
R语言在卫生统计学均数抽样分布教学中的应用
2017-12-06 03:46:32高启胜
浙江医学教育 2017年4期
高启胜
(杭州医学院,浙江 杭州 310053)
·教学研究与管理·
R语言在卫生统计学均数抽样分布教学中的应用
高启胜
(杭州医学院,浙江 杭州 310053)
抽样误差和中心极限定理是卫生统计学教学中的重点和难点,纯理论讲授学生理解较为困难。利用Excel、SPSS、SAS等软件虽然可以进行随机抽样模拟试验,但编程语言较为复杂。R语言能够生动形象地展现从不同总体中进行随机抽样样本均数的分布规律,有助于学生理解均数抽样分布规律,提高教学效果。R语言具有丰富的统计函数和强大的绘图功能等优点,在卫生统计学各类常用统计量抽样分布教学中有重要应用价值。
R语言;卫生统计学;抽样分布
由于个体变异的存在,在抽样研究中产生样本统计量和总体参数之间的差异或各样本统计量之间的差异,称为抽样误差。假设一个已知总体,从该总体中抽样,对每个样本计算统计量(均数、标准差等),观察样本统计量的分布规律称为抽样分布规律。抽样误差和抽样分布是统计推断的重要基础理论,由于这一内容比较抽象,也成为卫生统计学教学的难点。近年来,R语言因其开源免费、丰富的统计函数和模块、灵活强大的绘图功能等优点,在国内外大学统计教学和科研中获得广泛应用[1-3]。本文尝试利用R语言进行样本均数的随机抽样模拟试验,形象地展示抽样分布的规律以提高卫生统计学教学效果。
1 函数模拟及程序
1.1 均数抽样分布
分别设随机变量X服从总体均数为5,标准差为2的正态分布,X~N(5,22);随机变量Y服从总体均数和总体标准差为5的指数分布,Y~E(1/5); 随机变量Z服从区间[1,9]上总体均数为5,总体标准差为2.3的均匀分布,Z~U(1,32)。运用R语言编程进行随机抽样实验,参考程序如下:

表1 函数模拟参考程序
程序第1行设定图形布局,按列顺序绘图,为4行3列。程序2-9行为编写泛式sim.fun函数,其中,m为模拟样本次数,X代表需模拟的多个函数。第10行定义函数X为从总体均数为5,标准差为2的正态分布中随机抽样的样本均数。第15行定义函数Y为从总体均数和标准差为5的指数分布中随机抽样的样本均数。第20号定义函数Z为从总体均数为5,标准差为2.3的均匀分布中随机抽样的样本均数。第11-14行、16-19行、21-24行分别为按样本含量为1、5、10、30模拟抽样1000次的样本均数的直方图,结果见图1。
抽样实验小结:当n=1时抽样分布可看作从总体中抽取的样本量为1000的一个样本,其频数分布接近总体分布。从正态总体中随机抽样时,样本均数的分布仍呈现正态分布;从非正态总体中随机抽样(指数分布、均匀分布等),当样本含量足够大时,其样本均数的分布逐渐逼近正态分布;样本均数的均数位置始终在总体均数附近;随着样本量的增加,样本均数的离散程度越来越小,表现为样本均数的分布范围越来越窄,其高峰越来越尖。
1.2 中心极限定理
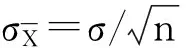

图1 从3个总体中抽取样本量分别为1、5、10和30时样本均数的分布

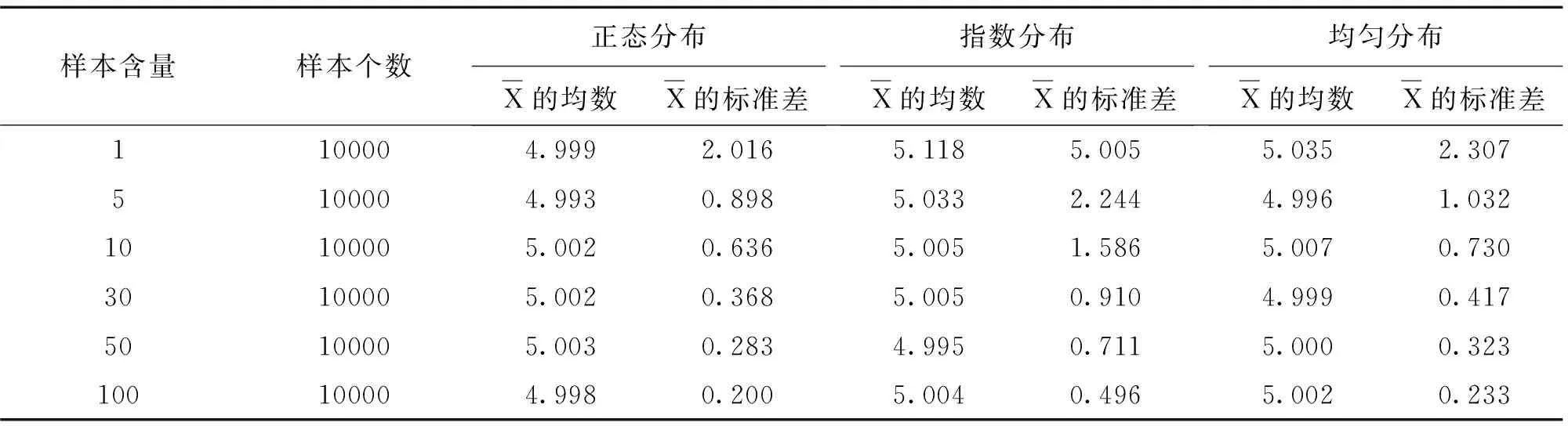
表2 从不同总体中以不同样本量抽样时样本均数和样本标准差的描述结果

表3 以相同样本量从不同正态总体中抽样时样本均数和样本标准差的描述结果
2 动画模拟及程序
在R语言中还可以运用animation扩展包进行中心极限定理的动画模拟实验[4]。默认从总体均数和标准差为1的指数总体分布中按给定的样本量(n=1,…,100)重复抽样300次分别计算样本均数,画出样本均数的直方图和相应的核密度估计曲线,同时运用shapiro.test对均数分布进行正态性检验,并把P值取出来画在下半幅图中。程序第1、2行为安装和载入animation包。第3行为设置时间间隔0.1秒和模拟的最大样本量100。第4行为设定下边距和左边距为4行,上边距和右边距分别为1行和0.5行。第5行为默认进行指数分布动画模拟,结果见图2。可见,当样本量n超过20之后,P值会普遍偏大,可以认为样本均值的分布和正态分布比较接近。此外,可以通过修改clt.ani()函数的参数,设定抽样次数和总体分布。如模拟1000次总体均数为5,标准差为2的正态分布的抽样实验,可设定clt.ani(obs=1000,FUN=rnorm,mean=5,sd=2);模拟1000次总体均数为5,标准差为2.3的均匀分布的抽样实验,可设定clt.ani(obs=1000,FUN=runif,mean=5,sd=2.3)等。

表4 中心极限定理动画模拟参考程序

图2 R语言动画模拟中心极限定理
3 讨论
运用R语言模拟样本均数抽样分布和中心极限定理的程序关键在于编写一个随机抽样循环函数,随后则可以同时纳入多个不同的总体分布。与以往运用SPSS、SAS等商业统计软件进行模拟教学相比,运用R语言主要有以下优势:(1)R语言为免费开源软件,不会引起版权争议;(2)R编程有强大的绘图功能,语言更加简洁高效;(3)R语言除了图形展示外,还定量地验证了样本均数和标准差的变化规律;(4)利用R语言扩展包可以动态模拟并给出正态性检验的P值。此外,R语言能够绘制常用连续性分布和离散性分布概率密度和累计概率曲线,每一种分布均有4个函数:d为密度函数,p为累积概率密度函数,q为分位数函数,r为随机数函数。利用随机数函数可以从对应分布总体中产生随机样本,进行模拟抽样实验。可见,R语言模拟抽样分布在卫生统计学教学中对帮助学生理解各类常用统计量的抽样分布具有重要应用价值。
[1]商豪,杨策平. 浅议 R 软件在概率论与数理统计教学中的运用[J].考试周刊, 2016,(4): 56-57.
[2]熊炳忠.基于R软件的概率统计课程实验教学探析[J].学园,2015,(34): 52-54.
[3]张哲,张豪.浅谈R语言在生物统计学教学中的应用[J].教育教学论坛,2013, (27): 54-55.
[4]赵军,杨琳.R 软件在大学数学教学中的应用探讨[J].高教学刊,2016, (7): 93-95.
TheapplicationofRprogramminglanguageinthemeansampling
GAOQisheng
(Hangzhou Medical College, Hangzhou 310053, China)
Sampling error and central-limit theorem are the important and difficult points in Health Statistics teaching, and it is difficult for students to understand by spoon-feed teaching. Though random sampling simulation tests can be developed by Excel, SPSS, SAS, the programming language is relatively complex. The R programming language can vividly shows sample mean distribution pattern from different population at the same time, which can help stimulate students’ interests in leaning and improve classroom teaching effects. The R programming language provides a wealth of statistic functions and powerful drawing functions, which has important application value in the teaching process of different commonly used statistics sampling distribution of health statistics.
R programming; health statistics; sampling distribution
高启胜(1984-),男,江西鄱阳人,硕士,讲师。研究方向:社会医学与卫生统计学教学和研究
G642.0
B
1672-0024(2017)04-0001-05
distributionteachingofHealthStatistics
猜你喜欢
内蒙古统计(2021年4期)2021-12-06 02:49:20
当代医药论丛(2021年3期)2021-03-17 07:03:12
测控技术(2018年4期)2018-11-25 09:46:52
上海精神医学(2017年5期)2017-11-29 06:03:10
系统医学(2016年8期)2016-02-20 02:55:08
赤峰学院学报·自然科学版(2015年15期)2015-03-21 00:30:56
中国现代医生(2014年20期)2014-08-19 09:39:27
中国现代医生(2014年13期)2014-07-09 01:19:15
中国现代医生(2014年10期)2014-04-23 11:56:10
医学理论与实践(2012年4期)2012-12-09 07:23:25
