
放宽生育政策与家庭储蓄率
——基于倾向得分匹配法的分析
2017-12-07 11:18:10王鑫
市场周刊 2017年11期
王鑫
放宽生育政策与家庭储蓄率
——基于倾向得分匹配法的分析
王鑫
文章使用CFPS2014数据来研究放宽生育政策对家庭储蓄率的影响。本文通过倾向得分匹配法估计平均处理效应来纠正自选择性所导致的估计偏误。在研究了二胎家庭和独生子女家庭储蓄率的差异后发现,二胎家庭的储蓄率显著低于独生子女家庭的储蓄率。进一步地将家庭按收入高低分类,分成中低收入家庭和高收入家庭,发现对中低收入家庭,二胎家庭的储蓄率显著低于独生子女家庭,而对于高收入群体,结果并不显著。
倾向得分匹配;家庭储蓄率;放宽生育政
一、引言
从70年代开始,政府在全国范围内实施计划生育,并在1982年将计划生育写入宪法,此后计划生育一直被当作国策予以贯彻实施。计划生育政策在控制人口快速增长中发挥了一定的作用,但也带来了生育率不断下降,老龄化不断加重等种种弊端。为了应对这些问题,政府于2016年起正式全面实施二胎政策。二胎政策的全面实行会引起一系列的经济反应。从微观层面来看,许多家庭随着第二个孩子的到来,家庭预算约束面临着改变,父母必须要在有限的资源约束下权衡消费和储蓄来达到自身效用最大化。储蓄率作为家庭跨期最优决策的结果,将会怎么变化呢?
已有的关于放开生育政策对储蓄率影响的研究并不多,结论也不一致,尚未达成共识。放开生育政策会导致子女数量的上升,改变家庭对子女的培养成本,而家庭对子女培养成本的改变主要取决与家庭对子女的重视程度。汪伟认为子女数量越多,父母对子女的培养重视度会下降,父母会增加教育支出从而减少家庭储蓄。王建志认为增加子女数量会增加父母对未来的时间偏好从而降低个人的即期消费,增加居民储蓄。还有些学者认为放宽生育政策对储蓄率没有影响。刘永平等认为增加子女数量并不会改变储蓄率。他认为放宽生育政策可能会增加储蓄也可能会减少储蓄,存在两种相互抵消的正负效应。
从研究方法上来看,已有的这方面研究多是集中于OLS或者固定效应估计,而笔者认为,用OLS或者固定效应估计会忽视自选择性这一问题。子女数量的选择并不是随机的,而是具有自选择性的,是决策者根据家庭综合多方面的因素(例如家庭特征、政策因素等)做出的决定,因此二胎家庭和独生子女家庭往往在总体上存在差异。如果单纯的利用包含是否是二胎家庭虚拟变量的经典线性回归模型来估计,这种自选择性往往会造成OLS估计结果的偏误。近年来,一些学者通过采用倾向匹配得分法,能够很好将自选择性所导致的估计偏误这一问题得以解决。因此,本文将借鉴倾向得分匹配的思想,对样本进行匹配,通过控制协变量,来解决自选择性所导致的估计偏误。
二、数据来源和变量描述性统计
(一)数据来源
本文使用中国家庭追踪调查(China Family Panel Studies,CFPS)2014年数据开展实证研究。CFPS数据是由北京大学中国社会科学调查中心主持进行的,通过对全国25个省份的162个县的635个社区(或村庄)进行抽样调查。该调查采用分层多阶段抽样,对于全国人口具有95%的代表性,因此本文所采用的样本数据具有很好的代表性。本文以家庭作为研究对象,将家庭户主的年龄控制在18-65岁,剔除缺失值最后得到关于7402个家庭的样本数据。其中,处理组二孩家庭有4461个,占60.27%,控制组独生子女家庭有2941个,占比39.73%。
储蓄率是本文实证研究的被解释变量,本文采用两种常见的定义方式。第一种储蓄率是根据经济学含义,用家庭收入与家庭消费支出的差值除以家庭收入,记作sr1。第二种储蓄率的定义方式用家庭收入的对数与家庭消费支出的对数差,也同时借鉴李雪松和黄彦彦的方法,删去小于-200%的极端值。这样做是为了减少极端的离群值对分析结果的负面影响,误差项也更能够趋近正态分布。
(二)变量选取
应用倾向得分匹配方法选择协变量要求匹配变量应该是影响家庭储蓄率及家庭生育选择的协变量,而不是受到家庭生育决策影响的协变量,结合调查数据,本文选取的协变量主要有:
1.户主特征变量,主要包括户主的性别、年龄、婚姻状况、学历状况。
2.家庭特征变量,主要包括是否是城镇家庭、所处的位置、家庭人口数、是否有未婚子女、家庭消费支出、是否拥有房屋产权、房屋的总价值及是否拥有房屋产权与房屋总价值的交互项。表1给出了各协变量的定义与描述性统计。

表1 变量的定义与描述性统计
三、估计结果与相关检验
(一)是否是二胎家庭对家庭储蓄率影响的估计结果
本文采用一对一匹配法来检验二胎家庭和独生子女家庭储蓄率的差异。表2列出了这一估计结果。

表2 是否是二胎家庭对家庭储蓄率的影响
从该表中可以看出,经过匹配后二胎家庭和独生子女家庭的储蓄率对数差异为0.077,高于匹配前的0.029,且结果更显著。这意味着,如果没有考虑选择性偏差,会低估估计结果。
(二)平衡性检验
使用匹配法时,需要注意的是独生子女家庭和二胎家庭样本组之间的平衡性问题,即经过匹配后,独生子女家庭和二胎家庭的样本之间除了家庭储蓄率存在差异外,在协变量方面不应该存在显著的系统性差异。平衡性检验结果如下表所示:
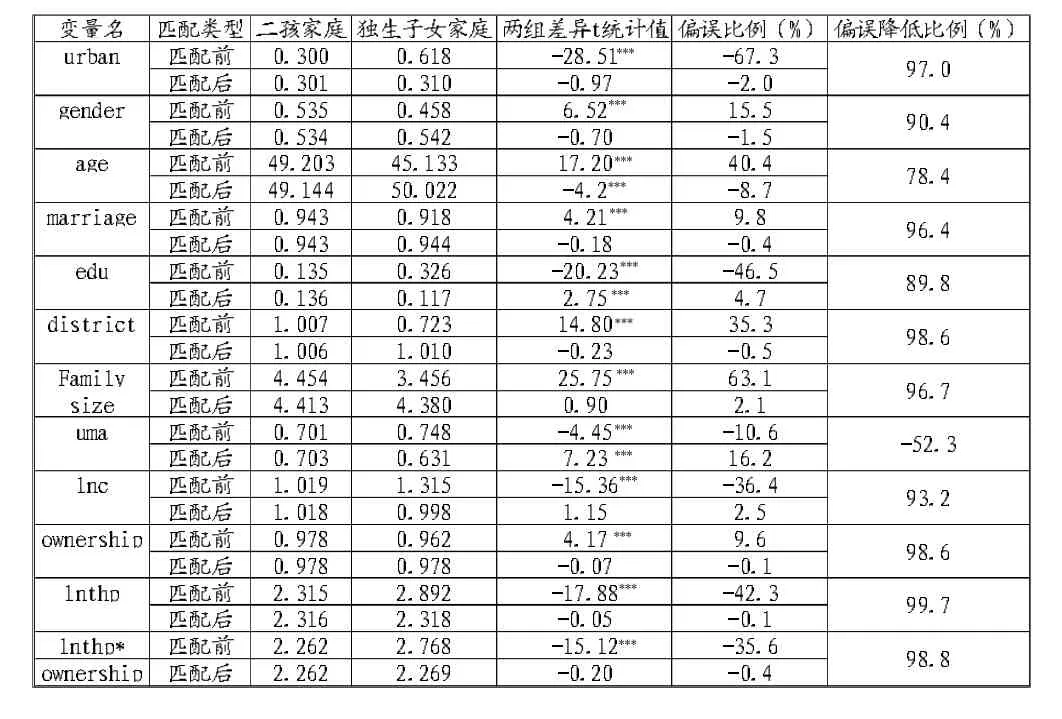
表3 二孩家庭与独生子女家庭样本组的平衡性
从上表中可以看出,经过匹配后,大部分特征变量的偏误比率都降到了10%以下。经过匹配后,偏误(绝对值)降低的比率都超过了50%,最高的达到了99.7%,这说明倾向得分匹配方法确实能够大大降低二胎家庭与独生子女家庭样本之间的差异。因此,样本匹配后基本能够通过平衡性检验,两组样本之间进行匹配所使用的协变量存在的差异很小,自选择性导致的估计偏误被大大削弱。

表4 稳健性检验结果一
(三)稳健性检验
本文尝试从两个方面进行稳健性分析。首先是改变被解释变量的定义方式,采用另一种储蓄率的定义。其次将收入从低到高排,将70%以下的人群定义为中低收入人群,70%以上的人群定义为高收入人群,来比较这两类人群中,二胎家庭与独生子女家庭储蓄率的差异。
1.稳健性检验一:采用另一种储蓄率定义
采用作为被解释变量,估计结果见表4。从表4可以看出,采用对数差减少极端值后,估计结果依然显著。
2.稳健性检验二:将家庭按收入分为中低收入家庭和高收入家庭
从上表中可以看出,对于中低收入家庭而言,二胎家庭的储蓄率要显著的比独生子女家庭低,而对于高收入家庭来说,二胎家庭的储蓄率也是要比独生子女家庭的储蓄率低,但这一结果并不显著。
四、研究结论
本文利用CFPS2014调查数据分析了家庭生育决策对家庭储蓄率的影响。结果显示,二胎家庭和独生子女家庭平均处理效应约为-7.7%。这说明二胎家庭的储蓄率确实低于独生子女家庭。进一步的,将家庭分为中低收入家庭和高收入家庭,发现对于中低收入家庭而言二胎家庭储蓄率要显著低于独生子女家庭,而对高收入家庭结果并不显著。
相比已有的关于生育政策和储蓄率的研究,本文的优点是采用了倾向得分匹配的方法,可以有效地解决自选择性带来的估计偏误问题,结果更有说服力。同时,本文还存在一些拓展空间,比如进一步的研究二胎家庭相对与独生子女家庭储蓄率下降的原因。目前,从放宽生育政策角度来解释家庭储蓄率的研究较为少见,本文对这一问的探索做出了一定的补充。
[1]刘永平,陆铭.放松计划生育政策将如何影响经济增长——基于家庭养老视角的理论分析[J].经济学(季刊),2008,(04).
[2]王建志,任继球,齐乾.我国居民消费问题研究——基于子女数量、内生时间偏好视角[J].宏观质量研究,2016,(03).
[3]梁文艳.“留守”对西部农村儿童学业发展的影响——基于倾向分数配对模型的估计[J].教育科学,2010,(05).
[4]李雪松,黄彦彦.房价上涨,多套房决策与中国城镇居民储蓄率[J].经济研究,2015,(09).
[5]汪伟.人口老龄化、生育政策调整与中国经济增长[J].经济学(季刊),2016,(16).
[6]李云森.自选择、父母外出与留守儿童学习表现——基于不发达地区调查的实证研究[J].经济学(季刊),2013,(03).
[7]陶然,周慧敏.父母外出务工与农村留守儿童学习成绩——基于安徽、江西两省调查实证分析的新发现与政策含义[J].管理世界,2013,(08).
C92-05
A
1008-4428(2017)11-115-02
王鑫,男,江苏溧水人,南京财经大学经济学院硕士研究生,研究方向:计量经济学理论与应用。
猜你喜欢
遵义(2018年21期)2018-11-19 06:34:56
金桥(2018年1期)2018-09-28 02:24:50
海外华文教育(2017年8期)2017-11-07 04:42:02
海外华文教育(2016年4期)2017-01-20 08:22:28
公民与法治(2016年14期)2016-05-17 04:15:19
祝你幸福·知心(2014年10期)2014-11-18 10:36:10
时代金融(2014年16期)2014-11-10 07:36:24
党建文汇·下(2014年6期)2014-08-26 11:21:59
北方经济(2012年7期)2012-04-29 20:16:31
海外华文教育(2012年3期)2012-03-20 14:05:01
