面向制造业的转型升级的大数据产品和系统[12]。随着国内外不断出现许多基于Storm的实时分布式流处理计算平台,例如:360实时平台、新浪实时分析平台、腾讯实时计算平台、阿里JStorm等[13-14],加之Storm还可以很方便地集成现有的各种技术框架,例如Kafka、HBase、HDFS等,使得Storm的应用领域和场景越来越广泛。
1 实时流处理相关技术
1.1 流式计算框架Storm
由Twitter公司开源的Storm,被广泛应用于实时分析统计,在线机器学习、持续计算、ETL等领域。Storm的出现解决了Hadoop不能处理实时数据的问题。但是Storm与Hadoop同样都是主从系统架构,由一个主节点运行Nimbus进程和多个从节点运行Supervisor进程,并且使用Zookeeper协作框架协调工作[15-16]。
1.1.1 Storm数据流模型Topology
在Storm中数据流stream可以抽象视为不间断且连续的tuple元组。由spout组件作为tuples的发送者,根据数据源的不同,spout可以订制化开发。bolt组件称为处理器,每个bolt可以消费任意数量的tuples,也可以发送给别的bolt。为了提高处理的效率,一般会有多个spout和bolt。Storm将此数据流模型称为Topology,如图1所示。Topology和Hadoop的job不同之处在于:job执行完后会主动停止,而Topology不会自动停止。
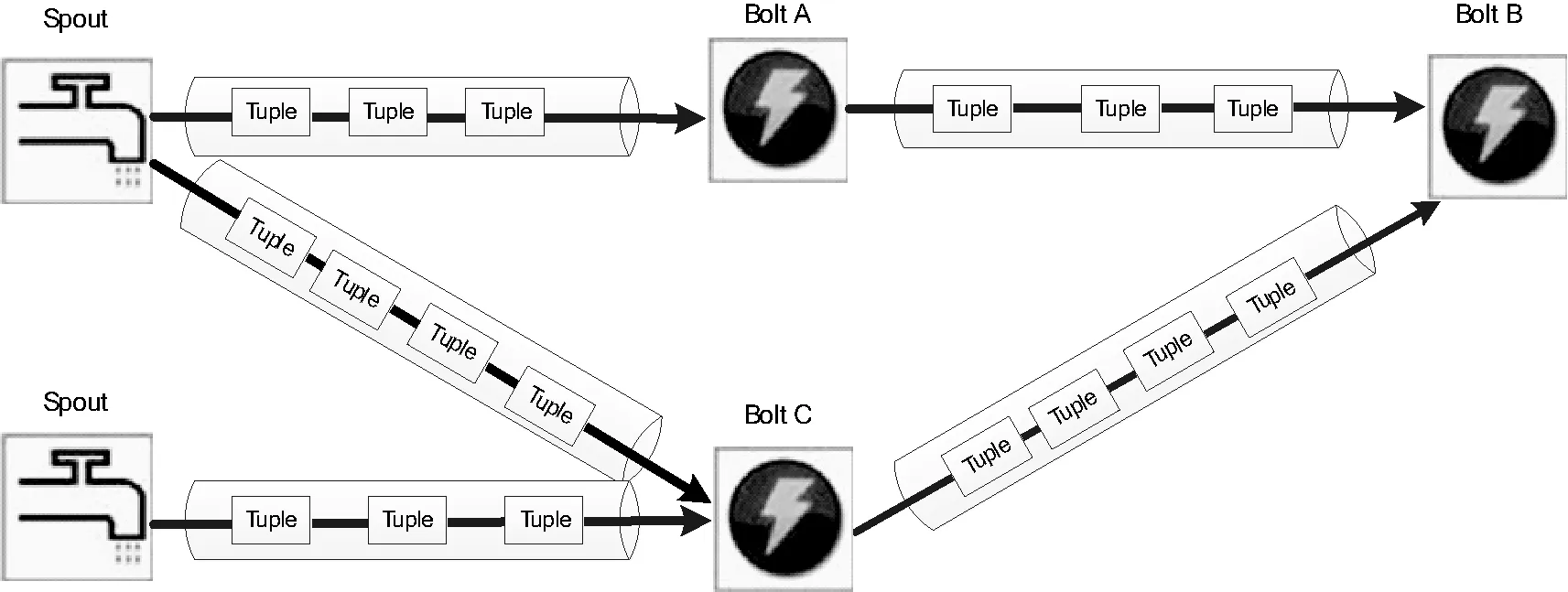
图1 拓扑模型示例
1.1.2 Storm框架的主从架构
Nimbus作为主节点的守护进程,监听Client提交的Topology。同时根据worker资源情况,计算每一个task应该如何在worker中分配,并且在Zookeeper上存储task和worker的对应信息。Supervisor作为Storm集群从节点上的运行进程,定时从Zookeeper上检查并获取最新的tasks到worker中。每个Supervisor可以有多个worker进程,worker进程又会启动多个executor去执行task。实际中executor的并发数量就可以代表Storm集群的并行度。Zookeeper在完成主从节点协调工作的同时,还创建节点监控task的心跳,如图2所示。
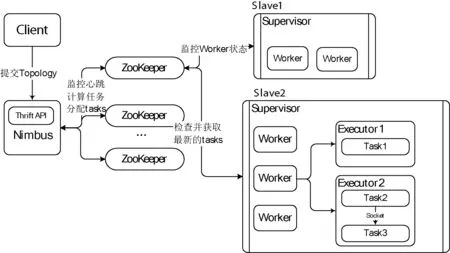
图2 Storm主从架构图
1.2 分布式消息系统Kafka
Kafka是一种分布式消息发布与订阅架构,常用于网页行为跟踪、运营数据监控、日志聚合和流处理等场景[17]。Kafka中的主题Topic是可以被多个消费者共享的队列,并且可以有多个partition,每个partition分布在不同的代理Broker中。Producer作为消息的生产者,根据指定的partition和消息id,将消息push到指定的partition中。Consumer作为消息的消费者,通过pull的方式从Broker中订阅并消费消息,流程如图3所示。
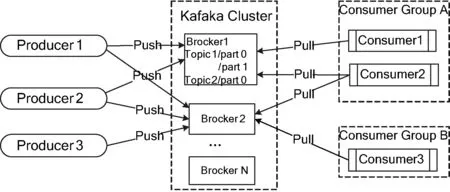
图3 Kafka消息流程图
1.3 文件收集库框架Flume
Flume是仅基于Linux环境的分布式日志数据收集服务框架[18]。它是一个简单的可扩展的数据模型,常用于实时数据分析。Flume中events是数据传输的基本单元,Source通过监控某个文件,拿到日志数据封装到event中,并且put到channel队列中。Sink会主动到channel中拉取数据,再写到下一个地方,如图4所示。
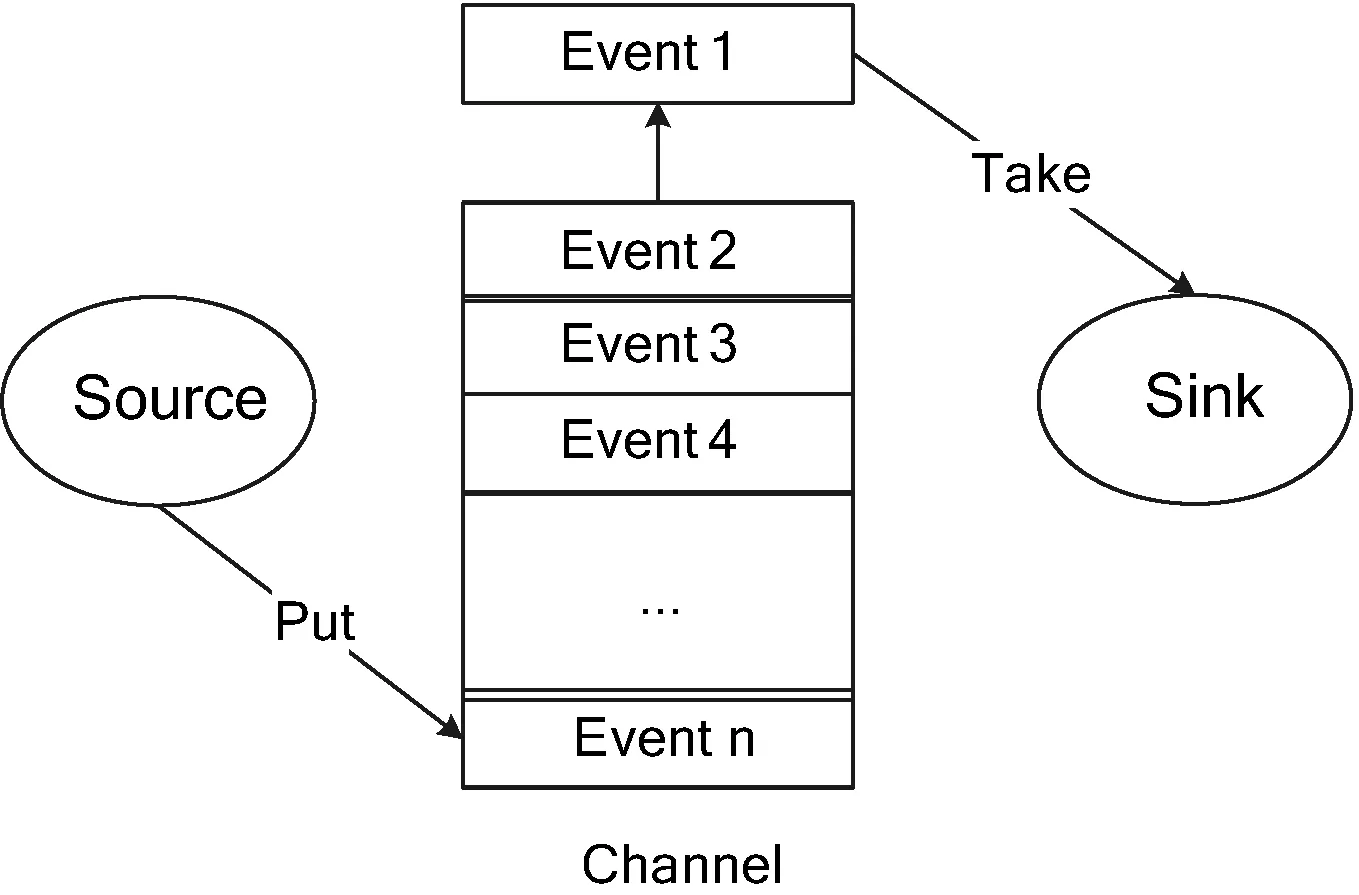
图4 Flume框架流程图
2 基于Storm的工厂流水线实时分析系统
目前工业生产过程正在不断地迈向智能化和信息化时代,如何对工业流水线的高效管理,将成为企业市场竞争力的保障[19]。但是目前的流水线管理方面仍然存在信息容量有限,无法及时更新信息,易丢失等缺点[20]。针对流水线具有实时和大量的特点,提出一种基于Storm的工厂流水线实时分析系统:从移动端或PC端实时上传流水线数据,生成Nginx日志,通过Storm的Topology实时分析各个厂区和各类型生产线上的生产总量、产品类型、终端编号等信息。并且设计了基于Storm的ack保障机制可以防止数据的丢失,使HBase可以实现持久化的存储。操作人员只需要在终端输入一些简单的流水线信息,企业管理人员便可以直接看到各地区工厂流水线生产状况。
2.1 系统框架
本文设计的系统采用Storm+Kafka+Flume+Nginx+HBase的实时流处理框架,流水线数据会在终端被输入的同时转换成日志格式。日志通过Flume读取到Kafka的topic主题中,并且此主题存在Zookeeper上。然后设计Kafka-Spout不断向Storm发送日志记录,通过Topology对记录分析,并将分析结果持久化保存到HBase中。
(1) 数据收集层:本层属于数据源层,通过不同的嵌入SDK创建event采集需要的流水线的数据信息。例如:流水线类型和编号、产品类型和数量、厂区编号、出现的问题等数据。
(2) 日志生成层:通过Nginx服务器,将获取到的数据转成日志文件,并且按照时间点进行日志分割。日志格式定义:
log_format access ′remote_addr remote_user [time_local] ″request″ status body_bytes_sent ″http_referer″ ″http_user_agent″ ′;
(3) 生产者层:通过Flume Agent监控Nginx的日志文件,通过tail命令不断读取日志文件,并传输到Kafka的指定Topic中。
(4) 主题队列层:本层是Kafka集群,因为具备水平扩展和高吞吐量等特性,用来保障输入数据的负载均衡和消息缓冲。该层的设计是防止数据采集端和Storm处理速度不同而导致的数据丢失。
(5) 业务逻辑层:构建Topology,对日志文件中每条记录进行拆分、分流、汇总,并实时发送到HBase中持久化存储。
(6) 持久化存储:选择HBase,因为其适用于海量数据存储和实时查询,并且有良好的兼容性,支持多种大数据框架。
流水线实时分析框架如图5所示。

图5 基于Storm的工厂流水线实时分析框架
2.2 Storm业务逻辑层的设计
2.2.1 Topology方案设计
为了增加消息发送的灵活度,Storm中通过Streamgrouping定义一个stream应该如何分配bolt上的多个task。在Storm中有6种类型的流发送方式:Shuffle grouping、Fields grouping、All grouping、Global grouping、Non grouping和Direct grouping。Shuffle表示随机分组,可保证每个bolt接收到的tuple数基本相等。Fields表示按字段分组,具有相同id的tuple会被发送到相同的bolt中。Global表示全局分组,Tuple只会被分配到一个bolt中。
针对Storm的拓扑模型和流分发策略,设计了如图6所示的拓扑结构。

图6 流水线实时分析Topology
此拓扑共分为5个阶段。
(1) 由于所有的日志记录都存在Kafka集群的消息队列中,因此设计Spout采用KafkaSpout。直接引用storm.kafka.*包,创建实例化KafkaSpout,通过提供的topic参数读取zookeeper上的主题位置。采用shufflegrouping的方式将记录随机发送给LogSplitBolt。
(2) LogSplitBolt对发送来的tuple进行解析,抽取各个字段。然后按照Stream设定的id号采用fieldsgroup流发送方式给HttpSplitBolt、IPCountBolt、AgentSplitBolt。
(3) HttpSplitBolt是将URL中传入的流水线参数和产品参数抽取出来,按照Stream设定的id号fieldsgroup发送给LineCountBolt和ProdCountBolt。同理,AgentSplitBolt将useragent中传入的browser和os信息抽取出来分id发送给BrowCountBolt和OSCountBolt。
(4) IPCountBolt、LineCountBolt、ProdCountBolt、BrowCountBolt、OSCountBolt作为计数模块,统计各个id的次数。并采用globalgrouping流发送方式到HBaseBolt。
(5) HBaseBolt设计。首先在prepare函数中创建Configuration对象并加载配置文件hbase-site.xml,连接数据库;然后再在execute函数中设计相应字段名称put到HBase中。
2.2.2 Tuple树的设计
Tuple元组是对Stream的抽象,每一个tuple可以包含多列,每列都是一个
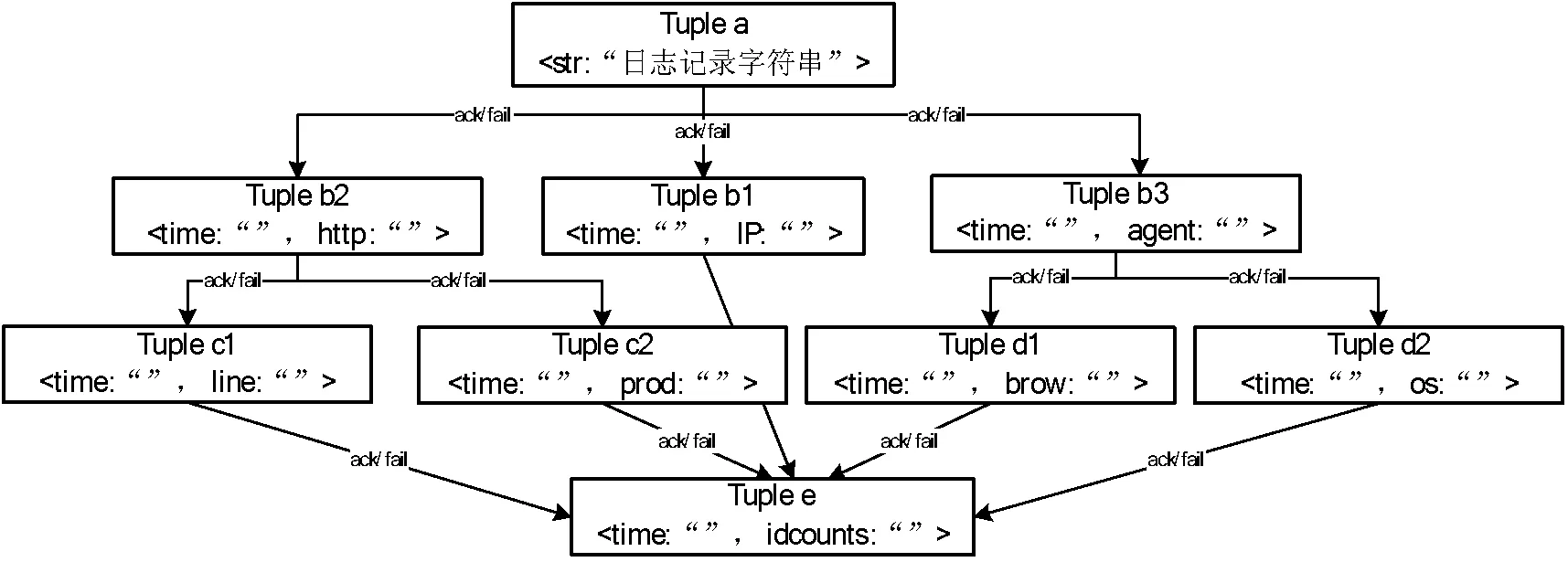
图7 Tuple树
此Tuple树是数据流Stream在Topology中的抽象表示。首先KafkaSpout将每一条日志记录封装成Tuple a格式流入到LogSplitBolt中。LogSplitBolt中设计正则表达式来抽取需要的字段,再构建并流出 Tuple b1、b2、b3。然后由HttpSplitBolt将Tuple b2重新构建成Tuple c1 和c2流出。由AgentSplitBolt将Tuple b3重新构建成Tuple d1和d2流出。IPCountBolt、LineCountBolt、ProdCountBolt、BrowCountBolt、OSCountBolt将流入的Tuple格式统一重新构建成Tuple e,最后流入HBaseBolt中。为了保障每个Tuple都被正确的处理,Storm有ack保障机制,采用异或算法。可以保障这个Tuple以及这个Tuple所产生的子Tuple都被成功的处理。
2.3 HBase设计
为了将实时统计的数据存到HBase中,设计表Counts。创建:hbase> create ‘Counts’,{Name=>’infos’,VERSION=>2147483647,BLOOMFILTER=>’ROWCOL’}。
将VERSION设置为Integer类型最大值,可以查看历史数据,如表1所示。
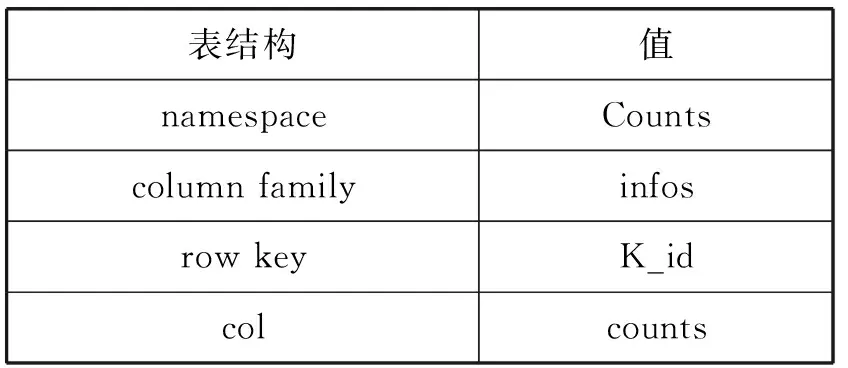
表1 Counts表
3 实验与分析
实验环境:由2台PC机组成集群;操作系统:CentOS 6.4,内存32 GB,JDK1.7,Core i7-6820HQ。集群信息如表2所示。
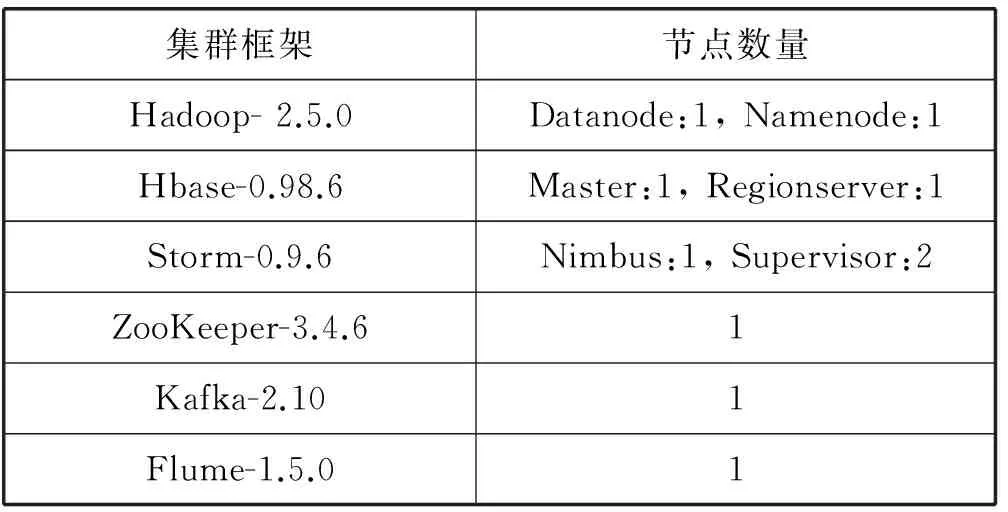
表2 集群信息
3.1 系统可靠性测试
实验采用运行Jar包模拟每1 ms产生1条Nginx日志记录。当数据源快速流出tuple时,计算tuple在无保障机制时的丢失率和采用ack保障机制后的tuple丢失率,为了保证准确性,采用3次数据的平均值。可以清晰地看出,保障机制有效地降低了tuple的丢失率,如图8所示。
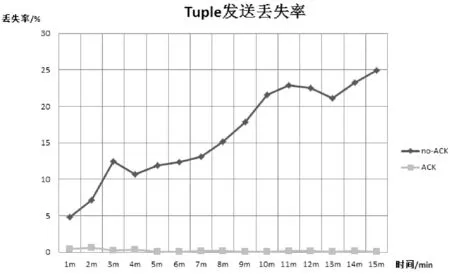
图8 Tuple失败率
通过上述图表可以看出该系统能有效地保障流水线数据信息的准确性,非常适用于工厂流水线实时生产的模式。
3.2 系统并行度测试
通过Storm UI可以方便地看到Topology的详细信息。Capacity参数代表的是拓扑并行度,参数值越接近1,表示该组件的并行度不够,需要适当地扩展组件的executor数量。通常情况下,一个worker里executor数量必须小于等于给定的task数量。所以通过改变线程数量,分析该系统的横向扩展能力,结果如图9所示。
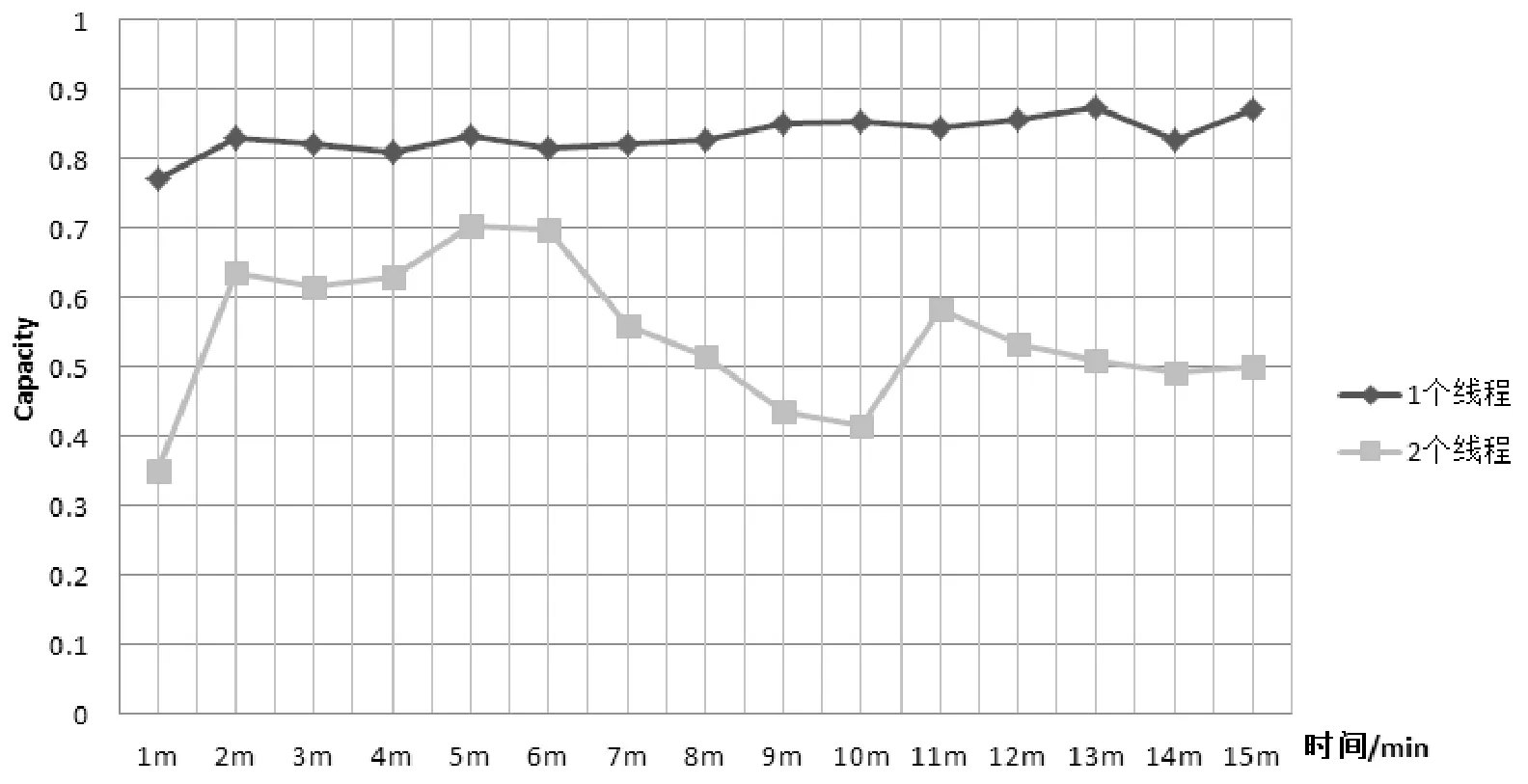
图9 并行度测试
通过图9可以看出该系统通过增加线程数量,确实可以有效降低Capacity数值,提高系统的并行度。
3.3 系统实时计算性能
通过表3可以得出系统实时计算总量和时间的关系,从而证明该框架有良好的健壮性和实时性。

表3 处理数据量和时间关系
4 结 语
随着国家工业转型升级的开始,工业大数据的应用将越来越多,而工厂中实时产生的海量数据将是创造智慧工厂的关键。本文通过对Storm架构的简单分析,结合多种开源框架,实现了一个基于Storm的工业流水线实时分析系统。该系统有良好的保障性和并行性。由于Storm是分布式流计算框架,因此该系统有良好的可扩展性、容错性、实时性。并且该系统采用开源框架,因此简单易搭建,且采用Linux环境具有平台通用性。接下来的工作是结合机器学习算法,训练数据实现预测。
[1] 张礼立.数据是工业4.0的核心驱动[J].中国工业评论,2015(12):36-43.
[2] 李国杰,程学旗.大数据研究:未来科技及经济社会发展的重大战略领域——大数据的研究现状与科学思考[J].中国科学院院刊,2012,27(6):5-15.
[3] 罗文.德国工业4.0战略对我国工业转型的启示[J].玻璃钢/复合材料,2014(11):125-128.
[4] 李杰,刘宗长.中国制造2025的核心竞争力——挖掘使用数据[J].博鳌观察,2015(4):52-55.
[5] Addo-Tenkorang R,Helo P T.Big Data Applications in Operations/Supply-Chain Management:A Literature Review[J].Computers & Industrial Engineering,2016,101:528-543.
[6] Rousseaux F.BIG DATA and Data-Driven Intelligent Predictive Algorithms to support creativity in Industrial Engineering[J].Computers & Industrial Engineering,2016.
[7] 高婴劢.工业大数据价值挖掘路径[J].中国工业评论,2015(s1):21-27.
[8] 孔宪光,章雄,马洪波,等.面向复杂工业大数据的实时特征提取方法[J].西安电子科技大学学报自然科学版,2016,43(5):70-74.
[9] 王建民.工业大数据技术[J].电信网技术,2016(8):1-5.
[10] 单莘,祝智岗,张龙,等.基于流处理技术的云计算平台监控方案的设计与实现[J].计算机应用与软件,2016,33(4):88-90.
[11] 万英杰,鲍远松,黄明.分布式工业数据实时分析计算平台[J].信息技术与标准化,2016(11):61-63.
[12] 黄明峰.工业大数据发展态势与典型应用[J].电信科学,2016,32(7):175-178.
[13] Sun D W,Zhang G Y,Zheng W M.Big data stream computing:technologies and instances[J].Journal of Software,2014,25(4):839-862.
[14] 孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013(1):146-169.
[15] Hadoop[EB/OL].[2017-01-19].http://hadoop.apache.org/.
[16] Storm[EB/OL].[2017-01-19].https://storm.apache.org/.
[17] Kafka[EB/OL].[2017-01-19].https://kafka.apache.org/.
[18] Flume[EB/OL].[2017-01-19].https://flume.apache.org/.
[19] Zhang Y,Xu J,Sun S,et al.Real-time information driven intelligent navigation method of assembly station in unpaced lines[J].Computers & Industrial Engineering,2015,84(C):91-100.
[20] 李二霞.大数据在立柱维修流水线的应用[J].科技创新与应用,2015(30):18-19.
DESIGNOFINDUSTRIALASSEMBLYLINEREAL-TIMEANALYSISSYSTEMBASEDONSTORMANDITSIMPLEMENTATION
Chen Zhiyun Xiao Chuqiao*
(SchoolofComputerScienceandSoftwareEngineering,EastChinaNormalUniversity,Shanghai200062,China)
With the rise of cloud computing, big data, IoT, AI, etc. in the global industrial field, the data has become the core driving force of Industry 4.0 era. In order to make up for the shortage of Hadoop distributed system in real-time industrial data processing, this paper presents an industrial assembly line real-time analysis system based on Storm. The system collects real-time terminal data through the embedded SDK, converts the data to the log file through the Nginx server, and uses the distributed information system Kafka as cache, then the message flowing into Storm and the results stored in HBase. Finally, the analysis of the system from the aspects of security, parallelism and real-time performance shows that the system converts the industrial data collected by each terminal into valuable information to facilitate the aggregation and optimization of data resources reliably.
Industrial big data Storm Kafka
2017-02-05。陈志云,副教授,主研领域:多媒体应用与教育技术。肖楚乔,硕士生。
TP311
A
10.3969/j.issn.1000-386x.2017.11.009
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22 14:50:17
小资CHIC!ELEGANCE(2022年1期)2022-01-11 00:49:59
华人时刊(2021年13期)2021-11-27 09:19:02
心声歌刊(2020年4期)2020-09-07 06:37:14
数学物理学报(2020年3期)2020-07-27 01:19:46
小学科学(学生版)(2020年2期)2020-03-03 13:40:16
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
法大研究生(2017年1期)2017-04-10 08:55:06
中国资源综合利用(2016年9期)2016-01-22 08:35:22
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:21
